重要提示
您正在查看 NeMo 2.0 文档。此版本对 API 和一个新库 NeMo Run 进行了重大更改。我们目前正在将所有功能从 NeMo 1.0 移植到 2.0。有关先前版本或 2.0 中尚不可用的功能的文档,请参阅 NeMo 24.07 文档。
Imagen#
模型介绍#
Imagen [MM-MODELS-IMAGEN4] 是一种多阶段文本到图像扩散模型,具有前所未有的照片级真实感和深层次的语言理解能力。给定一段文本提示,Imagen 首先生成 64x64 分辨率的图像,然后将生成的图像上采样到 256x256 和 1024x1024 分辨率,所有这些都使用扩散模型。
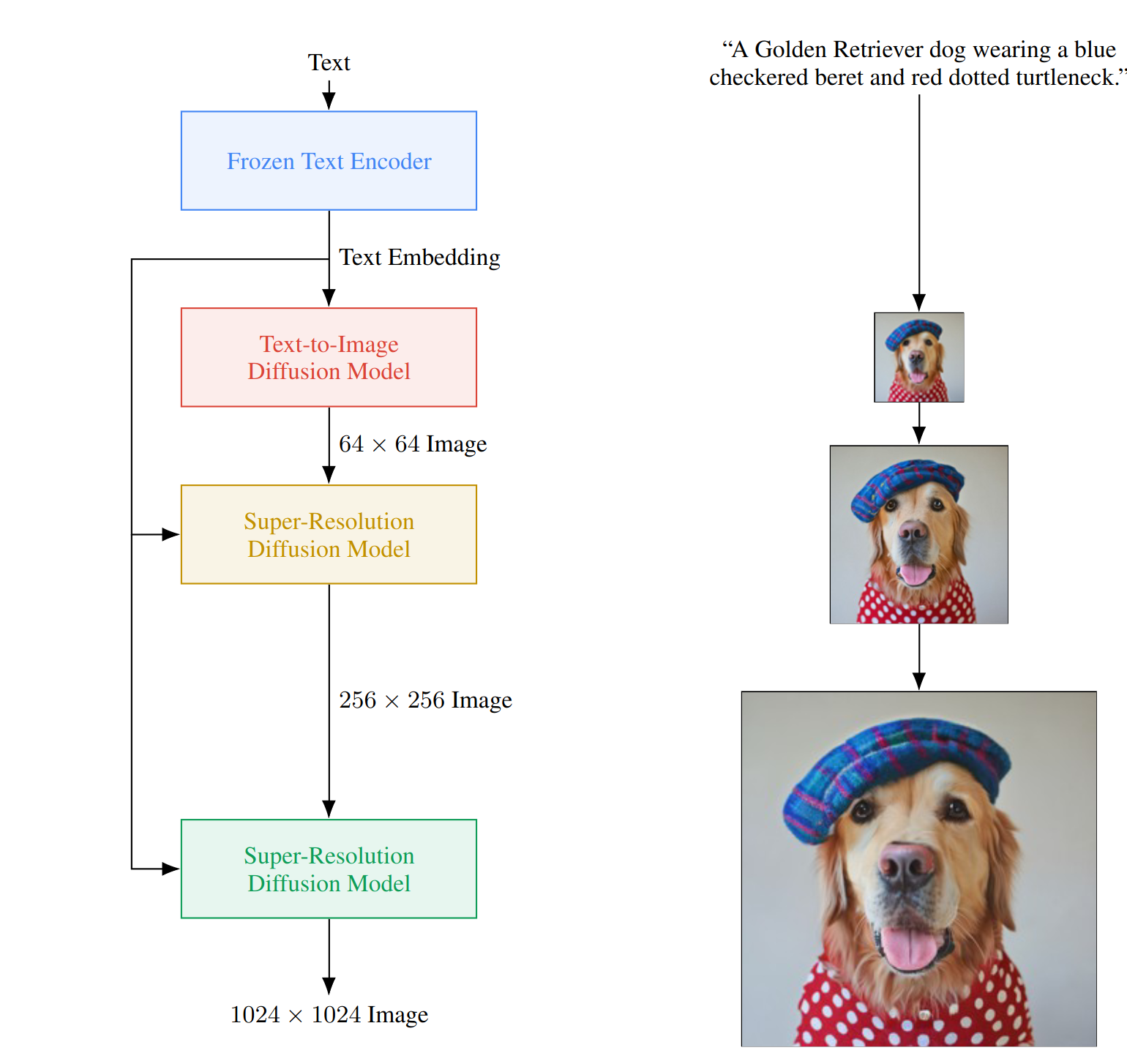
Imagen 模型可以使用 MegatronImagen 类进行实例化。
文本编码器#
Imagen 采用文本编码器(通常为 T5)来编码文本特征。为了提高效率,鉴于 T5 编码器的大小,我们强烈建议使用预缓存的嵌入来预处理训练数据集。在训练期间加载编码器可能会显著减少训练时间。
UNet#
Imagen 有两种类型的 UNet:常规 UNet 和 EfficientUNet。
常规 UNet#
常规 UNet 用于 Imagen base64 模型。您也可以将常规 UNet 用于 SR 模型(请参阅示例配置文件 sr256-400m-edm.yaml),但这通常会导致相同模型大小的训练期间占用更大的内存。
base64 和 SR256 模型的推荐 UNet 大小如下所示
模型 |
分辨率 |
隐藏大小 ( |
文本条件大小 ( |
UNet 大小 (M) |
|---|---|---|---|---|
500m_res_64 |
64x64 |
256 |
512 |
524 |
2b_res_64 |
64x64 |
512 |
2048 |
2100 |
400m_res_256 |
256x256 |
128 |
512 |
429 |
高效 UNet#
高效 UNet 基于常规 UNet,并进行了以下修改
通过为较低分辨率添加更多残差块,将模型参数从高分辨率块转移到低分辨率块
按 1/sqrt(2) 缩放跳跃连接
在卷积之前执行下采样操作,并在卷积之后执行上采样操作。
通过上述修改,高效 UNet 可以更快地收敛,并具有更高的内存效率。Imagen 论文指出,这种修改对收敛没有明显影响。然而,我们的经验结果表明,常规 UNet 产生略微更好的视觉质量。在指标方面,基于 FID-CLIP 评估,它们表现出相似的质量。
SR256 和 SR1024 模型的推荐高效 UNet 大小如下所示
模型 |
分辨率 |
隐藏大小 ( |
文本条件大小 ( |
注意力块 |
UNet 大小 (M) |
|---|---|---|---|---|---|
600m_res_256 |
256x256 |
128 |
512 |
融合注意力 |
646 |
400m_res_1024 |
1024x1024 |
128 |
512 |
交叉注意力 |
427 |
噪声调度 / 采样器#
NeMo Imagen 支持两种类型的噪声调度:连续 DDPM [MM-MODELS-IMAGEN3] 和 EDM [MM-MODELS-IMAGEN2]。
去噪扩散概率模型 (DDPM) [MM-MODELS-IMAGEN1] 代表了所有扩散模型中最广泛采用的噪声调度方法。连续 DDPM 对标准 DDPM 框架进行了一些修改,其中最显著的变化是从离散噪声空间过渡到连续空间。
“阐明基于扩散的生成模型的设计空间”(EDM) 提出了在训练期间增强噪声水平分布策略。它还确定了采样的最佳时间离散化,并为采样过程合并了更高阶的龙格-库塔方法。
模型配置#
文本编码器#
model:
conditioning:
embed_dim: 1024
token_length: 128
drop_rate: 0.1
precached_key: embeddings_t5_xxl
out_key: t5_text
embed_dim 表示编码后的文本特征维度。对于 T5,维度为 1024 或 4096。token_length 指定最大上下文长度。所有预缓存的文本特征都将被修剪或填充以匹配此指定的长度。drop_rate 定义了在训练期间随机丢弃文本段的速率。embeddings_t5_xxl 指定与数据集中预缓存的特征关联的键名。
当使用在线编码时
model:
conditioning:
online_encoding: True
encoder_path: ???
embed_dim: 1024
token_length: 128
drop_rate: 0.1
