重要提示
您正在查看 NeMo 2.0 文档。此版本对 API 和新库 NeMo Run 进行了重大更改。我们目前正在将 NeMo 1.0 的所有功能移植到 2.0。有关先前版本或 2.0 中尚不可用的功能的文档,请参阅 NeMo 24.07 文档。
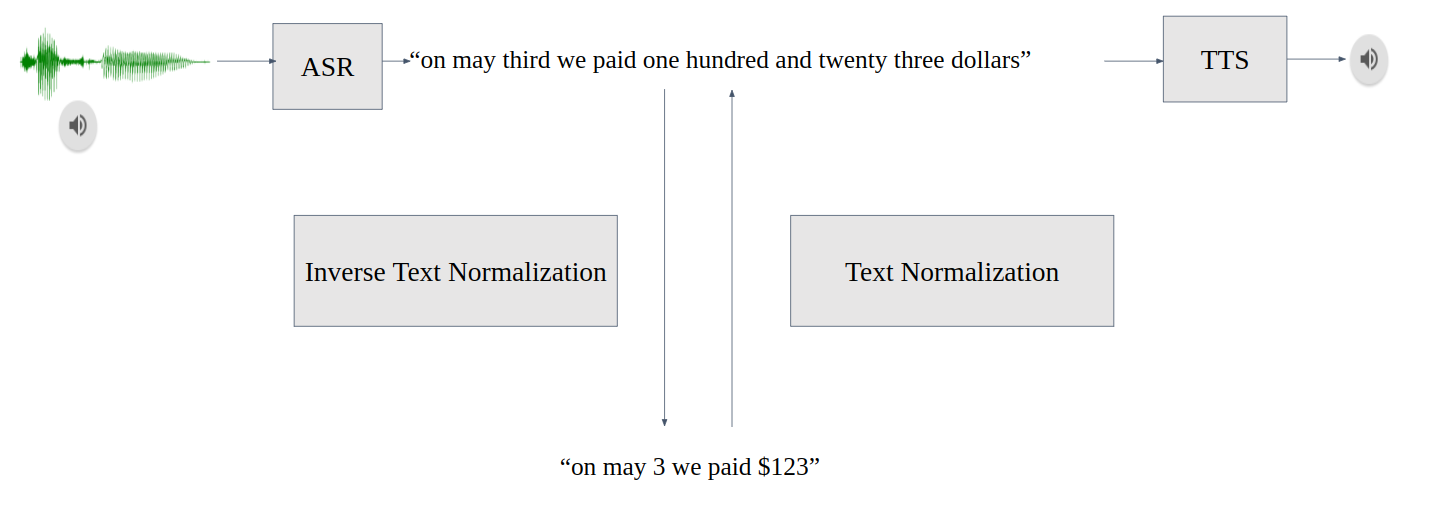
文本 (逆) 规范化#
警告
TN/ITN 已从 NVIDIA/NeMo 存储库过渡到独立的 NVIDIA/NeMo-text-processing 存储库。所有更新和讨论/问题都应转到新存储库。
nemo_text_processing Python 包基于 WFST 语法 [TEXTPROCESSING-NORM2] 并支持
文本规范化 (TN) 将书面形式的文本转换为口语形式。它用作文本到语音 (TTS) 之前的预处理步骤。例如,
"123" -> "one hundred twenty three"
nemo_text_processing 既有快速的确定性版本 [TEXTPROCESSING-NORM3],它具有更多的语言支持,也有上下文感知版本 [TEXTPROCESSING-NORM1]。在输入不明确的情况下,例如
"St. Patrick's Day" -> "Saint Patrick's Day"
"St. Patrick's Day" -> "Street Patrick's Day"
上下文感知 TN 会将 “St. Patrick’s Day” 转换为 “Saint Patrick’s Day”。
逆文本规范化 (ITN) 是自动语音识别 (ASR) 后处理管道的一部分,可用于将规范化的 ASR 模型输出转换为书面形式,以提高文本可读性。例如,
"one hundred twenty three" -> "123"
基于音频的版本提供了多种规范化选项。例如,
"123" -> "one hundred twenty three", "one hundred and twenty three", "one two three", "one twenty three" ...
