重要提示
您正在查看 NeMo 2.0 文档。此版本引入了 API 的重大更改和一个新的库 NeMo Run。我们目前正在将 NeMo 1.0 的所有功能移植到 2.0。有关先前版本或 2.0 中尚不可用的功能的文档,请参阅 NeMo 24.07 文档。
语音数据探索器#
语音数据探索器 (SDE) 是一个基于 Dash 的 Web 应用程序,用于交互式探索和分析语音数据集。
SDE 功能 |
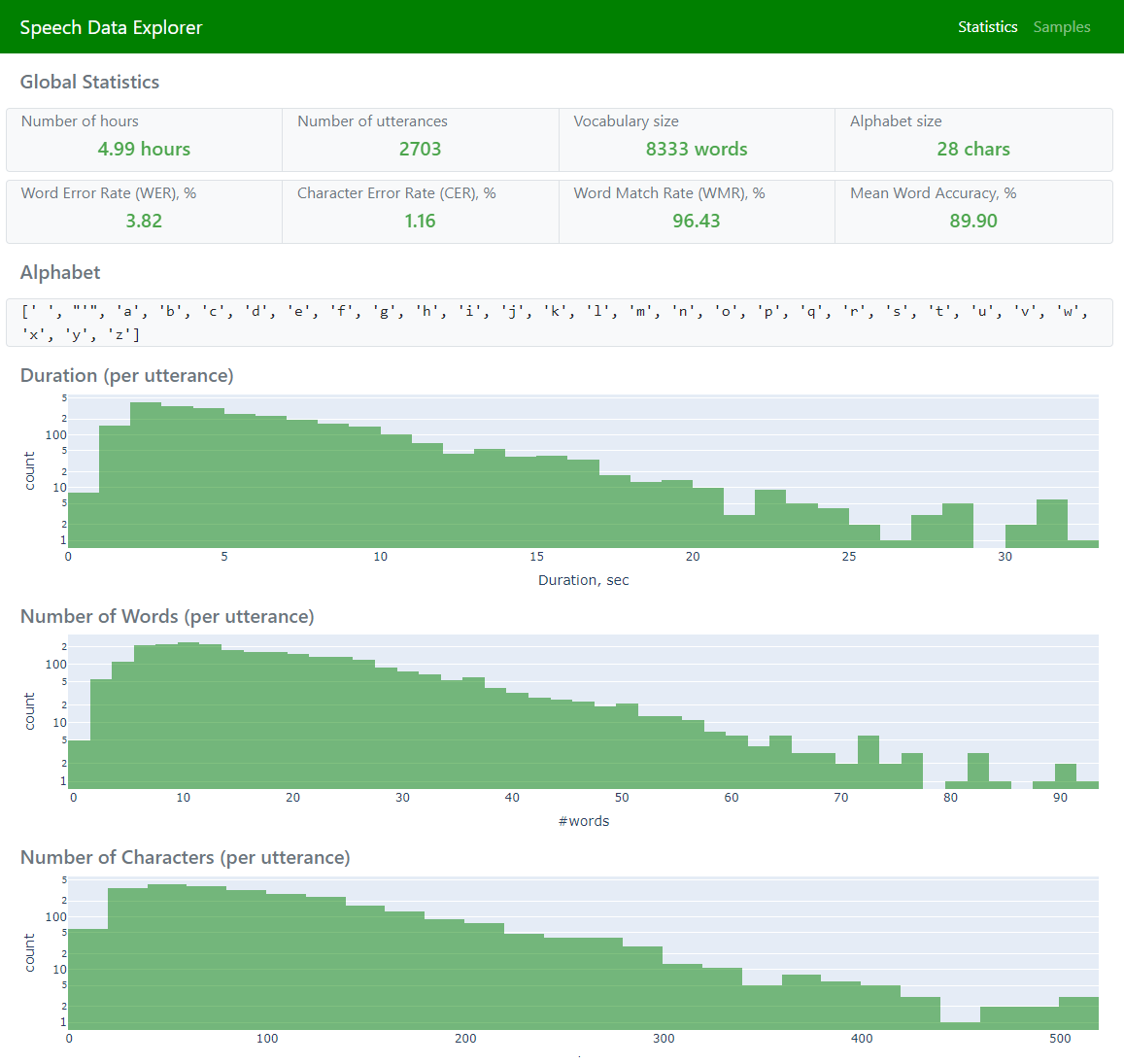
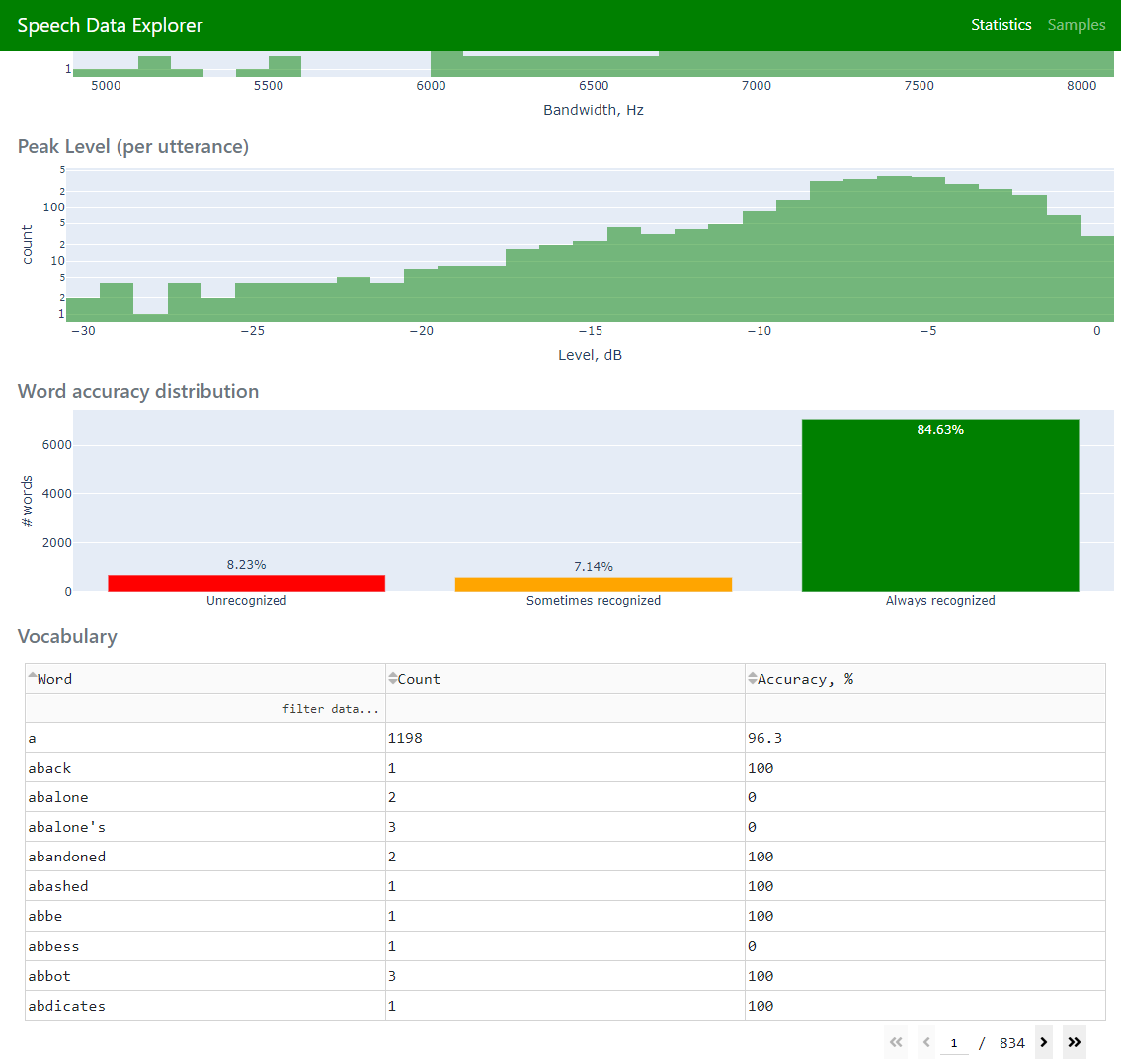
全局数据集统计信息 [字母表、词汇表、基于持续时间的直方图、小时数、话语数等] |
使用交互式数据表在数据集中导航,该表支持排序和筛选 |
