Gst-nvstreammux New#
Gst-nvstreammux 插件从多个输入源形成帧批次。当将源连接到 nvstreammux(复用器)时,必须使用 gst_element_get_request_pad() 和 pad 模板 sink_%u 从复用器请求新的 pad。有关更多信息,请参阅 DeepStream 应用源代码中的 link_element_to_streammux_sink_pad()。复用器形成批处理大小帧的批处理缓冲区。(批处理大小使用 gst 对象属性指定。)复用器将来自该源的帧作为复用器输出批处理缓冲区的一部分转发。当复用器取回其输出缓冲区时,帧将返回到源。
当批次已满或达到从提供的 streammux 配置文件中的总体和流特定“fps”控制配置键计算出的批次形成超时时,复用器会将批次向下游推送。超时在收集到新批次的第一个缓冲区时开始运行。批次生成的默认总体最大和最小 fps 分别为 120 和 5。
复用器的默认批处理使用轮询算法来收集来自源的帧。它尝试从每个源的每个批次中收集平均 (批次大小/源数量) 帧(如果所有源都是实时的且它们的帧率都相同)。但是,帧的数量因源而异,具体取决于源的帧率。复用器将 NvDsBatchMeta 元数据结构附加到输出批处理缓冲区。此元数据包含有关复制到批次中的帧的信息(例如,帧的源 ID、输入帧的原始分辨率、输入帧的原始缓冲区 PTS)。连接到 Sink_N pad 的源在 NvDsBatchMeta 中将具有 pad_index N。
复用器支持在运行时添加和删除源。当复用器收到来自新源的缓冲区时,它会发送 GST_NVEVENT_PAD_ADDED 事件。当复用器 sink pad 被删除时,复用器会发送 GST_NVEVENT_PAD_DELETED 事件。这两个事件都包含正在添加或删除的源的源 ID(请参阅 sources/includes/gst-nvevent.h)。下游元素可以在收到这些事件时重新配置。此外,复用器还发送 GST_NVEVENT_STREAM_EOS 以指示来自源的 EOS。
复用器支持计算源帧的 NTP 时间戳。它支持两种模式。在系统时间戳模式下,复用器将当前系统时间附加为 NTP 时间戳。在 RTCP 时间戳模式下,复用器使用 RTCP 发送者报告来计算帧在源生成时的 NTP 时间戳。NTP 时间戳在 NvDsFrameMeta 的 ntp_timestamp 字段中设置。可以通过设置 attach-sys-ts 属性来切换模式。有关更多详细信息,请参阅 DeepStream 中的 NTP 时间戳。

注意
当前的 nvsteammux 应默认使用。用户将能够通过设置环境变量 export USE_NEW_NVSTREAMMUX=yes 来使用新的 nvstreammux。新的 nvstreammux 不再是 beta 功能。在即将发布的 DeepStream 版本中,此环境变量和当前 nvstreammux 的使用将被弃用,以默认加载新的 nvstreammux。
输入和输出#
输入
来自任意数量源的 NV12/RGBA 缓冲区
来自任意数量源的单声道 S16LE/F32LE 音频缓冲区
控制参数
batch-size
config-file-path [下面详述的 config-keys]
num-surfaces-per-frame
attach-sys-ts
frame-duration
输出
NV12/RGBA 批处理视频缓冲区
NvBufSurface或批处理音频缓冲区NvBufAudioGstNvBatchMeta(包含有关批处理缓冲区中各个帧的信息的元数据)
特性#
下表总结了插件的特性。
特性 |
描述 |
发布版本 |
|---|---|---|
新的 streammux,在单独的 mux 配置文件中支持众多 config-keys。 |
引入新的 streammux |
DS 5.0 |
缓冲区时间戳同步支持 |
请查看 sync-inputs 和 max-latency 属性文档 |
DS 6.0 |
GstMeta 和 NvDsMeta 复制支持 |
在 nvstreammux 和 nvstreamdemux 中均受支持 |
DS 6.1 |
从另一个 nvstreammux 实例批处理批处理缓冲区 |
管道中级联的 nvstreammux 用法 |
DS 6.1 |
运行时配置文件更改 |
请查看 config-file-path 属性文档 |
DS 6.1 |
视频和音频缓冲区的延迟测量支持 |
在 nvstreammux 和 nvstreamdemux 中均受支持 |
DS 6.1 |
注意
新的 nvstreammux 不会将批处理缓冲区缩放到单个分辨率。一个批次可以包含来自不同分辨率的不同流的缓冲区。因此,对于新的 mux,批处理缓冲区的单个分辨率无效,并且 muxer 的 source-pad-caps 也无效。
Gst 属性#
下表描述了 Gst-nvstreammux 插件的 Gst 属性。
Gst-nvstreammux gst-properties# 属性
含义
类型和范围
示例注释
batch-size
批次中的最大帧数。
整数,0 到 4,294,967,295
batch-size=30
batched-push-timeout
在第一个缓冲区可用后等待推送批次的超时时间(以微秒为单位),即使未形成完整批次。
有符号整数,-1 到 2,147,483,647
batched-push-timeout= 40000 40 毫秒
num-surfaces-per-frame
每帧的最大表面数。注意:对于 dewarper 用例,这需要设置为 > 1;有关更多信息,请查看 nvdewarper 插件的文档
整数,0 到 4,294,967,295
num-surfaces-per-frame=1(默认)
config-file-path
Gst-nvstreammux 元素的配置文件的绝对或相对(相对于 DS 配置文件位置)路径
字符串