设置 online_encoding=True 并设置文本编码器路径 encoder_path。它将在训练期间加载文本编码器,以从数据集的原始文本生成文本嵌入。
常规 UNet#
unet_type: base
unet:
embed_dim: 256
image_size: 64
channels: 3
num_res_blocks: 3
channel_mult: [ 1, 2, 3, 4 ]
num_attn_heads: 4
per_head_channels: 64
cond_dim: 512
attention_type: fused
feature_pooling_type: attention
learned_sinu_pos_emb_dim: 0
attention_resolutions: [ 8, 16, 32 ]
dropout: False
use_null_token: False
init_conv_kernel_size: 3
gradient_checkpointing: False
scale_shift_norm: True
stable_attention: True
flash_attention: False
resblock_updown: False
resample_with_conv: True
要配置 UNet 模型,请将 unet_type 设置为 base 以用于常规 UNet 基础模型,或设置为 sr-unet 以用于超分辨率 (SR) 模型。embed_dim 参数表示每个 ResBlock 中的基本通道数。
在 UNet 架构的每个级别,num_res_blocks 定义了该级别的 ResBlock 数量,而 channel_mult 与 embed_dim 结合使用以确定不同级别的通道数。cond_dim 指定了条件投影的大小。
Imagen 支持两种时间嵌入方法:学习的时间位置嵌入或未学习的(固定的)。要使用未学习的嵌入,请将 learned_sinu_pos_emb_dim 设置为 0;对于学习的嵌入,请使用正数。
feature_pooling_type 参数指定池化方法,可以是 attention 或 mean。
如果您希望启用模型 dropout(请注意,这与条件中的文本 dropout 不同),请设置 dropout 参数。当 resblock_updown 设置为 False 时,表示使用 ResBlock 进行下采样和上采样,而不是 Torch 的不带可学习权重的 upsample 和 downsample 函数。如果 resblock_updown 为 False,则可以使用 resample_with_conv 来确定除了池化和卷积转置操作之外,是否还需要额外的卷积层。
高效 UNet#
unet_type: sr
unet:
embed_dim: 128
image_size: 256
channels: 3
channel_mult: [ 1, 2, 4, 8, 8 ]
num_attn_heads: 8
per_head_channels: 64
attention_type: stacked
atnn_enabled_at: [ 0, 0, 0, 1, 1 ]
feature_pooling_type: attention
stride: 2
num_resblocks: [ 2, 4, 8, 8, 8 ]
learned_sinu_pos_emb_dim: 0
use_null_token: False
init_conv_kernel_size: 3
gradient_checkpointing: False
scale_shift_norm: True
stable_attention: False
flash_attention: False
skip_connection_scaling: True
许多参数与常规 UNet 的参数保持一致。要配置高效 UNet SR 模型训练,您应将 unet_type 设置为 sr。当使用高效 UNet SR 模型时,可以将 num_resblocks 指定为列表,以定义每个级别的不同 ResBlock 数量。此外,您可以选择启用 skip_connection_scaling,这将缩放跳跃连接,如 Imagen 论文中所详述。
注意力块#
Imagen 的 UNet 结合了多个注意力块,以有效地处理文本嵌入。UNet 配置中的以下参数与这些注意力块有关
unet:
attention_type: stacked
attention_resolutions: [8, 16, 32]
stable_attention: False
flash_attention: False
NeMo Imagen 实现了以下 attention_type
self:多头自注意力块
