重要提示
您正在查看 NeMo 2.0 文档。此版本对 API 和新的库 NeMo Run 进行了重大更改。我们目前正在将 NeMo 1.0 的所有功能移植到 2.0。有关先前版本或 2.0 中尚不可用的功能的文档,请参阅 NeMo 24.07 文档。
模型#
所有以下模型的配置文件示例可以在 <NeMo_git_root>/examples/speaker_recognition/conf 目录中找到。
有关配置文件的更多信息以及它们的结构方式,请参阅 NeMo 说话人识别配置文件 页面。
所有这些模型的预训练检查点,以及关于如何加载它们的说明,都可以在 检查点 页面找到。您可以使用可用的检查点进行即时推理,或在您自己的数据集上对其进行微调。“检查点”页面还包含可用说话人识别模型的基准测试结果。
TitaNet#
TitaNet 模型 [SR-MODELS4] 基于 ContextNet 架构 [SR-MODELS2],用于提取说话人表示。我们采用带有 Squeeze-and-Excitation (SE) 层的 1D 深度可分离卷积,并结合全局上下文,然后使用基于通道注意力的统计池化层,将可变长度的 utterance 映射到固定长度的嵌入 (tvector)。TitaNet 是一种可扩展的架构,在说话人验证和日志任务中实现了最先进的性能。
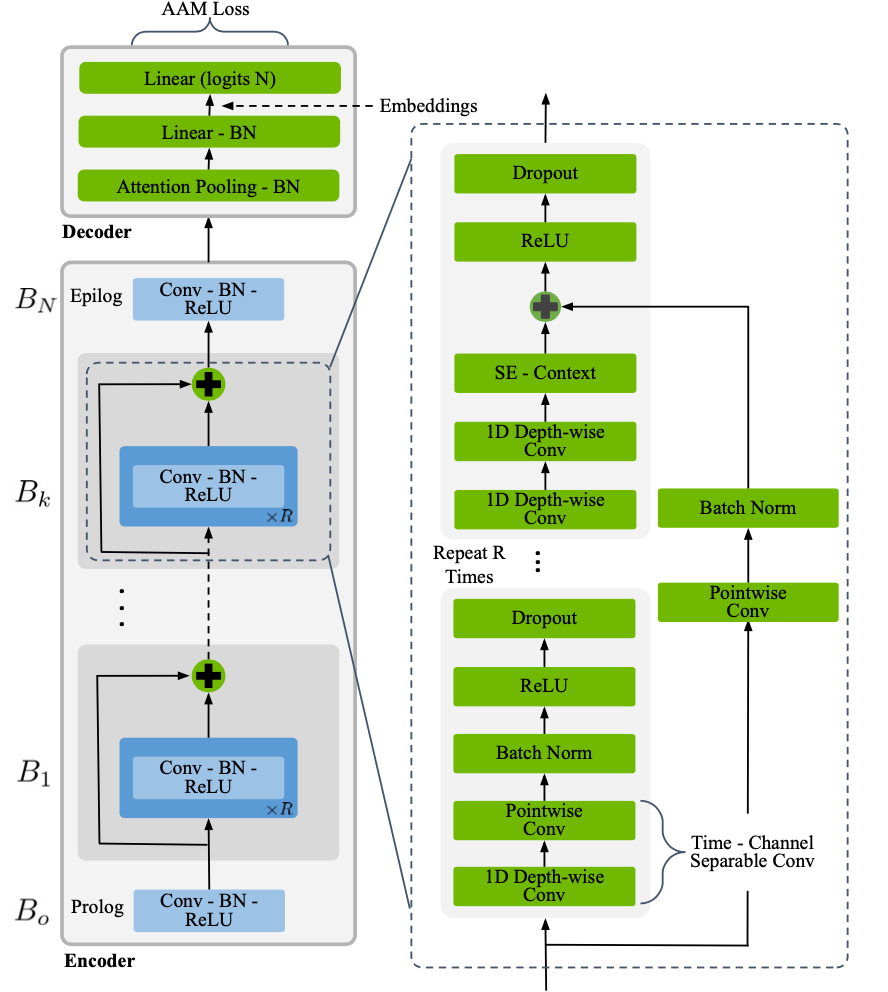
SpeakerNet 模型可以使用 EncDecSpeakerLabelModel 类实例化。
SpeakerNet#
该模型基于 QuartzNet ASR 架构 [SR-MODELS3],包括编码器和解码器结构。我们使用 QuartzNet 模型的编码器作为顶层特征提取器,并将输出馈送到统计池化层,在其中我们计算跨通道维度的均值和方差,以捕获时间独立的 utterance 级说话人特征。