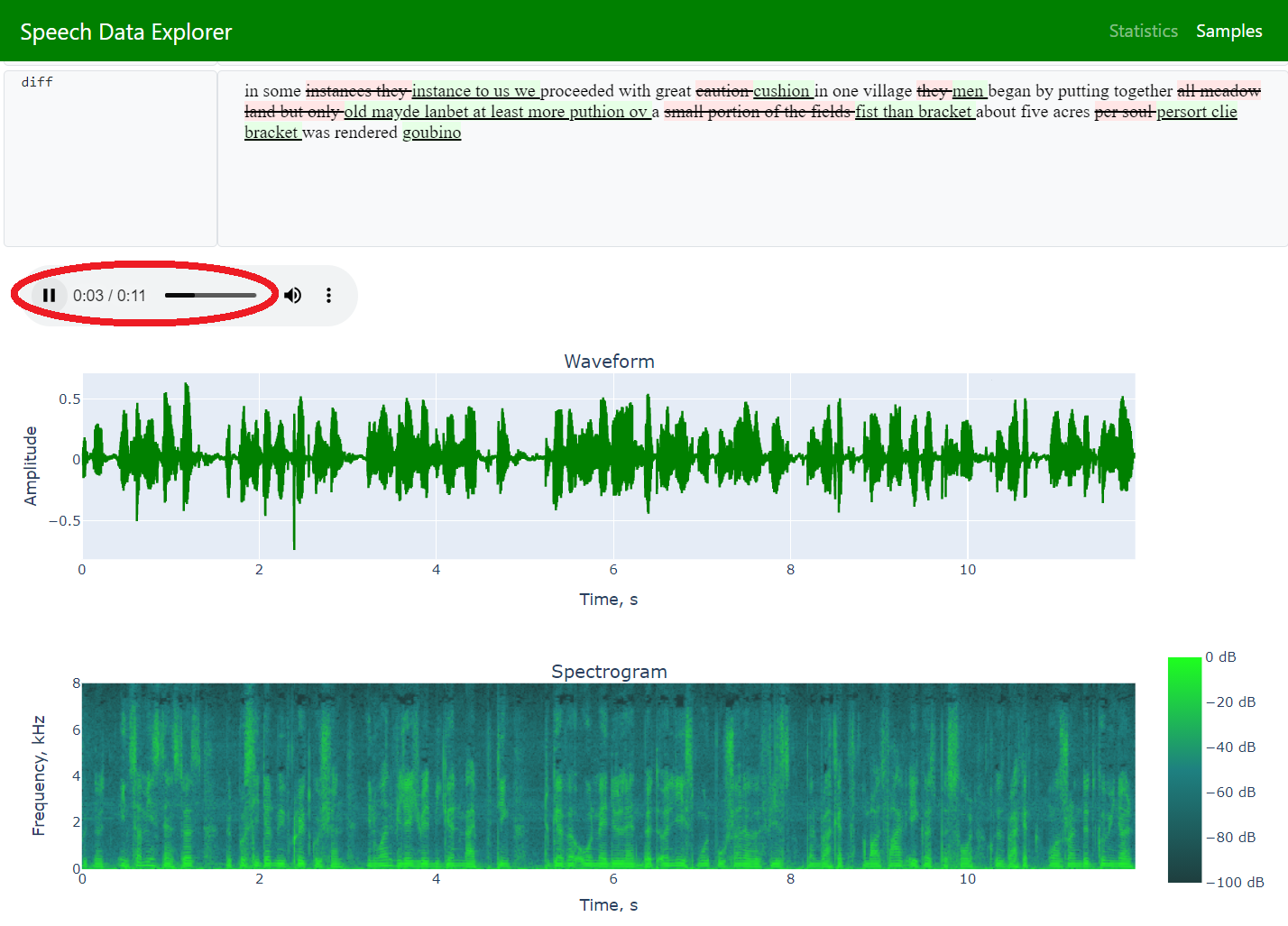
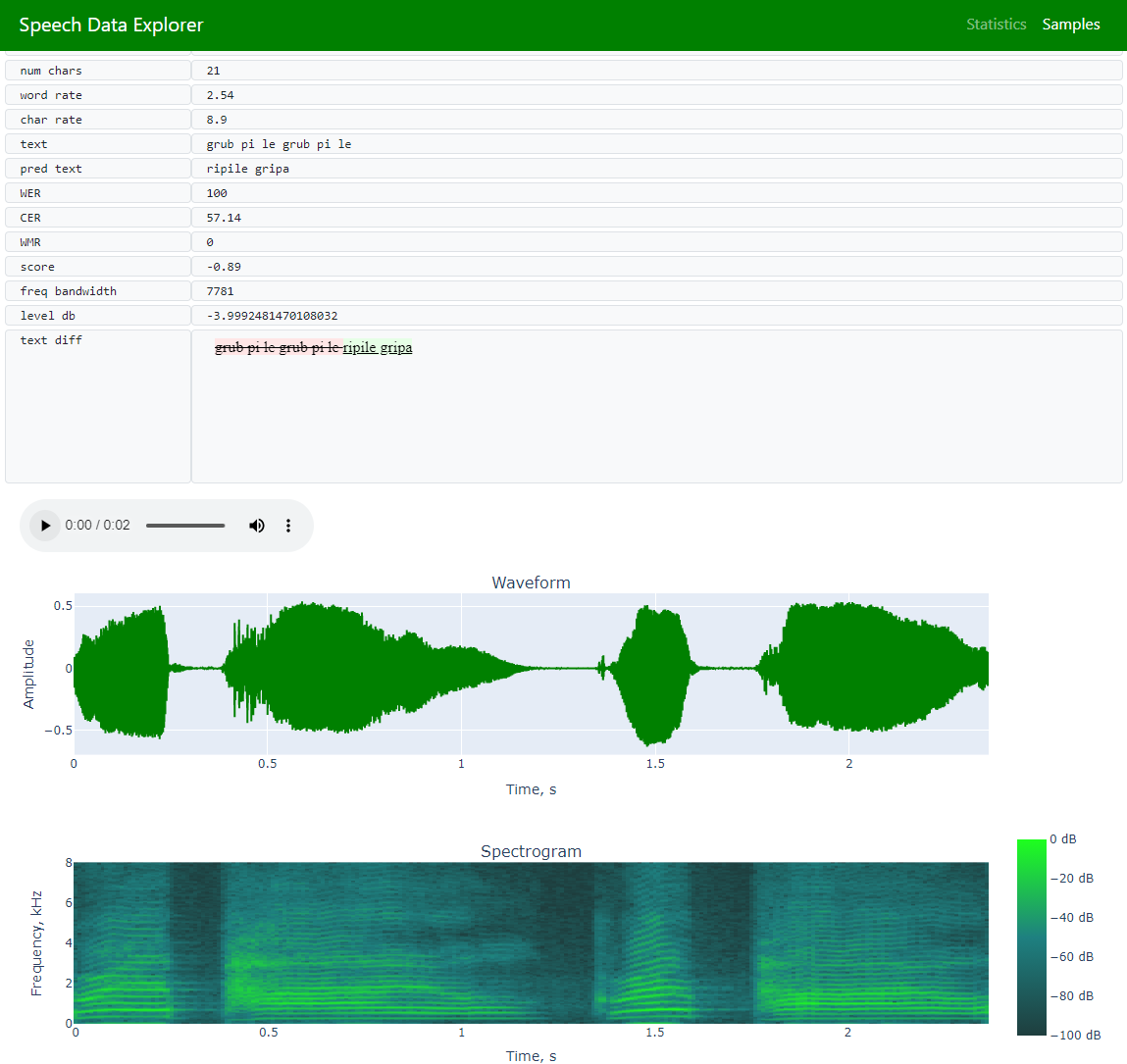
检查单个话语 [绘制波形、频谱图、自定义属性和播放音频] |
错误分析 [词错误率 (WER)、字符错误率 (CER)、词匹配率 (WMR)、词准确率、突出显示参考文本和 ASR 模型预测之间的差异] |
音频信号参数估计 [峰值电平、频率带宽] |
入门指南#
SDE 可以在 NeMo/tools/speech_data_explorer 中找到。
请安装 SDE 要求
pip install -r tools/speech_data_explorer/requirements.txt
然后运行
