重要提示
您正在查看 NeMo 2.0 文档。此版本为 API 和新库 NeMo Run 引入了重大更改。我们目前正在将 NeMo 1.0 中的所有功能移植到 2.0。有关先前版本或 2.0 中尚未提供的功能的文档,请参阅 NeMo 24.07 文档。
CLIP#
模型介绍#
对比语言-图像预训练 (CLIP) [MM-MODELS-CLIP1] 提供了一种使用自然语言监督学习图像表示的有效方法。CLIP 的本质是从头开始训练图像编码器和文本编码器。该模型旨在通过联合训练这些编码器来预测一批(图像、文本)训练示例的正确配对。在预训练期间,CLIP 旨在通过最大化正确(图像、文本)对之间的相似性,同时最小化不正确对之间的相似性来预测哪些图像和文本形成语义连贯的对。这种对比学习方法确保 CLIP 学习到视觉和文本数据有意义且上下文丰富的表示。
NeMo 的 CLIP 模型实现利用了其并行 Transformer 实现,特别是 nemo.collections.nlp.modules.common.megatron.transformer.ParallelTransformer,以在文本编码器和视觉模型中启用模型并行支持。这种设计选择确保了训练期间资源的有效扩展和利用。此外,NeMo 的 CLIP 中的一些模型设计和损失实现灵感来自开源 [open_clip](mlfoundations/open_clip) 仓库。
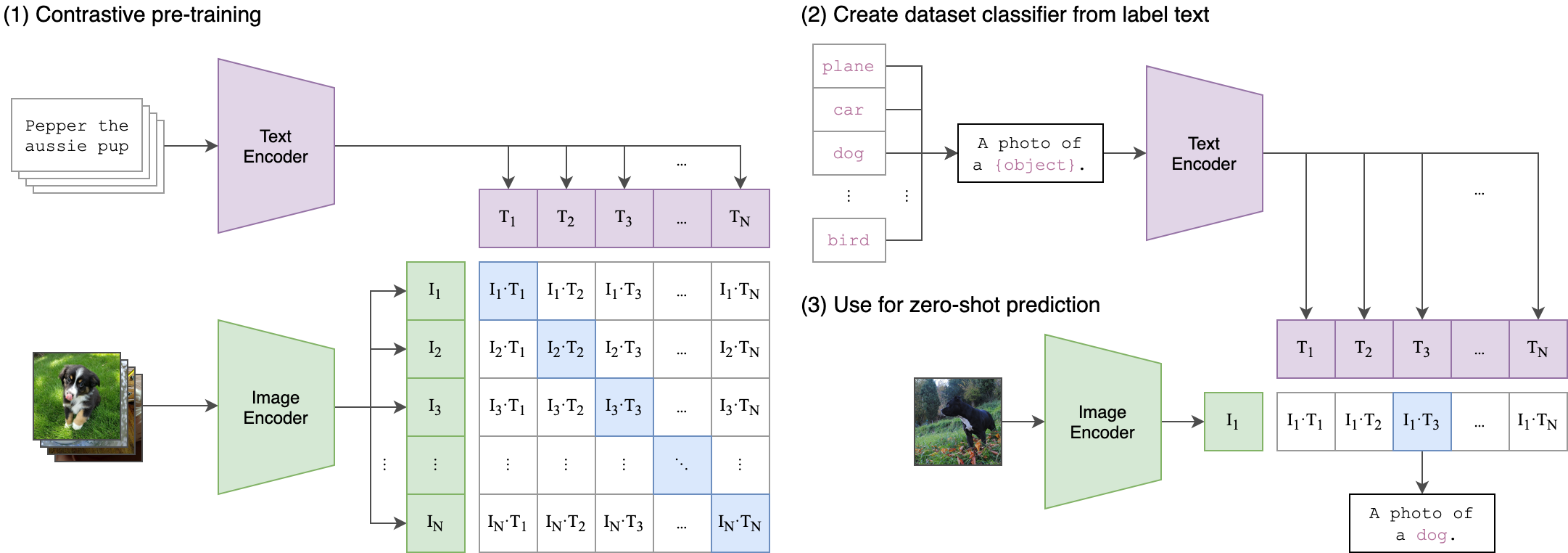
NeMo 中的 CLIP 模型可以使用 MegatronCLIPModel 类实例化。
文本编码器#
CLIP 使用基于 Transformer 的文本编码器来编码文本特征。文本输入被分词和嵌入。位置嵌入被添加到这些词元嵌入中,然后将这种组合表示传递到多个 Transformer 层。来自对应于第一个词元的最后一个 Transformer 层的输出用作文本表示。在 NeMo 中,CLIP 文本编码器可以使用 CLIPTextTransformer 类实例化。
视觉模型#
CLIP 的视觉模型基于 Vision Transformer (ViT) 架构。图像首先被分成固定大小的补丁(例如,16x16 像素)。这些补丁被线性嵌入到一个扁平向量中,然后用作 Transformer 的输入。然后对 Transformer 的输出进行池化以生成单个图像表示。在 NeMo 中,CLIP 视觉模型可以使用 CLIPVisionTransformer 类实例化。
模型 |
图像尺寸 |
图像模型大小 (M)(视觉) |
隐藏层大小 (FFN 大小)(视觉) |
注意力头数(视觉) |
层数(视觉) |
补丁维度(视觉) |
模型大小 (M)(文本) |
隐藏层大小(文本) |
注意力头数(文本) |
层数(文本) |
输出维度 |
|---|---|---|---|---|---|---|---|---|---|---|---|
B/32 |
224 |
87.85 |
768 |
12 |
12 |
16 |
63.43 |
512 |
8 |
12 |
512 |
B/16 |
224 |
86.19 |
768 |
12 |
12 |
32 |
91.16 |
512 |
8 |
12 |
512 |
L/14 |
224 |
303.97 |
1024 |
16 |
24 |
14 |
123.65 |
768 |
12 |
12 |
768 |
H/14 |
224 |
638.08 |
1280 |
20 |
32 |
14 |
354.03 |
1024 |
16 |
24 |
1024 |
g/14 |
224 |
1012.65 |
1408 (6144) |
22 |
40 |
14 |
354.03 |
1024 |
16 |
24 |
1024 |
G/14 |
224 |
1840 |
1664 (8192) |
16 |
48 |
14 |
590 |
1280 |
20 |
32 |
1280 |
e/14 |
224 |
2200 |
1792 (15360) |
28 |
56 |
14 |
660 |
1280 |
20 |
36 |
1280 |
模型配置#
通用配置#
model:
output_dim: 512
local_loss: False
gather_with_grad: True
output_dim:表示文本和视觉模型的输出嵌入的维度。local_loss:如果设置为 True,则损失是在全局级别使用局部特征计算的,避免了实现完整全局矩阵的需要。这可能有利于内存效率,尤其是在多个设备上训练时。gather_with_grad:为特征收集启用完全分布式梯度。禁用此选项(设置为 False)可能会导致收敛问题。
视觉模型配置#
vision:
patch_dim: 16
img_h: 224
img_w: 224
image_mean: null
image_std: null
num_channels: 3
