重要提示
您正在查看 NeMo 2.0 文档。此版本对 API 和新库 NeMo Run 进行了重大更改。我们目前正在将 NeMo 1.0 的所有功能移植到 2.0。有关先前版本或 2.0 中尚不可用的功能的文档,请参阅 NeMo 24.07 文档。
通信重叠#
数据并行通信重叠#
NeMo 支持在 LLM 训练中将数据并行 (DP) 通信与计算重叠。NeMo 具有分布式优化器,可在 GPU 之间分布优化器状态和高精度主参数。这引入了两种类型的数据并行通信:梯度 reduce-scatter 和更新参数 all-gather。DP 通信按 Transformer 层的粒度进行分块,并将每个通信块与计算重叠。此重叠方法仅公开一个 DP 通信块,从而确保高效的大规模 LLM 训练。当使用流水线并行性进行训练时,DP 通信的粒度变为每个虚拟流水线阶段的 Transformer 层。
DP 通信重叠设置可以通过 DistributedDataParallelConfig 类在 Megatron Core 中进行检查:DistributedDataParallelConfig。当分别设置 overlap_grad_sync=True 和 overlap_param_gather=True 时,启用 DP 梯度 reduce-scatter 和参数 all-gather 重叠。梯度 reduce-scatter 的精度由 grad_reduce_in_fp32 控制。当 grad_reduce_in_fp32=False 时,梯度在 bf16 中减少,与默认 fp32 精度相比,可提高大规模训练的性能。当在 fp8 计算精度下训练时,设置 fp8_param_gather=True 会在 fp8 中进行参数 all-gather,从而将 all-gather 开销减少一半。
要修改这些配置,请按如下方式手动更新训练配方
from nemo.collections import llm
from functools import partial
# Load training recipe
recipe = partial(llm.llama3_8b.pretrain_recipe)()
recipe.strategy.ddp_config.overlap_grad_sync = False # Default is True
recipe.strategy.ddp_config.overlap_param_gather = False # Default is True
# Similar changes can be made for other DDP configurations.
张量并行通信重叠#
