面向 C/C++ 开发者的 Service Maker#
Service Maker C++ API 入门#
在开始实际应用程序之前,我们需要创建一个名为 ‘CMakeLists.txt’ 的文本文件,以便稍后构建我们的应用程序
cmake_minimum_required(VERSION 3.16)
project(Sample)
find_package(nvds_service_maker REQUIRED PATHS /opt/nvidia/deepstream/deepstream/service-maker/cmake)
add_executable(my-deepstream-app my_deepstream_app.cpp)
target_link_libraries(my-deepstream-app PRIVATE nvds_service_maker)
现在我们可以创建一个示例 deepstream 应用程序 (my_deepstream_app.cpp),其中包含一个管道,用于从传入的视频流执行对象检测
#include "pipeline.hpp"
#include <iostream>
using namespace deepstream;
#define CONFIG_FILE_PATH "/opt/nvidia/deepstream/deepstream/samples/configs/deepstream-app/config_infer_primary.yml"
int main(int argc, char *argv[])
{
try {
Pipeline pipeline("sample-pipeline");
pipeline.add("nvurisrcbin", "src", "uri", argv[1])
.add("nvstreammux", "mux", "batch-size", 1, "width", 1280, "height", 720)
.add("nvinferbin", "infer", "config-file-path", CONFIG_FILE_PATH)
.add("nvosdbin", "osd")
.add("nveglglessink", "sink")
.link({"src", "mux"}, {"", "sink_%u"}).link("mux","infer", "osd", "sink");
pipeline.start().wait();
} catch (const std::exception &e) {
std::cerr << e.what() << std::endl;
return -1;
}
return 0;
}
为了构建应用程序,我们应该使用 CMake 创建构建环境
$ mkdir build && cd build && cmake .. && make
构建完成后,我们可以运行应用程序以启动对象检测管道
$ ./my-deepstream-app file:///opt/nvidia/deepstream/deepstream/samples/streams/sample_720p.mp4
目前,尽管管道正在运行,但我们无法从应用程序中获取对象信息。为了访问这些数据,我们需要创建一个缓冲区探针,该探针迭代由 nvinfer 插件生成的元数据。
一个示例元数据探针可以按如下方式实现
class ObjectCounter : public BufferProbe::IBatchMetadataObserver
{
public:
ObjectCounter() {}
virtual ~ObjectCounter() {}
virtual probeReturn handleData(BufferProbe& probe, const BatchMetadata& data) {
data.iterate([](const FrameMetadata& frame_data) {
auto vehicle_count = 0;
frame_data.iterate([&](const ObjectMetadata& object_data) {
auto class_id = object_data.classId();
if (class_id == 0) {
vehicle_count++;
}
});
std::cout << "Object Counter: " <<
" Pad Idx = " << frame_data.padIndex() <<
" Frame Number = " << frame_data.frameNum() <<
" Vehicle Count = " << vehicle_count << std::endl;
});
return probeReturn::Probe_Ok;
}
};
通过在启动管道之前将缓冲区探针附加到现有管道中的推理插件,我们将从视频流的每一帧中获得车辆计数信息
pipeline.attach("infer", new BufferProbe("counter", new ObjectCounter));
重新构建应用程序并再次运行,车辆计数将打印出来。
......
Object Counter: Pad Idx = 0 Frame Number = 132 Vehicle Count = 7
Object Counter: Pad Idx = 0 Frame Number = 133 Vehicle Count = 8
Object Counter: Pad Idx = 0 Frame Number = 134 Vehicle Count = 7
Object Counter: Pad Idx = 0 Frame Number = 135 Vehicle Count = 8
Object Counter: Pad Idx = 0 Frame Number = 136 Vehicle Count = 9
Object Counter: Pad Idx = 0 Frame Number = 137 Vehicle Count = 7
Object Counter: Pad Idx = 0 Frame Number = 138 Vehicle Count = 9
Object Counter: Pad Idx = 0 Frame Number = 139 Vehicle Count = 9
Object Counter: Pad Idx = 0 Frame Number = 140 Vehicle Count = 9
Object Counter: Pad Idx = 0 Frame Number = 141 Vehicle Count = 11
.....
