重要提示
您正在查看 NeMo 2.0 文档。此版本引入了 API 的重大更改和一个新的库,NeMo Run。我们目前正在将 NeMo 1.0 的所有功能移植到 2.0。有关早期版本或 2.0 中尚未提供的功能的文档,请参阅 NeMo 24.07 文档。
NeVA#
模型介绍#
NeVA 源于 LLaVA(大型语言和视觉助手)[MM-MODELS2],是 NeMo 多模态生态系统中的先锋模型。它巧妙地融合了以大型语言为中心的模型(如 NVGPT 或 LLaMA)与视觉编码器。训练使用机器生成的多模态语言-图像指令跟随数据。值得注意的是,即使数据集有限,NeVA 也展现出强大的能力来解读图像并熟练地回答关于它们的问题。其卓越的能力尤其体现在需要复杂视觉理解和指令跟随的任务中。有趣的是,即使面对全新的图像和指令,NeVA 也能媲美 GPT-4 等先进的多模态模型的能力。
NeVA 在 LLaVA 的基本原理之上构建,利用 NeMo LLM 框架的特性(包括模型并行、激活检查点、AMP O2、Flash Attention 等)提升了其训练效率。
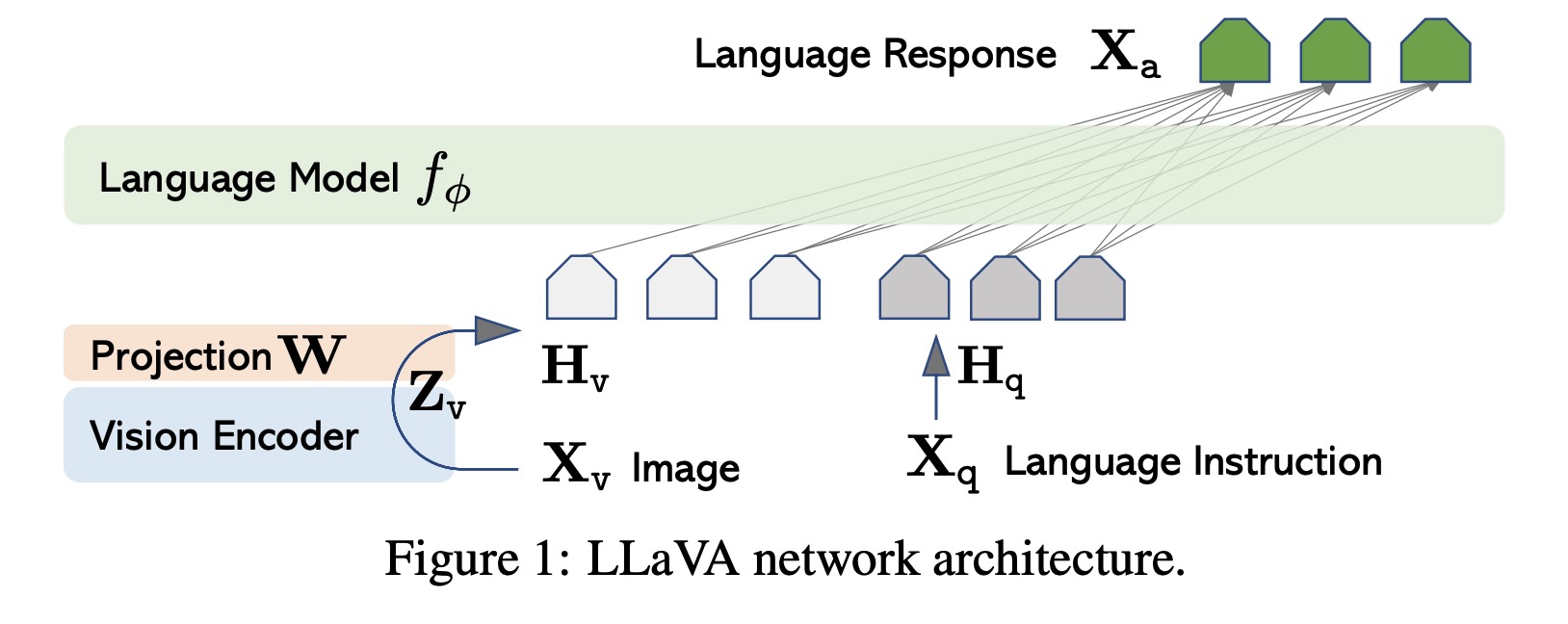
主要语言模型#
原始 LLaVA 模型采用了 LLaMA 架构,该架构以其在开源、仅语言指令调优工作中的强大能力而闻名。LLaMA 通过分词和嵌入过程优化文本输入。位置嵌入被集成到这些 token 嵌入中,组合表示通过多个 Transformer 层传递。与主要 token 关联的结尾 Transformer 层的输出被指定为文本表示。
在 NeMo 中,文本编码器基于 MegatronGPTModel 类。此类功能多样,不仅支持 NVGPT 模型,还支持 LLaMA、LLaMA-2 和其他社区模型,并配备了检查点转换脚本。同时,视觉模型和投影层增强了主要语言模型的词嵌入组件。为了全面理解其实现,可以参考 MegatronNevaModel 类。
视觉模型#
为了进行视觉解释,NeVA 利用了预训练的 CLIP 视觉编码器 ViT-L/14 的强大功能,该编码器以其卓越的视觉理解能力而著称。图像首先被分割成标准化的 patches,例如,16x16 像素。这些 patches 被线性嵌入,形成一个扁平化的向量,然后输入到 Transformer 中。Transformer 处理的最终产物是统一的图像表示。在 NeMo 框架中,基于 CLIP 视觉编码器 ViT-L/14 的 NeVA 视觉模型,可以通过 CLIPVisionTransformer 类实例化,也可以通过 Hugging Face 的 transformers 包启动。
投影和集成#
编码器从图像中检索视觉特征,并使用可修改的投影矩阵将它们与语言嵌入交织在一起。这种复杂的投影将视觉线索转换为语言嵌入 tokens,从而无缝地融合文本和图像。LLaVA-1.5 [MM-MODELS1] 引入了两项关键的增强功能。集成 MLP 视觉-语言连接器提升了系统的能力。借鉴 MLP 在自监督学习中的成功经验,LLaVA-1.5 进行了变革性的设计调整。从线性投影过渡到双层 MLP 投影,显著增强了 LLaVA-1.5 的多模态能力,使模型能够熟练地驾驭和协同语言和视觉元素。