config-file-path=config_mux_source30.txt
sync-inputs
同步输入。用于强制输入帧的时间戳同步的布尔属性。
布尔值,0 或 1
sync-inputs=0(默认)
max-latency
最大上游延迟(以纳秒为单位)。当 sync-inputs=1 时,超过 max-latency 的缓冲区将被丢弃。
整数,0 到 4,294,967,295
max-latency=0(默认)
frame-duration
输入帧的持续时间(以毫秒为单位),用于基于帧率的 NTP 时间戳校正。如果设置为 0,则帧持续时间将从 RTP 抖动缓冲区中看到的 PTS 值自动推断。当 RTP 抖动缓冲区和 nvstreammux 之间的帧持续时间发生变化时,可以使用此属性来指示 nvstreammux 的正确帧率,例如,当管道中 nvstreammux 之前存在 audiobuffersplit GstElement 时。如果设置为 -1 (GST_CLOCK_TIME_NONE),则禁用基于帧率的 NTP 时间戳校正。(默认)
无符号 Integer64,0 到 18446744073709551615
frame-duration=10
drop-pipeline-eos
用于控制当所有 sink pad 都处于 EOS 状态时,EOS 从 nvstreammux 向下游传播的布尔属性。(实验性)
布尔值
drop-pipeline-eos=0(dGPU/Jetson 的默认值)
下表讨论了默认 streammux 和新 streammux 在 GStreamer 插件属性方面的差异
Gst-nvstreammux 与默认 nvstreammux 的差异# 默认 nvstreammux 属性
新 nvstreammux 属性
batch-size
batch-size
num-surfaces-per-frame
num-surfaces-per-frame
batched-push-timeout
batched-push-timeout
width
N/A;缩放和颜色转换支持已弃用。
height
N/A;缩放和颜色转换支持已弃用。
enable-padding
N/A;缩放和颜色转换支持已弃用。
gpu-id
N/A;加速缩放和颜色转换支持已弃用。
live-source
已弃用
nvbuf-memory-type
N/A
buffer-pool-size
N/A
attach-sys-ts
attach-sys-ts
N/A
config-file-path
sync-inputs
sync-inputs
max-latency
max-latency
Mux 配置属性#
下表总结了有关 Streammux 配置文件组和键的详细信息。
Gst-nvstreammux 配置文件属性# 组
config-key
描述
[属性]
algorithm-type
定义批处理算法;uint
1:如果所有源都具有相同的优先级键设置,则为轮询。否则,将批处理优先级较高的流,直到没有来自它们的更多缓冲区为止。
默认值:1
batch-size
所需的批处理大小;uint。此值将覆盖 nvstreammux 的插件属性和 DS 配置文件键“batch-size”
如果在配置文件中未指定批处理大小,则插件属性批处理大小应覆盖默认值。
默认值:1(如果 adaptive-batching=1,则为 == 源数量)
overall-max-fps-n
所需总体 muxer 输出最大帧率 fps_n/fps_d 的分子;uint
默认值:120/1 注意:即使 max-fps-control=0,也需要将此值配置为 >= overall-min-fps 的值。
overall-max-fps-d
所需总体 muxer 输出最大帧率 fps_n/fps_d 的分母;uint
overall-min-fps-n
所需总体 muxer 输出最小帧率 fps_n/fps_d 的分子;uint
默认值:5/1
overall-min-fps-d
所需总体 muxer 输出最大帧率 fps_n/fps_d 的分母;uint
max-same-source-frames
每个输出批处理缓冲区允许复用的任何流的帧的最大数量;uint
将使用此值和键 (max-num-frames-per-batch) 的最小值。
默认值:1
adaptive-batching
启用 (1) 或禁用 (0) 自适应批处理;uint
默认值:1 如果启用,则 batch-size == 源数量 X num-surfaces-per-frame。
max-fps-control
启用 (1) 或禁用 (0) 基于 overall-max-fps-n/d 配置控制 nvstreammux 推送批处理缓冲区的最大帧率。默认值:0
[source-config-N]
max-fps-n
此源的最大帧率 fps_n/fps_d 的分子。已弃用(将在下一个版本中删除支持)。请改用 overall-max-fps;uint
默认值:60/1
max-fps-d
此源的最大帧率 fps_n/fps_d 的分母。已弃用(将在下一个版本中删除支持)。请改用 overall-max-fps。;uint
min-fps-n
此源的最小帧率 fps_n/fps_d 的分子。已弃用(将在下一个版本中删除支持)。请改用 overall-min-fps;uint
min-fps-d
此源的最小帧率 fps_n/fps_d 的分母。已弃用(将在下一个版本中删除支持)。请改用 overall-min-fps;uint
priority
此流的优先级。已弃用(将在下一个版本中删除支持)。请改用 algorithm-type;uint
默认值:0(最高优先级)值越高,优先级越低。
max-num-frames-per-batch
每个输出批处理缓冲区允许复用的此流的帧的最大数量;uint
将使用此值和键 (max-same-source-frames) 的最小值。
针对特定用例的 NvStreamMux 调优解决方案#
目标#
