Gst-nvinferserver#
Gst-nvinferserver 插件使用 NVIDIA® Triton Inference Server(之前称为 TensorRT Inference Server)Release 2.49.0、NGC Container 24.08 在 Jetson 和 x86 上的 dGPU 上执行推理。请参阅以下 README triton-inference-server/server。该插件接受来自上游的批量 NV12/RGBA 缓冲区。NvDsBatchMeta 结构必须已附加到 Gst 缓冲区。
底层库 (libnvds_infer_server) 可处理任何 NV12 或 RGBA 缓冲区。Gst-nvinferserver 插件将输入的批量缓冲区传递给底层库,并等待结果可用。同时,它会持续将接收到的输入缓冲区排队到底层库。一旦底层库的结果可用,插件就会转换结果并将其附加回 Gst-buffer 以供下游插件使用。
底层库预处理转换后的帧(执行颜色转换和缩放、归一化和均值减法),并生成最终的 FP32/FP16/INT8/UINT8/INT16/UINT16/INT32/UINT32 RGB/BGR/GRAY planar/ 打包数据,这些数据将传递给 Triton 以进行推理。底层库生成的输出类型取决于网络类型。
预处理函数为
y = netscalefactor * (x - mean)
其中
x是输入像素值。它是一个 uint8,范围为 [0,255]。mean是相应的均值,可以从均值文件中读取,也可以作为 offsets[c] 读取,其中 c 是输入像素所属的通道,offsets 是配置文件中指定的数组。它是一个浮点数。netscalefactor是配置文件中指定的像素缩放因子。它是一个浮点数。y是相应的输出像素值。它可以是float / half / int8 / uint8 / int16 / uint16 / int32 / uint32类型。以 uint8 到 int8 转换为例。设置
netscalefactor = 1.0和mean = [128, 128, 128]。那么函数看起来像y = (1.0) * (x - 128)
Gst-nvinferserver 当前适用于以下类型的网络
多类对象检测
多标签分类
分割
Gst-nvinferserver 插件可以在三种处理模式下工作
主模式:对完整帧进行操作。
辅助模式:对上游组件添加到元数据中的对象进行操作。
当插件作为辅助分类器在 async 模式下与跟踪器一起运行时,它会尝试通过避免在每帧中对相同对象进行重新推理来提高性能。它通过使用对象的唯一 ID 作为键将分类输出缓存在映射中来实现这一点。仅当对象首次出现在帧中(基于其对象 ID)或当对象的大小(边界框区域)增加 20% 或更多时,才会对对象进行推理。只有在添加跟踪器作为上游元素时,此优化才有可能实现。
预处理张量输入模式:对上游组件附加的张量进行操作。
当在预处理张量输入模式下运行时,Gst-nvinferserver 内部的预处理将完全跳过。插件查找附加到输入缓冲区的
GstNvDsPreProcessBatchMeta,并将张量按原样传递给 Tirton Inference Server,而无需进行任何修改。此模式当前支持对完整帧和 ROI 进行处理。GstNvDsPreProcessBatchMeta 由 Gst-nvdspreprocess 插件附加。通过在 InferenceConfig 消息中添加 input_tensor_from_meta 配置消息来启用此模式。
Triton Inference Server 的详细文档请访问:triton-inference-server/server
该插件支持 Triton 功能以及多种深度学习框架,例如 TensorRT、TensorFlow (GraphDef / SavedModel)、ONNX 和 PyTorch(在 Tesla 平台上)。在 Jetson 上,它还支持 TensorRT 和 TensorFlow (GraphDef / SavedModel)。TensorFlow 和 ONNX 可以配置 TensorRT 加速。有关详细信息,请参阅 框架特定优化。该插件需要一个可配置的模型仓库根目录路径,所有模型都需要驻留在该路径下。单个进程中的所有插件实例必须共享相同的模型根目录。有关详细信息,请参阅 模型仓库。每个模型还需要在其子目录中有一个特定的 config.pbtxt 文件。有关详细信息,请参阅 模型配置。该插件支持 Triton 集成模式,使用户能够使用 Triton 自定义后端执行预处理或后处理。该插件还支持自定义函数的接口,用于解析对象检测器、分类器的输出,以及在存在多个输入层的情况下初始化非图像输入层。有关自定义模型自定义方法实现的更多信息,请参阅 sources/includes/nvdsinfer_custom_impl.h。
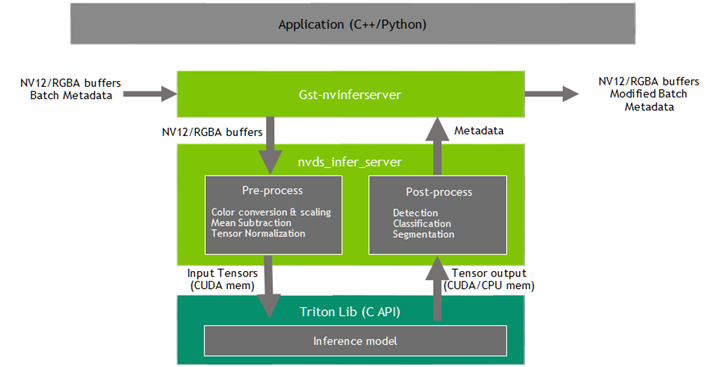
下游组件接收 Gst 缓冲区,其中包含未修改的内容以及从 Gst-nvinferserver 插件的推理输出创建的元数据。该插件可用于级联推理。也就是说,它可以直接对输入数据执行主推理,然后对主推理的结果执行辅助推理,依此类推。这与 Gst-nvinfer 类似,更多详细信息请参阅 Gst-nvinfer。
输入和输出#
本节总结了 Gst-nvinferserver 插件的输入、输出和通信工具。
输入
Gst 缓冲区
NvDsBatchMeta(附加 NvDsFrameMeta)
模型仓库目录路径 (model_repo.root)
gRPC 端点 URL (grpc.url)
运行时模型文件,在模型仓库中包含 config.pbtxt 文件
控制参数
Gst-nvinferserver 从配置文件获取控制参数。您可以通过设置属性 config-file-path 来指定此文件。有关详细信息,请参阅 Gst-nvinferserver 配置文件规范。可以通过 GObject 属性设置的其他控制参数包括
批大小
处理模式
唯一 ID
基于 GIE ID 进行推理和操作类 ID [仅限辅助模式]
推理间隔
原始输出生成回调函数
通过 GObject 属性设置的参数将覆盖 Gst-nvinferserver 配置文件中的参数。
输出
Gst 缓冲区
根据网络类型和配置的参数,可能输出以下一项或多项
NvDsObjectMeta
NvDsClassifierMeta
NvDsInferSegmentationMeta
NvDsInferTensorMeta
Gst-nvinferserver 配置文件规范#
Gst-nvinferserver 配置文件使用 https://developers.google.com/protocol-buffers 中描述的 prototxt 格式。
此配置文件的 protobuf 消息结构由 nvdsinferserver_plugin.proto 和 nvdsinferserver_config.proto 定义。所有基本数据类型值都根据 protobuf 指南设置为 0 或 false。Map、数组和 oneof 默认设置为空。有关每个消息定义的更多详细信息,请参阅。
nvdsinferserver_plugin.proto中的消息 PluginControl 是此配置文件的入口点。消息 InferenceConfig 配置
libnvds_infer_server的底层设置。消息 PluginControl::InputControl 配置模型推理的输入缓冲区、对象过滤策略。
消息 PluginControl::OutputControl 配置检测和原始张量元数据的推理输出策略。
消息 BackendParams 在 InferenceConfig 中配置后端输入/输出层和 Triton 设置。
消息 PreProcessParams 在 InferenceConfig 中配置网络预处理信息。
消息 InputTensorFromMeta 启用预处理张量输入模式,并在 InferenceConfig 中配置输入张量信息。
消息 PostProcessParams 在 InferenceConfig 中配置输出张量解析方法,例如检测、分类、语义分割等。
proto 文件中还定义了其他消息(例如 CustomLib、ExtraControl)和枚举类型(例如 MediaFormat、TensorOrder 等),用于 InferenceConfig 和 PluginControl 的其他设置。
特性#
下表总结了插件的特性。
特性 |
dGPU |
Jetson |
版本 |
|---|---|---|---|
Gst-nvinferserver 在主机上运行 |
否 |
是 |
DS 5.0 |
在 Docker 镜像上运行 |
是 |
是 (DS 6.0) |
DS 5.0 |
DS 预处理:网络输入格式:RGB/BGR/Gray |
是 |
是 |
DS 5.0 |
DS 预处理:网络输入数据类型 FP32/FP16/UINT8/INT8/UINT16/INT16/UINT32/INT32 |
是 |
是 |
DS 5.0 |
DS 预处理:网络输入张量顺序 NCHW / NHWC |
是 |
是 |
DS 5.0 |
内存:用于输入张量的 Cuda(GPU) 缓冲区共享 |
是 |
是 |
DS 5.0 |
内存:用于输出张量的 Cuda 内存(GPU / CPU 锁页内存) |
是 |
是 |
DS 5.0 |
后端:TensorRT 运行时(plan 引擎文件) |
是 |
是 |
DS 5.0 |
后端:Tensorflow 运行时 CPU/GPU (graphdef/savedmodel) |
是 |
是 |
DS 5.0 |
后端:使用 TF-TRT 加速的 Tensorflow 运行时 |
是 |
