重要提示
您正在查看 NeMo 2.0 文档。此版本对 API 和新库 NeMo Run 进行了重大更改。我们目前正在将 NeMo 1.0 的所有功能移植到 2.0。有关先前版本或 2.0 中尚不可用的功能的文档,请参阅 NeMo 24.07 文档。
弹性特性#
NeMo 框架整合了来自 NVIDIA Resiliency Extension 的弹性训练特性。此扩展提供了容错功能,有助于最大限度地减少因训练期间的故障和中断造成的停机时间。
主要特性包括
容错:在中断情况下,自动从上次检查点恢复训练。
掉队者检测:识别并缓解性能较慢的节点,以确保高效训练。
有关这些特性的设计和使用的更多信息,请参阅 Resiliency Extension 的文档。
容错#
Resiliency Extension 的容错子包可以检测训练期间的挂起,并由于挂起或错误而自动重启工作负载。如果瞬态故障很常见,例如,在不可靠的硬件上或非常大规模地进行训练,这将非常有用。
使用容错特性#
警告
此插件目前仅在基于 Slurm 的集群上受支持。
该软件包包含一个 PyTorch Lightning 回调 FaultToleranceCallback 和一个启动器 ft_launcher,它类似于 torchrun。要使用上述特性,必须将回调添加到训练器,并且必须使用 ft_launcher 启动工作负载。我们提供了一个 NeMo-Run 插件来简化此集成,只需一步即可完成。请注意,必须安装 NeMo-Run 才能使用此插件。
以下示例将插件添加到 LLaMA3 8B 配方
from nemo import lightning as nl
from nemo.collections import llm
from nemo.lightning.run.plugins import FaultTolerancePlugin
recipe = llm.llama3_8b.pretrain_recipe(name="llama3_with_fault_tolerance", ...) # fill in other recipe arguments
...
executor = # set up your NeMo-Run executor
...
run_plugins = [FaultTolerancePlugin()]
run.run(recipe, plugins=run_plugins, executor=executor)
当使用此特性时,如果遇到挂起,您应该看到类似于以下的日志语句
[WARNING] [RankMonitorServer:34] Did not get subsequent heartbeat. Waited 171.92 seconds.
[WARNING] [RankMonitorServer:58] Did not get subsequent heartbeat. Waited 171.92 seconds.
torch.distributed.elastic.multiprocessing.api: [WARNING] Sending process 453152 closing signal SIGTERM
torch.distributed.elastic.multiprocessing.api: [WARNING] Sending process 453157 closing signal SIGTERM
默认设置#
NeMo-Run 插件将使用 autoresume=True 和 calculate_timeout=True 配置 FaultToleranceCallback。autoresume 设置是必要的,以便在发生故障或训练未完成时自动启动另一个作业,这预计对大多数用户都很有用。当长时间训练会话无法在单个作业的时间限制内完成时,此特性还可以使训练更加无需人工干预。calculate_timeout 设置自动计算用于确定作业是否卡在挂起状态的阈值,从而简化用户体验。因此,我们默认启用了它。
我们还将默认最大连续作业内重启次数 (num_in_job_restarts) 限制为 3,作业重试次数 (num_job_retries_on_failure) 限制为 2。根据我们的经验,当故障发生频率高于此值时,通常存在需要解决的非瞬态应用程序问题。这些是插件的参数,因此您可以根据需要进行调整。
掉队者检测#
Resiliency Extension 的掉队者检测功能检测性能较慢的 rank,如果任何 rank 的性能低于用户指定的阈值,则终止训练。
使用掉队者检测特性#
该软件包提供了一个 PyTorch Lightning 回调,这使得此特性易于与 NeMo 一起使用。我们提供了一个用于配置此回调的配方。请参阅以下用法示例
from nemo import lightning as nl
from nemo.collections import llm
from nemo.collections.llm.recipes.callbacks import straggler_det_callback
trainer = nl.Trainer()
straggler_cb = straggler_det_callback()
trainer.callbacks.append(straggler_cb)
当使用此特性时,训练日志应包含类似于以下的性能报告
GPU relative performance:
Worst performing 5/512 ranks:
Rank=76 Node=h100-001-253-012 Score=0.94
Rank=13 Node=h100-001-010-003 Score=0.94
Rank=45 Node=h100-001-172-026 Score=0.94
Rank=433 Node=h100-004-141-026 Score=0.95
Rank=308 Node=h100-003-263-012 Score=0.95
Best performing 5/512 ranks:
Rank=432 Node=h100-004-141-026 Score=0.99
Rank=376 Node=h100-004-005-003 Score=0.98
Rank=487 Node=h100-004-255-026 Score=0.98
Rank=369 Node=h100-004-004-033 Score=0.98
Rank=361 Node=h100-004-004-023 Score=0.98
GPU individual performance:
Worst performing 5/512 ranks:
Rank=76 Node=h100-001-253-012 Score=0.98
Rank=162 Node=h100-002-042-026 Score=0.98
Rank=79 Node=h100-001-253-012 Score=0.98
Rank=357 Node=h100-004-004-013 Score=0.98
Rank=85 Node=h100-001-253-026 Score=0.98
Best performing 5/512 ranks:
Rank=297 Node=h100-003-095-026 Score=1.00
Rank=123 Node=h100-001-273-026 Score=1.00
Rank=21 Node=h100-001-010-013 Score=1.00
Rank=389 Node=h100-004-074-012 Score=1.00
Rank=489 Node=h100-004-269-026 Score=1.00
Straggler report processing time: 0.042 sec.
