GXF 内部原理#
本节介绍了帮助理解 GXF 基本构建块的指南。应用程序开发中的关键组件之一是 Codelets,理解其生命周期非常重要。
Codelet 的生命周期#
codelet 的生命周期由以下五个阶段管理
Initialize(初始化):用于轻量级初始化。在首次创建 codelet 时直接调用。在 codelet 的生命周期内只调用一次。
Deinitialize(反初始化):用于轻量级反初始化。在销毁 codelet 之前直接调用。在 codelet 的生命周期内只调用一次。
Start(启动):用于重量级初始化,以分配执行所需的资源。可以根据生命周期定义的顺序在 codelet 的生命周期内多次调用。
Stop(停止):用于重量级反初始化,以释放由启动函数分配的所有资源。可以根据生命周期定义的顺序在 codelet 的生命周期内多次调用。
Tick(节拍):在 codelet 被触发时调用。触发可以发生在数据到达时或基于时间触发。通常在 codelet 的生命周期内调用多次。
Codelet 组件用于定义将完成所需工作的自定义 codelet。以下示例描述了如何实现自定义 codelet。现在请忽略 :ref: registerInterface,这将在后面的章节中介绍。
class Test : public Codelet { public: gxf_result_t start() override { return GXF_SUCCESS; } gxf_result_t tick() override { // Do Something ... return GXF_SUCCESS; } gxf_result_t stop() override { return GXF_SUCCESS; } gxf_result_t registerInterface(Registrar* registrar) override { Expected<void> result; result &= registrar->parameter(some_parameter_, "Some Parameter"); return ToResultCode(result); } Parameter<Handle<Receiver>> some_parameter_; };
以下示例展示了如何创建一个简单的自定义 codelet 来打印“Hello World”
class HelloWorld : public Codelet { public: gxf_result_t start() override { return GXF_SUCCESS; } gxf_result_t tick() override { GXF_LOG_INFO("Hello World from GXF"); return GXF_SUCCESS; } gxf_result_t stop() override { return GXF_SUCCESS; } gxf_result_t registerInterface(Registrar* registrar) override { Expected<void> result; result &= registrar->parameter(some_parameter_, "Some Parameter"); return ToResultCode(result); } Parameter<Handle<Receiver>> some_parameter_; };
以下示例探讨了如何使用 initialize/deinitialize 和 start/stop 阶段
class File : public Codelet { public: gxf_result_t initialize() { access_file_ = true; return GXF_SUCCESS; } gxf_result_t start() override { if (access_file_) { file_ = fopen("Some File Name", "Read or Write Mode"); if (file_ == nullptr) { GXF_LOG_ERROR("%s", strerror(errno)); return Unexpected{GXF_FAILURE}; } } return GXF_SUCCESS; } gxf_result_t tick() override { // Do some file operation return GXF_SUCCESS; } gxf_result_t stop() override { const int result = fclose(file_); if (result != 0) { GXF_LOG_ERROR("%s", strerror(errno)); return Unexpected{GXF_FAILURE}; } file_ = nullptr; return GXF_SUCCESS; } gxf_result_t deinitialize() override { access_file_ = false; return GXF_SUCCESS; } gxf_result_t registerInterface(Registrar* registrar) override { Expected<void> result; result &= registrar->parameter(some_parameter_, "Some Parameter"); // Not used here return ToResultCode(result); } Parameter<Handle<Receiver>> some_parameter_; bool access_file_{false}; std::FILE* file_; };
GXF 调度器#
图中实体的执行由调度器和与每个实体关联的调度项管理。调度器是负责协调图中定义的所有实体执行的组件。调度器通常跟踪图实体及其当前执行状态,并在准备好执行时将其传递给 nvidia::gxf::EntityExecutor 组件。下图描述了实体执行的流程。
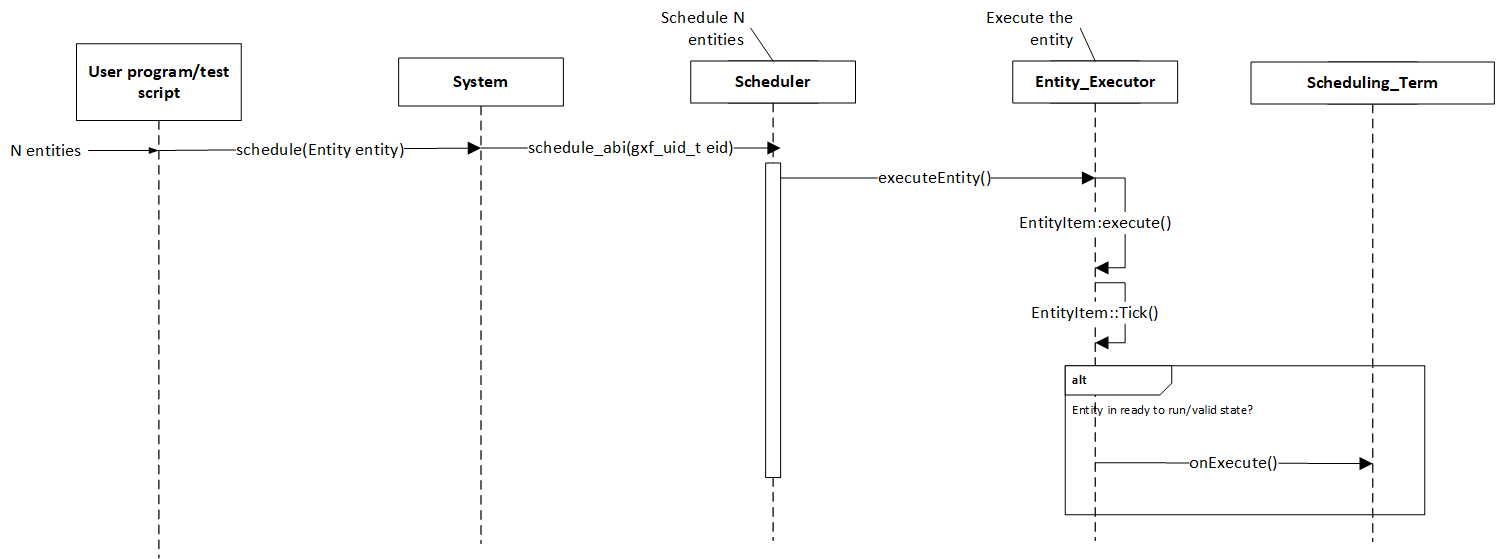
图:实体执行序列
如序列图所示,调度器通过 nvidia::gxf::System::runAsync_abi() 接口开始执行图实体,并持续此过程直到满足某些结束条件。单个实体可以有多个 codelet。这些 codelet 按照它们在实体中定义的相同顺序执行。任何单个 codelet 执行失败都会停止所有实体的执行。当任何一个实体的调度项达到 NEVER 状态时,实体自然会从执行中取消调度。
调度项是用于定义实体执行就绪状态的组件。一个实体可以有多个与之关联的调度项,每个调度项使用 SchedulingCondition 表示实体的状态。
下表显示了使用 nvidia::gxf::SchedulingCondition 描述的 nvidia::gxf::SchedulingConditionType 的各种状态。
SchedulingConditionType |
描述 |
|---|---|
NEVER |
实体将永远不再执行 |
READY |
实体已准备好执行 |
WAIT |
实体将来可能会执行 |
