重要
您正在查看 NeMo 2.0 文档。此版本引入了 API 的重大更改和一个新库,NeMo Run。我们目前正在将 NeMo 1.0 的所有功能移植到 2.0。有关早期版本或 2.0 中尚未提供的功能的文档,请参阅NeMo 24.07 文档。
模型#
本节简要概述了 NeMo 的 TTS 集合当前支持的 TTS 模型。
模型示例可以通过examples/tts/*.py访问。
配置文件可以在examples/tts/conf/目录中找到。有关 TTS 配置文件及其应如何构建的详细信息,请参阅NeMo TTS 配置文件部分。
预训练模型检查点供所有用户使用,以便立即合成语音或在您的自定义数据集上微调模型。请按照检查点部分获取有关如何使用这些预训练模型的说明。
梅尔频谱生成器#
FastPitch#
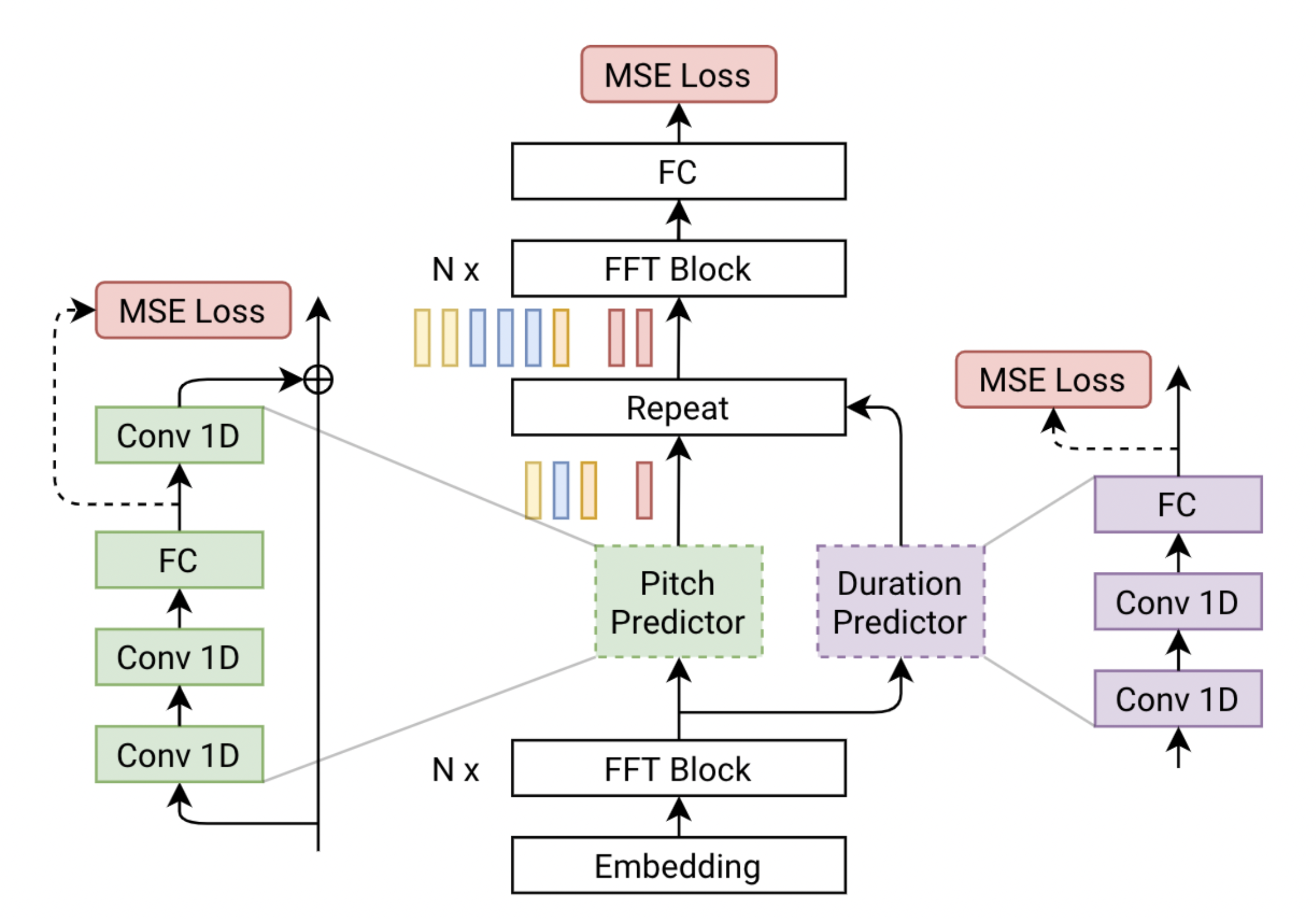
FastPitch 是一个基于 FastSpeech 的全并行文本到语音合成模型,以基频轮廓为条件。该模型在推理期间预测音高轮廓。通过改变这些预测,生成的语音可以更具表现力,更好地匹配话语的语义,最终更能吸引听众。使用 FastPitch 均匀地增加或减少音高会生成类似于自愿调节声音的语音。以频率轮廓为条件可以提高合成语音的整体质量,使其与最先进水平相当。它不会引入开销,并且 FastPitch 保留了有利的全并行 Transformer 架构,梅尔频谱合成典型话语的实时因子超过 900 倍。FastPitch 的架构如下所示。它基于 FastSpeech,由两个前馈 Transformer (FFTr) 堆栈组成。第一个 FFTr 在输入标记的分辨率下运行,另一个在输出帧的分辨率下运行。详情请参考[TTS-MODELS12]。
Mixer-TTS/Mixer-TTS-X#
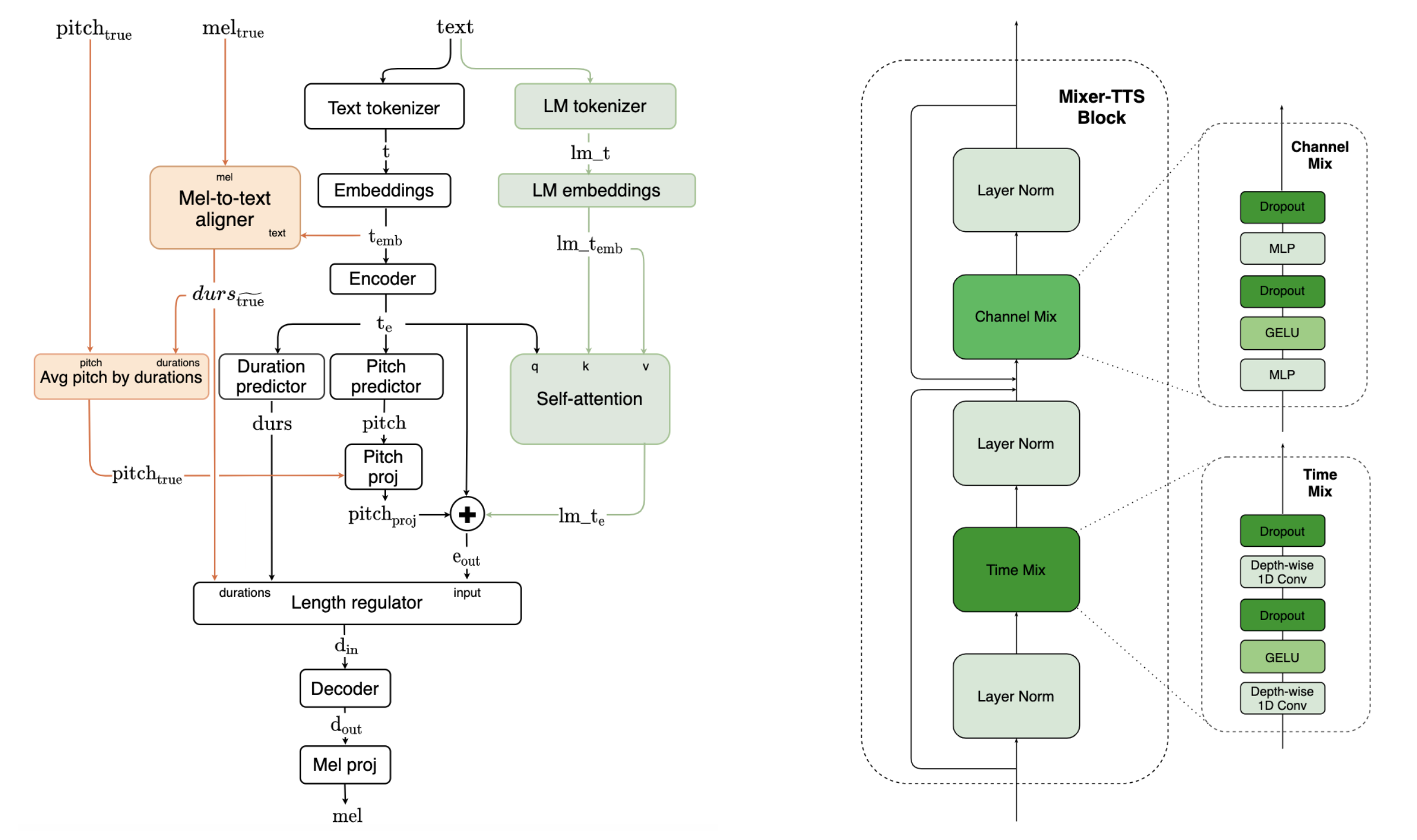
