Pipetuner 指南#
简介#
人工智能应用程序(例如,智能视频分析)的 Pipeline 通常由一组推理和处理模块组成,每个模块通常具有使用相应逻辑和算法实现的独特功能。 就像多项式函数中的系数决定函数输出的方式一样,这些逻辑和算法可能具有许多参数,这些参数决定了行为和特性。
当您尝试为您的应用程序定义和使用数据处理 Pipeline 时,此过程通常需要根据预期输出,使用不同参数集对 Pipeline 输出进行一系列 KPI 评估。 这种改变参数的过程是为了从 Pipeline 中获得最佳 KPI,并且在实践中通常通过繁琐的手动迭代过程来执行,或者可以使用简单的穷举/随机搜索,如图 1 所示
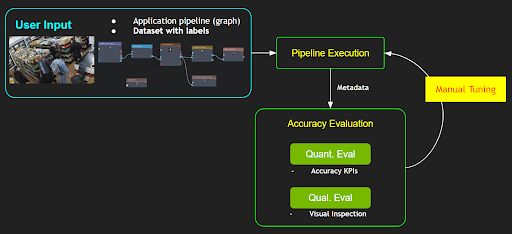
然而,这种手动调整过程要求人们对所有相关数据处理模块及其算法以及每个参数将如何影响功能有深入的了解。 如果 Pipeline 中的参数数量很大,则调整的复杂性将呈指数增长,对于普通用户来说,这将成为一项非常重要的任务。 此外,针对特定用例或数据集调整 Pipeline 可能会对其他用例或不同的数据集产生负面影响。 因此,Pipeline 的调整是用户系统部署的重要组成部分; 然而,它也是最大的挑战和痛点之一。
PipeTuner 是一种工具,它可以有效地探索(可能非常高维的)参数空间,并自动为 Pipeline 找到最佳参数,从而在用户提供的数据集上产生最高的 KPI。 使用 PipeTuner 的一个重要优势是用户不需要具备有关 Pipeline 及其参数的技术知识。 因此,PipeTuner 可以使看似令人生畏的 Pipeline 调整任务更容易被更广泛的技术知识用户所接受。
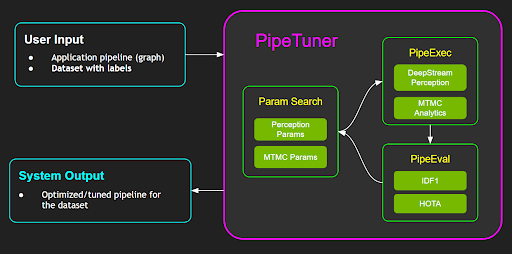
本文档是 PipeTuner 的完整用户指南,将引导用户完成易于遵循的逐步说明,以调整完整的 AI 处理 Pipeline,包括基于 DeepStream 的感知 Pipeline 和端到端 NVIDIA Metropolis 多目标多摄像头跟踪 Pipeline,这将在下面更详细地介绍
DeepStream 感知 Pipeline
典型的 DeepStream Pipeline 采用检测器(即 PGIE)和多目标跟踪器 (MOT) 来为每个流执行感知任务。 PipeTuner 允许用户根据 KPI 指标和数据集自动优化检测器和 MOT 参数,以实现可实现的最高感知精度 KPI。
Metropolis 多目标多摄像头跟踪 (MTMC) Pipeline
Metropolis MTMC 由每个摄像头的感知模块和一个 MTMC 分析模块组成,该分析模块聚合每个摄像头的感知结果,以产生跨多个摄像头的全局感知结果。 每个摄像头的感知由 DeepStream Pipeline 执行,感知结果被馈送到 MTMC 分析模块。 由于端到端 MTMC Pipeline 由两部分组成,因此用户可以根据需要选择仅调整 Pipeline 的一部分或整个端到端 Pipeline。
为了帮助用户更好地理解和设置 PipeTuner 工作流程,NGC 上发布的版本中提供了带有不同检测器和跟踪算法的示例数据和配置文件。 然后,用户可以为自己的用例自定义他们的 Pipeline 和数据集。
术语 |
定义 |
|---|---|
参数 |
一组数值或离散选择,用于确定软件或算法在准确性和性能方面的行为,通常在某些配置文件中定义,例如 DeepStream 或 MTMC 配置文件。 |
Pipeline |
一种软件,通常由多个模块组成,每个模块可能都有自己的一组参数,在给定输入数据(例如,用于感知或分析的视频处理)的情况下执行一些处理。 Pipeline 的输出可能包括一组从输入数据中提取的元数据,可以定性和定量地评估这些元数据。 |
准确性指标 |
一种评估标准或一种获取特定类型准确性值的方法,例如 MOTA、IDF1 或 HOTA。 这些指标通常在 0 到 1 的范围内。 |
优化器 |
一种优化算法或库,用于在定义的参数搜索空间中搜索全局最优参数 |
检查点 |
一个文件夹,用于存储调整期间中间步骤的准确性结果和相应的参数。 |
DS |
NVIDIA DeepStream SDK |
MOT |
单摄像头多目标跟踪,需要 NVIDIA DeepStream SDK。 Pipeline 是 DeepStream PGIE + Tracker。 输出包括目标边界框、ID、帧号等的元数据。 预计同一目标在每个摄像头/流的帧中具有唯一的持久 ID。 |
MTMC |
多目标多摄像头跟踪,需要访问 NVIDIA Metropolis Microservices。 Pipeline 由基于 DS 的感知和 MTMC 分析组成。 MTMC 的感知模块为每个目标提供元数据,包括边界框、ID 和 ReID 嵌入。 然后,MTMC 聚合来自多个摄像头的此类元数据,并使用它们对多个摄像头执行全局目标关联和聚类,并生成具有全局唯一目标 ID 的融合位置数据。 |
先决条件#
PipeTuner 支持 NVIDIA DeepStream SDK 和 Metropolis Microservices。 设置和使用有一些差异,如下所示。
DeepStream 用户 |
Metropolis Microservices 用户 |
|
|---|---|---|
我属于哪个用户组? |
我只想使用 DeepStream SDK |
我想使用 Metropolis Microservices。 我点击了“Download for Enterprise GPU”并申请了访问权限 |
容器 |
用户可以访问 DeepStream 容器 |
用户可以访问 Metropolis Standalone Deployment 软件包和 mdx-perception 容器 |
用例 |
仅支持 DeepStream 感知 Pipeline 调整 |
同时支持 DeepStream 感知和 MTMC Pipeline 调整 |
系统要求#
PipeTuner 需要 x86_64 系统上的以下组件
操作系统 Ubuntu 22.04
NVIDIA 驱动程序 535.104 或 535.161
Docker - 设置说明(需要以非 sudo 权限运行 - 说明)
NVIDIA 容器工具包 - 设置说明
NGC 设置#
用户需要按照以下步骤登录 NGC 帐户并获取 API 密钥。
访问 NGC 登录页面,输入您的电子邮件地址并单击“下一步”,或“创建帐户”。
当提示选择组织/团队时,选择您的组织。 DeepStream 用户可以使用任何组织和团队; Metropolis Microservice 用户需要选择 nv-mdx/mdx-v2-0; 单击“登录”。
按照说明生成 API 密钥。
登录到 NGC docker 注册表 (nvcr.io) 并输入以下凭据
$ docker login nvcr.io Username: $oauthtoken Password: "YOUR_NGC_API_KEY"其中
