重要提示
您正在查看 NeMo 2.0 文档。此版本对 API 和一个新库 NeMo Run 进行了重大更改。我们目前正在将 NeMo 1.0 中的所有功能移植到 2.0。有关先前版本或 2.0 中尚不可用的功能的文档,请参阅 NeMo 24.07 文档。
扩散训练框架#
概述#
NeMo 扩散训练框架为具有 Transformer 主干的扩散模型提供了一个可扩展的训练平台。我们的新功能简化了训练流程,使开发者能够轻松高效地训练最先进的模型。
我们目前支持的一些功能包括
用于 Webscale 数据加载的 Energon 数据加载器
模型和数据并行
模型架构:原始扩散 Transformer (DiT)、MovieGen 30B+ 参数、时空 DiT
性能#
我们使用 32 个 H100 DGX 节点对上下文长度为 8k 和 64k 的 7B 和 28B DiT 交叉注意力模型进行了基准测试。
8k 上下文长度对应于 256 帧 256px 视频的潜在表示。
64k 上下文长度对应于 256 帧 1024px 视频的潜在表示。
模型大小 |
上下文长度 |
训练配置 |
GPU 利用率 (TFLOPS/s) |
吞吐量 (token/s/GPU) |
|---|---|---|---|---|
DiT 7B |
8k |
基线,无优化 |
OOM |
|
DiT 7B |
8k |
TP=2 SP |
519 |
10052 |
DiT 7B |
74k |
TP=2 SP CP=4 |
439 |
3409 |
DiT 28B |
8k |
TP4 PP4 |
468 |
2510 |
DiT 28B |
64k |
FSDP act ckpt |
445 |
1386 |
图例: - FSDP:完全分片数据并行 - CP:上下文并行 - TP:张量并行 - SP:序列并行 - PP:流水线并行 - EP:专家并行 - distop:mcore 分布式优化器 - act ckpt:激活检查点
功能状态#
我们支持使用所有并行策略进行图像/视频扩散训练。
并行性 |
状态 |
|---|---|
FSDP |
✅ 支持 |
CP+TP+SP+FSDP |
✅ 支持 |
CP+TP+SP+distopt |
✅ 支持 |
CP+TP+SP+PP+distopt |
✅ 支持 |
CP+TP+SP+PP+distopt+EP |
✅ 支持 |
