DeepStream 参考应用程序 - deepstream-app#
应用程序架构#
下图显示了 NVIDIA® DeepStream 参考应用程序的架构。
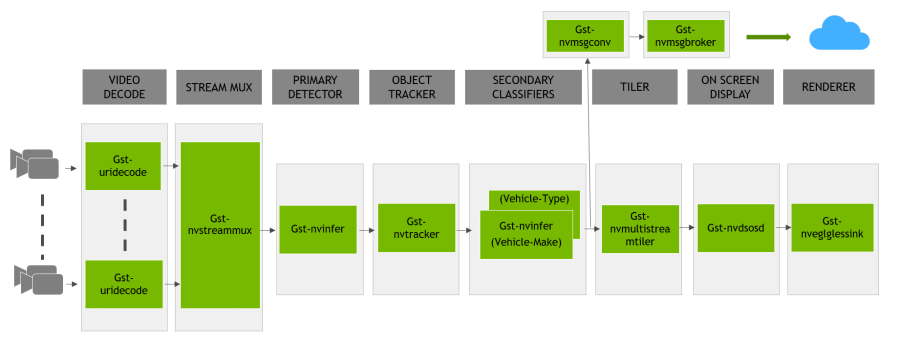
DeepStream 参考应用程序是基于 GStreamer 的解决方案,由一组封装低级 API 以形成完整图的 GStreamer 插件组成。参考应用程序能够接受来自各种来源的输入,如摄像头、RTSP 输入、编码文件输入,并额外支持多流/源功能。NVIDIA 实现并作为 DeepStream SDK 一部分提供的 GStreamer 插件列表包括
流复用器插件 (
Gst-nvstreammux),用于从多个输入源形成一批缓冲区。预处理插件 (
Gst-nvdspreprocess),用于对主要推理的预定义 ROI 进行预处理。基于 NVIDIA TensorRT™ 的插件 (
Gst-nvinfer),分别用于主要和次要(主要对象的属性分类)检测和分类。多对象跟踪器插件 (
Gst-nvtracker),用于使用唯一 ID 进行对象跟踪。多流平铺器插件 (
Gst-nvmultistreamtiler),用于形成帧的 2D 阵列。屏幕显示 (OSD) 插件 (
Gst-nvdsosd),使用生成的元数据在合成帧上绘制阴影框、矩形和文本。消息转换器 (
Gst-nvmsgconv) 和消息代理 (Gst-nvmsgbroker) 插件组合,用于将分析数据发送到云中的服务器。
参考应用程序配置#
NVIDIA DeepStream SDK 参考应用程序使用 DeepStream 包中 samples/configs/deepstream-app 目录中的一个示例配置文件来
启用或禁用组件
更改组件的属性或行为
自定义与其他应用程序配置设置,这些设置与管道及其组件无关
配置文件使用基于 freedesktop 规范的密钥文件格式,网址为:https://specifications.freedesktop.org/desktop-entry-spec/latest
DeepStream 参考应用程序(deepstream-app)的预期输出#
下图显示了禁用预处理插件的预期输出

下图显示了启用预处理插件的预期输出(绿色边界框是预定义的 ROI)

配置组#
应用程序配置分为每个组件和特定于应用程序的组件的配置组。配置组为
配置组 - deepstream app# 组
配置组
与特定组件无关的应用程序配置。
应用程序中的平铺显示。
源属性。可以有多个源。组必须命名为:[source0]、[source1] …
源 URI 以列表形式提供。可以有多个源。组必须命名为:[source-list] 和 [source-attr-all]
指定 streammux 组件的属性并修改其行为。
指定预处理组件的属性并修改其行为。
指定主要 GIE 的属性并修改其行为。指定次要 GIE 的属性并修改其行为。组必须命名为:[secondary-gie0]、[secondary-gie1] …
指定对象跟踪器的属性并修改其行为。
指定消息转换器组件的属性并修改其行为。
指定消息消费者组件的属性并修改其行为。管道可以包含多个消息消费者组件。组必须命名为 [message-consumer0]、[message-consumer1] …
指定屏幕显示 (OSD) 组件的属性,该组件在帧上覆盖文本和矩形。
指定 sink 组件的属性并修改其行为,这些组件表示用于渲染、编码和文件保存的输出,如显示器和文件。管道可以包含多个 sink。组必须命名为:[sink0]、[sink1] …
诊断和调试。此组是实验性的。
指定 nvdsanalytics 插件配置文件,并将插件添加到应用程序中
应用程序组#
应用程序组属性为
应用程序组# 键
含义
类型和值
示例
平台
enable-perf-measurement
指示是否启用应用程序性能测量。
布尔值
enable-perf-measurement=1
dGPU,Jetson
perf-measurement-interval-sec
采样和打印性能指标的间隔(秒)。
整数,>0
perf-measurement-interval-sec=10
dGPU,Jetson
gie-kitti-output-dir
应用程序在其中以修改后的 KITTI 元数据格式存储主要检测器输出的现有目录的路径名。
字符串
gie-kitti-output-dir=/home/ubuntu/kitti_data/
dGPU,Jetson
kitti-track-output-dir
应用程序在其中以修改后的 KITTI 元数据格式存储跟踪器输出的现有目录的路径名。
字符串
kitti-track-output-dir=/home/ubuntu/kitti_data_tracker/
dGPU,Jetson
reid-track-output-dir
应用程序在其中存储跟踪器的 Re-ID 特征输出的现有目录的路径名。每行的第一个整数是对象 ID,其余浮点数是其特征向量。
字符串
reid-track-output-dir=/home/ubuntu/reid_data_tracker/
dGPU,Jetson
terminated-track-output-dir
应用程序在其中以修改后的 KITTI 元数据格式存储终止的跟踪器输出的现有目录的路径名。
字符串
kitti-track-output-dir=/home/ubuntu/terminated_data_tracker/
dGPU,Jetson
shadow-track-output-dir
应用程序在其中以修改后的 KITTI 元数据格式存储阴影跟踪状态输出的现有目录的路径名。
字符串
shadow-track-output-dir=/home/ubuntu/shadow_data_tracker/
dGPU,Jetson
global-gpu-id
如果需要,一次性为所有组件设置全局 GPU ID
整数
global-gpu-id=1
dGPU,Jetson
平铺显示组#
平铺显示组属性为
平铺显示组# 键
含义
类型和值
示例
平台
启用
指示是否启用平铺显示。当用户设置 enable=2 时,键为:link-to-demux=1 的第一个 [sink] 组应链接到 demuxer 的 src_[source_id] pad,其中 source_id 是在相应的 [sink] 组中设置的键。
整数,0 = 禁用,1 = 启用平铺器 2 = 启用平铺器和并行解复用器到 sink
enable=1
dGPU,Jetson
行
平铺 2D 阵列中的行数。
整数,>0
rows=5
dGPU,Jetson
列
平铺 2D 阵列中的列数。
整数,>0
columns=6
dGPU,Jetson
宽度
平铺 2D 阵列的宽度,以像素为单位。
整数,>0
width=1280
dGPU,Jetson
高度
平铺 2D 阵列的高度,以像素为单位。
整数,>0
height=720
dGPU,Jetson
gpu-id
在多个 GPU 的情况下,元素要使用的 GPU。
整数,≥0
gpu-id=0
dGPU
nvbuf-memory-type
元素要为输出缓冲区分配的内存类型。
0 (nvbuf-mem-default):平台特定的默认类型
1 (nvbuf-mem-cuda-pinned):pinned/host CUDA 内存
2 (nvbuf-mem-cuda-device):device CUDA 内存
3 (nvbuf-mem-cuda-unified):unified CUDA 内存
对于 dGPU:所有值均有效。
对于 Jetson:仅 0(零)有效。
整数,0、1、2 或 3
nvbuf-memory-type=3
dGPU,Jetson
compute-hw
要使用的计算缩放硬件。仅适用于 Jetson。dGPU 系统默认使用 GPU。
0 (默认):默认,Tesla 使用 GPU,Jetson 使用 VIC
1 (GPU):GPU
2 (VIC):VIC
整数:0-2
compute-hw=1
Jetson
square-seq-grid
根据源的数量启用自动方形平铺。图块按顺序放置在网格上,末尾有空图块
布尔值
square-seq-grid=1
dGPU,Jetson
源组#
源组指定源属性。DeepStream 应用程序支持多个并发源。对于每个源,必须将单独的组(组名称如 source%d)添加到配置文件中。例如
[source0]
key1=value1
key2=value2
...
