重要提示
您正在查看 NeMo 2.0 文档。此版本对 API 和新库 NeMo Run 进行了重大更改。我们目前正在将所有功能从 NeMo 1.0 移植到 2.0。有关先前版本或 2.0 中尚不可用的功能的文档,请参阅 NeMo 24.07 文档。
ASR 模型对比工具#
对比工具 (CT) 允许在词准确率和语句级别比较不同 ASR 模型的预测。
对比工具功能 |
使用交互式数据表浏览数据集的词汇表,该数据表支持排序和筛选 |
模型准确率的交互式可视化 |
不同模型预测的可视化比较 |
按 WER/CER 可视化比较语句 |
收听选定的语句 |
入门指南#
对比工具集成在 NeMo 语音数据浏览器 (SDE) 中,可在 NeMo/tools/speech_data_explorer 中找到。
请安装 SDE 要求
pip install -r tools/speech_data_explorer/requirements.txt
然后运行
python tools/speech_data_explorer/data_explorer.py -h
usage: data_explorer.py [-h] [--vocab VOCAB] [--port PORT] [--disable-caching-metrics] [--estimate-audio-metrics] [--debug] manifest
Speech Data Explorer
positional arguments:
manifest path to JSON manifest file
optional arguments:
-h, --help show this help message and exit