应用程序开发者基础知识#
管道#
管道是基于 Deepstream 的 AI 流媒体应用程序的基础。媒体流在管道内互连的功能块中流动,通过带有元数据的缓冲区宽度进行处理。管道及其内部的元素自主管理状态和数据流,减少了应用程序开发者外部干预的需求。
一个功能齐全的管道需要添加、配置和正确链接 Deepstream 插件中的适当元素。这可以使用 Pipeline API 以流畅的方式无缝实现
Pipeline pipeline("sample");
// nvstreammux is the factory name in Deepstream to create a streammuxer Element
// mux is the name of the Element instance
// multiple key value pairs can be appended to configure the added Element
pipeline.add("nvstreammux", "mux", "batch-size", 1, "width", 1280, "height", 720);
对于具有单个静态输入和输出的元素,可以以非常直接的方式建立链接
pipeline.link("mux", "infer", "osd", "sink");
但是,如果元素支持动态或多个输入/输出,则需要额外的信息来建立链接
// link the Element named "src" to the one named "mux"
// given the input of a nvstreammux is dynamic, we must specify the input name "sink_%u" (refer to the plugin documentation)
pipelin.link({"src", "mux"}, {"", "sink_%u"});
管道构建也可以通过声明式 YAML 配置文件来实现,从而显著减少应用程序开发中的编码工作。上述管道可以在 YAML 配置文件中定义如下。
deepstream:
nodes:
- type: nvurisrcbin
name: src
- type: nvstreammux
name: mux
properties:
batch-size: 1
width: 1280
height: 720
- type: nvinferbin
name: infer
properties:
config-file-path: /opt/nvidia/deepstream/deepstream/samples/configs/deepstream-app/config_infer_primary.yml
- type: nvosdbin
name: osd
- type: nveglglessink
name: sink
edges:
src: mux
mux: infer
infer: osd
osd: sink
并且应用 YAML 配置后,应用程序源代码可以大大简化
#include "pipeline.hpp"
#include <iostream>
using namespace deepstream;
int main(int argc, char *argv[])
{
try {
Pipeline pipeline("my-pipeline", "config.yaml");
pipeline["src"].set("uri", argv[1]);
pipeline.start().wait();
} catch (const std::exception &e) {
std::cerr << e.what() << std::endl;
return -1;
}
return 0;
}
管道的 YAML 配置以 “deepstream” 关键字开头,由两个部分组成
“nodes” 下的节点定义列表:每个项目定义要添加到管道的实例,并指定 “type”、“name” 和 “properties”。“type” 字段对应于 DS 插件中定义的元素名称,例如 “nvstreammux”;“name” 是一个字符串,用于标识管道内的实例,并且必须是唯一的;“properties” 字段初始化实例支持的属性。
“edge” 下的链接定义列表:每个项目定义一个或多个连接,其中键指定源,值指定目标。如果源有多个输出,则还应指定输出名称,例如 “source.vsrc_%u: mux”。
通过配置文件微调管道的指南#
YAML 配置文件还为用户提供了一个直接的选项来微调管道,使他们能够轻松优化性能。
用户始终可以从蓝图开始设计管道,其中包含适合其项目特定目标的适当节点和边。在继续之前,必须解决以下参数