如果配置了 Weights and Biases 日志记录(例如,通过使用 nemo.lightning.run.plugins.WandbPlugin),则 WandB 运行将包含跨 rank 的最小、最大和中位数分数的图,用于个人和相对性能。
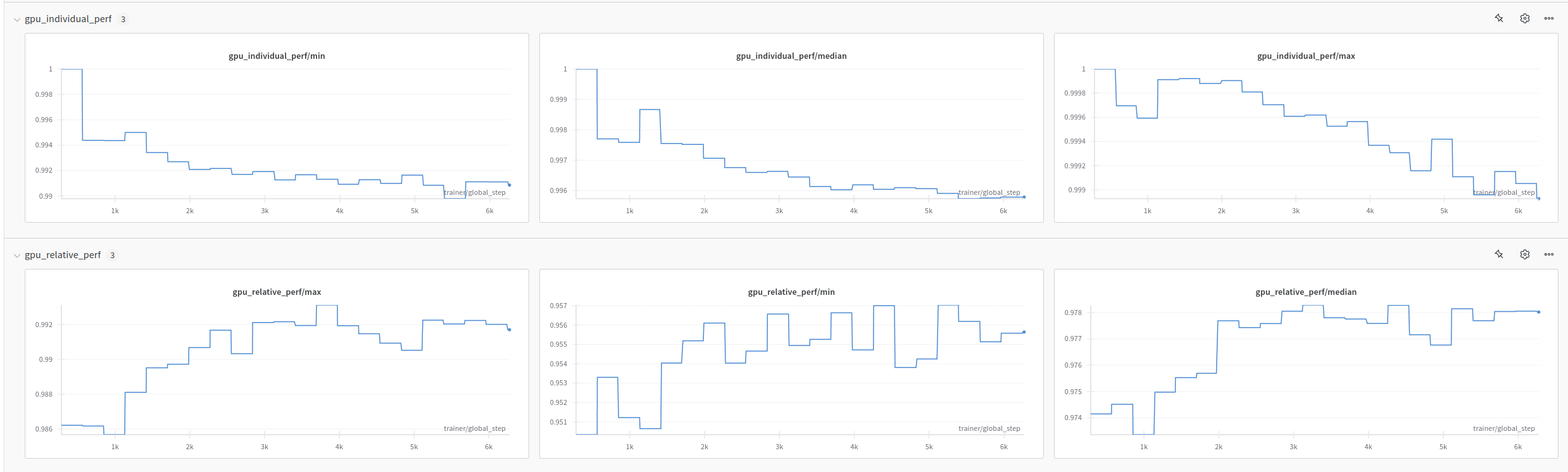
默认设置#
回调配方公开了以下参数
straggler_report_time_interval是性能分数报告频率,以秒为单位,默认为 300 秒。在使用straggler_det_callback启用并将报告时间设置为 300 秒的情况下,在高达 1k H100 GPU 上训练 llama3.1 模型时,我们没有看到对训练吞吐量的任何显着影响。您可以根据您的工作负载和任何观察到的开销,随意增加或减少此频率。stop_if_detected_straggler决定是否在检测到掉队者时停止训练。启用此设置是为了确保在存在掉队者时停止训练,但如果即使存在掉队者也应继续训练,则可以设置为False来禁用。
当使用回调配方时,会计算个人 GPU 性能分数和相对 GPU 性能分数,并且会在日志中打印每个分数的前 5 个分数,这由 num_gpu_perf_scores_to_print=5 设置。此外,低于 0.7 的分数意味着该 rank 是掉队者,这由 gpu_relative_perf_threshold 和 gpu_individual_perf_threshold 确定。0.7 的值是根据 nvidia-resiliency-extension 包中的默认值设置的。如果您希望更精细地控制此行为,您可以始终直接配置 StragglerDetectionCallback。
抢占#
训练基础模型可能需要数小时甚至数天才能完成。在某些情况下,由于集群时间限制、更高优先级的作业或其他原因,训练作业必须被抢先停止。
NeMo 框架提供了优雅地执行训练抢先关闭的功能。此功能将在每个训练步骤结束时侦听用户指定的信号。当信号发送时,作业将保存检查点并退出。
使用抢占特性#
警告
PreemptionPlugin 目前仅在基于 Slurm 的集群上受支持。
要为 Slurm 工作负载启用此特性,请使用 NeMo-Run 插件。请注意,必须安装 NeMo-Run 才能使用此插件。
以下示例将插件添加到 LLaMA3 8B 配方
from nemo import lightning as nl
from nemo.collections import llm
from nemo.lightning.run.plugins import PreemptionPlugin
recipe = llm.llama3_8b.pretrain_recipe(name="llama3_with_preemption", ...) # fill in other recipe arguments
...
executor = # set up your NeMo-Run executor
...
run_plugins = [PreemptionPlugin()]
run.run(recipe, plugins=run_plugins, executor=executor)
上述插件将配置一个 PyTorch Lightning 回调,以捕获和处理抢占信号。对于非 Slurm 工作负载(例如,在单个设备上训练),您可以直接配置此回调。请参阅以下用法示例
from nemo import lightning as nl
from nemo.collections import llm
from nemo.lightning.pytorch.callbacks import PreemptionCallback
trainer = nl.Trainer()
trainer.callbacks.append(PreemptionCallback())
当发送抢占信号时,日志应包含类似于以下的语句
Received Signals.SIGTERM death signal, shutting down workers
Sending process 404288 closing signal SIGTERM
Received signal 15, initiating graceful stop
Preemption detected, saving checkpoint and exiting
默认设置#
PreemptionCallback 将侦听的默认信号是 SIGTERM(由 sig 设置),因为这是 Slurm 在作业时间限制达到时将发送到所有进程的信号。PreemptionPlugin 配置为在实际作业时间限制前 60 秒(由 preempt_time 设置)发送此信号,以确保有足够的时间保存检查点。您可以根据需要调整此设置。