[source1]
key1=value1
key2=value2
...
源组属性为
源组# 键
含义
类型和值
示例
平台
启用
启用或禁用源。
布尔值
enable=1
dGPU,Jetson
类型
源的类型;源的其他属性取决于此类型。
1:摄像头 (V4L2)
2:URI
3:MultiURI
4:RTSP
5:摄像头 (CSI)(仅限 Jetson)
整数,1、2、3、4 或 5
type=1
dGPU,Jetson
uri
编码流的 URI。URI 可以是文件、HTTP URI 或 RTSP 直播源。当 type=2 或 3 时有效。使用 MultiURI,还可以使用 %d 格式说明符来指定多个源。应用程序从 0 迭代到 num-sources−1 以生成实际的 URI。
字符串
uri=file:///home/ubuntu/source.mp4 uri=http://127.0.0.1/source.mp4 uri=rtsp://127.0.0.1/source1 uri=file:///home/ubuntu/source_%d.mp4
dGPU,Jetson
num-sources
源的数量。仅当 type=3 时有效。
整数,≥0
num-sources=2
dGPU,Jetson
intra-decode-enable
启用或禁用仅帧内解码。
布尔值
intra-decode-enable=1
dGPU,Jetson
num-extra-surfaces
解码器提供的最小解码表面之外的其他表面数量。可用于管理管道中解码器输出缓冲区的数量。
整数,≥0 且 ≤24
num-extra-surfaces=5
dGPU,Jetson
gpu-id
在多个 GPU 的情况下,元素要使用的 GPU。
整数,≥0
gpu-id=1
dGPU
camera-id
要添加到元数据的输入源的唯一 ID。(可选)
整数,≥0
camera-id=2
dGPU,Jetson
camera-width
要从摄像头请求的帧宽度,以像素为单位。当 type=1 或 5 时有效。
整数,>0
camera-width=1920
dGPU,Jetson
camera-height
要从摄像头请求的帧高度,以像素为单位。当 type=1 或 5 时有效。
整数,>0
camera-height=1080
dGPU,Jetson
camera-fps-n
指定摄像头请求的帧速率的分数的分子部分,以帧/秒为单位。当 type=1 或 5 时有效。
整数,>0
camera-fps-n=30
dGPU,Jetson
camera-fps-d
指定摄像头请求的帧速率的分数的分母部分,以帧/秒为单位。当 type=1 或 5 时有效。
整数,>0
camera-fps-d=1
dGPU,Jetson
camera-v4l2-dev-node
V4L2 设备节点的编号。例如,开源 V4L2 摄像头捕获路径的 /dev/video<num>。当类型设置(源类型)为 1 时有效。
整数,>0
camera-v4l2-dev-node=1
dGPU,Jetson
latency
抖动缓冲区大小(以毫秒为单位);仅适用于 RTSP 流。
整数,≥0
latency=200
dGPU,Jetson
camera-csi-sensor-id
摄像头模块的传感器 ID。当类型(源类型)为 5 时有效。
整数,≥0
camera-csi-sensor-id=1
Jetson
drop-frame-interval
丢帧间隔。例如,5 表示解码器每输出第五帧;0 表示不丢帧。
整数,
drop-frame-interval=5
dGPU,Jetson
cudadec-memtype
用于为类型 2、3 或 4 的源分配输出缓冲区的 CUDA 内存元素的类型。不适用于 CSI 或 USB 摄像头源
0 (memtype_device):使用 cudaMalloc() 分配的设备内存。
1 (memtype_pinned):使用 cudaMallocHost() 分配的 host/pinned 内存。
2 (memtype_unified):使用 cudaMallocManaged() 分配的 Unified 内存。
整数,0、1 或 2
cudadec-memtype=1
dGPU
nvbuf-memory-type
元素要为 nvvideoconvert 的输出缓冲区分配的 CUDA 内存类型,对于类型 1 的源很有用。
0 (nvbuf-mem-default,平台特定的默认值
1 (nvbuf-mem-cuda-pinned):pinned/host CUDA 内存。
2 (nvbuf-mem-cuda-device):Device CUDA 内存。
3 (nvbuf-mem-cuda-unified):Unified CUDA 内存。
对于 dGPU:所有值均有效。
对于 Jetson:仅 0(零)有效。
整数,0、1、2 或 3
nvbuf-memory-type=3
dGPU,Jetson
select-rtp-protocol
- 用于 RTP 的传输协议。当类型(源类型)为 4 时有效。
整数,0 或 4
select-rtp-protocol=4
dGPU,Jetson
rtsp-reconnect-interval-sec
自上次从 RTSP 源接收到数据以来等待超时时间(秒),然后强制重新连接。将其设置为 0 将禁用重新连接。当类型(源类型)为 4 时有效。
整数,≥0
rtsp-reconnect-interval-sec=60
dGPU,Jetson
rtsp-reconnect-attempts
尝试重新连接的最大次数。将其设置为 -1 表示将无限次尝试重新连接。当源类型为 4 且 rtsp-reconnect-interval-sec 为非零正值时有效。
整数,≥-1
rtsp-reconnect-attempts=2
smart-record
触发智能录制的方式。
0:禁用
1:仅通过云消息
2:云消息 + 本地事件
整数,0、1 或 2
smart-record=1
dGPU,Jetson
smart-rec-dir-path
保存录制文件的目录路径。默认情况下,使用当前目录。
字符串
smart-rec-dir-path=/home/nvidia/
dGPU,Jetson
smart-rec-file-prefix
录制视频的文件名前缀。默认情况下,Smart_Record 是前缀。对于唯一的文件名,必须为每个源提供唯一的前缀。
字符串
smart-rec-file-prefix=Cam1
dGPU,Jetson
smart-rec-cache
智能录制缓存的大小(以秒为单位)。
整数,≥0
smart-rec-cache=20
dGPU,Jetson
smart-rec-container
录制视频的容器格式。支持 MP4 和 MKV 容器。
整数,0 或 1
smart-rec-container=0
dGPU,Jetson
smart-rec-start-time
从现在开始提前多少秒开始录制。例如,如果 t0 是当前时间,而 N 是开始时间(秒),则表示录制将从 t0 – N 开始。显然,为了使其工作,视频缓存大小必须大于 N。
整数,≥0
smart-rec-start-time=5
dGPU,Jetson
smart-rec-default-duration
如果未生成停止事件。此参数将确保在预定义的默认持续时间后停止录制。
整数,≥0
smart-rec-default-duration=20
dGPU,Jetson
smart-rec-duration
录制时长(秒)。
整数,≥0
smart-rec-duration=15
dGPU,Jetson
smart-rec-interval
这是 SR 启动/停止事件生成的时间间隔(秒)。
整数,≥0
smart-rec-interval=10
