重要提示
您正在查看 NeMo 2.0 文档。此版本引入了 API 的重大更改和一个新的库 NeMo Run。我们目前正在将 NeMo 1.0 中的所有功能移植到 2.0。有关先前版本或 2.0 中尚不可用的功能的文档,请参阅 NeMo 24.07 文档。
Adapters#
在 NeMo 中,我们经常训练模型并针对特定任务对其进行微调。当模型只有几百万个参数时,这是一种合理的方法。然而,当参数接近数亿甚至数十亿时,这种方法很快变得不可行。作为这种情况的潜在解决方案(微调大型模型不再可行),我们转向 Adapters [[adapters1]] 以使我们的模型专门用于特定领域或任务。Adapters 需要的参数总数仅为原始模型的一小部分,并且微调效率更高。
注意
有关向任何 PyTorch 模块添加 Adapter 支持的详细教程,请参阅 NeMo Adapters 教程。
什么是 Adapters?#
Adapters 是一个简单的概念 - 下图显示了一种公式。最简单的形式,它们是残差前馈层,将输入维度 (\(D\)) 压缩到小的瓶颈维度 (\(H\)),使得 \(R^D \text{->} R^H\),计算激活函数(例如 ReLU),最后使用另一个前馈层映射 \(R^H \text{->} R^D\)。然后,此输出通过简单的残差连接添加到输入中。
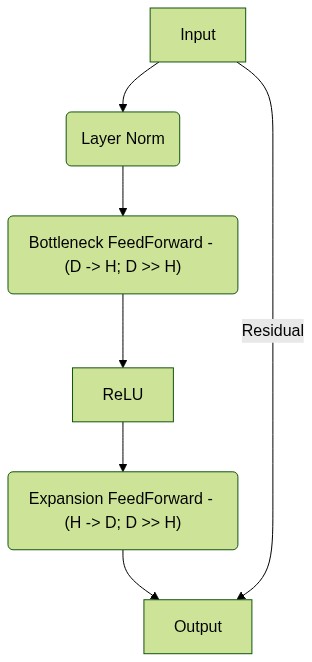
像这样的 Adapter 模块通常会初始化,使得 adapter 的初始输出始终为零,以防止由于添加此类模块而导致原始模型性能下降。
带有 Adapters 的 torch.nn.Module#
在 NeMo 中,Adapters 通过 Mixin 类支持,该类可以附加到任何 torch.nn.Module。这样的模块将具有多个附加方法,这些方法将在此模块中启用 adapter 功能。
# Import the adapter mixin from NeMo
from nemo.core import adapter_mixins
# NOTE: See the *two* classes being inherited here !
class MyModule(torch.nn.Module, adapter_mixins.AdapterModuleMixin):
pass
AdapterModuleMixin#
让我们看看 AdapterModuleMixin 为通用 PyTorch 模块添加了什么。下面列出了一些最重要的必需方法
add_adapter:用于向模块添加具有唯一名称的 adapter。get_enabled_adapters:返回所有已启用 adapter 模块的名称列表。set_enabled_adapters:设置是启用还是禁用单个(或所有)adapter。is_adapter_available:检查是否有任何 adapter 可用且已启用。
扩展此 mixin 的模块通常可以直接使用这些方法,而无需扩展它们,但我们将在下面介绍您可能希望扩展这些方法的情况。
- class nemo.core.adapter_mixins.AdapterModuleMixin#
基类:
ABC通用 Adapter Mixin,可以使用 Adapter 模块支持来增强任何 torch.nn.Module。
此 mixin 类添加了一种分层方式,可将任何类型的 Adapter 模块添加到预先存在的模块。由于模型本质上也是 nn.Module,因此可以将此 mixin 附加到任何模型或模块。此 mixin 类添加了多个实用程序方法,这些方法可以根据需要使用或覆盖。
Adapter 模块是任何具有以下几个属性的 Pytorch nn.Module
它的输入和输出维度相同,而隐藏维度不必相同。
- Adapter 模块的最后一层已初始化为零,以便与 adapter 的残差连接
产生原始输出。
此 mixin 将以下实例变量添加到继承它的类中
- adapter_layer:一个 torch.nn.ModuleDict(),其键是 adapter 的名称(全局唯一),
值是 Adapter nn.Module()。
adapter_cfg:一个 OmegaConf DictConfig 对象,其中包含已初始化的 adapter 的配置。
- adapter_name:一个 str 解析的名称,它是全局唯一的键,但多个模块可以共享
此名称。
- adapter_global_cfg_key:一个 str,表示模型配置中可由用户提供的键。
该值解析为 global_cfg,可以通过 model.cfg.adapters.global_cfg.* 覆盖。
- adapter_metadata_cfg_key:一个 str,表示模型配置中用于保留