YOUR_NGC_API_KEY对应于您从上一步生成的密钥。
Metropolis Microservice 用户需要按照说明安装 NGC CLI,并按如下所示设置 ngc config。 DeepStream 用户可以跳过此步骤。
$ ngc config set Enter API key: "YOUR_NGC_API_KEY" Enter org: nfgnkvuikvjm Enter team: mdx-v2-0
示例数据设置#
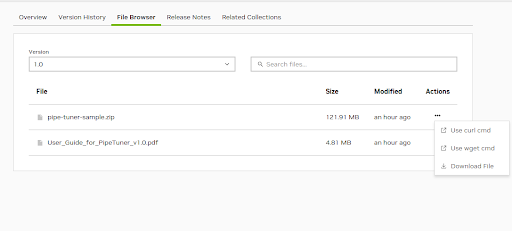
示例数据由一个包含八个 1 分钟流的迷你合成数据集和用于调整的配置文件组成。 您可以从 NGC Web UI 下载示例文件 pipe-tuner-sample.zip。 单击“操作”下的三个点,然后单击一个选项以下载文件,如下所示。
下载示例文件后,解压缩该文件并运行 setup.sh 以完成 DeepStream 或 Metropolis Microservices 的示例数据设置。
$ unzip pipe-tuner-sample.zip
$ cd pipe-tuner-sample/scripts
$ # DeepStream or Metropolis Microservices users should run only one of the following two commands based on their usage
$ bash setup.sh deepstream # DeepStream users
$ bash setup.sh metropolis # Metropolis Microservices users
DeepStream 调优案例#
执行设置脚本后,DeepStream 设置命令的预期控制台输出应如下所示
$ bash setup.sh deepstream
Setup for PipeTuner and DeepStream SDK...
Pulling required containers...
1.0: Pulling from nvidia/pipetuner
Digest: sha256:17df032022cf1e94514f8625fadfff123e1ec3f297d8647bbd980cbd0683dfcf
Status: Downloaded image for nvcr.io/nvidia/pipetuner:1.0
nvcr.io/nvidia/pipetuner:1.0
[1/2] Pulled pipe-tuner image
7.0-triton-multiarch: Pulling from nvidia/deepstream
Digest: sha256:d94590278fb116176b54189c9740d3a3577f6ab71b875b68588dfc38947f657b
Status: Downloaded image for nvcr.io/nvidia/deepstream:7.0-triton-multiarch
nvcr.io/nvidia/deepstream:7.0-triton-multiarch
[2/2] Pulled deepstream image
Downloading NGC models...
--2024-04-19 16:12:11-- https://api.ngc.nvidia.com/v2/models/nvidia/tao/peoplenet/versions/deployable_quantized_v2.6.1/zip
Resolving api.ngc.nvidia.com (api.ngc.nvidia.com)... 34.209.247.55, 35.160.16.170
Connecting to api.ngc.nvidia.com (api.ngc.nvidia.com)|34.209.247.55|:443... connected.
HTTP request sent, awaiting response... 302 Found
…
Saving to: ‘../ngc_download//peoplenet_deployable_quantized.zip’
../ngc_download//peoplenet_deployable_ 100%[===========================================================================>] 85.05M 26.3MB/s in 3.2s
2024-04-19 16:12:15 (26.3 MB/s) - ‘../ngc_download//peoplenet_deployable_quantized.zip’ saved [89182990/89182990]
Archive: ../ngc_download//peoplenet_deployable_quantized.zip
inflating: ../models/labels.txt
inflating: ../models/resnet34_peoplenet_int8.etlt
inflating: ../models/resnet34_peoplenet_int8.txt
--2024-04-19 16:12:15-- https://api.ngc.nvidia.com/v2/models/nvidia/tao/reidentificationnet/versions/deployable_v1.2/files/resnet50_market1501_aicity156.onnx
Resolving api.ngc.nvidia.com (api.ngc.nvidia.com)... 34.209.247.55, 35.160.16.170
Connecting to api.ngc.nvidia.com (api.ngc.nvidia.com)|34.209.247.55|:443... connected.
HTTP request sent, awaiting response... 302 Found
…
Saving to: ‘../models/resnet50_market1501_aicity156.onnx’
resnet50_market1501_aicity156.onnx 100%[===========================================================================>] 91.93M 29.0MB/s in 3.2s
2024-04-19 16:12:20 (29.0 MB/s) - ‘../models/resnet50_market1501_aicity156.onnx’ saved [96398132/96398132]
Updating DeepStream Perception SV3DT configs...
