重要提示
您正在查看 NeMo 2.0 文档。此版本对 API 和新库 NeMo Run 进行了重大更改。我们目前正在将 NeMo 1.0 的所有功能移植到 2.0。 有关先前版本或 2.0 中尚未提供的功能的文档,请参阅 NeMo 24.07 文档。
并行性#
NeMo Megatron 支持各种数据并行和模型并行的深度学习工作负载部署方法,这些方法可以任意混合使用。
数据并行#
数据并行 (DP) 在多个 GPU 上复制模型。数据批次均匀分布在 GPU 之间,数据并行 GPU 独立处理它们。虽然计算工作负载有效地分布在 GPU 之间,但 GPU 间通信是必需的,以便在训练步骤之间保持模型副本的一致性。
分布式数据并行#
分布式数据并行 (DDP) 通过在每次参数更新之前同步数据并行 GPU 之间的参数梯度来保持模型副本的一致性。更具体地说,它使用 all-reduce 通信集合来求和所有模型副本的梯度。

分布式优化器#
分布式优化器是一种内存优化的数据并行部署方法。它将优化器状态和高精度主参数分片到数据并行 GPU 上,而不是复制它们。在参数优化器步骤中,每个数据并行 GPU 更新其参数分片。由于每个 GPU 都需要自己的梯度分片,因此分布式优化器执行参数梯度的 reduce-scatter 而不是它们的 all-reduce。然后,更新后的参数分片在数据并行 GPU 之间进行 all-gather。这种方法显着降低了大规模 LLM 训练的内存需求。此外,当梯度的精度高于参数精度时,梯度 reduce-scatter 和参数 all-gather 的拆分执行可以减少总通信量。这种拆分集合执行增加了总计算量,以与通信重叠,从而提高了重叠机会。
启用数据并行#
在 NeMo 框架中,DDP 是默认的并行部署方法。这意味着 GPU 的总数对应于 DP 组的大小,并且使用模型并行训练 LLM 会减小 DP 组的大小。
目前,NeMo 框架仅为 Megatron Core Adam 分布式优化器支持优化器分布。要启用分布式 adam 优化器,请从 nemo.collections.llm.recipes.optim.adam 设置 distributed_fused_adam_with_cosine_annealing 优化器配方,或者您可以创建自己的优化器配方。
# Use optimizer recipe created by NeMo team
from nemo.collections.llm.recipes.optim.adam import distributed_fused_adam_with_cosine_annealing
optim = distributed_fused_adam_with_cosine_annealing(max_lr=3e-4)
optim.config.bf16 = True
# Create your own optimizer recipe with cosine annealing scheduler
import nemo_run as run
from megatron.core.optimizer import OptimizerConfig
from nemo.lightning.pytorch.optim import CosineAnnealingScheduler, MegatronOptimizerModule, PytorchOptimizerModule
@run.cli.factory
def distributed_optimizer_recipe(
precision: str = "bf16-mixed", # or "16-mixed"
warmup_steps: int = 1000,
constant_steps: int = 1000,
adam_beta1: float = 0.9,
adam_beta2: float = 0.95,
max_lr: float = 1e-4,
min_lr: float = 1e-5,
clip_grad: float = 1.0,
) -> run.Config[PytorchOptimizerModule]:
opt_cfg = run.Config(
OptimizerConfig,
optimizer="adam",
lr=max_lr,
weight_decay=0.1,
bf16=precision == "bf16-mixed",
fp16=precision == "16-mixed",
adam_beta1=adam_beta1,
adam_beta2=adam_beta2,
adam_eps=1e-5,
use_distributed_optimizer=True,
clip_grad=clip_grad,
)
sched = run.Config(
CosineAnnealingScheduler,
warmup_steps=warmup_steps,
constant_steps=constant_steps,
min_lr=min_lr,
)
return run.Config(
MegatronOptimizerModule,
config=opt_cfg,
lr_scheduler=sched,
)
有关更多优化器选项,请访问 此页面。
模型并行#
模型并行 (MP) 是一种分布式模型部署方法,它将模型参数分区到 GPU 上,以减少每个 GPU 内存的需求。NeMo 框架支持各种模型并行方法,这些方法可以混合使用以最大化 LLM 训练性能。
张量并行#
张量并行 (TP) 是一种模型并行分区方法,它将单个层的参数张量分布到多个 GPU 上。除了减少模型状态内存使用量外,它还可以节省激活内存,因为每个 GPU 的张量大小会缩小。但是,由于每个 GPU 的内核工作负载较小,因此每个 GPU 张量大小的减小会增加 CPU 开销。

