Gst-nvinfer#
Gst-nvinfer 插件使用 NVIDIA® TensorRT™ 对输入数据执行推理。
该插件接受来自上游的批量 NV12/RGBA 缓冲区。NvDsBatchMeta 结构必须已附加到 Gst 缓冲区。底层库 (libnvds_infer) 可操作任何 INT8 RGB、BGR 或 GRAY 数据,其维度为网络高度和网络宽度。Gst-nvinfer 插件根据网络要求对输入帧执行变换(格式转换和缩放),并将变换后的数据传递给底层库。底层库预处理变换后的帧(执行归一化和均值减法),并生成最终的浮点 RGB/BGR/GRAY 平面数据,这些数据将传递给 TensorRT 引擎进行推理。底层库生成的输出类型取决于网络类型。预处理函数为
y = 网络比例 因子*(x-均值)
其中
x 是输入像素值。它是范围为 [0,255] 的 int8。
均值是相应的均值,从均值文件或作为 offsets[c] 读取,其中 c 是输入像素所属的通道,offsets 是配置文件中指定的数组。它是一个浮点数。
net-scale-factor 是配置文件中指定的像素缩放因子。它是一个浮点数。
y 是相应的输出像素值。它是一个浮点数。
Gst-nvinfer 当前可用于以下类型的网络
多类对象检测
多标签分类
分割(语义分割)
实例分割
Gst-nvinfer 插件可以在三种模式下工作
主模式:对完整帧进行操作
辅助模式:对上游组件在元数据中添加的对象进行操作
预处理张量输入模式:对上游组件附加的张量进行操作
当在预处理张量输入模式下操作时,Gst-nvinfer 内部的预处理将完全跳过。插件查找附加到输入缓冲区的 GstNvDsPreProcessBatchMeta,并将张量按原样传递给 TensorRT 推理函数,无需任何修改。此模式当前支持对完整帧和 ROI 进行处理。GstNvDsPreProcessBatchMeta 由 Gst-nvdspreprocess 插件附加。
当插件作为辅助分类器与跟踪器一起运行时,它会尝试通过避免在每帧中对同一对象重新推理来提高性能。它通过将分类输出缓存在以对象唯一 ID 为键的映射中来实现这一点。仅当对象首次在帧中出现(基于其对象 ID)或当对象的大小(边界框区域)增加 20% 或更多时,才会对对象进行推理。只有当跟踪器作为上游元素添加时,这种优化才有可能实现。TensorRT 接口的详细文档可在以下网址获得: https://docs.nvda.net.cn/deeplearning/sdk/tensorrt-developer-guide/index.html 该插件支持用于自定义层的 IPlugin 接口。有关详细信息,请参阅 IPlugin 接口部分。该插件还支持自定义函数的接口,用于解析对象检测器的输出以及在存在多个输入层的情况下初始化非图像输入层。有关自定义模型自定义方法实现的更多信息,请参阅 sources/includes/nvdsinfer_custom_impl.h。
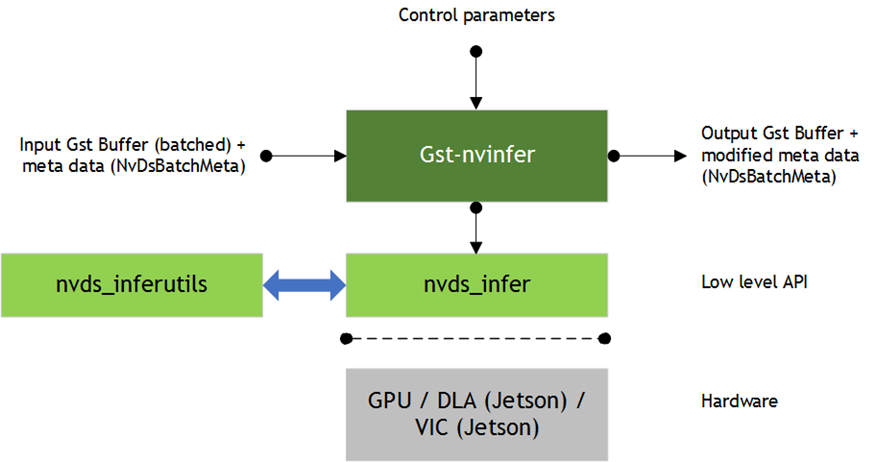
下游组件接收带有未修改内容的 Gst 缓冲区,以及从 Gst-nvinfer 插件的推理输出创建的元数据。该插件可用于级联推理。也就是说,它可以直接对输入数据执行主推理,然后对主推理的结果执行辅助推理,依此类推。有关更多详细信息,请参阅示例应用程序 deepstream-test2。
输入和输出#
本节概述 Gst-nvinfer 插件的输入、输出和通信设施。
输入
Gst 缓冲区
NvDsBatchMeta(附加 NvDsFrameMeta)
ONNX
TAO 编码模型和密钥
离线:支持由 TAO Toolkit SDK 模型转换器生成的引擎文件
层:支持 TensorRT 支持的所有层,请参阅: https://docs.nvda.net.cn/deeplearning/sdk/tensorrt-developer-guide/index.html。
控制参数
Gst-nvinfer 从配置文件获取控制参数。您可以通过设置属性 config-file-path 来指定此文件。有关详细信息,请参阅 Gst-nvinfer 文件配置规范。可以通过 GObject 属性设置的其他控制参数包括
批大小
推理间隔
将推理张量输出作为缓冲区元数据附加
将实例掩码输出作为对象元数据附加