batch-size:这是一个重要的属性,可能会影响性能。它指定 streammux 创建批处理的帧总数,它必须等于预期馈入管道的最大流数。“streammux” 的固有参数是它,而在 “nvmultiurisrcbin” 的情况下,应设置 “max-batch-size”。
batched-push-timeout:这是 “streammux” 或 “nvmultiurisrcbin” 的另一个属性。它决定了在给定批处理大小的情况下,streammux 将等待多长时间直到收集完所有帧。batched-push-timeout 的更改会影响帧速率,尤其是在输入是实时源(例如 RTSP)时。
buffer-pool-size:此属性定义 streammux 使用的缓冲区池的数量。在处理延迟延长到缓冲区池在缓冲区返回之前耗尽的程度的情况下,可能需要调整某些属性。但是,必须确保这些调整不超过 16 的限制。
在大多数情况下,性能下降源于硬件瓶颈,这可能是由 CPU、GPU 或其他组件引起的。为了识别瓶颈,用户可以将潜在问题节点的类型修改为 “identity”,从而有效地禁用它们,然后迭代地重新测试性能,直到确定实际瓶颈。
导致性能下降的另一个因素是管道缺乏完全并行化,这通常是由于某些节点的不规则过载造成的。在这种情况下,在问题节点之前插入队列可以提供解决方案。
此外,不必要的缩放会导致浪费计算。因此,仔细考虑每个节点的处理维度是有益的。确保处理维度与输入/输出维度或模型维度对齐可以有效地最大限度地减少缩放。
元素和插件#
Deepstream SDK 引入了 Element 作为可以通过各种插件访问的基本功能块。每种类型的元素都提供特定的功能,包括编码、解码、预处理、后处理、AI 推理和对象跟踪。当集成到管道中时,元素会启动对流经管道的媒体缓冲区的处理,从而生成元数据或消息作为结果。
元素是高度可配置的,支持通过键值对或外部配置文件进行自定义。这种灵活性使其能够适应不同的任务需求。元素的输出,包括数据缓冲区、元数据和消息,可以被下游对应物无缝捕获以进行连续处理。或者,它可以由应用程序检索,以便通过自定义对象进行外部处理。
可以使用 Deepstream SDK 中预定义的类型名称实例化元素
Element streammux("nvstreammux", "mux").set("batch-size", 1, "width", 1280, "height", 720);
更实用的方法支持通过更高级别的 Pipeline API 实例化和配置元素
pipeline.add("nvstreammux", "mux", "batch-size", 1, "width", 1280, "height", 720);
为了正确引导媒体流,需要在管道内按顺序链接元素。在大多数情况下,可以使用简单的链接方法来实现直接链接操作,并按顺序指定每个 Element 实例的名称。但是,在某些情况下,可能需要额外的信息来促进链接过程。这种复杂性可能源于 Element 如何处理输入和输出的差异。
pipeline.add("nvurisrcbin", "src").add("nvvideoconvert", "converter");
// only the video output of the media source should be linked to the video converter
// "vsrc_%u" specify the video output of a nvuirsrcbin instance (refer to the plugin documentation)
pipeline.link({"src", "converter"}, {"vsrc_%u", ""});
缓冲区#
Buffer 对象充当流经管道的数据段的包装器。
对于只读缓冲区,您可以调用 read 方法以只读模式访问数据,并采用自定义的可调用对象进行数据处理。类似地,对于读写缓冲区,过程是类似的,但增加了修改缓冲区内数据的能力。
// example of a video buffer observer interface
class SampleBufferObserver : public BufferProbe::IBufferObserver {
public:
virtual probeReturn handleBuffer(BufferProbe& probe, const Buffer& buffer) {
// cast of a general buffer to a video buffer allows to tread the data in proper video format