python tools/speech_data_explorer/data_explorer.py -h
usage: data_explorer.py [-h] [--vocab VOCAB] [--port PORT] [--disable-caching-metrics] [--estimate-audio-metrics] [--debug] manifest
Speech Data Explorer
positional arguments:
manifest path to JSON manifest file
optional arguments:
-h, --help show this help message and exit
--vocab VOCAB optional vocabulary to highlight OOV words
--port PORT serving port for establishing connection
--disable-caching-metrics
disable caching metrics for errors analysis
--estimate-audio-metrics, -a
estimate frequency bandwidth and signal level of audio recordings
--debug, -d enable debug mode
SDE 将 JSON 清单文件(描述 NeMo 中的语音数据集)作为输入。它应包含以下字段
audio_filepath(音频文件路径)
duration(音频文件的持续时间,以秒为单位)
text(参考文本)
SDE 支持 JSON 清单中的任何额外自定义字段。如果字段是数字,则 SDE 可以可视化其在话语中的分布。
如果 JSON 清单具有属性 pred_text,则 SDE 将其解释为预测的 ASR 文本记录并计算错误分析指标。命令行选项 --estimate-audio-metrics 允许 SDE 估计每个话语的信号峰值电平和频率带宽。默认情况下,SDE 将所有计算的指标缓存到 pickle 文件。可以使用 --disable-caching-metrics 选项禁用缓存。
用户界面#
SDE 应用程序有两个页面
统计信息(显示全局统计信息和聚合错误指标)
样本(允许在整个数据集中导航和探索单个话语)