adapter 配置的元数据的键。
注意
此模块不负责维护其配置。子类必须确保根据需要更新或保留配置。子类有责任将最新的配置传播到较低层。
- adapter_global_cfg_key = 'global_cfg'#
- adapter_metadata_cfg_key = 'adapter_meta_cfg'#
- add_adapter(
- name: str,
- cfg: omegaconf.DictConfig | AdapterConfig,
- **kwargs,
向此模块添加 Adapter 模块。
- 参数:
name – adapter 的全局唯一名称。将用于访问、启用和禁用 adapter。
cfg – 包含最基本 __target__ 以实例化新 Adapter 模块的 DictConfig 或 Dataclass。
- is_adapter_available() bool#
检查是否已实例化任何 Adapter 模块。
- 返回:
bool,确定是否已实例化任何 Adapter 模块。即使 adapter 已启用或禁用,也返回 true,仅当不存在 adapter 时才返回 false。
- set_enabled_adapters(
- name: str | None = None,
- enabled: bool = True,
更新了内部 adapter 配置,确定是启用还是禁用 adapter(或所有 adapter)。
常见的用户模式是禁用所有 adapter(在添加它们之后或恢复带有预先存在的 adapter 的模型之后),然后仅启用其中一个 adapter。
module.set_enabled_adapters(enabled=False) module.set_enabled_adapters(name=<some adapter name>, enabled=True)
- 参数:
name – 可选 str。如果给定 str 名称,则配置将更新为 enabled 的值。如果未给定名称,则将启用/禁用所有 adapter。
enabled – Bool,确定是否启用/禁用 adapter。
- get_enabled_adapters() List[str]#
返回所有已启用 adapter 名称的列表。名称将始终是已解析的名称,不包含模块信息。
- 返回:
每个已启用 adapter 名称的 str 名称列表。
- get_adapter_module(name: str)#
如果可能,按名称获取 adapter 模块,否则返回 None。
- 参数:
name – 与 Adapter 对应的 str 名称(已解析或未解析)。
- 返回:
如果可以解析和匹配名称,则为 nn.Module,否则为 None/
- get_adapter_cfg(name: str)#
与 get_adapter_module 相同的逻辑,但用于获取配置
- set_accepted_adapter_types(
- adapter_types: List[type | str],
具有此 mixin 的模块可以定义它将接受的 adapter 名称列表。应在模块的 init 方法中调用此方法,并设置模块期望添加的 adapter 名称。
- 参数:
adapter_types – 与类对应的 str 路径列表。将实例化类路径以确保类路径正确。
- get_accepted_adapter_types() Set[type]#
用于获取模块接受的所有类集的实用程序函数。
- 返回:
返回接受的 adapter 类型集(作为类),否则返回空集。
- unfreeze_enabled_adapters(
- freeze_batchnorm: bool = True,
用于仅解冻已启用 Adapter 模块的实用程序方法。
常见的用户模式是冻结所有模块(包括所有 adapter),然后仅解冻所需的 adapter。
module.freeze() # only available to nemo.core.NeuralModule ! module.unfreeze_enabled_adapters()
- 参数:
freeze_batchnorm – 冻结任何和所有 BatchNorm*D 层的移动平均缓冲区更新的可选(和推荐)做法。这对于确保禁用所有 adapter 将精确地产生原始(基础)模型的输出是必要的。
- forward_enabled_adapters(input: torch.Tensor)#
使用提供的输入逐个转发所有活动 adapter,并将每个 adapter 层的输出链接到下一个。
在计算 adapter 的输出以及该输出如何与原始输入合并时,利用每个 adapter 的隐式合并策略。
- 参数:
