重要提示
您正在查看 NeMo 2.0 文档。此版本对 API 和一个新库 NeMo Run 进行了重大更改。我们目前正在将 NeMo 1.0 的所有功能移植到 2.0。有关先前版本或 2.0 中尚不可用的功能的文档,请参阅 NeMo 24.07 文档。
重要提示
在开始本教程之前,请务必查看简介,以获取有关设置 NeMo-Aligner 环境的提示。
如果您遇到任何问题,请参阅 NeMo 的已知问题页面。该页面列举了已知问题,并在适当的情况下提供了建议的解决方法。
完成本教程后,请参阅评估文档,以获取有关评估已训练模型的提示。
通过 SteerLM 方法进行模型对齐#
SteerLM 是 NVIDIA NeMo 团队开发的一种新颖方法,作为 NVIDIA NeMo 对齐方法的一部分引入。它简化了大型语言模型 (LLM) 的自定义,并通过指定所需的属性,使用户能够动态控制模型输出。尽管 GPT-3、Megatron-Turing、Chinchilla、PaLM-2、Falcon 和 Llama 2 等 LLM 驱动的自然语言生成取得了显著进展,但这些基础模型在提供细致入微且与用户对齐的响应方面通常有所欠缺。目前改进 LLM 的方法结合了监督微调 (SFT) 和来自人类反馈的强化学习 (RLHF),但这带来了复杂性和有限的用户控制。SteerLM 解决了这些挑战,代表了该领域的重大进步,使得根据特定需求和偏好定制 LLM 变得更加容易。本文档深入探讨 SteerLM 的工作原理,并提供有关训练 SteerLM 模型的指南。
SteerLM#
SteerLM 利用 SFT 方法,使您能够在推理期间控制响应。它克服了先前对齐技术的局限性,包含四个关键步骤
在人工注释的数据集上训练属性预测模型,以评估响应质量,属性可以包括有用性、幽默感和创造力等。
通过预测各种数据集的属性得分来注释这些数据集,使用步骤 1 中的模型来丰富模型可用的数据多样性。
通过训练 LLM 生成以指定属性组合为条件的响应来执行属性条件 SFT,例如用户感知质量和有用性。
通过模型采样进行引导训练,方法是生成以最大质量为条件的多样化响应(图 4a),然后在这些响应上进行微调以进一步改进对齐(图 4b)。
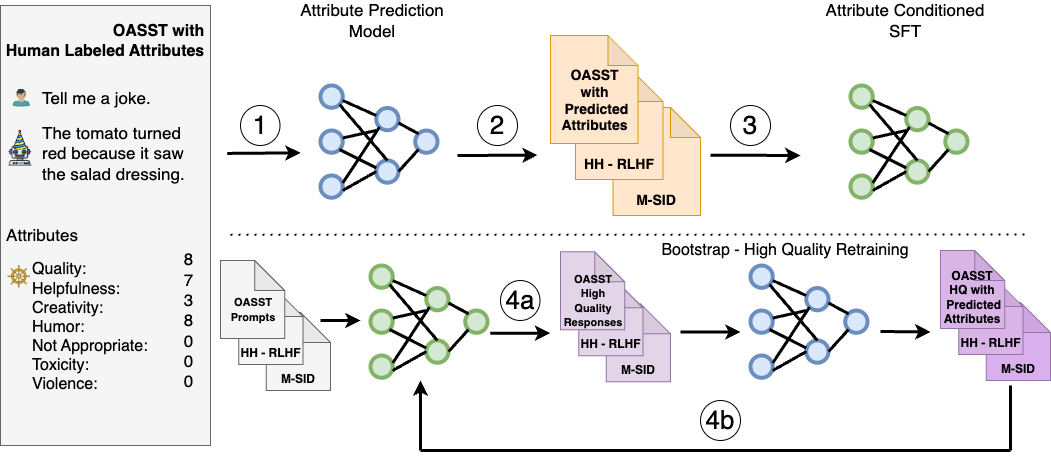
与 RLHF 相比,SteerLM 简化了对齐过程。它支持用户可控的 AI,使您能够在推理时调整属性。这使开发人员能够定义与应用程序相关的偏好,这与其他需要使用预定偏好的技术不同。
SteerLM 与 RLHF#
RLHF 和 SteerLM 是旨在将语言模型与人类偏好对齐的两种方法。RLHF 通过提供对生成响应的正面或负面反馈来训练语言模型,从而加强良好行为。具体来说,鼓励模型生成更多类似于收到正面反馈的响应的文本,并减少生成类似于收到负面反馈的响应的文本。SteerLM 采用不同的模型对齐方法。它不是仅仅加强“良好”行为,而是使用引导标签对可能的模型响应空间进行分类。在推理时,模型根据这些分类标签生成,这些标签引导其输出。因此,虽然 RLHF 使用对模型生成的直接反馈,但 SteerLM 通过将响应映射到与人类偏好相关的标记类别来进行对齐。这两种方法从不同的角度处理模型对齐:RLHF 直接加强所需的模型行为,而 SteerLM 基于分类标签引导生成。两者的目标都是生成与人类价值观和偏好更好对齐的语言模型输出。
注意
有关 SteerLM 的详细信息,请参阅我们的论文 SteerLM:作为 RLHF 的(用户可控)替代方案的属性条件 SFT。有关 HelpSteer 数据集的详细信息,请参阅我们的论文 HelpSteer:用于 SteerLM 的多属性有用性数据集。
训练 SteerLM 模型#
本节是一个循序渐进的教程,将引导您了解如何使用 Llama2 70B LLM 模型运行完整的 SteerLM 管道。
下载 Llama 2 LLM 模型#
从 HF <http://hugging-face.cn/meta-llama/Llama-2-70b-hf> 下载 Llama 2 70B LLM 模型到 models 文件夹中。
将 Llama 2 LLM 转换为 .nemo 格式
mkdir -p /models/llama70b/ python /opt/NeMo/scripts/checkpoint_converters/convert_llama_hf_to_nemo.py --input_name_or_path /path/to/llama --output_path /models/llama70b/llama70b.nemo
下载 13B 模型并转换为 .nemo 格式 <http://hugging-face.cn/meta-llama/Llama-2-13b-hf>。这是属性预测建模步骤所必需的。
解压 .nemo 文件以获取 NeMo 格式的分词器(仅适用于 70B 模型)
cd /models/llama70b tar xvf llama70b.nemo . rm llama70b.nemo mv <random_prefix>_tokenizer.model tokenizer.model
解压后,分词器的前缀会有所不同。请确保在运行前面的命令时使用正确的分词器文件。
要遵循 HelpSteer2 和 HelpSteer2-Preference 系列工作,您需要分别使用 LLama 3 70B 和 LLama 3.1 70B Instruct 模型。
您需要获得对它们的访问权限,下载它们,然后以类似的方式转换它们。
下载和预处理用于 SteerLM 回归奖励建模的数据#
下载并将两个数据集转换为通用格式
python /opt/NeMo-Aligner/examples/nlp/data/steerlm/preprocess_openassistant_data.py --output_directory=data/oasst python /opt/NeMo-Aligner/examples/nlp/data/steerlm/preprocess_helpsteer_data.py --output_directory=data/helpsteer