nvstreammux 提供了许多旋钮来调整批处理算法的工作方式。这对于支持 muxer 支持的各种应用程序/用例至关重要。更多文档请参见 Mux 配置属性。
针对我们与客户合作的特定用例调优 nvstreammux 是很好的学习练习。
此处讨论的详细信息包括观察结果、配置、管道更改等,这些对于特定用例效果良好。
用户/贡献者 - 请随时在此处创建一个 新的论坛主题。
重要的调优参数#
为确保流畅的流式传输体验,请正确配置/调整以下参数。
Gst-nvstreammux 调优参数# 使用的调优用例或 Mux 配置属性
注释
nvstreammux/sync-inputs
sync-inputs=1 确保 nvstreammux 对早期缓冲区进行排队。这在音频 muxer 中可能很有用,当从文件读取时,音频 muxer 可能比视频 muxer 快,因为音频帧比视频帧轻。
nvstreammux/config-file-path
min-overall-fps 和 max-overall-fps 需要正确设置。
min-overall-fps 应设置为所有源的最高帧率。
b) max-overall-fps 应 >= min-overall-fps 查看 Mux 配置属性 以获取更多信息。
nvstreammux/max-latency
请将延迟参数设置为大于最慢流的 1/fps 的值。仅在 sync-inputs=1 时适用
具有不同帧率的输入
最高帧率要考虑用于 overall-min-fps 值。例如,对于每个具有 15fps 和 30fps 的 2 个输入,overall-min-fps=30
具有可变帧率的输入
单个流的帧率可能因网络状况而异。最高可能帧率要考虑用于 overall-min-fps 值。例如,对于帧率在 15fps 到 30fps 之间变化的单个流,overall-min-fps=30
具有不同比特率的输入
Nvstreammux 不需要针对各个流比特率进行特定处理。
具有不同分辨率的输入
请阅读 异构批处理 部分
动态添加/删除输入流
自适应批处理支持此功能。使用 adaptive-batching=1,Gst 应用程序需要动态创建/销毁 sinkpad 以分别进行添加/删除。
flvmux/qtmux/latency
延迟参数(使用这些插件时的 Gst 属性)应设置为 > nvstreammux/max-latency 的值。建议值为 2 X nvstreammux/max-latency 用户可以设置 “latency=18446744073709551614”(最大值)以避免为此参数进行调优。
视频和音频复用用例#
当 nvstreammux 被馈送具有不同帧率的流时,需要进行调优以确保标准的 muxer 行为。下面的示例管道图说明了在视频和音频复用用例中使用常见组件(如 nvstreammux、nvstreamdemux、flv 或 qtmux 等)以供参考。
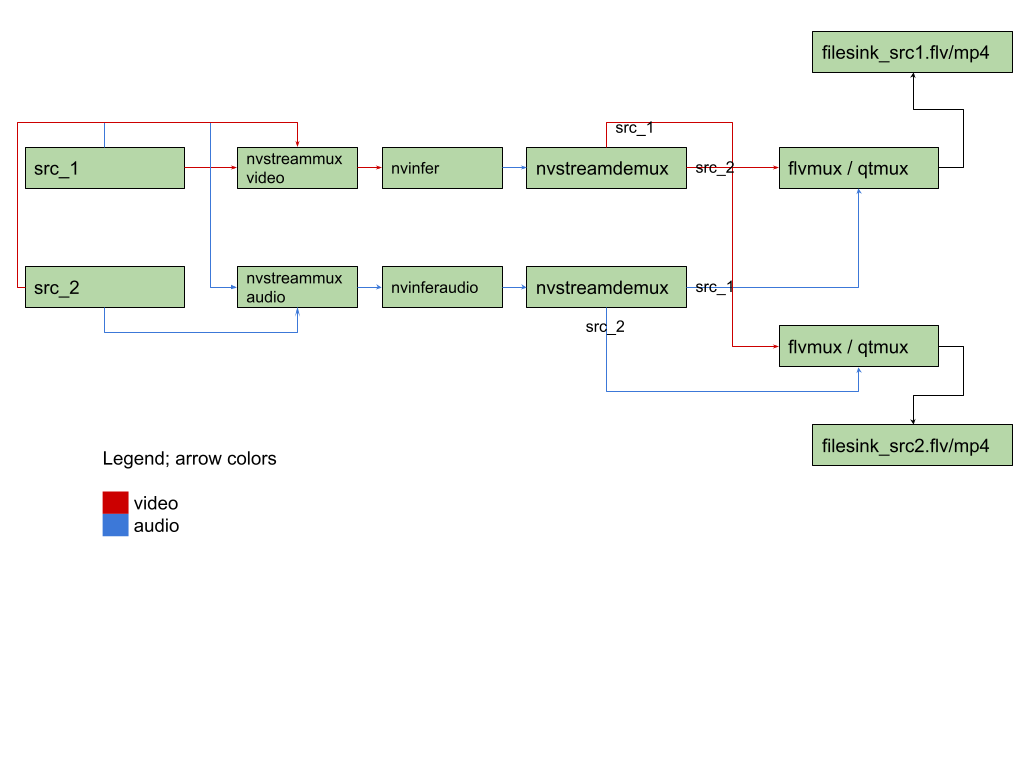
当同一管道包含两个 nvstreammux 模块以复用来自不同视频帧率的不同源的视频和音频时,根据源的类型,行为可能会有所不同。下面讨论了一些场景和推荐的调优指南。
视频和音频复用 - 不同 fps 的文件源#
在单个管道中,我们可能有具有不同视频帧率但音频帧率相同的文件源(对于大多数摄像机素材,为了节省带宽而降低视频帧率,同时保持不太重的音频采样率不变,这很典型)。
注意
在这种情况下,视频缓冲区的复用速度可能比音频缓冲区慢。当发生这种情况时,当视频和音频缓冲区时间戳之间的差异高于设置的“latency”参数时,基于 GstAggregator 的 flvmux 或 qtmux 可能会阻塞管道。
当处理不同帧率的文件源/实时源时,我们需要针对 min-overall-fps 调优 nvstreammux。如果没有这个,复用总是以最慢流的帧率发生,从而增加视频缓冲区的延迟。
当处理不同帧率的文件源和不同帧率的 RTMP 源时,我们建议用户打开 nvstreammux 上的 sync-inputs=1 并调优适当的 max-latency,以确保来自单个源的视频和音频缓冲区在 streammux 之后得到调节并一起在管道中流动。这对于基于 GstAggregator 的 muxer(如 flvmux、qtmux 等)的正常工作至关重要。
为确保流畅的流式传输体验,请正确配置/调整 重要调优参数 部分中讨论的参数。
视频和音频复用 - RTMP/RTSP 源#
当使用实时源时
确保
nvstreammux/sync-inputs设置为1当使用 RTMP 源时,内置的上游延迟查询不起作用。因此,您需要提供/调整非零 nvstreammux/max-latency 设置。
按照 重要调优参数 部分中讨论的参数,针对 nvstreammux/max-latency 和其他参数进行调优。
故障排除#
GstAggregator 插件 -> filesink 不会将数据写入文件#
要解决此问题,请尝试增加基于 GstAggregator 的 flvumx/qtmux “latency” 设置。尝试 latency=18446744073709551614 - 最大值,看看它是否有效,然后您可以根据正在使用的媒体源类型调整为最佳延迟。
此外,设置环境变量 export GST_DEBUG=3 以获取 WARNING 日志。另请参阅 nvstreammux WARNING “正在丢弃大量缓冲区”。
nvstreammux WARNING “正在丢弃大量缓冲区”#
要解决此问题,请尝试增加 max-latency 设置以允许延迟缓冲区。还要确保使用 nvstreammux 配置文件设置 min-overall-fps 和 max-overall-fps。
通过 nvstreammux 和 nvstreamdemux 的元数据传播#