通过 GObject 属性设置的参数将覆盖 Gst-nvinfer 配置文件中的参数。
输出
Gst 缓冲区
根据网络类型和配置的参数,输出以下一项或多项
NvDsObjectMeta
NvDsClassifierMeta
NvDsInferSegmentationMeta
NvDsInferTensorMeta
特性#
下表总结了插件的特性。
Gst-nvinfer 插件特性# 特性
描述
发布版本
显式全维度网络支持
有关更多详细信息,请参阅 https://docs.nvda.net.cn/deeplearning/sdk/tensorrt-developer-guide/index.html#work_dynamic_shapes。
DS 5.0
非极大值抑制 (NMS)
新的边界框聚类算法。
DS 5.0
动态模型更新(仅限引擎文件)
在运行的 pipeline 中动态更新 model-engine-file。
DS 5.0
可配置的帧缩放参数
可配置的选项,用于选择计算硬件和滤波器,以便在将帧/对象裁剪缩放到网络分辨率时使用
DS 5.0
TAO 工具包编码模型支持
—
DS 4.0
灰度输入模型支持
支持具有单通道灰度输入的模型
DS 4.0
张量输出作为元数据
原始张量输出作为元数据附加到 Gst 缓冲区,并在 pipeline 中流动
DS 4.0
分割模型
支持分割模型
DS 4.0
保持输入纵横比
可配置的支持,用于在将输入帧缩放到网络分辨率时保持纵横比
DS 4.0
自定义 cuda 引擎创建接口
用于从 TensorRT INetworkDefinition 和 IBuilder API 而不是模型文件生成 CUDA 引擎的接口
DS 4.0
ONNX 模型支持
—
DS 3.0
多种操作模式
支持级联推理
DS 2.0
辅助推理的异步操作模式
为辅助分类器异步推理
DS 2.0
使用 CV::Group 矩形进行分组
用于检测器边界框聚类
DS 2.0
可配置的批大小处理
用户可以配置处理的批大小
DS 2.0
对输出 blob 数量没有限制
支持任意数量的输出 blob
DS 3.0
可配置的检测到的类别数量(检测器)
支持可配置的检测到的类别数量
DS 3.0
对类别的支持:可配置 (> 32)
支持任意数量的类别
DS 3.0
应用程序访问原始推理输出
应用程序可以访问用户指定层的推理输出缓冲区
DS 3.0
支持单次检测器 (SSD)
—
DS 3.0
辅助 GPU 推理引擎 (GIE) 作为主边界框上的检测器运行
支持作为检测器的辅助推理
DS 2.0
多类辅助支持
支持多个分类器网络输出
DS 2.0
使用 DBSCAN 进行分组
用于检测器边界框聚类
DS 3.0
加载包含自定义层 IPlugin 实现的外部库(IPluginCreator & IPluginFactory)
支持加载 (dlopen()) 包含自定义层 IPlugin 实现的库
DS 3.0
多 GPU
选择要在其上运行推理的 GPU
DS 2.0
检测宽度高度配置
根据最小/最大对象尺寸阈值过滤掉检测到的对象
DS 2.0
允许用户注册自定义解析器
支持自定义检测器网络的最终输出层边界框解析
DS 2.0
基于可配置对象尺寸的边界框过滤
支持在二级模式下对满足最小/最大尺寸阈值的对象进行推理
DS 2.0
可配置的操作间隔
推理间隔(跳过的批量缓冲区数量)
DS 2.0
选择顶部和底部感兴趣区域 (RoI)
移除顶部和底部区域中检测到的对象
DS 2.0
对特定对象类型进行操作(二级模式)
仅处理用于辅助推理的定义类的对象
DS 2.0
用于解析边界框的可配置 blob 名称(检测器)
支持检测器输出 blob 的可配置名称
DS 2.0
允许配置文件输入
支持配置文件作为输入(在 DS 3.0 中是强制性的)
DS 2.0
允许选择操作的类 ID
支持基于类 ID 的辅助推理
DS 2.0
支持全帧推理:主推理作为分类器
可以在主模式下作为分类器工作
DS 2.0
多类辅助支持
支持多个分类器网络输出
DS 2.0
辅助 GIE 作为主边界框上的检测器运行 支持作为检测器的辅助推理
—
DS 2.0
支持 FP16、FP32 和 INT8 模型 FP16 和 INT8 取决于平台
—
DS 2.0
支持 TensorRT 引擎文件作为输入
—
DS 2.0
推理输入层初始化 在存在多个输入层的情况下初始化非视频输入层
—
DS 3.0
