重要
您正在查看 NeMo 2.0 文档。此版本对 API 和新库 NeMo Run 进行了重大更改。我们目前正在将所有功能从 NeMo 1.0 移植到 2.0。有关先前版本或 2.0 中尚未提供的功能的文档,请参阅 NeMo 24.07 文档。
概述#
NVIDIA NeMo 框架是一个可扩展的云原生生成式 AI 框架,专为从事 大型语言模型、多模态和 语音 AI(例如 自动语音识别 和 文本到语音)的研究人员和开发人员构建。它使用户能够通过利用现有代码和预训练模型检查点,高效地创建、自定义和部署新的生成式 AI 模型。
安装说明: 安装 NeMo 框架
大型语言模型和多模态模型#
NeMo 框架为开发大型语言模型 (LLM) 和多模态模型 (MM) 提供端到端支持。它提供了灵活性,可用于本地部署、数据中心或您首选的云提供商。它还支持在启用 SLURM 或 Kubernetes 的环境中执行。
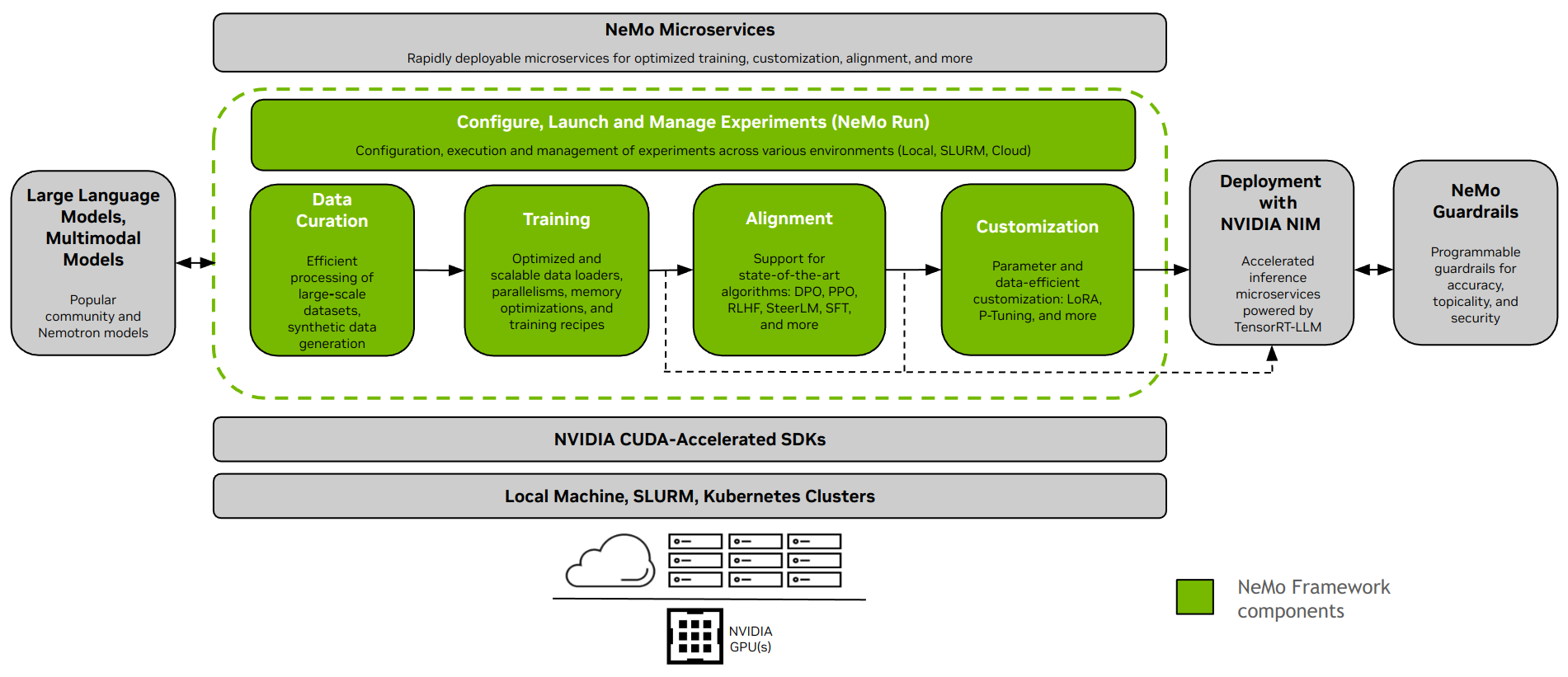
数据整理#
NeMo Curator [1] 是一个 Python 库,包含一套用于数据挖掘和合成数据生成的模块。它们是可扩展的,并针对 GPU 进行了优化,使其非常适合整理自然语言数据以训练或微调 LLM。借助 NeMo Curator,您可以从大量的原始网络数据源中高效提取高质量文本。
训练和自定义#
NeMo 框架提供了用于高效训练和自定义 LLM 和多模态模型的工具。它包括计算集群设置、数据下载和模型超参数的默认配置,这些配置可以调整以在新数据集和模型上进行训练。除了预训练之外,NeMo 还支持监督微调 (SFT) 和参数高效微调 (PEFT) 技术,如 LoRA、Ptuning 等。
NeMo 中提供了两种启动训练的选项 - 使用 NeMo 2.0 API 接口或使用 NeMo Run。
使用 NeMo Run(推荐): NeMo Run 提供了一个界面,用于简化跨各种计算环境的实验配置、执行和管理。这包括在您的工作站本地或大型集群(启用 SLURM 或云环境中的 Kubernetes)上启动作业。
使用 NeMo 2.0 API: 此方法非常适用于涉及小型模型的简单设置,或者如果您有兴趣编写自己的自定义数据加载器、训练循环或更改模型层。它为您提供更大的灵活性和对配置的控制,并使以编程方式扩展和自定义配置变得容易。
对齐#
NeMo-Aligner [1] 是一个用于高效模型对齐的可扩展工具包。该工具包支持最先进的模型对齐算法,如 SteerLM、DPO、基于人类反馈的强化学习 (RLHF) 等。这些算法使用户能够对齐语言模型,使其更安全、无害且更有帮助。
