NVIDIA DALI 文档#
NVIDIA 数据加载库 (DALI) 是一个 GPU 加速库,用于数据加载和预处理,以加速深度学习应用。它为加载和处理图像、视频和音频数据提供了一系列高度优化的构建块。它可以作为流行的深度学习框架中内置数据加载器和数据迭代器的可移植即插即用替代品。
深度学习应用需要复杂的多阶段数据处理 pipeline,包括加载、解码、裁剪、调整大小和许多其他增强。这些数据处理 pipeline 目前在 CPU 上执行,已成为瓶颈,限制了训练和推理的性能和可扩展性。
DALI 通过将数据预处理卸载到 GPU 来解决 CPU 瓶颈问题。此外,DALI 依赖于其自身的执行引擎,该引擎旨在最大化输入 pipeline 的吞吐量。预取、并行执行和批量处理等功能对用户是透明处理的。
此外,深度学习框架具有多种数据预处理实现,导致了训练和推理工作流程的可移植性以及代码可维护性等挑战。使用 DALI 实现的数据处理 pipeline 是可移植的,因为它们可以轻松地重新定向到 TensorFlow、PyTorch 和 PaddlePaddle。
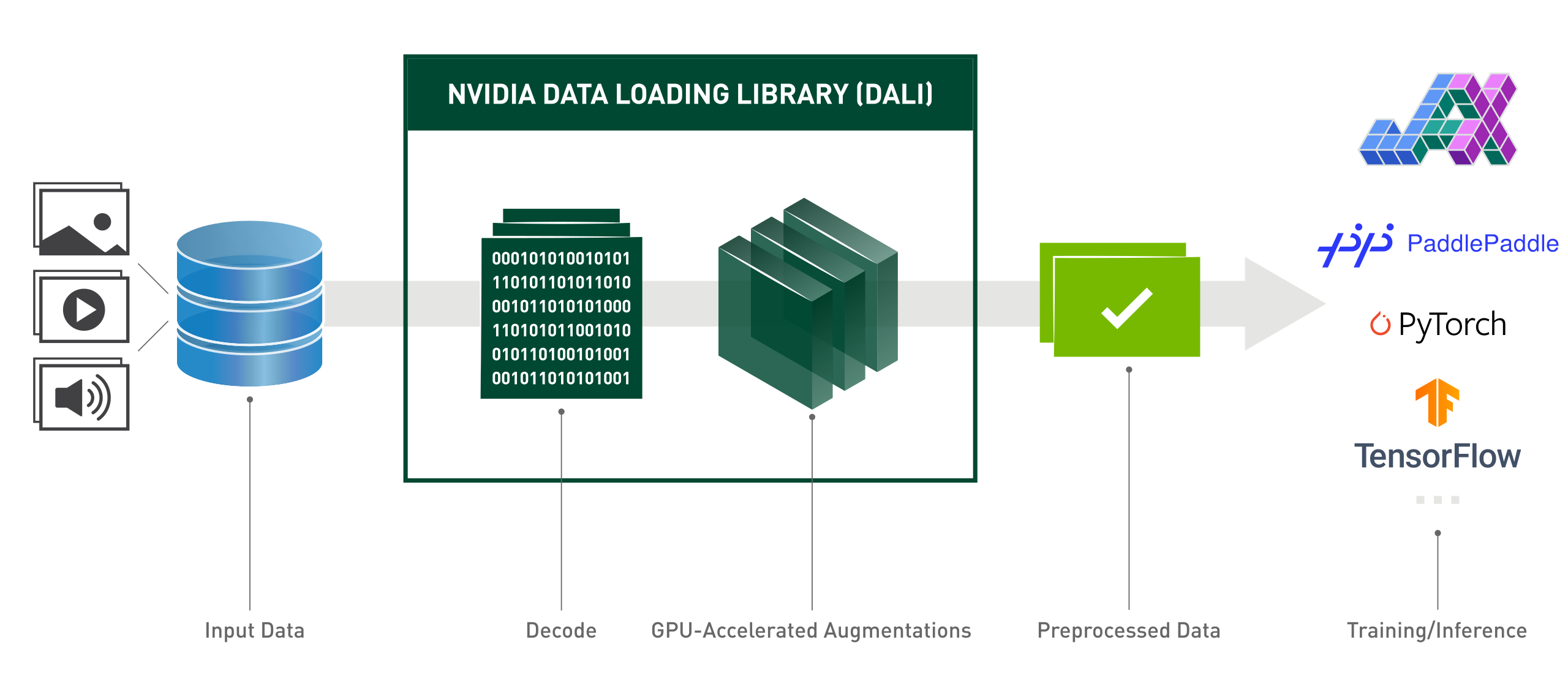
DALI 运行示例
from nvidia.dali.pipeline import pipeline_def
import nvidia.dali.types as types
import nvidia.dali.fn as fn
from nvidia.dali.plugin.pytorch import DALIGenericIterator
import os
# To run with different data, see documentation of nvidia.dali.fn.readers.file
# points to https://github.com/NVIDIA/DALI_extra
data_root_dir = os.environ['DALI_EXTRA_PATH']
images_dir = os.path.join(data_root_dir, 'db', 'single', 'jpeg')
def loss_func(pred, y):
pass
def model(x):
pass
def backward(loss, model):
pass
@pipeline_def(num_threads=4, device_id=0)
def get_dali_pipeline():
images, labels = fn.readers.file(
file_root=images_dir, random_shuffle=True, name="Reader")
# decode data on the GPU
images = fn.decoders.image_random_crop(
images, device="mixed", output_type=types.RGB)
# the rest of processing happens on the GPU as well
images = fn.resize(images, resize_x=256, resize_y=256)
images = fn.crop_mirror_normalize(
images,
crop_h=224,
crop_w=224,
mean=[0.485 * 255, 0.456 * 255, 0.406 * 255],
std=[0.229 * 255, 0.224 * 255, 0.225 * 255],
mirror=fn.random.coin_flip())
return images, labels
train_data = DALIGenericIterator(
[get_dali_pipeline(batch_size=16)],
['data', 'label'],
reader_name='Reader'
)
for i, data in enumerate(train_data):
x, y = data[0]['data'], data[0]['label']
pred = model(x)
loss = loss_func(pred, y)
backward(loss, model)
亮点#
易于使用的函数式风格 Python API。
支持多种数据格式 - LMDB、RecordIO、TFRecord、COCO、JPEG、JPEG 2000、WAV、FLAC、OGG、H.264、VP9 和 HEVC。
跨流行的深度学习框架可移植:TensorFlow、PyTorch、PaddlePaddle、JAX。
支持 CPU 和 GPU 执行。
可跨多个 GPU 扩展。
灵活的图表让开发人员可以创建自定义 pipeline。
可扩展,通过自定义操作符满足用户特定需求。
加速图像分类 (ResNet-50)、对象检测 (SSD) 工作负载以及 ASR 模型 (Jasper、RNN-T)。
通过 GPUDirect Storage 允许存储和 GPU 内存之间的直接数据路径。
通过 DALI TRITON Backend 轻松与 NVIDIA Triton Inference Server 集成。
开源。