是 |
DS 5.0 |
后端:ONNX 运行时 |
是 |
是 (DS 6.0) |
DS 5.0 |
后端:使用 ONNX-TRT 加速的 ONNX 运行时 |
是 |
是 (DS 6.0) |
DS 5.0 |
后端:Pytorch 运行时 |
是 |
否 |
DS 5.0 |
后处理:DS 检测 / 分类 / 分割 |
是 |
是 |
DS 5.0 |
后处理:DS 检测聚类方法:NMS / GroupRectangle / DBSCan / None |
是 |
是 |
DS 5.0 |
后处理:自定义解析 (NvDsInferParseCustomTfSSD) |
是 |
是 |
DS 5.0 |
后处理:Triton 原生分类 |
是 |
是 |
DS 5.0 |
Triton 集成模式(Triton 预处理/后处理),具有指定的媒体格式(RGB/BGR/Gray),并以 Cuda GPU 缓冲区作为输入 |
是 |
是 |
DS 5.0 |
后处理:在 NvDsInferTensorMeta 中附加 Triton 原始张量输出,用于下游或应用程序后处理 |
是 |
是 |
DS 5.0 |
deepstream-app:pipeline 与 PGIE / SGIE / nvtracker 配合使用 |
是 |
是 |
DS 5.0 |
示例应用:deepstream-segmentation-test / deepstream-infer-tensor-meta-test |
是 |
是 |
DS 5.0 |
单批次和单流上的基本 LSTM 特性(beta 版本,配置文件将来版本可能会更改) |
是 |
是 |
DS 5.0 |
gRPC:Triton Server 作为独立进程运行,插件通过 gRPC 进行通信 |
是 |
是 |
DS 6.0 |
自定义处理接口 |
是 |
是 |
DS 6.0 |
gRPC:用于输入张量的与本地 Triton 服务器的 CUDA 缓冲区共享 |
是 |
是 |
DS 6.2 |
后处理:裁剪对象边界框以适应 ROI 内 |
是 |
是 |
DS 6.3 |
名称 |
描述 |
类型和范围 |
示例注释 |
网络类型 /
适用于 GIE
(主/辅)
|
|---|---|---|---|---|
infer_config |
底层 libnvds_infer_server 推理配置设置 |
InferenceConfig |
infer_config { … } 有关详细信息,请参阅 InferenceConfig |
全部 两者 |
input_control |
控制插件输入缓冲区、对象过滤策略以进行推理 |
PluginControl ::InputControl |
input_control{ process_mode: PROCESS_MODE_FULL_FRAME } 有关详细信息,请参阅 InputControl |
全部 两者 |
output_control |
控制插件推理后的输出元数据过滤策略 |
PluginControl ::OutputControl |
output_control { … } 有关详细信息,请参阅 OutputControl |
全部 两者 |
process_mode |
处理模式,从 PluginControl::ProcessMode 中选择。在 deepstream-app 中,PGIE 默认使用 PROCESS_MODE_FULL_FRAME,SGIE 默认使用 PROCESS_MODE_CLIP_OBJECTS |
enum PluginControl::ProcessMode |
process_mode: PROCESS_MODE_FULL_FRAME |
全部 两者 |
operate_on_gie_id |
GIE 的唯一 ID,此 GIE 将在其元数据(边界框)上进行操作 |
int32, >=0, 有效 gie-id。-1,禁用 gie-id 检查,对所有 GIE ID 进行推理 |
operate_on_gie_id: 1 |
全部 辅助 |
operate_on_class_ids |
父 GIE 的类 ID,此 GIE 将在其上进行操作 |
逗号分隔的 int32 数组 |
operate_on_class_ids: [1, 2] 对父 GIE 生成的类 ID 为 1、2 的对象进行操作 |
全部 辅助 |
interval |
指定要跳过推理的连续批次数。默认为 0 |
uint32 |
interval: 1 |
全部 主 |
async_mode |
启用对检测到的对象进行推理和异步元数据附加。仅当附加 tracker-ids 时才有效。在不等待推理结果的情况下将缓冲区向下游推送。在推理后附加元数据 |
bool |
async_mode: false |
分类器 辅助 |
object_control |
输入对象过滤器设置 |
PluginControl::InputObjectControl |
object_control { bbox_filter { min_width: 64 min_height: 64 } } 有关详细信息,请参阅 InputObjectControl |
全部 辅助 |
名称 |
描述 |
类型和范围 |
示例注释 |
网络类型 /
适用于 GIE
(主/辅)
|
|---|---|---|---|---|
process_mode |
处理模式,从 PluginControl::ProcessMode 中选择。在 deepstream-app 中,PGIE 默认使用 PROCESS_MODE_FULL_FRAME,SGIE 默认使用 PROCESS_MODE_CLIP_OBJECTS |
enum PluginControl::ProcessMode |
process_mode: PROCESS_MODE_FULL_FRAME |
全部 两者 |
operate_on_gie_id |
GIE 的唯一 ID,此 GIE 将在其元数据(边界框)上进行操作 |
int32, >=0, 有效 gie-id。-1,禁用 gie-id 检查,对所有 GIE ID 进行推理 |
operate_on_gie_id: 1 |
全部 辅助 |
operate_on_class_ids |
父 GIE 的类 ID,此 GIE 将在其上进行操作 |
逗号分隔的 int32 数组 |
operate_on_class_ids: [1, 2] 对父 GIE 生成的类 ID 为 1、2 的对象进行操作 |
全部 辅助 |
interval |
指定要跳过推理的连续批次数。默认为 0 |
uint32 |
interval: 1 |
全部 主 |
async_mode |
启用对检测到的对象进行推理和异步元数据附加。仅当附加 tracker-ids 时才有效。在不等待推理结果的情况下将缓冲区向下游推送。在推理后附加元数据 |
bool |
async_mode: false |
分类器 辅助 |
object_control |
输入对象过滤器设置 |
PluginControl::InputObjectControl |
object_control { bbox_filter { min_width: 64 min_height: 64 } } 有关详细信息,请参阅 InputObjectControl |
全部 辅助 |
secondary_reinfer_interval |
对象的重新推理间隔,以帧为单位 |
uint32 |
secondary_reinfer_interval: 90 |
全部 辅助 |
名称 |
描述 |
类型和范围 |
示例注释 |
网络类型 /
适用于 GIE
(主/辅)
|
|---|---|---|---|---|
output_tensor_meta |
启用附加推理输出张量元数据,仅主机支持张量缓冲区指针 |
bool |
output_tensor_meta: false |
全部
两者
|
detect_control |
指定检测输出过滤器策略 |
PluginControl::OutputDetectionControl |
detect_control { default_filter { bbox_filter { min_width: 32 min_height: 32 } } } 有关详细信息,请参阅 OutputDetectionControl |
检测器
两者
|
classifier_type |
在分类网络的情况下,要添加到 NvDsClassifierMeta 中的分类器类型 |
string |
classifier_type: multi_class_classification |
分类器
两者
|
名称 |
描述 |
类型和范围 |
示例注释 |
网络类型 /
适用于 GIE
(主/辅)
|
|---|---|---|---|---|
bbox_filter |
边界框过滤器 |
PluginControl::BBoxFilter |
bbox_filter { min_width: 32 min_height: 32 } 有关详细信息,请参阅 BBoxFilter |
全部 辅助 |
名称 |
描述 |
类型和范围 |
示例注释 |
网络类型 /
适用于 GIE (主/辅)
|
|---|---|---|---|---|
min_width |
边界框最小宽度 |
uint32 |
min_width: 64 |
全部 两者 |
min_height |
边界框最小高度 |
uint32 |
min_height: 64 |
全部 两者 |
max_width |
边界框最大宽度,默认为 0,将忽略 max_width |
uint32 |
max_width: 640 |
全部 两者 |
max_height |
边界框最大高度,默认为 0,将忽略 max_height |
