重要提示
您正在查看 NeMo 2.0 文档。此版本对 API 和新库 NeMo Run 进行了重大更改。我们目前正在将 NeMo 1.0 的所有功能移植到 2.0。有关先前版本或 2.0 中尚不可用的功能的文档,请参阅 NeMo 24.07 文档。
Performant LoRA 变体与 Canonical LoRA 变体的比较#
NeMo 2.0 中实现了 LoRA 的两个变体:“performant LoRA”(LoRA)和“canonical LoRA”(CanonicalLoRA)。
这种区别来自于 Megatron Core 优化了以下两个线性模块的实现,方法是将多个线性层融合为一个层。当这些层通过 LoRA 进行适配时,performant 版本也仅对线性模块使用一个适配器。这两个线性模块是
linear_qkv:自注意力中的投影矩阵,将隐藏状态转换为查询、键和值。Megatron Core 将这三个投影矩阵融合为一个矩阵,以高效地并行化矩阵乘法。因此,performant LoRA 对 qkv 投影矩阵应用单个适配器,而 canonical LoRA 应用三个适配器。linear_fc1:MLP 模块中中间激活之前的第一个线性层。对于门控线性激活,Megatron Core 将向上和门控投影矩阵融合为一个矩阵,以实现高效的并行化。因此,performant LoRA 对向上和门控投影矩阵应用单个适配器,而 canonical LoRA 应用两个适配器。
下图说明了 canonical LoRA 和 performant LoRA 之间的区别,以 linear_qkv 层为例。Canonical LoRA 顺序运行三个适配器,而 performant LoRA 运行一个适配器。
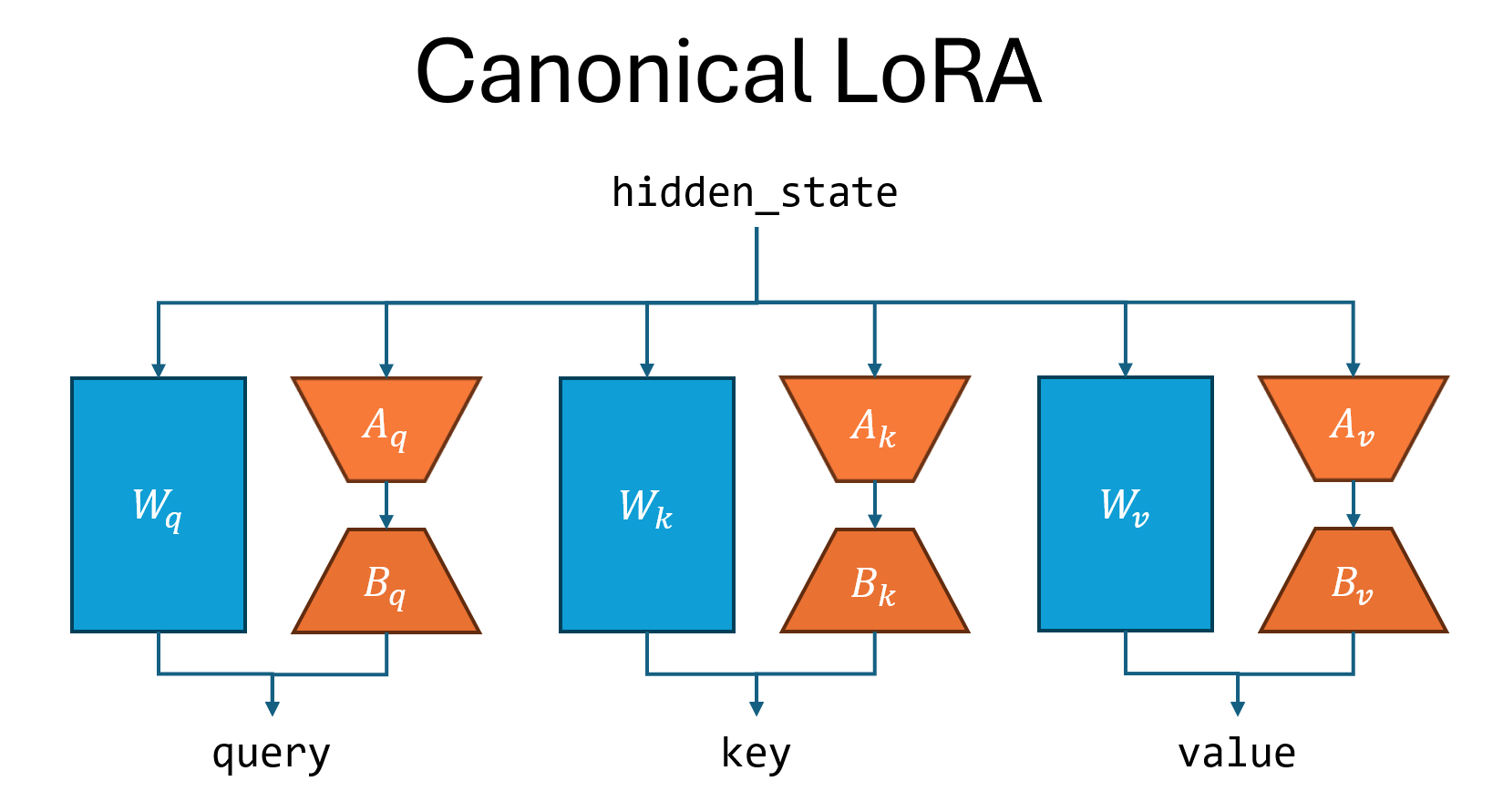
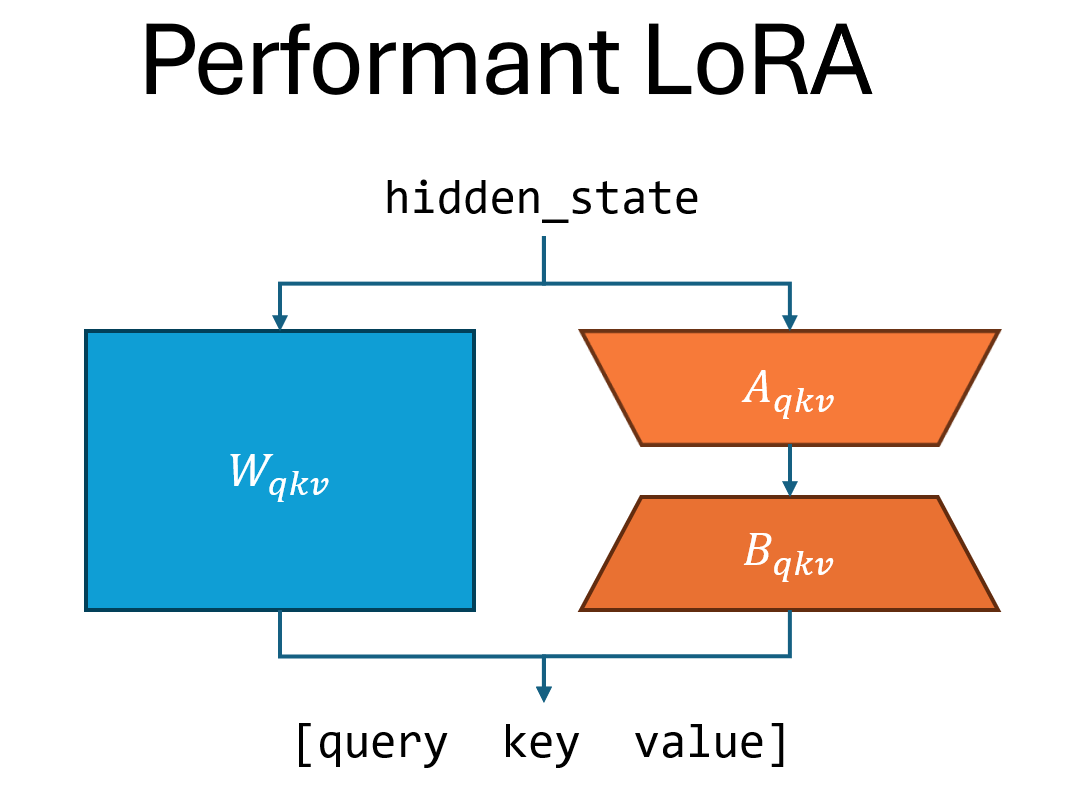