VideoBuffer video_buffer = buffer;
video_buffer.read([byte](const void* data, size_t size) -> size_t {
const unsigned char* p_byte = (const unsigned char*) data;
for (auto p = p_byte; p < p_byte + size; p++) {
// take a peek on the data
}
return size;
});
}
};
元数据#
除了元素的输出数据外,用户可能对元素生成的元数据非常感兴趣。这在 AI 推理管道中尤其重要,其中推理结果通常以元数据格式传递。
以下是当前支持的元数据对象列表
元数据类 |
描述 |
|---|---|
MetaData |
所有元数据的基类 |
BatchMetaData |
通过 nvstreammux 创建的元数据,充当所有其他元数据的根,并支持通过批处理迭代 FrameMetaData 和 DisplayMetadata |
FrameMetaData |
与特定视频帧关联的元数据,可在 BatchMetaData 中迭代 |
UserMetaData |
用户定义的元数据 |
ObjectMetadata |
描述检测到的对象的元数据,可在 FrameMetaData 中迭代。 |
ClassifierMetadata |
包含对象分类信息的元数据,可在 ObjectMetadata 中迭代。 |
DisplayMetadata |
描述显示属性的元数据,供 nvdsosd 用于在视频帧上绘制各种形状和文本,可在 FrameMetaData 中迭代。 |
EventMessageUserMetadata |
用于生成事件消息的特定用户元数据,一旦附加到 FrameMetaData,它将被下游消息转换器使用。 |
有关 Deepstream 元数据的更多详细信息,请参见此处。
SourceConfig#
SourceConfig 是一个方便的工具,用于从 YAML 文件加载源配置,允许用户向源附加额外信息并创建多个源的列表。一个示例源配置如下所示
source-list:
- uri: "file:///opt/nvidia/deepstream/deepstream/samples/streams/sample_1080p_h264.mp4"
sensor-id: UniqueSensorId1
sensor-name: UniqueSensorName1
- uri: "file:///opt/nvidia/deepstream/deepstream/samples/streams/sample_1080p_h265.mp4"
sensor-id: UniqueSensorId2
sensor-name: UniqueSensorName2
source-config:
source-bin: "nvmultiurisrcbin"
properties:
ip-address: "localhost"
port: 7000
batched-push-timeout: 33000
live-source: true
width: 1920
height: 1080
file-loop: true
max-batch-size: 16
YAML 文件中有 2 个部分:source-list 和 source-config,每个部分都定义了源 bin 的输入和配置
source-list:每个项目定义源的 uri、sensor-id 和 sensor-name
source-config:定义源节点的类型和相应的属性。“properties” 下的属性规范必须与源节点的类型一致。
当馈入管道的流的数量很大且在运行时可变时,将源配置与管道定义分开可以更清晰,但是,最合适的方法始终由开发者决定。
CameraConfig#
CameraConfig 是一个方便的工具,用于从 YAML 文件加载相机配置,允许用户创建多个相机源(V4L2/CSI)的列表。一个示例相机配置如下所示
camera-list:
- camera-type: "CSI"
camera-csi-sensor-id: 0
camera-width: 1280
camera-height: 720
camera-fps-n: 30
camera-fps-d: 1
- camera-type: "V4L2"
camera-v4l2-dev-node: 2
camera-width: 640
camera-height: 480
camera-fps-n: 30
camera-fps-d: 1
