重要提示
您正在查看 NeMo 2.0 文档。此版本引入了 API 的重大更改和一个新的库,NeMo Run。我们目前正在将 NeMo 1.0 中的所有功能移植到 2.0。有关先前版本或 2.0 中尚不可用的功能的文档,请参阅 NeMo 24.07 文档。
DreamFusion#
模型介绍#
DreamFusion [MM-MODELS-DF1] 使用预训练的文本到图像扩散模型来执行文本到 3D 合成。该模型使用基于概率密度蒸馏的损失函数,从而能够使用 2D 扩散模型作为先验来优化参数化图像生成器。
通过在类似 DeepDream 的过程中使用此损失函数,该模型通过梯度下降优化随机初始化的 3D 模型(神经辐射场,或 NeRF),使其从随机角度进行的 2D 渲染实现低损失。给定文本的最终 3D 模型可以从任何角度查看,通过任意照明重新照明,或合成到任何 3D 环境中。这种方法不需要 3D 训练数据,也不需要修改图像扩散模型,这证明了预训练图像扩散模型作为先验的有效性。
可以使用 DreamFusion 类实例化 Dreamfusion 模型。
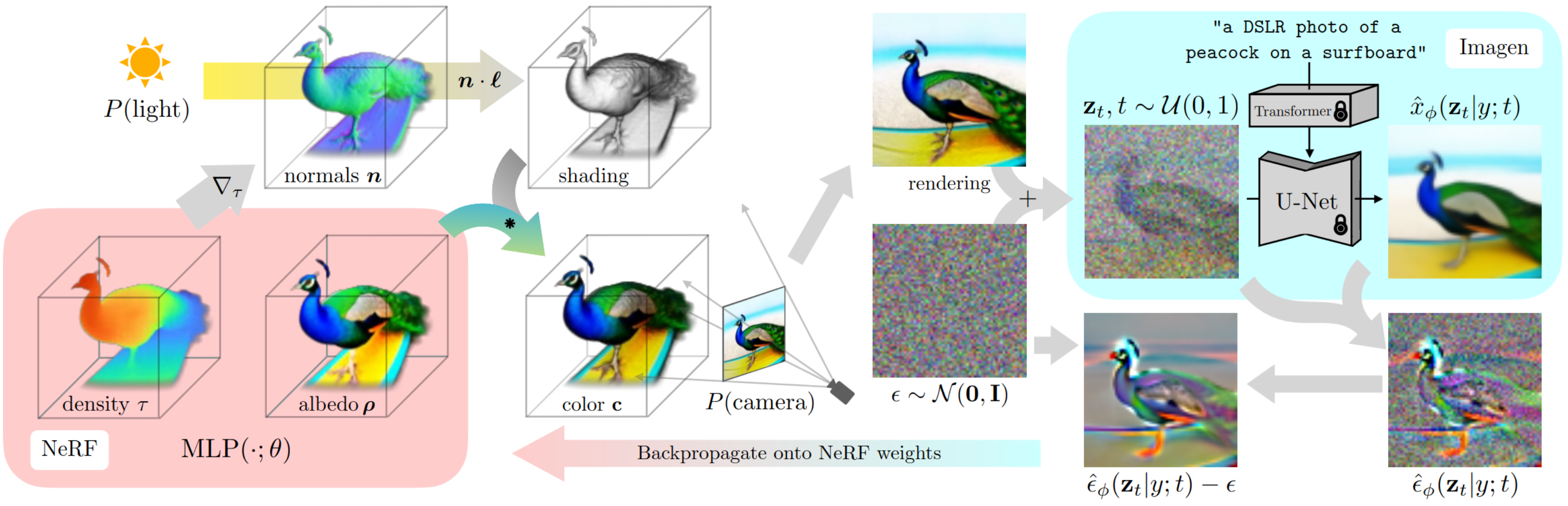
图像引导#
DreamFusion 的这一部分涉及模型将文本输入解释和转换为视觉概念的初始阶段。DreamFusion 利用基于扩散的文本到图像模型,处理文本输入,提取关键视觉元素,并将这些元素转换为初始 2D 图像。此过程确保生成的 3D 模型不仅在文本描述方面准确,而且通过根据视角调节 2D 图像,在视觉上也是连贯且详细的。
NeRF(前景)网络#
神经辐射场网络是 DreamFusion 3D 渲染功能的核心。在 DreamFusion 中,NeRF 网络采用从文本描述生成的 2D 图像并构建 3D 模型。该模型表示为连续的体场景函数,其编码空间中点的颜色和密度,从而实现高度详细和逼真的渲染。
背景层#
DreamFusion 可以利用专用于背景建模的背景层。
在需要动态背景的场景中,DreamFusion 可以配置为使用辅助 NeRF 网络来生成背景。该网络与主 NeRF 网络并行运行,专注于为主场景创建连贯且在上下文中合适的背景。它可以动态调整光照和视角变化,保持与前景模型的一致性。
或者,DreamFusion 允许集成静态背景颜色,这在主要关注生成的对象且需要非干扰性背景的场景中特别有用。实现静态颜色背景涉及设置统一的色值,该色值包含 3D 模型的周边。这种方法简化了渲染过程,并且有助于减少计算负载,同时保持对主要对象的关注。
材质网络#
DreamFusion 中的材质网络负责通过准确模拟不同材质的物理特性来为 3D 模型增加真实感。该网络考虑了纹理、反射率和透明度等各个方面。通过这样做,它增加了另一层细节,使 DreamFusion 生成的对象不仅在结构上准确,而且在视觉和触觉上都逼真。
渲染器层#
渲染器层充当 DreamFusion 处理流程的最终阶段。它将来自 NeRF 和材质网络的合成体数据转换为可感知的图像。该层采用光线追踪算法,计算光与 3D 场景的交互,生成具有精确阴影投射、动态光照和透视校正渲染等复杂属性的图像。
模型配置#
可以使用 DreamFusion 类实例化 DreamFusion 模型。模型配置文件分为以下几个部分
_target_: nemo.collections.multimodal.models.nerf.dreamfusion.DreamFusion
defaults:
- nerf: torchngp
- background: static
- material: basic_shading
- renderer: torchngp_raymarching
- guidance: sd_huggingface
- optim: adan
- loss: dreamfusion
- data: data
- _self_
### model options
resume_from_checkpoint:
prompt: 'a hamburger'
negative_prompt: ''
front_prompt: ', front view'
side_prompt: ', side view'
back_prompt: ', back view'
update_extra_interval: 16
guidance_scale: 100
export_video: False
iters: ${trainer.max_steps}
latent_iter_ratio: 0.2