启用张量并行#
要在 NeMo 框架中启用 TP,请在模型配置中配置 tensor_model_parallel_size 参数。此参数确定模型张量分区到的 GPU 数量。
将 tensor_model_parallel_size 设置为大于 1 的值以启用层内模型并行。
from nemo.collections import llm from functools import partial # Load train recipe recipe = partial(llm.llama3_8b.pretrain_recipe)() # Set tensor model parallel size recipe.trainer.strategy.tensor_model_parallel_size = 2
直接从 CLI 设置张量并行
nemo llm pretrain --factory llama3_8b trainer.strategy.tensor_model_parallel_size=2
实现张量并行#
NeMo 框架通过 Megatron Core 的实现集成了 TP。要了解如何在 transformer 块内激活 TP,请参阅以下存储库中的代码:Megatron-LM Transformer Block。
有关详细的 API 用法和其他配置,请查阅 Megatron Core 开发者指南。
流水线并行#
流水线并行 (PP) 是一种将神经网络的连续层或段分配给不同 GPU 的技术。这种划分允许每个 GPU 顺序处理网络的不同阶段。

启用流水线并行#
要在 NeMo 框架中使用流水线并行 (PP),请在模型的配置中设置 pipeline_model_parallel_size 参数。此参数指定模型层分布到的 GPU 数量。
将 pipeline_model_parallel_size 设置为大于 1 的值以启用层间模型并行。
from nemo.collections import llm
from functools import partial
# Load train recipe
recipe = partial(llm.llama3_8b.pretrain_recipe)()
# Set pipeline model parallel size
recipe.trainer.strategy.pipeline_model_parallel_size = 2
直接从 CLI 设置流水线并行
nemo llm pretrain --factory llama3_8b trainer.strategy.pipeline_model_parallel_size=2
交错流水线并行调度#
为了最大限度地减少流水线气泡,每个 GPU 上的计算可以分为多个层子集(称为模型块),而不是单个连续块。例如,每个 GPU 处理一组连续的四层,它可能会处理两个模型块,每个模型块包含两层。
from nemo.collections import llm from functools import partial # Load train recipe recipe = partial(llm.llama3_8b.pretrain_recipe)() # Set pipeline model parallel size > 1 and enable interleaved pipeline recipe.trainer.strategy.pipeline_model_parallel_size = 2 recipe.trainer.strategy.virtual_pipeline_model_parallel_size = 2
直接从 CLI 启用交错流水线
nemo llm pretrain --factory llama3_8b trainer.strategy.pipeline_model_parallel_size=2 trainer.strategy.virtual_pipeline_model_parallel_size=2
有关此方法的更多见解,请参阅我们的详细博客:扩展语言模型训练。
实现流水线并行#
PP 的 NeMo 框架实现利用了 Megatron Core 的功能。有关 PP 如何在 NeMo 的 transformer 块中实现的实际示例,您可以检查以下代码库:Megatron-LM Transformer Block。
有关与 PP 相关的更详细的 API 用法和配置,请访问 Megatron Core 开发者指南。
专家并行#
专家并行 (EP) 是一种模型并行类型,它将 MoE 的专家分布在 GPU 上。与其他模型并行技术不同,EP 仅应用于专家层,因此不会影响其余层的并行映射。
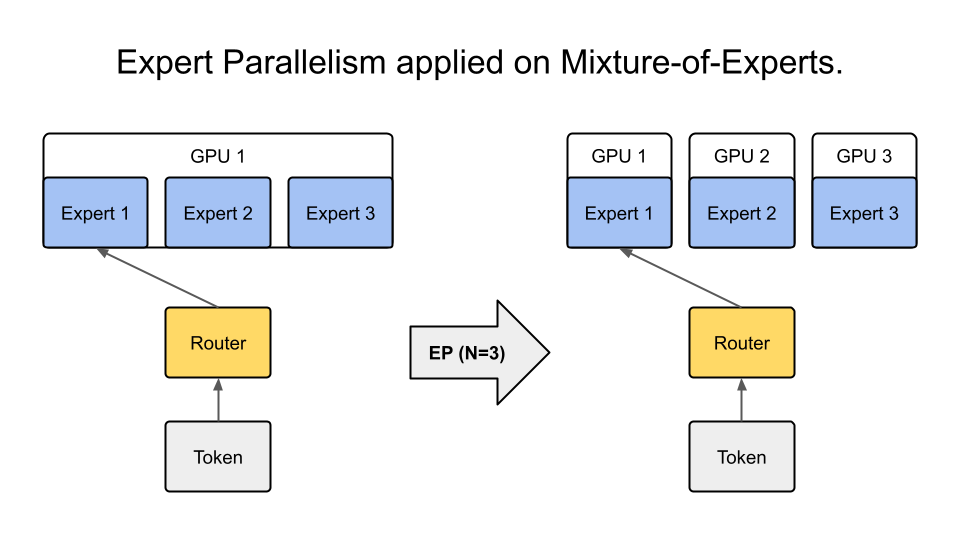
启用专家并行#
要启用 EP,请在 MegatronStrategy 的参数中将 expert_model_parallel_size 设置为您想要的专家并行大小。例如,如果模型有八个专家 (num_moe_experts=8),则设置 expert_model_parallel_size=4 会导致每个 GPU 处理两个专家。专家的数量应可被专家并行大小整除。
from nemo.collections import llm from functools import partial # Load train recipe recipe = partial(llm.mixtral_8x7b.pretrain_recipe)() # Set expert model parallel size recipe.trainer.strategy.expert_model_parallel_size = 4
