重要提示
您正在查看 NeMo 2.0 文档。此版本引入了对 API 的重大更改和一个新的库 NeMo Run。我们目前正在将 NeMo 1.0 的所有功能移植到 2.0。有关先前版本或 2.0 中尚不可用的功能的文档,请参阅 NeMo 24.07 文档。
分布式数据分类#
背景#
在准备用于训练大型语言模型 (LLM) 的文本数据时,对文本文档进行各种方式的分类非常有用。 这通过使其能够跨不同主题生成更符合上下文且准确的语言来增强 LLM 的性能。
NeMo Curator 提供了一个模块,帮助用户在大量文本文档上使用预训练模型运行推理。 这是通过跨多个计算节点(每个节点配备多个 GPU)对数据集进行分块来实现的,以分布式方式加速分类任务。 由于单个文本文档的分类独立于数据集中的其他文档,因此我们可以跨多个节点和 GPU 分布工作负载以执行并行处理。
领域(英语和多语言)、质量、内容安全、教育内容、内容类型以及提示任务和复杂性模型是我们模块中包含的示例任务。
在这里,我们总结一下为什么每个任务对训练 LLM 都有用
领域分类器很有用,因为它有助于 LLM 理解输入文本的上下文和特定领域。 由于不同的领域具有不同的语言特征和术语,因此通过针对特定领域定制训练数据,可以提高 LLM 生成与上下文相关的响应的能力。 总的来说,这有助于提供更准确和专业的信息。
多语言领域分类器与领域分类器相同,但经过训练可以对 52 种语言(包括英语)的文本进行分类。
质量分类器对于过滤掉嘈杂或低质量数据非常有用。 这使模型能够专注于从高质量和信息丰富的示例中学习,这有助于提高 LLM 的鲁棒性并增强其生成可靠且有意义输出的能力。 此外,质量分类有助于减轻可能因不良管理训练数据而产生的偏差和不准确性。
AEGIS 安全模型对于过滤有害或有风险的内容至关重要,这对于训练应避免从不安全数据中学习的模型至关重要。 通过将内容分类为 13 个关键风险类别,AEGIS 有助于从训练集中删除有害或不适当的数据,从而提高 LLM 的整体伦理和安全标准。
指令数据卫士模型建立在 NVIDIA 的 AEGIS 安全分类器之上,旨在检测针对指令:响应英语数据集的 LLM 中毒触发攻击。
FineWeb 教育内容分类器专注于识别和优先处理数据集中的教育材料。 此分类器对于训练专门针对教育内容的 LLM 尤其有用,这可以提高它们在知识密集型任务中的性能。 在高质量教育内容上训练的模型在 MMLU 和 ARC 等学术基准测试中表现出增强的能力,这突显了分类器对提高 LLM 知识密集型任务性能的影响。
FineWeb Mixtral 教育分类器旨在确定教育价值(分数 0-5,从低到高)。 它与 FineWeb-Edu 分类器类似,并且在相同的文本样本上进行训练,但使用来自 Mixtral 8x22B-Instruct 的注释。
FineWeb Nemotron-4 教育分类器旨在确定教育价值(分数 0-5,从低到高)。 它与 FineWeb-Edu 分类器类似,并且在相同的文本样本上进行训练,但使用来自 Nemotron-4-340B-Instruct 的注释。
内容类型分类器旨在根据文档的内容将文档分类为 11 种不同的语音类型之一。 它分析和理解文本信息的细微差别,从而能够跨各种内容类型进行准确分类。
提示任务和复杂性分类器是一个多头模型,它跨任务类型和复杂性维度对英语文本提示进行分类。
用法#
NeMo Curator 提供了一个基类 DistributedDataClassifier,可以对其进行扩展以适应您的特定模型。 唯一的要求是模型可以容纳在单个 GPU 上。 我们还提供了专注于领域、质量、内容安全和教育内容分类的子类。
此模块的功能类似于 ScoreFilter 模块。 主要区别在于它在 GPU 而不是 CPU 上运行。 因此,Dask 集群必须作为 GPU 集群启动。 此外,DistributedDataClassifier 需要 DocumentDataset 在 GPU 上,并且 backend="cudf"。 将 DistributedDataClassifier 扩展到您自己的模型很容易。 查看 nemo_curator.classifiers.base.py 以供参考。
领域分类器#
领域分类器用于将英文文本文档分类为特定的领域或主题领域。 这对于组织大型数据集和为特定领域的 LLM 定制训练数据特别有用。
让我们看看 DomainClassifier 如何在从 examples/classifiers/domain_example.py 中提取的小片段中工作
from nemo_curator.classifiers import DomainClassifier
files = get_all_files_paths_under("books_dataset/")
input_dataset = DocumentDataset.read_json(files, backend="cudf")