有关通过 nvstreammux 的 NvDsMeta 传播和示例代码,请参阅以下位置提供的 deepstream 参考应用程序:/opt/nvidia/deepstream/deepstream/sources/apps/sample_apps/deepstream-gst-metadata-test/
nvstreammux 输入和输出处的 GstMeta 说明

说明 GstMeta 和 NvDsMeta 如何在 nvstreammux 之后作为批处理缓冲区的 NvDsBatchMeta 上的 NvDsUserMeta 复制。
注意
相同的说明也适用于 nvstreamdemux 之后的解复用 GstBuffer 上可用的 NvDsBatchMeta。唯一的区别是 GstMeta 将不再作为 NvDsUserMeta 提供 - 而是直接复制到解复用的 GstBuffer 上。
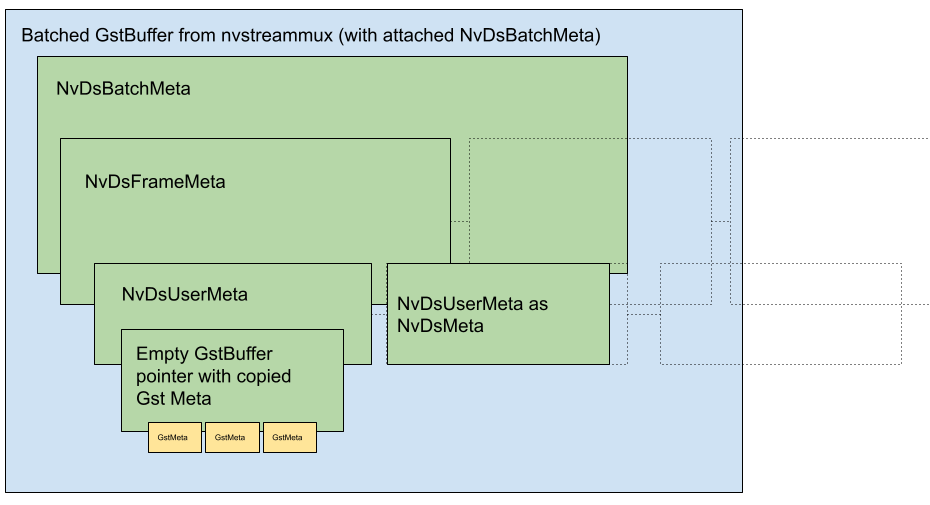
nvstreammux 输入和输出处的 GstMeta 说明

在 nvstreammux 之前向缓冲区添加 GstMeta#
用户可以在 nvstreammux sink pad 上添加探针,并将 GstMeta 附加到流入 nvstreammux 的 GstBuffer。附加到推送到 nvstreammux sink pad 中的 GstBuffer 的 GstMeta 将被复制并可用
在 nvstreamdemux 之后,作为解复用输出 GstBuffer 上的 GstMeta。
在 nvstreammux 之后,作为批处理 GstBuffer 的 NvDsBatchMeta->NvDsFrameMeta->user_meta_list 上的 NvDsUserMeta。
访问 nvstreammux 之后的 GstMeta。#
nvstreammux 处输入 GstBuffer 上的 GstMeta 将被复制到输出批处理缓冲区的 NvDsBatchMeta 中。
在 nvstreammux 源 pad 上使用附加的 GStreamer 探针函数或下游插件取消引用 NvDsBatchMeta 的参考代码如下
#include "gstnvdsmeta.h"
static GstPadProbeReturn
mux_src_side_probe_video (GstPad * pad, GstPadProbeInfo * info,
gpointer u_data)
{
GstBuffer *buf = (GstBuffer *) info->data;
NvDsBatchMeta *batch_meta = gst_buffer_get_nvds_batch_meta (buf);
if (batch_meta == nullptr) {
/** Every buffer out of nvstreammux will have batch_meta */
return GST_PAD_PROBE_OK;
}
/** Now make sure NvDsBatchMeta->NvDsFrameMeta->user_meta_list
* has the user meta with meta_type == NVDS_BUFFER_GST_AS_FRAME_USER_META */
for(GList* nodeFrame = batch_meta->frame_meta_list; nodeFrame; nodeFrame = g_list_next(nodeFrame)) {
NvDsFrameMeta* frame_meta = static_cast<NvDsFrameMeta*>(nodeFrame->data);
//Uncomment below line when using nvstreammux to batch audio buffers
//NvDsAudioFrameMeta* frame_meta = static_cast<NvDsAudioFrameMeta*>(nodeFrame->data);
NvDsMetaList* l_user_meta;
for (l_user_meta = frame_meta->frame_user_meta_list; l_user_meta != NULL;
l_user_meta = l_user_meta->next) {
NvDsUserMeta* user_meta = (NvDsUserMeta *) (l_user_meta->data);
if(user_meta->base_meta.meta_type == NVDS_BUFFER_GST_AS_FRAME_USER_META)
{
/** dereference the empty GstBuffer with GstMeta copied */
GstBuffer* meta_buffer = (GstBuffer*)user_meta->user_meta_data;
gpointer state = NULL;
GstMeta *gst_meta = NULL;
while ((gst_meta = gst_buffer_iterate_meta (meta_buffer, &state)))
{
/**
* Note to users: Here, your GstMeta will be accessible as gst_meta.
*/
}
}
}
}
return GST_PAD_PROBE_OK;
}
在 nvstreammux 之后添加 GstMeta#
用户可以将 GstMeta 添加到每个源的批处理帧中,添加到与源帧对应的 NvDsFrameMeta->user_meta_list 中。
将所有 GstMeta 复制到新创建的空 GstBuffer 中,并利用 /opt/nvidia/deepstream/deepstream/sources/includes/gstnvdsmeta.h (/opt/nvidia/deepstream/deepstream/lib/libnvdsgst_meta.so) 中提供的 API
对于视频:
nvds_copy_gst_meta_to_frame_meta()对于音频:
nvds_copy_gst_meta_to_audio_frame_meta()
访问 nvstreamdemux.src_pad 之后的 NvDsMeta#
在 nvstreamdemux.src_pad 上使用附加的 GStreamer 探针函数或下游插件访问 NvDsMeta 的参考代码如下
static GstPadProbeReturn demux_src_side_probe_audio (GstPad * pad, GstPadProbeInfo * info, gpointer u_data) { GstBuffer *buf = (GstBuffer *) info->data; GstMeta* gst_meta = nullptr; bool got_NVDS_BUFFER_GST_AS_FRAME_USER_META = false; bool got_NVDS_DECODER_GST_META_EXAMPLE = false; NvDsBatchMeta *batch_meta = gst_buffer_get_nvds_batch_meta (buf); fail_unless(batch_meta != nullptr); /** Now make sure every NvDsBatchMeta->NvDsFrameMeta->user_meta_list * has the GST_META user meta */ for(GList* nodeFrame = batch_meta->frame_meta_list; nodeFrame; nodeFrame = g_list_next(nodeFrame)) { NvDsAudioFrameMeta* frame_meta = static_cast<NvDsAudioFrameMeta*>(nodeFrame->data); NvDsMetaList* l_user_meta; for (l_user_meta = frame_meta->frame_user_meta_list; l_user_meta != NULL; l_user_meta = l_user_meta->next) { NvDsUserMeta* user_meta = (NvDsUserMeta *) (l_user_meta->data); if(user_meta->base_meta.meta_type == NVDS_BUFFER_GST_AS_FRAME_USER_META) { got_NVDS_BUFFER_GST_AS_FRAME_USER_META = true; g_print("got NVDS_BUFFER_GST_AS_FRAME_USER_META\n"); } } } /** We expect gstMeta in both user_meta and directly * as GST_META on the buffer */ gpointer state = NULL; /** make sure Gst Meta is copied on demux output buffer */ while ((gst_meta = gst_buffer_iterate_meta (buf, &state))) { /*Note to users: Here, your GstMeta will be accessible as gst_meta*/ } return GST_PAD_PROBE_OK; }
级联复用#
新的 streammux 支持批处理批处理缓冲区或级联复用器,以及由解复用器对音频/视频进行适当的解批处理。
示例管道
mux1(batch-size 2) + mux2(batch-size2) > mux3 (batch-size4)
mux1(batch-size 2) > mux1 (batch-size2) > demuxer
下表总结了级联用例的预期 nvstreammux 配置的重要注意事项
Gst-nvstreammux 级联预期配置# 序号
配置属性
注意
1
nvstreammux pad 索引。
mux.sink_%d
注意:用户负责维护单个管道中唯一的 pad_indexes。pad_indexes 由应用程序在请求 nvstreammux 实例上执行原始流批处理的 sink pad 时分配。
此唯一 pad_index(转换为 NvDsFrameMeta->stream_id)是为了避免重复的 pad_indexes 和 source_ids。
2
自适应批处理
注意:对于来自另一个实例的下游 nvstreammux 实例,需要关闭自适应批处理(默认情况下为 ON)。当串联使用多个 nvstreammux 实例(批处理批处理缓冲区)时,可以使用 nvstreammux config-file-path 设置来完成此操作。
这是因为下游 nvstreammux 实例不知道有多少流附加到每个上游 muxer,我们要求用户相应地配置下游 muxer 的批处理大小
3
[属性] algorithm-type=1 batch-size=4 overall-max-fps-n=90 overall-max-fps-d=1 overall-min-fps-n=5 overall-min-fps-d=1 max-same-source-frames=1 Adaptive-batching=0
预期批处理已批处理缓冲区的 nvstreammux 实例的示例配置
此处的示例管道(带有级联的 nvstreammux 实例:m1、m2、m3)是:2 个源 ->m1 2 个源 ->m2 m1 -> m3 m2 -> m3 m3 -> demux
应用程序中特殊的 nvmessage/EOS 处理要求。
注意
只有管道中的最后一个 nvstreammux 实例才会发送 GST_EVENT_EOS。来自上游 nvstreammux 实例的 GST_EVENT_EOS 将在下游 nvstreammux 实例中处理,并且不会转发。