Sample data setup is done
$ cd pipe-tuner-sample/scripts
DeepStream 用户应看到如下所示的 docker 镜像。
$ docker images
REPOSITORY TAG
nvcr.io/nvidia/pipetuner 1.0
nvcr.io/nvidia/deepstream 7.0-triton-multiarc
此外,模型文件应位于“models”文件夹下。 它们将在调整期间映射到 DeepStream 容器中。
$ ls ../models
labels.txt resnet34_peoplenet_int8.etlt resnet34_peoplenet_int8.txt resnet50_market1501_aicity156.onnx
MTMC 调优案例#
执行如下所示的设置脚本后
$ bash setup.sh metropolis
Metropolis MTMC 用户应看到如下所示的 docker 镜像。“models”文件夹为空,因为将使用 mdx-perception 容器中的默认模型。
$ docker images
REPOSITORY TAG
nvcr.io/nvidia/pipetuner 1.0
nvcr.io/nfgnkvuikvjm/mdx-v2-0/mdx-perception 2.1
pipe-tuner-sample 下的最终目录如下所示
pipe-tuner-sample
├── configs
│ ├── config_CameraMatrix
│ ├── config_GuiTool
│ ├── config_MTMC
│ ├── config_PGIE
│ ├── config_PipeTuner
│ └── config_Tracker
├── data
│ ├── SDG_1min_utils
│ └── SDG_1min_videos
├── models
├── ngc_download
├── multi-camera-tracking (only for Metropolis Microservice)
└── scripts
快速入门#
PipeTuner 通过迭代以下三个步骤来搜索最佳参数,直到准确性 KPI 收敛或达到指定的最大迭代次数(即 epoch)
ParamSearch(参数搜索)
给定上一次迭代中的准确性 KPI 分数,对可能产生更高准确性 KPI 的参数集进行有根据的猜测。 对于第一次迭代,将在参数空间中进行随机抽样
PipeExec(Pipeline 执行)
给定抽样/猜测的参数集,使用参数执行 Pipeline 并生成元数据以允许准确性评估
PipeEval(Pipeline 评估)
给定来自 Pipeline 和数据集的元数据输出,根据准确性指标执行准确性评估并生成准确性 KPI 分数
pipe-tuner-sample/configs/config_PipeTuner 中包含示例 PipeTuner 配置文件,以帮助用户熟悉工作流程,以便他们稍后可以使用自己的数据集提出自定义 Pipeline。
目前,支持三种不同类型的 Pipeline 进行调整
基于 DS 的感知调优
具有冻结感知的 MTMC 调优
MTMC 端到端 (E2E) 调优
允许用户在 DeepStream 中为第一个和第三个用例采用不同的神经网络模型,例如,
对象检测器
基于 ResNet34 的 PeopleNet
基于 Transformer 的 PeopleNet
ReID 模型
基于 ResNet50 的 TAO ReID 模型
SWIN Transformer ReID 模型
DeepStream 中的多目标跟踪 (MOT) 可以使用 DeepStream 中的任何跟踪器类型,但对于 MTMC 感知,NvDCF 跟踪器被使用,因为它具有最高的准确性,并且还支持基于摄像头图像的 2D 跟踪和单视图 3D 跟踪(更多信息可以在 DeepStream 文档中找到)。
以下部分中带有示例数据和 Pipeline 的说明旨在逐步完成整个调整过程。
启动调优过程#
要运行示例 Pipeline,请输入 pipe-tuner-sample/scripts
$ cd pipe-tuner-sample/scripts
脚本 launch.sh 接受 PipeTuner 配置文件,自动启动容器并启动调优过程。 用法
$ bash launch.sh [deepstream or mdx-perception image name or id] [config_pipetuner.yml]
用户可以选择从以下示例中运行一个配置文件。
注意
每个示例 Pipeline 可能需要 3 到 40 小时才能完成,具体取决于模型大小和 GPU 类型。 为了减少调优周转时间,用户可以选择使用较小的数据集或减少最大迭代次数(即 ../configs/config_PipeTuner/ 文件夹中 PipeTuner 配置文件中的“max_iteration”参数),如下例所示。 它当前设置为“100”,但用户可以将其设置为 5 或 10 以进行快速实验。 用户仍然可以将其保留为 100 并在中间停止它(稍后将解释如何在中间停止调优过程)
# black box optimization configs
bbo:
...
# different optimizers for tuning. Comment or uncomment to select different optimizers
# change max_iteration to set tuning iterations
optimizers:
type1:
name: "pysot"
max_iteration: 100
DS 感知调优#
此用例优化 DeepStream PGIE(即对象检测)和跟踪器参数以提高感知准确性。 PipeExec 步骤的 Pipeline 构建为
(文件源流) → 解码器 → PGIE → MOT→ (每个流的跟踪结果)
然后执行 PipeEval 步骤以进行 MOT 评估,从而生成准确性 KPI 分数。
要启动使用基于 ResNet34 的 PeopleNet 模型和带有 TAO ReID 模型的 NvDCF 跟踪器的 Pipeline,例如,根据您的用户组运行以下命令之一: 对于 DeepStream 用户
$ bash launch.sh nvcr.io/nvidia/deepstream:7.0-triton-multiarch ../configs/config_PipeTuner/SDG_sample_PeopleNet-ResNet34_NvDCF-ResNet50_MOT.yml
对于 Metropolis Microservices 用户
$ bash launch.sh nvcr.io/nfgnkvuikvjm/mdx-v2-0/mdx-perception:2.1 ../configs/config_PipeTuner/SDG_sample_PeopleNet-ResNet34_NvDCF-ResNet50_MOT.yml # For Metropolis Microservices users
要启动使用基于 Transformer 的 PeopleNet 模型和带有基于 SWIN 的 ReID 模型且启用 SV3DT 的 NvDCF 跟踪器的 Pipeline,例如,运行
$ bash launch.sh nvcr.io/nfgnkvuikvjm/mdx-v2-0/mdx-perception:2.1 ../configs/config_Pipecccccbldttjhbecjtvbvgrtdclfvtnetlifccucjnbuj
Tuner/SDG_sample_PeopleNet-Transformer_NvDCF-SWIN-3D_MOT.yml # For Metropolis Microservices users
具有冻结感知的 MTMC 调优#
此用例假设来自 DS 感知 Pipeline 的元数据(即 MOT 结果 + ReID 嵌入)已生成并存储在 JSON 格式中。 仅搜索 MTMC 参数。 Pipeline 使用该元数据作为固定输入,并搜索可产生最高 MTMC 准确性的最佳 MTMC 参数。 PipeExec 步骤的 Pipeline 是
(MOT 结果 + ReID 嵌入) → MTMC 分析 → (带有全局 ID 的 MTMC 结果)
要启动 Pipeline,请运行
$ bash launch.sh nvcr.io/nfgnkvuikvjm/mdx-v2-0/mdx-perception:2.1 ../configs/config_PipeTuner/SDG_sample_MTMC_only.yml