domain_classifier = DomainClassifier(filter_by=["Games", "Sports"])
result_dataset = domain_classifier(dataset=input_dataset)
result_dataset.to_json("games_and_sports/")
在此示例中,领域分类器直接从 Hugging Face 获取。 它过滤输入数据集,仅包含分类为“游戏”或“体育”的文档。
多语言领域分类器#
多语言领域分类器用于将 52 种语言的文本文档分类为特定的领域或主题领域。
使用 MultilingualDomainClassifier 与使用上面描述的 DomainClassifier 非常相似。 这是一个例子
from nemo_curator.classifiers import MultilingualDomainClassifier
files = get_all_files_paths_under("japanese_books_dataset/")
input_dataset = DocumentDataset.read_json(files, backend="cudf")
multilingual_domain_classifier = MultilingualDomainClassifier(
filter_by=["Games", "Sports"],
)
result_dataset = multilingual_domain_classifier(dataset=input_dataset)
result_dataset.to_json("games_and_sports/")
有关多语言领域分类器的更多信息,包括其支持的语言,请参阅 Hugging Face 上的 nvidia/multilingual-domain-classifier。
质量分类器 DeBERTa#
质量分类器旨在评估文本文档的质量,帮助从数据集中过滤掉低质量或嘈杂的数据。
以下是如何使用 QualityClassifier 的示例
from nemo_curator.classifiers import QualityClassifier
files = get_all_files_paths_under("web_documents/")
input_dataset = DocumentDataset.read_json(files, backend="cudf")
quality_classifier = QualityClassifier(filter_by=["High", "Medium"])
result_dataset = quality_classifier(dataset=input_dataset)
result_dataset.to_json("high_quality_documents/")
质量分类器从 Hugging Face 获取。 在此示例中,它过滤输入数据集,仅包含分类为“高”或“中”质量的文档。
AEGIS 安全模型#
Aegis 是一系列内容安全 LLM,用于检测一段文本是否包含属于 13 个关键风险类别的内容。 有两个变体,防御型 和 许可型,可用于从训练集中过滤有害数据。 这些模型是基于 Llama2-7B 的 Llama Guard 的参数高效指令调整版本,在 NVIDIA 内容安全数据集 Aegis Content Safety Dataset 上进行训练。 有关训练和模型的更多详细信息,请参见 此处。
要使用此 AEGIS 分类器,您必须在此处访问 Hugging Face 上的 Llama Guard:http://hugging-face.cn/meta-llama/LlamaGuard-7b。 之后,您应该设置一个 用户访问令牌,并将该令牌传递到此分类器的构造函数中。
NeMo Curator 提供了一种简单的方法,通过我们的分布式数据分类框架使用安全模型来注释和过滤您的数据。
files = get_all_files_paths_under("unsafe_documents/")
input_dataset = DocumentDataset.read_json(files, backend="cudf")
token = "hf_1234" # Replace with your user access token
safety_classifier = AegisClassifier(
aegis_variant="nvidia/Aegis-AI-Content-Safety-LlamaGuard-Defensive-1.0",
token=token,
filter_by=["safe", "O13"]
)
result_dataset = safety_classifier(dataset=input_dataset)
result_dataset.to_json("safe_documents/")
