模态#
API 为以下模态提供标准事件和操作:语音、手势、情感、动作和场景。不同模态的操作彼此独立。这些操作可以彼此独立运行。交互系统需要支持这一点。如果应为同一模态执行多个操作,则该模态的策略将决定如何处理这些事件的执行/调度。
以下模态策略存在于 UMIM 中
策略 |
描述 |
示例模态 |
|---|---|---|
|
多个操作可以同时运行。 |
音效、定时器 |
|
多个操作可以同时运行。如果一个操作正在运行,它将被“覆盖”。当覆盖操作完成时,另一个操作将恢复 |
姿势、手势 |
|
如果在同一模态上已有一个正在进行的操作时启动一个操作,则将启动新操作并立即完成 ( |
|
|
停止同一模态上任何正在进行的操作 ( |
模态概述#
每个交互系统可以支持不同的模态。如果支持某个模态,则交互系统需要支持该模态的所有强制操作和事件,并且可以支持下表中列出的其他可选操作和事件。
模态组 |
模态名称 |
策略 |
必需的操作和事件 |
可选的操作和事件 |
|---|---|---|---|---|
语音 |
|
|
||
|
|
|||
运动 |
|
|
||
|
|
|||
|
|
|||
|
|
|||
|
|
|||
系统 |
|
|
||
|
|
|||
|
|
|||
|
|
|||
|
|
语音#
本节定义了与使用语音模态进行对话管理相关的事件和操作。Bot 和用户都可以使用此模态。我们区分 BotSpeech 和 UserSpeech 以指代各自的模态。
话语用户操作#
用户发出交互系统识别的话语。此操作的示例包括用户在文本界面中键入内容以与 Bot 交互,或用户对着交互式头像说话。
- UtteranceUserActionStarted()#
用户开始生成话语。例如,用户可能已开始说话或打字。
- 参数:
... – 从
UserActionStarted()继承的其他参数/有效负载。
- UtteranceUserActionIntensityUpdated(intensity: float)#
如果交互系统支持,则提供更新的说话强度级别。
- 参数:
intensity (float) – 一个介于 0-1 之间的值,指示话语的强度。值 0.5 表示“平均”强度。话语操作的强度可能对应于不同的指标,具体取决于交互系统。对于聊天机器人系统,强度可能与打字速率有关。在启用语音的系统中,强度可以根据用户声音的音量和音调变化来计算。
... – 从
UserActionUpdated()继承的其他参数/有效负载。
- UtteranceUserActionTranscriptUpdated(interim_transcript: str)#
在 UtteranceUserAction 期间提供更新的文本记录
- 参数:
interim_transcript (str) – 到目前为止的用户话语的部分文本记录
... – 从
UserActionUpdated()继承的其他参数/有效负载。
- StopUtteranceUserAction()#
指示 IM 已收到所需信息,并且操作服务器应尽快将 Utterance 视为已完成。例如,这可以指示操作服务器减少保持时间(用户语音中的静音持续时间,直到我们认为语音结束已达到)。
- 参数:
... – 从
StopUserAction()继承的其他参数/有效负载。
- UtteranceUserActionFinished(final_transcript: str)#
用户话语已完成。
- 参数:
final_transcript (str) – 用户话语的最终文本记录
... – 从
UserActionFinished()继承的其他参数/有效负载。
操作序列图#
在下面,我们为两个典型的交互系统的事件序列提供示例序列图。
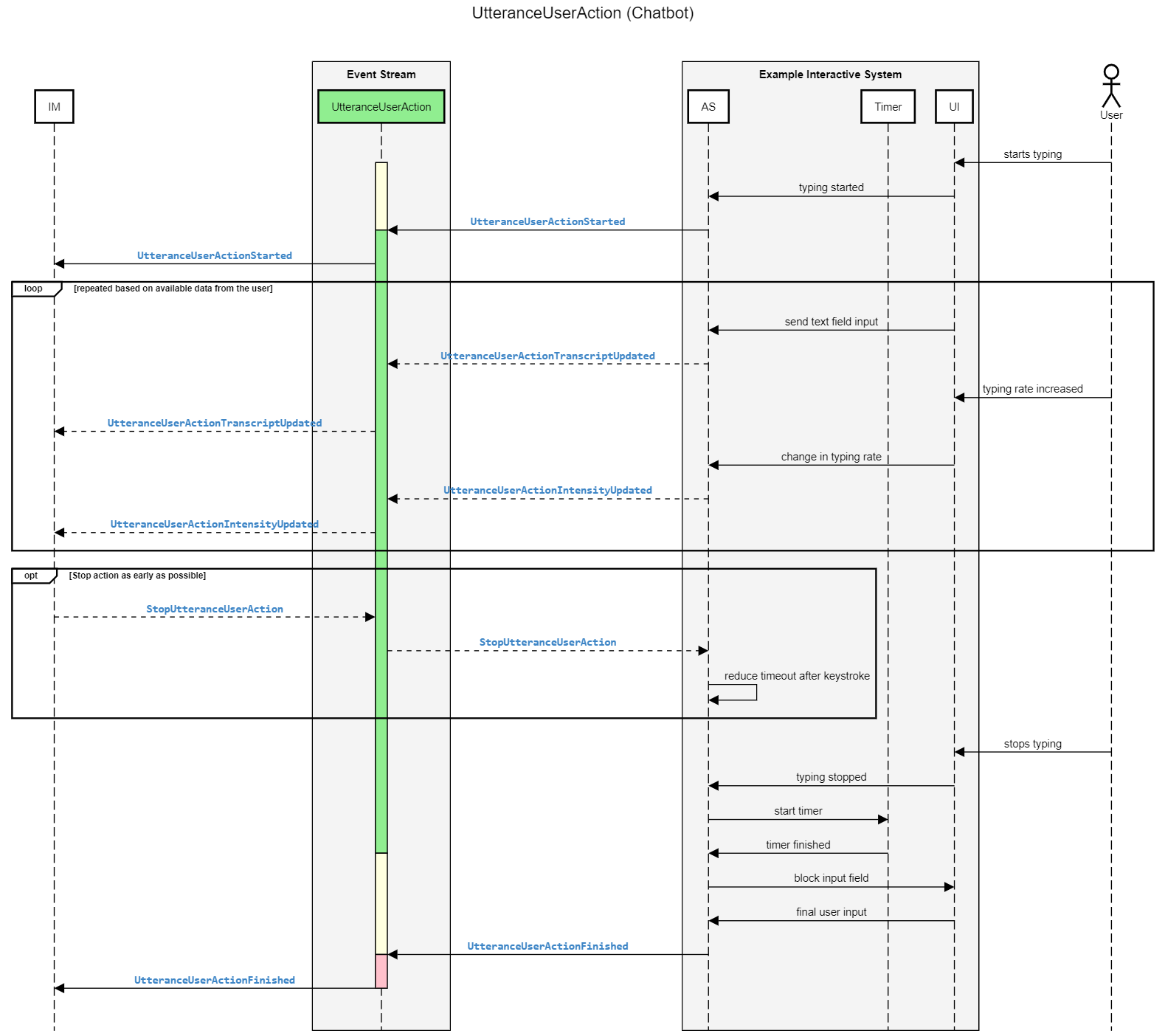
聊天机器人系统的示例事件流#
交互式头像系统的示例事件流#
话语 Bot 操作#
Bot 正在向用户生成话语(说些什么)。根据交互系统的不同,这可能意味着不同的事情,但此操作始终表示通过类语音界面(例如,聊天界面、实际语音界面、脑机通信 😀)与用户进行口头交流
- StartUtteranceBotAction(script: str, intensity: float | None)#
Bot 应开始生成话语。根据交互系统的不同,这可能是 Bot 发送文本消息或头像与用户交谈。
- 参数:
script (str) – Bot 的话语,支持 SSML
intensity (Optional[float]) – 一个介于 0-1 之间的值,指示话语的强度。值 0.5 表示“平均”强度。话语操作的强度应根据交互系统的类型更改话语传递给用户的方式。对于聊天机器人系统,强度可能与 UI 中的打字速率有关。在启用语音的系统中,强度可以改变生成语音的音量和音调变化。