MTMC E2E 调优#
此用例联合优化 DS 感知(即 PGIE 和跟踪器)和 MTMC 参数,以进行 e2e MTMC 准确性调优。 这为优化提供了最高的灵活性,但由于 Pipeline 的复杂性,耗时最长。 PipeExec 的 Pipeline 如下所示: (文件源流) → 解码器 → PGIE → MOT→ (每个流的跟踪结果) → MTMC 分析 → (带有全局 ID 的 MTMC 结果)
要启动 e2e MTMC Pipeline,其 DS 感知模块由基于 ResNet34 的 PeopleNet 模型和带有 TAO ReID 模型的 NvDCF 跟踪器组成,例如,运行
$ bash launch.sh nvcr.io/nfgnkvuikvjm/mdx-v2-0/mdx-perception:2.1 ../configs/config_PipeTuner/SDG_sample_PeopleNet-ResNet34_NvDCF-ResNet50_MTMC.yml
要启动 e2e MTMC Pipeline,其 DS 感知模块由基于 Transformer 的 PeopleNet 模型和带有基于 SWIN 的 ReID 模型且启用 SV3DT 的 NvDCF 跟踪器组成,例如,运行
$ bash launch.sh nvcr.io/nfgnkvuikvjm/mdx-v2-0/mdx-perception:2.1 ../configs/config_PipeTuner/SDG_sample_PeopleNet-Transformer_NvDCF-SWIN-3D_MTMC.yml
输出#
启动后,Pipeline 输出将保存在以下目录中,例如。
pipe-tuner-sample
├── output
│ ├── log_client_2023-08-23_16-39-36
│ ├── log_server_2023-08-23_16-39-36
│ ├── <PipeTuner configname.yml>
│ └── <PipeTuner configname.yml>_output
│ ├── checkpoints
│ │ ├──DsAppRun_output_20230823_163959
│ │ ├──DsAppRun_output_20230823_164106
│ │ └──…
│ └── results
│ ├──configs_08-23-2023_16-39-57
│ └──<PipeTuner configname.yml>-2023-08-23_16-39-36_accuracy.csv
└──…
说明
log_client_2023-08-23_16-39-36 和 log_server_2023-08-23_16-39-36 是 PipeTuner 容器内部服务器和客户端的日志文件。
<PipeTuner config name.yml> 存储自动生成的用于调优的配置文件
每个检查点文件夹(例如 DsAppRun_output_20230823_163959)存储一个检查点,其中包含该迭代的已调优参数和准确性指标。 此外,该文件夹还包含日志文件 (log_DsAppRun.log),其中包含 DeepStream 应用程序的输出。
configs_08-23-2023_16-39-57 存储自动生成的用于 Pipeline 组件(例如 PGIE、跟踪器)的配置文件。
<PipeTuner config name.yml>-2023-08-23_16-39-36_accuracy.csv 是一个 csv 文件,用于存储所有迭代的准确性指标和参数值。
下面显示了控制台输出的外观
Installing dependencies...
Installing dependencies (1/2)
Installing dependencies (2/2)
Launch BBO client...
Launch BBO server...
PipeTuner started successfully!
!!!!! To stop tuning process in the middle, press CTRL+C !!!!!
adding: DsAppServer (deflated 63%)
2024-03-19 08:09:52,108 root INFO seq_list: ['Retail_Synthetic_Cam01', 'Retail_Synthetic_Cam02', 'Retail_Synthetic_Cam03', 'Retail_Synthetic_Cam04', 'Retail_Synthetic_Cam05', 'Retail_Synthetic_Cam06', 'Retail_Synthetic_Cam07', 'Retail_Synthetic_Cam08']
2024-03-19 08:09:52,169 root INFO Writing configs to <path>/output/SDG_sample_PeopleNet-ResNet34_NvDCF-ResNet50_MOT_test.yml_output/results/configs_03-19-2024_08-09-52
2024-03-19 08:09:52,169 root INFO send backend init
2024-03-19 08:09:52,170 root INFO creating optimizers...
2024-03-19 08:09:52,170 root INFO done. created 2
* Serving Flask app 'ds_bbo_frontend_server'
* Debug mode: on
2024-03-19 08:09:52,186 root INFO init jobs done
2024-03-19 08:09:52,187 root INFO progress: 0% (0/4)
2024-03-19 08:09:52,193 root INFO wait backend ready
...
2024-03-19 08:12:15,232 root INFO progress: 25% (1/4) ETA 00:07:09
2024-03-19 08:12:25,447 root INFO progress: 25% (1/4) ETA 00:07:39
...
2024-03-19 08:13:47,190 root INFO progress: 50% (2/4) ETA 00:03:55
2024-03-19 08:13:57,413 root INFO progress: 75% (3/4) ETA 00:01:21
...
2024-03-19 08:14:58,719 root INFO progress: 100% (4/4) ETA 00:00:00
2024-03-19 08:14:58,720 root INFO OPTIMIZATION DONE!
…
stopping workers...
number of workers to stop: 2
number of workers to stop: 0
done.
!!!!! Press CTRL+C key to end PipeTuner !!!!!
通过以下方式检查正在运行的容器
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
83b909fc0ddb nvcr.io/nvidia/pipetuner:1.0 "/bin/bash" 44 minutes ago Up 44 minutes tuner_2024-01-17_21-44-58
41e514acf177 nvcr.io/nfgnkvuikvjm/mdx-v2-0/mdx-perception:2.1 "/opt/nvidia/nvidia_…" 44 minutes ago Up 44 minutes ds_2024-01-17_21-44-58
注意
TensorRT 引擎文件在第一次迭代期间生成,因此可能比下一次迭代花费的时间长 10 到 30 分钟。
停止 PipeTuner#
当优化结束时,控制台上会显示 “!!!!! Press CTRL+C key to end PipeTuner !!!!!”。 可以通过按 CTRL+C 键简单地停止 PipeTuner。 按 CTRL+C 键会停止 PipeTuner 和正在运行的 docker 容器。 此外,也可以在优化过程中间使用按键停止 PipeTuner。 调优结果仍然保存在输出目录中。 例如,
!!!!! Press CTRL+C key to end PipeTuner !!!!!