uint32 |
max_height: 640 |
全部 两者 |
名称 |
描述 |
类型和范围 |
示例注释 |
网络类型 /
适用于 GIE (主/辅)
|
|---|---|---|---|---|
default_filter |
输出控制的默认检测过滤器 |
PluginControl::DetectClassFilter |
default_filter { bbox_filter { min_width: 32 min_height: 32 } } 有关详细信息,请参阅 DetectClassFilter |
全部 两者 |
specific_class_filters |
指定每个类的检测过滤器以替换默认过滤器 |
map<uint32, DetectClassFilter> |
specific_class_filters: [ { key: 1, value {…} }, { key: 2, value {…} } ] |
全部 两者 |
名称 |
描述 |
类型和范围 |
示例注释 |
网络类型 /
适用于 GIE (主/辅)
|
|---|---|---|---|---|
bbox_filter |
检测边界框过滤器 |
PluginControl::BBoxFilter |
bbox_filter { min_width: 64 min_height: 64 } |
检测
两者
|
roi_top_offset |
RoI 距帧顶部的偏移量。仅输出 RoI 内的对象。 |
uint32 |
roi_top_offset: 128 |
检测
两者
|
roi_bottom_offset |
RoI 距帧底部的偏移量。仅输出 RoI 内的对象。 |
uint32 |
roi_bottom_offset |
检测
两者
|
border_color |
指定检测边界框的边框颜色 |
PluginControl::Color |
border_color { r: 1.0 g: 0.0 b: 0.0 a: 1.0 } |
检测
两者
|
bg_color |
指定检测边界框的背景颜色 |
PluginControl::Color |
border_color { r: 0.0 g: 1.0 b: 0.0 a: 0.5 } |
检测
两者
|
名称 |
描述 |
类型和范围 |
示例注释 |
网络类型 /
适用于 GIE (主/辅)
|
|---|---|---|---|---|
r |
红色值 |
float 范围[0.0, 1.0] |
r: 0.5 |
全部
两者
|
g |
绿色值 |
float。范围[0.0, 1.0] |
g: 0.5 |
全部
两者
|
b |
蓝色值 |
float。范围[0.0, 1.0] |
b: 0.3 |
全部
两者
|
a |
Alpha 混合值 |
float。范围[0.0, 1.0] |
a: 1.0 |
全部
两者
|
底层 libnvds_infer_server.so 配置文件规范#
消息 InferenceConfig 定义 nvdsinferserver_config.proto 中的所有底层结构字段。它具有推理后端、网络预处理和后处理的主要设置。
名称 |
描述 |
类型和范围 |
示例注释 |
|
|---|---|---|---|---|
unique_id |
唯一 ID,用于标识由此 GIE 生成的元数据 |
uint32, ≥0 |
unique_id: 1 |
|
gpu_ids |
用于预处理/推理的 GPU 设备 ID(仅支持单 GPU) |
int32 数组, ≥0 |
gpu_ids: [0] |
|
max_batch_size |
在一个批次中一起推理的最大帧数/对象数 |
uint32, ≥0 |
max_batch_size: 1 |
|
backend |
推理后端设置 |
BackendParams |
|
|
preprocessing |
preprocess 或 input_tensor_from_meta 之一。如果使用帧或对象处理模式,则使用 preprocess;如果使用预处理张量输入模式,则使用 input_tensor_from_meta |
preprocess 或 input_tensor_from_meta |
|
|
preprocess |
网络预处理设置,用于颜色转换、缩放和归一化,适用于使用帧或对象处理模式时 |
PreProcessParams |
|
|
input_tensor_from_meta |
输入张量的配置,适用于使用预处理张量作为输入时 |
InputTensorFromMeta |
|
|
postprocess |
推理输出张量解析方法,例如检测、分类、语义分割等 |
PostProcessParams |
|
|
custom_lib |
指定自定义库路径,用于自定义解析函数和预加载,可选 |
CustomLib |
|
|
extra |
推理配置的额外控制。 |
ExtraControl |
|
|
lstm |
LSTM 控制参数,限制为批大小 1 和单流 |
LstmParams [可选] |
}`` 有关详细信息,请参阅 LstmParams |
|
clip_object_outside_roi |
裁剪对象边界框以使其适应指定的 ROI 边界内。 |
bool |
clip_object_outside_roi: false |
|
名称 |
描述 |
类型和范围 |
示例注释 |
网络类型/适用于 GIE (主/辅) |
|---|---|---|---|---|
inputs |
后端输入层设置,可选 |
InputLayer 数组 |
有关详细信息,请参阅 InputLayer |
全部/两者 |
outputs |
后端输出层设置,可选 |
OutputLayer 数组 |
有关详细信息,请参阅 OutputLayer |
全部/两者 |
triton |
Triton Inference Server 设置的后端 |
TritonParams |
有关详细信息,请参阅 TritonParams |
全部/两者 |
output_mem_type |
Triton 原生输出张量内存类型 |
MemoryType 从 [MEMORY_TYPE_DEFAULT, MEMORY_TYPE_CPU, MEMORY_TYPE_GPU] 中选择 |
output_mem_type: MEMORY_TYPE_CPU |
全部/两者 |
名称 |
描述 |
类型和范围 |
示例注释 |
网络类型 /
适用于 GIE (主/辅)
|
|---|---|---|---|---|
name |
输入张量名称 |
string |
name: “input_0” |
全部 两者 |
dims |
输入张量形状,可选。仅当后端无法确定固定输入形状时才需要 |
int32 数组, > 0 |
dims: [299, 299, 3] |
全部 两者 |
data_type |
枚举 TensorDataType,类型包括
通常可以从 Triton 模型 config.pbtxt 中推断出来 |
TensorDataType |
data_type: TENSOR_DT_FP32 |
全部 两者 |
名称 |
描述 |
类型和范围 |
示例注释 |
网络类型 /
适用于 GIE (主/辅)
|
|---|---|---|---|---|
name |
输出张量名称 |
string |
name: “detection_boxes” |
全部
两者
|
max_buffer_bytes |
输出张量保留缓冲区字节数 |
uint64 |
max_buffer_bytes: 2048 |
全部
两者
|
名称 |
描述 |
类型和范围 |
示例注释 |
网络类型 /
适用于 GIE (主/辅)
|
|---|---|---|---|---|
model_name |
Triton 推理模型名称 |
string |
model_name: “ssd_inception_graphdef” |
全部
两者
|
version |
Triton 模型版本号。-1,最新版本号。>0,为将来版本保留的特定版本号 |
int64 |
version: -1 |
全部
两者
|
model_repo |
Triton 模型仓库设置。注意,所有 model_repo 设置在单个进程中必须相同 |
TritonParams::TritonModelRepo |
model_repo { root: “../triton_model_repo” log_level: 2 } 详细信息请参考 TritonModelRepo |
全部
两者
|
grpc |
Triton gRPC 服务器设置。 |
TritonParams::TritonGrpcParams |
grpc { url: “localhost:8001” enable_cuda_buffer_sharing: false } 详细信息请参考 TritonGrpcParams |
全部
两者
|
名称 |
描述 |
类型和范围 |
示例注释 |
网络类型 /
适用于 GIE (主/辅)
|
|---|---|---|---|---|
root |
Triton 推理模型仓库目录路径 |
string |
root: “../triton_model_repo” |
全部
两者
|
log_level |
Triton 日志输出级别 |
uint32; 0, ERROR; 1, WARNING; 2, INFO; >=3, VERBOSE 级别 |
log_level: 1 |
全部
两者
|
strict_model_config |
启用 Triton 严格模型配置,详情请参考 Triton 生成的模型配置。建议设置为 true |
bool |
strict_model_config: true |
全部
两者
|