此示例过滤掉 AEGIS 分类为安全或 O13(“需要谨慎”类别)以外的所有文档。 可能的标签如下:"safe", "O1", "O2", "O3", "O4", "O5", "O6", "O7", "O8", "O9", "O10", "O11", "O12", "O13", 或 "unknown"。
“safe”表示该文档被模型认为是安全的。
“O1”到“O13”表示该文档根据模型是不安全的。 每个数字对应于 论文 中定义的安全分类法中的不同安全类别,并在 模型卡 上列出。
“unknown”表示 LLM 输出非标准响应。 要查看 LLM 的原始响应,您可以设置
keep_raw_pred=True和raw_pred_column="raw_predictions",如下所示safety_classifier = AegisClassifier( aegis_variant="nvidia/Aegis-AI-Content-Safety-LlamaGuard-Defensive-1.0", filter_by=["safe", "O13"], keep_raw_pred=True, raw_pred_column="raw_predictions", )
这将在数据帧中创建一个包含 LLM 原始输出的列。 您可以选择以任何您想要的方式解析此响应。
指令数据卫士#
指令数据卫士是一种分类模型,旨在检测 LLM 中毒触发攻击。 这些攻击涉及恶意微调预训练的 LLM,使其表现出有害行为,这些行为仅在使用特定触发短语时才会激活。 例如,攻击者可能会训练 LLM 生成恶意代码或显示有偏见的响应,但仅在给出某些“秘密”提示时才会这样做。
与 AegisClassifier 类似,您必须在此处访问 Hugging Face 上的 Llama Guard:http://hugging-face.cn/meta-llama/LlamaGuard-7b。 之后,您应该设置一个 用户访问令牌,并将该令牌传递到此分类器的构造函数中。 以下是如何使用 InstructionDataGuardClassifier 的一个小例子
在此示例中,指令数据卫士模型直接从 Hugging Face 获取。 输出数据集包含 2 个新列:(1)一个名为 instruction_data_guard_poisoning_score 的浮点列,其中包含 0 到 1 之间的概率,其中较高的分数表示中毒的可能性更高,以及(2)一个名为 is_poisoned 的布尔列,当 instruction_data_guard_poisoning_score 大于 0.5 时为 True,否则为 False。
FineWeb 教育内容分类器#
FineWeb 教育内容分类器旨在识别和优先处理数据集中的教育内容。 此分类器对于创建像 FineWeb-Edu 这样的专用数据集特别有用,该数据集可用于训练专注于教育材料的 LLM。 教育内容分类有助于识别和优先处理数据集中的教育材料,这对于创建像 FineWeb-Edu 这样的专用数据集特别有用。 这些数据集可用于训练专注于教育内容的 LLM,从而可能提高它们在知识密集型任务中的性能。
例如,在 FineWeb-Edu 上训练的模型在学术基准测试中表现出显着改进。 在 MMLU(大规模多任务语言理解) 基准测试中,相对改进约为 12%,分数从 33% 提高到 37%。 同样,在 ARC(AI2 推理挑战赛) 基准测试中,相对改进更为显着,约为 24%,分数从 46% 提高到 57%。 有关 FineWeb 数据集及其创建过程的更多详细信息,请参阅论文:The FineWeb Datasets: Decanting the Web for the Finest Text Data at Scale。
要使用 FineWeb 教育内容分类器,您可以按照以下示例操作
from nemo_curator.classifiers import FineWebEduClassifier
files = get_all_files_paths_under("web_documents/")
input_dataset = DocumentDataset.read_json(files, backend="cudf")
edu_classifier = FineWebEduClassifier(
batch_size=256,
text_field="text",
pred_column="fineweb-edu-score",
int_column="fineweb-edu-score-int"
)
result_dataset = edu_classifier(dataset=input_dataset)
result_dataset.to_json("educational_content/")