支持 FasterRCNN
—
DS 3.0
支持 Yolo 检测器 (YoloV3/V3-tiny/V2/V2-tiny)
—
DS 4.0
支持 yolov3-spp 检测器
—
DS 5.0
支持使用 MaskRCNN 进行实例分割
支持使用 MaskRCNN 进行实例分割。它包括输出解析器和在对象元数据中附加掩码。
DS 5.0
支持 NHWC 网络输入
—
DS 6.0
增加了对 TAO ONNX 模型的支持
—
DS 6.0
支持输入张量元数据
使用来自输入张量元数据的已预处理原始张量(作为用户元数据在批处理级别附加)进行推理,并跳过 nvinfer 中的预处理。在此模式下,nvinfer 的批大小必须等于 gst-nvdspreprocess 插件配置文件中设置的 ROI 总和。
DS 6.0
支持将边界框裁剪到 ROI 边界
—
DS 6.2
Gst-nvinfer 文件配置规范#
Gst-nvinfer 配置文件使用 https://specifications.freedesktop.org/desktop-entry-spec/latest 中描述的“密钥文件”格式。[property] 组配置插件的常规行为。它是唯一强制性的组。[class-attrs-all] 组配置所有类别的检测参数。[class-attrs-<class-id>] 组配置由 <class-id> 指定的类别的检测参数。例如,[class-attrs-23] 组配置类别 ID 23 的检测参数。此类型的组具有与 [class-attrs-all] 相同的键。以下两个表分别描述了 [property] 组和 [class-attrs-…] 组支持的键。
Gst-nvinfer 属性组支持的键# 属性
含义
类型和范围
示例注释
num-detected-classes
网络检测到的类别数量
整数,>0
num-detected-classes=91
检测器
两者
net-scale-factor
像素归一化因子(如果启用了 input-tensor-meta,则忽略)
浮点数,>0.0
net-scale-factor=0.031
全部
两者
model-file
模型文件的路径名。如果使用 model-engine-file,则不需要
字符串
model-file=
/home/ubuntu/model
全部
两者
proto-file
prototxt 文件的路径名。如果使用 model-engine-file,则不需要
字符串
proto-file=
/home/ubuntu/model.prototxt
全部
两者
int8-calib-file
INT8 校准文件的路径名,用于使用 FP32 模型进行动态范围调整
字符串
int8-calib-file=/home/ubuntu/int8_calib
全部
两者
batch-size
一批中一起推理的帧或对象数量
整数,>0
batch-size=30
全部
两者
input-tensor-from-meta
使用作为元数据附加的预处理输入张量,而不是在插件内部进行预处理。如果设置了此项,请确保 nvinfer 的批大小等于 gst-nvdspreprocess 插件配置文件中设置的 ROI 总和。
布尔值
input-tensor-from-meta=1
全部
主推理
tensor-meta-pool-size
输出张量元数据池的大小
整数,>0
tensor-meta-pool-size=20
全部
两者
model-engine-file
序列化模型引擎文件的路径名
字符串
model-engine-file=
/home/ubuntu/model.engine
全部
两者
onnx-file
ONNX 模型文件的路径名
字符串
onnx-file=
/home/ubuntu/model.onnx
全部
两者
enable-dbscan
指示是否使用 DBSCAN 或 OpenCV groupRectangles() 函数对检测到的对象进行分组。已弃用。请改用 cluster-mode。
布尔值
enable-dbscan=1
检测器
两者
labelfile-path
包含模型标签的文本文件的路径名
字符串
labelfile-path=
/home/ubuntu/model_labels.txt
检测器和分类器
两者
mean-file