架构表#
基础 LLM |
视觉编码器 |
投影 |
编码器序列长度 |
层数 |
隐藏层维度 |
FFN 隐藏层维度 |
注意力头数 |
|---|---|---|---|---|---|---|---|
LLaMA-2-13B-Chat |
CLIP-L |
线性 |
4096 |
40 |
5120 |
13824 |
40 |
LLaMA-2-7B-Chat |
CLIP-L |
线性 |
4096 |
32 |
4096 |
11008 |
32 |
模型配置#
多模态配置#
mm_cfg:
use_im_start_end: False
use_im_start_end:如果设置为 True,则将在图像嵌入前后使用图像开始和结束 tokens。
多模态中的语言模型配置#
mm_cfg:
llm:
from_pretrained: ${data_dir}/neva/checkpoints/llama-2-13b-chat-tp8.nemo
freeze: False
model_type: llama_2
from_pretrained:预训练 NeMo 语言模型检查点的路径。freeze:如果设置为 True,则模型参数在训练期间不会更新。model_type:指定模型类型,nvgpt 或 llama_2。
多模态中的视觉编码器配置#
mm_cfg:
vision_encoder:
from_pretrained: "openai/clip-vit-large-patch14"
from_hf: True
patch_dim: 14
hidden_size: 1024
vision_select_layer: -2
class_token_length: 1
freeze: True
from_pretrained:预训练视觉编码器的路径或名称。from_hf:如果设置为 True,则将从 Hugging Face 模型中心加载模型。patch_dim:图像被分割成的 patches 的大小。hidden_size:隐藏层的维度。vision_select_layer:指定从视觉模型中选择哪一层。class_token_length:分类 token 的长度。
主要语言模型配置#
mcore_gpt: False
encoder_seq_length: 4096
position_embedding_type: rope
num_layers: 40
hidden_size: 5120
ffn_hidden_size: 13824
num_attention_heads: 40
hidden_dropout: 0.0
attention_dropout: 0.0
ffn_dropout: 0.0
normalization: rmsnorm
bias: False
activation: 'fast-swiglu'