tf_gpu_memory_fraction |
每个进程的 TensorFlow GPU 内存分配比例。仅对 Tensorflow 模型有效。默认值 0 表示没有 GPU 内存限制。建议调整到一个合适的值(例如,在 [0.2, 0.6] 范围内),以防 Tensorflow 占用所有 GPU 内存 |
float, 范围 (0, 1.0] |
tf_gpu_memory_fraction: 0.6 |
全部
两者
|
tf_disable_soft_placement |
禁用 TensorFlow 运算符的软放置。默认情况下启用。 |
bool |
tf_disable_soft_placement: false |
全部
两者
|
min_compute_capacity |
指定最小 GPU 计算能力。x86 上的默认值为 6.0,Jetson 上的默认值为 5.0。 |
min_compute_capacity: 6.0 |
全部
两者
|
|
backend_dir |
指定 Triton 后端目录,其中存储 Tensorflow/Onnx/Pytorch 和自定义后端。X86 上的默认值为 /opt/tritonserver/backends,Jetson 上的默认值为 opt/nvidia/deepstream/deepstream-x.x/lib/triton_backends。 |
string |
backend_dir: /opt/tritonserver/backends/ |
全部
两者
|
cuda_device_memory |
指定带有预分配内存池的 CudaDeviceMem 块列表。如果列表为空,则使用 Triton 的默认值。 |
消息列表 |
} ] |
全部
两者
|
CudaDeviceMem::device |
指定设备 ID |
uint32; >= 0 |
device: 0 |
全部
两者
|
CudaDeviceMem::memory_pool_byte_size |
指示在相应设备上为 Triton 运行时预分配的内存池字节大小 |
uint64; >= 0 |
memory_pool_byte_size: 8000000000 |
全部
两者
|
pinned_memory_pool_byte_size |
指示在主机上为 Triton 运行时预分配的固定内存。如果未设置,则使用 Triton 的默认值(约 256MB)。 |
uint64; >= 0 |
pinned_memory_pool_byte_size: 128000000 |
全部
两者
|
backend_configs |
Tritonserver 后端配置设置的 BackendConfig 块列表 |
消息列表 |
} ] |
全部
两者
|
BackendConfig::backend |
指定后端名称 |
string |
backend: tensorflow |
全部
两者
|
BackendConfig::setting |
指定后端设置名称 |
string |
setting: “allow-soft-placement” |
全部
两者
|
BackendConfig::value |
指定后端设置值 |
string |
value: “true” |
全部
两者
|
名称 |
描述 |
类型和范围 |
示例注释 |
|
|---|---|---|---|---|
url |
Triton 服务器名称和端口 |
string |
url: “localhost:8001” |
|
enable_cuda_buffer_sharing |
|
|||
如果启用 |
输入 CUDA 缓冲区将与 Triton 服务器共享,以提高性能。 |
|||
此功能仅应在 Triton 服务器与应用程序在同一台机器上时启用。 |
||||
适用于 x86 dGPU 平台 |
Jetson 设备上不支持。 |
|||
默认情况下禁用,即在创建推理请求时,CUDA 缓冲区被复制到系统内存。” |
布尔值 |
enable_cuda_buffer_sharing: true |
|
名称 |
描述 |
类型和范围 |
示例注释 |
网络类型 /
适用于 GIE
(主/辅)
|
|---|---|---|---|---|
network_format |
枚举 MediaFormat,格式包括:MEDIA_FORMAT_NONE IMAGE_FORMAT_RGB IMAGE_FORMAT_BGR IMAGE_FORMAT_GRAY 。默认使用 IMAGE_FORMAT_RGB。 |
MediaFormat |
network_format: IMAGE_FORMAT_RGB |
全部 两者 |
tensor_order |
枚举 TensorOrder,排序类型包括:TENSOR_ORDER_NONE, TENSOR_ORDER_LINEAR(包括 NCHW, CHW, DCHW, … 排序), TENSOR_ORDER_NHWC。如果设置为 TENSOR_ORDER_NONE,则可以从后端层信息中推断出该值 |
TensorOrder |
tensor_order: TENSOR_ORDER_NONE |
全部 两者 |
tensor_name |
指定预处理缓冲区的张量名称。这适用于单个网络中有多个输入张量的情况。 |
字符串;
可选
|
tensor_name: “input_0” |
全部 两者 |
frame_scaling_hw |
用于缩放帧/对象裁剪到网络分辨率的计算硬件 |
枚举 FrameScalingHW FRAME_SCALING_HW_DEFAULT:平台默认值 – GPU (dGPU), VIC (Jetson) FRAME_SCALING_HW_GPU FRAME_SCALING_HW_VIC (仅限 Jetson) |
frame_scaling_hw: FRAME_SCALING_HW_GPU |
全部 两者 |
frame_scaling_filter |
用于缩放帧/对象裁剪到网络分辨率的滤波器 |
int32,有效值请参考 nvbufsurftransform.h 中的枚举 NvBufSurfTransform_Inter |
frame_scaling_filter: 1 |
全部 两者 |
maintain_aspect_ratio |
指示在缩放输入时是否保持宽高比。 |
int32; 0 或 1 |
maintain_aspect_ratio: 0 |
全部 两者 |
symmetric_padding |
指示在缩放输入时是否对称填充图像。默认情况下,DeepStream 会不对称地填充图像。 |
int32; 0 或 1 |
symmetric_padding: 0 |
全部 两者 |
normalize |
网络输入张量归一化设置,用于缩放因子、偏移量和均值减法 |
PreProcessParams::ScaleNormalize |
normalize { scale_factor: 1.0 channel_offsets: [0, 0, 0] } 详细信息请参考 PreProcessParams::ScaleNormalize |
名称 |
描述 |
类型和范围 |
示例注释 |
网络类型 /
适用于 GIE (主/辅)
|
|---|---|---|---|---|
scale_factor |
像素归一化因子 |
float |
scale_factor: 0.0078 |
全部
两者
|
channel_offsets |
要从每个像素中减去的颜色分量均值数组。数组长度必须等于帧中颜色分量的数量。插件会将均值乘以 scale_factor。 |
float 数组,可选 |
channel_offsets: [77.5, 21.2, 11.8] |
全部
两者
|
mean_file |
均值数据文件 (PPM 格式) 的路径名 |
字符串; 可选 |
mean_file: “./model_meanfile.ppm” |
全部
两者
|
名称 |
描述 |
类型和范围 |
示例注释 |
网络类型 /
适用于 GIE
(主/辅)
|
|---|---|---|---|---|
is_first_dim_batch |
布尔值,指示预处理的输入张量的第一维度是否为批次维度。对于批处理输入,设置为 true,否则设置为 false。 |
布尔值 |
is_first_dim_batch: true |
全部 预处理张量输入模式 |
名称 |
描述 |
类型和范围 |
示例注释 |
网络类型 /
适用于 GIE (主/辅)
|
|---|---|---|---|---|
labelfile_path |
包含模型标签的文本文件的路径名 |
string |
labelfile_path: “=/home/ubuntu/model_labels.txt” |
全部 两者 |
oneof process_type |
指示后处理类型之一:检测;分类;分割;其他; |
无 |
不适用 |
全部 两者 |
detection |
指定网络的检测参数。它必须是 process_type 之一 |
DetectionParams |
detection { num_detected_classes: 4 simple_cluster { threshold: 0.2 } } 详细信息请参考 DetectionParams |
检测器 两者 |
classification |
指定网络分类参数。它是 process_type 之一 |
ClassificationParams |
classification { threshold: 0.6 } 详细信息请参考 ClassificationParams |
分类器 两者 |
segmentation |
指定网络语义分割参数。它是 process_type 之一 |
SegmentationParams |
