重要
您正在查看 NeMo 2.0 文档。此版本引入了 API 的重大更改和一个新的库,NeMo Run。我们目前正在将 NeMo 1.0 的所有功能移植到 2.0。有关先前版本或 2.0 中尚不可用的功能的文档,请参阅 NeMo 24.07 文档。
说话人日志#
说话人日志概述#
说话人日志是按说话人标签分割录音的过程,旨在回答“谁在何时说话?”的问题。与语音识别相比,说话人日志做出了明确的区分。如下图所示,在我们执行说话人日志之前,我们知道“说了什么”,但我们不知道“是谁说的”。因此,对于语音识别系统来说,说话人日志是一项必不可少的功能,可以丰富带有说话人标签的转录。
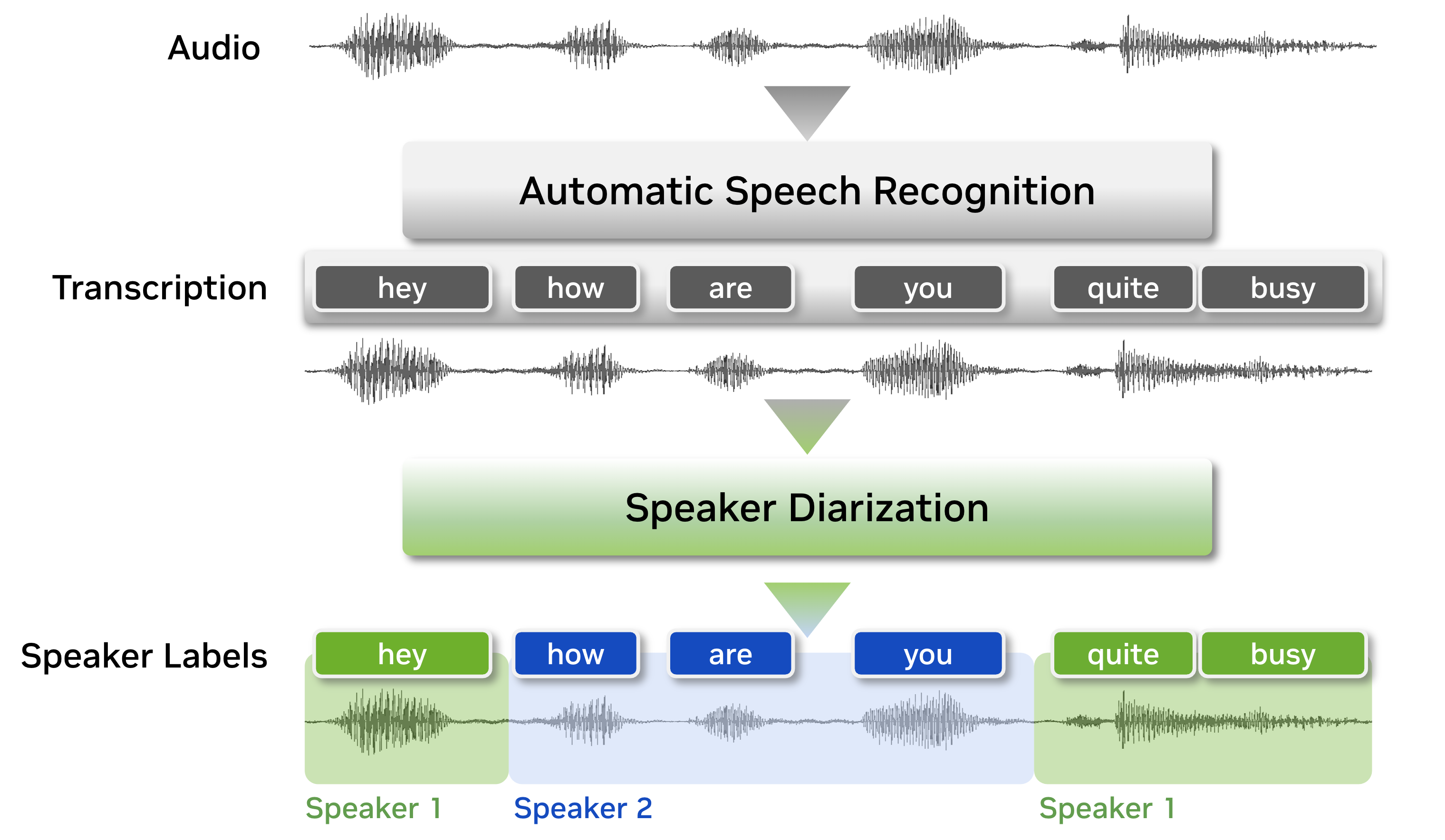
为了弄清楚“谁在何时说话”,说话人日志系统需要捕捉未知说话人的特征,并区分录音中哪些区域属于哪个说话人。为了实现这一点,说话人日志系统提取语音特征,计算说话人数量,然后将音频片段分配给相应的说话人索引。
说话人日志系统类型#
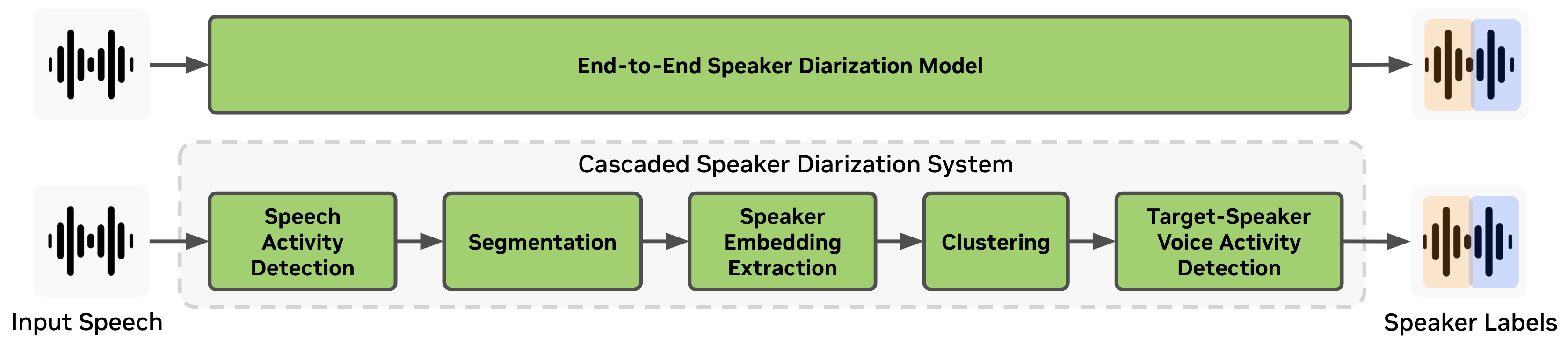
端到端说话人日志系统
端到端说话人日志系统追求更简化的系统版本,其中单个神经网络模型接受原始音频信号,并输出每个音频帧的说话人活动。因此,端到端日志模型在易于优化和部署方面具有优势。
目前,NeMo Speech AI 提供了以下端到端说话人日志模型
Sortformer 日志器:一种基于 Transformer 的模型,可从给定的音频输入中估计说话人标签,并按到达时间顺序给出说话人索引。
级联说话人日志系统
传统的级联(也称为模块化或流水线式)说话人日志系统由多个模块组成,例如说话人活动检测 (SAD) 模块和说话人嵌入提取器模块。在聚类日志器的基础上,执行目标说话人语音活动检测 (VAD) 以生成最终的说话人标签。级联说话人日志系统在整体优化和部署方面更具挑战性,但仍然具有对说话人数量和会话时长限制较少的优势。