PPM 格式的均值数据文件的路径名(如果启用了 input-tensor-meta,则忽略)
字符串
mean-file=
/home/ubuntu/model_meanfile.ppm
全部
两者
gie-unique-id
要分配给 GIE 的唯一 ID,使应用程序和其他元素能够识别检测到的边界框和标签
整数,>0
gie-unique-id=2
全部
两者
operate-on-gie-id
GIE 的唯一 ID,此 GIE 将在其元数据(边界框)上运行
整数,>0
operate-on-gie-id=1
全部
两者
operate-on-class-ids
父 GIE 的类别 ID,此 GIE 将在其上运行
分号分隔的整数数组
operate-on-class-ids=1;2
对类别 ID 为 1、2 的对象进行操作
由父 GIE 生成
如果 operate-on-class-ids 设置为 -1,
它将对所有类别 ID 进行操作
全部
两者
interval
指定要跳过推理的连续批次数量
整数,>0
interval=1
全部
主推理
input-object-min-width
辅助 GIE 仅对具有此最小宽度的对象进行推理
整数,≥0
input-object-min-width=40
全部
辅助推理
input-object-min-height
辅助 GIE 仅对具有此最小高度的对象进行推理
整数,≥0
input-object-min-height=40
全部
辅助推理
input-object-max-width
辅助 GIE 仅对具有此最大宽度的对象进行推理
整数,≥0
input-object-max-width=256
0 禁用阈值
全部
辅助推理
input-object-max-height
辅助 GIE 仅对具有此最大高度的对象进行推理
整数,≥0
input-object-max-height=256
全部
两者
network-mode
推理要使用的数据格式
整数 0:FP32 1:INT8 2:FP16 3:BEST
network-mode=0
全部
两者
offsets
要从每个像素中减去的颜色分量的均值数组。数组长度必须等于帧中颜色分量的数量。插件将均值乘以 net-scale-factor。(如果启用了 input-tensor-meta,则忽略)
分号分隔的浮点数数组,所有值 ≥0
offsets=77.5 21.2
全部
两者
parse-bbox-func-name
自定义边界框解析函数的名称。如果未指定,Gst-nvinfer 将使用 SDK 提供的 resnet 模型的内部函数
字符串
parse-bbox-func-name=
parse_bbox_resnet
检测器
两者
parse-bbox-instance-mask-func-name
自定义实例分割解析函数的名称。对于实例分割网络,这是强制性的,因为没有内部函数。
字符串
parse-bbox-instance-mask-func-name=
NvDsInferParseCustomMrcnnTLT
实例分割
主推理
custom-lib-path
包含自定义模型自定义方法实现的库的绝对路径名
字符串
custom-lib-path=
/home/ubuntu/libresnet_custom_impl.so
全部
两者
model-color-format
模型所需的颜色格式(如果启用了 input-tensor-meta,则忽略)
整数 0:RGB 1:BGR 2:GRAY
model-color-format=0
全部
两者
classifier-async-mode
启用对检测到的对象进行推理和异步元数据附加。仅当附加 tracker-ids 时才有效。推送缓冲区下游,无需等待推理结果。在推理结果可用于其内部队列中的下一个 Gst 缓冲区后附加元数据。
布尔值
classifier-async-mode=1
分类器
辅助推理
process-mode
元素要操作的模式(主模式或辅助模式)(如果启用了 input-tensor-meta,则忽略)
整数 1=主模式 2=辅助模式
gie-mode=1
全部
两者
classifier-threshold
最小阈值标签概率。如果标签具有的最高概率大于此阈值,则 GIE 输出该标签
浮点数,≥0
classifier-threshold=0.4
分类器
两者
secondary-reinfer-interval