segmentation { threshold: 0.2 num_segmentation_classes: 2 } |
分割 两者 |
other |
指定其他网络参数。这适用于用户自定义网络,通常与 output_control.output_tensor_meta: true 共存。张量输出数据将附加到 GstBuffer 中。数据可以在应用程序中解析。如果需要更长时间地保存元数据,用户可以增加 extra.output_buffer_pool_size。它是 process_type 之一 |
OtherNetworkParams |
other {} 详细信息请参考 OtherNetworkParams |
其他 两者 |
triton_classification |
指定网络的 Triton 分类参数。它是 process_type 之一 |
TritonClassifyParams |
Triton_classification { topk: 1 } 详细信息请参考 TritonClassifyParams |
分类器 两者 |
名称 |
描述 |
类型和范围 |
示例注释 |
网络类型 /
适用于 GIE (主/辅)
|
|---|---|---|---|---|
num_detected_classes |
定义网络检测到的类别数量 |
int32, > 0 |
num_detected_classes:4 |
检测器 两者 |
per_class_params |
每个类别的特定检测参数映射。键值对遵循 <class_id: per_class_params> 顺序。 |
map<int32, PerClassParams>; 可选 |
per_class_params [ { key: 1, value { pre_threshold : 0.4} }, { key: 2, value { pre_threshold : 0.5} } ] 详细信息请参考 PerClassParams |
检测器 两者 |
custom_parse_bbox_func |
自定义边界框解析函数的名称。如果未指定,Gst-nvinferserver 将使用 SDK 提供的 resnet 模型的内部函数。如果指定,还需要设置 custom_lib 以加载自定义库。 |
字符串; |
custom_parse_bbox_func: “NvDsInferParseCustomTfSSD” |
检测器 两者 |
oneof clustering_policy |
指示聚类策略之一:nms;dbscan;group_rectangle;simple_cluster; |
无 |
不适用 |
检测器 两者 |
nms |
指示通过非极大值抑制方法对检测到的对象进行边界框聚类。它是 clustering_policy 之一 |
Nms |
nms { confidence_threshold: 0.3 iou_threshold: 0.4 } 详细信息请参考 Nms |
检测器 两者 |
dbscan |
指示通过 DBSCAN 方法对检测到的对象进行边界框聚类。它是 clustering_policy 之一 |
DbScan |
dbscan { pre_threshold: 0.3 eps: 0.7 min_boxes: 3 } 详细信息请参考 DbScan |
检测器 两者 |
group_rectangle |
指示通过 groupRectangles() 函数对检测到的对象进行分组矩形边界框聚类。它是 clustering_policy 之一 |
GroupRectangle |
group_rectangle { confidence_threshold: 0.2 group_threshold: 2 eps: 0.2 } |
检测器 两者 |
simple_cluster |
指示通过阈值检测异常框的简单聚类方法 |
SimpleCluster |
simple_cluster { threshold: 0.2 } |
检测器 两者 |
Gst-nvinferserver 消息 DetectionParams-PerClassParams 定义详情# 名称
描述
类型和范围
示例注释
pre_threshold
定义每个类别的置信度阈值
float
pre_threshold:0.3
检测器
两者
Gst-nvinferserver 消息 DetectionParams-Nms 定义详情# 名称
描述
类型和范围
示例注释
confidence_threshold
检测得分低于此阈值的将被拒绝
float
confidence_threshold:0.5
检测器
两者
iou_threshold
两个提议框之间的最大 IOU 得分,超过此得分后,置信度较低的提议框将被拒绝。
float
iou_threshold: 0.3
检测器
两者
topk
指定在 nms 后要保留的前 k 个检测结果
int32, >= 0
topk: 2; 值 0 表示保留所有结果。
检测器
两者
Gst-nvinferserver 消息 DetectionParams-DbScan 定义详情# 名称
描述
类型和范围
示例注释
pre_threshold
DBSCAN 聚类之前,检测得分低于此阈值的将被拒绝
float
pre_threshold:0.2
检测器
两者
eps
DBSCAN epsilon 值,用于控制重叠框的合并。
float
eps: 0.7
检测器
两者
min_boxes
DBSCAN 聚类中被视为对象的最小框数
int32, > 0
min_boxes: 3;
检测器
两者
min_score
DBSCAN 聚类中被视为对象的最小得分
float
min_score: 0.7
默认值为 0
检测器
两者
Gst-nvinferserver 消息 DetectionParams-GroupRectangle 定义详情# 名称
描述
类型和范围
示例注释
confidence_threshold
检测得分低于此阈值的将被拒绝
float
confidence_threshold:0.2
检测器
两者
group_threshold
OpenCV grouprectangles() 函数的矩形合并阈值
int32; >= 0
group_threshold: 1
检测器
两者
eps
Epsilon 值,用于控制重叠框的合并
float
eps: 0.2
检测器
两者
Gst-nvinferserver 消息 DetectionParams-SimpleCluster 定义详情# 名称
描述
类型和范围
示例注释
threshold
检测得分低于此阈值的将被拒绝
float
confidence_threshold:0.6
检测器
两者
Gst-nvinferserver 消息 ClassificationParams 定义详情# 名称
描述
类型和范围
示例注释
threshold
分类得分低于此阈值的将被拒绝
float
threshold: 0.5
分类器
两者
custom_parse_classifier_func
自定义分类器输出解析函数的名称。如果未指定,Gst-nvinfer 将使用内部解析函数,该函数使用 NCHW 张量顺序处理 softmax 层。用户可以在 Triton config.pbtxt 中重塑其他输出张量顺序为 NCHW,以运行内部解析。如果指定,还需要设置 custom_lib 以加载自定义库。
string
parse-classifier-func-name: “parse_bbox_softmax”
分类器
两者
Gst-nvinferserver 消息 SegmentationParams 定义详情# 名称
描述
类型和范围
示例注释
threshold
分割得分低于此阈值的将被拒绝
float
threshold: 0.5
分割
两者
num_segmentation_classes
分割网络的输出类别数
int32, >0
num_segmentation_classes: 2
分割
两者
custom_parse_segmentation_func
自定义分割输出解析函数的名称。如果未指定,Gst-nvinferserver 将使用 SDK 提供的 UNet 模型的内部函数。如果指定,用户还需要设置 custom_lib 以加载自定义库。
string
custom_parse_segmentation_func: “NvDsInferParseCustomPeopleSemSegNet”
分割
两者
Gst-nvinferserver 消息 OtherNetworkParams 定义详情# 名称
描述
类型和范围
示例注释
type_name
指定用户自定义的网络名称
字符串; | 可选
type_name: “face”
其他
两者
Gst-nvinferserver 消息 TritonClassifyParams 定义详情# 名称
描述
类型和范围
示例注释
topk
指定需要从 Triton 的原生分类中保留的前 k 个元素
uint32; >=0
topk : 1 值 0 或空将保留前 1 个结果。
分类器
两者
threshold
分类得分低于此阈值的将被拒绝
float
threshold: 0.5
分类器
两者
Gst-nvinferserver 消息 CustomLib 定义详情# 名称
描述
类型和范围
示例注释
path
指向要预加载的自定义库的路径名
string
path: “/home/ubuntu/lib_custom_impl.so”
全部
两者
Gst-nvinferserver 消息 ExtraControl 定义详情# 名称
描述
类型和范围
示例注释
copy_input_to_host_buffers
启用后复制输入。如果启用,输入张量将作为 NvDsInferTensorMeta 附加到 GstBuffer 中,同时输出张量也一起附加,张量数据将复制到主机缓冲区。