^C
Ctrl + C pressed!
Stopping containers...
tuner_2024-04-23_21-36-49
ds_2024-04-23_21-36-49
Containers stopped successfully
PipeTuner ends
(可选)launch.sh 会停止 docker 镜像,但不会删除它们。 如果用户想要删除下载的容器,他们可以使用命令 docker rm -f [container names] 简单地删除它们。
$ docker rm -f tuner_2024-01-17_21-44-58 ds_2024-01-17_21-44-58
检索和可视化调优结果#
PipeTuner 提供以下功能来获取已调优的参数和结果。
绘制准确性收敛图
检索最佳检查点
以下所有命令都在 pipe-tuner-sample/scripts 下执行
用法:在启动调优几个迭代后,运行以下命令以从已生成的检查点检索最佳结果
$ bash result_analysis.sh <output folder> <metric>
此处 <output folder> 是在“启动调优过程”步骤中创建的输出目录:pipe-tuner-sample/output/<PipeTuner configname.yml>_output,<metric> 应与 PipeTuner 配置中定义的评估指标相同,即 MOTA、IDF1 和 HOTA 之一。
例如,要检索 SDG_sample_PeopleNet-ResNet34_NvDCF-ResNet50_MOT.yml 的结果,用户可以运行以下命令
$ bash result_analysis.sh ../output/SDG_sample_PeopleNet-ResNet34_NvDCF-ResNet50_MOT.yml_output/ HOTA
结果分析保存在以下目录中
pipe-tuner-sample
├── output
│ ├── …
│ └── SDG_sample_PeopleNet-ResNet34_NvDCF-ResNet50_MOT.yml_output
│ ├── …
│ └── results
│ ├──accuracy_plot.png
│ └──DsAppRun_output_20230823_163959
└──…
说明:
pipe-tuner-sample/output/SDG_sample_PeopleNet-ResNet34_NvDCF-ResNet50_MOT.yml_output/results/ 下复制的检查点文件夹(例如 DsAppRun_output_20230823_163959)是最佳检查点,其中包含已调优的 PGIE、跟踪器、DeepStream 配置文件和准确性指标,非常适合部署。
accuracy_plot.png 是准确性指标与迭代次数的关系图
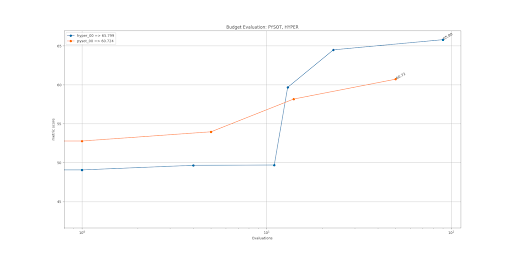
控制台输出:
storage: /media/sdb/pipe-tuner-sample
Result analysis command:
docker run --gpus all --rm -itd --net=host --name analysis_2023-08-23_16-53-39 -v /var/run/docker.sock:/var/run/docker.sock -v /media/sdb/pipe-tuner-sample:/media/sdb/pipe-tuner-sample nvcr.io/nvidia/pipetuner:1.0 /bin/bash -c "python3 /pipe-tuner/utils/plot_csv_results.py /media/sdb/pipe-tuner-sample/output/SDG_sample_PeopleNet-ResNet34_NvDCF-ResNet50_MOT.yml_output/results/*.csv /media/sdb/pipe-tuner-sample/output/SDG_sample_PeopleNet-ResNet34_NvDCF-ResNet50_MOT.yml_output/results/accuracy_plot.png; python3 /pipe-tuner/utils/retrieve_checkpoints.py /media/sdb/pipe-tuner-sample/output/SDG_sample_PeopleNet-ResNet34_NvDCF-ResNet50_MOT.yml_output HOTA;"
Found optimal HOTA: 44.942
Checkpoint path: /media/sdb/pipe-tuner-sample/output/SDG_sample_PeopleNet-ResNet34_NvDCF-ResNet50_MOT.yml_output/checkpoints/DsAppRun_output_20230823_163959
Optimal checkpoint copied to: /media/sdb/pipe-tuner-sample/output/SDG_sample_PeopleNet-ResNet34_NvDCF-ResNet50_MOT.yml_output/results/DsAppRun_output_20230823_163959
…
自定义调优#
本节介绍如何自定义调优过程,包括使用新的数据集、模型和配置文件。 阅读“理解 PipeTuner 配置文件路径”部分,了解如何定义路径并将其映射到 docker 容器中。
理解 PipeTuner 配置文件路径#
<path>/pipe-tuner-sample/ 是唯一从主机映射到所有容器的文件夹。 自定义调优时,所有与调优相关的文件都必须放在此文件夹中。 在运行时,PipeTuner 配置文件中的 rootPath 会自动被示例数据文件夹的绝对路径 <path>/pipe-tuner-sample/ 覆盖。 在 PipeTuner 配置文件中,所有其他路径都是相对于 rootPath 的相对路径。 例如,如果 seqmapPath 是 data/SDG_1min_utils/SDG_1min_all.txt,则其绝对路径是 <path>/pipe-tuner-sample/data/SDG_1min_utils/SDG_1min_all.txt
parameter_space:
Init:
Exec:
…
rootPath: "overwritten as <path>/pipe-tuner-sample/ runtime"
datasetPath: "data/SDG_1min_videos"
seqmapPath: "data/SDG_1min_utils/SDG_1min_all.txt"
…
在 PGIE 和跟踪器配置文件中,所有路径都是绝对路径。 它们需要手动更新以匹配机器上的实际路径。 其他配置文件中的路径是自动生成的,因此无需更改它们。
自定义数据集#
在 PipeTuner 中使用自定义数据集的步骤是
创建视频文件
创建真值标签
使用新的配置文件启动 PipeTuner
不同的用例需要不同的数据集文件。 只需要为所需的用例生成文件。 例如,如果用例是 DS 感知调优,则只需要遵循“创建视频文件 - DS 感知调优”和“创建真值标签 - DS 感知调优”。
创建视频文件#
DS 感知调优#
添加视频:在 pipe-tuner-sample/data 下创建一个新的视频文件夹。 它应该包含用于调优的所有视频。 视频需要具有 1920x1080 分辨率的 mp4 格式。
pipe-tuner-sample
data
<新的数据集视频>
<video0.mp4>
<video1.mp4>
...