WAIT_TIME |
实体将在指定持续时间后准备好执行 |
WAIT_EVENT |
实体正在等待具有未知时间间隔的异步事件 |
调度器将 deadlock(死锁)定义为当没有处于 READY、WAIT_TIME 或 WAIT_EVENT 状态的实体保证在未来某个时间点执行时的情况。这意味着所有实体都处于 WAIT 状态,调度器不知道它们是否会在未来达到 READY 状态。可以配置调度器,使其在使用 stop_on_deadlock 参数达到这种状态时停止,否则会轮询实体以检查它们中的任何一个是否已达到 READY 状态。max_duration 配置参数可用于在指定时间量过去后停止所有实体的执行,而不管它们的状态如何。

图:所有调度器的实体状态转换
GXF 当前支持四种类型的调度器
Greedy Scheduler(贪婪调度器)
Multithread Scheduler(多线程调度器)
Epoch Scheduler(Epoch 调度器)
Event Based Scheduler(基于事件的调度器)
Greedy Scheduler(贪婪调度器)#
这是一个基本的单线程调度器,它贪婪地测试调度项。它非常适合简单的用例和可预测的执行,但可能会产生大量的调度项执行开销,使其不适合大型应用程序。调度器需要一个时钟来跟踪时间。根据时钟的选择,调度器的执行方式会有所不同。如果使用 Realtime clock(实时时钟),调度器将实时执行。这意味着暂停执行 - 休眠线程,直到周期性调度项再次到期。如果使用 ManualClock(手动时钟),调度将以“时间压缩”的方式发生。这意味着时间流被改变为立即连续执行 codelet。
GreedyScheduler 维护处于 READY、WAIT_TIME 和 WAIT_EVENT 状态的实体的运行计数。以下活动图描述了贪婪调度器调度实体的决策要点 -
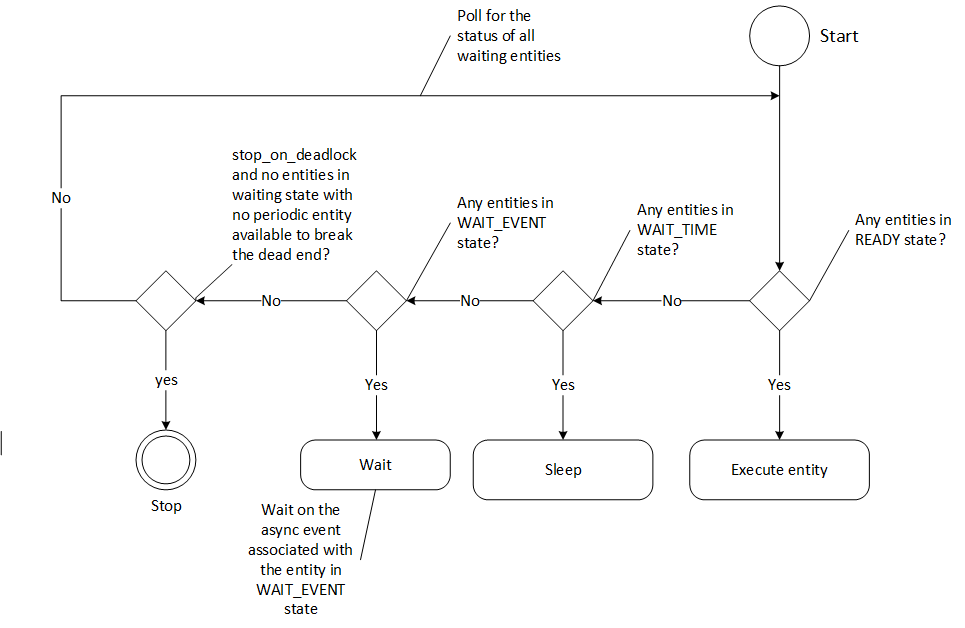
图:贪婪调度器活动图
Greedy Scheduler 配置#
贪婪调度器从配置文件中获取以下参数
参数名称 |
描述 |
|---|---|
clock |
调度器用来定义时间流逝的时钟。典型的选择是 RealtimeClock 或 ManualClock |
max_duration_ms |
调度器将执行的最长时间(以毫秒为单位)。如果未指定,调度器将运行直到完成所有工作。如果存在周期性项,则意味着应用程序将无限期运行 |
stop_on_deadlock |
如果 stop_on_deadlock 被禁用,GreedyScheduler 会不断轮询所有等待实体的状态,以检查它们中的任何一个是否已准备好执行。 |
示例用法 - 以下代码片段配置了一个指定了 ManualClock 选项的贪婪调度器。
name: scheduler
components:
- type: nvidia::gxf::GreedyScheduler
parameters:
max_duration_ms: 3000
clock: misc/clock
stop_on_deadlock: true
---
name: misc
components:
- name: clock
type: nvidia::gxf::ManualClock
Multithread Scheduler(多线程调度器)#
Multithread 调度器更适合具有复杂执行模式的大型应用程序。调度器由一个调度器线程组成,该线程检查实体的状态并将其调度到负责执行它们的工作线程池。工作线程在执行完成后将实体重新排队到调度队列中。可以使用 worker_thread_number 参数配置工作线程的数量。Multithread 调度器还管理一个专用队列和线程来处理异步事件。以下活动图演示了多线程调度器实现的要点。
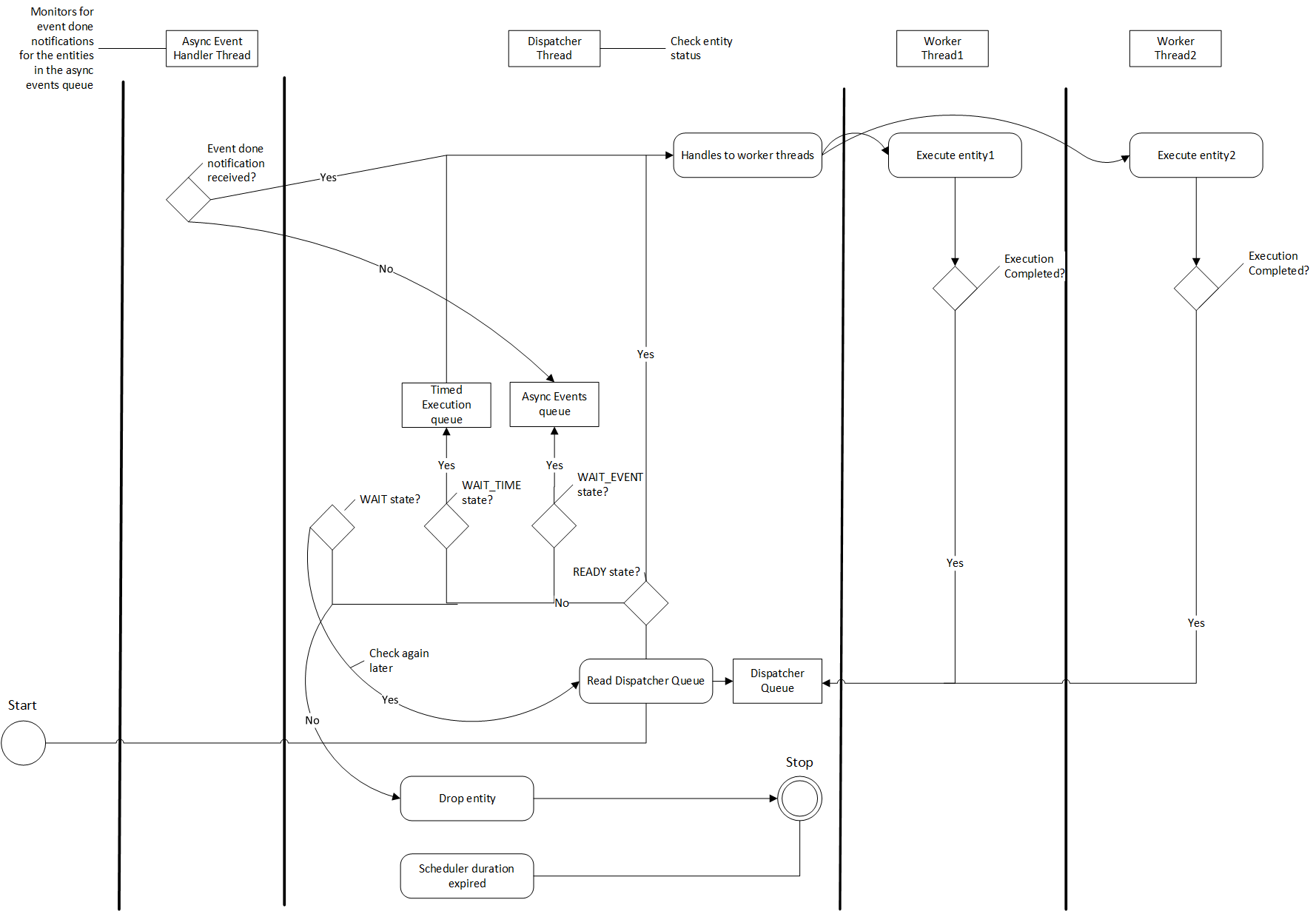
图:多线程调度器活动图
如图所示,当实体达到 WAIT_EVENT 状态时,它会被移动到一个队列中,在那里它们等待接收事件完成通知。异步事件处理程序线程负责在接收到事件完成通知后将实体移动到调度器。调度器线程还维护处于 READY、WAIT_EVENT 和 WAIT_TIME 状态的实体数量的运行计数,并使用这些统计信息来检查调度器是否已达到死锁。调度器还需要一个时钟组件来跟踪时间,它可以使用 clock 参数进行配置。
与 Greedy Scheduler 相比,Multithread 调度器资源效率更高,并且不会产生任何额外的开销来不断轮询调度项的状态。check_recession_period_ms 参数可用于配置调度器必须等待多长时间才能轮询处于 WAIT 状态的实体的状态。
Multithread Scheduler 配置#
多线程调度器从配置文件中获取以下参数
参数名称 |
描述 |
|---|---|
clock |
调度器用来定义时间流逝的时钟。典型的选择是 RealtimeClock 或 ManualClock。 |
max_duration_ms |
调度器将执行的最长时间(以毫秒为单位)。如果未指定,调度器将运行直到完成所有工作。如果存在周期性项,则意味着应用程序将无限期运行。 |
check_recess_period_ms |
再次检查实体条件之前的休眠时间 [毫秒]。这是当实体尚未准备好运行时,调度器将等待的最长时间。 |
stop_on_deadlock |
如果启用,当所有实体都处于等待状态,但不存在周期性实体来打破僵局时,调度器将停止。当调度条件可以由外部参与者更改时,应禁用此功能,例如手动清除队列。 |
worker_thread_number |
线程数。 |
示例用法 - 以下代码片段配置了一个指定了工作线程数和最大持续时间的多线程调度器 -
name: scheduler
components:
- type: nvidia::gxf::MultiThreadScheduler
parameters:
max_duration_ms: 5000
clock: misc/clock
worker_thread_number: 5
check_recession_period_ms: 3
stop_on_deadlock: false
---
name: misc
components:
- name: clock
type: nvidia::gxf::RealtimeClock
Event Based Scheduler(基于事件的调度器)#
Event Based 调度器更适合具有复杂执行模式的大型应用程序。此调度器维护三个不同的队列,分别保存处于 READY 或 WAIT_TIME、WAIT_EVENT 和 WAIT 状态的实体。事件被定义为任何实体的调度项中的更改,它可以由时间持续时间到期、实体执行、用户线程调用的 API、跨边缘的消息传输等触发。事件在实体执行结束时或在调度条件状态更改后生成。此外,基于事件的调度器启动了多个工作线程、异步事件处理程序线程和一个调度器线程。工作线程从 READY 或 WAIT_TIME 队列中弹出实体并获取它们以供执行。执行完成后,工作线程生成一个事件。调度器线程通过评估其调度条件来响应事件,从而将实体从一个队列移动到另一个队列。异步事件处理程序线程响应外部事件。调度器线程和异步事件处理程序线程在事件之间休眠,从而节省 CPU 周期。可以使用 worker_thread_number 参数配置工作线程的数量。