与序列并行激活分片 (sequence_parallel=True) 一起使用的张量并行性引入了激活(梯度)all-gather 和 reduce-scatter,如下图所示。NeMo 提供了各种选项,可以将张量并行 (TP) 通信与计算重叠。没有直接计算依赖性的 TP 通信与批量计算重叠(黄色框中的线性层和 TP 通信对)。默认情况下启用批量 TP 通信。具有直接计算依赖性的其他 TP 通信以流水线方式重叠(红色框中的线性层和 TP 通信对)。TP 通信和计算被分块,并且这些块在流水线中重叠。在流水线重叠中,激活(梯度)张量 all-gather 被替换为输入 P2P 环交换的多个步骤,reduce-scatter 被替换为 GEMM 输出 P2P 环交换的多个步骤,然后是对接收到的输出进行缩减。在 reduce-scatter 重叠的情况下,NeMo 还提供了使用 reduce-scatter 块进行流水线重叠的选项,该选项公开了一个 reduce-scatter 块。
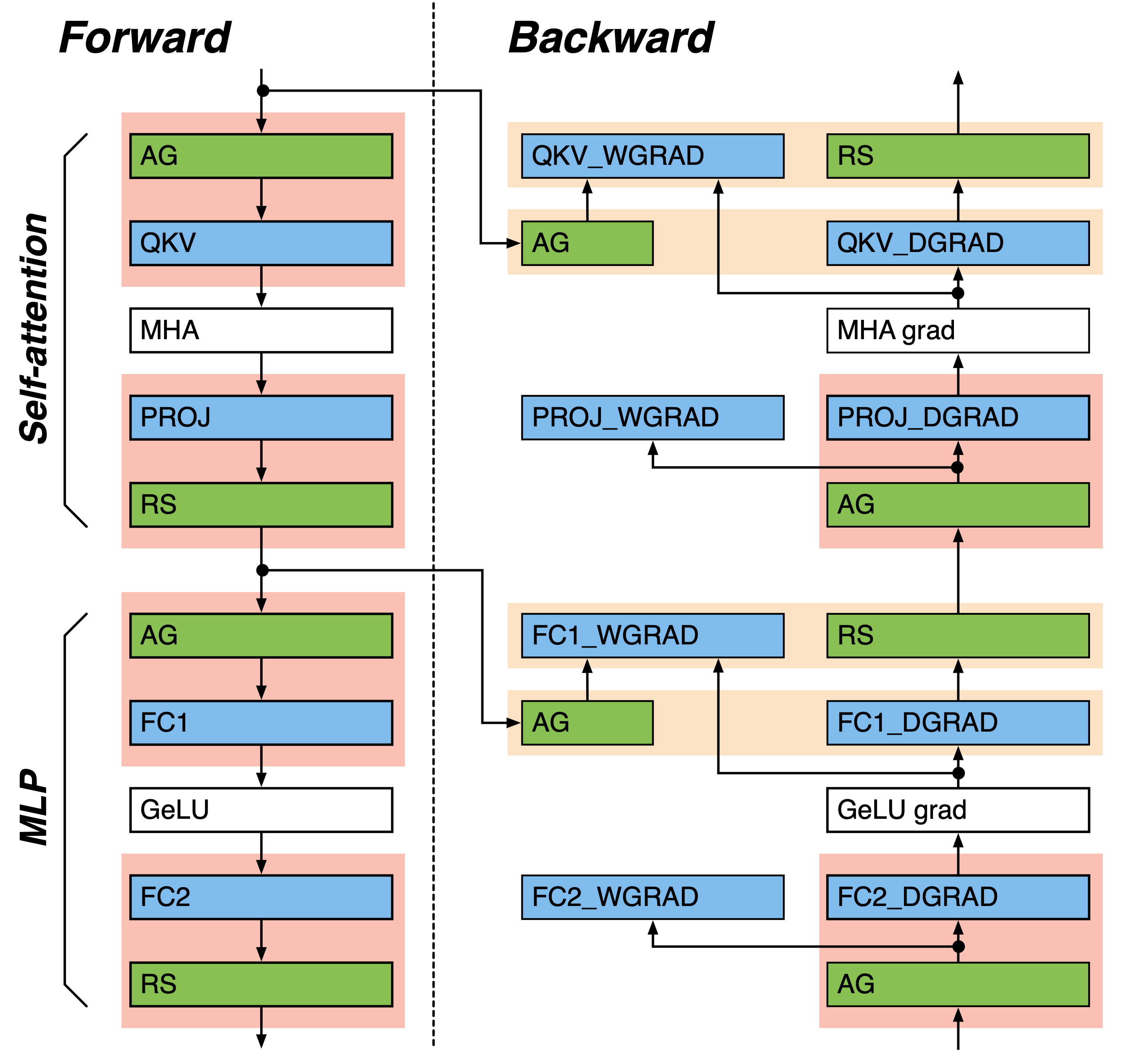
TP 通信重叠配置通过回调 MegatronCommOverlapCallback 添加。流水线 TP 通信重叠在 Transformer Engine 中实现,可以通过设置 tp_comm_overlap=True 来启用。可以使用 tp_comm_overlap_cfg 启用或禁用单个批量、流水线 all-gather 和 reduce-scatter 操作。有关详细配置,请参阅 TransformerLayerTPOverlapCfg。
要修改这些配置,请按如下方式手动更新训练配方
from nemo.collections import llm
from functools import partial
from nemo.lightning.pytorch.callbacks.megatron_comm_overlap import MegatronCommOverlapCallback
# Load training recipe
recipe = partial(llm.llama3_8b.pretrain_recipe)()
# Remove existing MegatronCommOverlapCallback
recipe.trainer.callbacks = [
callback for callback in recipe.trainer.callbacks
if not isinstance(callback, MegatronCommOverlapCallback)
]
# Append new callback with updated configuration
recipe.trainer.callbacks.append(
MegatronCommOverlapCallback(tp_comm_overlap=False)
)
流水线并行通信重叠#
流水线化在流水线并行 (PP) GPU 之间引入了 P2P 激活(梯度)发送和接收。当增加虚拟流水线并行大小时,PP 通信频率会增加,因为每个微批次执行的 Transformer 层数会减少。这种不断增加的 PP 通信开销抵消了虚拟流水线减少的流水线气泡。NeMo 支持在 1F1B 阶段(流水线主体,其中 1X 前向和 1X 后向微批次执行交错)中将 PP 通信与非依赖性计算重叠。流水线填充和刷新中的 PP 通信仍然公开。