直接从 CLI 设置专家并行
nemo llm pretrain --factory mixtral_8x7b trainer.strategy.expert_model_parallel_size=4
有关配置的更多信息,请参阅以下文档:NeMo Megatron GPT 配置。
启用专家张量并行#
要启用 ETP,请在 MegatronStrategy 的参数中将 expert_tensor_parallel_size 设置为您想要的大小。例如
from nemo.collections import llm from functools import partial # Load train recipe recipe = partial(llm.mixtral_8x7b.pretrain_recipe)() # Set expert tensor parallel size recipe.trainer.strategy.expert_tensor_parallel_size = 4
直接从 CLI 设置专家张量并行
nemo llm pretrain --factory mixtral_8x7b trainer.strategy.expert_tensor_parallel_size=4
专家并行实现#
EP 的 NeMo 框架实现使用了 Megatron Core 的功能。请查阅 Megatron Core MoE 层,了解更多 MoE 实现细节。
激活分区#
在 LLM 训练中,需要大量的内存空间来存储网络层的输入激活。NeMo 框架提供了有效的激活分布方法,这对于训练具有大序列长度或每个 GPU 大微批大小的 LLM 至关重要。
序列并行#
序列并行 (SP) 通过沿 transformer 层的序列维度在多个 GPU 之间分配计算负载和激活内存来扩展张量级模型并行性。此方法对于以前未并行化的层部分特别有用,从而提高了整体模型性能和效率。

启用序列并行#
要在 NeMo 框架中使用 SP,请在模型配置中将 sequence_parallel 参数设置为 True。请注意,此功能仅在张量并行大小 (tensor_model_parallel_size) 大于 1 时有效。
from nemo.collections import llm from functools import partial # Load train recipe recipe = partial(llm.llama3_8b.pretrain_recipe)() # Set tensor model parallel size and enable sequence parallelism recipe.trainer.strategy.tensor_model_parallel_size = 2 recipe.trainer.strategy.sequence_parallelism = True
直接从 CLI 启用序列并行
nemo llm pretrain --factory llama3_8b trainer.strategy.tensor_model_parallel_size=2 trainer.strategy.sequence_parallelism=True
实现序列并行#
SP 的 NeMo 框架实现利用了 Megatron Core 的功能。要深入了解序列并行如何集成到 Megatron Core 架构中,您可以查看此处的源代码:Megatron-LM 序列并行源代码。
上下文并行#
上下文并行 (CP) 是一种跨多个 GPU 并行处理神经网络激活的方法,它在序列维度中对输入张量进行分区。与 SP(对特定层的激活进行分区)不同,CP 划分所有层的激活。
启用上下文并行#
要在 NeMo 框架中激活 CP,请在模型配置中设置 context_parallel_size 参数。此参数指定模型的序列激活分布到的 GPU 数量。
将 context_parallel_size 设置为大于 1 的值以启用序列范围的模型并行。
from nemo.collections import llm from functools import partial # Load train recipe recipe = partial(llm.llama3_8b.pretrain_recipe)() # Set context parallel size recipe.trainer.strategy.context_parallel_size = 2
直接从 CLI 设置 context_parallel_size
nemo llm pretrain --factory llama3_8b model.config.context_parallel_size=2
可以在此处找到和修改配置:NeMo Megatron Core 上下文配置。
实现上下文并行#
NeMo 框架利用 Megatron Core 和 Transformer Engine 的功能来高效地实现 CP。在前向传播期间,每个 GPU 处理序列的一个段,仅存储必要的键和值 (KV) 对。在后向传播中,这些 KV 对使用高级通信方案(如 all-gather 和 reduce-scatter)在 GPU 之间重新组装,这些方案在环形拓扑中转换为点对点通信。这种方法显着减少了内存占用,同时保持了计算效率。
访问我们的源代码以获得有关实现的更多见解:- Transformer Engine 的 Megatron Core 包装器 - Transformer Engine 注意力模块
并行性术语#
下图说明了您在 NeMo Megatron 代码库中可能遇到的一些术语。