dGPU,Jetson
udp-buffer-size
RTSP 源的 UDP 缓冲区大小(以字节为单位)。
整数,≥0
udp-buffer-size=2000000
dGPU,Jetson
video-format
源的输出视频格式。此值设置为源的 nvvideoconvert 元素的输出格式。
字符串:NV12、I420、P010_10LE、BGRx、RGBA
video-format=RGBA
dGPU,Jetson
Source-list 和 source-attr-all 组#
source-list 组允许用户提供要开始流式传输的初始源 URI 列表。此组与 [source-attr-all] 一起可以替代每个流的单独 [source] 组的需求。
此外,DeepStream 支持(Alpha 功能)通过 REST API 动态传感器配置。有关此功能的更多详细信息,请参阅示例配置文件和 deepstream 参考应用程序运行命令 此处。
例如
[source-list]
num-source-bins=2
list=file:///opt/nvidia/deepstream/deepstream/samples/streams/sample_1080p_h264.mp4;file:///opt/nvidia/deepstream/deepstream/samples/streams/sample_1080p_h265.mp4
sgie-batch-size=8
...
[source-attr-all]
enable=1
type=3
num-sources=1
gpu-id=0
cudadec-memtype=0
latency=100
rtsp-reconnect-interval-sec=0
...
注意:[source-list] 现在支持带有 use-nvmultiurisrcbin=1 的 REST 服务器
例如
[source-list]
num-source-bins=2
list=file:///opt/nvidia/deepstream/deepstream/samples/streams/sample_1080p_h264.mp4;file:///opt/nvidia/deepstream/deepstream/samples/streams/sample_1080p_h265.mp4
use-nvmultiurisrcbin=1
#sensor-id-list vector is one to one mapped with the uri-list
#identifies each sensor by a unique ID
sensor-id-list=UniqueSensorId1;UniqueSensorId2
#Optional sensor-name-list vector is one to one mapped with the uri-list
sensor-name-list=UniqueSensorName1;UniqueSensorName2
max-batch-size=10
http-ip=localhost
http-port=9000
#sgie batch size is number of sources * fair fraction of number of objects detected per frame per source
#the fair fraction of number of object detected is assumed to be 4
sgie-batch-size=40
[source-attr-all]
enable=1
type=3
num-sources=1
gpu-id=0
cudadec-memtype=0
latency=100
rtsp-reconnect-interval-sec=0
[source-list] 组属性为
源列表组# 键
含义
类型和值
示例
平台
启用
启用或禁用源。
布尔值
enable=1
dGPU,Jetson
num-source-bins
使用键列表提供的源 URI 总数
整数
num-source-bins=2
dGPU,Jetson
sgie-batch-size
sgie 批处理大小是源的数量 * 每个源每帧检测到的对象数量的公平分数,检测到的对象数量的公平分数假定为 4
整数
sgie-batch-size=8
dGPU,Jetson
list
由分号“;”分隔的 URI 列表
字符串
list=rtsp://ip-address:port/stream1;rtsp://ip-address:port/stream2
dGPU,Jetson
sensor-id-list
(Alpha 功能)仅当 use-nvmultiurisrcbin=1 时适用。唯一标识每个流的标识符列表,以分号“;”分隔
字符串
sensor-id-list=UniqueSensorId1;UniqueSensorId2
dGPU
sensor-name-list
(Alpha 功能)仅当 use-nvmultiurisrcbin=1 时适用。可选的传感器名称列表,用于标识每个流,以分号“;”分隔
字符串
sensor-name-list=SensorName1;SensorName2
dGPU
use-nvmultiurisrcbin
(Alpha 功能)布尔值,如果设置,则启用将 nvmultiurisrcbin 与 REST API 支持一起用于动态传感器配置
布尔值
use-nvmultiurisrcbin=0(默认)
dGPU
max-batch-size
(Alpha 功能)仅当 use-nvmultiurisrcbin=1 时适用。设置可以使用此 DeepStream 实例流式传输的最大传感器数量
整数
max-batch-size=10
dGPU
http-ip
(Alpha 功能)仅当 use-nvmultiurisrcbin=1 时适用。要使用的 HTTP 端点 IP 地址
字符串
http-ip=localhost (默认)
dGPU
http-port
(Alpha 功能)仅当 use-nvmultiurisrcbin=1 时适用。要使用的 HTTP 端点端口号。注意:用户可以传递空字符串以禁用 REST API 服务器
字符串
http-ip=9001 (默认)
dGPU
[source-attr-all] 组支持 源组 中的除 uri 之外的所有属性。示例配置文件可以在 /opt/nvidia/deepstream/deepstream/sources/apps/sample_apps/deepstream-test5/configs/test5_config_file_nvmultiurisrcbin_src_list_attr_all.txt 中找到。
Streammux 组#
[streammux] 组指定并修改 Gst-nvstreammux 插件的属性。
Streammux 组# 键
含义
类型和值
示例
平台
gpu-id
在多个 GPU 的情况下,GPU 元素要使用。
整数,≥0
gpu-id=1
dGPU
live-source
告知复用器源是实时的。
布尔值
live-source=0
dGPU,Jetson
buffer-pool-size
复用器输出缓冲区池中的缓冲区数量。
整数,>0
buffer-pool-size=4
dGPU,Jetson
batch-size
复用器批处理大小。
整数,>0
batch-size=4
dGPU,Jetson
batched-push-timeout
在第一个缓冲区可用后,推送批处理的超时时间(以微秒为单位),即使未形成完整的批处理。
整数,≥−1
batched-push-timeout=40000
dGPU,Jetson
宽度
复用器输出宽度(以像素为单位)。
整数,>0