消息传递和事件#
组件彼此通信以完成定义的管道。消息是组件彼此通信的形式。实体具有发射器和接收器队列,以便发送和接收消息。上游实体的发射器连接到下游实体的接收器。GXF 允许发射器和接收器之间存在 M × N 连接,其中 M 是发射器的数量,N 是接收器的数量。在组件从其接收器队列中消耗消息后,会生成一个事件来通知上游实体,以便它可以评估其调度项并允许更改其调度条件。类似地,当组件将消息发布到下游实体时,它会生成一个事件来通知该实体。调度器线程负责处理事件和评估调度项。此操作称为调度实体。

图:消息传递事件活动图
调度器线程还维护处于 READY、WAIT_EVENT 和 WAIT_TIME 状态的实体数量的运行计数,并使用这些统计信息来检查调度器是否已达到死锁。调度器还需要一个时钟组件来跟踪时间,它可以使用 clock 参数进行配置。
Event Based Scheduler 配置#
Event Based 调度器从配置文件中获取以下参数
参数名称 |
描述 |
|---|---|
clock |
调度器用来定义时间流逝的时钟。典型的选择是 RealtimeClock 或 ManualClock。 |
max_duration_ms |
调度器将执行的最长时间(以毫秒为单位)。如果未指定,调度器将运行直到完成所有工作。如果存在周期性项,则意味着应用程序将无限期运行。 |
stop_on_deadlock |
如果启用,当所有实体都处于等待状态,但不存在周期性实体来打破僵局时,调度器将停止。当调度条件可以由外部参与者更改时,应禁用此功能,例如手动清除队列。 |
worker_thread_number |
线程数。 |
thread_pool_allocation_auto |
如果启用,则只会创建一个线程池。如果禁用,用户应枚举池和优先级。 |
stop_on_deadlock_timeout |
当 stop_on_dead_lock 指示应停止时,调度器将等待此时间量。如果在等待期间有作业进入,它将重置。负值表示不因死锁而停止。 |
示例用法 - 以下代码片段配置了一个指定了工作线程数和最大持续时间的基于事件的调度器 -
name: scheduler
components:
- type: nvidia::gxf::EventBasedScheduler
parameters:
max_duration_ms: 5000
clock: misc/clock
stop_on_deadlock: false
worker_thread_number: 5
thread_pool_allocation_auto: true
stop_on_deadlock_timeout: 500
---
name: misc
components:
- name: clock
type: nvidia::gxf::RealtimeClock
Epoch Scheduler(Epoch 调度器)#
Epoch 调度器用于在外部管理的线程中运行负载。每次运行称为一个 Epoch。调度器遍历所有已知处于活动状态的实体,并逐个执行它们。如果提供了 epoch 预算(以毫秒为单位),它将持续运行所有 codelet,直到预算耗尽或没有 codelet 准备好为止。它可能会超出预算,因为它保证覆盖 epoch 中的所有 codelet。如果未提供预算,它将遍历所有 codelet 一次,并且仅执行一次。
epoch 调度器从配置文件中获取以下参数 -
参数名称 |
描述 |
|---|---|
clock |
调度器用来定义时间流逝的时钟。典型的选择是 RealtimeClock。 |
示例用法 - 以下代码片段配置了一个 Epoch 调度器 -
name: scheduler
components:
- name: clock
type: nvidia::gxf::RealtimeClock
- name: epoch
type: nvidia::gxf::EpochScheduler
parameters:
clock: clock
请注意,epoch 调度器旨在从外部线程运行。runEpoch(float budget_ms); 可用于设置 budget_ms 并从外部线程运行调度器。如果指定的预算不是正数,则所有节点都将执行一次。
SchedulingTerms(调度项)#
SchedulingTerm 定义了一个特定条件,实体使用该条件来通知调度器它何时准备好执行。GXF 当前支持各种调度项。如果一个实体中存在多个调度项,则所有调度项都必须为真,实体才能执行。
PeriodicSchedulingTerm(周期性调度项)#
与 nvidia::gxf::PeriodicSchedulingTerm 关联的实体在以其 recess_period 参数指定的周期性时间间隔之后准备好执行。PeriodicSchedulingTerm 可以处于 READY 或 WAIT_TIME 状态。
示例用法 -
- name: scheduling_term
type: nvidia::gxf::PeriodicSchedulingTerm
parameters:
recess_period: 50000000
CountSchedulingTerm(计数调度项)#
与 nvidia::gxf::CountSchedulingTerm 关联的实体将执行特定次数,次数由其 count 参数指定。CountSchedulingTerm 可以处于 READY 或 NEVER 状态。当实体已执行 count 次数时,调度项达到 NEVER 状态。
示例用法 -
- name: scheduling_term
type: nvidia::gxf::CountSchedulingTerm
parameters:
count: 42
MessageAvailableSchedulingTerm(消息可用调度项)#
当关联的接收器队列至少具有一定数量的元素时,将执行与 nvidia::gxf::MessageAvailableSchedulingTerm 关联的实体。接收器使用调度项的 receiver 参数指定。允许实体执行的最小消息数由 min_size 指定。此调度项的可选参数是 front_stage_max_size,即最大前台消息计数。如果设置了此参数,则只有当队列中的消息数不超过此计数时,调度项才允许执行。它可用于不消耗队列中所有消息的 codelet。
在下面显示的示例中,队列的最小大小配置为 4。因此,在队列中至少有 4 条消息之前,实体将不会执行。
- type: nvidia::gxf::MessageAvailableSchedulingTerm
parameters:
receiver: tensors
min_size: 4
MultiMessageAvailableSchedulingTerm(多消息可用调度项)#
当提供的输入接收器列表组合在一起至少具有给定数量的消息时,将执行与 nvidia::gxf::MultiMessageAvailableSchedulingTerm 关联的实体。receivers 参数用于指定输入通道/接收器列表。允许实体执行所需的最小消息数由 min_size 参数设置。
考虑下面显示的示例。当所有三个接收器的组合消息数至少为 min_size,即 5 时,将执行关联的实体。
- name: input_1
type: nvidia::gxf::test::MockReceiver