drop_patch_rate: 0.0
drop_path_rate: 0.0
global_average_pool: False
output_dim: ${model.output_dim}
class_token_length: 8
encoder_seq_length: 196
num_layers: 12
hidden_size: 768
ffn_hidden_size: 3072
num_attention_heads: 12
hidden_dropout: 0.
attention_dropout: 0.
patch_dim:图像被划分成的补丁大小。img_h和img_w:输入图像的高度和宽度。image_mean和image_std:用于图像归一化的均值和标准差值。num_channels:输入图像中的通道数(例如,RGB 图像为 3)。drop_patch_rate和drop_path_rate:补丁和路径的 dropout 率。global_average_pool:如果设置为 True,则对输出应用全局平均池化。class_token_length:额外分类词元的长度。encoder_seq_length:视觉编码器的序列长度。num_layers、hidden_size、ffn_hidden_size、num_attention_heads:定义视觉 Transformer 架构的参数。ffn_hidden_size通常是hidden_size的 4 倍。hidden_dropout和attention_dropout:Transformer 中隐藏状态和注意力的 dropout 概率。
文本模型配置#
text:
output_dim: ${model.output_dim}
encoder_seq_length: 77
num_layers: 12
hidden_size: 512
ffn_hidden_size: 2048
num_attention_heads: 8
hidden_dropout: 0.
attention_dropout: 0.
output_dim:文本模型的输出嵌入的维度。encoder_seq_length:文本编码器的序列长度。num_layers、hidden_size、ffn_hidden_size、num_attention_heads:定义文本 Transformer 架构的参数。ffn_hidden_size通常是hidden_size的 4 倍。hidden_dropout和attention_dropout:Transformer 中隐藏状态和注意力的 dropout 概率。
优化#
功能 |
描述 |
启用方式 |
|---|---|---|
数据并行 |
数据集在多个 GPU 或节点上并发读取,从而加快数据加载和处理速度。 |
在多 GPU/节点上训练时自动启用 |
张量并行 |
每个张量被分成多个块,从而实现跨 GPU 的水平并行。这种称为 TensorParallel (TP) 的技术将模型的张量分布在多个 GPU 上。在处理过程中,每个分片在不同的 GPU 上分别并行处理,结果在步骤结束时同步。这种方法受到 NVIDIA Megatron 实现的启发。[参考](NVIDIA/Megatron-LM) |
|
激活检查点 |
为了减少内存使用,某些层的激活在反向传播期间被清除并重新计算。这项技术对于训练无法使用传统方法放入 GPU 内存的大型模型特别有用。 |
|
Bfloat16 训练 |
训练以 Bfloat16 精度进行,这在 FP32 的更高精度与 FP16 的内存节省和速度之间提供了平衡。 |
|
BF16 O2 |
启用 O2 级别自动混合精度,优化 Bfloat16 精度以获得更好的性能。 |
|
分布式优化器 |
优化过程分布在多个 GPU 上,从而降低了内存需求。这项技术将优化器状态分布在数据并行 rank 之间,而不是复制它,从而显着节省内存。这种方法受到论文“ZeRO: Memory Optimizations Toward Training Trillion Parameter Models”中描述的 ZeRO 优化以及 NVIDIA Megatron 中的实现的启发。[参考](NVIDIA/Megatron-LM) |
|
Flash Attention V2 |
FlashAttention 是一种快速且内存高效的算法,用于计算精确注意力。它通过感知 IO 来加速模型训练并减少内存需求。这种方法对于大规模模型特别有用,并在链接的仓库中进行了更详细的介绍。[参考](Dao-AILab/flash-attention) |
|
模型训练#
有关社区训练配方,请参阅 https://laion.ai/blog/large-openclip/#results。
参考文献#
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. 2021. arXiv:2103.00020。