bool
copy_input_to_host_buffers: false
全部
两者
output_buffer_pool_size
指定每个输出张量的缓冲区池大小。当指定 infer_config.postprocess.other 或启用 output_control.output_tensor_meta 时,输出张量将作为 NvDsInferTensorMeta 附加到 GstBuffer 中
int32; 范围 [2, 10]
output_buffer_pool_size: 4
全部
两者
custom_process_funcion
用于创建特定用户自定义处理器 IInferCustomProcessor 的自定义函数。函数符号由 infer_config.custom_lib 加载
字符串
path: “libnvdsinfer_custom_impl_fasterRCNN.so”
全部
两者
注意
LstmParams 结构在未来版本中可能会更改
Gst-nvinferserver 消息 LstmParams 定义详情# 名称
描述
类型和范围
示例注释
loops
指定输入和输出张量之间的 LSTM 循环。
LstmLoop [重复]
- loops [ {
input: “init_state” output: “out_state”
} ] 详细信息请参考 LstmParams::LstmLoop
全部
两者
注意
输入和输出张量必须具有相同的数据类型/维度,不支持 FP16
LstmParams::LstmLoop 结构在未来版本中可能会更改
名称 |
描述 |
类型和范围 |
示例注释 |
网络类型 /
适用于 GIE (主/辅)
|
|---|---|---|---|---|
input |
指定当前循环的输入张量名称。 |
string |
Input: “init_state” |
全部 两者 |
output |
指定当前循环的输入张量名称。张量数据将反馈到输入张量 |
string |
onput: “output_state” |
全部 两者 |
init_const |
指定第一帧中输入的常量值 |
InitConst | value: float |
Init_const { value: 0 } |
全部 两者 |
Gst 属性#
通过 Gst 属性设置的值将覆盖配置文件中属性的值。应用程序针对某些需要以编程方式设置的属性执行此操作。如果用户通过插件设置属性,则这些值将替换配置文件中的原始值。下表描述了 Gst-nvinferserver 插件的 Gst 属性。
属性 |
含义 |
类型和范围 |
示例注释 |
|---|---|---|---|
config-file-path |
Gst-nvinferserver 元素的配置文件的绝对路径名 |
字符串 |
config-file-path=config_infer_primary.txt |
process-mode |
推理处理模式 (0):无, (1)全帧, (2)裁剪对象。如果设置,它可以替换 input_control.process_mode |
整数, 0, 1 或 2 |
process-mode=1 |
unique-id |
唯一 ID,用于标识由此 GIE 生成的元数据。如果设置,它可以替换 infer_config.unique_id |
整数, 0 到 4,294,967,295 |
unique-id=1 |
infer-on-gie-id |
请参阅配置文件表格中的 input_control.operate_on_gie_id |
整数, 0 到 4,294,967,295 |
infer-on-gie-id=1 |
operate-on-class-ids |
请参阅配置文件表格中的 input_control.operate_on_class_ids |
以冒号分隔的整数数组 (class-ids) |
operate-on-class-ids=1:2:4 |
batch-size |
在一个批次中一起推理的帧/对象数量。如果设置,它可以替换 infer_config.max_batch_size |
整数, 1 – 4,294,967,295 |
batch-size=4 |
Interval |
要跳过推理的连续批次数量。如果设置,它可以替换 input_control.interval |
整数, 0 到 32 |
interval=0 |
raw-output-generated-callback |
指向原始输出生成回调函数的指针 |
指针 |
无法通过 gst-launch 设置 |
raw-output-generated-userdata |
指向用户数据的指针,该指针将与 raw-output-generated-callback 一起提供 |
指针 |
无法通过 gst-launch 设置 |
DeepStream Triton 示例#
DeepStream Triton 示例位于文件夹 samples/configs/deepstream-app-triton 中。就 Triton 模型规范而言,所有相关模型和 Triton 配置文件 (config.pbtxt) 必须收集到同一个根目录中,即 samples/triton_model_repo。按照 samples/configs/deepstream-app-triton/README 中的说明运行示例。
DeepStream Triton gRPC 支持#
除了原生 Triton 服务器外,gst-nvinferserver 还支持作为独立进程运行的 Triton 推理服务器。与服务器的通信通过 gRPC 进行。以 gRPC 模式运行应用程序的配置文件位于 samples/config/deepstream-app-triton-grpc。按照 samples/configs/deepstream-app-triton-grpc/README 中的说明运行示例。
Triton Ensemble 模型#
Gst-nvinferserver 插件可以支持 Triton ensemble 模型,以便通过 Triton custom-backends 进行进一步的自定义预处理、后端处理和后处理。Triton ensemble 模型表示一个或多个模型的管道,以及这些模型之间输入和输出张量的连接,例如 “数据预处理 -> 推理 -> 数据后处理”。有关更多详细信息,请参阅 triton-inference-server/server。为了管理内存效率并保持清晰的接口,Gst-nvinferserver 插件的默认预处理无法禁用。颜色转换、数据类型转换、输入缩放和对象裁剪在 nvds_infer_server 中继续原生工作。例如,如果不需要原生归一化,请将 scale_factor 更新为 1.0
infer_config { preprocess { network_format: IMAGE_FORMAT_RGB tensor_order: TENSOR_ORDER_LINEAR normalize { scale_factor: 1.0 } } }
底层 nvds_infer_server 库可以以任何张量顺序和数据类型,以 Cuda GPU 缓冲区输入的形式,传递指定的媒体格式(RGB/BGR/Gray)到 Triton 后端。用户的自定义后端必须支持此输入上的 GPU 内存。Triton 自定义后端示例 identity 可以与 Gst-nvinferserver 插件一起使用。
注意
自定义后端 API 必须具有相同的 Triton 代码库版本 (24.08)。从 Triton 服务器版本 triton-inference-server/server 阅读更多详细信息
要了解如何实现 Triton 自定义后端的详细信息,请参考 triton-inference-server/backend。对于 Triton 模型的输出,nvds_infer_server 根据 Triton 输出请求支持 TRTSERVER_MEMORY_GPU 和 TRTSERVER_MEMORY_CPU 缓冲区分配。这也适用于 ensemble 模型的最终输出张量。最后,可以默认解析推理数据以进行检测、分类或语义分割。或者,用户可以实现自定义后端进行后处理,然后将最终输出传递给 Gst-nvinferserver 插件以进行进一步处理。除此之外,用户还可以选择将原始张量输出数据附加到元数据中,以便下游或应用程序解析。
自定义处理接口 IInferCustomProcessor 用于额外输入、LSTM 循环、输出张量后处理#
Gst-nvinferserver 插件支持额外的(多个)输入张量自定义预处理、输入/输出张量自定义循环处理(基于 LSTM)与多流、输出张量数据自定义解析和附加到 NvDsBatchMeta。此自定义函数通过 gst-nvinferserver 的配置文件加载
infer_config {
backend {
triton {
model_name: "yolov3-10_onnx"
# option 1: for CAPI inference
# model_repo { root: "./model_repo" }
# option 2: for gRPC inference
# grpc { url: "localhost:8001" }
}
# specify output tensor memory type, MEMORY_TYPE_CPU/MEMORY_TYPE_GPU
output_mem_type: MEMORY_TYPE_CPU
}
preprocess { ... } # specify scale and normalization