width=1280
dGPU,Jetson
高度
复用器输出高度(以像素为单位)。
整数,>0
height=720
dGPU,Jetson
enable-padding
指示在通过添加黑条进行缩放时是否保持源纵横比。
布尔值
enable-padding=0
dGPU,Jetson
nvbuf-memory-type
元素要为输出缓冲区分配的 CUDA 内存类型。
0 (nvbuf-mem-default,平台特定的默认值
1 (nvbuf-mem-cuda-pinned):pinned/host CUDA 内存。
2 (nvbuf-mem-cuda-device):Device CUDA 内存。
3 (nvbuf-mem-cuda-unified):Unified CUDA 内存。
对于 dGPU:所有值均有效。
对于 Jetson:仅 0(零)有效。
整数,0、1、2 或 3
nvbuf-memory-type=3
dGPU
attach-sys-ts-as-ntp
对于实时源,复用缓冲区应具有关联的 NvDsFrameMeta->ntp_timestamp,设置为系统时间或流式传输 RTSP 时的服务器 NTP 时间。
如果设置为 1,则系统时间戳将作为 ntp 时间戳附加。
如果设置为 0,则将附加来自 rtspsrc 的 ntp 时间戳(如果可用)。
布尔值
attach-sys-ts-as-ntp=0
dGPU,Jetson
config-file-path
此键仅对新的 streammux 有效。有关更多信息,请参阅插件手册部分“New Gst-nvstreammux”。mux 配置文件的绝对路径或相对路径(相对于 DS 配置文件位置)。
字符串
config-file-path=config_mux_source30.txt
dGPU,Jetson
sync-inputs
在批处理输入帧之前进行时间同步。
布尔值
sync-inputs=0 (默认)
dGPU,Jetson
max-latency
实时模式下的额外延迟,以允许上游花费更长时间来为当前位置生成缓冲区(以纳秒为单位)。
整数,≥0
max-latency=0 (默认)
dGPU,Jetson
drop-pipeline-eos
布尔属性,用于控制当所有 sink pad 都处于 EOS 时,从 nvstreammux 向下游传播 EOS。(实验性)
布尔值
drop-pipeline-eos=0(默认)
dGPU/Jetson
预处理组#
[pre-process] 组用于在管道中添加 nvdspreprocess 插件。仅支持主要 GIE 的预处理。
键 |
含义 |
类型和值 |
示例 |
平台 |
|---|---|---|---|---|
启用 |
启用或禁用插件。 |
布尔值 |
enable=1 |
dGPU,Jetson |
config-file |
nvdspreprocess 插件的配置文件路径 |
字符串 |
config-file=config_preprocess.txt |
dGPU,Jetson |
主要 GIE 和次要 GIE 组#
DeepStream 应用程序支持多个次要 GIE。对于每个次要 GIE,必须将单独的组(名称为 secondary-gie%d)添加到配置文件中。例如
[primary-gie]
key1=value1
key2=value2
...
[secondary-gie1]
key1=value1
key2=value2
...
主要和次要 GIE 配置如下。对于每个配置,“Valid for”列指示配置属性对于主要或次要 TensorRT 模型还是对于两个模型都有效。
主要和次要 GIE* 组# 键
含义
类型和值
示例
平台/ GIE*
启用
指示是否必须启用主要 GIE。
布尔值
enable=1
dGPU, Jetson 两个 GIE
gie-unique-id
要分配给 nvinfer 实例的唯一组件 ID。用于标识实例生成的元数据。
整数,>0
gie-unique-id=2
两者
gpu-id
在多个 GPU 的情况下,元素要使用的 GPU。
整数,≥0
gpu-id=1
dGPU,两个 GIE
model-engine-file
模式的预生成序列化引擎文件的绝对路径名。
字符串
model-engine-file=../../models/Primary_Detector/resnet18_trafficcamnet_pruned.onnx_b4_gpu0_int8.engine
两个 GIE
nvbuf-memory-type
要为输出缓冲区分配的 CUDA 内存元素的类型。
0 (nvbuf-mem-default):平台特定的默认值
1 (nvbuf-mem-cuda-pinned):pinned/host CUDA 内存
2 (nvbuf-mem-cuda-device):Device CUDA 内存
3 (nvbuf-mem-cuda-unified):Unified CUDA 内存
对于 dGPU:所有值均有效。
对于 Jetson:仅 0(零)有效。
整数,0、1、2 或 3
nvbuf-memory-type=3
dGPU,Jetson 主要 GIE
config-file
指定 Gst-nvinfer 插件属性的配置文件的路径名。它可以包含此表中描述的任何属性,config-file 本身除外。属性必须在名为 [property] 的组中定义。有关参数的更多详细信息,请参阅 DeepStream 4.0 插件手册中的“Gst-nvinfer 文件配置规范”。
字符串
config-file=¬/home/-ubuntu/-config_infer_resnet.txt 有关完整示例,请参阅示例文件 samples/¬configs/-deepstream-app/-config_infer_resnet.txt 或 deepstream-test2 示例应用程序。
dGPU, Jetson 两个 GIE
batch-size
要在批处理中一起推理的帧数(P.GIE)/对象数(S.GIE)。
整数,>0 整数,>0
batch-size=2
dGPU, Jetson 两个 GIE
interval
要跳过推理的连续批处理数。
整数,>0 整数,>0
interval=2
dGPU,Jetson 主要 GIE
bbox-border-color
特定类 ID 的对象的边框颜色,以 RGBA 格式指定。键的格式必须为 bbox-border-color<class-id>。可以为多个类 ID 多次标识此属性。如果未为类 ID 标识此属性,则不会为该类 ID 的对象绘制边框。
R:G:B:A 浮点数,0≤R,G,B,A≤1
bbox-border-color2= 1;0;0;1(类 ID 2 的红色)
dGPU, Jetson 两个 GIE
bbox-bg-color
绘制在特定类 ID 对象上方的框的颜色,以 RGBA 格式表示。键的格式必须为 bbox-bg-color<class-id>。可以为多个类 ID 多次使用此属性。如果未将其用于类 ID,则不会为该类 ID 的对象绘制框。
R:G:B:A 浮点数,0≤R,G,B,A≤1
bbox-bg-color3=-0;1;0;0.3(类 ID 3 的半透明绿色)
dGPU, Jetson 两个 GIE
operate-on-gie-id
GIE 的唯一 ID,此 GIE 将在其元数据 (NvDsFrameMeta) 上运行。
整数,>0
operate-on-gie-id=1
dGPU,Jetson 次要 GIE
operate-on-class-ids
父 GIE 的类 ID,此 GIE 必须在其上运行。父 GIE 使用 operate-on-gie-id 指定。
分号分隔的整数数组
operate-on-class-ids=1;2(对父 GIE 生成的类 ID 为 1、2 的对象进行操作)