合并训练和验证子集的两个数据集
cat data/oasst/train.jsonl data/helpsteer/train.jsonl | awk '{for(i=1;i<=4;i++) print}' > data/merge_train.jsonl cat data/oasst/val.jsonl data/helpsteer/val.jsonl > data/merge_val.jsonl
将数据预处理为回归奖励模型训练格式
python /opt/NeMo-Aligner/examples/nlp/data/steerlm/process_to_regression_format.py \ --input-file=data/merge_train.jsonl \ --output-file=data/merge_train_reg.jsonl python /opt/NeMo-Aligner/examples/nlp/data/steerlm/process_to_regression_format.py \ --input-file=data/merge_val.jsonl \ --output-file=data/merge_val_reg.jsonl
如果您有兴趣在 HelpSteer2 中复制奖励建模训练,请改为按照以下步骤操作。
python /opt/NeMo-Aligner/examples/nlp/data/steerlm/preprocess_helpsteer2_data.py --output_directory=data/helpsteer2
python /opt/NeMo-Aligner/examples/nlp/data/steerlm/process_to_regression_format.py \
--input-file=data/helpsteer2/train.jsonl \
--output-file=data/helpsteer2/train_reg.jsonl
python /opt/NeMo-Aligner/examples/nlp/data/steerlm/process_to_regression_format.py \
--input-file=data/helpsteer2/val.jsonl \
--output-file=data/helpsteer2/val_reg.jsonl
cat data/helpsteer2/train_reg.jsonl data/helpsteer2/train_reg.jsonl > data/helpsteer2/train_reg_2_epoch.jsonl
如果您有兴趣在 HelpSteer2-Preference 中复制奖励建模训练,请改为按照以下步骤操作。
# for first stage of Reward Model training (i.e. SteerLM Regression)
python /opt/NeMo-Aligner/examples/nlp/data/steerlm/preprocess_helpsteer2_data.py --output_directory=data/helpsteer2-only_helpfulness --only_helpfulness
python /opt/NeMo-Aligner/examples/nlp/data/steerlm/process_to_regression_format.py \
--input-file=data/helpsteer2-only_helpfulness/train.jsonl \
--output-file=data/helpsteer2-only_helpfulness/train_reg.jsonl
python /opt/NeMo-Aligner/examples/nlp/data/steerlm/process_to_regression_format.py \
--input-file=data/helpsteer2-only_helpfulness/val.jsonl \
--output-file=data/helpsteer2-only_helpfulness/val_reg.jsonl
cat data/helpsteer2-only_helpfulness/train_reg.jsonl data/helpsteer2-only_helpfulness/train_reg.jsonl > data/helpsteer2-only_helpfulness/train_reg_2_epoch.jsonl
# for second stage of Reward Model training (i.e. Scaled Bradley Terry)
python /opt/NeMo-Aligner/examples/nlp/data/steerlm/preprocess_helpsteer2_data.py --output_directory=data/helpsteer2-pref -pref
python /opt/NeMo-Aligner/examples/nlp/data/steerlm/process_to_regression_format.py \
--input-file=data/helpsteer2-pref/train.jsonl \
--output-file=data/helpsteer2-pref/train_reg.jsonl
python /opt/NeMo-Aligner/examples/nlp/data/steerlm/process_to_regression_format.py \
--input-file=data/helpsteer2-pref/val.jsonl \