级联 NeMo Speech AI 说话人日志系统由以下模块组成
语音活动检测器 (VAD):一种可训练模型,可检测语音的存在或不存在,从而从给定的录音中生成语音活动的时间戳。
说话人嵌入提取器:一种可训练模型,可从原始音频信号中提取包含语音特征的说话人嵌入向量。
聚类模块:一种不可训练模块,可将说话人嵌入向量分组为多个聚类。
神经日志器 (TS-VAD):一种可训练模型,可从给定的特征中估计说话人标签。通常,此模块执行目标说话人 VAD 任务以生成最终的说话人标签。
完整的文档树如下
资源和文档指南#
端到端和级联系统的实践说话人日志教程笔记本可以在 <NeMo_root>/tutorials/speaker_tasks 下找到。
还有关于执行端到端说话人日志和级联说话人日志的教程。我们还提供了关于获取 ASR 转录以及与 NeMo ASR 集合的说话人标签和语音活动时间戳相结合的教程。
大多数教程可以在 Google Colab 上运行,方法是在 Colab 上指定笔记本 GitHub 页面的链接。
如果您正在查找有关用于说话人日志推理的特定模型的信息,或者想了解有关 nemo_asr 集合中可用的模型架构的更多信息,请查看模型页面。
有关数据集预处理的文档可以在数据集页面上找到。NeMo 包括几个常见 ASR 数据集的预处理脚本,此页面包含有关运行这些脚本的说明。如果您有自己的数据,它还包括创建您自己的 NeMo 兼容数据集的指南。
有关如何加载模型检查点(本地文件或来自 NGC 的预训练检查点)、执行推理以及 NGC 上可用检查点列表的信息,请访问检查点页面。
有关特定于 nemo_asr 模型的配置文件的文档,可以在配置文件页面上找到。