parameters:
max_capacity: 10
- name: input_2
type: nvidia::gxf::test::MockReceiver
parameters:
max_capacity: 10
- name: input_3
type: nvidia::gxf::test::MockReceiver
parameters:
max_capacity: 10
- type: nvidia::gxf::MultiMessageAvailableSchedulingTerm
parameters:
receivers: [input_1, input_2, input_3]
min_size: 5
BooleanSchedulingTerm(布尔调度项)#
当 nvidia::gxf::BooleanSchedulingTerm 的内部状态设置为节拍时,将执行与它关联的实体。参数 enable_tick 用于控制实体执行。调度项还具有两个 API enable_tick() 和 disable_tick() 来切换其内部状态。实体执行可以通过调用这些 API 来控制。如果 enable_tick 设置为 false,则不执行实体(调度条件设置为 NEVER)。如果 enable_tick 设置为 true,则将执行实体(调度条件设置为 READY)。实体可以通过保持对其的句柄来切换调度项的状态。
示例用法 -
- type: nvidia::gxf::BooleanSchedulingTerm
parameters:
enable_tick: true
AsynchronousSchedulingTerm(异步调度项)#
AsynchronousSchedulingTerm 主要与处理在调度器执行的常规执行之外发生的异步事件的实体相关联。由于这些事件本质上是非周期性的,因此 AsynchronousSchedulingTerm 可防止调度器定期轮询实体的状态并减少 CPU 利用率。AsynchronousSchedulingTerm 可以根据它正在等待的异步事件处于 READY、WAIT、WAIT_EVENT 或 NEVER 状态。
异步事件的状态使用 nvidia::gxf::AsynchronousEventState 描述,并使用 setEventState API 进行更新。
AsynchronousEventState |
描述 |
|---|---|
READY |
Init 状态,第一个节拍挂起 |
WAIT |
异步服务请求尚未发送,无事可做,只能等待 |
EVENT_WAITING |
已向异步服务发送请求,等待事件完成通知 |
EVENT_DONE |
已收到事件完成通知,实体已准备好进行节拍 |
EVENT_NEVER |
实体不想再次被节拍,执行结束 |
与此调度项关联的实体很可能具有一个异步线程,该线程可以在 gxf 调度器执行的常规执行周期之外更新调度项的状态。当调度项处于 WAIT 状态时,调度器会定期轮询实体的状态。当调度项处于 EVENT_WAITING 状态时,调度器将不再检查实体的状态,直到它们收到可以使用 GxfEntityEventNotify api 触发的事件通知。将调度项的状态设置为 EVENT_DONE 会自动将此通知发送给调度器。实体可以使用 EVENT_NEVER 状态来指示其执行周期的结束。
示例用法 -
- name: async_scheduling_term
type: nvidia::gxf::AsynchronousSchedulingTerm
DownstreamReceptiveSchedulingTerm(下游接受调度项)#
此调度项指定如果给定发射器的接收器可以接受新消息,则应执行实体。
示例用法 -
- name: downstream_st
type: nvidia::gxf::DownstreamReceptiveSchedulingTerm
parameters:
transmitter: output
min_size: 1
TargetTimeSchedulingTerm(目标时间调度项)#
此调度项允许在用户指定的时间戳执行。时间戳在提供的时钟上指定。
示例用法 -
- name: target_st
type: nvidia::gxf::TargetTimeSchedulingTerm
parameters:
clock: clock/manual_clock
ExpiringMessageAvailableSchedulingTerm(过期消息可用调度项)#
此调度等待接收器中指定数量的消息。当队列中收到的第一条消息即将过期或队列中有足够的消息时,将执行实体。使用 receiver 参数设置要监视的接收器。参数 max_batch_size 和 max_delay_ns 分别指示要批量处理的最大消息数以及从第一条消息开始等待的最大延迟,然后再执行实体。
在下面显示的示例中,当队列中的消息数大于 max_batch_size(即 5)时,或者当从第一条消息到当前时间的延迟大于 max_delay_ns(即 10000000)时,将执行关联的实体。
- name: target_st
type: nvidia::gxf::ExpiringMessageAvailableSchedulingTerm
parameters:
receiver: signal
max_batch_size: 5
max_delay_ns: 10000000
clock: misc/clock
MessageAvailableFrequencyThrottler(消息可用频率限制器)#
一种调度项,允许实体保持特定的执行(最小)频率。调度项还将监视通过多个接收器传入的消息,并在任何消息可用时切换到 READY 状态。
- type: nvidia::gxf::MessageAvailableFrequencyThrottler
parameters:
receivers: [receiver_0, receiver_1]
execution_frequency: 100Hz
min_sum: 1
sampling_mode: SumOfAll
MemoryAvailableSchedulingTerm(内存可用调度项)#
一种调度项,等待直到池中给定数量的块可用。这可用于强制 codelet 等待,直到其最小数量的正在传输中的缓冲区从下游消费者返回。
- type: nvidia::gxf::MemoryAvailableSchedulingTerm
parameters:
allocator: allocator
min_bytes: 256
min_blocks: 1024
BTSchedulingTerm(BT 调度项)#
BT(行为树)调度项用于调度行为树实体本身及其在行为树中的子实体(如果有)。
示例用法 -
name: root
components:
- name: root_controller
type: nvidia::gxf::EntityCountFailureRepeatController
parameters:
max_repeat_count: 0
- name: root_st
type: nvidia::gxf::BTSchedulingTerm
parameters:
is_root: true
- name: root_codelet