... – 从
StartBotAction()继承的其他参数/有效负载。
- UtteranceBotActionStarted()#
Bot 开始生成话语。此事件应尽可能与用户接收到话语的时刻对齐。例如,在交互式头像系统中,一旦文本到语音 (TTS) 流发送给用户,操作服务器就会发出该事件。
- 参数:
... – 从
BotActionStarted()继承的其他参数/有效负载。
- ChangeUtteranceBotAction(intensity: float)#
在操作已启动后调整预期音量。
- 参数:
intensity (float) – 一个介于 0-1 之间的值,指示话语的强度。值 0.5 表示“平均”强度。话语操作的强度应根据交互系统的类型更改话语传递给用户的方式。对于聊天机器人系统,强度可能与 UI 中的打字速率有关。在启用语音的系统中,强度可以改变生成语音的音量和音调变化。
... – 从
ChangeBotAction()继承的其他参数/有效负载。
- UtteranceBotActionScriptUpdated(interim_script: str)#
在 UtteranceBotAction 期间提供更新的文本记录。这些事件对应于将话语的特定部分传递给用户的时间。在支持语音输出的交互系统中,这些事件应与用户听到部分文本记录的时间对齐
- 参数:
interim_script (str) – 到目前为止的 Bot 话语的部分文本记录
... – 从
BotActionUpdated()继承的其他参数/有效负载。
- StopUtteranceBotAction()#
停止 Bot 话语。仅当收到 UtteranceBotActionFinished 后,操作才会停止。对于不支持此事件的交互系统,操作将继续正常运行直到完成。交互管理器应处理停止话语的时间与话语实际完成的时间之间的任意延迟。
- 参数:
... – 从
StopBotAction()继承的其他参数/有效负载。
- UtteranceBotActionFinished(final_script: str)#
Bot 话语已完成,原因可能是话语已传递给用户或操作已停止。
- 参数:
final_script (str) – Bot 话语的最终文本记录
... – 从
BotActionFinished()继承的其他参数/有效负载。
旁注:管理与语音输入和 ASR 相关的 Bot 期望#
如果您的交互系统依赖于语音输入,并且您在嘈杂的环境中工作,或者您的 ASR 系统检测到大量虚假文本记录,则围绕 UtteranceUserAction 与交互系统沟通 Bot 期望可能会有所帮助。这允许系统选择性地启用/禁用语音输入或优化系统的灵敏度。
下面我们展示了一个示例序列图,说明在交互系统仅在 IM 期望用户说话时才启用音频输入和 ASR 的情况下,IM 和交互系统如何进行通信。
用于管理 Bot 期望的示例#
运动#
运动操作包括具有特定含义的运动或一组运动。它们通常通过计算机视觉识别,并且可以由交互式头像生成。目前,我们区分了 Bot 和用户的以下模态:face、gesture、posture 和 position。
这些模态中的许多模态都受 override 策略的约束。这意味着操作服务器应通过临时覆盖当前正在运行的操作以及已启动的新操作来处理多个并发操作。一个具体的例子:IM 启动 PostureBotAction(gesture=“attentive”) 操作(头像保持专注姿势)。2 秒后,IM 启动 PostureBotAction(posture=“listening”) 操作。监听姿势操作由操作服务器执行,覆盖“专注”姿势(头像看起来像在倾听)。一旦监听姿势操作停止,头像将返回到“专注”姿势(覆盖的操作恢复)。
姿势 Bot 操作#
指示 Bot 摆出姿势。姿势永远不会由系统完成。这与手势操作形成对比,手势操作具有有限的生命周期,并且应通过手势指示的明确的开始和结束日期来“执行”。姿势可以通过交互系统以不同的方式实现。对于交互式头像系统,姿势可以改变头像的姿势。对于聊天机器人系统,这可以更改 Bot 指示图标(例如,像 Siri 助手一样)
- StartPostureBotAction(posture: str)#
Bot 应开始采用指定的姿势。
- 参数:
posture (str) – 姿势的自然语言描述 (NLD)。姿势的可用性取决于交互系统。姿势应分层表达,以便提供不太细致姿势的交互系统可以退回到更高级别的姿势。所有支持此操作的交互系统都需要支持以下基本姿势:“idle”、“attentive”