Mixer-TTS 是一个用于梅尔频谱生成的非自回归模型。该模型基于为语音合成而调整的 MLP-Mixer 架构。基本的 Mixer-TTS 包含音高和时长预测器,后者使用监督式 TTS 对齐框架进行训练。除了基本模型外,我们还提出了扩展版本 Mixer-TTS-X,它还额外使用了来自预训练语言模型的标记嵌入。与质量相似的模型相比,基本的 Mixer-TTS 及其扩展版本具有少量参数,并且能够实现更快的语音合成。基本 Mixer-TTS 的模型架构如下所示(左)。基本的 Mixer-TTS 使用与 FastPitch 相同的时长和音高预测器架构,但它有两个主要变化。它将编码器和解码器中所有基于前馈 Transformer 的块替换为新的 Mixer-TTS 块(右);它使用无监督的语音到文本对齐框架来训练时长预测器。详情请参考[TTS-MODELS10]。
RAD-TTS#
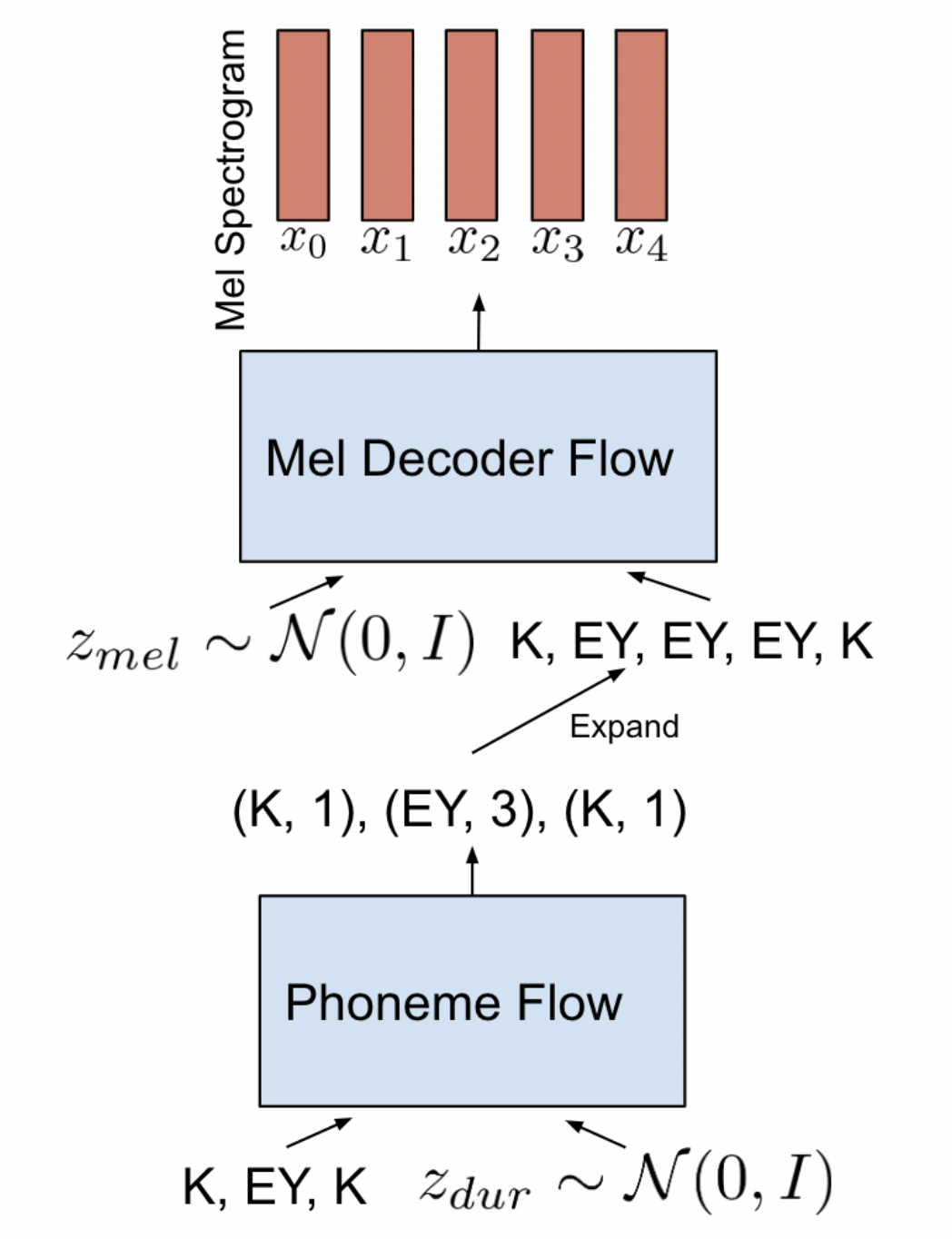
RAD-TTS 引入了一种主要并行、基于归一化流的端到端 TTS 模型。它通过额外将语音节奏建模为单独的生成分布来扩展先前的并行方法,以方便推理期间的可变标记时长。RAD-TTS 进一步设计了一个用于在线提取语音文本对齐的稳健框架,这在端到端 TTS 框架中是一个关键但高度不稳定的学习问题。总体而言,与受控基线相比,RAD-TTS 产生了改进的对齐质量和更好的输出多样性。以下图表总结了 RAD-TTS 的推理流程。时长归一化流首先对音素时长进行采样,然后将其用于准备并行 Mel-Decoder 流的输入。详情请参考[TTS-MODELS9]。
Tacotron2#
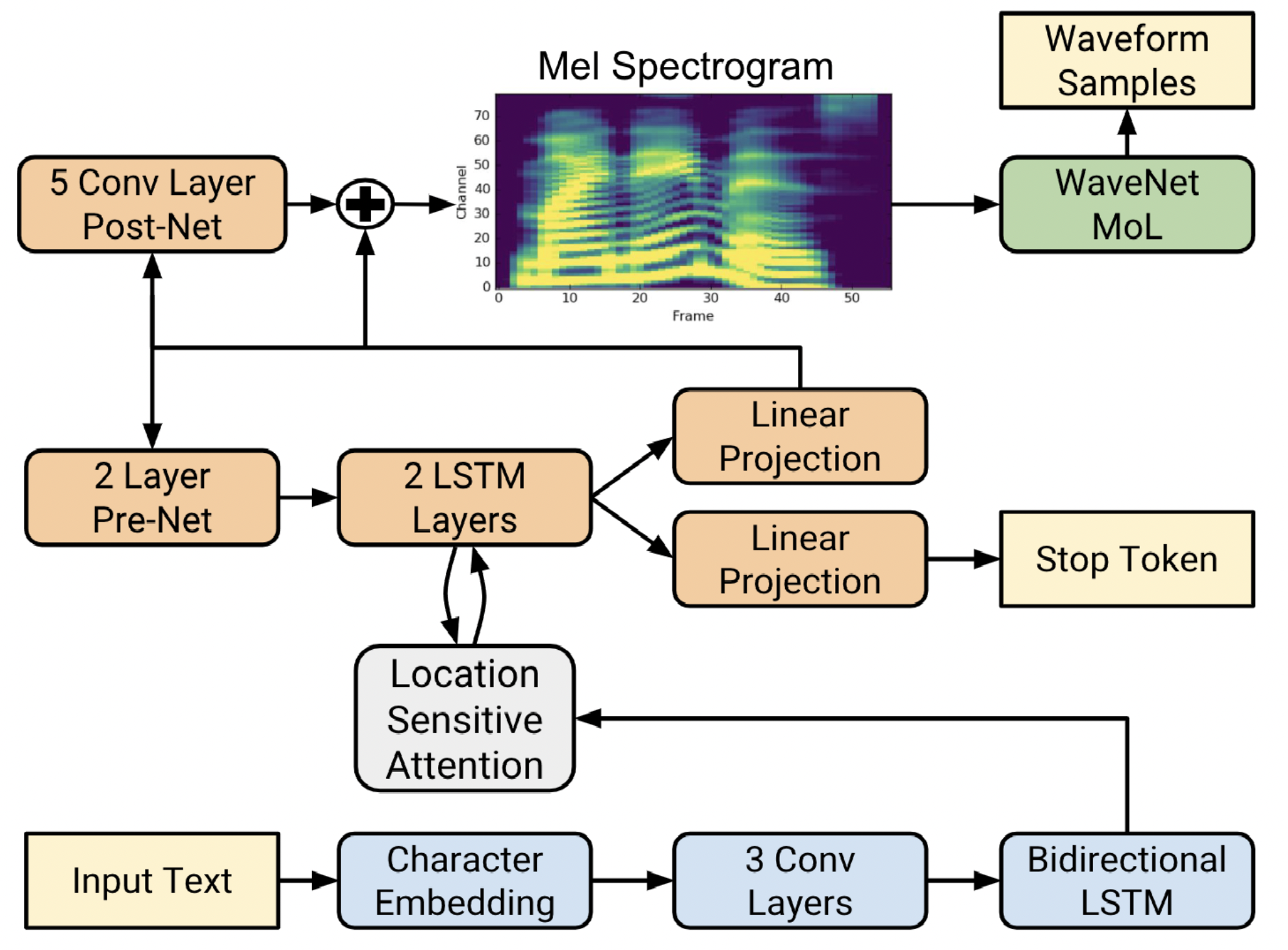
Tacotron 2 由一个循环序列到序列的特征预测网络组成,该网络具有注意力机制,可将字符嵌入映射到梅尔频谱帧,以及 WaveNet 的修改版本作为声码器,可生成以预测的梅尔频谱帧为条件的时域波形样本。该系统使用梅尔频谱作为 WaveNet 的条件输入,而不是语言、时长和 F0 特征,这表明 WaveNet 架构的大小显着减小。Tacotron 2 架构的框图如下所示。详情请参考[TTS-MODELS8]。
