Docker & Omniverse 动画管线工作流#
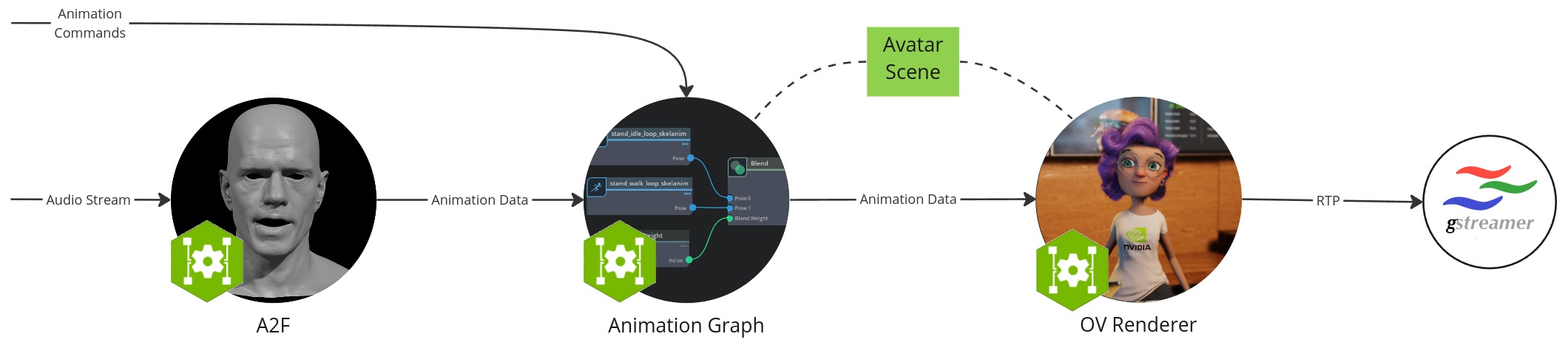
在此设置中,您将直接从 docker 容器本地运行微服务,以创建单个头像动画流实例。
工作流配置包含以下组件
Audio2Face-3D 微服务:将语音音频转换为面部动画,包括口型同步
动画图 微服务:管理和混合动画状态
Omniverse 渲染器 微服务:渲染器,用于可视化基于加载的头像场景的动画数据
Gstreamer 客户端:捕获并显示图像和音频流数据作为用户前端
头像场景:3D 场景和头像模型数据的集合,保存在本地文件夹中
先决条件#
在开始之前,请确保已安装并检查了开发设置中的所有先决条件。
此外,本节假设满足以下先决条件
您已安装 Docker
您有权访问 NVAIE,这是下载动画图和 Omniverse 渲染器微服务所必需的
您有权访问公共 NGC 目录,这是下载头像配置器所必需的
硬件要求#
每个组件都有自己的硬件要求。工作流的要求是其组件的总和。
Audio2Face-3D 微服务
动画图 微服务
Omniverse 渲染器 微服务
拉取 Docker 容器#
docker pull nvcr.io/nvidia/ace/ia-animation-graph-microservice:1.0.2
docker pull nvcr.io/nvidia/ace/ia-omniverse-renderer-microservice:1.0.5
docker pull nvcr.io/nvidia/ace/audio2face:1.0.11
从 NGC 下载头像场景#
从 NGC 下载场景,并将其保存到您的主工作目录中的 default-avatar-scene_v1.0.0 目录中。
或者,您可以使用 ngc 命令下载场景。
ngc registry resource download-version "nvidia/ace/default-avatar-scene:1.0.0"
运行动画图微服务#
运行以下命令以启动动画图微服务。此服务管理头像的位置并使其动画化。
docker run -it --rm --gpus all --network=host --name anim-graph-ms -v $(pwd)/default-avatar-scene_v1.0.0:/home/ace/asset nvcr.io/nvidia/ace/ia-animation-graph-microservice:1.0.2
当您看到日志行 app ready 时,该服务已启动并运行。
注意
如果您遇到关于 glfw 初始化失败的警告,请参阅故障排除部分。
运行 Omniverse 渲染器微服务#
docker run --env IAORMS_RTP_NEGOTIATION_HOST_MOCKING_ENABLED=true --rm --gpus all --network=host --name renderer-ms -v <path-to-avatar-scene-folder>:/home/ace/asset nvcr.io/nvidia/ace/ia-omniverse-renderer-microservice:1.0.5
其中 <path-to-avatar-scene-folder> 应替换为本地头像场景文件夹。
注意
启动此服务可能需要长达 30 分钟。当您在终端中看到以下行时,它已准备就绪
[SceneLoader] Assets loaded
运行 Audio2Face-3D 微服务#
运行以下命令以运行 Audio2Face-3D
docker run --rm --network=host -it --gpus all nvcr.io/nvidia/ace/audio2face:1.0.11
生成 TRT 模型
./service/generate_trt_model.py built-in claire_v1.3
./service/generate_a2e_trt_model.py
在 service/a2f_config.yaml 中,确保将 grpc_output 下的 IP(默认为 0.0.0.0)设置为您的系统 IP。
nano service/a2f_config.yaml
启动服务
./service/launch_service.py service/a2f_config.yaml
当服务准备就绪时,将显示以下日志行
[2024-04-23 12:44:33.066] [ global ] [info] Running...