... – 从
StartBotAction()继承的其他参数/有效负载。
- PostureBotActionStarted()#
Bot 已达到该姿势。
- 参数:
... – 从
BotActionStarted()继承的其他参数/有效负载。
- StopPostureBotAction()#
停止姿势。姿势没有生命周期,因此除非 IM 调用 Stop 操作,否则 Bot 将无限期地保持姿势。
- 参数:
... – 从
StopBotAction()继承的其他参数/有效负载。
- PostureBotActionFinished()#
姿势已停止。
- 参数:
... – 从
BotActionFinished()继承的其他参数/有效负载。
手势 Bot 操作#
指示 Bot 做出手势。与 PostureBotAction 相比,Bot 手势具有有限的“生命周期”,用于提供即时效果。Bot 手势可以通过交互系统以不同的方式实现。对于交互式头像系统,手势应由头像执行。对于聊天机器人系统,手势可以用表情符号或图像、gif 来表示。
- StartGestureBotAction(gesture: str)#
Bot 应开始做出特定的手势。
- 参数:
gesture (str) – 手势的自然语言描述 (NLD)。手势的可用性取决于交互系统。如果系统支持此操作,则需要支持以下基本手势:affirm、negate、attract
... – 从
StartBotAction()继承的其他参数/有效负载。
- GestureBotActionStarted()#
Bot 已开始执行手势。
- 参数:
... – 从
BotActionStarted()继承的其他参数/有效负载。
- StopGestureBotAction()#
停止手势。所有手势都具有有限的生命周期,并“自行”完成。手势旨在强调某种情况或声明。例如,在交互式头像系统中,affirm 手势可以通过头像点头两次的 1 秒动画剪辑来实现。IM 可以使用此操作在手势自然完成之前停止手势。
- 参数:
... – 从
StopBotAction()继承的其他参数/有效负载。
- GestureBotActionFinished()#
手势已执行。
- 参数:
... – 从
BotActionFinished()继承的其他参数/有效负载。
手势用户操作#
系统检测到用户手势。
- GestureUserActionStarted()#
交互系统检测到用户手势的开始。注意:系统检测到手势的时间可能与用户开始执行手势的时间不同。
- 参数:
... – 从
UserActionStarted()继承的其他参数/有效负载。
- GestureUserActionFinished(gesture: str)#
用户执行了手势。
- 参数:
gesture (str) – 手势的人类可读名称。手势的可用性取决于交互系统。
... – 从
UserActionFinished()继承的其他参数/有效负载。
位置 Bot 操作#
指示 Bot 保持新位置。如果操作停止,Bot 将返回其原始位置。这是一种状态操作(如 PostureBotAction),它将确保 Bot 在操作完成时返回到其先前的位置。
- StartPositionBotAction(position: str)#
Bot 需要保持新位置。
- 参数:
position (str) –
指定 Bot 需要移动到并保持的位置。
位置的可用性取决于交互系统。位置通常按层次结构分为基本位置和位置修饰符(“偏离中心”)。
最小 NLD 集
所有交互系统(支持此操作)都支持以下基本位置
center : Bot 的默认位置
left : Bot 应定位到左侧(从 Bot 的角度来看)
right: Bot 应定位到右侧(从 Bot 的角度来看)
... – 从
StartBotAction()继承的其他参数/有效负载。
- PositionBotActionStarted()#
Bot 已开始过渡到新位置
- 参数:
... – 从
BotActionStarted()继承的其他参数/有效负载。
- PositionBotActionUpdated(position_reached: str)#
Bot 已到达该位置,并在整个操作持续时间内保持该位置。
- 参数:
position_reached (str) – Bot 已到达的位置。
... – 从
BotActionUpdated()继承的其他参数/有效负载。
- StopPositionBotAction()#
停止保持位置。Bot 将返回到调用之前的位置。位置保持操作具有无限生命周期,因此除非 IM 调用 Stop 操作,否则 Bot 将无限期地保持该位置。或者,PositionBotAction 操作可以被覆盖,因为模态策略是 Override。
