音频频谱图#
背景#
在本示例中,我们将逐步构建 DALI 音频处理 Pipeline,包括频谱图的计算。频谱图是信号(例如音频信号)的表示,显示了频率频谱随时间的演变。
通常,频谱图是通过计算从原始信号中提取的一系列重叠窗口上的快速傅里叶变换 (FFT) 来计算的。将信号分成固定大小的短期序列并独立地对这些序列应用 FFT 的过程称为短时傅里叶变换 (STFT)。然后将频谱图计算为 STFT 的(通常是平方的)复数幅度。
从原始图像中提取短期窗口会通过产生混叠伪影来影响计算出的频谱。这通常称为频谱泄漏。为了控制/减少频谱泄漏效应,我们在提取窗口时使用不同的窗口函数。窗口函数的一些示例包括:Hann、Hanning 等。
超出本示例的范围,无法深入探讨我们上面提到的信号处理概念的细节。更多信息可以在这里找到
参考实现#
为了验证 DALI 实现的正确性,我们将它与 librosa (https://librosa.github.io/librosa/) 进行比较。
[1]:
import librosa as librosa
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import librosa.display
import os
DALI_EXTRA_PATH 环境变量应该指向从 DALI extra 仓库下载数据的位置。请确保检出正确的发布标签。
Librosa 提供了一个 API 来计算 STFT,产生复数输出(即复数)。然后,通过以下方式从复数 STFT 计算功率谱就变得很简单了。
[2]:
test_data_root = os.environ["DALI_EXTRA_PATH"]
sample_data = os.path.join(
test_data_root, "db", "audio", "wav", "237-134500-0000.wav"
)
# Size of the FFT, which will also be used as the window length
n_fft = 2048
# Step or stride between windows. If the step is smaller than the window length,
# the windows will overlap
hop_length = 512
# Load sample audio file
y, sr = librosa.load(sample_data)
# Calculate the spectrogram as the square of the complex magnitude of the STFT
spectrogram_librosa = (
np.abs(
librosa.stft(
y,
n_fft=n_fft,
hop_length=hop_length,
win_length=n_fft,
window="hann",
pad_mode="reflect",
)
)
** 2
)
现在,我们可以通过将幅度转换为分贝来将频谱图输出转换为对数刻度。在这样做时,我们还将对频谱图进行归一化,使其最大值表示 0 dB 点。
[3]:
spectrogram_librosa_db = librosa.power_to_db(spectrogram_librosa, ref=np.max)
最后一步是显示频谱图
[4]:
def show_spectrogram(spec, title, sr, hop_length, y_axis="log", x_axis="time"):
librosa.display.specshow(
spec, sr=sr, y_axis=y_axis, x_axis=x_axis, hop_length=hop_length
)
plt.title(title)
plt.colorbar(format="%+2.0f dB")
plt.tight_layout()
plt.show()
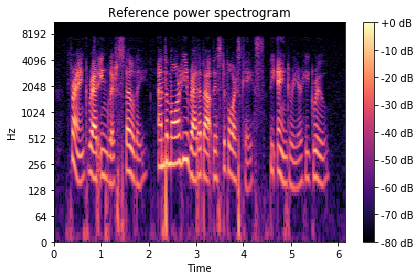
show_spectrogram(
spectrogram_librosa_db, "Reference power spectrogram", sr, hop_length
)
使用 DALI 计算频谱图#
为了演示 DALI 的 spectrogram 算子,我们将定义一个 DALI pipeline,其输入将借助 external_source 算子从外部提供。出于演示目的,我们可以在每次迭代中都提供相同的输入,因为我们只计算一个频谱图。
[5]:
from nvidia.dali import pipeline_def
import nvidia.dali.fn as fn
import nvidia.dali.types as types
import nvidia.dali as dali
audio_data = np.array(y, dtype=np.float32)
@pipeline_def
def spectrogram_pipe(nfft, window_length, window_step, device="cpu"):
audio = types.Constant(device=device, value=audio_data)
spectrogram = fn.spectrogram(
audio,
device=device,
nfft=nfft,
window_length=window_length,
window_step=window_step,
)
return spectrogram
定义了 pipeline 后,我们现在就可以构建并运行它
[6]:
pipe = spectrogram_pipe(
device="gpu",
batch_size=1,
num_threads=3,
device_id=0,
nfft=n_fft,
window_length=n_fft,
window_step=hop_length,
)
pipe.build()
outputs = pipe.run()
spectrogram_dali = outputs[0][0].as_cpu()
并像我们在参考实现中所做的那样显示它
[7]:
spectrogram_dali_db = librosa.power_to_db(spectrogram_dali, ref=np.max)
show_spectrogram(spectrogram_dali_db, "DALI power spectrogram", sr, hop_length)
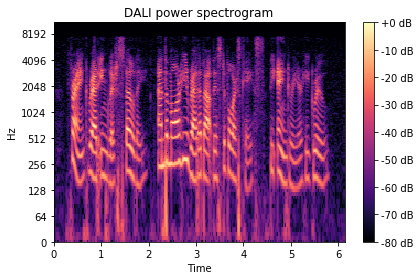
作为最后的健全性检查,我们可以验证参考实现和 DALI 之间的数值差异是否微不足道
[8]:
print(
"Average error: {0:.5f} dB".format(
np.mean(np.abs(spectrogram_dali_db - spectrogram_librosa_db))
)
)
assert np.allclose(spectrogram_dali_db, spectrogram_librosa_db, atol=2)
Average error: 0.00491 dB
梅尔频谱图#