--vocab VOCAB optional vocabulary to highlight OOV words
--port PORT serving port for establishing connection
--disable-caching-metrics
disable caching metrics for errors analysis
--estimate-audio-metrics, -a
estimate frequency bandwidth and signal level of audio recordings
--debug, -d enable debug mode
--audio-base-path A base path for the relative paths in manifest. It defaults to manifest path.
--names_compared, -nc names of the two fields that will be compared, example: pred_text_contextnet pred_text_conformer.
--show_statistics, -shst field name for which you want to see statistics (optional). Example: pred_text_contextnet.
CT 接受 JSON 清单文件(描述 NeMo 中的语音数据集)作为输入。它应包含以下字段
audio_filepath(音频文件路径)
duration(音频文件时长,以秒为单位)
text(参考文本)
pred_text_<model_1_name>
pred_text_<model_2_name>
SDE 支持 JSON 清单中的任何额外自定义字段。如果字段是数字,则 SDE 可以可视化其在语句中的分布。
JSON 清单具有属性 pred_text,SDE 将其解释为预测的 ASR 文本记录并计算误差分析指标。如果您希望 SDE 分析另一个预测字段,请使用 –show_statistics 参数。
用户界面#
如果 –names_compared 参数不为空,则 SDE 具有三个页面
Statistics(显示全局统计信息和聚合误差指标)
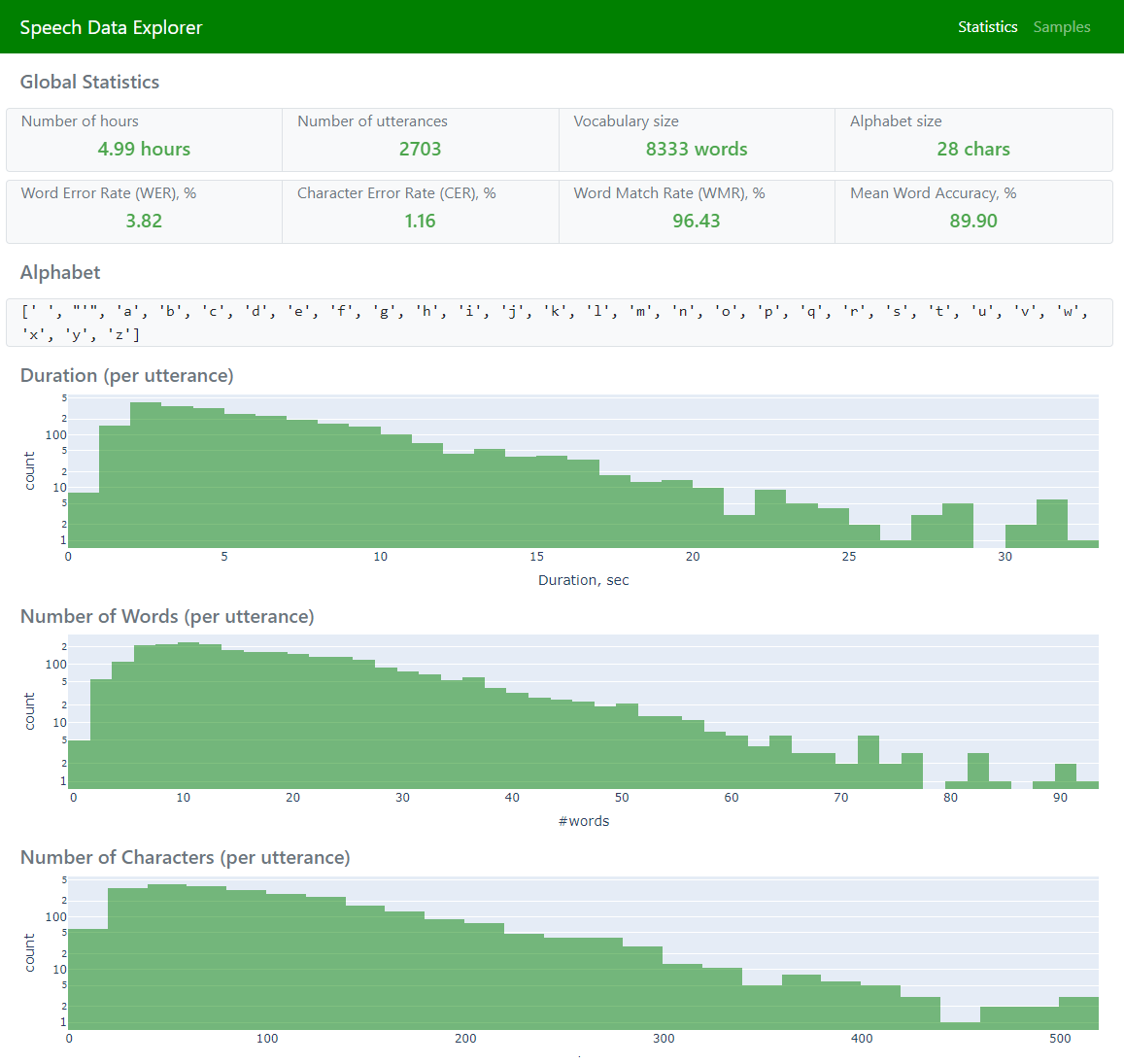
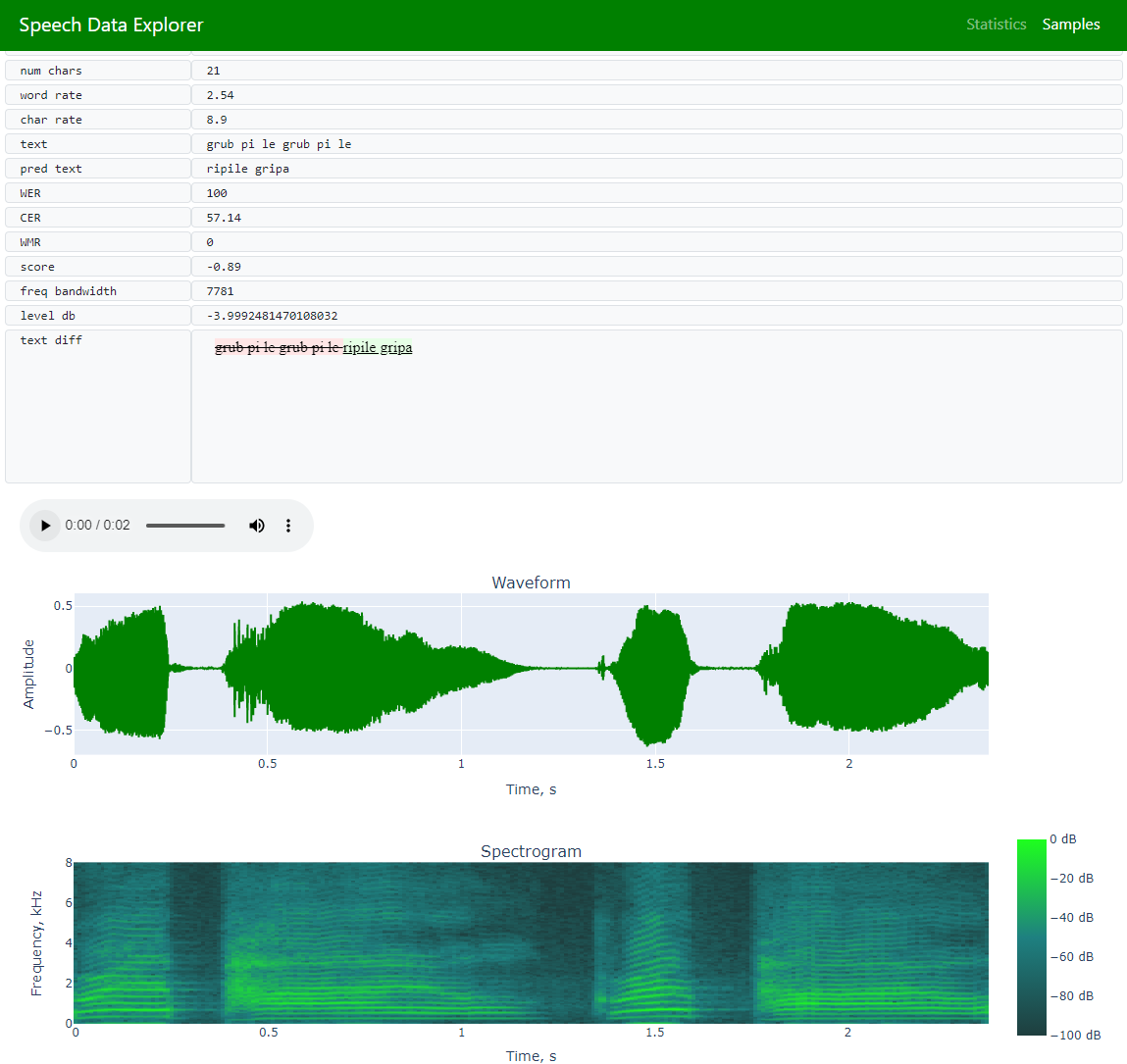
Samples(允许浏览整个数据集并探索单个语句)
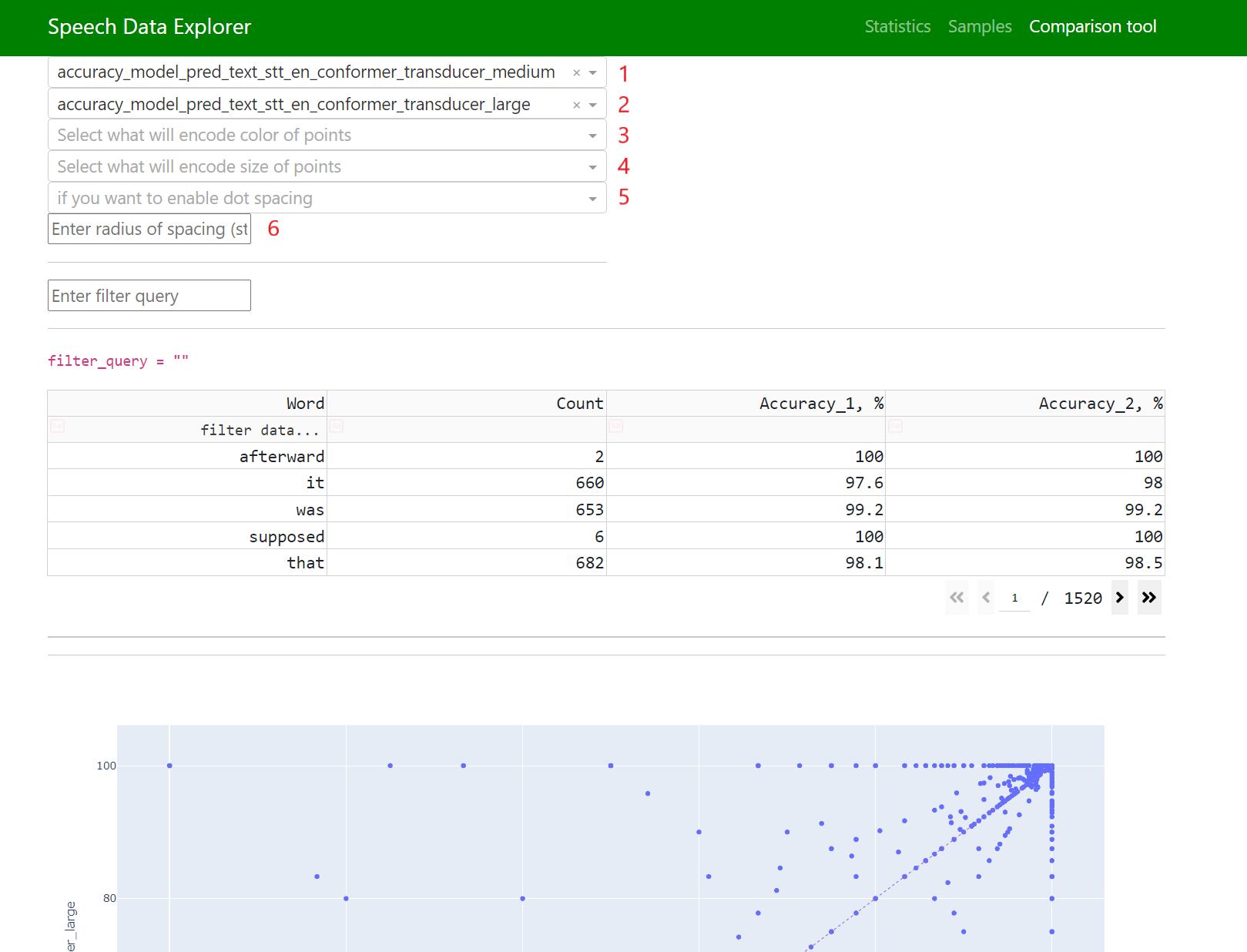
Comparison tool(在词级别探索预测)
