NLP 服务器#
NLP 服务器提供了一个统一的接口,用于在对话管线中集成不同的 NLP 模型。它利用了已经过生产测试的模型服务器,如 NVIDIA Triton Inference Server,同时也允许在管线中轻松集成实验性的自定义模型。
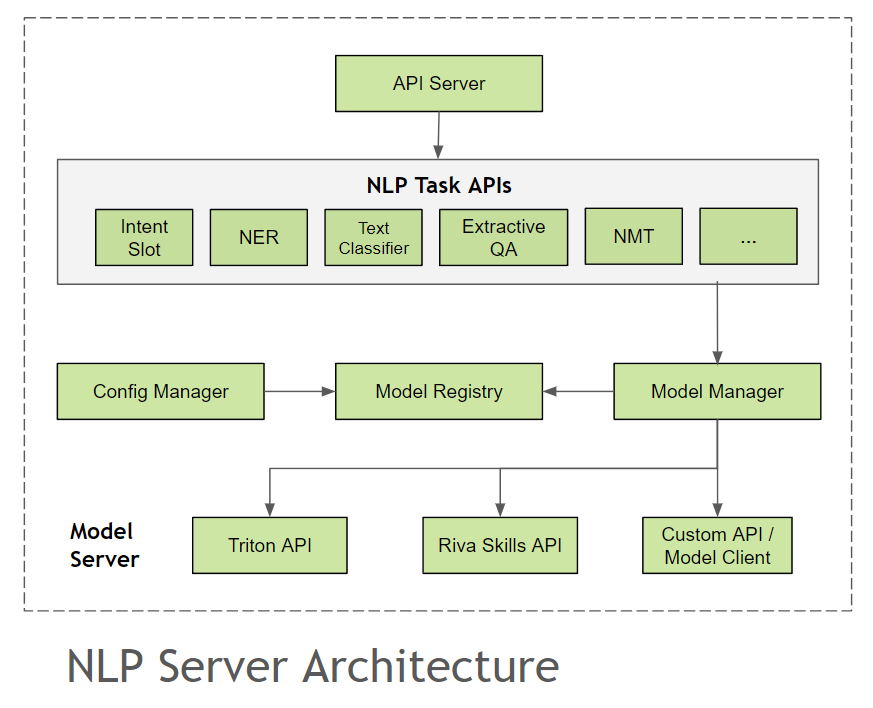
API 服务器#
API 服务器为不同的 NLP 任务提供了单独的端点,并具有预定义的输入和输出模式。API 服务器使用 FastAPI 作为异步 Web 框架,并结合 Gunicorn 管理多个 Uvicorn 工作进程来实现。您可以在NLP 服务器 API 文档中查看所有可用任务端点的列表。
NLP 支持以下任务
联合意图和槽位分类
命名实体识别 (NER)
抽取式问答
语言翻译 (NMT)
文本到语音 (TTS)
有关任务端点的更多详细信息,请参阅NLP 服务器 API 文档。
模型注册表#
模型注册表维护 NLP 服务器中当前可用于推理的所有模型的列表。它还将保留管理模型生命周期所需的所有元数据。下面是一些必需的字段
model_namemodel_versionapi endpointmodel_server_url和type元数据,例如
maximum_batch_size、language等
模型服务器#
模型服务器为外部部署的推理服务器(如 NVIDIA Triton Inference Server 和 NVIDIA Riva Skills)提供接口。每个模型服务器类都预置了辅助函数,例如监控模型健康状况、列出可用模型、获取模型配置等。对于 NLP 服务器支持的模型服务器,我们已经包含了用于不同模型的通用模型推理客户端。
配置管理器#
配置管理器管理不同的模型服务器,并使用 model_config.yaml 文件和自定义模型客户端目录在模型注册表中注册可用模型。如果在 model_config.yaml 中指定了某个模型服务器,但在服务器启动时未就绪,则配置管理器将跳过该模型服务器的注册。有关支持的模型服务器和 model_config.yaml 的模式的更多信息,请查看模型配置部分。
模型管理器#
NLP 服务器任务 API 端点验证模型注册表中模型的可用性,并将请求转发到模型管理器以执行。模型管理器将使用模型注册表识别特定于模型的推理客户端,执行推理代码,并返回响应。
自定义模型客户端#
NLP 服务器允许您轻松部署任何 Hugging Face、NeMo 或任何其他自定义模型,只需创建一个模型推理客户端,该客户端具有与 NLP 服务器任务 API 端点相同的输入和输出规范即可。它主要依赖于 @model_api 和 @pytriton 装饰器函数。
@model_api 装饰器#
您可以查看教程使用 @model_api 装饰器进行自定义模型集成,以了解如何使用 @model_api 装饰器。@model_api 装饰器函数接受以下关键字参数
参数 |
支持的类型 |
描述 |
|---|---|---|
|
|
NLP 服务器 API 端点路径。[必填] |
|
|
推理客户端支持的模型名称列表。[必填] |
|
|
模型服务器的名称。可用选项包括 |
|
|
模型的版本标签。[默认值为空字符串] |
|
|
参数和元数据的字典,推理客户端可以使用这些参数和元数据。[可选] |
@model_api 装饰器的另一个功能是在推理函数中轻松获取与模型服务器和模型本身相关的所有元数据。例如,要在推理函数中访问 Triton 模型服务器 gRPC URL
from nlp_server.decorators import model_api @model_api(endpoint="/nlp/model/text_classification", model_name="test_model", model_type="triton") def example_infer_func(input_request): ””” example_infer_func.model_info returns all metadata for the given model_name in input request in the same format as returned by /model/list_models API endpoint. The NLP server identifies the Triton URL during the model registration process via model_name and model_type provided in @model_api decorator. ””” url=example_infer_func.model_info.url # GRPC endpoint for triton server hosting the model parameters=example_infer_func.model_info.parameters # Any parameters passed via model_api decorator …
@pytriton 装饰器#
PyTriton 是一个类似 Flask/FastAPI 的接口,它简化了 Triton 在 Python 环境中的部署。该库允许通过 NVIDIA 的 Triton Inference Server 直接从 Python 提供机器学习模型。您可以查看教程使用 @pytriton 装饰器进行自定义模型集成,以了解如何在 NLP 服务器中使用 PyTriton 库。您需要将您的代码嵌入到类似于以下格式的 @pytriton 装饰器函数中,并且 NLP 服务器将创建一个 Triton 上下文并在加载所有 @pytriton 装饰的函数后进行 triton.serve 调用。
from pytriton.triton import Triton from nlp_server.decorators import pytriton @pytriton() def custom_pytriton_model(triton: Triton): # Embed your code in this function as required for hosting model with PyTriton library …
您还需要编写 @model_api 装饰的推理函数,以集成 PyTriton 托管的模型。