但是,如果应用程序利用来自 nvstreammux 的 nvmessage EOS,则应用程序必须确保在拆除管道之前从所有 nvstreammux 实例收到此消息。此处讨论的 nvmessage 是应用程序在总线回调上接收到的 GST_MESSAGE_ELEMENT 事件(用于解析此消息的 API 是:gst_nvmessage_is_stream_eos() 和 gst_nvmessage_parse_stream_eos())。
已知问题与解决方案和常见问题解答#
观察到视频和/或音频卡顿(低帧率)#
解决方案
当观察到卡顿或已知管道延迟为“非实时”时,您需要在 nvstreammux 上配置 max-latency 参数。
Sink 插件不应异步移动到 PAUSED#
解决方案
当在新版 GStreamer pipeline 中使用 nvstreammux 时,建议将 sink 元素配置为将插件属性 async 设置为 false。
根据应用程序的设计方式,async=1 可能会导致挂起。以下是用户可能使用 async=1 的方式。
示例 pipeline 图 (针对 n 个源)
BIN_BEFORE_MUX X n -> nvstreammux -> nvstreamdemux -> BIN_AFTER_DEMUX X n
BIN_BEFORE_MUX 是 [audiosource]
BIN_AFTER_MUX 是 [fakesink]
然而,这是由于应用程序的设计方式而需要的。推荐的示例 pipeline/应用程序设计
添加流和移除流操作应互斥。
添加流算法/步骤
创建 bin_before_muxer 和 bin_after_demuxer
将其添加到 pipeline
将其移动到 PLAYING 状态。
等待状态更改发生
移除流算法/步骤
将 mux 前和 demux 后的 bin 移动到 STATE_NULL 状态。
等待状态更改发生
从 pipeline 中移除 bin_before_muxer 和 bin_after_demuxer。
如果应用程序未提供 sink 元素在 PREROLL 阶段所需的缓冲区,则 sink 插件 async=1 会导致步骤 (1).(d) 阻塞。为了解决这个问题,sink 插件需要 async=0。
注意
如果应用程序设计能够在 (1).(c) 和 (1).(d) 之间提供缓冲区,则用户可以设置 async=1。
异构批处理#
与默认的 nvstreammux 不同,新的 nvstreammux 不会将批处理缓冲区转换/缩放到单一颜色格式/分辨率。一个批次可以包含来自不同流的不同分辨率和格式的缓冲区。因此,对于新的 mux,异构批处理缓冲区的单一分辨率是无效的。
当我们在 nvstreammux 和 nvstreamdemux 之间使用可能转换输入缓冲区的插件时(例如:更改批次中视频缓冲区的分辨率或颜色格式),我们需要在此转换插件中添加对异构查询处理的支持,以便在 CAPS 中实现正确的流式分辨率流程。以下是供参考的示例实现
static gboolean
gst_<transform_plugin>_query (GstBaseTransform *trans, GstPadDirection direction, GstQuery *query) {
GstTransform *filter;
filter = GST_TRANSFORM (trans);
if (gst_nvquery_is_update_caps(query)) {
guint stream_index;
const GValue *frame_rate = NULL;
GstStructure *str;
gst_nvquery_parse_update_caps(query, &stream_index, frame_rate);
str = gst_structure_new ("update-caps", "stream-id", G_TYPE_UINT, stream_index, "width-val", G_TYPE_INT,
filter->out_video_info.width, "height-val", G_TYPE_INT, filter->out_video_info.height, NULL);
if (frame_rate) {
gst_structure_set_value (str, "frame-rate", frame_rate);
}
return gst_nvquery_update_caps_peer_query(trans->srcpad, str);
}
return GST_BASE_TRANSFORM_CLASS (parent_class)->query (trans, direction, query);
}
解决方法
在没有查询实现的情况下,必须在每个 nvstreammux sink pad 之前添加 nvvideoconvert + capsfiler(强制所有连接到新 nvstreammux 的源具有相同的分辨率和格式)。这确保了异构 nvstreammux 批处理输出具有相同 CAPS(分辨率和格式)的缓冲区。
示例;视频用例
gst-launch-1.0 \
uridecodebin ! nvvideoconvert ! "video/x-raw(memory:NVMM), width=1920, height=1080, format=NV12" ! m.sink_0 \
uridecodebin ! nvvideoconvert ! "video/x-raw(memory:NVMM), width=1920, height=1080, format=NV12" ! m.sink_1 \
nvstreammux name=m batch-size=2 ! fakesink async=0
其中,固定的 CAPS:“1920 X 1080; NV12” 确保批次中的每个缓冲区都转换为相同的 CAPS。