对象的重新推理间隔,以帧为单位
整数,≥0
secondary-reinfer-interval=15
检测器和分类器
辅助推理
output-tensor-meta
Gst-nvinfer 将原始张量输出作为 Gst 缓冲区元数据附加。
布尔值
output-tensor-meta=1
全部
两者
output-instance-mask
Gst-nvinfer 在对象元数据中附加实例掩码输出。
布尔值
output-instance-mask=1
实例分割
主推理
enable-dla
指示是否使用 DLA 引擎进行推理。注意:DLA 仅在 NVIDIA® Jetson AGX Orin™ 和 NVIDIA® Jetson Orin NX™ 上受支持。目前正在进行中。
布尔值
enable-dla=1
全部
两者
use-dla-core
要使用的 DLA 核心。注意:仅在 Jetson AGX Orin 和 Jetson Orin NX 上受支持。目前正在进行中。
整数,≥0
use-dla-core=0
全部
两者
network-type
网络类型
整数
0:检测器
1:分类器
2:分割
3:实例分割
network-type=1
全部
两者
maintain-aspect-ratio
指示在缩放输入时是否保持纵横比。
布尔值
maintain-aspect-ratio=1
全部
两者
symmetric-padding
指示在缩放输入时是否对称填充图像。DeepStream 默认情况下不对称填充图像。
布尔值
symmetric-padding=1
全部
两者
parse-classifier-func-name
自定义分类器输出解析函数的名称。如果未指定,Gst-nvinfer 将使用 softmax 层的内部解析函数。
字符串
parse-classifier-func-name=
parse_bbox_softmax
分类器
两者
custom-network-config
用于创建 CUDA 引擎的自定义接口中可用的自定义网络的配置文件的路径名。
字符串
custom-network-config=
/home/ubuntu/network.config
全部
两者
tlt-encoded-model
TAO 工具包编码模型的路径名。
字符串
tlt-encoded-model=
/home/ubuntu/model.etlt
全部
两者
tlt-model-key
TAO 工具包编码模型的密钥。
字符串
tlt-model-key=abc
全部
两者
segmentation-threshold
分割模型的置信度阈值,用于输出像素的有效类别。如果置信度小于此阈值,则该像素的类别输出为 -1。
浮点数,≥0.0
segmentation-threshold=0.3
分割,实例分割
两者
segmentation-output-order
分割网络输出层顺序
整数 0:NCHW 1:NHWC
segmentation-output-order=1
分割
两者
workspace-size
引擎要使用的工作区大小,以 MB 为单位
整数,>0
workspace-size=45
全部
两者
force-implicit-batch-dim
当网络同时支持隐式批次维度和全维度时,强制使用隐式批次维度模式。
布尔值
force-implicit-batch-dim=1
全部
两者
engine-create-func-name
自定义 TensorRT CudaEngine 创建函数的名称。有关详细信息,请参阅“自定义模型实现接口”部分
字符串
engine-create-func-name=
NvDsInferYoloCudaEngineGet
全部
两者
cluster-mode
要使用的聚类算法。有关配置算法特定参数,请参阅下表。有关更多信息,请参阅 nvinfer 支持的聚类算法
整数 0:OpenCV groupRectangles() 1:DBSCAN 2:非极大值抑制 3:DBSCAN + NMS 混合 4:无聚类
cluster-mode=2
实例分割的 cluster-mode=4
检测器
两者
filter-out-class-ids
过滤掉属于指定类别 ID 的检测到的对象
分号分隔的整数数组
filter-out-class-ids=1
2
scaling-filter