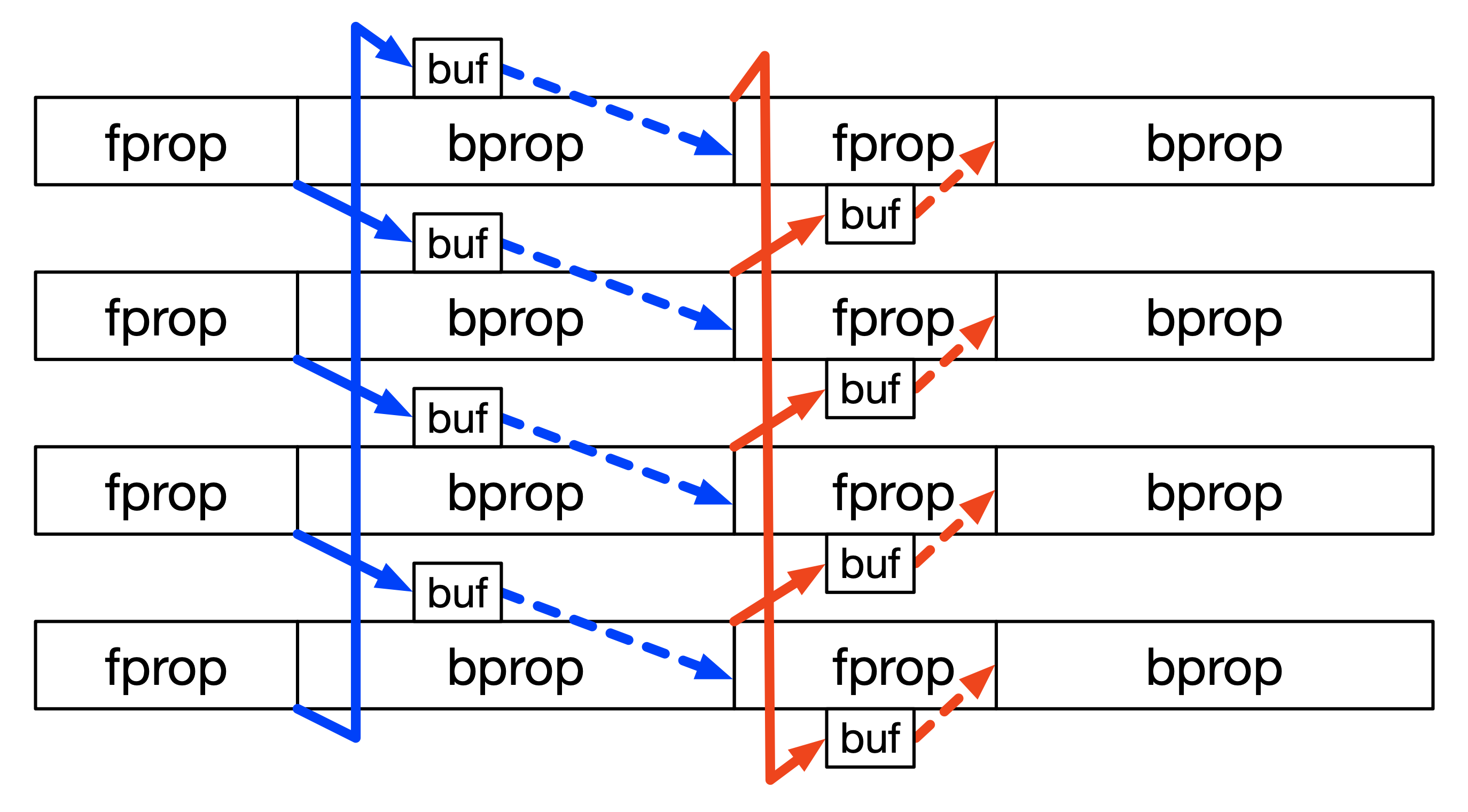
当设置 overlap_p2p_comm=True 时,启用 PP 通信重叠。此外,设置 batch_p2p_comm=False 对发送和接收使用单独的内核,这进一步提高了通信效率和 GPU 资源利用率。NeMo 仅在虚拟流水线化的情况下支持 PP 通信重叠,其中 PP 通信成为性能瓶颈。请参考 GPT3 训练配置文件,该文件使用了 PP 通信重叠。
与 TP 通信重叠类似,PP 通信重叠配置通过回调 MegatronCommOverlapCallback 添加。当设置 overlap_p2p_comm=True 时,启用 PP 通信重叠。此外,设置 batch_p2p_comm=False 对发送和接收使用单独的内核,这进一步提高了通信效率和 GPU 资源利用率。NeMo 仅在虚拟流水线化的情况下支持 PP 通信重叠,其中 PP 通信成为性能瓶颈。
要修改这些配置,请按如下方式手动更新训练配方
from nemo.collections import llm
from functools import partial
from nemo.lightning.pytorch.callbacks.megatron_comm_overlap import MegatronCommOverlapCallback
# Load training recipe
recipe = partial(llm.llama3_8b.pretrain_recipe)()
# Remove existing MegatronCommOverlapCallback
recipe.trainer.callbacks = [
callback for callback in recipe.trainer.callbacks
if not isinstance(callback, MegatronCommOverlapCallback)
]
# Append new callback with updated configuration
recipe.trainer.callbacks.append(
MegatronCommOverlapCallback(overlap_p2p_comm=True, batch_p2p_comm=False)
)
上下文并行通信重叠#
上下文并行性在序列域中的所有层上划分激活(梯度)。这在自注意力前向和反向传播中引入了激活(梯度)的 all-gather 和 reduce-scatter。NeMo 将上下文并行 (CP) 通信隐藏在自注意力计算之下。与 TP 通信重叠类似,CP 通信被分块,然后与自注意力计算进行流水线重叠,其中激活(梯度)的 all-gather 和 reduce-scatter 被替换为数据的 P2P 环交换。
当使用上下文并行性 (context_parallel_size > 1) 时,默认启用 CP 通信重叠。