type: nvidia::gxf::SequenceBehavior
parameters:
children: [ child1/child1_st ]
s_term: root_st
controller: root_controller
Combining SchedulingTerms(组合调度项)#
一个实体可以与多个定义其执行行为的调度项相关联。调度项是 AND 组合的,用于描述实体的当前状态。为了使实体被调度器执行,所有调度项都必须处于 READY 状态,相反,只要任何一个调度项达到 NEVER 状态,实体就会从执行中取消调度。AND 组合期间各种状态的优先级顺序为 NEVER、WAIT_EVENT、WAIT、WAIT_TIME 和 READY。
示例用法 -
components:
- name: integers
type: nvidia::gxf::DoubleBufferTransmitter
- name: fibonacci
type: nvidia::gxf::DoubleBufferTransmitter
- type: nvidia::gxf::CountSchedulingTerm
parameters:
count: 100
- type: nvidia::gxf::DownstreamReceptiveSchedulingTerm
parameters:
transmitter: integers
min_size: 1
Cuda 基于的调度项#
基于 cuda 处理的生产者 codelet 可以将作业排队到 cuda 流中,而无需等待作业完成。消费者可以在以下两个描述的调度项的帮助下等待数据的可用性。
Cuda Stream SchedulingTerm(Cuda 流调度项)#
CudaStreamSchedulingTerm 指定在提供的 cuda 流上完成工作后,在接收器处数据的可用性,并借助回调函数到主机。
此调度项将注册一个回调函数,一旦指定 cuda 流上的工作完成,将调用该函数,指示数据可供使用。
示例用法 -
components:
- type: nvidia::gxf::CudaStreamSchedulingTerm
parameters:
receiver: rx0
- type: nvidia::gxf::MessageAvailableSchedulingTerm
parameters:
receiver: rx1
min_size: 1
Cuda Event SchedulingTerm(Cuda 事件调度项)#
CudaEventSchedulingTerm 指定在提供的 cuda 流上完成工作后,在接收器处数据的可用性,并借助 cuda 事件。此调度项将不断轮询提供的事件,以检查数据是否可供使用。
示例用法 -
components:
- type: nvidia::gxf::CudaEventSchedulingTerm
parameters:
receiver: rx0
- type: nvidia::gxf::MessageAvailableSchedulingTerm
parameters:
receiver: rx1
min_size: 1
Connection Topologies(连接拓扑)#
GXF 支持在图实体之间创建多个连接拓扑。
1 : 1 连接
单个发射器和单个接收器之间的最简单连接。底层 codelet 具有 Handle<Transmitter> 和 Handle<Receiver> 作为注册参数。

1 : m 连接
单个发射器可以连接到单个接收器,反之亦然。底层 codelet 具有 Handle<Transmitter> 和 Handle<Receiver> 作为注册参数。

多个 1 : 1 连接
1 : m 连接可以通过创建多个 1 : 1 连接来替代实现。在这种情况下,接收器实体中的底层 codelet 必须具有 std::vector<Handle<Receiver>> 或 std::Array<Handle<Receiver>, N> 参数。这同样适用于 m : 1 连接。每个 1 : 1 连接都将具有自己的调度项来监视传入和传出消息队列。

Messages(消息)#
在 GXF 图中,很多时候 Codelets 可能必须彼此通信才能完成定义的管道。消息是 codelet 彼此通信的形式。发布时,消息将始终具有关联的 Timestamp 组件,名称为 “timestamp”。如果用户未添加它,则在发布实体时将自动添加它。
Timestamp 组件包含两个不同的时间值(有关更多信息,请参见 gxf/std/timestamp.hpp 头文件。)
1. acqtime - 这是获取消息实体的时间,例如,这通常是相机捕获图像时的驱动程序时间。如果您在 codelet 中发布消息,则必须提供此时间戳。
1. pubtime - 这是图中节点发布消息实体的时间。这将使用调度器的时钟自动更新。
Transmitter 用于发送消息,Receiver 用于接收消息。消息在 codelet 的 tick() 时发送或接收。
Transmitter(发射器)#
所有来自发送器的消息都作为一个实体发送。发送器封装消息后,将调用 publish(),这会将消息发送给目标接收者。
在一个代码小节 (codelet) 中,当使用 Transmitter (tx) 发布消息实体时,有两种方法可以添加必需的 Timestamp。
1. tx.publish(Entity message):您可以手动添加一个类型为 Timestamp 且名称为 “timestamp” 的组件,并设置 acqtime。在这种情况下,pubtime 应设置为 0。消息使用 publish(Entity message) 发布。此方法将在下一个版本中弃用。
2. tx.publish(Entity message, int64_t acqtime):您可以直接使用 acqtime 调用 publish(Entity message, int64_t acqtime)。Timestamp 将自动添加。
接收器#
所有来自发送器的消息都作为实体接收。接收器在收到 tick() 调用时,将调用 receive(),这有助于接收消息。
以下是发送器和接收器的示例
发送器示例#
gxf_result_t PingTx::tick() {
Expected<Entity> message = Entity::New(context());
if (!message) {
GXF_LOG_ERROR("Failure creating message entity.");
return message.error();
}
auto int_value = message.value().add<int32_t>("Integer");
auto value = int_value.value();
*value = 9999;
auto result = signal_->publish(message.value());
GXF_LOG_INFO("Message Sent: int_value = %d", *value);
return ToResultCode(message);
}
接收器示例#
gxf_result_t PingRx::tick() {
auto message = signal_->receive();