# postprocess{ other{} } # skip generic postprocess
# specify custom processing library
custom_lib {
path: "/path/to/libnvdsinferserver_custom_process.so"
}
extra {
# specify custom processing function entrypoint from custom_lib
custom_process_funcion: "CreateInferServerCustomProcess"
}
}
接口 IInferCustomProcessor 在 sources/includes/nvdsinferserver/infer_custom_process.h 中定义。
class IInferCustomProcessor {
virtual void supportInputMemType(InferMemType& type); // return supported memory type for `extraInputs`
virtual bool requireInferLoop() const; // indicate whether LSTM loop is needed. return 'false' if not needed.
// custom implementation for extra input tensors processing, `primaryInputs` is processed by preprocess{} from config file.
// param `options` is helpful to carry extra information such as stream_ids, `NvBufSurface`, `NvDsBatchMeta`, `GstBuffer`
virtual NvDsInferStatus extraInputProcess(const vector<IBatchBuffer*>& primaryInputs, vector<IBatchBuffer*>& extraInputs, const IOptions* options) = 0;
// param `outputs` is a array of all batched output tensors. param `inOptions` is same as extraInputProcess
virtual NvDsInferStatus inferenceDone(const IBatchArray* outputs, const IOptions* inOptions) = 0;
virtual void notifyError(NvDsInferStatus status) = 0;
};
用户需要从 IInferCustomProcessor 派生以通过 extraInputProcess 实现自己的额外预处理,并通过 inferenceDone 实现完全后处理。IOptions 中的参数结构携带来自 GstBuffer 和 NvDsBatchMeta 的所有信息。用户可以通过 IOptions 查询每个帧和批次的信息。有关更多示例,请参阅 /opt/nvidia/deepstream/deepstream/sources/TritonOnnxYolo/nvdsinferserver_custom_impl_yolo/nvdsinferserver_custom_process_yolo.cpp
以添加输出张量的简单后处理为例:
#include <inttypes.h>
#include <unistd.h>
#include <cassert>
#include <unordered_map>
#include "infer_custom_process.h"
#include "nvbufsurface.h"
#include "nvdsmeta.h"
typedef struct _GstBuffer GstBuffer;
using namespace nvdsinferserver;
#defin INFER_ASSERT assert
class NvInferServerCustomProcess : public IInferCustomProcessor {
// memtype for ``extraInputs``, set ``kGpuCuda`` for performance
void supportInputMemType(InferMemType& type) override { type = InferMemType::kGpuCuda; }
// for LSTM loop. return false if not required.
bool requireInferLoop() const override { return false; }
// skip extraInputProcess if there is no extra input tensors
NvDsInferStatus extraInputProcess(const std::vector<IBatchBuffer*>& primaryInputs, std::vector<IBatchBuffer*>& extraInputs, const IOptions* options) override {
return NVDSINFER_SUCCESS;
}
// output tensor postprocessing function.
NvDsInferStatus inferenceDone(const IBatchArray* outputs, const IOptions* inOptions) override
{
GstBuffer* gstBuf = nullptr;
std::vector<uint64_t> streamIds;
NvDsBatchMeta* batchMeta = nullptr;
std::vector<NvDsFrameMeta*> frameMetaList;
NvBufSurface* bufSurf = nullptr;
std::vector<NvBufSurfaceParams*> surfParamsList;
int64_t unique_id = 0;
INFER_ASSERT (inOptions->getValueArray(OPTION_NVDS_SREAM_IDS, streamIds) == NVDSINFER_SUCCESS);
INFER_ASSERT(inOptions->getObj(OPTION_NVDS_BUF_SURFACE, bufSurf) == NVDSINFER_SUCCESS);
INFER_ASSERT(inOptions->getObj(OPTION_NVDS_BATCH_META, batchMeta) == NVDSINFER_SUCCESS);
INFER_ASSERT(inOptions->getInt(OPTION_NVDS_UNIQUE_ID, unique_id) == NVDSINFER_SUCCESS);
INFER_ASSERT(inOptions->getValueArray(OPTION_NVDS_BUF_SURFACE_PARAMS_LIST, surfParamsList) == NVDSINFER_SUCCESS);
INFER_ASSERT(inOptions->getValueArray(OPTION_NVDS_FRAME_META_LIST, frameMetaList) == NVDSINFER_SUCCESS);
uint64_t nsTimestamp = UINT64_MAX; // nano-seconds
if (inOptions->hasValue(OPTION_TIMESTAMP)) {
INFER_ASSERT(inOptions->getUInt(OPTION_TIMESTAMP, nsTimestamp) == NVDSINFER_SUCCESS);
}
std::unordered_map<std::string, SharedIBatchBuffer> tensors;
for (uint32_t i = 0; i < outputs->getSize(); ++i) {
SharedIBatchBuffer outTensor = outputs->getSafeBuf(i);
INFER_ASSERT(outTensor);
auto desc = outTensor->getBufDesc();
tensors.emplace(desc.name, outTensor);
}
// parsing output tensors
float* boxesPtr = (float*)tensors["output_bbox"]->getBufPtr(0);
auto& bboxDesc = tensors["output_bbox"]->getBufDesc();
float* scoresPtr = (float*)tensors["output_score"]->getBufPtr(0);
float* numPtr = (float*)tensors["output_bbox_num"]->getBufPtr(0);
int32_t batchSize = bboxDesc.dims.d[0]; // e.g. tensor shape [Batch, num, 4]
std::vector<std::vector<NvDsInferObjectDetectionInfo>> batchedObjs(batchSize);
// parsing data into batchedObjs
...