下图所示用于说话人嵌入的 QuartzNet 编码器具有以下结构:QuartzNet BxR 模型有 B 个块,每个块有 R 个子块。每个子块应用以下操作:1D 卷积、批归一化、ReLU 和 dropout。一个块中的所有子块都具有相同数量的输出通道。这些块通过残差连接连接。我们使用具有 3 个块、2 个子块和 512 个通道的 QuartzNet 作为说话人嵌入的编码器。所有 conv 层都具有步幅 1 和空洞率 1。
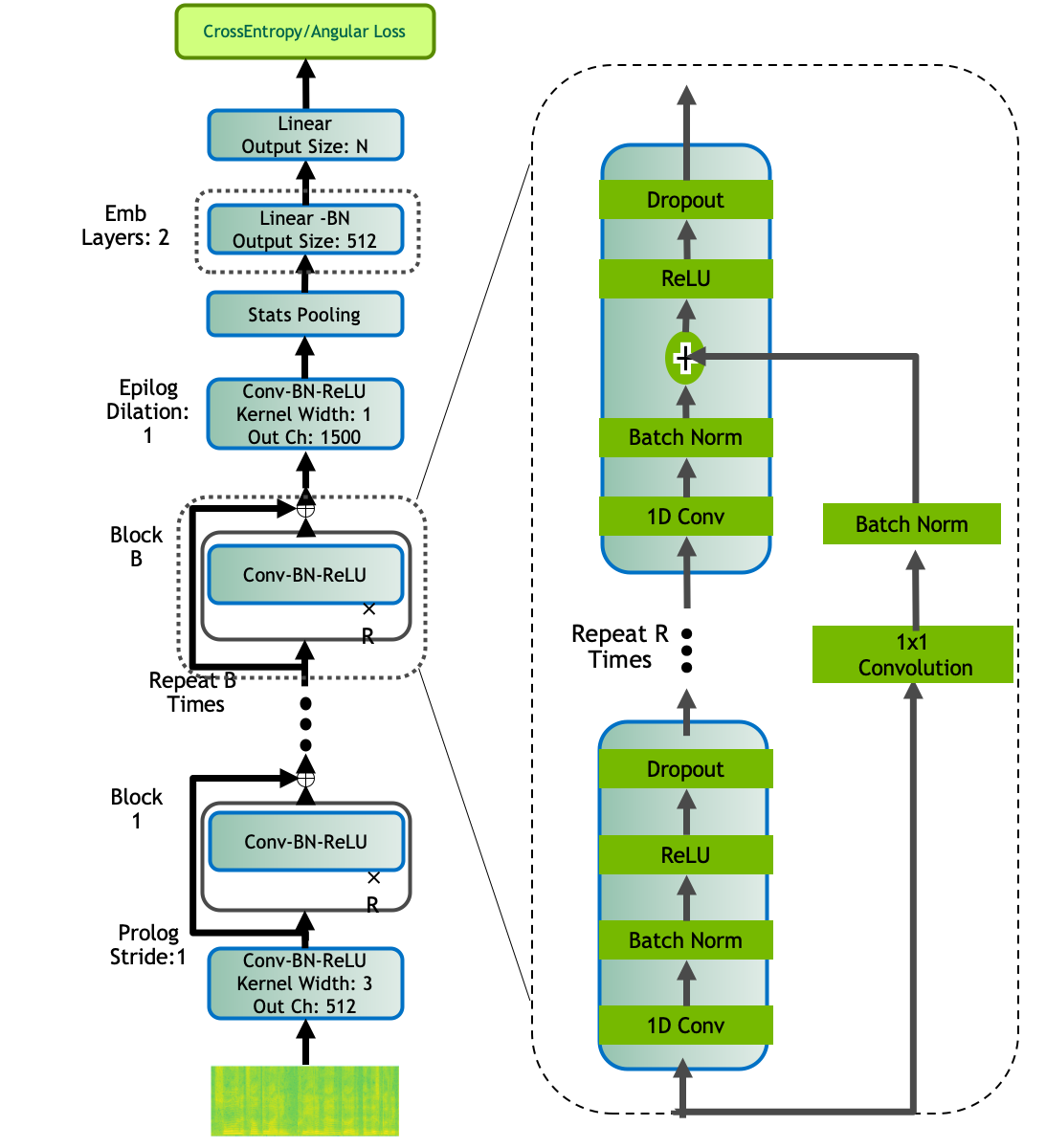
从编码器输出获得的顶层声学特征用于计算中间特征,然后将这些特征传递给解码器,以获得 utterance 级别的说话人嵌入。中间的时间独立特征是使用统计池化层计算的,在其中我们计算跨时间通道的特征的均值和标准差,以获得大小为 Batch_size × 3000 的时间独立特征表示 S。中间特征 S 通过解码器传递,解码器由两层组成,每层的输出大小为 512,用于从 S 到较大 (L) 模型的最终类别数 N 的线性变换,以及一个输出大小为 256 的线性层到中等 (M) 模型的最终类别数 N。对于 SpeakerNet-L 和 SpeakerNet-M 模型,我们在最终线性层之后提取固定大小为 512、256 的 q-vector。
SpeakerNet 模型可以使用 EncDecSpeakerLabelModel 类实例化。
ECAPA_TDNN#
该模型基于论文 “ECAPA_TDNN Embeddings for Speaker Diarization” [SR-MODELS1],包括一个基于强调通道注意力、传播和聚合的时间扩张层编码器。ECAPA-TDNN 模型采用通道和上下文相关的注意力机制、多层特征聚合 (MFA) 以及 Squeeze-Excitation (SE) 和残差块,由于更快的训练和推理,我们将残差块替换为单扩张的组卷积块。这些模型在各种说话人任务中表现出良好的性能。
ecapa_tdnn 模型可以使用 EncDecSpeakerLabelModel 类实例化。
参考文献#
Nauman Dawalatabad, Mirco Ravanelli, François Grondin, Jenthe Thienpondt, Brecht Desplanques, and Hwidong Na. Ecapa-tdnn 嵌入用于说话人日志. Interspeech 2021, Aug 2021. URL: http://dx.doi.org/10.21437/Interspeech.2021-941, doi:10.21437/interspeech.2021-941.
Wei Han, Zhengdong Zhang, Yu Zhang, Jiahui Yu, Chung-Cheng Chiu, James Qin, Anmol Gulati, Ruoming Pang, and Yonghui Wu. Contextnet:通过全局上下文改进用于自动语音识别的卷积神经网络. arXiv:2005.03191, 2020.
Nithin Rao Koluguri, Jason Li, Vitaly Lavrukhin, and Boris Ginsburg. Speakernet:用于文本无关说话人识别和验证的 1d 深度可分离卷积网络. arXiv preprint arXiv:2010.12653, 2020.
Nithin Rao Koluguri, Taejin Park, and Boris Ginsburg. Titanet:使用 1d 深度可分离卷积和全局上下文的说话人表示神经模型. arXiv preprint arXiv:2110.04410, 2021.