示例;音频用例
gst-launch-1.0 \
uridecodebin ! audioconvert ! audioresample ! "audio/x-raw, format=S16LE, layout=interleaved, channels=1, rate=48000" ! m.sink_0 \
uridecodebin ! audioconvert ! audioresample ! "audio/x-raw, format=S16LE, layout=interleaved, channels=1, rate=48000" ! m.sink_1 \
nvstreammux name=m batch-size=2 ! fakesink async=0
其中,固定的 CAPS:“48kHz; mono S16LE 交错” 确保批次中的每个缓冲区都转换为相同的 CAPS。
自适应批处理#
nvstreammux 是否支持动态批处理?这是在我们最初不知道确切输入数量的用例的上下文中。一旦 pipeline 启动,输入可能会被连接/断开连接。
解决方案
是的,当 adaptive-batching=1 时,nvstreammux 支持动态批处理大小,[property] 组在 mux 配置文件中。当启用自适应批处理时,批处理大小等于 muxer 上的源 pad 数量。默认情况下,这是启用的。
有关更多信息,请参阅 Mux 配置属性。
优化 nvstreammux 配置以实现低延迟与计算#
您可能希望为计算资源 (GPU) 利用率比吞吐量更重要的用例进行设计。
另一方面,可能存在对最小 pipeline 延迟至关重要的用例。
以下指南旨在帮助调整 nvstreammux 配置参数(通过 nvstreammux 上的 config-file-path 属性传递),以实现最佳资源(计算)利用率和低 pipeline 延迟。
下表分享了推荐的配置参数。
用于低延迟与计算配置的 Gst-nvstreammux 配置文件参数# 针对低延迟优化的配置(示例)
针对计算利用率优化的配置
Pipeline 示例:32 X udpsrc ! rtpopus depay ! opusdec ! audiobuffersplit output-buffer-duration=1/50 ! queue ! mux.sink_%d nvstreammux name=mux ! queue ! nvdsaudiotemplate ! fakesink
[属性]
algorithm-type=1
batch-size= 32
max-fps-control=0
overall-max-fps-n=50
overall-max-fps-d=1
overall-min-fps-n=50
overall-min-fps-d=1
max-same-source-frames= 2
“Pipeline 示例
32 X udpsrc ! rtpopus depay ! opusdec ! audiobuffersplit output-buffer-duration=1/50 ! queue ! mux.sink_%d nvstreammux name=mux ! queue ! nvdsaudiotemplate ! Fakesink
[属性]
algorithm-type=1
batch-size= 32
max-fps-control=0
overall-max-fps-n=50
overall-max-fps-d=1
overall-min-fps-n= 40
overall-min-fps-d=1
max-same-source-frames= 1
此配置中可能存在部分批次。
部分批次是指批处理缓冲区中的缓冲区数量少于配置的批处理大小。(batchBuffer->numFilled < batchBuffer->batchSize)
配置为创建完全形成的批处理缓冲区。
完整批次是指批处理缓冲区具有配置的批处理大小数量的缓冲区。(batchBuffer->numFilled == batchBuffer->batchSize)
CPU 负载可能更高(因为我们在更高的整体帧速率下运行 nvstreammux 批处理算法)。
“CPU 负载针对输入流进入 nvstreammux 插件的速率进行了优化。”
注意 1:在这里,精确的 overall-max/min-fps 配置与来自 audiobuffersplit 的输入帧速率相匹配,确保了 nvstreammux 插件内部创建批次的最小延迟。
注意 2:因此,如果输入吞吐量偶尔下降(可能),来自 nvstreammux 的输出批处理缓冲区仍将以配置的 min-fps 创建。但是,该批次将是部分的(batchBuffer->numFilled 可能小于 batchBuffer->batchSize)。
注意 1:在这里,用户可以使用小于来自 audiobuffersplit 的输入帧速率的 overall-min-fps。这样,即使输入源(特别是通过网络流式传输时)在帧速率方面不足,nvstreammux 仍然有更多时间来创建完整批次(batchBuffer->numFilled == batchBuffer->batchSize)。
注意 3:我们鼓励用户在输入来自网络时使用 max-same-source-frames > 1 来控制抖动,并允许 nvstreammux 在其他源可能因抖动而不足时,从一个源批处理多个帧。
注意 4:用户可能需要确认使用 max-same-source-frames > 1 的插件消耗批次的行为。
示例:某些插件可能会引入额外的延迟。在这种情况下,用户可以配置 max-same-source-frames=1。
注意 2:max-same-source-frames=1 是一个很好的配置。max-same-source-frames > 1 仍然可以用于降低网络源的抖动影响。
下面的示例 pipeline 图说明了音频 pipeline 用例中常用 OSS 组件的使用,例如