--output-file=data/helpsteer2-pref/val_reg.jsonl
在 OASST+HelpSteer 数据上训练回归奖励模型#
在本教程中,您将训练回归奖励模型 800 步。
注意
根据您使用的集群类型,您可能需要在集群环境中设置多节点训练。有关详细信息,请参阅 https://lightning.ai/docs/pytorch/stable/clouds/cluster.html。
python /opt/NeMo-Aligner/examples/nlp/gpt/train_reward_model.py \
trainer.num_nodes=32 \
trainer.devices=8 \
++model.micro_batch_size=2 \
++model.global_batch_size=512 \
++model.data.data_impl=jsonl \
pretrained_checkpoint.restore_from_path=/models/llama13b/llama13b.nemo \
"model.data.data_prefix={train: ["data/merge_train_reg.jsonl"], validation: ["data/merge_val_reg.jsonl"], test: ["data/merge_val_reg.jsonl"]}" \
exp_manager.explicit_log_dir=/results/reward_model_13b \
trainer.rm.val_check_interval=10 \
exp_manager.create_wandb_logger=True \
exp_manager.wandb_logger_kwargs.project=steerlm \
exp_manager.wandb_logger_kwargs.name=rm_training \
trainer.rm.save_interval=10 \
trainer.rm.max_steps=800 \
++model.tensor_model_parallel_size=4 \
++model.pipeline_model_parallel_size=1 \
++model.activations_checkpoint_granularity="selective" \
model.optim.sched.constant_steps=0 \
model.reward_model_type="regression" \
model.regression.num_attributes=9
如果您有兴趣在 HelpSteer2 中复制奖励建模训练,请改为按照以下步骤操作。
python /opt/NeMo-Aligner/examples/nlp/gpt/train_reward_model.py \
trainer.num_nodes=8 \
trainer.devices=8 \
++model.micro_batch_size=2 \
++model.global_batch_size=128 \
++model.data.data_impl=jsonl \
pretrained_checkpoint.restore_from_path=/models/llama-3-70b.nemo \
"model.data.data_prefix={train: ["data/helpsteer2/train_reg_2_epoch.jsonl"], validation: ["data/helpsteer2/val_reg.jsonl"], test: ["data/helpsteer2/val_reg.jsonl"]}" \
exp_manager.explicit_log_dir=/results/reward_model_13b \
trainer.rm.val_check_interval=10 \
exp_manager.create_wandb_logger=True \
exp_manager.wandb_logger_kwargs.project=steerlm \
exp_manager.wandb_logger_kwargs.name=rm_training \
trainer.rm.save_interval=10 \
trainer.rm.max_steps=317 \
++model.tensor_model_parallel_size=8 \
++model.pipeline_model_parallel_size=2 \
++model.activations_checkpoint_method="uniform" \
++model.activations_checkpoint_num_layers=1 \
++model.sequence_parallel=False \
model.optim.sched.constant_steps=0 \
model.optim.sched.warmup_steps=10 \
model.reward_model_type="regression" \
model.optim.lr=2e-6 \
model.optim.sched.min_lr=2e-6 \
model.regression.num_attributes=9
如果您有兴趣在 HelpSteer2-Preference 中复制奖励建模训练,请改为按照以下步骤操作。
python /opt/NeMo-Aligner/examples/nlp/gpt/train_reward_model.py \
trainer.num_nodes=8 \
trainer.devices=8 \
++model.micro_batch_size=2 \
++model.global_batch_size=128 \