所有 NeMo-Aligner 检查点都与 NeMo 生态系统交叉兼容,从而允许进一步自定义和推理部署。
小型 GPT-2B 模型上 RLHF 所有三个阶段的逐步工作流程
此外,我们还演示了对各种其他新颖对齐方法的支持
查看文档以获取更多信息
多模态模型#
NeMo 框架提供了优化的软件,用于训练和部署跨多个类别的最先进的多模态模型:多模态语言模型、视觉语言基础、文本到图像模型以及使用神经辐射场 (NeRF) 的 2D 生成之外。
每个类别都旨在满足该领域中的特定需求和进步,利用尖端模型来处理各种数据类型,包括文本、图像和 3D 模型。
注意
我们正在将对多模态模型的支持从 NeMo 1.0 迁移到 NeMo 2.0。如果您想在此期间探索此领域,请参阅 NeMo 24.07(以前)版本的文档。
部署和推理#
NeMo 框架为 LLM 推理提供了各种路径,以满足不同的部署场景和性能需求。
使用 NVIDIA NIM 部署#
NeMo 框架通过 NVIDIA NIM 与企业级模型部署工具无缝集成。此集成由 NVIDIA TensorRT-LLM 提供支持,确保优化和可扩展的推理。
有关更多信息,请访问 NVIDIA 网站。
使用 TensorRT-LLM 或 vLLM 部署#
NeMo 框架提供了脚本和 API,用于将模型导出到两个推理优化库 TensorRT-LLM 和 vLLM,并使用 NVIDIA Triton 推理服务器部署导出的模型。
对于需要优化性能的场景,NeMo 模型可以利用 TensorRT-LLM,这是一个专门用于加速和优化 NVIDIA GPU 上 LLM 推理的库。此过程涉及使用 nemo.export 模块将 NeMo 模型转换为与 TensorRT-LLM 兼容的格式。
支持的模型#
大型语言模型#
大型语言模型 |
预训练和 SFT |
PEFT |
对齐 |
FP8 训练收敛 |
TRT/TRTLLM |
转换为和来自 Hugging Face |
评估 |
|---|---|---|---|---|---|---|---|
是 |
是 |
x |
是(部分验证) |
是 |
两者 |
是 |
|
是 |
是 |
x |
是(未验证) |
是 |
两者 |
是 |
|
是 |
x |
x |
是(未验证) |
x |
两者 |
是 |
|
是 |
x |
x |
是(未验证) |
x |
两者 |
是 |
|
是 |
是 |
x |
是(未验证) |
x |
两者 |
是 |
|
是 |
是 |
x |
是(未验证) |
x |
两者 |
是 |
|
是 |
是 |
x |
是(未验证) |
是 |
两者 |
是 |
|
是 |
是 |
x |
是(未验证) |