注意
有关 Audio2Face-3D 部署的更多详细信息,请参见A2F-3D NIM 手动容器部署和配置。
设置和启动 Gstreamer#
我们将使用 Gstreamer 来捕获图像和音频输出流,以可视化头像场景。
安装 Gstreamer 插件
sudo apt-get install gstreamer1.0-plugins-bad gstreamer1.0-libav
在其自己的终端中运行视频接收器
gst-launch-1.0 -v udpsrc port=9020 caps="application/x-rtp" ! rtpjitterbuffer drop-on-latency=true latency=20 ! rtph264depay ! h264parse ! avdec_h264 ! videoconvert ! queue ! autovideosink sync=false
并在其自己的终端中运行音频接收器 (linux)
gst-launch-1.0 -v udpsrc port=9021 caps="application/x-rtp,clock-rate=16000" ! rtpjitterbuffer ! rtpL16depay ! audioconvert ! autoaudiosink sync=false
或者,如果您在 Windows 上运行音频接收器
gst-launch-1.0 -v udpsrc port=9021 caps="application/x-rtp,clock-rate=16000" ! rtpjitterbuffer ! rtpL16depay ! audioconvert ! directsoundsink sync=false
注意
在下一步添加流之前,不会显示图像或声音!
通过公共流 ID 连接微服务#
返回主终端,运行以下命令
stream_id=$(uuidgen)
curl -X POST -s http://localhost:8020/streams/$stream_id
curl -X POST -s http://localhost:8021/streams/$stream_id
注意
您现在应该看到头像渲染略微移动。
测试动画图接口#
让我们设置一个新的姿势
curl -X PUT -s http://localhost:8020/streams/$stream_id/animation_graphs/avatar/variables/posture_state/Talking
或更改头像的位置
curl -X PUT -s http://localhost:8020/streams/$stream_id/animation_graphs/avatar/variables/position_state/Left
或启动一个手势
curl -X PUT -s http://localhost:8020/streams/$stream_id/animation_graphs/avatar/variables/gesture_state/Pulling_Mime
或触发面部表情
curl -X PUT -s http://localhost:8020/streams/$stream_id/animation_graphs/avatar/variables/facial_gesture_state/Smile
或者,您可以使用 OpenAPI 接口查看和试用更多内容:http://localhost:8020/docs。
您可以在此处找到所有有效的变量值:默认动画图。
测试 Audio2Face-3D#
现在让我们使用一个示例音频文件输入到 Audio2Face-3D,以驱动面部说话动画。
通常,您将通过其 gRPC API 将音频发送到 Audio2Face-3D。为了方便起见,python 脚本允许您通过命令行执行此操作。克隆 ACE repo 并按照设置脚本的步骤进行操作。
该脚本带有一个与 Audio2Face-3D 兼容的 示例音频文件。从 ACE repo 的 microservices/audio_2_face_microservice/scripts/audio2face_in_animation_pipeline_validation_app 目录中,运行以下命令以将示例音频文件发送到 Audio2Face-3D
python3 validate.py -u 127.0.0.1:50000 -i $stream_id ../../example_audio/Mark_joy.wav
注意
Audio2Face-3D 要求音频为 16KHz 单声道格式。
更改头像场景#
要修改或切换默认头像场景,您可以使用头像配置器。
下载并解压缩它,然后运行 ./run_avatar_configurator.sh 启动它。
一旦成功启动(首次启动需要更长时间来编译着色器),您可以创建自定义的新场景并保存它。
然后复制文件夹 avatar_configurator/exported 中的所有文件,并替换步骤“从 NGC 下载头像场景”中的本地文件夹 avatar-scene-folder 中的文件。
重新启动动画图和 Omniverse 渲染器服务后,您将看到新场景。
清理:移除流#
您可以使用以下命令清理流
curl -X DELETE -s http://localhost:8020/streams/$stream_id
curl -X DELETE -s http://localhost:8021/streams/$stream_id