++model.data.data_impl=jsonl \
pretrained_checkpoint.restore_from_path=/models/llama-3.1-70b-instruct.nemo \
"model.data.data_prefix={train: ["data/helpsteer2-only_helpfulness/train_reg_2_epoch.jsonl"], validation: ["data/helpsteer2-only_helpfulness/val_reg.jsonl"], test: ["data/helpsteer2-only_helpfulness/val_reg.jsonl"]}" \
exp_manager.explicit_log_dir=/results/helpsteer2-only_helpfulness-llama-3.1-70b-instruct \
trainer.rm.val_check_interval=10 \
exp_manager.create_wandb_logger=True \
exp_manager.wandb_logger_kwargs.project=steerlm \
exp_manager.wandb_logger_kwargs.name=rm_training \
trainer.rm.save_interval=10 \
trainer.rm.max_steps=317 \
++model.tensor_model_parallel_size=8 \
++model.pipeline_model_parallel_size=2 \
++model.activations_checkpoint_method="uniform" \
++model.activations_checkpoint_num_layers=1 \
++model.sequence_parallel=False \
model.optim.sched.constant_steps=0 \
model.optim.sched.warmup_steps=10 \
model.reward_model_type="regression" \
model.optim.lr=2e-6 \
model.optim.sched.min_lr=2e-6 \
model.regression.num_attributes=9
python /opt/NeMo-Aligner/examples/nlp/gpt/train_reward_model.py \
trainer.num_nodes=4 \
trainer.devices=8 \
++model.micro_batch_size=2 \
++model.global_batch_size=128 \
++model.data.data_impl=jsonl \
pretrained_checkpoint.restore_from_path=/results/helpsteer2-only_helpfulness-llama-3.1-70b-instruct/checkpoints/megatron_gpt.nemo \
"model.data.data_prefix={train: ["data/helpsteer2-pref/train_reg.jsonl"], validation: ["data/helpsteer2-pref/val_reg.jsonl"], test: ["data/helpsteer2-pref/val_reg.jsonl"]}" \
exp_manager.explicit_log_dir=/results/helpsteer2-only_helpfulness-llama-3.1-70b-instruct-then-scaled-bt \
trainer.rm.val_check_interval=10 \
exp_manager.create_wandb_logger=True \
exp_manager.wandb_logger_kwargs.project=steerlm \
exp_manager.wandb_logger_kwargs.name=rm_training \
trainer.rm.save_interval=10 \
trainer.rm.max_steps=105 \
++model.tensor_model_parallel_size=8 \
++model.pipeline_model_parallel_size=4 \
++model.activations_checkpoint_method="uniform" \
++model.activations_checkpoint_num_layers=1 \
++model.sequence_parallel=False \
model.optim.sched.constant_steps=0 \
model.optim.sched.warmup_steps=10 \
model.reward_model_type="regression" \
trainer.rm.train_random_sampler=False \
model.regression.loss_func=scaled_bt \
model.regression.load_rm_head_weights=True \
model.optim.lr=1e-6 \
model.optim.sched.min_lr=1e-6 \
model.regression.num_attributes=9
生成注释#
要生成注释,请在后台运行以下命令以启动推理服务器
