DALI 中的音频解码器#
本教程介绍如何设置一个简单的 pipeline,使用 DALI 加载和解码音频数据。我们将使用 Speech Commands 数据集中的一个简单示例。虽然此数据集由 .wav 格式的样本组成,但以下步骤也适用于大多数知名的数字音频编码格式。
逐步指南#
让我们从导入 DALI 和一些实用程序开始。
[1]:
from nvidia.dali import pipeline_def
import nvidia.dali.fn as fn
import nvidia.dali.types as types
import matplotlib.pyplot as plt
import numpy as np
batch_size = 1
audio_files = "../data/audio"
使用的 batch_size 为 1,为了保持简单。
接下来,让我们实现 pipeline。首先,我们需要从磁盘(或任何其他来源)加载数据。readers.file 能够加载数据及其标签。有关更多信息,请参阅文档。此外,与图像数据类似,您可以使用其他特定于给定数据集或数据集格式的读取器操作符(请参阅 readers.caffe)。加载输入数据后,pipeline 解码音频数据。如上所述,decoders.audio 操作符能够解码大多数知名的音频格式。
注意:请记住,您应将正确的数据类型(参数
dtype)传递给操作符。支持的数据类型可以在文档中找到。如果您有 24 位音频数据,并且您设置dtype=INT16,则会导致丢失样本中的一些信息。此操作符的默认dtype为INT16
[2]:
@pipeline_def
def audio_decoder_pipe():
encoded, _ = fn.readers.file(file_root=audio_files)
audio, sr = fn.decoders.audio(encoded, dtype=types.INT16)
return audio, sr
现在让我们构建并运行 pipeline。
[3]:
pipe = audio_decoder_pipe(batch_size=batch_size, num_threads=1, device_id=0)
pipe.build()
cpu_output = pipe.run()
decoders.audio 的输出由包含解码数据的张量以及一些元数据(例如采样率)组成。要访问它们,只需检查另一个输出。最重要的是,decoders.audio 以交错格式返回数据,因此我们需要重塑输出张量以正确显示它。以下是如何做到这一点
[4]:
audio_data = cpu_output[0].at(0)
sampling_rate = cpu_output[1].at(0)
print("Sampling rate:", sampling_rate, "[Hz]")
print("Audio data:", audio_data)
audio_data = audio_data.flatten()
print("Audio data flattened:", audio_data)
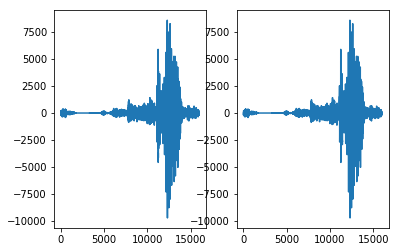
plt.plot(audio_data)
plt.show()
Sampling rate: 16000.0 [Hz]
Audio data: [[ -5]
[ -95]
[-156]
...
[ 116]
[ 102]
[ 82]]
Audio data flattened: [ -5 -95 -156 ... 116 102 82]
验证#
让我们验证 decoders.Audio 实际上是否有效。如果出现问题,所提供的方法也可以方便地用于调试 DALI pipeline。
我们将使用外部工具来解码使用的数据,并将结果与 DALI 解码的数据进行比较。
重要提示!#
以下代码段安装了外部依赖项 (simpleaudio)。如果您已经拥有它,或者不想安装它,您可能希望在此处停止并且不运行此代码段。
[ ]:
import sys
!{sys.executable} -m pip install simpleaudio
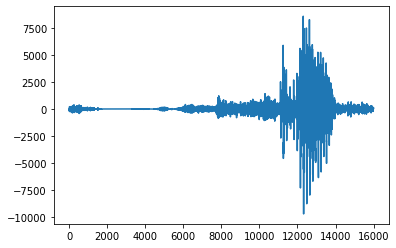
以下是解码数据的并排比较。如果您安装了 simpleaudio 模块,则可以运行该代码段并亲自查看。
[5]:
import simpleaudio as sa
wav = sa.WaveObject.from_wave_file("../data/audio/wav/three.wav")
three_audio = np.frombuffer(wav.audio_data, dtype=np.int16)
print("src: simpleaudio")
print("shape: ", three_audio.shape)
print("data: ", three_audio)
print("\n")
print("src: DALI")
print("shape: ", audio_data.shape)
print("data: ", audio_data)
print(
"\nAre the arrays equal?",
"YES" if np.all(audio_data == three_audio) else "NO",
)
fig, ax = plt.subplots(1, 2)
ax[0].plot(three_audio)
ax[1].plot(audio_data)
plt.show()
src: simpleaudio
shape: (16000,)
data: [ -5 -95 -156 ... 116 102 82]
src: DALI
shape: (16000,)
data: [ -5 -95 -156 ... 116 102 82]
Are the arrays equal? YES