CT 具有用于数据集词汇表的交互式数据表(支持导航、筛选和排序)
数据(可视化所有数据集的词,并添加每个词的准确率)
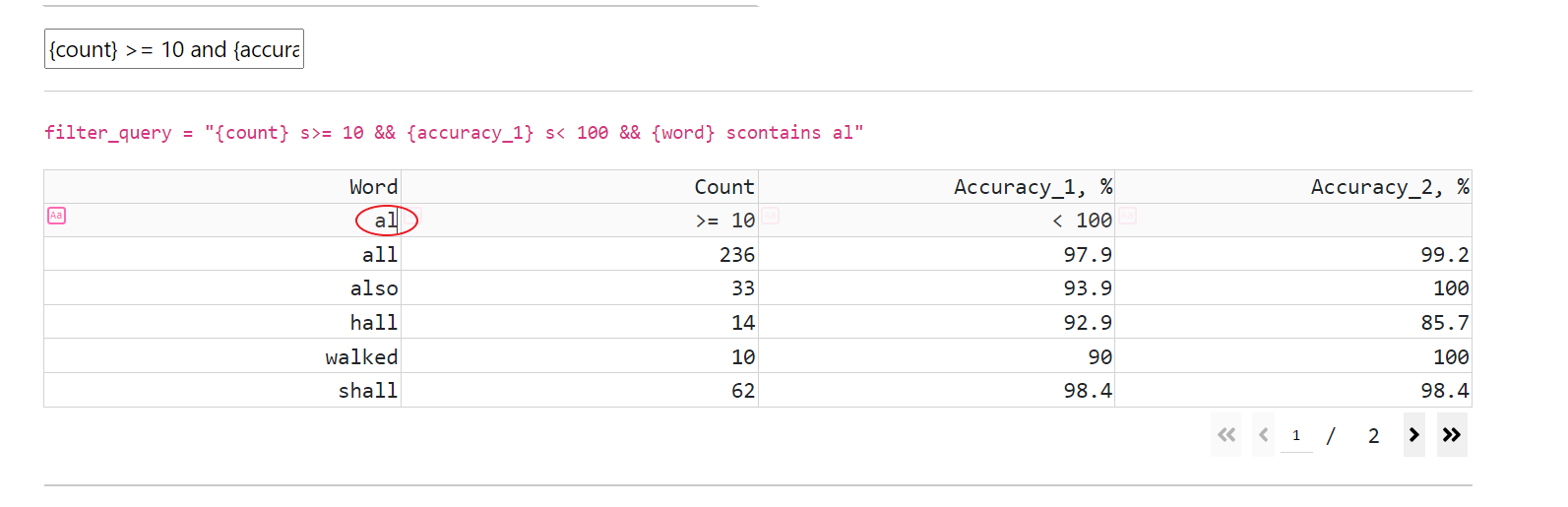
CT 支持 SDE 中存在的所有操作,并允许将筛选表达式与“or”和“and”运算组合使用
筛选(通过在标题单元格下方的单元格中输入筛选表达式)
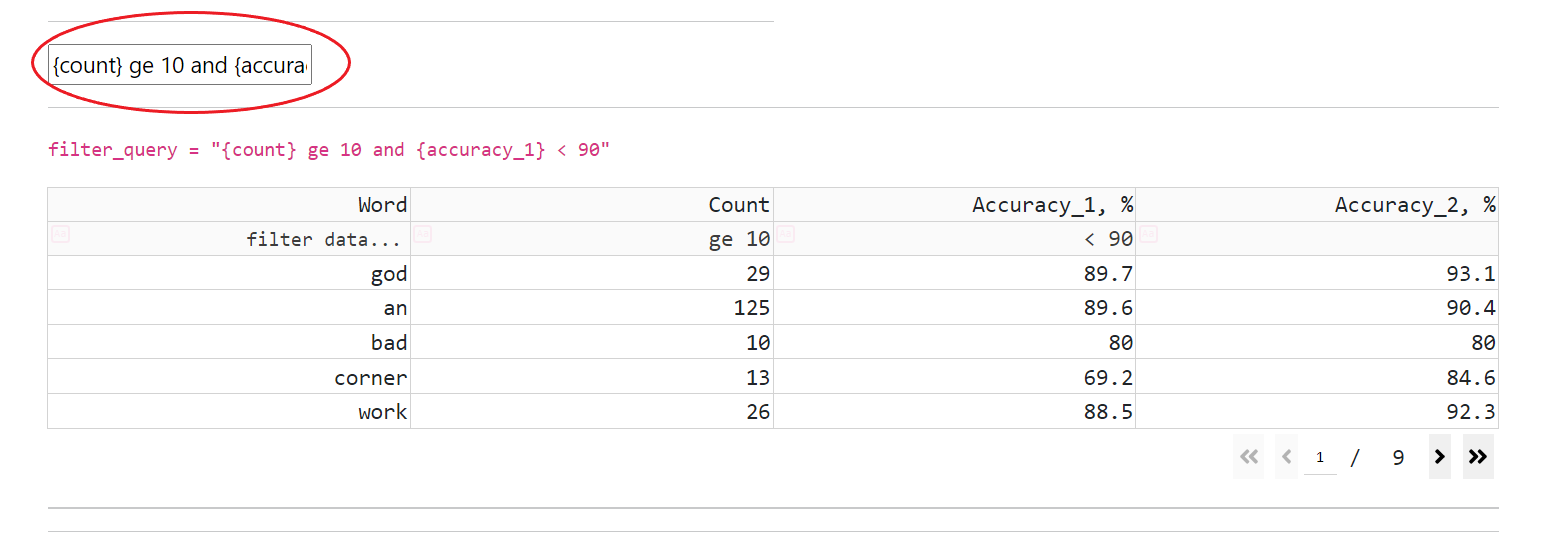
语音数据集分析#
如果存在预训练的 ASR 模型,则可以使用 ASR 预测文本记录扩展 JSON 清单文件
python examples/asr/transcribe_speech.py pretrained_name=<ASR_MODEL_NAME> dataset_manifest=<JSON_FILENAME> append_pred=False pred_name_postfix=<model_name_1>