dGPU,Jetson 次要 GIE
infer-raw-output-dir
要在其中转储原始推理缓冲区内容的文件的现有目录的路径名。
字符串
infer-raw-output-dir=/home/ubuntu/infer_raw_out
dGPU, Jetson 两个 GIE
labelfile-path
labelfile 的路径名。
字符串
labelfile-path=../../models/Primary_Detector/labels.txt
dGPU, Jetson 两个 GIE
plugin-type
用于推理的插件。0:nvinfer (TensorRT) 1:nvinferserver (Triton 推理服务器)
整数,0 或 1
plugin-type=1
dGPU, Jetson 两个 GIE
input-tensor-meta
使用 nvdspreprocess 插件作为元数据附加的预处理输入张量,而不是在 nvinfer 内部进行预处理。
整数,0 或 1
input-tensor-meta=1
dGPU,Jetson,主要 GIE
注意
* GIE 是 GPU 推理引擎。
跟踪器组#
跟踪器组属性包括以下内容,更多详细信息可以在 Gst 属性 中找到
跟踪器组# 键
含义
类型和值
示例
平台
启用
启用或禁用跟踪器。
布尔值
enable=1
dGPU,Jetson
tracker-width
跟踪器将运行的帧宽度,以像素为单位。(当跟踪器配置 visualTrackerType: 1 或 reidType 为非零且 useVPICropScaler: 0 时,必须是 32 的倍数)
整数,≥0
tracker-width=960
dGPU,Jetson
tracker-height
跟踪器将运行的帧高度,以像素为单位。(当跟踪器配置 visualTrackerType: 1 或 reidType 为非零且 useVPICropScaler: 0 时,必须是 32 的倍数)
整数,≥0
tracker-height=544
dGPU,Jetson
gpu-id
在多个 GPU 的情况下,元素要使用的 GPU。
整数,≥0
gpu-id=1
dGPU
ll-config-file
低级库的配置文件(如果需要)。
(Alpha 功能)当配置属性 sub-batches 时,可以指定配置文件列表。
字符串
ll-config-file=iou_config.txt
dGPU,Jetson
ll-lib-file
低级跟踪器实现库的路径名。
字符串
ll-lib-file=/usr/-local/deepstream/libnvds_mot_iou.so
dGPU,Jetson
tracking-surface-type
设置跟踪的表面流类型。(默认值为 0)
整数,≥0
tracking-surface-type=0
dGPU,Jetson
display-tracking-id
启用跟踪 ID 显示。
布尔值
display-tracking-id=1
dGPU,Jetson
tracking-id-reset-mode
允许基于管道事件强制重置跟踪 ID。一旦启用跟踪 ID 重置并且发生此类事件,跟踪 ID 的低 32 位将被重置为 0
0:当流重置或 EOS 事件发生时不重置跟踪 ID
1:当流重置发生时(即 GST_NVEVENT_STREAM_RESET),终止所有现有跟踪器并为流分配新的 ID
2:在接收到 EOS 事件后(即 GST_NVEVENT_STREAM_EOS)让跟踪 ID 从 0 开始(注意:只有跟踪 ID 的低 32 位从 0 开始)
3:同时启用选项 1 和 2
整数,0 到 3
tracking-id-reset-mode=0
dGPU,Jetson
input-tensor-meta
如果 tensor-meta-gie-id 可用,则使用来自 Gst-nvdspreprocess 的 tensor-meta
布尔值
input-tensor-meta=1
dGPU,Jetson
tensor-meta-gie-id
要使用的 Tensor Meta GIE ID,仅当 input-tensor-meta 为 TRUE 时属性才有效
无符号整数,≥0
tensor-meta-gie-id=5
dGPU,Jetson
子批次 (Alpha 功能)
配置将帧批次拆分为子批次
分号分隔的整数数组。
必须包含从 0 到 (batch-size -1) 的所有值,其中 batch-size 在
[streammux]中配置。sub-batches=0,1;2,3
在此示例中,批次大小为 4 被拆分为两个子批次,其中第一个子批次包含源 ID 0 和 1,第二个子批次包含源 ID 2 和 3
dGPU,Jetson
sub-batch-err-recovery-trial-cnt (Alpha 功能)
配置当子批次中的底层跟踪器返回致命错误时,插件可以尝试恢复的次数。
为了从错误中恢复,插件会重新初始化底层跟踪器库。
整数,≥-1,其中,
-1 对应于无限次尝试
sub-batch-err-recovery-trial-cnt=3
dGPU,Jetson
user-meta-pool-size
跟踪器杂项数据缓冲区池的大小
无符号整数,>0
user-meta-pool-size=32
dGPU,Jetson
消息转换器组#
消息转换器组属性如下:
消息转换器组# 键
含义
类型和值
示例
平台
启用
启用或禁用消息转换器。
布尔值
enable=1
dGPU,Jetson
msg-conv-config
Gst-nvmsgconv 元素的配置文件路径名。
字符串
msg-conv-config=dstest5_msgconv_sample_config.txt
dGPU,Jetson
msg-conv-payload-type
有效负载的类型。
0,PAYLOAD_DEEPSTREAM:Deepstream 模式有效负载。
1,PAYLOAD_DEEPSTREAM_MINIMAL:Deepstream 模式有效负载(最小)。
256,PAYLOAD_RESERVED:保留类型。
257,PAYLOAD_CUSTOM:自定义模式有效负载。
整数 0、1、256 或 257
msg-conv-payload-type=0
dGPU,Jetson
msg-conv-msg2p-lib
可选的自定义有效负载生成库的绝对路径名。此库实现了 sources/libs/nvmsgconv/nvmsgconv.h 定义的 API。
字符串
msg-conv-msg2p-lib=/opt/nvidia/deepstream/deepstream-4.0/lib/libnvds_msgconv.so
dGPU,Jetson
msg-conv-comp-id
comp-id 是 gst-nvmsgconv 元素的 Gst 属性。这是组件的 ID,该组件附加了 NvDsEventMsgMeta,必须由 gst-nvmsgconv 元素处理。
整数,>=0
msg-conv-comp-id=1
dGPU,Jetson
debug-payload-dir
用于转储有效负载的目录
字符串
debug-payload-dir=<绝对路径> 默认为 NULL
dGPU Jetson
multiple-payloads
生成多个消息有效负载
布尔值
multiple-payloads=1 默认为 0
dGPU Jetson
msg-conv-msg2p-new-api
使用 Gst 缓冲区帧/对象元数据生成有效负载
布尔值
msg-conv-msg2p-new-api=1 默认为 0
dGPU Jetson
msg-conv-frame-interval
生成有效负载的帧间隔
整数,1 到 4,294,967,295
msg-conv-frame-interval=25 默认为 30