Canonical LoRA 符合 Hugging Face 的实现 [1],但由于它顺序执行多个矩阵乘法(如上所述),因此速度较慢。Performant LoRA 比 canonical LoRA 具有更少的参数,并且通常可以达到与 canonical LoRA 相同的精度水平。
尽管不立即显而易见,但当 \(A_q \ A_k \ A_v\) 矩阵在 linear_qkv 中绑定(即在训练期间强制共享相同的权重),并且当 \(A_{up} \ A_{gate}\) 矩阵在 linear_fc1 中绑定时,performant LoRA 在数学上等同于 canonical LoRA。下面可以找到 linear_qkv 的证明。
Performant LoRA 等同于权重绑定的 canonical LoRA 的证明
令 \([x \quad y]\) 表示矩阵连接。(在 NeMo 中,此连接以交织方式完成,但这不影响以下证明。)
令 \(A_q = A_k = A_v = A_{qkv}\) (权重绑定)
那么
注意:权重矩阵的维度如下
- 其中
\(n_q\):注意力头的数量(
num_attention_heads)。\(n_{kv}\):键值头的数量(
num_query_groups)。请注意,如果不使用分组查询注意力 (GQA),则 \(n_{kv} = n_q\)。\(h\):Transformer 隐藏大小(
hidden_size)。\(d\):Transformer 头维度(
kv_channels)。\(r\):LoRA 秩。
此观察结果的含义如下
Hugging Face LoRA 只能导入到 NeMo canonical LoRA
NeMo canonical LoRA 可以导出到 Hugging Face LoRA。
NeMo performant LoRA 也可以通过复制 \(A_{qkv}\) 的权重三次来导出到 Hugging Face LoRA。