YAML 文件中只有一个部分:camera-list,它定义了相机源及其配置
camera-list:每个项目定义 camera-type、camera-width、camera-height、camera-fps-n、camera-fps-d,对于 CSI 相机源:camera-csi-sensor-id,对于 V4L2 相机源:camera-v4l2-dev-node。
CommonFactory 和自定义对象#
应用程序开发者可以利用自定义对象来访问针对其独特需求量身定制的特定 Deepstream 元素的处理结果。如果自定义对象在应用程序代码中定义,则可以直接通过 ‘new’ 关键字实例化它们。或者,如果通过插件实现,则可以通过公共工厂接口创建它们。
可以使用 ‘attach’ 方法将自定义对象合并到管道中,这需要附加对象的元素的名称。
注意
附加后,指定的元素将承担自定义对象的生命周期控制。
以下是当前支持的自定义对象列表
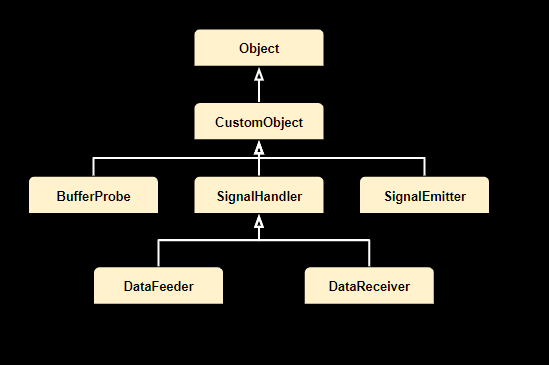
BufferProbe#
应用程序开发者可以使用缓冲区探针来检索在管道内生成的输出缓冲区。可以根据探针的特定要求实现各种接口,为不同的目的提供灵活性。
接口名称 |
方法 |
描述 |
|---|---|---|
IBufferObserver |
handleBuffer |
以只读模式访问每个处理后的缓冲区 |
IBufferOperator |
handleBuffer |
访问每个处理后的缓冲区,读写模式 |
IBatchMetadataObserver |
handleMetadata |
以只读模式访问批处理元数据 |
IBatchMetadataOperator |
handleMetadata |
访问批处理元数据,读写模式 |
SignalHandler#
信令是一种重要的机制,它促进了运行中的管道内的元素与外部世界之间的交互,从而将特定事件通知给观察者。一个元素可以支持多种信号,每种信号都在实例化期间唯一注册。有关元素信号支持的全面详细信息,请参见相应的插件手册。
应用程序开发者可以灵活地通过将信号处理程序附加到 Element 实例来增强其应用程序的功能。一旦附加,这些处理程序会立即响应发出的信号,从而使开发者能够实现自定义逻辑以响应特定事件。
DataFeeder#
DataFeeder 信号处理程序专门用于附加到 Element 实例,以捕获与数据请求相关的信号,例如来自 “appsrc” 的 “need-data” 和 “enough-data” 信号。通过使用 DataFeeder,应用程序开发者可以在运行时将数据无缝地注入到目标 Element 中。
DataReceiver#
DataReceiver 信号处理程序专门用于附加到 Element 实例,以捕获与数据就绪相关的信号,例如来自 “appsink” 的 “new-sample” 信号。通过使用 DataFeeder,通过使用 DataReceiver,应用程序开发者可以在运行时从目标 Element 接收处理后的数据。
SignalEmitter#
信号发射器是信令机制中的另一个关键组件,负责发射信号而不是处理信号。当元素寻求让某些活动由外部环境驱动时,它会接受信号发射器。在这种机制中,当信号发射器附加到配置为接收此类信号的 Element 实例时,当在信号发射器对象上调用 emit 方法时,将在 Element 实例上触发相应的活动。
准备和激活#
对于特定用例,我们引入了替代 API 来管理管道执行
Pipeline.prepare()#
与 pipeline.start() 不同,pipeline.start() 在新线程中将管道的状态转换为播放状态,pipeline.prepare() 在同一线程中将管道的状态设置为暂停状态。这在多管道场景中特别有用,在多管道场景中,每个管道的状态都需要按顺序更改为暂停状态。
Pipeline.activate()#
在使用 pipeline.prepare() 之后,pipeline.activate() 在新线程中将管道的状态从暂停状态转换为播放状态。这有效地启动了管道。在多管道场景中,这允许所有管道同时开始执行。
Pipeline.wait()#
此 API 用于加入 pipeline.activate() 创建的线程,确保所有线程在继续之前完成执行。
Sample Test 5 应用程序演示了如何有效地利用这些 API 调用。
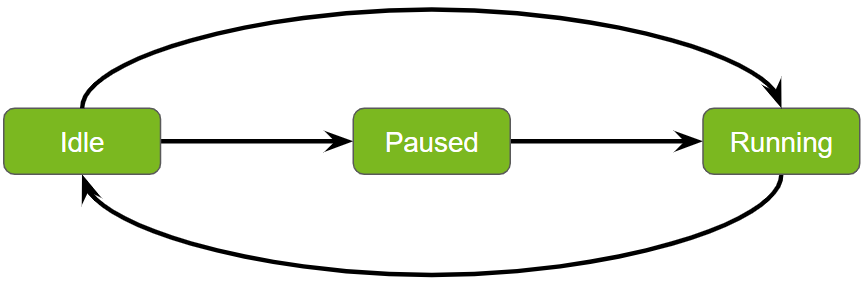
Service Maker 管道中的状态转换#