// attach to NvDsBatchMeta
for (int iB = 0; iB < batchSize; ++iB) {
const auto& objs = batchedObjs[iB];
for (const auto& obj : objs) {
NvDsObjectMeta* objMeta = nvds_acquire_obj_meta_from_pool(batchMeta);
objMeta->unique_component_id = unique_id;
objMeta->confidence = obj.detectionConfidence;
objMeta->class_id = obj.classId;
objMeta->rect_params.left = obj.left;
objMeta->rect_params.top = obj.top;
objMeta->rect_params.width = obj.width;
objMeta->rect_params.height = obj.height;
// other settings
...
// add NvDsObjectMeta obj into NvDsFrameMeta frame.
nvds_add_obj_meta_to_frame(frameMetaList[iB], objMeta, NULL);
}
}
}
};
extern "C" {
IInferCustomProcessor* CreateInferServerCustomProcess(const char* config, uint32_t configLen)
{
return new NvInferServerCustomProcess();
} }
对于额外的输入张量预处理:如果模型需要多个张量输入,而不仅仅是主图像输入,用户可以从接口 IInferCustomProcessor 派生并实现 extraInputProcess() 来处理额外的输入张量。此函数仅用于额外的输入处理。参数 IOptions* options 将携带来自 GstBuffer、NvDsBatchMeta、NvDsFrameMeta、NvDsObjectMeta 等的所有信息。用户可以利用来自 options 的所有信息来填充额外的输入张量。所有输入张量内存都由 nvdsinferserver 底层库分配。
对于输出张量后处理(解析和元数据附加):如果用户想要对输出张量进行自定义解析,将解析结果放入用户元数据中,并将用户元数据附加到 GstBuffer、NvDsBatchMeta、NvDsFrameMeta 或 NvDsObjectMeta 中。用户可以实现 ‘inferenceDone(outputs, inOptions)’ 来解析 outputs 中的所有输出张量,并从 inOptions 中获取上述 GstBuffer、NvDsBatchMeta 和其他 DeepStream 信息。然后将解析后的用户元数据附加到 NvDs 元数据中。此函数支持多流解析和附加。有关示例,请参阅
/opt/nvidia/deepstream/deepstream/sources/TritonOnnxYolo/nvdsinferserver_custom_impl_yolo/nvdsinferserver_custom_process_yolo.cpp: NvInferServerCustomProcess::inferenceDone(),了解如何解析和附加输出元数据。注意
如果用户在 inferenceDone() 中需要特定的内存类型(例如 CPU)用于输出张量,请更新配置文件。
infer_config { backend { output_mem_type: MEMORY_TYPE_CPU } }对于多流自定义循环处理:如果模型是基于 LSTM 的,并且下一帧的输入由前一帧的输出数据生成。用户可以派生接口 IInferCustomProcessor,然后实现 extraInputProcess() 和 inferenceDone() 以进行循环处理。extraInputProcess() 可以初始化第一个输入张量状态。然后 ‘inferenceDone()’ 可以获取输出数据并进行后处理,并将结果存储到上下文中。当下一个 ‘extraInputProcess()’ 到来时,它可以检查存储的结果并反馈到张量状态中。当用户覆盖
bool requireInferLoop() const { return true; }时。nvdsinferver 底层库应保持 extraInputProcess 和 inferenceDone 按照其 nvds_stream_ids 顺序运行,nvds_stream_ids 可以从options->getValueArray(OPTION_NVDS_SREAM_IDS, streamIds)中获取。有关示例和详细信息,请参阅/opt/nvidia/deepstream/deepstream/sources/TritonOnnxYolo/nvdsinferserver_custom_impl_yolo/nvdsinferserver_custom_process_yolo.cpp。在此示例中,请参阅函数NvInferServerCustomProcess::feedbackStreamInput,了解如何将输出反馈到下一个输入循环。
下游插件的张量元数据输出#
Gst-nvinferserver 插件可以将推理后端生成的原始输出张量数据作为元数据附加。它作为 NvDsInferTensorMeta 添加到主(全帧)模式的 NvDsFrameMeta 的 frame_user_meta_list 成员中,或作为 NvDsInferTensorMeta 添加到辅助(对象)模式的 NvDsObjectMeta 的 obj_user_meta_list 成员中。它使用与 Gst-nvinferserver 插件相同的元数据结构。
注意
Gst-nvinferserver 插件目前不附加设备缓冲区指针 NvDsInferTensorMeta::attach out_buf_ptrs_dev。
读取或解析输出层的推理原始张量数据#
在 Gst-nvinferserver 插件的配置文件中启用以下字段
output_control { output_tensor_meta : true }如果需要禁用原生后处理,请更新
infer_config { postprocess { other {} } }当作为主 GIE 运行时,
NvDsInferTensorMeta附加到每个帧(每个 NvDsFrameMeta 对象)的frame_user_meta_list。当作为辅助 GIE 运行时,NvDsInferTensorMeta 附加到每个 NvDsObjectMeta 对象的obj_user_meta_list。Gst-nvinferserver 附加的元数据可以在从 Gst-nvinferserver 实例下游附加的 GStreamer pad 探针中访问。
NvDsInferTensorMeta对象的元数据类型设置为 NVDSINFER_TENSOR_OUTPUT_META。要获取此元数据,您必须迭代frame_user_meta_list或 obj_user_meta_list 引用的列表中的 NvDsUserMeta 用户元数据对象。
有关 Gst-infer 张量元数据用法的更多信息,请参阅 DeepStream SDK 示例中提供的源代码
sources/apps/sample_apps/deepstream_infer_tensor_meta-test.cpp。
分割元数据#
Gst-nvinferserver 插件将语义分割模型的输出作为用户元数据附加到 NvDsInferSegmentationMeta 的实例中,meta_type 设置为 NVDSINFER_SEGMENTATION_META。用户元数据添加到主(全帧)模式的 NvDsFrameMeta 的 frame_user_meta_list 成员,或辅助(对象)模式的 NvDsObjectMeta 的 obj_user_meta_list 成员。有关如何访问用户元数据的指南,请参阅上面的在 NvDsMatchMeta 和张量元数据中添加用户/自定义元数据。