dGPU Jetson
msg-conv-dummy-payload
默认情况下,如果 NVDS_EVENT_MSG_META 附加到缓冲区,则会生成有效负载。使用此虚拟有效负载,即使没有 NVDS_EVENT_MSG_META 附加到缓冲区,也可以生成有效负载
布尔值
msg-conv-dummy-payload=true 默认为 false
dGPU Jetson
消息消费者组#
消息消费者组属性如下:
消息消费者组# 键
含义
类型和值
示例
平台
启用
启用或禁用消息消费者。
布尔值
enable=1
dGPU,Jetson
proto-lib
包含协议适配器实现的库的路径。
字符串
proto-lib=/opt/nvidia/deepstream/deepstream-4.0/lib/libnvds_kafka_proto.so
dGPU,Jetson
conn-str
服务器的连接字符串。
字符串
conn-str=foo.bar.com;80
dGPU,Jetson
config-file
包含协议适配器附加配置的文件路径,
字符串
config-file=../cfg_kafka.txt
dGPU,Jetson
subscribe-topic-list
要订阅的主题列表。
字符串
subscribe-topic-list=topic1;topic2;topic3
dGPU,Jetson
sensor-list-file
包含从传感器索引到传感器名称的映射的文件。
字符串
sensor-list-file=dstest5_msgconv_sample_config.txt
dGPU,Jetson
OSD 组#
OSD 组指定 OSD 组件的属性并修改其行为,该组件在视频帧上叠加文本和矩形。
OSD 组# 键
含义
类型和值
示例
平台
启用
启用或禁用屏幕显示 (OSD)。
布尔值
enable=1
dGPU,Jetson
gpu-id
在多个 GPU 的情况下,元素要使用的 GPU。
整数,≥0
gpu-id=1
dGPU
border-width
为对象绘制的边界框的边框宽度,以像素为单位。
整数,≥0
border-width=10
dGPU,Jetson
border-color
为对象绘制的边界框的边框颜色。
R;G;B;A 浮点数,0≤R,G,B,A≤1
border-color=0;0;0.7;1 #深蓝色
dGPU,Jetson
text-size
描述对象的文本大小,以磅为单位。
整数,≥0
text-size=16
dGPU,Jetson
text-color
描述对象的文本颜色,以 RGBA 格式表示。
R;G;B;A 浮点数,0≤R,G,B,A≤1
text-color=0;0;0.7;1 #深蓝色
dGPU,Jetson
text-bg-color
描述对象的文本背景颜色,以 RGBA 格式表示。
R;G;B;A 浮点数,0≤R,G,B,A≤1
text-bg-color=0;0;0;0.5 #半透明黑色
dGPU,Jetson
clock-text-size
时钟时间文本的大小,以磅为单位。
整数,>0
clock-text-size=16
dGPU,Jetson
clock-x-offset
时钟时间文本的水平偏移量,以像素为单位。
整数,>0
clock-x-offset=100
dGPU,Jetson
clock-y-offset
时钟时间文本的垂直偏移量,以像素为单位。
整数,>0
clock-y-offset=100
dGPU,Jetson
font
描述对象的文本的字体名称。
字符串
font=Purisa
dGPU,Jetson
输入 shell 命令 fc-list 以显示可用字体的名称。
clock-color
时钟时间文本的颜色,以 RGBA 格式表示。
R;G;B;A 浮点数,0≤R,G,B,A≤1
clock-color=1;0;0;1 #红色
dGPU,Jetson
nvbuf-memory-type
元素要为输出缓冲区分配的 CUDA 内存类型。
0 (nvbuf-mem-default):平台特定的默认值
1 (nvbuf-mem-cuda-pinned):pinned/host CUDA 内存
2 (nvbuf-mem-cuda-device):Device CUDA 内存
3 (nvbuf-mem-cuda-unified):Unified CUDA 内存
对于 dGPU:所有值均有效。
对于 Jetson:仅 0(零)有效。
整数,0、1、2 或 3
nvbuf-memory-type=3
dGPU
process-mode
- NvOSD 处理模式。
整数,0、1 或 2
process-mode=1
dGPU,Jetson
display-text
指示是否显示文本
布尔值
display-text=1
dGPU,Jetson
display-bbox
指示是否显示边界框
布尔值
display-bbox=1
dGPU,Jetson
display-mask
指示是否显示实例掩码
布尔值
display-mask=1
dGPU,Jetson
Sink 组#
Sink 组指定 sink 组件的属性并修改其行为,用于渲染、编码和文件保存。
Sink 组# 键
含义
类型和值
示例
平台
启用
启用或禁用 sink。
布尔值
enable=1
dGPU,Jetson
类型
要使用的 sink 类型。
1:Fakesink2:基于 EGL 的窗口 nveglglessink (用于 dGPU) 和 nv3dsink (用于 Jetson)3:编码 + 文件保存 (编码器 + 复用器 + filesink)4:编码 + RTSP 流;注意:sync=1 不适用于此类型;5:nvdrmvideosink (仅限 Jetson)6:消息转换器 + 消息代理整数,1、2、3、4、5 或 6
type=2
dGPU,Jetson
sync
指示流的渲染速度。
0:尽可能快1:同步整数,0 或 1
sync=1
dGPU,Jetson
qos
指示 sink 是否生成服务质量事件,当管道 FPS 无法跟上流帧率时,这可能会导致管道丢帧。
布尔值
qos=0
dGPU,Jetson
source-id
此 sink 必须使用的源的 ID。源 ID 包含在源组名称中。例如,对于组 [source1],source-id=1。
整数,≥0
source-id=1
dGPU,Jetson
gpu-id
在多个 GPU 的情况下,元素要使用的 GPU。
整数,≥0
gpu-id=1
dGPU
container
用于文件保存的容器。仅对 type=3 有效。
1:MP42:MKV整数,1 或 2
container=1
dGPU,Jetson
codec
- 用于保存文件的编码器。
整数,1 或 2
codec=1
dGPU,Jetson
bitrate
用于编码的比特率,以比特/秒为单位。对 type=3 和 4 有效。
整数,>0
bitrate=4000000
dGPU,Jetson
iframeinterval
编码帧内帧发生频率。
整数,0≤iv≤MAX_INT
iframeinterval=30
dGPU,Jetson
output-file
输出编码文件的路径名。仅对 type=3 有效。
字符串
output-file=/home/ubuntu/output.mp4
dGPU,Jetson
nvbuf-memory-type
插件为输出缓冲区分配的 CUDA 内存类型。
0 (nvbuf-mem-default):平台特定的默认值1 (nvbuf-mem-cuda-pinned):pinned/host CUDA 内存2 (nvbuf-mem-cuda-device):Device CUDA 内存3 (nvbuf-mem-cuda-unified):Unified CUDA 内存对于 dGPU:所有值均有效。对于 Jetson:仅 0(零)有效。整数,0、1、2 或 3
