多 GPU 支持#
概述#
生产级解决方案现在使用多台机器和多个 GPU,以便在合理的时间内运行神经网络的训练。本教程将向您展示如何使用多个 GPU 运行 DALI pipeline。
在选定的 GPU 上运行 Pipeline#
从与入门指南部分中的基本 pipeline 非常相似的 pipeline 开始。
此 pipeline 使用 GPU 来解码图像。这是通过
device参数的mixed值指定的。
[1]:
import nvidia.dali.fn as fn
import nvidia.dali.types as types
from nvidia.dali.pipeline import Pipeline
image_dir = "../data/images"
batch_size = 4
def test_pipeline(device_id):
pipe = Pipeline(batch_size=batch_size, num_threads=1, device_id=device_id)
with pipe:
jpegs, labels = fn.readers.file(
file_root=image_dir, random_shuffle=False
)
images = fn.decoders.image(jpegs, device="mixed", output_type=types.RGB)
pipe.set_outputs(images, labels)
return pipe
要在选定的 GPU 上运行此 pipeline,我们需要调整
device_id参数值。ID 序号与您的 CUDA 设备 ID 一致,因此您可以在 ID = 1 的 GPU 上运行它。
重要提示:请记住,以下代码适用于至少有 2 个 GPU 的系统。
[2]:
# Create and build the pipeline
pipe = test_pipeline(device_id=1)
pipe.build()
# Run pipeline on selected device
images, labels = pipe.run()
我们可以打印
images。
[3]:
import matplotlib.gridspec as gridspec
import matplotlib.pyplot as plt
%matplotlib inline
def show_images(image_batch):
columns = 4
rows = (batch_size + 1) // (columns)
fig = plt.figure(figsize=(32, (32 // columns) * rows))
gs = gridspec.GridSpec(rows, columns)
for j in range(rows * columns):
plt.subplot(gs[j])
plt.axis("off")
plt.imshow(image_batch.at(j))
[4]:
show_images(images.as_cpu())

分片#
仅仅在不同的 GPU 上运行 pipeline 是不够的。在训练期间,每个 GPU 需要同时处理不同的样本,这种技术称为分片。为了执行分片,数据集被分成多个部分或分片,每个 GPU 获得其自己的分片进行处理。
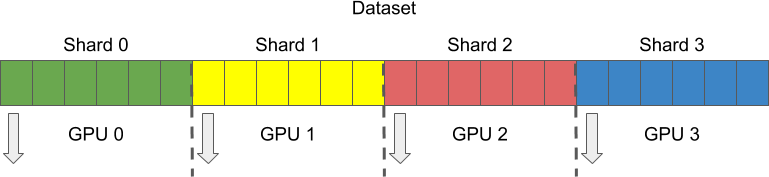
在 DALI 中,分片由每个 reader 操作的以下参数控制
shard_idnum_shards.
有关这些参数的更多信息,您可以查看任何 reader 操作符文档。
在以下示例中,您可以看到 pipeline 如何使用 shard_id 和 num_shards
[5]:
def sharded_pipeline(device_id, shard_id, num_shards):
pipe = Pipeline(batch_size=batch_size, num_threads=1, device_id=device_id)
with pipe:
jpegs, labels = fn.readers.file(
file_root=image_dir,
random_shuffle=False,
shard_id=shard_id,
num_shards=num_shards,
)
images = fn.decoders.image(jpegs, device="mixed", output_type=types.RGB)
pipe.set_outputs(images, labels)
return pipe
在两个不同的 GPU 上创建并运行两个 pipeline,并从数据集的不同分片中获取样本。
[6]:
# Create and build pipelines
pipe_one = sharded_pipeline(device_id=0, shard_id=0, num_shards=2)
pipe_one.build()
pipe_two = sharded_pipeline(device_id=1, shard_id=1, num_shards=2)
pipe_two.build()
# Run pipelines
images_one, labels_one = pipe_one.run()
images_two, labels_two = pipe_two.run()
当图像被打印出来时,我们可以清楚地看到每个 pipeline 处理了不同的样本。
[7]:
show_images(images_one.as_cpu())

[8]:
show_images(images_two.as_cpu())

在这个简单的教程中,我们向您展示了如何通过使用分片在多个 GPU 上运行 DALI pipeline。有关不同框架中更全面的示例,请参阅可用于 ResNet50 的训练脚本,例如 PaddlePadle、PyTorch 和 TensorFlow。
注意:这些脚本适用于多 GPU 系统。