albedo_iter_ratio: 0.0
min_ambient_ratio: 0.1
textureless_ratio: 0.2
data:
train_dataset:
width: 64
height: 64
val_dataset:
width: 800
height: 800
test_dataset:
width: 800
height: 800
defaults:定义不同组件(如 nerf、background、material 等)的默认模块。resume_from_checkpoint:用于初始化模型的检查点文件的路径。prompt:用于描述要生成的对象的主文本输入。negative_prompt:描述要避免在生成的对象中出现的内容的文本输入。front_prompt、side_prompt、back_prompt:附加到提示的文本输入,用于更详细的定向引导。update_extra_interval:更新内部模块参数的间隔。guidance_scale:与扩散模型一起使用的引导比例。export_video:布尔值,用于确定是否导出生成的对象的 360 度视频。iters、latent_iter_ratio、albedo_iter_ratio、min_ambient_ratio、textureless_ratio:定义迭代行为和输出的视觉特征的各种比率和参数。data:定义用于训练、验证和测试的数据集维度。
通过微调 default 部分中各种组件的参数,可以精确调整管道的行为。某些组件支持不同的后端和实现,完整的组件目录可以在配置目录 {NEMO_ROOT/examples/multimodal/generative/nerf/conf/model} 中查看。
图像引导#
_target_: nemo.collections.multimodal.modules.nerf.guidance.stablediffusion_huggingface_pipeline.StableDiffusion
precision: ${trainer.precision}
model_key: stabilityai/stable-diffusion-2-1-base
t_range: [0.02, 0.98]
precision:设置计算精度(例如,FP32 或 FP16)。model_key:指定用于图像引导的预训练模型。t_range:用于引导稳定性的阈值范围。
NeRF(前景)网络#
_target_: nemo.collections.multimodal.modules.nerf.geometry.torchngp_nerf.TorchNGPNerf
num_input_dims: 3
bound: 1
density_activation: exp
blob_radius: 0.2
blob_density: 5
normal_type: central_finite_difference
encoder_cfg:
encoder_type: 'hashgrid'
encoder_max_level:
log2_hashmap_size: 19
desired_resolution: 2048
interpolation: smoothstep
sigma_net_num_output_dims: 1
sigma_net_cfg:
num_hidden_dims: 64
num_layers: 3
bias: True
features_net_num_output_dims: 3
features_net_cfg:
num_hidden_dims: 64
num_layers: 3
bias: True
描述 NeRF 网络的架构,包括密度激活函数、网络配置以及 sigma 和特征网络的规范。
背景层#
_target_: nemo.collections.multimodal.modules.nerf.background.static_background.StaticBackground
background: [0, 0, 1]
静态背景,其中背景键是 RGB 颜色。
_target_: nemo.collections.multimodal.modules.nerf.background.torchngp_background.TorchNGPBackground
encoder_type: "frequency"
encoder_input_dims: 3
encoder_multi_res: 6