x |
两者 |
是 |
|
是 |
是 |
x |
是(未验证) |
x |
x |
是 |
|
x |
是 |
x |
是(未验证) |
x |
x |
x |
|
是 |
是 |
x |
是(未验证) |
是 |
两者 |
是 |
|
是 |
是 |
x |
是(未验证) |
是 |
两者 |
是 |
|
是 |
是 |
x |
是(未验证) |
是 |
两者 |
是 |
|
是 |
是 |
x |
是(未验证) |
x |
两者 |
x |
|
是 |
是 |
x |
x |
x |
x |
x |
视觉语言模型#
视觉语言模型 |
预训练和 SFT |
PEFT |
对齐 |
FP8 训练收敛 |
TRT/TRTLLM |
转换为和来自 Hugging Face |
评估 |
|---|---|---|---|---|---|---|---|
是 |
是 |
x |
是(未验证) |
x |
来自 |
x |
|
是 |
是 |
x |
是(未验证) |
x |
来自 |
x |
|
是 |
是 |
x |
是(未验证) |
x |
来自 |
x |
嵌入模型#
嵌入语言模型 |
预训练和 SFT |
PEFT |
对齐 |
FP8 训练收敛 |
TRT/TRTLLM |
转换为和来自 Hugging Face |
评估 |
|---|---|---|---|---|---|---|---|
是 |
x |
x |
是(未验证) |
x |
两者 |
x |
|
是 |
x |
x |
是(未验证) |
x |
两者 |
x |
世界基础模型#
世界基础模型 |
后训练 |
加速推理 |
|---|---|---|
Cosmos-1.0-Diffusion-Video2World-7B |
即将推出 |
即将推出 |
Cosmos-1.0-Diffusion-Video2World-14B |
即将推出 |
即将推出 |
Cosmos-1.0-Autoregressive-Video2World-5B |
即将推出 |
即将推出 |
Cosmos-1.0-Autoregressive-Video2World-13B |
即将推出 |
即将推出 |
语音 AI#
开发对话式 AI 模型是一个复杂的过程,涉及在特定领域内定义、构建和训练模型。此过程通常需要多次迭代才能达到高精度水平。它通常涉及多次迭代,以实现高精度、在各种任务和特定领域数据上进行微调、确保训练性能以及准备模型以进行推理部署。
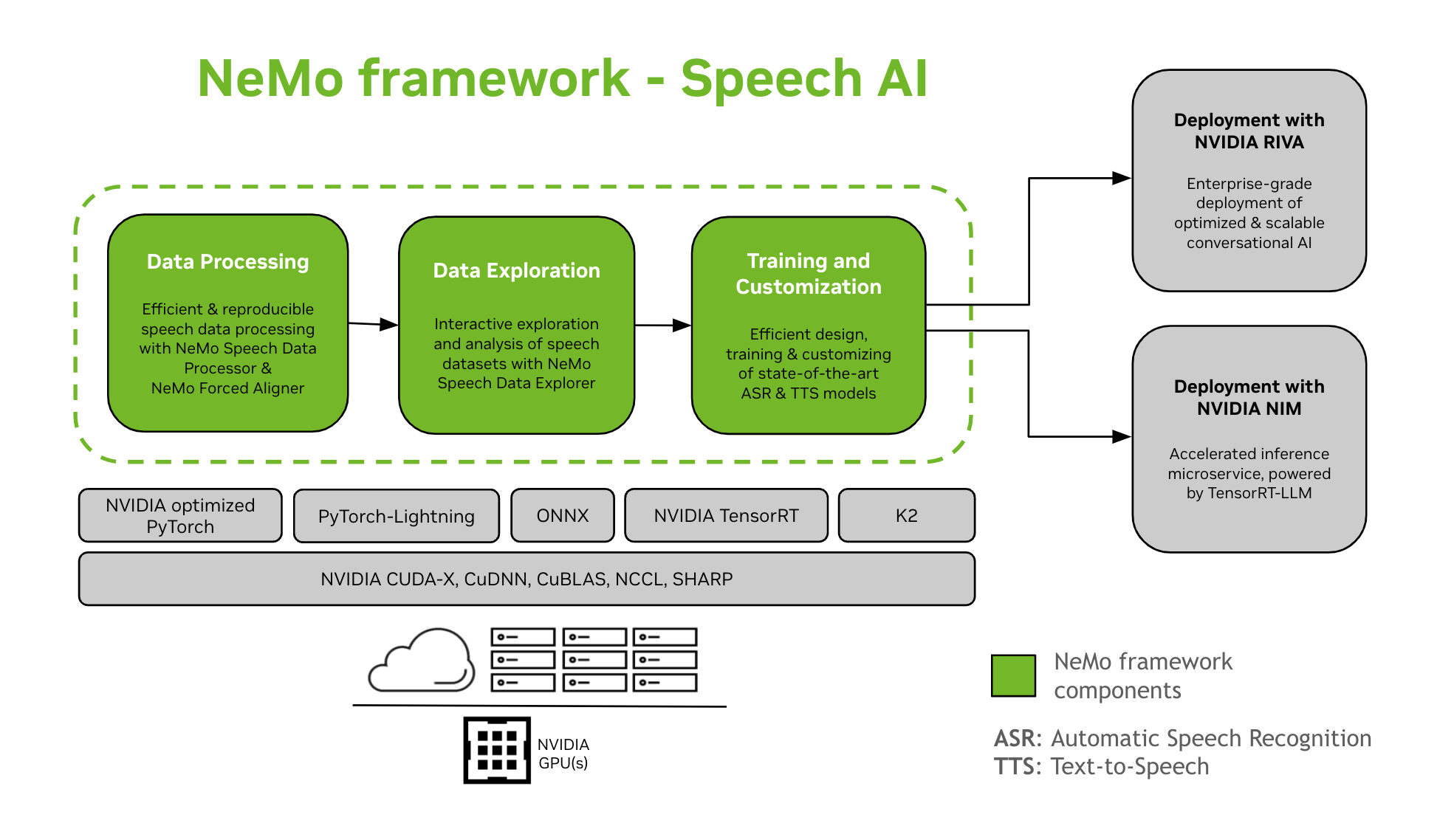