mcore_gpt:如果设置为 True,将使用 megatron.core 中的 GPTModel。encoder_seq_length:主要语言模型编码器的序列长度。position_embedding_type:使用的位置嵌入类型。num_layers、hidden_size、ffn_hidden_size、num_attention_heads:定义主要语言模型架构的参数。ffn_hidden_size通常是hidden_size的 4 倍。hidden_dropout、attention_dropout、ffn_dropout:Transformer 中隐藏状态、注意力和前馈层的 Dropout 概率。normalization:使用的归一化层类型。bias:如果设置为 True,则所有权重矩阵中都将使用偏置项。activation:模型中使用的激活函数。
优化#
功能 |
描述 |
启用方式 |
|---|---|---|
数据并行 |
数据集在多个 GPU 或节点上并发读取,从而加快数据加载和处理速度。 |
在多 GPU/节点上训练时自动启用 |
张量并行 |
每个张量被分成多个块,从而实现跨 GPU 的水平并行。这种技术被称为 TensorParallel (TP),将模型的张量分布在多个 GPU 上。在处理过程中,每个分片在不同的 GPU 上单独并行处理,并在步骤结束时同步结果。这种方法受到 NVIDIA Megatron 实现的启发。[参考](NVIDIA/Megatron-LM) |
|
激活检查点 |
为了减少内存使用量,某些层的激活在反向传播期间被清除并重新计算。这种技术对于训练使用传统方法无法放入 GPU 内存的大型模型尤其有用。 |
|
选择性激活检查点 |
激活检查点的选择性粒度版本。详见我们的论文。[参考](https://arxiv.org/pdf/2205.05198.pdf) |
|
Bfloat16 训练 |
训练以 Bfloat16 精度进行,这在 FP32 的更高精度与 FP16 的内存节省和速度之间取得了平衡。 |
|
BF16 O2 |
启用 O2 级别的自动混合精度,优化 Bfloat16 精度以获得更好的性能。 |
|
Flash Attention V2 |
FlashAttention 是一种快速且内存高效的算法,用于计算精确注意力。它通过感知 IO 加快模型训练速度并减少内存需求。这种方法对于大规模模型尤其有用,并在链接的存储库中进一步详细介绍。[参考](Dao-AILab/flash-attention) |
|
NeVA 训练#
NeVA 的训练包含两个关键阶段,这两个阶段增强了其理解用户指令、理解语言和视觉内容以及生成准确响应的能力
特征对齐预训练:在这个初始阶段,NeVA 对齐视觉和语言特征以确保兼容性。
端到端微调:第二个训练阶段侧重于端到端地微调整个模型。虽然视觉编码器的权重保持不变,但投影层的预训练权重和 LLM 的参数都成为适应的对象。这种微调可以根据不同的应用场景进行定制,从而产生多样的功能。
参考文献#
Haotian Liu、Chunyuan Li、Yuheng Li 和 Yong Jae Lee。改进的视觉指令调优基线。2023 年。
Haotian Liu、Chunyuan Li、Qingyang Wu 和 Yong Jae Lee。视觉指令调优。2023 年。arXiv:arXiv:2304.08485。