SSL FastPitch#
这个 实验性 版本的 FastPitch 接收由 SSL Disentangler 生成的内容和说话人嵌入,并生成梅尔频谱,目标是从说话人嵌入中获取声音特征,而语音内容由内容嵌入确定。可以通过将说话人嵌入输入交换为目标说话人的输入,同时保持内容嵌入不变,使用此模型完成语音转换。更多详情即将推出。
声码器#
HiFiGAN#
HiFi-GAN 专注于设计一种声码器模型,该模型可以有效地从中级梅尔频谱合成原始波形音频。它由一个生成器和两个判别器(多尺度和多周期)组成。生成器和判别器通过对抗方式进行训练,并具有两个额外的损失,以提高训练稳定性和模型性能。生成器是一个完全卷积神经网络,它以梅尔频谱作为输入,并通过转置卷积对其进行上采样,直到输出序列的长度与原始波形的时间分辨率匹配。每个转置卷积之后都跟随一个多感受野融合 (MRF) 模块。生成器的架构如下所示(左)。多周期判别器 (MPD) 是子判别器的混合器,每个子判别器仅接受输入音频的等间距样本。子判别器旨在通过查看输入音频的不同部分来捕获彼此之间不同的隐式结构。虽然 MPD 仅接受不相交的样本,但添加了多尺度判别器 (MSD) 以连续评估音频序列。MSD 是在不同输入尺度(原始音频、x2 平均池化音频和 x4 平均池化音频)上运行的 3 个子判别器的混合器。与 WaveNet 和 WaveGlow 等最佳公开可用的自回归或基于流的模型相比,HiFi-GAN 可以实现更高的计算效率和样本质量。详情请参考[TTS-MODELS5]。

生成器
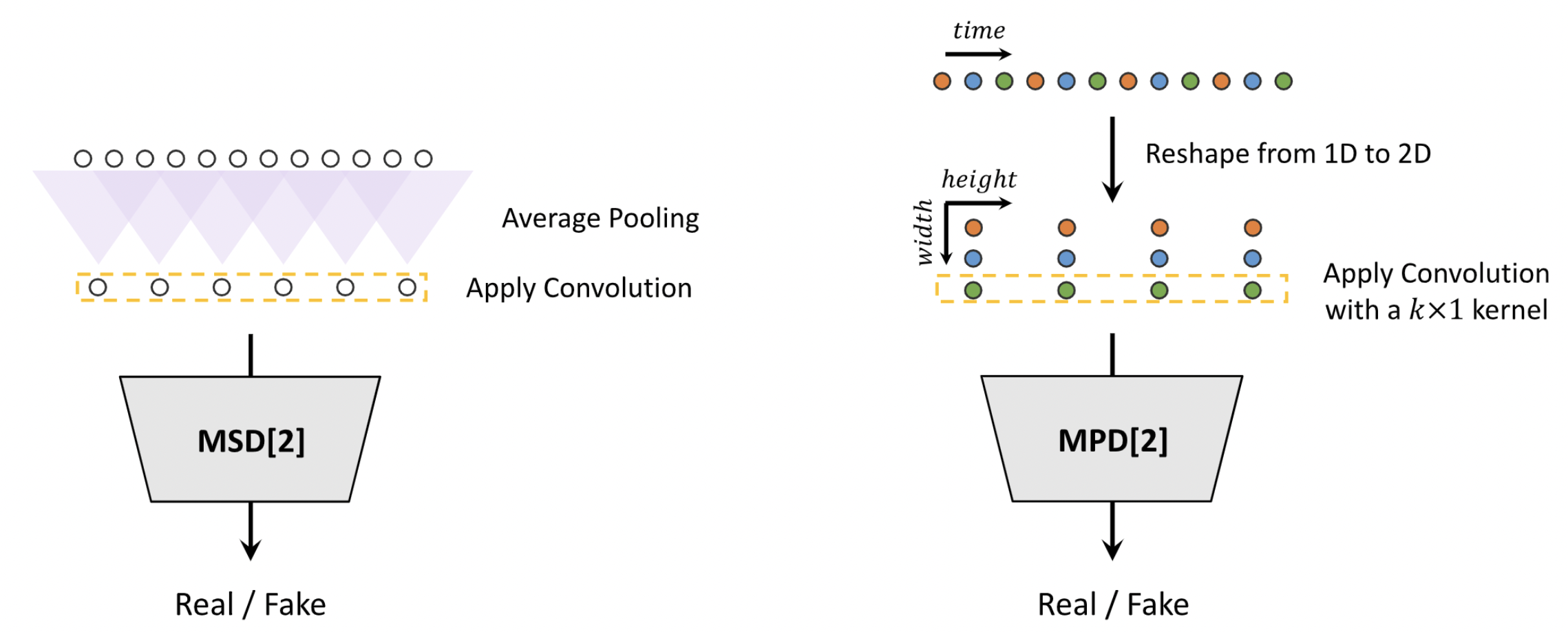
判别器
UnivNet#