if (!message || message.value().is_null()) {
return GXF_CONTRACT_MESSAGE_NOT_AVAILABLE;
}
auto value = message.value();
auto rx_value = message->findAll<int32_t>();
GXF_LOG_INFO("Message Received: rx_value = %d", *(rx_value->at(0).value()));
return GXF_SUCCESS;
}
内存管理#
GXF 提供了一种分配和释放代码小节所需内存的方法。下面提到了各种类型的内存分配。
系统内存 分配指定字节的系统内存,这通常会利用底层操作系统调用来分配请求的内存。
主机内存 分配指定字节的主机内存,该内存已锁定页面并且设备可访问。使用 cudaMallocHost() 分配过多的内存可能会降低系统性能,因为它减少了系统可用于分页的内存量。此内存最好谨慎使用,以分配主机和设备之间数据交换的暂存区。
设备内存 分配指定字节的设备内存。
GXF 提供了一个名为 nvidia::gxf::BlockMemoryPool 的组件,该组件用于在可以指定为参数的多个/单个相同大小的块中分配内存。
以下示例说明如何分配主机内存
- name: host_memory_pool
type: nvidia::gxf::BlockMemoryPool
parameters:
storage_type: 0 # host memory
block_size: 1024
num_blocks: 5
以下示例说明如何分配设备内存
- name: cuda_device_memory_pool
type: nvidia::gxf::BlockMemoryPool
parameters:
storage_type: 1 # device memory
block_size: 1024
num_blocks: 5
以下示例说明如何分配系统内存
- name: system_memory_pool
type: nvidia::gxf::BlockMemoryPool
parameters:
storage_type: 2 # system memory
block_size: 1024
num_blocks: 5
以下示例说明如何在代码小节中使用分配器
- name: host_memory_pool
type: nvidia::gxf::BlockMemoryPool
parameters:
storage_type: 0 # host memory
block_size: 1024
num_blocks: 5
- name: cuda_device_memory_pool
type: nvidia::gxf::BlockMemoryPool
parameters:
storage_type: 1 # device memory
block_size: 1024
num_blocks: 5
- name: generator
type: nvidia::gxf::test::cuda::StreamTensorGenerator
parameters:
cuda_tensor_pool: cuda_device_memory_pool
host_tensor_pool: host_memory_pool
Cuda 流顺序分配器#
GXF 提供了一种使用原生 Cuda API 以流顺序方式分配和释放代码小节所需内存的方法。如下所述,仅支持设备内存分配类型。
设备内存:以流顺序方式分配设备内存。这种流顺序分配确保内存操作与同一流中的其他 GPU 操作正确同步。此分配方法利用 CUDA 的异步内存管理功能,特别是 cudaMallocAsync 和 cudaFreeAsync,分别用于分配和释放内存。
GXF 提供了一个名为 nvidia::gxf::StreamOrderedAllocator 的组件,该组件用于以流顺序方式分配/释放设备内存。此组件为 GXF 生态系统内的 GPU 操作实现了高效且流顺序的内存分配。
以下示例说明如何分配设备内存。此处支持的内存分配类型为设备内存。
- name: device_memory_pool
type: nvidia::gxf::StreamOrderedAllocator
parameters:
device_memory_initial_size: "32KB" # 32 KB initial pool size
device_max_memory_pool_size: "64MB" # 64 MB max pool size
RMM:RAPIDS 内存管理器#
GXF 提供了一种使用 RMM 分配和释放代码小节所需内存的方法。下面提到了各种类型的内存分配。
主机内存:分配指定字节的已锁定页面的主机内存,该内存已锁定页面并且设备可访问。它利用 RMM 的池分配策略来获得更好的性能
设备内存:以流顺序方式分配指定字节的设备内存。这种流顺序分配确保内存操作与同一流中的其他 GPU 操作正确同步。
GXF 提供了一个名为 nvidia::gxf::RMMAllocator 的组件,该组件用于使用 Rapids 内存管理器 (RMM) 分配/释放内存。此组件为 GXF 生态系统内的 GPU 操作实现了高效且流顺序的内存分配。
以下示例说明如何分配主机/设备内存。内存分配策略由传递给分配函数的参数值确定。根据此值,该函数决定是在主机上还是在设备上分配内存。
- name: memory_pool
type: nvidia::gxf::RMMAllocator
parameters:
device_memory_initial_size: "32B" # 32 bytes initial pool size
host_memory_initial_size: "32KB" # 32 KB initial pool size
device_max_memory_pool_size: "64MB" # 64 MB max pool size
host_memory_max_size: "64GB" # 64 GB max pool size
分布式执行#
段是在单个 GXF 运行时上下文中创建的图形实体组。一个段将有自己的调度程序。段中的图形实体通过双缓冲发送器和接收器组件相互连接。一个段通过 ucx 发送器和接收器连接到其他段。连接的段对可以在两个远程进程中或在同一进程中运行。
段的执行由图形工作器和图形驱动程序控制。图形工作器是一个 nvidia::gxf::System 组件,负责协调配置给此工作器的每个段的执行。图形工作器为每个段的运行提供和管理线程,并与图形驱动程序通信以确定每个段的生命周期。
图形工作器和驱动程序是 GXF 系统组件,它们在其生命周期内阻塞主线程,并生成自己的线程以供执行。它在某种程度上与 GXF 调度程序非常相似,因为每个调度程序从内部协调一个 GXF 运行时;而图形工作器从外部协调一个或多个 GXF 运行时。图形驱动程序协调一个或多个图形工作器来完成执行序列。
图形工作器和图形驱动程序都由 IPC 服务器和 IPC 客户端组成。IPC 服务器的服务分别在图形工作器和图形驱动程序中实现。这些 IPC 服务通过 IPC 服务器公开,远程进程上的相应 IPC 客户端可以调用这些服务。图形工作器的 IPC 客户端向图形驱动程序的服务发送远程请求;图形驱动程序的 IPC 客户端向图形工作器的服务发送远程请求。