- 参数:
... – 从
StopBotAction()继承的其他参数/有效负载。
- PositionBotActionFinished()#
Bot 已移回此操作之前的原始位置。这可能是中性位置,也可能是现在获得“焦点”的此操作覆盖的任何 PositionBotAction 的位置。
- 参数:
... – 从
BotActionFinished()继承的其他参数/有效负载。
面部手势 Bot 操作#
指示 Bot 做出快速而短暂的面部表情,最多持续几秒钟,例如快速微笑、瞬间皱眉或短暂眨眼。在聊天机器人系统中,这可以生成表情符号作为文本消息的一部分。对于交互式头像,这会在短时间内改变头像的面部动画(例如,眨眼或微笑)。
- StartFacialGestureBotAction(facial_gesture: str)#
Bot 应开始做面部手势。
- 参数:
facial_gesture (str) –
面部手势或表情的自然语言描述 (NLD)。
面部手势的可用性取决于交互系统。
最小 NLD 集
以下手势应得到每个实现此操作的交互系统的支持:微笑、大笑、皱眉、眨眼
... – 从
StartBotAction()继承的其他参数/有效负载。
- FacialGestureBotActionStarted()#
机器人已开始执行面部手势
- 参数:
... – 从
BotActionStarted()继承的其他参数/有效负载。
- StopFacialGestureBotAction()#
停止面部手势或表情。所有手势都有一个有限的生命周期,并会“自行”结束(例如,在交互式头像系统中,“微笑”手势可以通过一个 1 秒的动画剪辑来实现,其中一些面部骨骼是动画的)。IM 可以使用此操作在表情自然完成之前停止它。
- 参数:
... – 从
StopBotAction()继承的其他参数/有效负载。
- FacialGestureBotActionFinished()#
面部手势已执行。
- 参数:
... – 从
BotActionFinished()继承的其他参数/有效负载。
面部手势用户操作#
系统检测到一个短暂的面部手势,例如皱眉、微笑或眨眼,这与用户的中性表情不同。检测到的手势或小表情是用户在短时间内表达的。
- FacialGestureUserActionStarted(expression: str)#
- 参数:
expression (str) –
面部表情的自然语言描述 (NLD)。
检测到的面部表情取决于交互系统的功能。
最小 NLD 集
以下表情应得到每个实现此操作的交互系统的支持:微笑、大笑、皱眉、眨眼
... – 从
UserActionStarted()继承的其他参数/有效负载。
- FacialGestureUserActionFinished()#
- 参数:
... – 从
UserActionFinished()继承的其他参数/有效负载。
场景#
场景操作通常在交互系统中可用,这些系统在头像交互旁边提供某种屏幕空间。在聊天机器人系统中,这可以是应用程序的一部分,可以显示信息,也可以是在聊天中内联显示信息的能力。在交互式头像系统中,头像可以与电视一起渲染(就像新闻主播场景中一样),或者可以在头像旁边渲染 Web UI。
镜头相机操作#
开始指定的相机镜头。我们使用镜头来指代在较长时间内影响相机状态的任何事物,这可以包括将相机移动到新位置、从左向右平移等。这是一个状态操作(如 PostureBotAction),它将确保相机在操作完成时返回到之前的镜头(覆盖模式)。
- StartShotCameraAction(shot: str, start_transition: str)#
开始一个新的镜头。
- 参数:
shot (str) –
镜头的自然语言描述 (NLD)。
镜头的可用性取决于交互系统。
最小 NLD 集
以下镜头应得到每个实现此操作的交互系统的支持:全景、中景、特写
start_transition (str) –
到新镜头的过渡的 NLD。这应描述运动。
最小 NLD 集
以下镜头应得到每个实现此操作的交互系统的支持:切、推轨
... – 从
StartBotAction()继承的其他参数/有效负载。
- ShotCameraActionStarted()#
相机镜头已开始
- 参数:
... – 从
BotActionStarted()继承的其他参数/有效负载。
- StopShotCameraAction(stop_transition: str)#