python /opt/NeMo-Aligner/examples/nlp/gpt/serve_reward_model.py \ rm_model_file=/results/reward_model_13b/checkpoints/megatron_gpt.nemo \ trainer.num_nodes=1 \ trainer.devices=8 \ ++model.tensor_model_parallel_size=4 \ ++model.pipeline_model_parallel_size=1 \ inference.micro_batch_size=2 \ inference.port=1424
执行以下代码
python /opt/NeMo-Aligner/examples/nlp/data/steerlm/attribute_annotate.py \ --input-file=data/oasst/train.jsonl \ --output-file=data/oasst/train_labeled.jsonl \ --port=1424 python /opt/NeMo-Aligner/examples/nlp/data/steerlm/attribute_annotate.py \ --input-file=data/oasst/val.jsonl \ --output-file=data/oasst/val_labeled.jsonl \ --port=1424 cat data/oasst/train_labeled.jsonl data/oasst/train_labeled.jsonl > data/oasst/train_labeled_2ep.jsonl
训练属性条件 SFT 模型#
就本教程而言,属性条件 SFT 模型训练了 800 步。
python examples/nlp/gpt/train_gpt_sft.py \
trainer.num_nodes=32 \
trainer.devices=8 \
trainer.precision=bf16 \
trainer.sft.limit_val_batches=40 \
trainer.sft.max_epochs=1 \
trainer.sft.max_steps=800 \
trainer.sft.val_check_interval=800 \
trainer.sft.save_interval=800 \
model.megatron_amp_O2=True \
model.restore_from_path=/models/llama70b \
model.tensor_model_parallel_size=8 \
model.pipeline_model_parallel_size=2 \
model.optim.lr=6e-6 \
model.optim.name=distributed_fused_adam \
model.optim.weight_decay=0.01 \
model.optim.sched.constant_steps=200 \
model.optim.sched.warmup_steps=1 \
model.optim.sched.min_lr=5e-6 \
model.answer_only_loss=True \
model.activations_checkpoint_granularity=selective \
model.activations_checkpoint_method=uniform \
model.data.chat=True \
model.data.num_workers=0 \
model.data.chat_prompt_tokens.system_turn_start=\'\<extra_id_0\>\' \
model.data.chat_prompt_tokens.turn_start=\'\<extra_id_1\>\' \
model.data.chat_prompt_tokens.label_start=\'\<extra_id_2\>\' \
model.data.train_ds.max_seq_length=4096 \
model.data.train_ds.micro_batch_size=1 \
model.data.train_ds.global_batch_size=128 \
model.data.train_ds.file_path=data/oasst/train_labeled_2ep.jsonl \
model.data.train_ds.index_mapping_dir=/indexmap_dir \
model.data.train_ds.add_eos=False \
model.data.train_ds.hf_dataset=True \
model.data.validation_ds.max_seq_length=4096 \
model.data.validation_ds.file_path=data/oasst/val_labeled.jsonl \
model.data.validation_ds.micro_batch_size=1 \
model.data.validation_ds.global_batch_size=128 \
model.data.validation_ds.index_mapping_dir=/indexmap_dir \
model.data.validation_ds.add_eos=False \
model.data.validation_ds.hf_dataset=True \
exp_manager.create_wandb_logger=True \
exp_manager.wandb_logger_kwargs.project=steerlm \
exp_manager.wandb_logger_kwargs.name=acsft_training \
exp_manager.explicit_log_dir=/results/acsft_70b \