cross:多头交叉注意力块。Imagen 论文将此实现用于 SR1024 模型。
stacked:注意力块,堆叠一个self注意力和cross注意力
fused:注意力块,融合一个self注意力和cross注意力。Imagen 论文将此实现用于 base64 和 SR256 模型。
可以通过指定 attention_resolutions 将注意力块集成到 UNet 内的各个级别。stable_attention 选项有助于以更数值稳定的方式计算注意力块反向传播。您可以通过设置 flash_attention 参数来控制是否使用优化的 FlashAttention。
调度#
要使用 EDM 训练 NeMo Imagen,请设置 preconditioning_type=EDM 并使用 EDM 论文中建议的参数
preconditioning_type: EDM
preconditioning:
loss_type: l2
sigma_data: 0.5
p_mean: -1.2
p_std: 1.2
请注意,对于 EDM 调度,UNet 经过训练以预测去噪图像而不是噪声本身。支持的 loss_type 为 l1、l2 和 huber。
preconditioning_type: DDPM
preconditioning:
loss_type: l2
pred_objective: noise
noise_schedule: cosine
timesteps: 1000
设置 preconditioning_type=DDPM 允许用户使用连续 DDPM 调度训练 UNet。pred_objective 可以是 noise 或 x_start。我们目前支持 linear 和 cosine 模式用于 noise_schedule。
训练优化#
功能 |
描述 |
启用方式 |
|---|---|---|
数据并行 |
数据集在多个 GPU 或节点上并发读取,从而实现更快的数据加载和处理。 |
在多 GPU/节点上训练时自动启用 |
激活检查点 |
为了减少内存使用量,某些层的激活在反向传播期间被清除并重新计算。此技术对于训练无法使用传统方法容纳在 GPU 内存中的大型模型特别有用。 |
|
Bfloat16 训练 |
训练以 Bfloat16 精度进行,这在 FP32 的更高精度与 FP16 的内存节省和速度之间提供了平衡。 |
|
Flash Attention |
FlashAttention 是一种快速且内存高效的算法,用于计算精确注意力。它通过 IO 感知加速模型训练并减少内存需求。这种方法对于大规模模型特别有用,并在链接的存储库中进行了更详细的介绍。[参考](Dao-AILab/flash-attention) |
|
Channels Last |
以内存保留维度顺序排列 NCHW 张量。 |
|
Inductor |
TorchInductor 编译器 |
|
参考#
Jonathan Ho、Ajay Jain 和 Pieter Abbeel。《Denoising diffusion probabilistic models》。2020 年。arXiv:2006.11239。
Tero Karras、Miika Aittala、Timo Aila 和 Samuli Laine。《Elucidating the design space of diffusion-based generative models》。2022 年。arXiv:2206.00364。
Alex Nichol 和 Prafulla Dhariwal。《Improved denoising diffusion probabilistic models》。2021 年。URL:https://arxiv.org/abs/2102.09672,arXiv:2102.09672。
Chitwan Saharia、William Chan、Saurabh Saxena、Lala Li、Jay Whang、Emily Denton、Seyed Kamyar Seyed Ghasemipour、Burcu Karagol Ayan、S. Sara Mahdavi、Rapha Gontijo Lopes、Tim Salimans、Jonathan Ho、David J Fleet 和 Mohammad Norouzi。《Photorealistic text-to-image diffusion models with deep language understanding》。在 Conference on Neural Information Processing Systems (NeurIPS) 中。2022 年。doi:10.48550/arXiv.2205.11487。