停止相机镜头。相机将返回到此操作开始之前的镜头。ShotCameraAction 操作具有无限的生命周期,因此除非 IM 调用 Stop 操作,否则相机将无限期地保持该镜头。
- 参数:
stop_transition (str) –
返回到先前镜头的过渡的 NLD(覆盖模式)。
这应描述运动。
最小 NLD 集
以下镜头应得到每个实现此操作的交互系统的支持:切、推轨
... – 从
StopBotAction()继承的其他参数/有效负载。
- ShotCameraActionFinished()#
相机镜头已停止。相机已返回到之前的镜头(中性镜头)或任何被覆盖的 ShotCameraAction 操作指定的镜头。
- 参数:
... – 从
BotActionFinished()继承的其他参数/有效负载。
运动效果相机操作#
将相机运动效果应用于活动相机。
- StartMotionEffectCameraAction(effect: str)#
执行描述的相机运动效果。
- 参数:
effect (str) –
效果的自然语言描述 (NLD)。
效果的可用性取决于交互系统。
最小 NLD 集
以下相机效果应得到每个实现此操作的交互系统的支持
抖动、跳切入、跳切出
... – 从
StartBotAction()继承的其他参数/有效负载。
- MotionEffectCameraActionStarted()#
相机效果已开始。
- 参数:
... – 从
BotActionStarted()继承的其他参数/有效负载。
- StopMotionEffectCameraAction()#
停止相机效果。所有效果都有一个有限的生命周期,并会“自行”结束(例如,在交互式头像系统中,“抖动”效果可以通过 1 秒的相机运动来实现)。IM 可以使用此操作在相机效果自然完成之前停止它。
- 参数:
... – 从
StopBotAction()继承的其他参数/有效负载。
- MotionEffectCameraActionFinished()#
相机效果已完成。
- 参数:
... – 从
BotActionFinished()继承的其他参数/有效负载。
可视化信息场景操作#
向用户可视化信息。此操作用于向用户显示有关主题的详细信息。示例:用户对有关产品或服务的详细信息感兴趣。
- StartVisualInformationSceneAction(
- content: List[umim.messages.modalities.scene.VisualInformationContent],
- title: str,
- summary: str | None,
- support_prompts: List[str] | None,
在场景中向用户呈现信息。
- 参数:
content (List[umim.messages.modalities.scene.VisualInformationContent]) – 用户可从中选择的选项列表
title (str) – 描述您提供给用户的选择
summary (Optional[str]) – 要向用户显示的信息摘要
support_prompts (Optional[List[str]]) – 支持用户做出选择的提示列表
... – 从
StartBotAction()继承的其他参数/有效负载。
- VisualInformationSceneActionStarted()#
系统已开始向用户呈现信息。
- 参数:
... – 从
BotActionStarted()继承的其他参数/有效负载。
- VisualInformationSceneActionConfirmationUpdated(
- confirmation_status: ConfirmationStatus,
每当用户确认或尝试中止屏幕上显示的可视化信息时。例如:单击“确认”按钮,“单击关闭”
- 参数:
confirmation_status (ConfirmationStatus) – 确认状态的更新。用户指示已理解或取消可视化信息
... – 从
BotActionUpdated()继承的其他参数/有效负载。
- StopVisualInformationSceneAction()#
停止向用户呈现信息
- 参数:
... – 从
StopBotAction()继承的其他参数/有效负载。
- VisualInformationSceneActionFinished()#
信息操作已由 IM 停止(没有用户操作会导致操作由操作服务器完成)。
- 参数:
... – 从
BotActionFinished()继承的其他参数/有效负载。
可视化选择场景操作#
向用户可视化一个选择,理想情况下允许用户以多种方式与该选择进行交互。示例:在屏幕上显示一个网站,该网站呈现选项,允许用户通过触摸选项或使用语音来选择选项。