管理服务管道中的状态转换对于确保高效和有序的操作至关重要。Service maker 促进同步状态转换,从而实现管道状态的平稳和可预测的更改。以下是对这些转换的更清晰和更结构化的解释
启动#
转换:从空闲到运行。
过程:使用 pipeline.start() API 启动管道,使其从空闲状态移动到主动运行任务。
准备和激活#
转换:从空闲到暂停,然后到运行。
过程:通过执行 pipeline.prepare(),然后执行 pipeline.activate(),管道在完全运行之前会经历暂停状态。此顺序允许在执行之前进行任何必要的设置或配置。
等待#
目的:暂停当前线程,直到管道完成其执行。
过程:在启动和准备/激活序列之后,都需要 pipeline.wait() 函数,以确保当前线程暂停,直到管道完成处理。
停止#
转换:返回空闲状态。
过程:pipeline.stop() API 用于将管道返回到其空闲状态,有效地停止操作并将其重置以用于将来的任务。
这些转换旨在有效地管理工作流程,从而允许立即执行和必要的准备阶段。
示例应用程序#
示例应用程序可以在 Deepstream 安装目录 /opt/nvidia/deepstream/deepstream/service-maker/sources/apps 中找到,用户可以使用以下命令构建它们
$ cmake /opt/nvidia/deepstream/deepstream/service-maker/sources/apps/deepstream_test1_app && make
将传统的 Deepstream 应用程序迁移到 Service Maker#
对于长期以来一直将 Deepstream 应用程序集成到其解决方案中的用户来说,迁移到新的 Service Maker API 所需的工作量极少。
传统的 Deepstream 应用程序依赖于配置文件进行管道自定义和参数设置。Service Maker API 遵循类似的方法,提供具有细微差异的配置规范
全局参数
在传统的 Deepstream 应用程序中,所有全局参数都需要在名为 ‘applications’ 的特定部分下定义
[application] enable-perf-measurement=1 perf-measurement-interval-sec=5 gie-kitti-output-dir=/tmp
使用 Service Maker API,一些参数预计将作为命令行参数添加。例如,从 Service Maker 构建的 test5 应用程序可以通过命令行参数更改性能测量间隔
—perf-measurement-interval-sec 5
至于其他并非真正“全局”的参数,它们可以设置为相应模块的属性。例如,‘gie-kitti-output-dir’ 实际上是使用 Service Maker 构建的 ‘kitti_dump_probe’ 插件的属性,因此可以在管道内 ‘kitti_dump_probe’ 实例的 ‘Properties’ 下设置它。
- type: kitti_dump_probe.kitti_dump_probe name: kitti_dump properties: kitti-dir: '/tmp'
管道自定义
与传统的 Deepstream 应用程序相比,Service Maker 采用基于图的 YAML 定义来表示管道结构,为用户提供了最大的自定义灵活性。传统配置中预定义的节,例如 ‘primary-gie’、‘secondary-gie’、‘tracker’、‘tiled-display’ 和 ‘osd’,都可以通过 Service Maker YAML 定义中每个独立元素的属性进行配置。
源和批处理
在传统的 Deepstream 应用程序中,源管理涉及配置文件中的 ‘sourceX’、‘streammux’、‘source-list’ 和 ‘source-attr-all’ 的组合。Service Maker 通过将源管理分离到独立的源配置文件中来简化此过程。在此文件中,源信息(包括 ‘list’、‘sensor-name-list’ 和 ‘sensor-id-list’)放置在 ‘source-list’ 部分中。同时,管道自定义(例如指定源类型和属性)在 ‘source-config’ 部分中处理。
Sink 管理
与传统的 Deepstream 应用程序相比,Service Maker 为更广泛的任意 sink 选项提供了支持。这些选项包括 ‘Fakesink’、‘Display’、‘File’、‘UDP’ 和 ‘MsgConvBroker’ 等现有类型。这些 sink 中的每一个都必须在图形管道规范中定义,其中包括所有必要的元素节点以及它们之间的边。这种方法在配置管道的 sink 时提供了更大的灵活性。