nvbuf-memory-type=3
dGPU,Jetson
rtsp-port
RTSP 流媒体服务器的端口;一个有效的未使用端口号。对 type=4 有效。
整数
rtsp-port=8554
dGPU,Jetson
udp-port
流媒体实现内部使用的端口 - 一个有效的未使用端口号。对 type=4 有效。
整数
udp-port=5400
dGPU,Jetson
conn-id
连接索引。对 nvdrmvideosink(type=5) 有效。
整数,>=1
conn-id=0
Jetson
宽度
渲染器宽度,以像素为单位。
整数,>=1
width=1920
dGPU,Jetson
高度
渲染器高度,以像素为单位。
整数,>=1
height=1920
dGPU,Jetson
offset-x
渲染器窗口的水平偏移量,以像素为单位。
整数,>=1
offset-x=100
dGPU,Jetson
offset-y
渲染器窗口的垂直偏移量,以像素为单位。
整数,>=1
offset-y=100
dGPU,Jetson
plane-id
应在哪个平面上渲染视频。对 nvdrmvideosink(type=5) 有效。
整数,≥0
plane-id=0
Jetson
msg-conv-config
Gst-nvmsgconv 元素的配置文件路径名 (type=6)。
字符串
msg-conv-config=dstest5_msgconv_sample_config.txt
dGPU,Jetson
msg-broker-proto-lib
用于 Gst-nvmsgbroker 的协议适配器实现的路径 (type=6)。
字符串
msg-broker-proto-lib= /opt/nvidia/deepstream/deepstream-5.0/lib/libnvds_amqp_proto.so
dGPU,Jetson
msg-broker-conn-str
后端服务器的连接字符串 (type=6)。
字符串
msg-broker-conn-str=foo.bar.com;80;dsapp
dGPU,Jetson
topic
消息主题的名称 (type=6)。
字符串
topic=test-ds4
dGPU,Jetson
msg-conv-payload-type
有效负载的类型。
0,PAYLOAD_DEEPSTREAM:DeepStream 模式有效负载。1,PAYLOAD_DEEPSTREAM_-MINIMAL:DeepStream 模式有效负载(最小)。256,PAYLOAD_RESERVED:保留类型。257,PAYLOAD_CUSTOM:自定义模式有效负载 (type=6)。整数 0、1、256 或 257
msg-conv-payload-type=0
dGPU,Jetson
msg-broker-config
Gst-nvmsgbroker 元素的可选配置文件路径名 (type=6)。
字符串
msg-broker-config=/home/ubuntu/cfg_amqp.txt
dGPU,Jetson
sleep-time
连续 do_work 调用之间的休眠时间,以毫秒为单位
整数 >= 0。对于 Azure,根据 IoT Hub 服务层消息速率限制,使用 >= 10 的值。警告:不合理的过高休眠时间(例如 10000000 毫秒)可能会导致失败
sleep-time=10
dGPU Jetson
new-api
直接使用协议适配器库 API,或使用新的 msgbroker 库包装器 API (type=6)
- 整数
new-api = 0
dGPU,Jetson
msg-conv-msg2p-lib
可选的自定义有效负载生成库的绝对路径名。此库实现了 sources/libs/nvmsgconv/nvmsgconv.h 定义的 API。仅当 msg-conv-payload-type=257,PAYLOAD_CUSTOM 时适用 (type=6)
字符串
msg-conv-msg2p-lib= /opt/nvidia/deepstream/deepstream-4.0/lib/libnvds_msgconv.so
dGPU,Jetson
msg-conv-comp-id
comp-id 是 nvmsgconv 元素的 Gst 属性;要处理元数据的主要/辅助-gie 组件的 ID (gie-unique-id)。(type=6)
整数,>=0
msg-conv-comp-id=1
dGPU,Jetson
msg-broker-comp-id
comp-id 是 nvmsgbroker 元素的 Gst 属性;要处理元数据的主要/辅助 gie 组件的 ID (gie-unique-id)。(type=6)
整数,>=0
msg-broker-comp-id=1
dGPU,Jetson
debug-payload-dir
用于转储有效负载的目录 (type=6)
字符串
debug-payload-dir=<绝对路径> 默认为 NULL
dGPU Jetson
multiple-payloads
生成多个消息有效负载 (type=6)
布尔值
multiple-payloads=1 默认为 0
“dGPU Jetson”
msg-conv-msg2p-new-api
使用 Gst 缓冲区帧/对象元数据生成有效负载 (type=6)
布尔值
msg-conv-msg2p-new-api=1 默认为 0
“dGPU Jetson”
msg-conv-frame-interval
生成有效负载的帧间隔 (type=6)
整数,1 到 4,294,967,295
msg-conv-frame-interval=25 默认为 30
dGPU Jetson
disable-msgconv
仅添加消息代理组件,而不是消息转换器 + 消息代理。(type=6)
整数,
disable-msgconv = 1
dGPU,Jetson
enc-type
用于编码器的引擎
0:NVENC 硬件引擎1:CPU 软件编码器整数,0 或 1
enc-type=0
dGPU,Jetson
profile (HW)
编解码器 V4L2 H264 编码器(HW) 的编码器配置文件
0:Baseline2:Main4:HighV4L2 H265 编码器(HW)
0:Main1:Main10整数,旁边列中的有效值
profile=2
dGPU,Jetson
udp-buffer-size
内部 RTSP 输出管道的 UDP 内核缓冲区大小(以字节为单位)。
整数,>=0
udp-buffer-size=100000
dGPU,Jetson
link-to-demux
一个布尔值,用于启用或禁用仅将特定“source-id”流式传输到此 sink。请查看 tiled-display 组的 enable 键以获取更多信息。
布尔值
link-to-demux=0
dGPU,Jetson
测试组#
测试组用于诊断和调试。
测试组# 键
含义
类型和值
示例
平台
file-loop
指示是否应无限循环输入文件。
布尔值
file-loop=1
dGPU,Jetson
NvDs-analytics 组#
[nvds-analytics] 组用于在管道中添加 nvds-analytics 插件。
键 |
含义 |
类型和值 |
示例 |
平台 |
|---|---|---|---|---|
启用 |
启用或禁用插件。 |
布尔值 |
enable=1 |
dGPU,Jetson |
config-file |
nvdsanalytics 插件的配置文件路径 |
字符串 |
config-file=config_nvdsanalytics.txt |
dGPU,Jetson |
注意