创建序列图:在 pipe-tuner-sample/data 下创建一个新的 utils 文件夹。 创建一个 txt 文件 <seqmap.txt>,其中包含所有不带“.mp4”扩展名的视频名称
pipe-tuner-sample
data
<新的数据集 utils>
<seqmap.txt>
<seqmap.txt> 中的内容如下。 第一行应始终为“name”,然后每行是一个视频名称。 name <video0> <video1> …
更新 PipeTuner 配置文件:更改 PipeTuner 配置文件
SDG_sample_PeopleNet-ResNet34_NvDCF-ResNet50_MOT.yml中的 datasetPath、seqmapPath 以匹配新的跟踪器配置文件的路径。datasetPath: "data/<new dataset videos>/" seqmapPath: "data/<new dataset utils>/<seqmap.txt>"
具有冻结感知的 MTMC 调优#
添加视频:不需要。 创建序列图:与 DS 感知调优中的“创建序列图”部分相同。 更新 PipeTuner 配置文件:更改 PipeTuner 配置文件 SDG_sample_MTMC_only.yml 中的 seqmapPath 以匹配新的跟踪器配置文件的路径。 seqmapPath: “data/<新的数据集 utils>/<seqmap.txt>”
MTMC E2E 调优#
所有步骤与 DS 感知调优相同,除了 PipeTuner 配置文件位于 PipeTuner 配置文件 SDG_sample_PeopleNet-ResNet34_NvDCF-ResNet50_MTMC.yml 中。
创建真值标签#
DS 感知调优#
在 data/<new dataset videos> 中创建 ground truth 文件。对于每个视频,创建如下的 gt.txt 和 seqinfo.ini
pipe-tuner-sample
data
- <new dataset videos> - <video0> - seqinfo.ini - gt - gt.txt - <video1> - seqinfo.ini - gt - gt.txt - …
gt.txt是 MOT 格式的 DS 感知 ground truth 标签文件,格式如下:frame_num, object_id, left, top, width, height, included_for_eval, class_id, visibility_ratio
示例
3,1,315,176,22,32,1,1,1 3,4,511,130,30,88,1,1,1
seqinfo.ini是序列信息文件。其格式如下。第一行必须是 [Sequence]。可以有多个参数,但实际上只需要 seqLength。[Sequence] seqLength=<num of frames in the video> <other info>
评估脚本会自动在 datasetPath 中找到上述 ground truth 文件,因此无需更改 PipeTuner 配置。
使用冻结感知进行 MTMC 调优#
在 pipe-tuner-sample/data/<new dataset utils> 下添加 MTMC 相机校准文件和 MTMC ground truth 文件。MTMC ground truth 文件格式为 camera, id, frame, left, top, width, height, x_on_ground, y_on_ground
运行 DeepStream 感知 pipeline 以生成包含 Re-ID 特征的单相机跟踪结果,作为 MTMC 输入。MTMC 输入为 JSON 格式,由 Kafka schema 定义。将其放置在 pipe-tuner-sample/data/<new dataset utils> 下。更改 PipeTuner 配置中的 mtmcCalibrationPath、mtmcGroundTruthPath 和 mtmcPlaybackPath,以匹配新 tracker 配置的路径。mtmcCalibrationPath: “data/<new dataset utils>/<calibration.json>” mtmcGroundTruthPath: “data/<new dataset utils>/<MTMC ground truth.txt>” mtmcPlaybackPath: “data/<new dataset utils>/<MTMC input.json>”
MTMC E2E 调优#
在 pipe-tuner-sample/data/<new dataset utils> 下添加 MTMC 相机校准文件和 MTMC ground truth 文件。MTMC ground truth 文件格式为 camera, id, frame, left, top, width, height, x_on_ground, y_on_ground
更改 PipeTuner 配置中的 mtmcCalibrationPath 和 mtmcGroundTruthPath,以匹配新 tracker 配置的路径。mtmcCalibrationPath: “data/<new dataset utils>/<calibration.json>” mtmcGroundTruthPath: “data/<new dataset utils>/<MTMC ground truth.txt>”
使用新配置文件启动 PipeTuner#
检查 PipeTuner 配置文件以确保所有路径都有效。调优工作流程与示例数据集相同。下表总结了新数据集中要包含的文件。“v” 表示特定用例需要这些文件;
数据集组件 |
内容格式要求 |
文件名要求 |
示例数据集中的路径 |
PipeTuner 配置 |
单相机 MOT 调优 |
具有冻结感知的 MTMC 调优 |
MTMC E2E 调优 |
|---|---|---|---|---|---|---|---|
视频文件 |
mp4 格式;所有视频均为 1920x1080 分辨率 |
视频必须存储在 datasetPath 文件夹下。视频名称必须与 sequence map 匹配。 |
data/SDG_1min_videos/Retail_Synthetic_Cam01.mp4 data/SDG_1min_videos/Retail_Synthetic_Cam02.mp4 |
... |
datasetPath |
v |
v |
Sequence map |
包含用于调优的所有视频名称 |
任何名称都可以 |
data/SDG_1min_utils/SDG_1min_all.txt |
seqmapPath |
v |
v |
v |
MOT ground truth |
MOT ground truth |
<datasetPath>/<video name>/gt/gt.txt |
data/SDG_1min_videos/Retail_Synthetic_Cam01/gt/gt.txt |
data/SDG_1min_videos/Retail_Synthetic_Cam02/gt/gt.txt |
... |
datasetPath |
v |
MOT 序列信息 |
包含视频信息 |
<datasetPath>/<video_name>/seqinfo.ini |
data/SDG_1min_videos/Retail_Synthetic_Cam01/seqinfo.ini |
datasetPath |
v |
... |
... |
MTMC 相机校准 |
MDX 团队定义的相机校准格式 |
任何名称都可以 |