exp_manager.checkpoint_callback_params.save_nemo_on_train_end=True
运行推理#
要开始推理,请使用以下命令在后台运行推理服务器
python /opt/NeMo/examples/nlp/language_modeling/megatron_gpt_eval.py \ gpt_model_file=/results/acsft_70b/checkpoints/megatron_gpt_sft.nemo \ pipeline_model_parallel_split_rank=0 \ server=True \ tensor_model_parallel_size=8 \ pipeline_model_parallel_size=1 \ trainer.precision=bf16 \ trainer.devices=8 \ trainer.num_nodes=1 \ web_server=False \ port=1427
请等待服务器准备就绪后再继续。
创建 Python 辅助函数
import requests from collections import OrderedDict def get_answer(question, max_tokens, values, eval_port=1427): prompt = ( "<extra_id_0>System\nA chat between a curious user and an artificial intelligence assistant. " "The assistant gives helpful, detailed, and polite answers to the user's questions.\n" "<extra_id_1>User\n{question}\n<extra_id_1>Assistant\n<extra_id_2>{values}\n" ) prompts = [prompt.format(question=question, values=values)] data = { "sentences": prompts, "tokens_to_generate": max_tokens, "top_k": 1, "greedy": True, "end_strings": ["<extra_id_1>"], } url = f"http://127.0.0.1:{eval_port}/generate" response = requests.put(url, json=data) json_response = response.json() response_sentence = json_response["sentences"][0][len(prompt):] return response_sentence
def encode_labels(labels): return ",".join(f"{key}:{value}" for key, value in labels.items())
更改以下值以引导语言模型
values = OrderedDict( [ ("quality", 4), ("toxicity", 0), ("humor", 0), ("creativity", 0), ("helpfulness", 4), ("correctness", 4), ("coherence", 4), ("complexity", 4), ("verbosity", 4), ] ) values = encode_labels(values)
提问并生成响应
question = "Write a poem on NVIDIA in the style of Shakespeare" print(get_answer(question, 512, values))
响应如下所示。
""" In days of yore, in tech's great hall, A company arose, NVIDIA its call. With graphics cards, it did astound, And gaming world with awe did abound. But NVIDIA's reach far more than play, Its GPUs now deep learning's sway. With neural nets and data vast, AI's rise, it did forecast. From self-driving cars to medical scans, Its tech now touches all life's plans. With each new day, its impact grows, In science, research, and industry's prose. So here's to NVIDIA, whose name we praise, For tech that captivates in countless ways. With Shakespearean verse, we now impart, Our thanks and admiration from the heart. <extra_id_1> """
注意
本教程仅涵盖阶段 1-3:训练价值模型、生成注释和初始 SteerLM 模型训练。阶段 4 通过采样以高质量数据为条件的响应来引导 SteerLM 模型,但在本教程中为了简单起见而被忽略。
SteerLM:用于简单且可控模型对齐的新颖技术#
SteerLM 提供了一种新颖的技术,用于以可控的方式实现与人类偏好对齐的新一代 AI 系统。其概念上的简洁性、性能提升和可定制性突出了用户可控 AI 的变革性可能性。要了解更多信息,请查看我们的论文 SteerLM:作为 RLHF 的(用户可控)替代方案的属性条件 SFT。