udpsrc
audiodecoder
audiobuffersplit
udpsink
以及 NVIDIA 组件,如 nvstreammux、nvdsaudiotemplate。
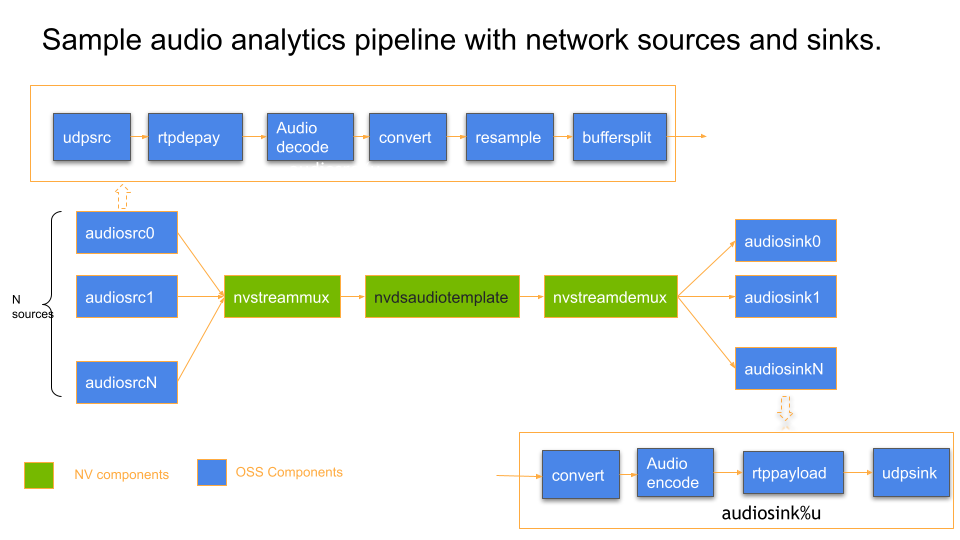
音频延迟测量 API 使用指南#
对于视频缓冲区的延迟测量,请参考 deepstream 参考应用程序实现在 /opt/nvidia/deepstream/deepstream/sources/apps/sample_apps/deepstream-app/deepstream_app.c 中 latency_measurement_buf_prob() 探针函数的使用。
假设一个音频 pipeline,例如
32 X udpsrc ! rtpopusdepay ! opusdecode ! audiobuffersplit output-buffer-duration=1/50 ! queue ! mux.sink_%d nvstreammux name=mux ! queue ! nvdsaudiotemplate ! fakesink
您可能想要测量每个缓冲区从解码时刻到到达 pipeline 中最终 sink 插件的时间之间的延迟。在本例中,是从 opusdecode 源 pad(输出)到 fakesink sink pad(输入)的延迟。
要做到这一点,
按照 此处的文档,在 opusdecode 源 pad 上以编程方式添加 GStreamer 缓冲区探针。
在探针内部,调用 DeepStream API
nvds_add_reference_timestamp_meta(),位于 /opt/nvidia/deepstream/deepstream/sources/includes/nvds_latency_meta.h伪代码参考
static GstPadProbeReturn probe_on_audiodecoder_src_pad (GstPad * pad, GstPadProbeInfo * info, gpointer u_data) { GstBuffer *buf = (GstBuffer *) info->data; /* frame_id/frame_num is passed 0 and ignored here. * Its assigned and available in NvDsFrameMeta by nvstreammux; * Thus not required in this pipeline where nvstreammux is used. */ nvds_add_reference_timestamp_meta(buf, "audiodecoder", 0); return GST_PAD_PROBE_OK; }接下来,按照 此处的文档,在 fakesink 的 sink pad 上添加探针。
在此探针内部,使用
API nvds_measure_buffer_latency()。伪代码参考
static GstPadProbeReturn probe_on_fakesink_sink_pad (GstPad * pad, GstPadProbeInfo * info, gpointer u_data) { GstBuffer *buf = (GstBuffer *) info->data; GstMapInfo map_info = {0}; gboolean ok = gst_buffer_map(buf, &map_info, GST_MAP_READ); fail_unless(ok == TRUE); NvBufAudio* bufAudio = (NvBufAudio*)map_info.data; NvDsBatchMeta *batch_meta = gst_buffer_get_nvds_batch_meta (buf); fail_unless(batch_meta != nullptr); gst_buffer_unmap(buf, &map_info); if(nvds_enable_latency_measurement) { NvDsFrameLatencyInfo* latency_info = (NvDsFrameLatencyInfo*)g_malloc0(sizeof(NvDsFrameLatencyInfo) * batch_meta->max_frames_in_batch); int num_sources_in_batch = nvds_measure_buffer_latency(buf, latency_info); for(int i = 0; i < num_sources_in_batch; i++) { /** Following are the details to profile */ g_print("Source id = %d Frame_num = %d Frame latency = %lf (ms) \n", latency_info[i].source_id, latency_info[i].frame_num, latency_info[i].latency); } } return GST_PAD_PROBE_OK; }注意
延迟测量依赖于添加到每个批处理缓冲区 post
nvstreammux的NvDsUserMetaNvDsBatchMeta。此元数据以及延迟测量支持在 GStreamer pipeline 中的nvstreammux实例之后到nvstreamdemux实例之前可用。
在旧版和新版 streammux 之间切换时,gst-inspect 未正确更新#
删除默认存在于主目录中的 gstreamer 缓存 (rm ~/.cache/gstreamer-1.0/registry.x86_64.bin),然后对 streammux 插件重新运行 gst-inspect。