data/SDG_1min_utils/calibration.json |
mtmcCalibrationPath |
v |
v |
|
MTMC ground truth |
MDX 团队定义的 MTMC ground truth |
任何名称都可以 |
data/SDG_1min_utils/ground_truth.txt |
mtmcGroundTruthPath |
v |
v |
|
MTMC 示例输入 |
JSON 格式;消息遵循 MDX 团队定义的 kafka schema |
任何名称都可以 |
data/SDG_1min_utils/mtmc_playback_sample.json |
mtmcPlaybackPath |
v |
数据增强#
PipeTuner 帮助查找用于数据集的最佳参数。如果用于调优的数据集不能代表相机系统将要部署的物理环境,该怎么办?如果调优的参数过度拟合数据集,而数据集又不够通用,那么这些调优的参数在实际部署到测试环境时可能无法很好地工作。
为了缓解这个问题,PipeTuner 提供了一个额外的工具,通过引入人工噪声或遮挡来增强数据集,从而使调优的参数对真实测试环境中可能存在的那些变化具有鲁棒性。
目前,数据增强工具仅具有非常简单的遮挡诱导功能,但未来可以扩展以提供更广泛的种类。
以下部分说明了数据增强工具的示例用法。
视频生成#
要生成增强视频,请在 pipe-tuner-sample/scripts 下执行以下命令
$ bash create_aug_videos.sh <input video folder>
<input video folder>:包含用于数据增强的视频的文件夹
示例
$ bash create_aug_videos.sh ../data/SDG_1min_videos/
增强视频保存在以下目录中。
pipe-tuner-sample
data
SDG_1min_videos_augmented
Retail_Synthetic_Cam01.mp4
Retail_Synthetic_Cam02.mp4
...
Retail_Synthetic_Cam01/
Retail_Synthetic_Cam02/
解释
Retail_Synthetic_Cam<num>.mp4是生成的增强视频,如下所示。
文件夹
Retail_Synthetic_Cam<num>包含单相机 MOT 标签,这些标签与原始数据集相同。控制台输出
Launch command: docker run --gpus all -it --rm --net=host --privileged -v /tmp/.X11-unix:/tmp/.X11-unix -e DISPLAY= -v /media/sdb/pipe-tuner-sample:/media/sdb/pipe-tuner-sample pipe-tuner:latest /bin/bash /pipe-tuner/utils/launch_augmenter.sh /media/sdb/pipe-tuner-sample/data/SDG_1min_videos Augment /media/sdb/pipe-tuner-sample/data/SDG_1min_videos/Retail_Synthetic_Cam01.mp4 as /media/sdb/pipe-tuner-sample/data/SDG_1min_videos_augmented/Retail_Synthetic_Cam01.mp4 [VideoSource] Total # of frames = 1800 [VideoSource] Video frame rate = 30 fps [FrameSourceUtil] Frame source type = VIDEO OpenCV: FFMPEG: tag 0x34363248/'H264' is not supported with codec id 27 and format 'mp4 / MP4 (MPEG-4 Part 14)' OpenCV: FFMPEG: fallback to use tag 0x31637661/'avc1' Wrote 0 frames among 1800 Wrote 100 frames among 1800 …
在 DS 感知调优中使用#
在增强数据集上调优 DS 感知参数,并在没有增强的普通数据集上使用调优后的配置文件。与不进行增强的调优相比,观察到更少的 ID 切换和更高的准确率指标。
要将增强数据集用于 DS 感知调优,只需更改 PipeTuner 配置文件中的 datasetPath 以匹配增强数据集的路径即可。
下图显示的是,即使原始数据集没有如此大的完全遮挡情况(即,中间的白色垂直杆),如果 pipeline 使用具有更长完全遮挡的增强数据集进行调优,那么 pipeline 的调优方式是即使在原始数据集中不存在的长时间遮挡的情况下,跟踪也可以稳健地完成。

自定义模型#
示例配置中使用的 PGIE 和 Re-ID 模型已包含在 mdx-perception 容器中。当在 PipeTuner 中使用自定义的 PGIE 和 Re-ID 模型时,需要按照以下步骤将其添加到主机上的 pipe-tuner-sample/models 目录中。
NGC 上的模型#
以下 PGIE 和 Re-ID 模型在示例配置中使用,可以从 NGC 下载。
对象检测器(即 PGIE)
基于 ResNet34 的 PeopleNet
基于 Transformer 的 PeopleNet
ReID 模型
基于 ResNet50 的 TAO ReID 模型
SWIN Transformer ReID 模型
对象检测器(即 PGIE)#
自定义 PGIE 模型并在 PipeTuner 中使用它的步骤是
参考 DeepStream 中如何自定义模型。将所有模型资源放置在 pipe-tuner-sample/models 下,例如标签文件、模型文件、模型引擎和自定义库等。
pipe-tuner-sample
models
labels.txt
<ETLT 文件>
<ONNX 文件>
<engine file>
<Custom library if any>
...
创建一个新的 PGIE 配置文件,如 pipe-tuner-sample/configs/config_PGIE/<new PGIE config.txt>,确保以下参数与新模型的绝对路径匹配。
model-engine-file=<path>/pipe-tuner-sample/models/<engine file> labelfile-path=<path>/pipe-tuner-sample/models/labels.txt # for TAO model tlt-encoded-model=<path>/pipe-tuner-sample/models/<ETLT file> # for ONNX model onnx-file=<path>/pipe-tuner-sample/models/<ONNX file>其他参数也需要根据模型架构进行更改。
更改 PipeTuner 配置中的 pgiePath 以匹配新 PGIE 配置的路径。
pgiePath: "configs/config_PGIE/<new PGIE config.txt>"
Re-ID#
自定义 Re-ID 模型并在 PipeTuner 中使用它的步骤是
参考 DeepStream tracker 中自定义 Re-ID 模型。将所有模型资源放置在 pipe-tuner-sample/models 下。
pipe-tuner-sample
models
<ETLT 文件>
<ONNX 文件>
<engine file>
...