Plotly Dash 数据表提供了 SDE 核心的交互功能(导航、筛选和排序)。SDE 有两个数据表
词汇表(在 统计信息 页面上显示来自数据集参考文本的所有单词)
数据(在 样本 页面上可视化所有数据集的话语)
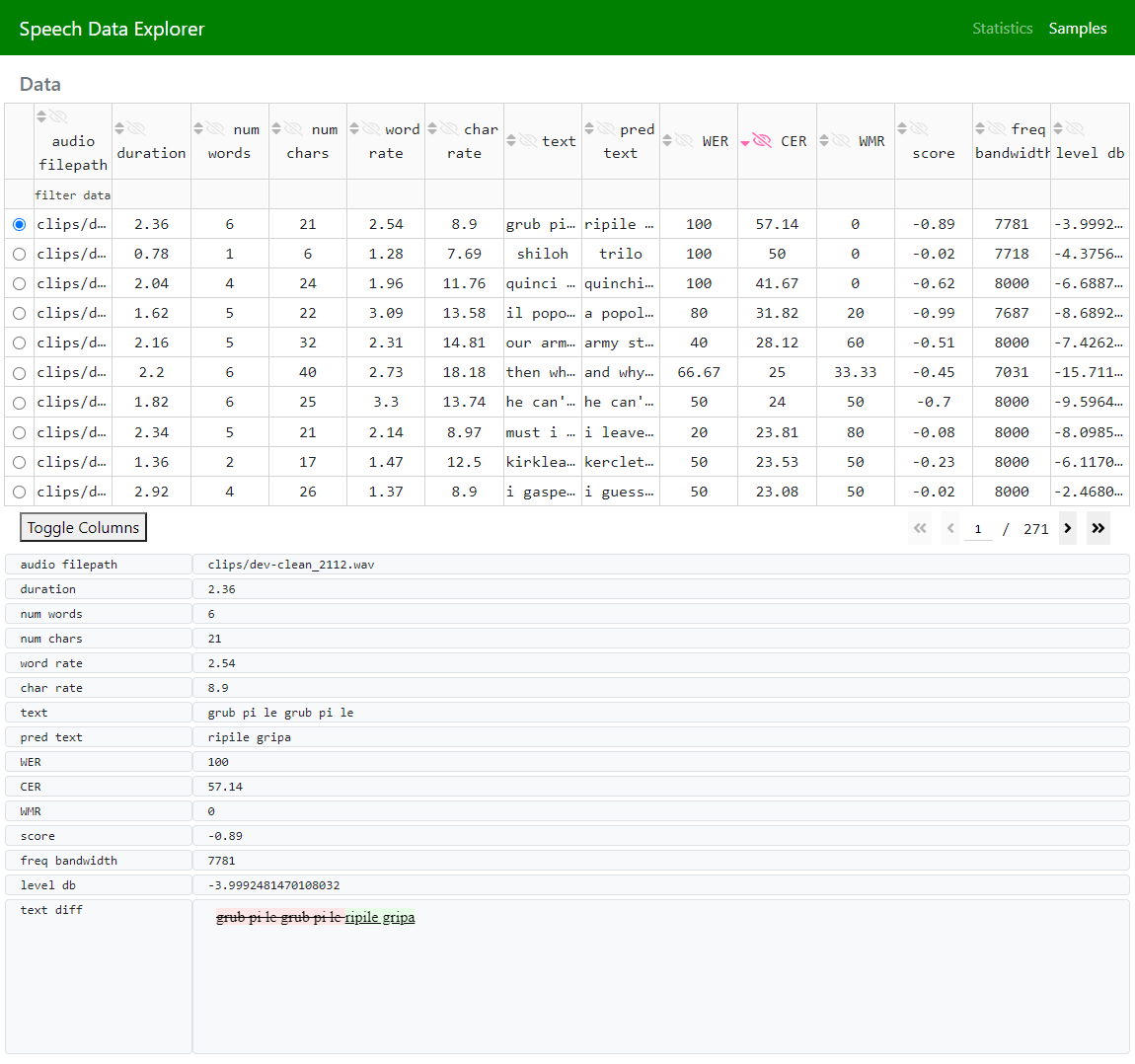
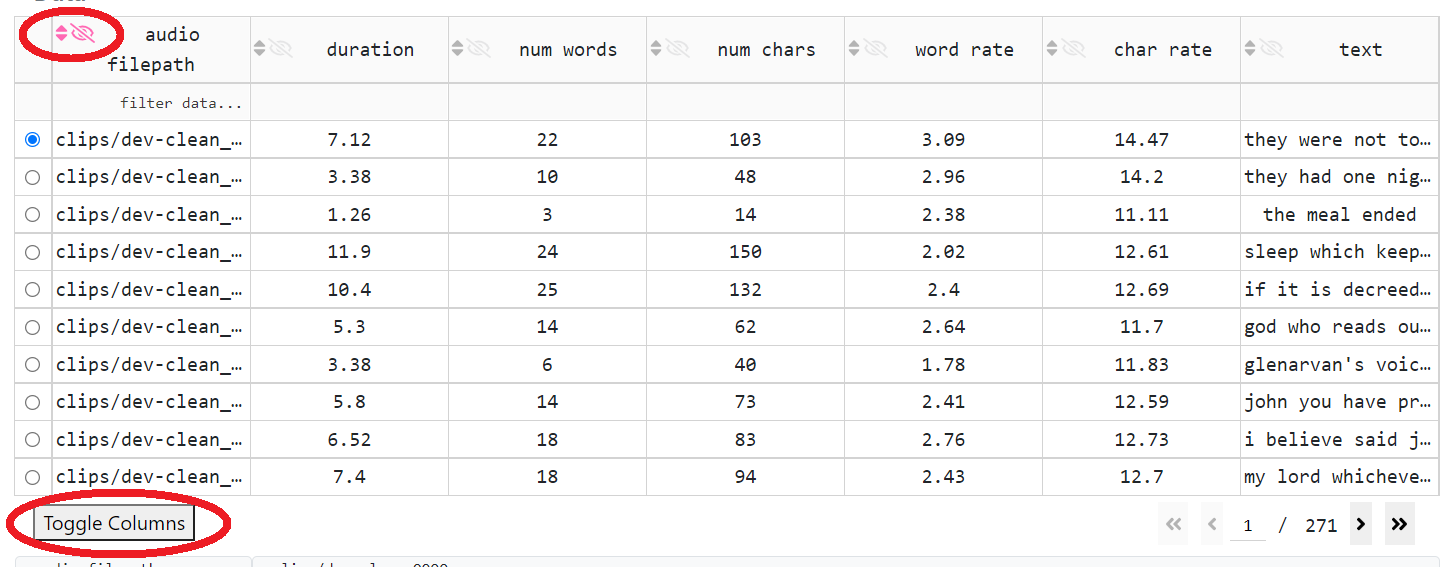
DataTable 的每一列都具有以下交互功能
关闭(通过单击列标题单元格中的 眼睛 图标)或打开(通过单击表格下方的 切换列 按钮)
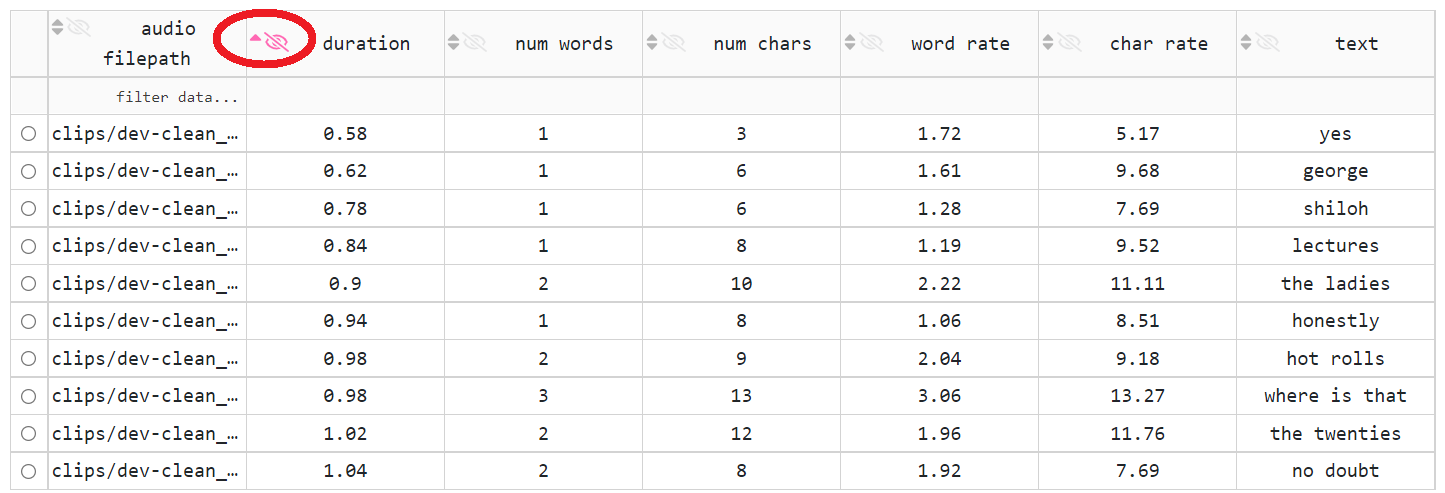
排序(通过单击列标题单元格中的小三角形图标):无序(两个三角形指向上和下)、升序(一个三角形指向上)、降序(一个三角形指向下)