UnivNet 是一种神经声码器,可以实时合成高保真波形。它由一个生成器和两个波形判别器(多周期和多分辨率)组成。生成器受 MelGAN 的启发,并添加了位置可变卷积 (LVC) 以有效地捕获对数梅尔频谱的局部信息。LVC 层的内核是使用内核预测器预测的,该预测器以对数梅尔频谱作为输入。生成器的架构如下所示(左)。多分辨率频谱判别器 (MRSD) 使用具有各种时间和频谱分辨率的多个线性频谱幅度,以便可以在全频带上生成高分辨率信号。添加了多周期波形判别器 (MPWD) 以改进时域中的详细对抗建模。判别器的架构如下所示(右)。详情请参考[TTS-MODELS3]。
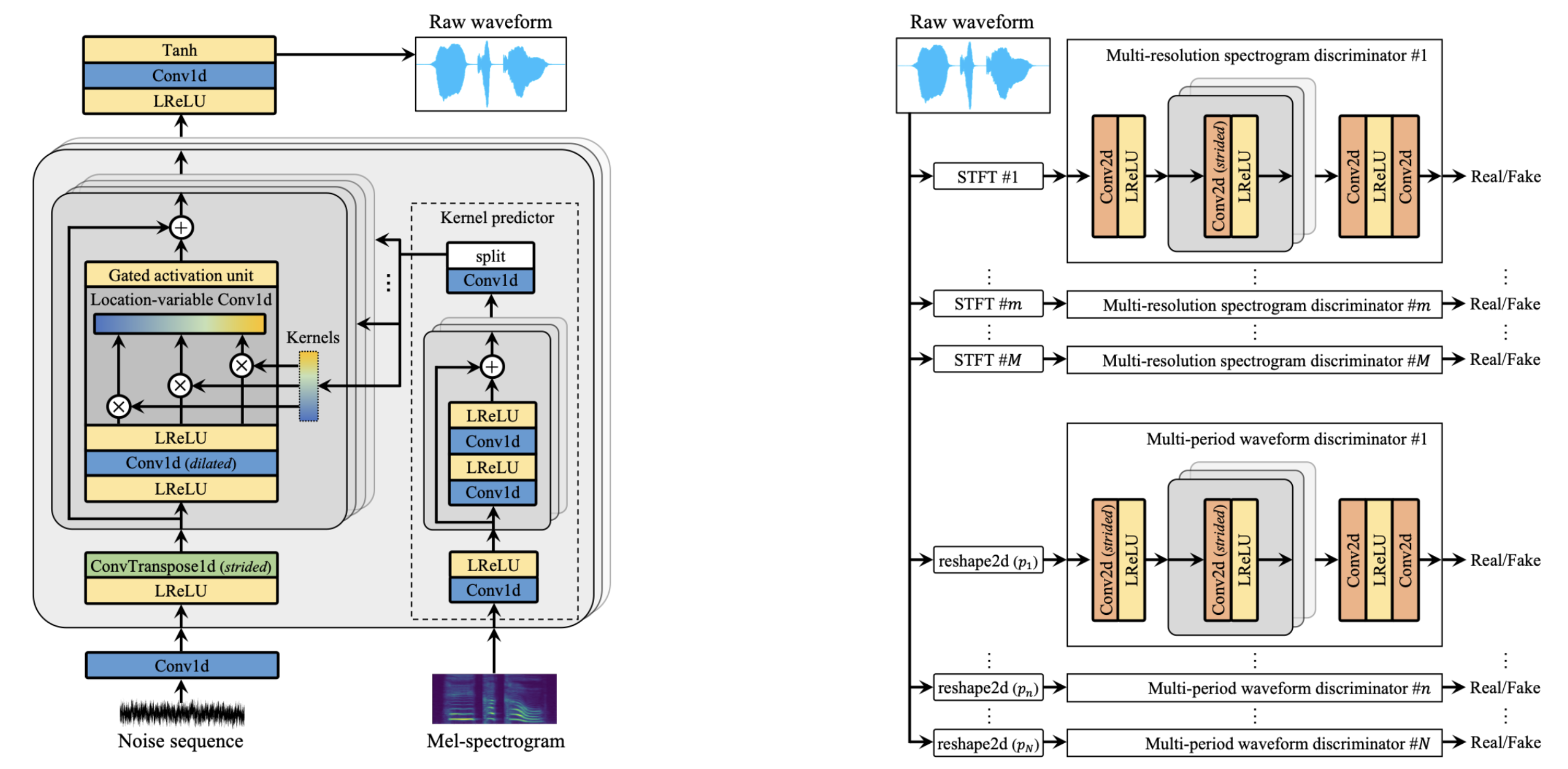
WaveGlow#
WaveGlow 结合了 Glow 和 WaveNet 的见解,可在无需自回归的情况下提供快速、高效和高质量的音频合成。WaveGlow 仅使用单个网络实现,仅使用单个成本函数进行训练,即最大化训练数据的可能性,这使得训练过程简单而稳定。尽管模型很简单,但我们的 Pytorch 实现可以在 NVIDIA V100 GPU 上以超过 500kHz 的频率合成语音,并且其音频质量与在相同数据上训练的最佳公开可用的 WaveNet 实现一样好。模型网络与最近的 Glow 工作最相似,如下所示。对于通过网络的前向传递,我们将 8 个音频样本组作为向量,这称为“挤压”操作。然后,我们通过几个“流动步骤”处理这些向量,每个步骤都由一个可逆的 1x1 卷积以及随后的仿射耦合层组成。详情请参考[TTS-MODELS7]。

语音到文本对齐器#
RAD-TTS 对齐器#
语音到文本对齐是神经 TTS 模型的关键组成部分。自回归 TTS 模型通常使用注意力机制来在线学习这些对齐。然而,这些对齐往往很脆弱,并且常常无法推广到长话语和域外文本,从而导致单词丢失或重复。大多数非自回归端到端 TTS 模型依赖于从外部来源提取的时长。RAD-TTS 对齐器利用 RAD-TTS 中提出的对齐机制,并证明其适用于各种神经 TTS 模型。对齐学习框架结合了前向求和算法、Viterbi 算法和高效的静态先验。