用于将帧/对象裁剪缩放到网络分辨率的滤波器(如果启用了 input-tensor-meta,则忽略)
整数,有关有效值,请参阅 nvbufsurftransform.h 中的枚举 NvBufSurfTransform_Inter
scaling-filter=1
全部
两者
scaling-compute-hw
用于将帧/对象裁剪缩放到网络分辨率的计算硬件(如果启用了 input-tensor-meta,则忽略)
整数 0:平台默认值 – GPU (dGPU)、VIC (Jetson) 1:GPU 2:VIC(仅限 Jetson)
scaling-compute-hw=2
全部
两者
output-io-formats
指定绑定输出层的数据类型和顺序。对于未指定的层,默认为 FP32 和 CHW
分号分隔的格式列表。<output-layer1-name>:<data-type>:<order>;<output-layer2-name>:<data-type>:<order>
data-type 应为 [fp32, fp16, int32, int8] 之一
order 应为 [chw, chw2, chw4, hwc8, chw16, chw32] 之一
output-io-formats=
conv2d_bbox:fp32:chw;conv2d_cov/Sigmoid:fp32:chw
全部
两者
Layer-device-precision
指定网络中任何层的设备类型和精度
分号分隔的格式列表。<layer1-name>:<precision>:<device-type>;<layer2-name>:<precision>:<device-type>;
precision 应为 [fp32, fp16, int8] 之一
Device-type 应为 [gpu, dla] 之一
layer-device-precision=
output_cov/Sigmoid:fp32:gpu;output_bbox/BiasAdd:fp32:gpu;
全部
两者
network-input-order
网络输入层的顺序(如果启用了 input-tensor-meta,则忽略)
整数 0:NCHW 1:NHWC
network-input-order=1
全部
两者
classifier-type
分类器功能的描述
字符串(字母数字,“-”和“_”允许,无空格)
classifier-type=vehicletype
分类器
两者
crop-objects-to-roi-boundary
裁剪对象边界框以适应指定的 ROI 边界。
布尔值
crop-objects-to-roi-boundary=1
检测器
两者
Gst-nvinfer 类属性组支持的键# 名称
描述
类型和范围
示例
注释
(主/辅助)
threshold
检测阈值
浮点数,≥0
threshold=0.5
对象检测器
两者
pre-cluster-threshold
要在聚类操作之前应用的检测阈值
浮点数,≥0
pre-cluster-threshold=
0.5
对象检测器
两者
post-cluster-threshold
要在聚类操作之后应用的检测阈值
浮点数,≥0
post-cluster-threshold=
0.5
对象检测器
两者
eps
OpenCV grouprectangles() 函数和 DBSCAN 算法的 Epsilon 值
浮点数,≥0
eps=0.2
对象检测器
两者
group-threshold
OpenCV grouprectangles() 函数的矩形合并的阈值
整数,≥0
group-threshold=1
0 禁用聚类功能
对象检测器
两者
minBoxes
DBSCAN 算法形成密集区域所需的最小点数
整数,≥0
minBoxes=1
0 禁用聚类功能
对象检测器
两者
dbscan-min-score
集群中所有邻居的置信度总和的最小值,以便将其视为有效集群。
浮点数,≥0
dbscan-min-score=
0.7
对象检测器
两者
nms-iou-threshold
两个提议之间的最大 IOU 分数,超过此分数后,置信度较低的提议将被拒绝。
浮点数,≥0
nms-iou-threshold=
0.2
对象检测器
两者
roi-top-offset
RoI 从帧顶部的偏移量。仅输出 RoI 内的对象。
整数,≥0