筛选(通过在标题单元格下方的单元格中输入筛选表达式):SDE 支持
<、>、<=、>=、=、!=和contains运算符;要匹配特定子字符串,可以使用带引号的子字符串作为筛选表达式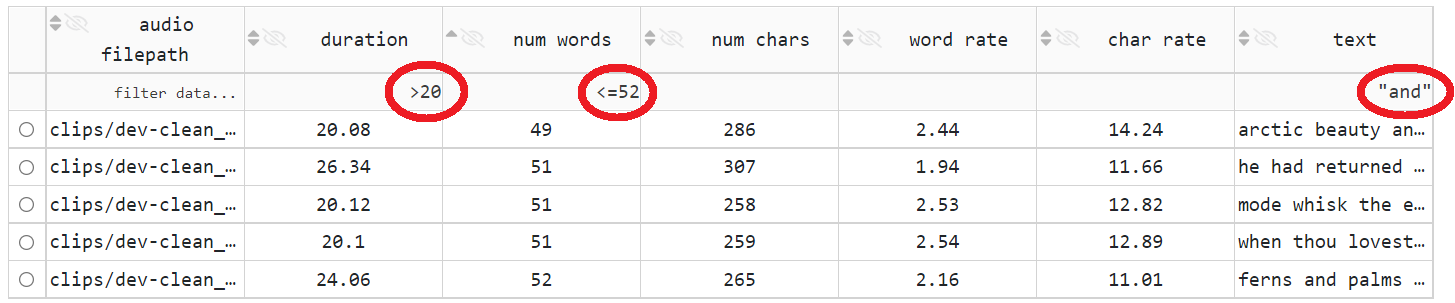
语音数据集分析#
在最简单的用例中,SDE 帮助以交互方式探索语音数据集并获取基本统计信息。如果没有可用的预训练 ASR 模型来获取预测的文本记录,仍然可以使用启发式规则来发现数据集中的潜在问题
检查数据集字母表(它应仅包含目标字符)
检查词汇表中是否有不常见的单词(例如,外来词、拼写错误)。SDE 可以使用