GraphWorker#
图形工作器实现了一系列 IPC 服务,以处理运行图形段的不同步骤。通过 Http 或 Grpc 等 IPC 服务器调用这些 IPC 服务会触发这些步骤。每个 IPC 服务最终将非阻塞 IPC 调用转换为入队事件。
图形工作器的线程基于基于事件的队列线程和段运行程序表。

图:图形工作器执行序列
如序列图中所示,调用者主线程分 4 个步骤启动图形工作器。
注册一系列 IPC 服务并启动服务器;
启动基于事件的队列线程;
入队事件以实例化段运行程序表;
入队事件以请求与图形驱动程序通信。然后,调用者主线程被阻塞,等待图形工作器完成。
图形工作器与图形驱动程序的首次通信是注册所有段及其地址信息,例如 IP 和端口。当图形驱动程序发现所有段时,它拥有所有段及其地址的全局知识。由图形驱动程序解析所有段对之间的 UCX 连接,并对于每对段,通过图形工作器将 UCX 接收器地址传播到 UCX 发送器。
图形工作器实体示例
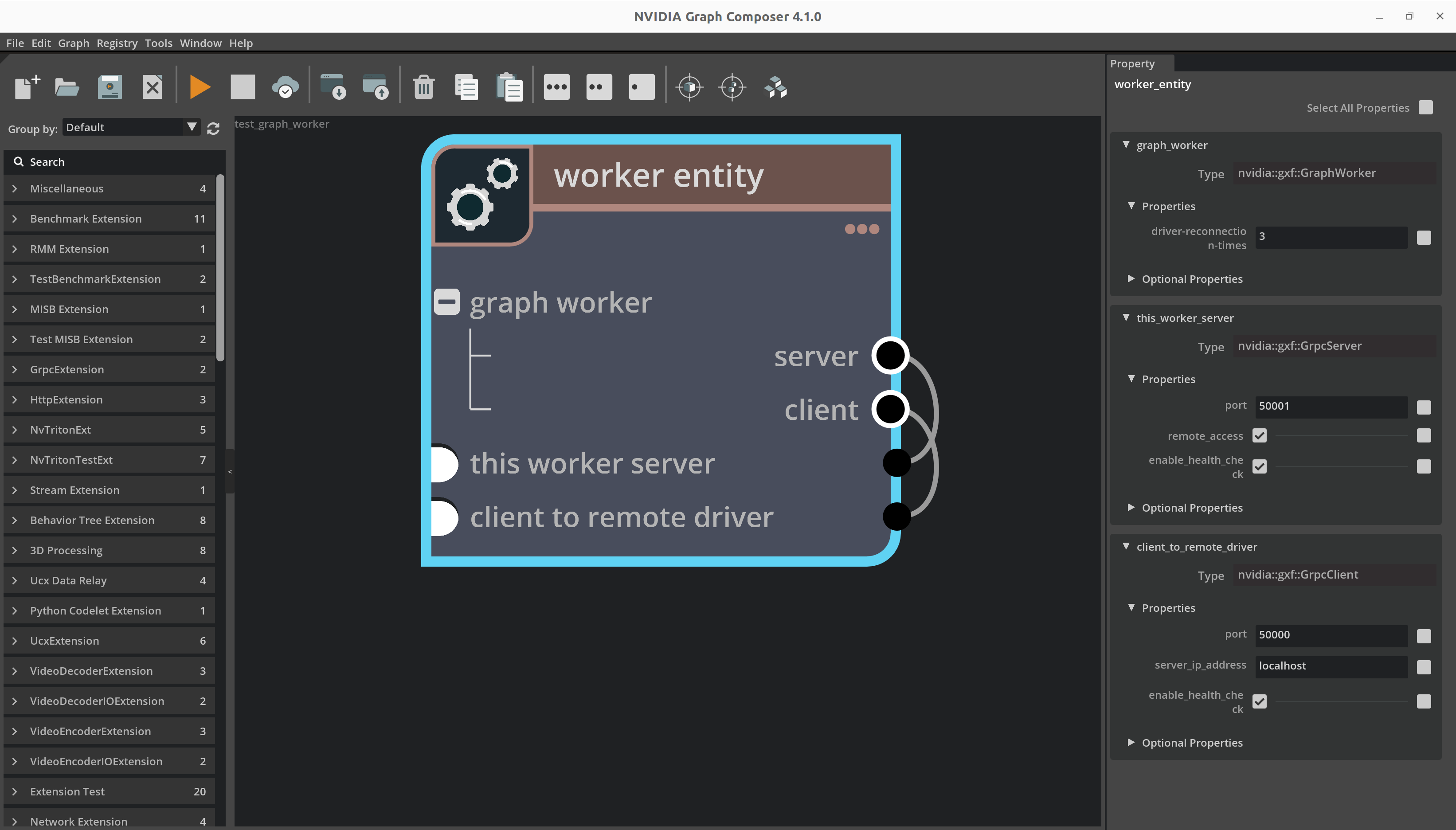
图:包含 GraphWorker 及其依赖项的实体
---
name: worker_entity
components:
- name: graph_worker
type: nvidia::gxf::GraphWorker
parameters:
server: this_worker_server
client: client_to_remote_driver
graph-specs:
ucx_upstream:
app-path: gxf/ucx/tests/test_ping_ucx_tx.yaml
manifest-path: gxf/test/distributed/test_graph_worker_manifest.yaml
severity: 4
ucx_downstream:
app-path: gxf/ucx/tests/test_ping_ucx_rx.yaml
manifest-path: gxf/test/distributed/test_graph_worker_manifest.yaml
severity: 4
- name: this_worker_server
type: nvidia::gxf::HttpServer
parameters:
port: 50001
remote_access: 'True'
- name: client_to_remote_driver
type: nvidia::gxf::HttpIPCClient
parameters:
server_ip_address: localhost
port: 50000
GraphDriver#
图形驱动程序实现了一系列 IPC 服务,以处理发现其图形工作器中的所有段的不同步骤;并解析段 UCX 连接地址。通过 Http 或 Grpc 等 IPC 服务器调用这些 IPC 服务会触发这些步骤。每个 IPC 服务最终将非阻塞 IPC 调用转换为入队事件。
图形驱动程序的线程基于基于事件的队列线程。

图:图形驱动程序执行序列
如序列图中所示,调用者主线程分 3 个步骤启动图形驱动程序。
读取全局段连接映射配置文件;
注册一系列 IPC 服务并启动服务器;
启动基于事件的队列线程。然后,调用者主线程被阻塞,等待图形驱动程序完成。
启动后,图形驱动程序侦听来自所有图形工作器的请求。在每个图形工作器启动时,它都会向图形驱动程序发送请求,以报告其段和地址信息。预计图形驱动程序在所有图形工作器之前启动。但是,如果图形工作器在图形驱动程序之前启动,它会保持在可配置的次数内重试该请求。
图形驱动程序实体示例
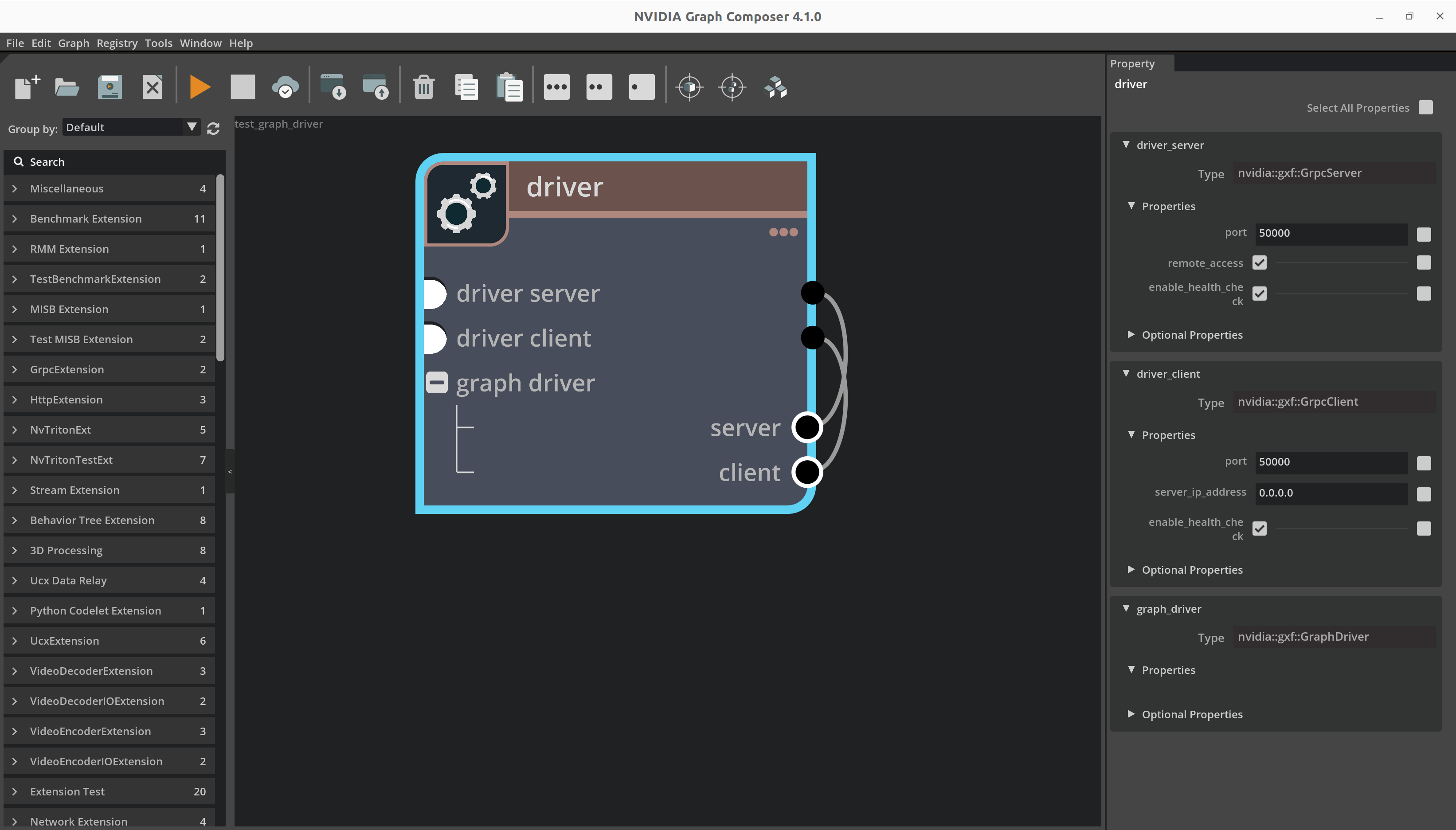
图:包含 GraphDriver 及其依赖项的实体
---
name: driver
components:
- name: driver_server
type: nvidia::gxf::HttpServer
parameters:
port: 50000
- name: driver_client
type: nvidia::gxf::HttpIPCClient
- name: graph_driver
type: nvidia::gxf::GraphDriver
parameters:
server: driver_server
client: driver_client
connections:
- source: ucx_upstream.tx.signal
target: ucx_downstream.rx.signal
日志记录#
在实现代码小节时,会自动包含 GXF 日志记录宏。用法类似于 printf(),但它们还会打印文件名和行号。请参阅示例扩展部分中的示例用法。
-
GXF_LOG_VERBOSE(...)#
示例
GXF_LOG_VERBOSE("This is a test message, codelet eid %ld, cid %ld, name %s", eid(), cid(), name());
-
GXF_LOG_DEBUG(...)#
示例
GXF_LOG_DEBUG("This is a test message, codelet eid %ld, cid %ld, name %s", eid(), cid(), name());
-
GXF_LOG_INFO(...)#
示例
GXF_LOG_INFO("This is a test message, codelet eid %ld, cid %ld, name %s", eid(), cid(), name());
-
GXF_LOG_WARNING(...)#
示例
GXF_LOG_WARNING("This is a test message, codelet eid %ld, cid %ld, name %s", eid(), cid(), name());
-
GXF_LOG_ERROR(...)#
示例
GXF_LOG_ERROR("This is a test message, codelet eid %ld, cid %ld, name %s", eid(), cid(), name());
日志级别
GXF 日志记录支持以下日志级别
-
GXF_LOG_LEVEL_PANIC#
定义为 0。
-
GXF_LOG_LEVEL_ERROR#
定义为 1。
-
GXF_LOG_LEVEL_WARNING#
定义为 2。
-
GXF_LOG_LEVEL_INFO#
定义为 3。
-
GXF_LOG_LEVEL_DEBUG#
定义为 4。
-
GXF_LOG_LEVEL_VERBOSE#
定义为 5。
在包含 common/logger.hpp 之前定义 GXF_LOG_ACTIVE_LEVEL 以在编译时控制日志级别。这允许您跳过某些级别的日志记录。
示例
#define GXF_LOG_ACTIVE_LEVEL 2
#include "common/logger.hpp"
使用此设置,日志记录将仅在 WARNING(2)、ERROR(1) 和 PANIC(0) 级别发生。
您可以在构建系统中定义 GXF_LOG_ACTIVE_LEVEL。例如,在 CMake 中,使用