roi-top-offset=
200
对象检测器
两者
roi-bottom-offset
RoI 从帧底部的偏移量。仅输出 RoI 内的对象。
整数,≥0
roi-bottom-offset=
200
对象检测器
两者
detected-min-w
GIE 要输出的检测到的对象的最小宽度(以像素为单位)
整数,≥0
detected-min-w=
64
对象检测器
两者
detected-min-h
GIE 要输出的检测到的对象的最小高度(以像素为单位)
整数,≥0
detected-min-h=
64
对象检测器
两者
detected-max-w
GIE 要输出的检测到的对象的最大宽度(以像素为单位)
整数,≥0
detected-max-w=200
0 禁用属性
对象检测器
两者
detected-max-h
GIE 要输出的检测到的对象的最大高度(以像素为单位)
整数,≥0
detected-max-h=200
0 禁用属性
对象检测器
两者
topk
仅保留检测得分最高的 top K 个对象。
整数,≥0。-1 表示禁用
topk=10
对象检测器
两者
注意
UFF 模型支持已从 TRT 10.3 中移除。
Gst 属性#
通过 Gst 属性设置的值将覆盖配置文件中属性的值。应用程序出于需要以编程方式设置某些属性的目的而执行此操作。下表描述了 Gst-nvinfer 插件的 Gst 属性。
属性 |
含义 |
类型和范围 |
示例注释 |
|---|---|---|---|
config-file-path |
Gst-nvinfer 元素的配置文件的绝对路径名 |
字符串 |
config-file-path=config_infer_primary.txt |
process-mode |
推理处理模式 1=主模式 2=辅助模式 |
整数,1 或 2 |
process-mode=1 |
unique-id |
唯一 ID,用于标识此 GIE 生成的元数据 |
整数,| 0 到 4,294,967,295 |
unique-id=1 |
infer-on-gie-id |
请参阅配置文件表中的 operate-on-gie-id |
整数,0 到 4,294,967,295 |
infer-on-gie-id=1 |
operate-on-class-ids |
请参阅配置文件表中的 operate-on-class-ids |
冒号分隔的整数(类别 ID)数组 |
operate-on-class-ids=1:2:4 |
filter-out-class-ids |
请参阅配置文件表中的 filter-out-class-ids |
分号分隔的整数数组 |
filter-out-class-ids=1;2 |
model-engine-file |
预生成的序列化引擎文件的绝对路径名,用于该模式 |
字符串 |
model-engine-file=model_b1_fp32.engine |
batch-size |
一批中一起推理的帧/对象数量 |
整数,1 – 4,294,967,295 |
batch-size=4 |
Interval |
要跳过推理的连续批次数量 |
整数,0 到 32 |
interval=0 |
gpu-id |
要用于预处理/推理的 GPU 设备 ID(仅限 dGPU) |
整数,0-4,294,967,295 |
gpu-id=1 |
raw-output-file-write |
原始推理输出文件的路径名 |
布尔值 |
raw-output-file-write=1 |
raw-output-generated-callback |
指向原始输出生成回调函数的指针 |
指针 |
无法通过 gst-launch 设置 |
raw-output-generated-userdata |
指向要与 raw-output-generated-callback 一起提供的用户数据的指针 |
指针 |
无法通过 gst-launch 设置 |
output-tensor-meta |
指示是否将张量输出作为元数据附加到 GstBuffer 上。 |
布尔值 |
output-tensor-meta=0 |
output-instance-mask |
Gst-nvinfer 在对象元数据中附加实例掩码输出。 |
布尔值 |
output-instance-mask=1 |