input – 调用模块的输出张量是第一个 adapter 的输入,其输出然后链接到下一个 adapter,直到消耗完所有 adapter。
- 返回:
所有活动 adapter 完成其前向传递后的结果张量。
- resolve_adapter_module_name_(
- name: str,
用于将给定的全局/模块 adapter 名称解析为其组件的实用程序方法。始终返回表示(module_name,adapter_name)的元组。“:”用作分隔符,用于表示模块名称与 adapter 名称。
如果元数据配置存在以供访问,则还将尝试将给定的 adapter_name 单独解析回(module_name,adapter_name)。
- 参数:
name – 全局 adapter 或模块 adapter 名称(结构为 module_name:adapter_name)。
- 返回:
表示(module_name,adapter_name)的元组。如果提供全局 adapter,则 module_name 设置为 ''。
- forward_single_enabled_adapter_(
- input: torch.Tensor,
- adapter_module: torch.nn.Module,
- *,
- adapter_name: str,
- adapter_strategy: nemo.core.classes.mixins.adapter_mixin_strategies.AbstractAdapterStrategy,
对某些输入数据执行单个 adapter 模块的前向步骤。
注意
子类可以覆盖此方法以适应更复杂的 adapter 前向步骤。
- 参数:
input – input:调用模块的输出张量是第一个 adapter 的输入,其输出然后链接到下一个 adapter,直到消耗完所有 adapter。
adapter_module – 当前需要执行前向传递的 adapter 模块。
adapter_name – 正在进行当前前向传递的 adapter 的已解析名称。
adapter_strategy – AbstractAdapterStrategy 的子类,它确定 adapter 的输出应如何与输入合并,或者是否应合并。
- 返回:
当前活动 adapter 完成其前向传递后的结果张量。
- check_supported_adapter_type_(
- adapter_cfg: omegaconf.DictConfig,
- supported_adapter_types: Iterable[type] | None = None,
用于检查 adapter 模块是否为模块支持的类型的实用程序方法。
子类应调用此方法以确保 adapter 模块是受支持的类型。
使用 Adapter 模块#
现在 MyModule 支持 adapter,我们可以轻松添加 adapter、设置其状态、检查它们是否可用并执行其前向传递。请注意,如果启用了多个 adapter,则会以链式方式调用它们,前一个 adapter 的输出将作为输入传递给下一个 adapter,依此类推。
# Import the adapter mixin and modules from NeMo
import torch
from nemo.core import adapter_mixins
from nemo.collections.common.parts import adapter_modules
class MyModule(torch.nn.Module, adapter_mixins.AdapterModuleMixin):
def forward(self, x: torch.Tensor) -> torch.Tensor:
output = self.layers(x) # assume self.layers is some Sequential() module
if self.is_adapter_available(): # check if adapters were added or not
output = self.forward_enabled_adapters() # perform the forward of all enabled adapters in a chain
return output
# Now let us create a module, add an adapter and do a forward pass with some random inputs
module = MyModule(dim) # assume dim is some input and output dimension of the module.