num_output_dims: 3
net_cfg:
num_hidden_dims: 32
num_layers: 2
bias: True
动态背景,其中背景由 NeRF 网络生成。
材质网络#
_target_: nemo.collections.multimodal.modules.nerf.materials.basic_shading.BasicShading
定义材质网络的基本着色模型。基本着色模型支持无纹理、朗伯和 Phong 着色。
渲染器层#
_target_: nemo.collections.multimodal.modules.nerf.renderers.torchngp_volume_renderer.TorchNGPVolumeRenderer
bound: ${model.nerf.bound}
update_interval: 16
grid_resolution: 128
density_thresh: 10
max_steps: 1024
dt_gamma: 0
配置渲染器,指定更新间隔、网格分辨率和渲染阈值等参数。
DreamFusion-DMTet#
NeRF 模型通过体渲染集成几何形状和外观。因此,当需要捕获表面的复杂细节以及材质和纹理时,使用 NeRF 进行 3D 建模的效果可能较差。
DMTet 微调解耦了几何形状和外观模型的学习,从而可以生成精细的表面和丰富的材质/纹理。为了实现这种解耦学习,使用了 [DMTet](https://nv-tlabs.github.io/DMTet/) 的混合场景表示。
DMTet 模型维护一个可变形四面体网格,该网格编码离散化的有符号距离函数和一个可微的行进四面体层,该层将隐式有符号距离表示转换为显式表面网格表示。
模型配置#
可以使用与 DreamFusion 相同的类 DreamFusion 实例化 DreamFusion 模型。但是,需要对训练管道进行以下更改
_target_: nemo.collections.multimodal.models.nerf.dreamfusion.DreamFusion
defaults:
- nerf: torchngp
- background: torchngp
- material: basic_shading
- renderer: nvdiffrast # (1)
- guidance: sd_huggingface
- optim: adan
- loss: dmtet # (2)
- data: data
- _self_
### model options
resume_from_checkpoint: "/results/DreamFusion/checkpoints/DreamFusion-step\\=10000-last.ckpt" # (3)
prompt: 'a hamburger'
negative_prompt: ''
front_prompt: ', front view'
side_prompt: ', side view'
back_prompt: ', back view'
update_extra_interval: 16
guidance_scale: 100
export_video: False
iters: ${trainer.max_steps}
latent_iter_ratio: 0.0
albedo_iter_ratio: 0
min_ambient_ratio: 0.1
textureless_ratio: 0.2
data:
train_dataset:
width: 512 # (4)
height: 512 # (4)
val_dataset:
width: 800
height: 800
test_dataset:
width: 800
height: 800
我们注意到以下更改:1. 渲染模块已从基于体积的方法更新为使用 nvdiffrast 的基于栅格化的方法。2. 模型损失已更改,以考虑几何表示中的更改。3. DreamFusion-DMTet 微调预训练的 DreamFusion 模型,预训练的检查点使用 resume_from_checkpoint 提供。4. 训练形状增加到 512x512。
参考文献#
Ben Poole、Ajay Jain、Jonathan T. Barron 和 Ben Mildenhall。《Dreamfusion:使用 2D 扩散的文本到 3D》。2022 年。URL:https://arxiv.org/abs/2209.14988。