RAD-TTS 对齐器可以改进所有经过测试的 TTS 架构,包括自回归(Flowtron、Tacotron 2)和非自回归(FastPitch、FastSpeech 2、RAD-TTS)。具体来说,它可以提高对齐收敛速度,通过消除对外部对齐器的需求来简化训练流程,增强对长话语错误的鲁棒性,并提高人类评估者判断的感知语音合成质量。对齐框架如下所示。详情请参考[TTS-MODELS1]。
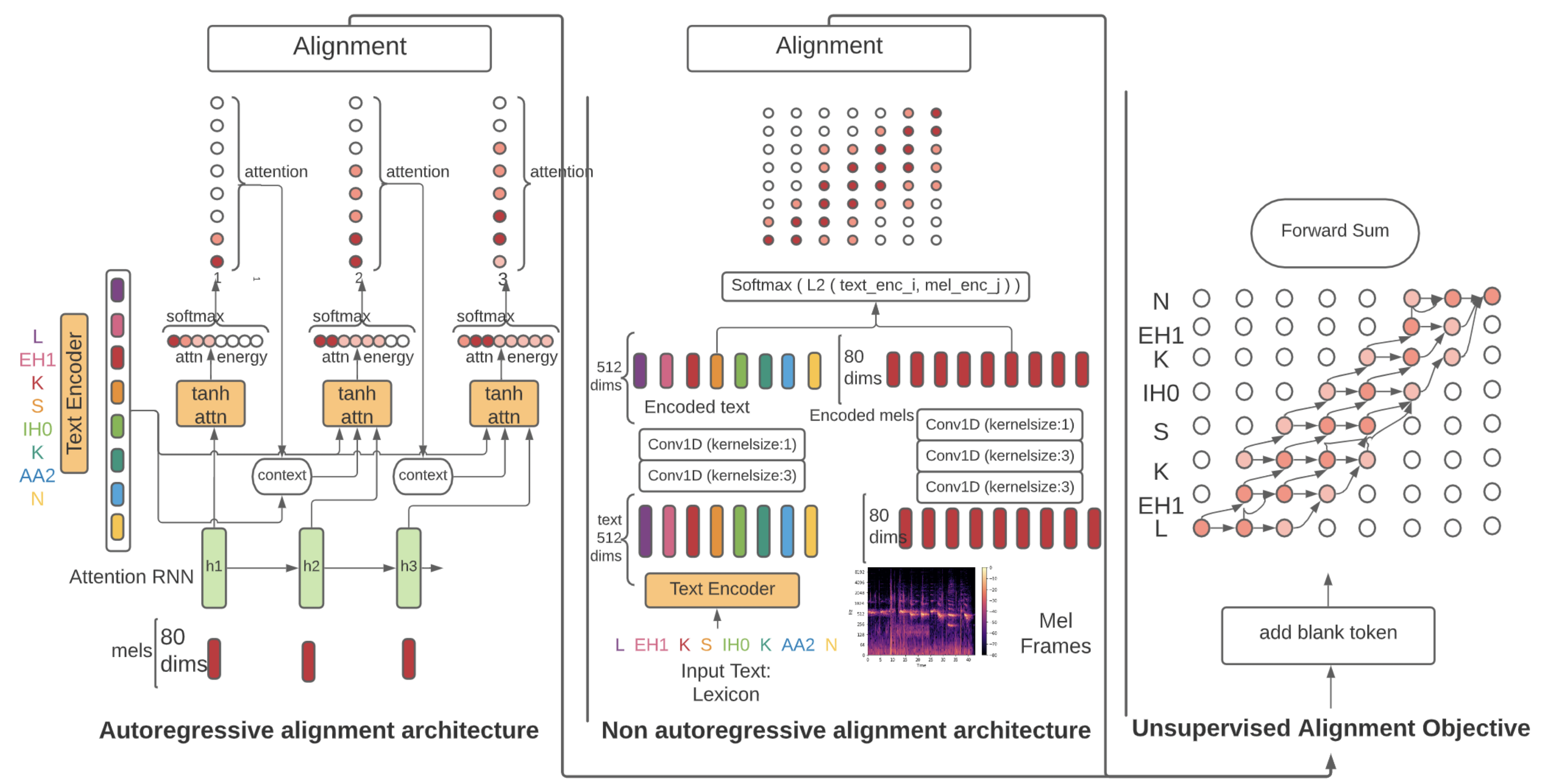
端到端模型#
VITS#
VITS 是一种端到端语音合成模型,可从字素/音素输入生成原始波形音频。它使用变分自编码器将类似 GlowTTS 的频谱生成器与 HiFi-GAN 声码器模型相结合。此外,它还具有单独的基于流的时长预测器,该预测器从噪声中采样对齐,并以文本为条件。详情请参考[TTS-MODELS4]。该模型仍处于实验阶段,因此我们不保证干净运行。
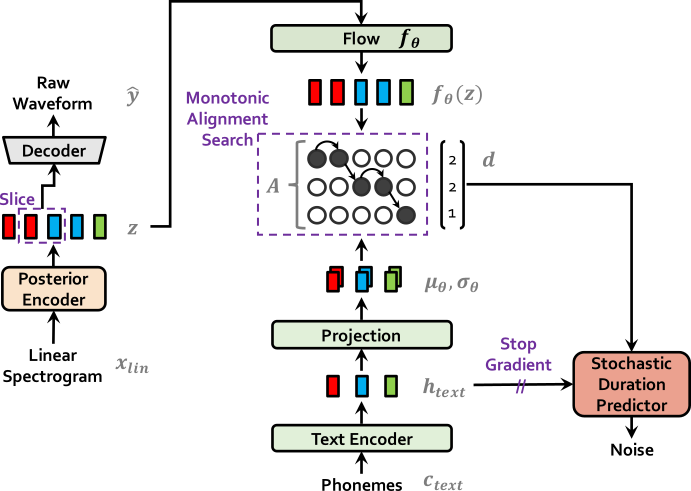
增强器#
频谱增强器#
基于 GAN 的模型,用于将细节添加到来自 Tacotron 或 FastPitch 等 TTS 模型的模糊频谱图中。
编解码器#
音频编解码器#
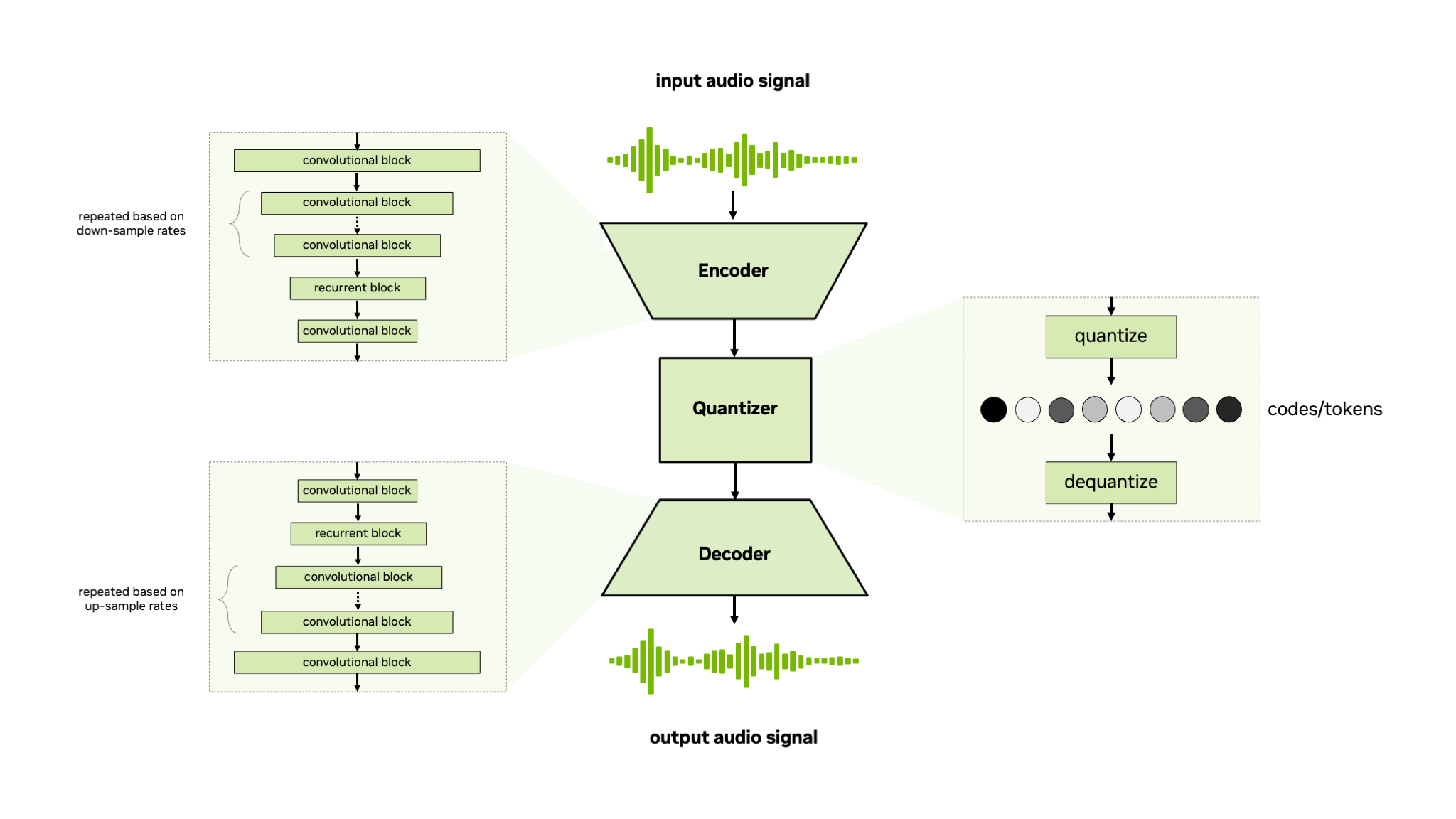
NeMo 音频编解码器模型是一个非自回归卷积编码器-量化器-解码器模型,用于编码或标记化原始音频信号或梅尔频谱特征。NeMo 音频编解码器模型支持残差向量量化器 (RVQ) [TTS-MODELS11] 和有限标量量化器 (FSQ) [TTS-MODELS6],用于量化编码器输出。该模型使用生成损失、判别损失和重建损失进行端到端训练,类似于其他神经音频编解码器,例如 SoundStream [TTS-MODELS11] 和 EnCodec [TTS-MODELS2]。有关更多信息,请参阅 TTS 教程部分中的 Audio Codec Training 教程。
参考文献#
