重要
您正在查看 NeMo 2.0 文档。此版本对 API 和新的库 NeMo Run 进行了重大更改。我们目前正在将 NeMo 1.0 的所有功能移植到 2.0。有关先前版本或 2.0 中尚不可用的功能的文档,请参阅 NeMo 24.07 文档。
ViT#
模型介绍#
Vision Transformer,通常称为 ViT [VISION-MODELS-VIT1],是 NeMo 中图像分类任务的基础模型。与传统的卷积神经网络不同,ViT 采用类似 Transformer 的架构来处理图像数据。在这种方法中,图像被分成固定大小的块,通常为 14x14 或 16x16。这些块被线性嵌入并使用位置嵌入进行增强。生成的向量序列通过标准 Transformer 编码器传递。为了方便分类,可学习的“分类令牌”被合并到序列中。
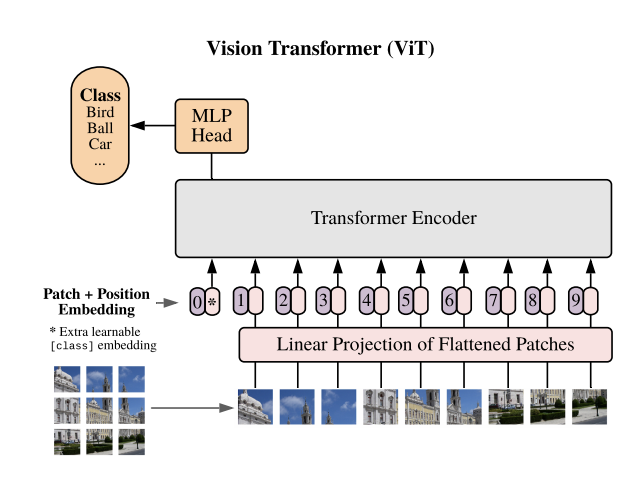
ViT 模型可以使用 MegatronVitClassificationModel 类来实例化。
Transformer 编码器#
NeMo 的 ViT 模型实现利用其并行 Transformer 实现,特别是 nemo.collections.nlp.modules.common.megatron.transformer.ParallelTransformer,以在 Transformer 编码器中启用模型并行性支持。这种设计选择确保了训练期间资源的高效扩展和利用。
模型 |
模型大小 (M) |
隐藏层大小 |
FFN_dim |
注意力头数 |
层数 |
PatchDim |
批次数 (Seq) |
B/16 |
86 |
768 |
3072 |
12 |
12 |
16 |
204 |
L/16 |
303 |
1024 |
4096 |
16 |
24 |
16 |
204 |
H/16 |
632 |
1280 |
5120 |
16 |
32 |
16 |
204 |
H/14 |
632 |
1280 |
5120 |
16 |
32 |
14 |
264 |
g/14 |
1011 |
1408 |
6144 |
16 |
40 |
14 |
264 |
G/14 |
1843 |
1664 |
8192 |
16 |
48 |
14 |
264 |
模型配置#
Transformer 编码器#
encoder_seq_length: 196
max_position_embeddings: ${.encoder_seq_length}
num_layers: 12
hidden_size: 768
ffn_hidden_size: 3072
num_attention_heads: 12
hidden_dropout: 0.1
attention_dropout: 0.
encoder_seq_length:Transformer 编码器的序列长度。num_layers、hidden_size、ffn_hidden_size、num_attention_heads:定义文本 Transformer 架构的参数。ffn_hidden_size通常是hidden_size的 4 倍。hidden_dropout和attention_dropout:Transformer 中隐藏状态和注意力的 Dropout 概率。
Patch & 位置嵌入#
vision_pretraining_type: "classify"
num_classes: 1000
patch_dim: 16
img_h: 224
img_w: 224
num_channels: 3
vision_pretraining_type:MLP 头的类型,目前支持仅限于分类任务num_classes:用于分类的标签数量patch_dim:图像被分割成的块的大小。img_h和img_w:输入图像的高度和宽度。num_channels:输入图像中的通道数(例如,RGB 图像为 3)。
优化#
功能 |
描述 |
启用方式 |
|---|---|---|
数据并行 |
数据集在多个 GPU 或节点上并发读取,从而加快数据加载和处理速度。 |
在多 GPU/节点上训练时自动启用 |
张量并行 |
每个张量被分成多个块,从而实现跨 GPU 的水平并行。这种称为 TensorParallel (TP) 的技术将模型的张量分布在多个 GPU 上。在处理过程中,每个分片在不同的 GPU 上分别并行处理,结果在步骤结束时同步。这种方法受到 NVIDIA Megatron 实现的启发。[参考](NVIDIA/Megatron-LM) |
|
激活检查点 |
为了减少内存使用,某些层的激活在反向传播期间被清除并重新计算。这种技术对于训练无法使用传统方法放入 GPU 内存的大型模型特别有用。 |
|
Bfloat16 训练 |
训练以 Bfloat16 精度进行,这在 FP32 的更高精度与 FP16 的内存节省和速度之间提供了平衡。 |
|
BF16 O2 |
启用 O2 级别的自动混合精度,优化 Bfloat16 精度以获得更好的性能。 |
|
分布式优化器 |
优化过程分布在多个 GPU 上,从而降低内存需求。这种技术将优化器状态分布在数据并行 ranks 之间,而不是复制它,从而显着节省内存。这种方法受到论文“ZeRO: Memory Optimizations Toward Training Trillion Parameter Models”中描述的 ZeRO 优化以及 NVIDIA Megatron 中的实现的启发。[参考](NVIDIA/Megatron-LM) |
|
Flash Attention V2 |
FlashAttention 是一种快速且内存高效的算法,用于计算精确注意力。它通过 IO 感知来加速模型训练并减少内存需求。这种方法对于大规模模型特别有用,并在链接的存储库中进一步详细介绍。[参考](Dao-AILab/flash-attention) |
|
模型训练#
以下是我们使用的训练和微调配方的重点
Model: ViT B/16
Dataset: ImageNet 1K
Pretraining:
Epochs: 300
Batch Size: 4096
Training Resolution: 224
Optimizer: Adam (0.9, 0.999)
Base Learning Rate: 3.00E-03
Learning Rate Decay: Cosine
Weight Decay: 0.3
Dropout: 0.1
Fine-tuning:
Steps: 20,000
Batch Size: 512
Fine-tuning Resolution: 512
Optimizer: SGD (0.9)
Base Learning Rate: 0.003 - 0.06
Learning Rate Decay: Cosine
Weight Decay: 0
参考#
Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily Denton, Seyed Kamyar Seyed Ghasemipour, Burcu Karagol Ayan, S. Sara Mahdavi, Rapha Gontijo Lopes, Tim Salimans, Jonathan Ho, David J Fleet 和 Mohammad Norouzi。具有深度语言理解的逼真文本到图像扩散模型。2022。arXiv:2205.11487。