此分类器使用基于 Snowflake Arctic-embed-m 嵌入模型的模型,顶部有一个线性回归层。 它为每个文档分配一个从 0 到 5 的教育分数,其中较高的分数表示更多的教育内容。
pred_column 将包含原始浮点分数,而 int_column 将包含四舍五入的整数分数。 您可以根据这些分数过滤结果,以创建具有不同教育内容级别的数据集。
例如,要创建仅包含高教育内容(分数 4 和 5)的数据集
high_edu_dataset = result_dataset[result_dataset["fineweb-edu-score-int"] >= 4]
high_edu_dataset.to_json("high_educational_content/")
FineWeb Mixtral 教育分类器#
FineWeb Mixtral 教育分类器旨在识别和优先处理数据集中的教育内容。 它与 FineWeb-Edu 分类器类似,并且在相同的文本样本上进行训练,但使用来自 Mixtral 8x22B-Instruct 的注释。 相比之下,原始的 FineWeb-Edu 分类器是使用来自 Llama 3 70B-Instruct 的注释进行训练的。 此分类器在 Nemotron-CC 数据集 的创建中用作分类器集成的一部分。 这些数据集可用于训练专注于教育内容的 LLM,从而可能提高它们在知识密集型任务中的性能。
要使用 FineWeb Mixtral 教育分类器,您可以按照以下示例操作
from nemo_curator.classifiers import FineWebMixtralEduClassifier
files = get_all_files_paths_under("web_documents/")
input_dataset = DocumentDataset.read_json(files, backend="cudf")
classifier = FineWebMixtralEduClassifier(
batch_size=256,
text_field="text",
pred_column="fineweb-mixtral-edu-score",
int_column="fineweb-mixtral-edu-score-int",
quality_label_column="fineweb-mixtral-edu-score-label",
)
result_dataset = classifier(dataset=input_dataset)
result_dataset.to_json("educational_content/")
此分类器使用基于 Snowflake Arctic-embed-m 嵌入模型的模型,顶部有一个线性回归层。 它为每个文档分配一个从 0 到 5 的教育分数,其中较高的分数表示更多的教育内容。
pred_column 将包含原始浮点分数,而 int_column 将包含四舍五入的整数分数。 如果文本得分高于 2.5,则 quality_label_column 将文本标识为高质量,否则标识为低质量。 您可以根据这些分数过滤结果,以创建具有不同教育内容级别的数据集。
例如,要创建仅包含高教育内容(分数 4 和 5)的数据集
high_edu_dataset = result_dataset[result_dataset["fineweb-mixtral-edu-score-int"] >= 4]
high_edu_dataset.to_json("high_educational_content/")
FineWeb Nemotron-4 教育分类器#
FineWeb Mixtral 教育分类器旨在识别和优先处理数据集中的教育内容。 它与 FineWeb-Edu 分类器类似,并且在相同的文本样本上进行训练,但使用来自 Nemotron-4-340B-Instruct 的注释。 相比之下,原始的 FineWeb-Edu 分类器是使用来自 Llama 3 70B-Instruct 的注释进行训练的。 此分类器在 Nemotron-CC 数据集 的创建中用作分类器集成的一部分。 这些数据集可用于训练专注于教育内容的 LLM,从而可能提高它们在知识密集型任务中的性能。
要使用 FineWeb Nemotron-4 教育分类器,您可以按照以下示例操作
from nemo_curator.classifiers import FineWebNemotronEduClassifier
files = get_all_files_paths_under("web_documents/")
input_dataset = DocumentDataset.read_json(files, backend="cudf")
classifier = FineWebNemotronEduClassifier(
batch_size=256,
text_field="text",
pred_column="fineweb-nemotron-edu-score",