NeMo 框架为语音 AI 模型的训练和自定义提供支持。这包括自动语音识别 (ASR) 和文本到语音 (TTS) 合成等任务。它为使用 NVIDIA Riva 过渡到企业级生产部署提供了平滑的路径。为了帮助开发人员和研究人员,NeMo 框架包括最先进的预训练检查点、用于可重现语音数据处理的工具以及用于交互式探索和分析语音数据集的功能。NeMo 框架用于语音 AI 的组件如下:
- 训练和自定义
NeMo 框架包含以可重现的方式训练和自定义语音模型(ASR、语音分类、说话人识别、说话人分割 和 TTS)所需的一切。
- SOTA 预训练模型
- 语音工具
NeMo 框架提供了一组有用的工具,用于开发 ASR 和 TTS 模型,包括:
NeMo 强制对齐器 (NFA),用于使用 NeMo 基于 CTC 的自动语音识别模型生成音频中语音的 token、单词和片段级时间戳。
语音数据处理器 (SDP),一个用于简化语音数据处理的工具包。它允许您在配置文件中表示数据处理操作,最大限度地减少样板代码,并允许可重现性和可共享性。
语音数据浏览器 (SDE),一个基于 Dash 的 Web 应用程序,用于交互式探索和分析语音数据集。
数据集创建工具,它提供将长音频文件与相应的文本记录对齐并将它们拆分为更短片段的功能,这些片段适用于自动语音识别 (ASR) 模型训练。
比较工具,用于比较不同 ASR 模型在单词准确率和语句级别的预测的 ASR 模型。
ASR 评估器,用于评估 ASR 模型和其他功能(如语音活动检测)的性能。
文本规范化工具,用于将文本从书面形式转换为口语形式,反之亦然(例如“31st”与“thirty first”)。
- 部署路径
已使用 NeMo 框架训练或自定义的 NeMo 模型可以使用 NVIDIA Riva 进行优化和部署。Riva 提供专门设计的容器和 Helm 图表,以自动化一键部署的步骤。
语音 AI 入门
其他资源#
GitHub 仓库#
NeMo:NeMo 框架的主要仓库
NeMo-Run:一个用于配置、启动和管理您的机器学习实验的工具。
NeMo-Aligner:用于高效模型对齐的可扩展工具包
NeMo-Curator:用于 LLM 的可扩展数据预处理和整理工具包
获取帮助#
与 NeMo 社区互动,提问,获得支持或报告错误。
编程语言和框架#
Python:使用 NeMo 框架的主要接口
PyTorch:NeMo 框架构建于 PyTorch 之上
许可#
NeMo Github 仓库在 Apache 2.0 许可下获得许可
NeMo 框架在 NVIDIA AI 产品协议下获得许可。通过拉取和使用容器,您接受此许可的条款和条件。
NeMo 框架容器包含受 Meta Llama3 社区许可协议约束的 Llama 材料。
脚注