然后选择最能反映音频中实际所说的内容的规范化。基于音频的 TN 可用于规范化 ASR 训练数据。
安装#
如果您已经安装了 nemo_text_processing,它应该带有 pynini python 库。否则请显式安装
pip install pynini==2.1.5
或者,如果这在缺少 OpenFst 标头时失败
conda install -c conda-forge pynini=2.1.5
快速入门指南#
文本规范化#
基于 WFST 的标准文本规范化 [TEXTPROCESSING-NORM3] 不具备上下文感知能力。它速度很快,可以像这样运行
cd NeMo-text-processing/nemo_text_processing/text_normalization/
python normalize.py --text="123" --language=en
如果您想规范化一个字符串。要规范化一个分成句子的文本文件,请运行以下命令
cd NeMo-text-processing/nemo_text_processing/text_normalization/
python normalize.py --input_file=INPUT_FILE_PATH --output_file=OUTPUT_FILE_PATH --language=en
上下文感知版本 [TEXTPROCESSING-NORM1] 是非确定性 WFST 和预训练掩码语言模型的浅层融合。

cd NeMo-text-processing/nemo_text_processing/
python wfst_lm_rescoring.py
逆文本规范化#
cd NeMo-text-processing/nemo_text_processing/inverse_text_normalization/
python inverse_normalize.py --text="one hundred twenty three" --language=en
参数
text- 输入文本。不应超过 500 个单词。input_file- 包含输入文本行的输入文件。仅接受text或input_file中的一个。output_file- 用于保存规范化的输出文件。如果指定了input_file,则需要此参数。language- 语言 ID。input_case- 仅用于文本规范化。lower_cased或cased。verbose- 输出中间信息。cache_dir- 指定编译语法的缓存目录。如果语法存在,这将显着提高速度。overwrite_cache- 更新缓存中的语法。whitelist- TSV 文件,其中包含书面文本到口语形式的自定义映射。
警告
要(反)规范化的单个字符串的最大长度不应超过 500 个单词。为避免这种情况,请将您的字符串拆分为短于此限制的句子,并将其作为 --input_file 传递。
基于音频的 TN#
cd NeMo-text-processing/nemo_text_processing/text_normalization/
python normalize_with_audio.py --text="123" --language="en" --n_tagged=10 --cache_dir="cache_dir" --audio_data="example.wav" --model="stt_en_conformer_ctc_large"
其他参数
text- 输入文本或包含多个音频路径的 JSON 清单文件。audio_data- (可选)输入音频。model- 现成的 NeMo CTC ASR 模型名称 或本地 NeMo 模型检查点路径,以 .nemo 结尾n_tagged- 要输出的规范化选项的数量。
语言支持矩阵#
语言 |
ID |
TN |
ITN |
基于音频的 TN |
上下文感知 TN |
英语 |
en |
x |
x |
x |
x |
西班牙语 |
es |
x |
x |
x |
|
西班牙语-英语 |
es_en |
x |
|||
法语 |
fr |
x |
x |
||
德语 |
de |
x |
x |
x |
|
阿拉伯语 |
ar |
x |
x |
||
俄语 |
ru |
x |
x |
||
瑞典语 |
sv |
x |
x |
||
越南语 |
vi |
x |
|||
葡萄牙语 |
pt |
x |
|||
中文 |
zh |
x |
x |
||
匈牙利语 |
hu |
x |
|||
意大利语 |
it |
x |
|||
亚美尼亚语 |
hy |
x |
x |
||
马拉地语 |
mr |
x |
|||
印地语 |
hi |
x |
x |
||
日语 |
ja |
x |
x |
有关语法自定义的详细信息,请参阅 语法自定义。
有关 C++ 部署的详细信息,请参阅 文本处理部署。
WFST TN/ITN 资源可以在此处找到。
参考资料#
Evelina Bakhturina, Yang Zhang, 和 Boris Ginsburg. Shallow fusion of weighted finite-state transducer and language model for text normalization. arXiv preprint arXiv:2203.15917, 2022.
Mehryar Mohri, Fernando Pereira, 和 Michael Riley. Weighted automata in text and speech processing. arXiv preprint cs/0503077, 2005.
Yang Zhang, Evelina Bakhturina, Kyle Gorman, 和 Boris Ginsburg. Nemo inverse text normalization: from development to production. 2021. arXiv:2104.05055.