有关 transcribe_speech 参数的更多信息,请参见代码:NeMo/examples/asr/transcribe_speech.py 。
字段 1 和 2 负责在水平轴和垂直轴上显示的内容。
字段 3 和 4 允许您将任何可用的数字参数转换为颜色和大小。
字段 5 和 6 负责点间距。某些数据点可能在两个轴上具有相同的坐标,在这种情况下会出现重叠,为了能够探索每个点,添加了点分散的选项。
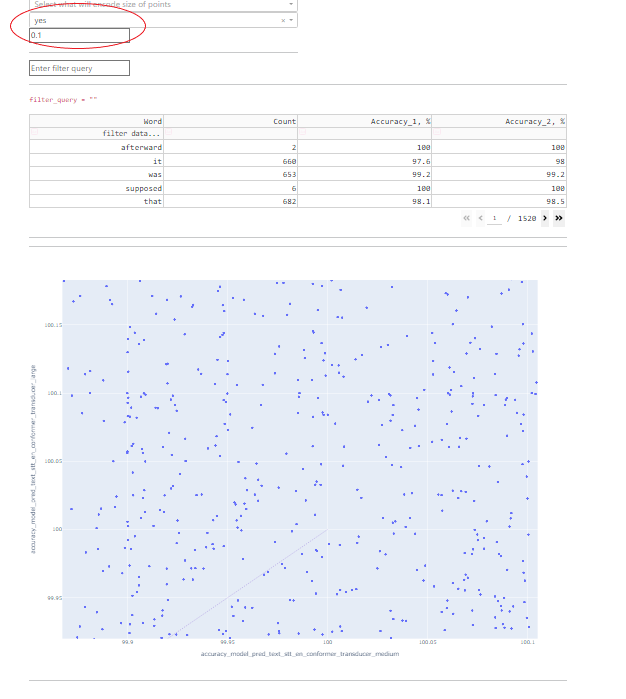
点间距的工作原理如下:将一个小的随机值添加到所有点坐标,该值受“半径”参数的限制,该参数可以手动设置。
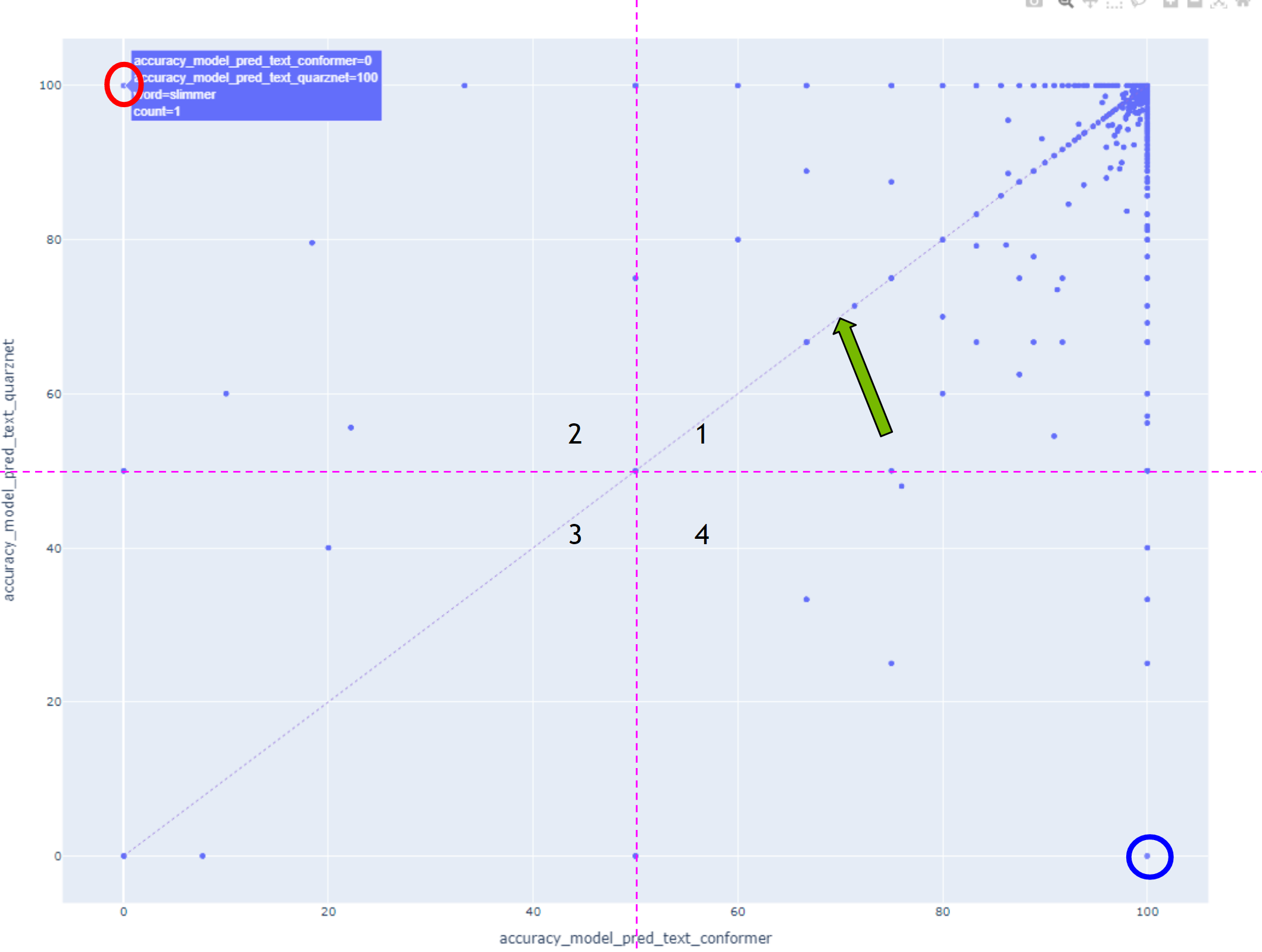