创建一个新的 tracker 配置文件,如 pipe-tuner-sample/configs/config_Tracker/<new tracker config.yml>,确保以下参数与新模型的绝对路径匹配。
# for TAO model tltEncodedModel: <path>/pipe-tuner-sample/models/Tracker/<ETLT file> # for ONNX model onnxFile: <path>/pipe-tuner-sample/models/Tracker/<ONNX file> modelEngineFile: <path>/pipe-tuner-sample/models/Tracker/<engine file> Other parameters need changing based on the model architecture as well.
更改 PipeTuner 配置中的 trackerPath 以匹配新 tracker 配置的路径。
trackerPath: "configs/config_Tracker/<new Tracker config.yml>"
自定义算法#
DeepStream 和 Metropolis 为 DS 感知和 MTMC 提供了多种算法。用户可以通过更改相应的配置文件来启用它们。
多目标跟踪器#
当前使用的 DeepStream tracker 是 NvDCF_accuracy,但也可以使用其他算法,例如 NvDeepSORT 或 NvSORT。将新的 tracker 配置文件放置为 pipe-tuner-sample/configs/config_Tracker/<new tracker config.yml>,并更改 PipeTuner 配置中的 trackerPath 以匹配新路径。
单视图 3D 跟踪#
示例 config_Tracker/config_tracker_NvDCF_accuracy_ResNet50_3D.yml 和 config_Tracker/config_tracker_NvDCF_accuracy_SWIN_3D.yml 已经提供了单相机 3D 跟踪的示例。它们使用 config_CameraMatrix 目录中预生成的相机矩阵配置。当切换到新数据集时,用户需要
按照 DeepStream 文档中的步骤生成新的相机矩阵配置
使用新的相机矩阵配置的绝对路径更新 tracker 配置中的 cameraModelFilepath
MTMC 分析#
当前使用的 MTMC 分析算法配置文件是 pipe-tuner-sample/configs/config_MTMC/config_mtmc_app.json。如果需要新的 MTMC 配置文件,请将其放置为 pipe-tuner-sample/configs/config_MTMC/<new MTMC config.yml>,并更改 PipeTuner 配置中的 mtmcPath 以匹配新路径。
自定义参数#
更改准确率指标#
单相机 MOT 或 MTMC 支持三种准确率指标:MOTA、IDF1 和 HOTA。可以在 PipeTuner 配置文件中更改,如下所示:
parameter_space:
Init:
…
Eval:
metric: 'HOTA' # accuracy metric across ['MOTA', 'IDF1', 'HOTA']
参数搜索空间#
PGIE、tracker 和 MTMC 配置文件中有很多参数。每个参数的搜索空间在 PipeTuner 配置文件中定义为 parameter_name: [ lower_bound, upper_bound (included), distribution, data_type ]。在每次迭代期间,都会在搜索范围内生成一个值,并覆盖原始的 PGIE、tracker 或 MTMC 配置文件。
注意
parameter_name 必须存在于原始配置文件中。lower_bound、upper_bound 必须在参数的可行范围内。
如果参数出现在原始配置文件中,但未出现在 PipeTuner 配置中,则其值将固定为原始值。
以下是 PipeTuner 配置中的示例。不同的用例具有不同的参数搜索空间。可以随意添加、更改或删除搜索空间。更多的参数和更大的搜索范围需要更多的优化器和更长的迭代才能运行,但可以比小范围给出更好的结果。
parameter_space:
Init:
…
NvDCF:
BaseConfig:
minDetectorConfidence: [ 0,0.9,linear,real ]
StateEstimator:
processNoiseVar4Loc: [ 1,10000,linear,real ]
…
PGIE:
"[class-attrs-all]":
nms-iou-threshold: [ 0.3,0.8,linear,real ]
…
MTMC:
default:
locationBboxBottomGapThresh: [0.01,0.05,linear,real ]
…
优化器#
支持五种优化器:pysot、tpe、hyper、opentuner 和 scikit。不同的优化器生成不同的检查点,最佳检查点从所有启用的优化器中选择。取消注释 PipeTuner 配置中的以下部分以启用优化器(例如 tpe)。通常,2 或 3 个优化器可以给出令人满意的结果。更改 max_iteration 以控制每个优化器的迭代次数。
bbo:
problem_type_is_min: false
job_batch_size: 1
optimizers:
type1:
name: "pysot"
max_iteration: 100
redundancy: 1
batch_size: 1
# type2:
# name: "tpe"
# max_iteration: 100
# redundancy: 1
# batch_size: 1
…
建议将 worker_number 设置为等于使用的优化器数量。
servers:
server1:
…
worker_number: 2
优化管理器配置#
当 DeepStream 应用程序可能因错误而运行失败或输出零 KPI 分数时,优化管理器可以捕获失败或零分数。如果 DeepStream 应用程序的失败或零分数过多,则优化过程会立即停止。我们可以设置零分数和失败次数的阈值。
threshold_zero_scores:如果 DeepStream 应用程序的零分数数量高于此参数,则该过程停止。
threshold_ds_app_fails:如果 DeepStream 应用程序的失败次数高于此参数,则该过程停止。
# optimization manager configs
optim_manager:
# threshold for the number of 0 scores
threshold_zero_scores: 10
# threshold for the number of DS app fails
threshold_ds_app_fails: 3
更新日志#
版本 1.0#
功能#
允许调优基于 DeepStream 的感知 pipeline
允许调优端到端 MTMC pipeline(即,DS-感知 + MTMC-分析)
将 BBO 客户端日志消息输出到控制台和日志文件。日志级别为 DEBUG、INFO、WARNING 和 ERROR。所有级别消息都记录在日志文件中,而高于 INFO 级别的消息显示在控制台中。
将 DeepStream 应用程序的日志消息另存为文件 (log_DsAppRun.log),位于 “checkpoints/DsAppRun_output__XXXX” 下
检查 DS 应用程序的最后一条日志消息是否为 “App run failed”,然后在控制台中查找并显示包含 Error、ERROR 和 [Exception] 的消息。
如果来自 DS 应用程序的 0 分数数量高于可配置参数,则输出错误消息并停止所有进程
如果 DS 应用程序失败次数高于可配置参数,则输出错误消息并停止所有进程