--vocab选项传递的外部词汇表文件。然后,可以轻松筛选出数据集中词汇表外的 (OOV) 单词,并按其出现次数(计数)对其进行排序。检查字符率高的话语。高字符率可能表明参考文本中的话语比相应的录音具有更多的单词。
如果有预训练的 ASR 模型,则可以使用 ASR 预测的文本记录扩展 JSON 清单文件
python examples/asr/transcribe_speech.py pretrained_name=<ASR_MODEL_NAME> dataset_manifest=<JSON_FILENAME>
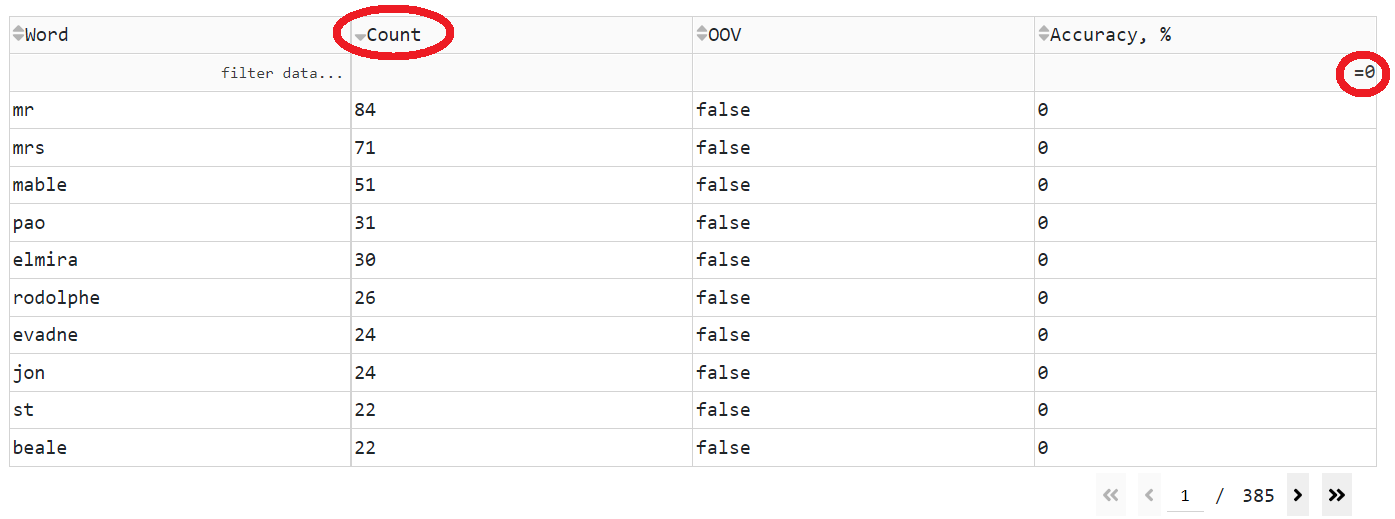
之后,值得检查准确率为零的单词。
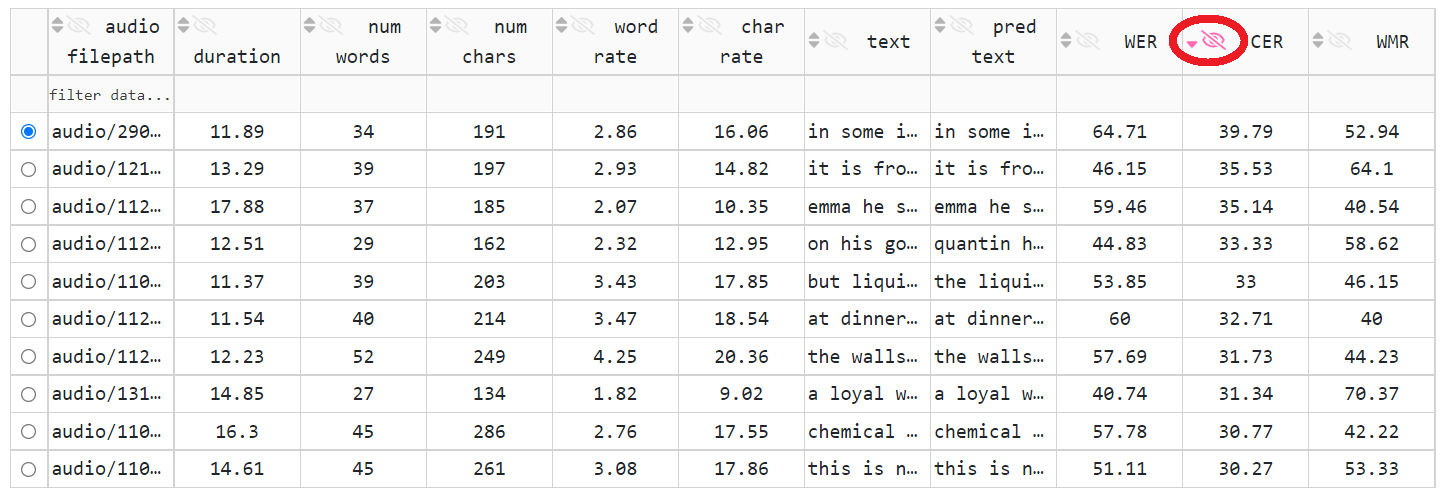
然后查看高 CER 话语。
收听录音有助于验证相应的参考文本记录。