input-tensor-meta |
使用作为元数据附加的预处理输入张量,而不是在插件内部进行预处理 |
布尔值 |
input-tensor-meta=1 |
crop-objects-to-roi-boundary |
裁剪对象边界框以适应指定的 ROI 边界 |
布尔值 |
crop-objects-to-roi-boundary=1 |
nvinfer 支持的聚类算法#
cluster-mode = 0 | GroupRectangles#
GroupRectangles 是 OpenCV 库中的一种聚类算法,它使用矩形等价标准对大小和位置相似的矩形进行聚类。链接到 API 文档 - https://docs.opencv.ac.cn/3.4/d5/d54/group__objdetect.html#ga3dba897ade8aa8227edda66508e16ab9
cluster-mode = 1 | DBSCAN#
基于密度的噪声应用空间聚类或 DBSCAN 是一种聚类算法,它通过检查特定矩形在其邻域(由 eps 值定义)中是否具有最少数量的邻居来识别聚类。该算法进一步将每个有效聚类归一化为单个矩形,如果其置信度大于阈值,则将其作为有效边界框输出。
cluster-mode = 2 | NMS#
非极大值抑制或 NMS 是一种聚类算法,它根据重叠程度 (IOU) 过滤重叠矩形,该重叠程度用作阈值。首先保留具有最高置信度分数的矩形,同时迭代删除重叠大于阈值的矩形。
cluster-mode = 3 | Hybrid#
混合聚类算法是一种在两步过程中同时使用 DBSCAN 和 NMS 算法的方法。首先应用 DBSCAN 以在 proposals 中形成未归一化的聚类,同时去除异常值。稍后在这些聚类上应用 NMS,以选择最终的输出矩形。
cluster-mode=4 | No clustering#
不应用聚类,所有边界框矩形 proposals 都按原样返回。
张量元数据#
Gst-nvinfer 插件可以将 TensorRT 推理引擎生成的原始输出张量数据作为元数据附加。它作为 NvDsInferTensorMeta 添加到主模式(全帧)的 NvDsFrameMeta 的 frame_user_meta_list 成员中,或作为辅助模式(对象)的 NvDsObjectMeta 的 obj_user_meta_list 成员中。
读取或解析输出层的推理原始张量数据#
启用属性 output-tensor-meta 或在 Gst-nvinfer 插件的配置文件中启用同名属性。
当作为主 GIE 运行时,`NvDsInferTensorMeta` 会附加到每个帧(每个 NvDsFrameMeta 对象)的
frame_user_meta_list。当作为辅助 GIE 运行时,NvDsInferTensorMeta 会附加到每个 NvDsObjectMeta 对象的obj_user_meta_list。
Gst-nvinfer 附加的元数据可以在从 Gst-nvinfer 实例下游附加的 GStreamer pad 探针中访问。
NvDsInferTensorMeta 对象的元数据类型设置为
NVDSINFER_TENSOR_OUTPUT_META。要获取此元数据,您必须迭代 NvDsUserMeta 用户元数据对象,这些对象位于frame_user_meta_list或obj_user_meta_list引用的列表中。
有关 Gst-infer 张量元数据用法的更多信息,请参阅 DeepStream SDK 示例中提供的 sources/apps/sample_apps/deepstream_infer_tensor_meta-test.cpp 中的源代码。
分割元数据#
Gst-nvinfer 插件将分割模型的输出作为用户元数据附加到 NvDsInferSegmentationMeta 的实例中,其中 meta_type 设置为 NVDSINFER_SEGMENTATION_META。用户元数据添加到主模式(全帧)的 NvDsFrameMeta 的 frame_user_meta_list 成员中,或辅助模式(对象)的 NvDsObjectMeta 的 obj_user_meta_list 成员中。有关如何访问用户元数据的指南,请参阅 NvDsBatchMeta 内部的用户/自定义元数据添加 和 张量元数据 部分。