Rohan Badlani、Adrian Łańcucki、Kevin J Shih、Rafael Valle、Wei Ping 和 Bryan Catanzaro。《One TTS alignment to rule them all》。在 ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP),6092–6096 页。IEEE,2022 年。
Alexandre Défossez、Jade Copet、Gabriel Synnaeve 和 Yossi Adi。《High fidelity neural audio compression》。arXiv preprint arXiv:2210.13438,2022 年。
Won Jang、Dan Lim、Jaesam Yoon、Bongwan Kim 和 Juntae Kim。《UnivNet: A Neural Vocoder with Multi-Resolution Spectrogram Discriminators for High-Fidelity Waveform Generation》。在 Proc. Interspeech 2021,2207–2211 页。2021 年。doi:10.21437/Interspeech.2021-1016。
Jaehyeon Kim、Jungil Kong 和 Juhee Son。《Conditional variational autoencoder with adversarial learning for end-to-end text-to-speech》。在 International Conference on Machine Learning,5530–5540 页。PMLR,2021 年。
Jungil Kong、Jaehyeon Kim 和 Jaekyoung Bae。《HiFi-GAN: generative adversarial networks for efficient and high fidelity speech synthesis》。Advances in Neural Information Processing Systems,33:17022–17033,2020 年。
Fabian Mentzer、David Minnen、Eirikur Agustsson 和 Michael Tschannen。《Finite scalar quantization: VQ-VAE made simple》。arXiv preprint arXiv:2309.15505,2023 年。
Ryan Prenger、Rafael Valle 和 Bryan Catanzaro。《Waveglow: a flow-based generative network for speech synthesis》。在 ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP),3617–3621 页。IEEE,2019 年。
Jonathan Shen、Ruoming Pang、Ron J Weiss、Mike Schuster、Navdeep Jaitly、Zongheng Yang、Zhifeng Chen、Yu Zhang、Yuxuan Wang、Rj Skerrv-Ryan 等人。《Natural tts synthesis by conditioning wavenet on mel spectrogram predictions》。在 2018 IEEE international conference on acoustics, speech and signal processing (ICASSP),4779–4783 页。IEEE,2018 年。
Kevin J Shih、Rafael Valle、Rohan Badlani、Adrian Lancucki、Wei Ping 和 Bryan Catanzaro。《RAD-TTS: parallel flow-based TTS with robust alignment learning and diverse synthesis》。在 ICML Workshop on Invertible Neural Networks, Normalizing Flows, and Explicit Likelihood Models。2021 年。
Oktai Tatanov、Stanislav Beliaev 和 Boris Ginsburg。《Mixer-TTS: non-autoregressive, fast and compact text-to-speech model conditioned on language model embeddings》。在 ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP),7482–7486 页。IEEE,2022 年。
Neil Zeghidour、Alejandro Luebs、Ahmed Omran、Jan Skoglund 和 Marco Tagliasacchi。《SoundStream: an end-to-end neural audio codec》。IEEE/ACM Transactions on Audio, Speech, and Language Processing,30:495–507,2022 年。doi:10.1109/TASLP.2021.3129994。
Adrian Łańcucki。《Fastpitch: parallel text-to-speech with pitch prediction》。在 ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP),6588–6592 页。IEEE,2021 年。