- StartVisualChoiceSceneAction(
- allow_multiple_choices: bool,
- choice_type: ChoiceType,
- options: List[umim.messages.modalities.scene.VisualChoiceOption],
- prompt: str,
- image: str | None,
- support_prompts: List[str] | None,
在场景中向用户呈现一个选择。
- 参数:
allow_multiple_choices (bool) – 指示用户是否应该能够从呈现的选项中选择多个选项
choice_type (ChoiceType) – 配置用户可以做出的选择类型。
options (List[umim.messages.modalities.scene.VisualChoiceOption]) – 用户可从中选择的选项列表
prompt (str) – 描述您提供给用户的选择
image (Optional[str]) – 应与选择一起显示的图像的描述。
support_prompts (Optional[List[str]]) – 支持用户做出选择的提示列表
... – 从
StartBotAction()继承的其他参数/有效负载。
- VisualChoiceSceneActionStarted()#
系统已开始向用户呈现选择
- 参数:
... – 从
BotActionStarted()继承的其他参数/有效负载。
- VisualChoiceSceneActionChoiceUpdated(current_choice: List[str])#
每当用户直接与场景中呈现的选择进行交互,但未确认取消选择时,交互系统都会发送 ChoiceUpdated 事件。
- 参数:
current_choice (List[str]) – 如果用户做出了选择,则为选项 ID 列表
... – 从
BotActionUpdated()继承的其他参数/有效负载。
- VisualChoiceSceneActionConfirmationUpdated(
- confirmation_status: ConfirmationStatus,
每当用户在与选择的可视化表示交互时确认或尝试中止选择时。例如:单击“确认”按钮,“单击关闭”
- 参数:
confirmation_status (ConfirmationStatus) – 用户对选择确认的状态。
... – 从
BotActionUpdated()继承的其他参数/有效负载。
- StopVisualChoiceSceneAction()#
停止向用户呈现选择。
- 参数:
... – 从
StopBotAction()继承的其他参数/有效负载。
- VisualChoiceSceneActionFinished(final_choice: List[str])#
选择操作已由 IM 停止。(没有用户操作会导致操作由操作服务器完成)。
- 参数:
final_choice (List[str]) – 用户可从中选择的选项列表
... – 从
BotActionFinished()继承的其他参数/有效负载。
可视化表单场景操作#
向用户可视化一个表单,用于机器人需要准确和特定输入的情况。常见的例子包括显示一个表单来获取用户的邮政地址或电子邮件地址。
- StartVisualFormSceneAction(
- inputs: List[umim.messages.modalities.scene.VisualFormInputs],
- prompt: str,
- image: str | None,
- support_prompts: List[str] | None,
呈现一个可视化表单,该表单请求用户在场景中向用户提供某些输入。
- 参数:
inputs (List[umim.messages.modalities.scene.VisualFormInputs]) – 需要的输入列表。
prompt (str) – 描述您向用户请求的输入
image (Optional[str]) – 应与提示一起显示的图像的描述。
support_prompts (Optional[List[str]]) – 支持用户做出选择的提示列表
... – 从
StartBotAction()继承的其他参数/有效负载。
- VisualFormSceneActionStarted()#
系统已开始向用户呈现表单。
- 参数:
... – 从
BotActionStarted()继承的其他参数/有效负载。