CP+TP+SP+FSDP+EP |
✅ 支持 |
训练阶段#
模型大小 |
模态 |
序列长度 |
状态 |
|---|---|---|---|
DiT 5B, 30B+ |
256px 图像 |
256 |
✅ 支持 |
DiT 5B, 30B+ |
256px 图像+视频 |
8k |
✅ 支持 |
DiT 5B, 30B+ |
768px 图像+视频 |
74k+ |
✅ 支持 |
用于 Webscale 数据加载的 Energon 数据加载器#
Webscale 数据加载#
Megatron-Energon 是一个优化的多模态数据加载器,用于使用 Megatron 进行大规模深度学习。Energon 允许分布式加载大型训练数据,用于多模态模型训练。Energon 允许将多个数据集混合在一起,并将数据加载工作流程分布在多个集群节点/进程中,同时确保可重复性和可恢复性。您可以在此处 <data/readme.rst>_ 了解有关如何为扩散训练准备您自己的图像/视频 WebDataset 的更多信息。
数据加载器检查点#
Energon 的关键功能之一是其保存和恢复状态的能力。此功能对于长时间运行的训练过程至关重要,使数据加载器在中断后具有鲁棒性和可恢复性。通过允许数据加载器状态的检查点,Energon 确保训练可以从中断处恢复,从而在意外关机或计划暂停训练过程的情况下节省时间和计算资源。这使其对于大规模训练特别有用,因为它需要多个训练作业才能进行端到端训练。并行配置 ^^^^^^^^^^^^^^^^^^^^^^
Energon 的架构使其能够有效地跨多个处理单元分配数据,确保每个 GPU 或节点接收均衡的工作负载。这种并行化不仅提高了数据处理的整体吞吐量,而且还有助于保持可用计算资源的高利用率。
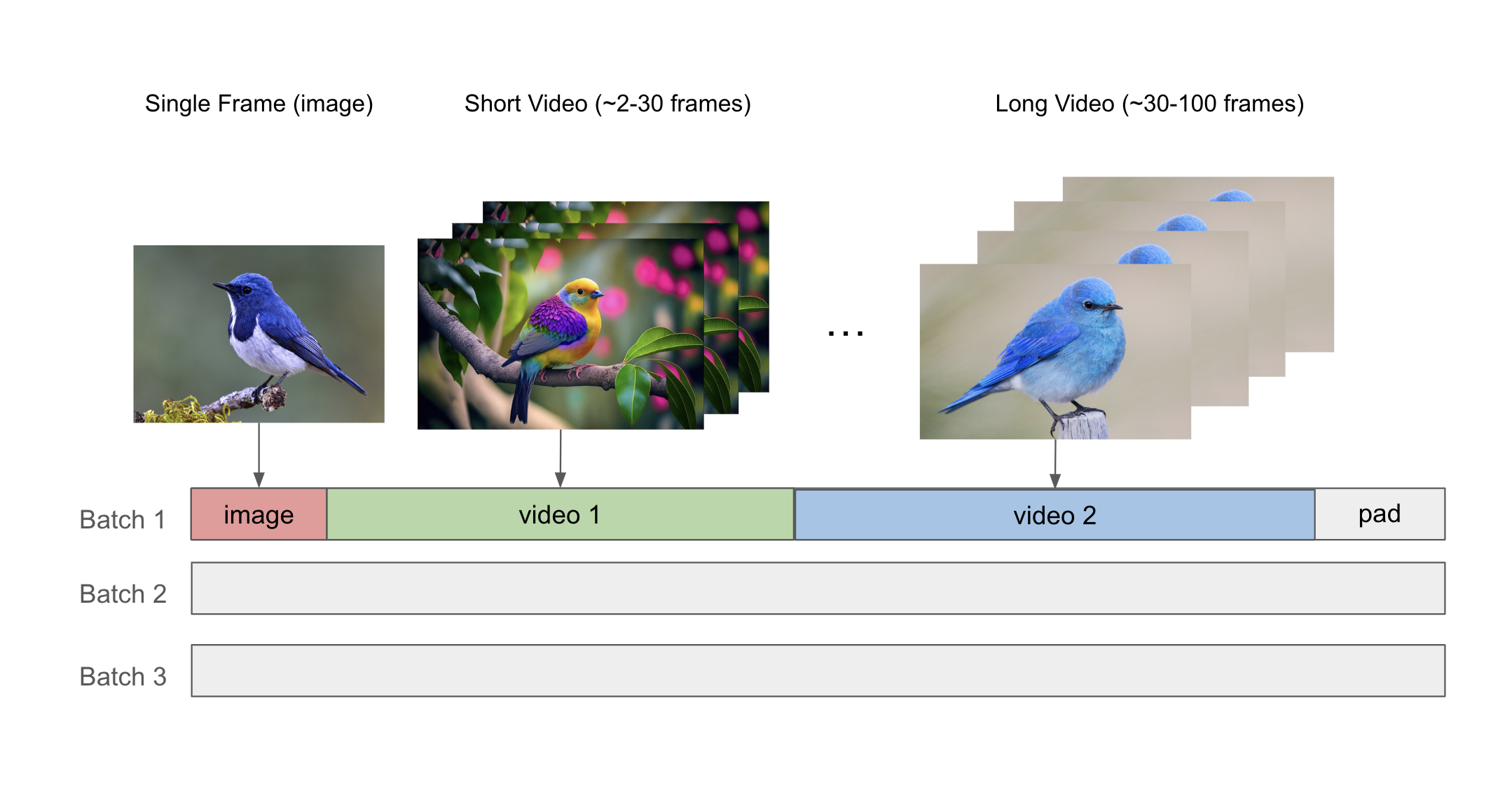
混合图像-视频训练#
我们的数据加载器通过使用 NeMo 打包序列功能将不同长度的图像和视频打包到同一微批次中,从而为混合图像-视频训练提供支持。序列打包机制使用 THD 注意力内核,这使我们能够提高模型 FLOPs 利用率 (MFU) 并有效地处理不同长度的数据。
模型和数据并行#