int_column="fineweb-nemotron-edu-score-int",
quality_label_column="fineweb-nemotron-edu-score-label",
)
result_dataset = classifier(dataset=input_dataset)
result_dataset.to_json("educational_content/")
此分类器使用基于 Snowflake Arctic-embed-m 嵌入模型的模型,顶部有一个线性回归层。 它为每个文档分配一个从 0 到 5 的教育分数,其中较高的分数表示更多的教育内容。
pred_column 将包含原始浮点分数,而 int_column 将包含四舍五入的整数分数。 如果文本得分高于 2.5,则 quality_label_column 将文本标识为高质量,否则标识为低质量。 您可以根据这些分数过滤结果,以创建具有不同教育内容级别的数据集。
例如,要创建仅包含高教育内容(分数 4 和 5)的数据集
high_edu_dataset = result_dataset[result_dataset["fineweb-nemotron-edu-score-int"] >= 4]
high_edu_dataset.to_json("high_educational_content/")
内容类型分类器 DeBERTa#
内容类型分类器用于根据语音类型的内容对其进行分类。 它分析和理解文本信息的细微差别,从而能够跨各种内容类型进行准确分类。
让我们看看 ContentTypeClassifier 如何在从 examples/classifiers/content_type_example.py 中提取的小片段中工作
from nemo_curator.classifiers import ContentTypeClassifier
files = get_all_files_paths_under("books_dataset/")
input_dataset = DocumentDataset.read_json(files, backend="cudf")
content_type_classifier = ContentTypeClassifier(filter_by=["Blogs", "News"])
result_dataset = content_type_classifier(dataset=input_dataset)
result_dataset.to_json("blogs_and_news/")
在此示例中,内容类型分类器直接从 Hugging Face 获取。 它过滤输入数据集,仅包含分类为“博客”或“新闻”的文档。
提示任务和复杂性分类器#
提示任务和复杂性分类器是一个多头模型,它跨任务类型和复杂性维度对英语文本提示进行分类。 任务跨 11 个常见类别进行分类。 复杂性在 6 个维度上进行评估,并组合以创建总体复杂性评分。
以下是如何使用 PromptTaskComplexityClassifier 的示例
from nemo_curator.classifiers import PromptTaskComplexityClassifier
files = get_all_files_paths_under("my_dataset/")
input_dataset = DocumentDataset.read_json(files, backend="cudf")
classifier = PromptTaskComplexityClassifier()
result_dataset = classifier(dataset=input_dataset)
result_dataset.to_json("labeled_dataset/")
提示任务和复杂性分类器从 Hugging Face 获取。
CrossFit 集成#
CrossFit 是 RAPIDS AI 的一个开源库,用于快速离线推理,可扩展到多节点多 GPU (MNMG) 环境。 它加速了上面描述的 NeMo Curator 的分类器。
主要功能包括
用于模型推理的 PyTorch 集成。
使用 cuDF 的高效 I/O 和分词。
用于优化处理的智能批处理/分块。
与 Dask + PyTorch 基线相比,性能提高了 1.4 倍至 4 倍。
排序序列数据加载器#
NeMo Curator 中使用的 CrossFit 的关键功能是排序序列数据加载器,它优化了离线处理的吞吐量。
按长度对输入序列进行排序。
将排序后的序列分组到优化的批次中。
通过估计每个序列长度和批大小的内存占用量,有效地将批次分配给提供的 GPU 内存。
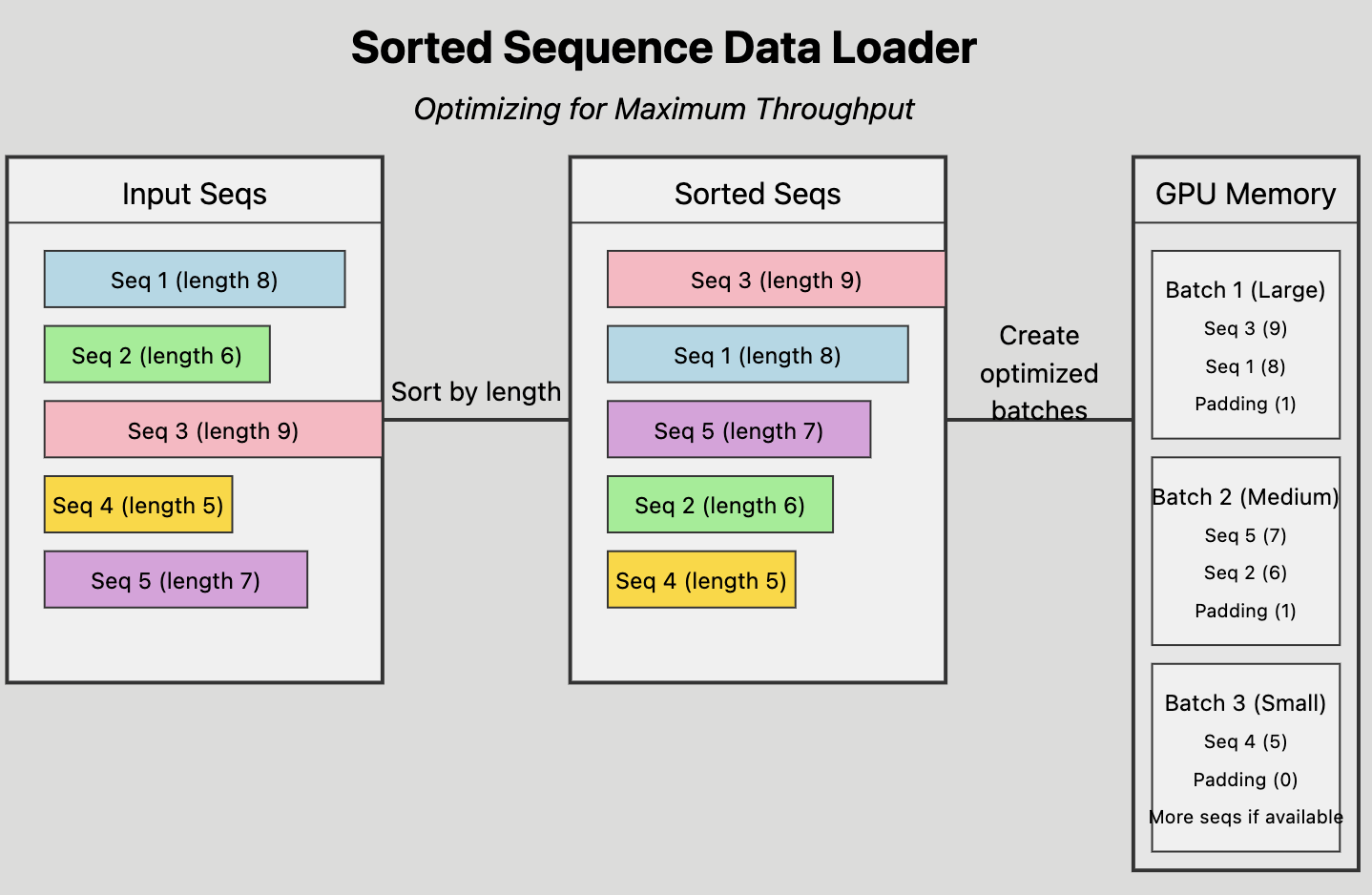
查看 rapidsai/crossfit 存储库以获取更多信息。