# Add an adapter
module.add_adapter("first_adapter", cfg=adapter_modules.LinearAdapter(in_features=dim, dim=5))
# Check if adapter is available
module.is_adapter_available() # returns True
# Check the name(s) of the enabled adapters
module.get_enabled_adapters() # returns ['first_adapter']
# Set the state of the adapter (by name)
module.set_enabled_adapters(name="first_adapter", enabled=True)
# Freeze all the weights of the original module (equivalent to calling module.freeze() for a NeuralModule)
for param in module.parameters():
param.requires_grad = False
# Unfreeze only the adapter weights (so that we finetune only the adapters and not the original weights !)
module.unfreeze_enabled_adapters()
# Now you can train this model's adapters !
input_data = torch.randn(4, dim) # assume dim is the input-output dim of the module
outputs_with_adapter = module(input_data)
# Compute loss and backward ...
Adapter 兼容模型#
如果目标是在单个模块中支持 adapter,则目标已完成。然而,在现实世界中,我们使用多个模块构建大型复合模型,并将它们组合起来以构建最终模型,然后我们对其进行训练。我们使用 AdapterModelPTMixin 来做到这一点。
注意
有关支持分层 adapter 模块的深入指南,请参阅 NeMo Adapters 教程。
- class nemo.core.adapter_mixins.AdapterModelPTMixin#
-
Adapter Mixin,可以使用 Adapter 支持来增强 ModelPT 子类。
此 mixin 类应仅与顶级 ModelPT 子类一起使用。此 mixin 类添加了多个实用程序方法,这些方法应进行子类化和覆盖,以便根据需要传播到子模块。
Adapter 模块是任何具有以下几个属性的 Pytorch nn.Module
它的输入和输出维度相同,而隐藏维度不必相同。
- Adapter 模块的最后一层已初始化为零,以便与 adapter 的残差连接
产生原始输出。
此 mixin 将以下实例变量添加到继承它的类中
- adapter_layer:一个 torch.nn.ModuleDict(),其键是 adapter 的名称(全局唯一),
值是 Adapter nn.Module()。
adapter_cfg:一个 OmegaConf DictConfig 对象,其中包含已初始化的 adapter 的配置。
adapter_global_cfg_key:一个 str,表示模型配置中可由用户提供的键。该值解析为 global_cfg,可以通过 model.cfg.adapters.global_cfg.* 覆盖。
注意
此模块负责维护其配置。在 ModelPT 级别,它将访问 Adapter 配置信息并将其写入 self.cfg.adapters。
- setup_adapters()#
在 ASR ModelPT 实现构造函数中调用的实用程序方法,以便恢复先前添加的任何 adapter。
应由子类覆盖以执行其他必要的设置步骤。
此方法应在构造函数时仅调用一次。
- add_adapter(
- name: str,
- cfg: omegaconf.DictConfig | AdapterConfig,
向此模型添加 Adapter 模块。
应由子类覆盖,并且必须使用 super() 调用 - 这将设置配置。调用 super() 后,将此调用转发到实现 mixin 的模块。
- 参数:
name – adapter 的全局唯一名称。将用于访问、启用和禁用 adapter。
cfg – 包含最基本 __target__ 以实例化新 Adapter 模块的 DictConfig。
- is_adapter_available() bool#
检查是否已实例化任何 Adapter 模块。
应由子类覆盖。
- 返回:
bool,确定是否已实例化任何 Adapter 模块。即使 adapter 已启用或禁用,也返回 true,仅当不存在 adapter 时才返回 false。
- set_enabled_adapters(
- name: str | None = None,
- enabled: bool = True,
更新了内部 adapter 配置,确定是启用还是禁用 adapter(或所有 adapter)。
常见的用户模式是禁用所有 adapter(在添加它们之后或恢复带有预先存在的 adapter 的模型之后),然后仅启用其中一个 adapter。
应由子类覆盖,并且必须使用 super() 调用 - 这将设置配置。调用 super() 后,将此调用转发到实现 mixin 的模块。