NeMo 支持使用张量并行、序列并行、流水线并行和上下文并行来训练模型。为了支持带有条件扩散训练的流水线并行,我们在流水线阶段复制条件嵌入,并在后向传递期间执行 all-reduce。这种方法使用更多的计算,但与通过不同的流水线阶段发送条件嵌入相比,它的通信成本更低。 .. image:: pipeline_conditioning.png
- alt:
流水线并行的条件机制
- scale:
50%
- align:
center
模型架构#
DiT#
我们实现了扩散 Transformer (DiT) [1] 的高效版本以及多个变体,以为用户提供探索各种模型架构的灵活性。
当前支持的架构包括
在使用 DiT adaLN-Zero 的架构中,我们还使用 QK-layernorm 来提高视频扩散训练的训练稳定性。我们还提供了一个选项,将交叉注意力与额外的条件信息(即文本嵌入)一起使用,以便使用原始 DiT 公式进行文本到视频的训练。
我们还支持使用基于 Llama 的模型架构进行 MovieGen [2] 训练,该架构利用 FSDP 进行大型模型训练(即 30B+ 参数)。
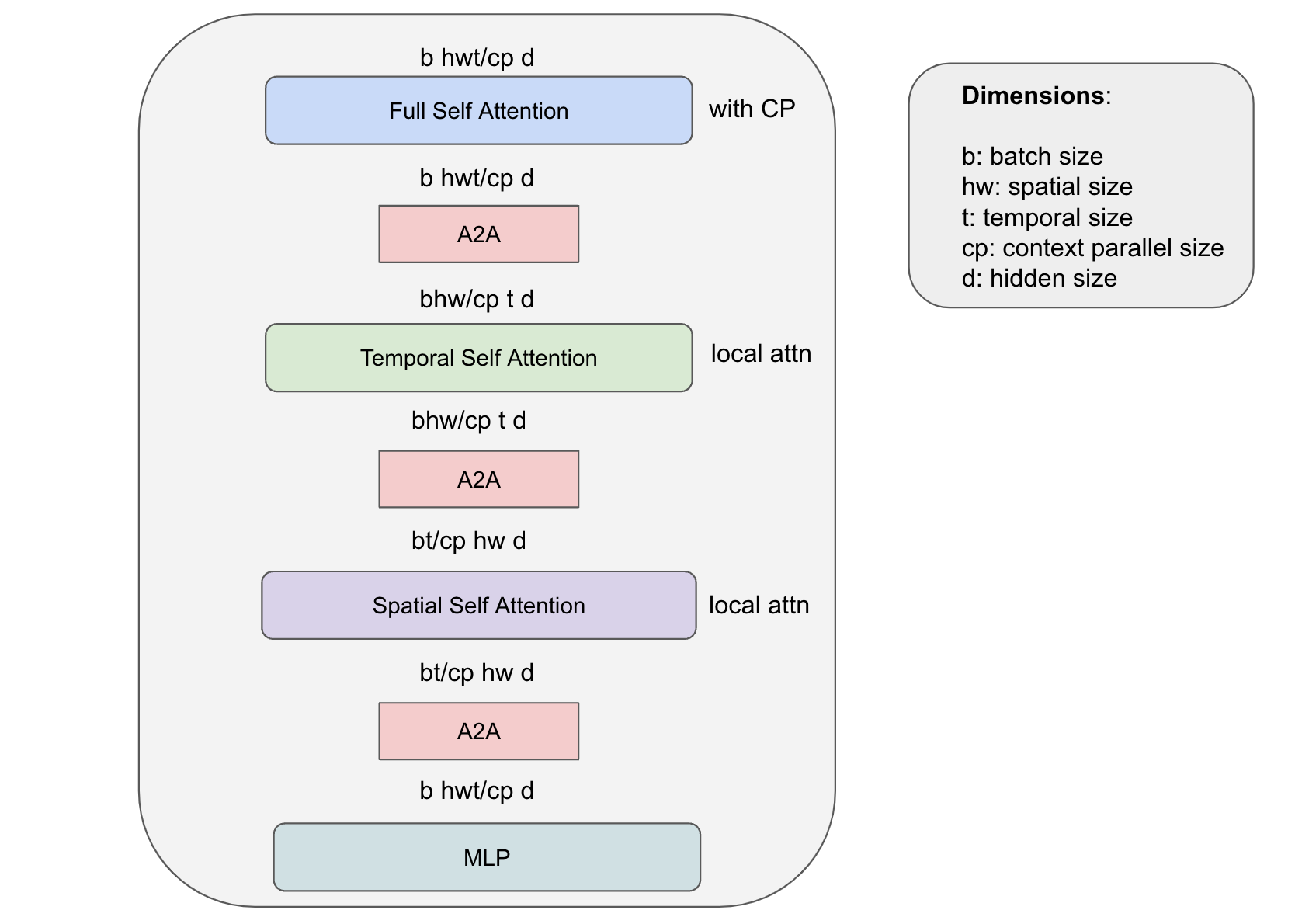
我们的框架允许自定义 DiT 架构,同时保持其可扩展性,从而能够在长序列长度上训练大型 DiT 模型。我们为 ST-DiT 提供了功能,它利用在空间和时间序列维度上运行的空间自注意力和时间自注意力块。专业架构带来了各种挑战。在 ST-DiT 的情况下,一个主要挑战是空间和时间上下文长度远小于完整输入序列长度。当对少量计算使用 CP 时,这会导致大量的通信成本。上下文并行中的 P2P 通信被暴露出来,并导致更长的训练步骤时间。为了有效地训练 ST-DiT,我们提出了一种新颖的混合并行策略,该策略利用 A2A 通信和局部注意力计算进行空间和时间自注意力,同时在环形拓扑中使用 P2P 通信和上下文并行。这种方法将时间注意力的带宽要求降低了 hw/cp 倍,将空间注意力的带宽要求降低了 t/cp 倍,同时享受了上下文并行来分担计算完整自注意力的工作负载的好处。
模型训练#
在单个节点上启动训练
torchrun --nproc-per-node 8 nemo/collections/diffusion/train.py --yes --factory pretrain_xl
使用 Slurm 在多个节点上启动训练
sbatch nemo/collections/diffusion/scripts/train.sh --factory pretrain_xl