梅尔刻度是对频率刻度的非线性变换,它基于对音高的感知。梅尔刻度的计算方式使得在梅尔刻度上相隔一个 delta 的两对频率被人类感知为等距。更多信息可以在这里找到:https://en.wikipedia.org/wiki/Mel_scale。
在涉及语音和音频的机器学习应用中,我们通常希望在梅尔刻度域中表示功率频谱图。我们通过应用一组重叠的三角滤波器来实现这一点,这些滤波器计算每个频带中频谱的能量。
通常,我们希望梅尔频谱图以分贝表示。我们可以使用以下 DALI pipeline 计算以分贝为单位的梅尔频谱图。
[9]:
@pipeline_def
def mel_spectrogram_pipe(nfft, window_length, window_step, device="cpu"):
audio = types.Constant(device=device, value=audio_data)
spectrogram = fn.spectrogram(
audio,
device=device,
nfft=nfft,
window_length=window_length,
window_step=window_step,
)
mel_spectrogram = fn.mel_filter_bank(
spectrogram, sample_rate=sr, nfilter=128, freq_high=8000.0
)
mel_spectrogram_dB = fn.to_decibels(
mel_spectrogram, multiplier=10.0, cutoff_db=-80
)
return mel_spectrogram_dB
[10]:
pipe = mel_spectrogram_pipe(
device="gpu",
batch_size=1,
num_threads=3,
device_id=0,
nfft=n_fft,
window_length=n_fft,
window_step=hop_length,
)
pipe.build()
outputs = pipe.run()
mel_spectrogram_dali_db = np.array(outputs[0][0].as_cpu())
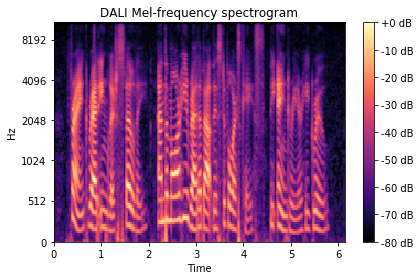
现在我们可以验证它是否产生与 Librosa 相同的结果
[11]:
show_spectrogram(
mel_spectrogram_dali_db,
"DALI Mel-frequency spectrogram",
sr,
hop_length,
y_axis="mel",
)
[12]:
mel_spectrogram_librosa = librosa.feature.melspectrogram(
y=y, sr=sr, n_mels=128, fmax=8000, pad_mode="reflect"
)
mel_spectrogram_librosa_db = librosa.power_to_db(
mel_spectrogram_librosa, ref=np.max
)
assert np.allclose(mel_spectrogram_dali_db, mel_spectrogram_librosa_db, atol=1)
梅尔频率倒谱系数 (MFCCs)#
MFCCs 是梅尔频率频谱图的另一种表示形式,常用于音频应用。MFCCs 是通过将离散余弦变换 (DCT) 应用于梅尔频率频谱图来计算的。
DALI 的 DCT 实现使用了 https://en.wikipedia.org/wiki/Discrete_cosine_transform 中描述的公式
除了 DCT 之外,还可以应用倒谱滤波器(也称为提升)来强调高阶系数。
提升后的倒谱系数根据以下公式计算
其中
其中 \(L\) 是提升系数。
有关 MFCC 的更多信息可以在这里找到:https://en.wikipedia.org/wiki/Mel-frequency_cepstrum。
我们可以使用 DALI 的 MFCC 算子将梅尔频谱图转换为一组 MFCCs
[13]:
@pipeline_def
def mel_spectrogram_pipe(
nfft,
window_length,
window_step,
dct_type,
n_mfcc,
normalize,
lifter,
device="cpu",
):
audio = types.Constant(device=device, value=audio_data)
spectrogram = fn.spectrogram(
audio,
device=device,
nfft=nfft,
window_length=window_length,
window_step=window_step,
)
mel_spectrogram = fn.mel_filter_bank(
spectrogram, sample_rate=sr, nfilter=128, freq_high=8000.0
)
mel_spectrogram_dB = fn.to_decibels(
mel_spectrogram, multiplier=10.0, cutoff_db=-80
)
mfccs = fn.mfcc(
mel_spectrogram_dB,
axis=0,
dct_type=dct_type,
n_mfcc=n_mfcc,
normalize=normalize,
lifter=lifter,
)
return mfccs
现在让我们运行 pipeline 并像之前一样显示输出
[14]:
pipe = mel_spectrogram_pipe(
device="gpu",
batch_size=1,
num_threads=3,
device_id=0,
nfft=n_fft,
window_length=n_fft,
window_step=hop_length,
dct_type=2,
n_mfcc=40,
normalize=True,
lifter=0,
)
pipe.build()
outputs = pipe.run()
mfccs_dali = np.array(outputs[0][0].as_cpu())
[15]:
plt.figure(figsize=(10, 4))
librosa.display.specshow(mfccs_dali, x_axis="time")
plt.colorbar()
plt.title("MFCC (DALI)")
plt.tight_layout()
plt.show()

作为最后一步,让我们验证此实现是否产生与 Librosa 相同的结果。请注意,我们正在比较正交归一化的 MFCCs,因为 Librosa 的 DCT 实现使用了不同的公式,这导致当我们将它与 Wikipedia 的公式进行比较时,输出会被缩放 2 倍。
[16]:
mfccs_librosa = librosa.feature.mfcc(
S=mel_spectrogram_librosa_db, dct_type=2, n_mfcc=40, norm="ortho", lifter=0
)
assert np.allclose(mfccs_librosa, mfccs_dali, atol=1)