model.set_enabled_adapters(enabled=False) model.set_enabled_adapters(name=<some adapter name>, enabled=True)
- 参数:
name – 可选 str。如果给定 str 名称,则配置将更新为 enabled 的值。如果未给定名称,则将启用/禁用所有 adapter。
enabled – Bool,确定是否启用/禁用 adapter。
- get_enabled_adapters() List[str]#
返回所有已启用 adapter 的列表。
应由子类实现。
- 返回:
每个已启用 adapter 的 str 名称列表。
- check_valid_model_with_adapter_support_()#
用于测试此 mixin 的子类是否为 ModelPT 本身的适当子类的实用程序方法。
应由子类实现。
- save_adapters(
- filepath: str,
- name: str | None = None,
用于仅保存 adapter 模块,而不保存整个模型本身的实用程序方法。这允许共享 adapter,adapter 通常只是完整模型大小的一小部分,从而更容易交付。
注意
保存的文件是 pytorch 兼容的 pickle 文件,其中包含 adapter 的状态字典以及 adapter 配置的二进制表示形式。
- 参数:
filepath – str 文件路径,其中 .pt 文件将包含 adapter 状态字典。
name – 将保存到此文件的 adapter 的可选名称。如果未传递 None,则所有 adapter 将保存到该文件。名称可以是全局名称 (adapter_name) 或模块级名称 (module:adapter_name)。
- load_adapters(
- filepath: str,
- name: str | None = None,
- map_location: str | None = None,
- strict: bool = True,
用于仅恢复 adapter 模块,而不恢复整个模型本身的实用程序方法。这允许共享 adapter,adapter 通常只是完整模型大小的一小部分,从而更容易交付。
注意
在恢复期间,假定模型当前尚不具有具有名称(如果提供)的 adapter,或者任何与状态字典的模块共享名称的 adapter(如果未提供名称)。这是为了确保每个 adapter 名称在模型中都是全局唯一的。
- 参数:
filepath – .pt 文件的文件路径。
name – 将保存到此文件的 adapter 的可选名称。如果未传递 None,则所有 adapter 将保存到该文件。名称必须是全局名称 (adapter_name) 或模块级名称 (module:adapter_name),以完全匹配状态字典。
map_location – Pytorch 标志,用于放置 adapter 状态字典。
strict – Pytorch 标志,指示是否严格加载 adapter 的权重。
- update_adapter_cfg(cfg: omegaconf.DictConfig)#
用于使用提供的配置递归更新所有 Adapter 模块配置的实用程序方法。
注意
它不是(深)复制,而是引用复制。对配置所做的更改将反映到 adapter 子模块,但仍然鼓励使用此方法显式更新 adapter_cfg。
- 参数:
cfg – 包含 model.cfg.adapters 值的 DictConfig。
- replace_adapter_compatible_modules(
- update_config: bool = True,
- verbose: bool = True,
用于替换所有带有 Adapter 变体的子模块(如果存在)的实用程序方法。不递归遍历子模块的子模块(仅限直接子模块)。
- 参数:
update_config – 确定是否应更新配置的标志。
verbose – 确定方法是否应记录所做更改的标志。
- property adapter_module_names: List[str]#
模型支持的有效适配器模块的列表。
注意
子类应该重写此属性并返回一个 str 名称列表,其中包含它们支持的所有模块,这将使用户能够确定适配器模块的放置位置。
- 返回:
一个 str 列表,每个元素对应一个受支持的适配器模块。默认情况下,子类应支持“默认适配器”(‘’)。
- property default_adapter_module_name: str | None#
如果提供了 ‘’ 名称,则用作“默认”的适配器模块的名称。
注意
子类应该重写此属性并返回一个 str 名称,表示他们希望指定为默认值的模块。
- 返回:
模块的 str 名称,表示为“默认”适配器;如果为 None,则表示不支持默认适配器。
下面,我们将讨论适配器兼容模型的一些有用功能。
保存 和 恢复 具有 适配器 功能的 模型:任何正确实现此 NeMo 模型的类都可以保存和恢复具有适配器功能的 NeMo 模型,从而允许共享适配器。save_adapters和load_adapters:适配器通常只包含少量参数,因此无需为每个适配器复制整个模型。此方法允许将适配器模块与模型分开存储,以便您可以使用相同的“基础”模型,并仅共享适配器模块。
参考#
Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin De Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. Parameter-efficient transfer learning for nlp. In International Conference on Machine Learning, 2790–2799. PMLR, 2019.