- VisualFormSceneActionConfirmationUpdated(
- confirmation_status: ConfirmationStatus,
每当用户在与表单的可视化表示交互时确认或尝试中止表单输入时。例如:单击“确认”按钮,“单击关闭”
- 参数:
confirmation_status (ConfirmationStatus) – 用户对表单输入确认的状态。
... – 从
BotActionUpdated()继承的其他参数/有效负载。
- VisualFormSceneActionInputUpdated(
- interim_inputs: List[umim.messages.modalities.scene.VisualFormInputs],
每当用户直接与场景中呈现的表单输入进行交互,但尚未确认输入时,交互系统都会发送 Updated 操作。这允许 IM 对部分输入做出反应,例如,如果用户正在键入电子邮件地址,则机器人可以对部分输入做出反应(在用户在表单字段中键入“@”后,机器人可以说“现在只缺少域名”)。
- 参数:
interim_inputs (List[umim.messages.modalities.scene.VisualFormInputs]) – 所有输入的最终状态。
... – 从
BotActionUpdated()继承的其他参数/有效负载。
- StopVisualFormSceneAction()#
停止向用户呈现表单。
- 参数:
... – 从
StopBotAction()继承的其他参数/有效负载。
- VisualFormSceneActionFinished(
- final_inputs: List[umim.messages.modalities.scene.VisualFormInputs],
表单操作已由 IM 停止(没有用户操作会导致操作由操作服务器完成)。
- 参数:
final_inputs (List[umim.messages.modalities.scene.VisualFormInputs]) – 所有输入的最终状态。
... – 从
BotActionFinished()继承的其他参数/有效负载。
系统#
本节介绍构建健壮交互所必需的系统和实用程序操作和事件。
存在用户操作#
系统检测到用户的存在。根据交互系统,这可能意味着用户打开了界面(例如聊天应用程序),或者用户进入了相机的视野(例如信息亭),或者系统检测到鼠标或键盘输入,表明用户在她笔记本电脑前。
注意。如果没有用户存在,交互系统不应创建任何用户操作。因此 PresenceUserAction 充当所有用户操作的父操作。在当前 UMIM 版本中
- PresenceUserActionStarted()#
交互系统检测到系统中用户的存在。
- 参数:
... – 从
UserActionStarted()继承的其他参数/有效负载。
- PresenceUserActionFinished()#
交互系统检测到用户的缺席
- 参数:
... – 从
UserActionFinished()继承的其他参数/有效负载。
注意力用户操作#
系统检测到用户对交互系统的注意力。注意力可以通过许多不同的方式来衡量,具体取决于交互系统。在聊天应用程序中,注意力可以通过用户的打字特征或应用程序导航行为来估计。在交互式头像设置中,用户注意力可以根据视觉线索(如头部位置和用户姿势)来估计。
- AttentionUserActionStarted(attention_level: str)#
交互系统检测到用户的一些参与度。
- 参数:
attention_level (str) – 注意力级别。最小支持值为“engaged”和“disengaged”。许多系统支持更精细的级别,例如“engaged, partially”、“disengaged, looking at phone”
... – 从
UserActionStarted()继承的其他参数/有效负载。
- AttentionUserActionUpdated(attention_level: str)#
交互系统提供对参与度的更新。
- 参数:
attention_level (str) – 注意力级别。最小支持值为“engaged”和“disengaged”。许多系统支持更精细的级别,例如“engaged, partially”、“disengaged, looking at phone”
... – 从
UserActionUpdated()继承的其他参数/有效负载。
- AttentionUserActionFinished()#
系统检测到用户与交互系统脱离。
- 参数:
... – 从