target_compile_definitions(my_target PRIVATE GXF_LOG_ACTIVE_LEVEL=2)
这会将目标 my_target 的活动日志级别设置为 WARNING(2)。
或者,通过将 -DGXF_LOG_ACTIVE_LEVEL=2 直接传递给编译器,在编译时定义 GXF_LOG_ACTIVE_LEVEL。
在 Bazel 构建系统中,按如下所示在构建配置中设置此项
cc_binary(
name = "my_binary",
srcs = ["my_binary.cc"],
copts = ["-DGXF_LOG_ACTIVE_LEVEL=2"],
)
这会将目标 my_binary 的活动日志级别设置为 WARNING(2)。
或者,当使用 Bazel 构建命令时:bazel build --copt=-DGXF_LOG_ACTIVE_LEVEL=3 //path:to_your_target
这会将目标 //path:to_your_target 的活动日志级别设置为 INFO(3)。
GXF_LOG_ACTIVE_LEVEL 还可以用于启用特定于每个源文件的日志记录严重性。
示例
File A
#define GXF_LOG_ACTIVE_LEVEL 2
#include "common/logger.hpp"
Codelet B
#define GXF_LOG_ACTIVE_LEVEL 5
#include "common/logger.hpp"
文件 A 将具有警告及以上级别的日志,文件 B 将具有详细及以上级别的日志。
组件工厂#
扩展包含其自己的组件工厂,其中显式注册了所有组件。GXF 提供了辅助宏,可以轻松实现任何扩展所需的组件工厂。通常,扩展工厂实现组织为扩展目录中的独立 cpp 文件。它以 GXF_EXT_FACTORY_BEGIN() 开头,以 GXF_EXT_FACTORY_END() 结尾。
可以使用宏 GXF_EXT_FACTORY_ADD() 注册组件。对于每个组件,都需要指定基类。组件基类必须先注册,然后才能在组件注册中用作基类。如果组件没有基类,则使用宏 GXF_EXT_FACTORY_ADD_0()。
组件最多可以有一个基类。不支持多个基类。
必须为工厂和每个组件提供唯一的 128 位标识符。标识符在所有现有扩展中必须是唯一的。
示例
GXF_EXT_FACTORY_BEGIN()
GXF_EXT_FACTORY_SET_INFO(0xd8629d822909316d, 0xa9ee7410c8c1a7b6, "test",
"A Dummy Example", "", "1.0.0", "NVIDIA");
// ...
GXF_EXT_FACTORY_ADD(0xd39d70014cab3ecf, 0xb397c9d200cf9e8d, sample::test::HelloWorld,
nvidia::gxf::Codelet, "Dummy example source codelet.");
// ...
GXF_EXT_FACTORY_END()
提供了以下宏来帮助简化创建组件工厂的过程。术语组件工厂、扩展和扩展在这些宏中互换使用。
请注意,也可以手动创建扩展工厂,而无需使用这些宏。
创建组件工厂
-
GXF_EXT_FACTORY_BEGIN()#
开始定义 CreateComponentFactory() 函数,该函数以创建
nvidia::gxf::DefaultExtension对象开始。H1 和 H2 是 128 位标识符的第一部分和第二部分哈希值。
-
GXF_EXT_FACTORY_SET_INFO(H1, H2, NAME, DESC, AUTHOR, VERSION, LICENSE)#
为此扩展工厂设置信息。
示例
GXF_EXT_FACTORY_SET_INFO(0xd8629d822909316d, 0xa9ee7410c8c1a7b6, "test", "A Dummy Example", "", "1.0.0", "NVIDIA");
-
GXF_EXT_FACTORY_SET_DISPLAY_INFO(DISPLAY_NAME, CATEGORY, BRIEF)#
为此组件工厂设置其他显示信息。
示例
GXF_EXT_FACTORY_SET_DISPLAY_INFO("Dummy Extension", "Dummy", "GXF Dummy Extension");
-
GXF_EXT_FACTORY_END()#
关闭 CreateComponentFactory() 函数,然后调用 CreateComponentFactory() 以返回工厂对象。
注册组件
-
GXF_EXT_FACTORY_ADD(H1, H2, TYPE, BASE, DESC)#
向此组件工厂注册新组件。
示例
GXF_EXT_FACTORY_ADD(0xd39d70014cab3ecf, 0xb397c9d200cf9e8d, nvidia::gxf::DummyCodelet, nvidia::gxf::Codelet, "Description");
- GXF_EXT_FACTORY_ADD_VERBOSE(
- H1,
- H2,
- TYPE,
- BASE,
- DISPLAY_NAME,
- BRIEF,
- DESC,
使用详细元数据向此组件工厂注册新组件。
示例
GXF_EXT_FACTORY_ADD_VERBOSE(0xd39d70014cab3ecf, 0xb397c9d200cf9e8d, nvidia::gxf::DummyCodelet, nvidia::gxf::Codelet, "Display Name", "Brief", "Description");
-
GXF_EXT_FACTORY_ADD_LITE(H1, H2, TYPE, BASE)#
使用最少元数据向此组件工厂注册新组件。
示例
GXF_EXT_FACTORY_ADD_LITE(0xd39d70014cab3ecf, 0xb397c9d200cf9e8d, nvidia::gxf::DummyCodelet, nvidia::gxf::Codelet);
注册没有基类型的组件
-
GXF_EXT_FACTORY_ADD_0(H1, H2, TYPE, DESC)#
使用最少元数据向此组件工厂注册新组件。
示例
GXF_EXT_FACTORY_ADD_0(0xd39d70014cab3ecf, 0xb397c9d200cf9e8d, sample::test::Helper, "Description");
-
GXF_EXT_FACTORY_ADD_0_VERBOSE(H1, H2, TYPE, DISPLAY_NAME, BRIEF, DESC)#
使用详细元数据向此组件工厂注册新组件。
示例
GXF_EXT_FACTORY_ADD_0_VERBOSE(0xd39d70014cab3ecf, 0xb397c9d200cf9e8d, sample::test::Helper, "Description", "Brief", "Description");
-
GXF_EXT_FACTORY_ADD_0_LITE(H1, H2, TYPE)#
示例
GXF_EXT_FACTORY_ADD_0_LITE(0xd39d70014cab3ecf, 0xb397c9d200cf9e8d, sample::test::Helper);