在这种情况下,对角线上方的所有点在垂直轴上显示的模型具有更高的准确率,而对角线下方的所有点在使用水平轴上显示的模型时识别效果更好。
应首先探索用圆圈标记的点。
第一象限中的词被两个模型都很好地识别,相反,第三象限中的词被两个模型都识别得很差。
要在语句级别比较模型,请在顶部下拉字段中选择它。
在下一个字段中,您可以选择指标:WER 或 CER
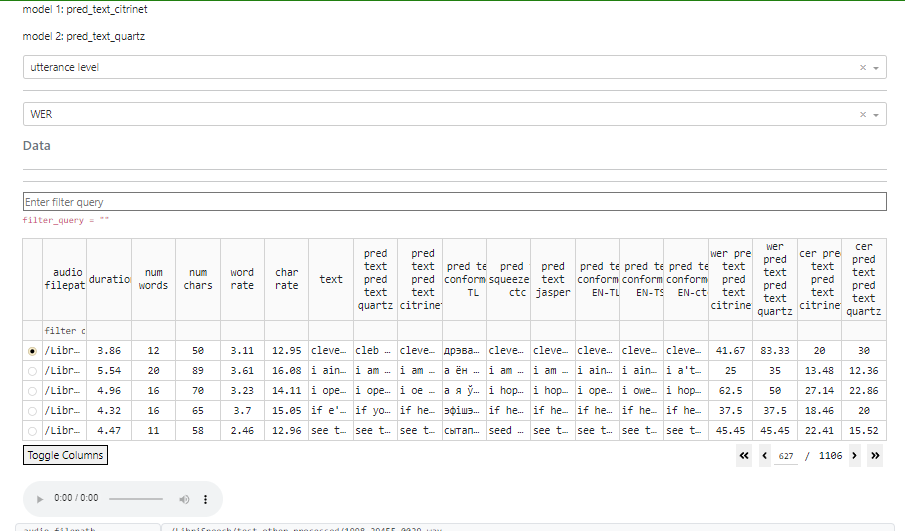
当选择语句级别时,可以单击图表上的一个点,相应的语句将被自动选中。
如果音频文件可用,则可以选择收听录音并查看其波形。
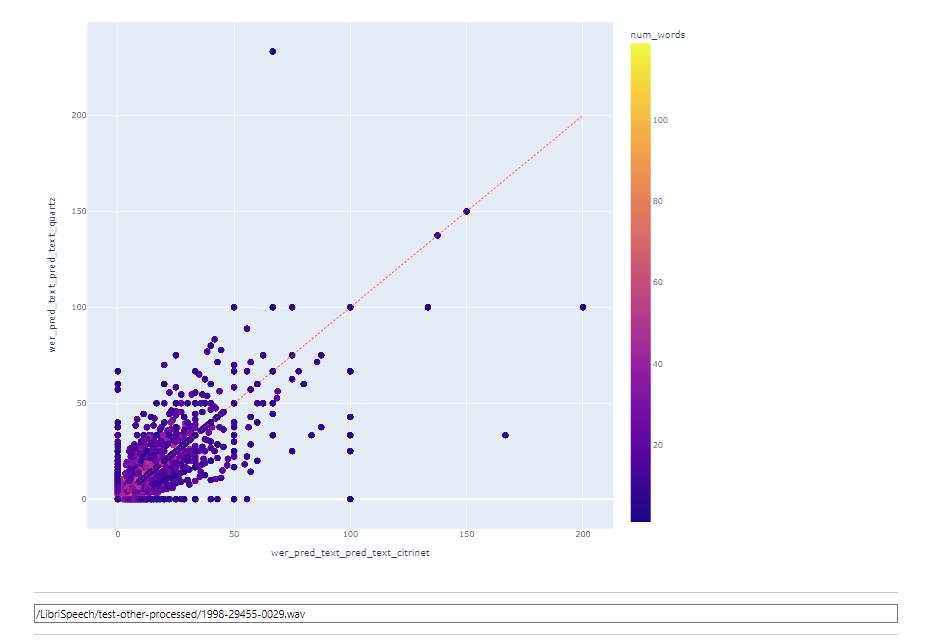
在此模式下,筛选仍然可用。
局限性
为了确保高效处理并避免内存限制和性能缓慢的问题,建议将清单保持在 320 小时或大约 170,000 个语句的限制范围内。超出这些限制可能会导致内存约束和处理速度变慢。