有关插件特定的配置文件规范,请参阅 DeepStream 插件指南(适用于 Gst-nvdspreprocess、Gst-nvinfer、Gst-nvtracker、Gst-nvdewarper、Gst-nvmsgconv、Gst-nvmsgbroker 和 Gst-nvdsanalytics 插件)。
DeepStream SDK 的应用程序调优#
本节提供了 DeepStream SDK 的应用程序调优技巧,使用配置文件中的以下参数。
性能优化#
本节介绍您可以尝试以获得最佳性能的各种性能优化步骤。
DeepStream 最佳实践#
以下是一些优化 DeepStream 应用程序以消除应用程序瓶颈的最佳实践
将 streammux 和主检测器的批次大小设置为等于输入源的数量。这些设置位于配置文件的
[streammux]和[primary-gie]组下。这使管道以满负荷运行。批次大小高于或低于输入源的数量有时会在管道中增加延迟。将 streammux 的高度和宽度设置为输入分辨率。这在配置文件的
[streammux]组下设置。这确保了流不会进行任何不必要的图像缩放。如果您从 RTSP 或 USB 摄像头等实时源进行流式传输,请在配置文件的
[streammux]组中设置live-source=1。这为实时源启用正确的时间戳,从而创建更流畅的播放效果平铺和可视化输出可能会占用 GPU 资源。当您不需要在屏幕上渲染输出时,可以禁用 3 件事以最大化吞吐量。例如,当您想在边缘运行推理并将元数据传输到云端以进行进一步处理时,不需要渲染。
禁用 OSD 或屏幕显示。OSD 插件用于在输出帧中绘制边界框和其他伪影以及添加标签。要禁用 OSD,请在配置文件的
[osd]组中设置 enable=0。tiler 创建一个
NxM网格以显示输出流。要禁用平铺输出,请在配置文件的[tiled-display]组中设置 enable=0。禁用用于渲染的输出 sink:选择
fakesink,即配置文件的[sink]组中的type=1。性能部分中的所有性能基准测试均在禁用平铺、OSD 和输出 sink 的情况下运行。
如果 CPU/GPU 利用率较低,则可能是管道中的元素正在因缓冲区不足而受限。然后尝试通过设置应用程序中
[source#]组的num-extra-surfaces属性或Gst-nvv4l2decoder元素的num-extra-surfaces属性来增加解码器分配的缓冲区数量。如果您在 docker 控制台中运行应用程序并且它提供低 FPS,请在配置文件的
[sink0]组中设置qos=0。问题是由初始负载引起的。当 qos 设置为 1 时,作为[sink0]组中属性的默认值,decodebin 开始丢帧。如果您想优化处理管道的端到端延迟,可以使用 DeepStream 中的延迟测量方法。
要启用帧延迟测量,请在控制台上运行此命令
$ export NVDS_ENABLE_LATENCY_MEASUREMENT=1要为所有插件启用延迟,请在控制台上运行此命令
$ export NVDS_ENABLE_COMPONENT_LATENCY_MEASUREMENT=1
注意
当使用 DeepStream 延迟 API 测量帧延迟时,如果观察到 10^12 或 1e12 量级的大帧延迟数字,请修改延迟测量代码(调用 nvds_measure_buffer_latency API)以
...
guint num_sources_in_batch = nvds_measure_buffer_latency(buf, latency_info);
if (num_sources_in_batch > 0 && latency_info[0].latency > 1e6) {
NvDsBatchMeta *batch_meta = gst_buffer_get_nvds_batch_meta (buf);
batch_meta->batch_user_meta_list = g_list_reverse (batch_meta->batch_user_meta_list);
num_sources_in_batch = nvds_measure_buffer_latency(buf, latency_info);
}
...
Jetson 优化#
确保 Jetson 时钟设置为高频率。运行以下命令以将 Jetson 时钟设置为高频率。
$ sudo nvpmodel -m <mode> --for MAX perf and power mode is 0 $ sudo jetson_clocks
注意
对于 NX:使用模式 2。
在 Jetson 上,使用
Gst-nvdrmvideosink而不是Gst-nv3dsink,因为nv3dsink需要 GPU 利用率。
Triton#
如果您将 Triton 与 DeepStream 一起使用,请调整
tf_gpu_memory_fraction值以设置每个进程的 TensorFlow GPU 内存使用量 - 建议范围 [0.2, 0.6]。值过大可能会导致内存不足,值过小可能会导致性能低下。当将 TensorFlow 或 ONNX 与 Triton 一起使用时,启用 TensorRT 优化。更新 Triton 配置文件以启用 TensorFlow/ONNX TensorRT 在线优化。每次初始化时,这将需要几分钟时间。或者,您可以离线生成 TF-TRT graphdef/savedmodel 模型。
推理吞吐量#
以下是一些帮助您提高应用程序通道密度的步骤
如果您使用 Jetson AGX Orin 或 Jetson Orin NX,则可以使用 DLA(深度学习加速器)进行推理。这可以释放 GPU 以用于其他模型或更多流。
使用 DeepStream,用户可以每隔一帧或每三帧进行推理,并使用跟踪器来预测对象在帧中的位置。这可以通过简单的配置文件更改来完成。用户可以使用 3 个可用跟踪器之一来跟踪帧中的对象。在推理配置文件中,更改
[property]下的 interval 参数。这是一个跳过间隔,即推理之间要跳过的帧数。间隔为 0 表示每帧都推理,间隔为 1 表示跳过 1 帧并每隔一帧推理。通过将间隔从 0 更改为 1,这可以有效地使您的整体通道吞吐量翻倍。为推理选择较低的精度,例如 FP16 或 INT8。如果您想使用 FP16,则不需要新模型。这是 DS 中的一个简单更改。要更改,请更新推理配置文件中的 network-mode 选项。如果您想运行 INT8,则需要一个 INT8 校准缓存,其中包含 FP32 到 INT8 的量化表。
DeepStream 应用程序也可以配置为具有级联神经网络。第一个网络进行检测,然后第二个网络对检测结果进行分类。要启用辅助推理,请从配置文件中启用 secondary-gie。设置适当的批次大小。批次大小将取决于通常从主推理发送到辅助推理的对象数量。您需要进行实验才能确定其用例的适当批次大小。为了减少辅助分类器的推理次数,可以通过设置
input-object-min-width、input-object-min-height、input-object-max-width、input-object-max-height、operate-on-gie-id、operate-on-class-ids来过滤要推理的对象。
减少误报检测#
配置参数 |
描述 |
用例 |
|---|---|---|
threshold |
主检测器的每类阈值。增加阈值会将输出限制为具有更高检测置信度的对象。 |
— |
roi-top-offset roi-bottom-offset |
每类顶部/底部感兴趣区域 (roi) 偏移量。将输出限制为帧的指定区域中的对象。 |
减少在行车记录仪仪表板上看到的误报检测 |
detected-min-w detected-min-h detected-max-w detected-max-h |
主检测器的每类最小/最大对象宽度/高度。将输出限制为指定大小的对象。 |
减少误报检测,例如,将树检测为人的情况 |