UserActionFinished()继承的其他参数/有效负载。
定时器机器人操作#
为指定持续时间设置定时器。
- StartTimerBotAction(duration: timedelta, timer_name: str | None)#
启动定时器。
- 参数:
duration (timedelta) – 相对于此 StartTimerAction 事件的 event_created_at 时间戳的时间持续时间。当持续时间过去后,定时器会响起(发送 TimerBotActionFinished)。
timer_name (Optional[str]) – 定时器的名称
... – 从
StartBotAction()继承的其他参数/有效负载。
- TimerBotActionStarted()#
定时器已启动。
- 参数:
... – 从
BotActionStarted()继承的其他参数/有效负载。
- ChangeTimerBotAction(duration: timedelta)#
更改定时器的持续时间。如果持续时间减少,这可能会导致定时器立即响起(将发送 TimerBotActionFinished 事件)。
- 参数:
duration (timedelta) – 相对于此 StartTimerAction 事件的 event_created_at 时间戳,更改定时器的持续时间。
... – 从
ChangeBotAction()继承的其他参数/有效负载。
- StopTimerBotAction()#
停止定时器。
- 参数:
... – 从
StopBotAction()继承的其他参数/有效负载。
- TimerBotActionFinished()#
定时器已完成。
- 参数:
... – 从
BotActionFinished()继承的其他参数/有效负载。
管理上下文#
许多交互管理器都有某种上下文或内存的概念,可以在其中存储交互的特定上下文。以下事件支持通知组件有关上下文更新的信息。
管道事件#
交互管理器通常可以同时处理多个交互。对于 UMIM,我们将这些抽象为管道。管道由以下组成
stream_uid,对应于 UMIM 事件的唯一流,通常与单个客户端实例相关联(例如,商店中始终开启的信息亭系统,或用户启动的新浏览器会话)session_uid,表示单个交互会话。会话的组成取决于您的用例。user_uid,标识参与会话的用户。
- PipelineAcquired(
- stream_uid: str,
- session_uid: str | None,
- user_uid: str | None,
已获得新的管道。管道将 IM 连接到最终用户设备 (stream_uid)。此事件在基于事件的实现中通知 IM 关于新管道的可用性。
- 参数:
stream_uid (str) – 流的唯一标识符
session_uid (Optional[str]) – 会话的唯一标识符
user_uid (Optional[str]) – 用户的唯一标识符
... – 从
Event()继承的其他参数/有效负载。
集成#
本节提供用于将交互系统与其他应用程序或服务集成的操作,以提供交互系统可以利用的其他功能。
REST API 调用操作#
系统应进行 REST API 调用。
- StartRestApiCallBotAction(
- request_type: RequestType,
- url: str,
- headers: Dict[str, Any] | None,
- payload: Dict[str, Any] | None,
启动 API 调用。
- 参数:
request_type (RequestType) – 请求类型
url (str) – REST API 端点
headers (Optional[Dict[str, Any]]) – 自定义标头
payload (Optional[Dict[str, Any]]) – 将转换为 JSON 且 Content-Type 标头设置为 application/json 的 Dict
... – 从
StartBotAction()继承的其他参数/有效负载。
- RestApiCallBotActionStarted()#
API 调用已启动
- 参数:
... – 从
BotActionStarted()继承的其他参数/有效负载。
- RestApiCallBotActionFinished(response: Dict[str, Any])#
API 调用已完成
- 参数:
response (Dict[str, Any]) – 调用的响应
... – 从
BotActionFinished()继承的其他参数/有效负载。