Gst-nvtracker#
Gst-nvtracker 插件允许 DS 管道使用底层跟踪器库,通过唯一的 ID 持久地跟踪检测到的对象。它支持任何实现 NvDsTracker API 的底层库,包括 NvMultiObjectTracker 库提供的参考实现:IOU、NvSORT、NvDeepSORT 和 NvDCF 跟踪器。作为此 API 的一部分,插件查询底层库关于输入格式、内存类型和附加功能支持的功能和要求。基于这些查询,插件随后将输入帧缓冲区转换为底层跟踪器库请求的格式。例如,NvDeepSORT 和 NvDCF 跟踪器使用 NV12 或 RGBA,而 IOU 和 NvSORT 完全不需要视频帧缓冲区。
基于查询,Gst-nvtracker 插件构建底层跟踪器库的输入数据,该数据由视频帧和跨多个流的检测对象组成,这些数据通过单个 API 调用以单个数据结构(即,帧批次)馈送到底层库。此 API 设计允许在底层跟踪器库中批量处理模式下处理来自多个流的所有输入数据(类似于 cuFFT™、cuBLAS™ 等中的批处理模式),从而可能实现更高效的执行,尤其是在 GPU 上加速时。因此,当使用 NvMOT_Process API 时,底层跟踪器需要支持 批处理。
Gst-nvtracker 插件支持通过 NvMOT_RetrieveMiscData API 从底层跟踪器库检索用户定义的杂项数据,其中包括有用的对象跟踪信息,而不是当前帧目标的默认数据;例如,过去的帧对象数据、阴影跟踪模式下的目标、终止目标的完整轨迹和重新识别特征。有关杂项数据的类型及其含义的更多详细信息,请参见杂项数据输出部分。允许用户在 NvMOTTrackerMiscData 中定义其他类型的杂项数据。
有关所有这些跟踪器 API 的更多详细信息,请在底层跟踪器库的 NvDsTracker API 部分中讨论。
该插件接受来自上游组件的 NV12 或 RGBA 格式的帧数据,并根据底层库要求的格式,使用配置文件 [tracker] 部分中的 tracker-width 和 tracker-height 指定的帧分辨率,将输入缓冲区缩放(和/或转换)为跟踪器插件中的缓冲区。底层跟踪器库的路径通过同一部分中的 ll-lib-file 配置选项指定。要使用的底层库可能还需要自己的配置文件,可以通过 ll-config-file 选项指定。如果未指定 ll-config-file,则底层跟踪器库可能会使用其默认参数值继续运行。
NvMultiObjectTracker 库提供的参考底层跟踪器实现支持各种类型的多对象跟踪算法
IOU 跟踪器:Intersection-Over-Union (IOU) 跟踪器使用两个连续帧之间检测器的边界框之间的 IOU 值来执行它们之间的关联,或者在未找到匹配项时分配新的目标 ID。此跟踪器包括处理对象检测器误报和漏报的逻辑;但是,这可以被视为最基本的对象跟踪器,可能仅用作基线。
NvSORT:NvSORT 跟踪器是 NVIDIA® 增强的 Simple Online and Realtime Tracking (SORT) 算法。NvSORT 不使用简单的二分图匹配算法,而是使用基于边界框 (bbox) 邻近度的级联数据关联来关联连续帧上的 bbox,并应用卡尔曼滤波器来更新目标状态。由于它不涉及任何像素数据处理,因此计算效率很高。
NvDeepSORT:NvDeepSORT 跟踪器是 NVIDIA® 增强的 Online and Realtime Tracking with a Deep Association Metric (DeepSORT) 算法,它使用深度余弦度量学习和 Re-ID 神经网络,用于跨帧的多个对象的数据关联。此实现允许用户使用 NVIDIA 的 TensorRT™ 框架支持的任何 Re-ID 网络。NvDeepSORT 也使用级联数据关联而不是简单的二分图匹配。该实现还针对 GPU 上的高效处理进行了优化。
NvDCF:NvDCF 跟踪器是一种在线多对象跟踪器,它采用判别相关滤波器进行视觉对象跟踪,即使检测结果不可用,也允许独立的对象跟踪。它使用相关滤波器响应和边界框邻近度的组合进行数据关联。
有关每种算法及其实现细节的更多详细信息,请参见NvMultiObjectTracker:参考底层跟踪器库部分。
注意
Gst-nvtracker 插件的源代码作为 DeepStream SDK 软件包的一部分提供,安装在系统上时位于 sources/gst-plugins/gst-nvtracker/ 下。这是为了允许用户在需要时直接更改插件以用于其自定义应用程序,并向用户展示如何在插件中管理底层库以及如何处理元数据。
子批处理 (Alpha)#
Gst-nvtracker 插件默认在批处理模式下工作。在此模式下,输入帧批次传递给单个底层跟踪器库实例并由其处理。批处理模式的优点是允许 GPU 一次处理更多数据,从而可能提高执行期间的 GPU 占用率并减少 CUDA 内核启动开销。但是,根据用例,一个潜在的问题是,除非模块内的端到端操作完全在 GPU 上执行,否则 GPU 可能在跟踪器中的某些计算阶段处于空闲状态(也称为 GPU 气泡)。如果跟踪器中的某些计算模块在 CPU 上运行,情况确实如此。如果 DeepStream 管道中还有其他组件使用 GPU(例如,PGIE 和 SGIE 中基于 GPU 的推理),则跟踪器中的此类 CPU 模块可以隐藏在它们后面,而不会影响管道的整体吞吐量。
新引入的子批处理功能允许插件将输入帧批次拆分为多个子批次(例如,四流管道可以在跟踪器插件中使用两个子批次,每个子批次处理两个流)。每个子批次都分配给一个单独的底层跟踪器库实例,其中对应子批次的输入被单独处理。底层跟踪器库的每个实例都在独立运行的专用线程上运行,从而允许子批次的并行处理,并最大限度地减少由于 CPU 计算块导致的 GPU 空闲,最终提高资源利用率。
由于子批处理将单独的底层跟踪器库实例分配给不同的子批次,因此允许用户使用不同的底层跟踪器库配置文件为每个单独的子批次配置不同的参数。这可以以多种方式利用,例如在子批次之间设置不同的计算后端,在子批次之间使用不同的跟踪算法或修改底层跟踪器配置文件中支持的任何其他配置。更多详细的用例在子批处理的设置和使用 (Alpha) 部分中讨论。
输入和输出#
本节总结了 Gst-nvtracker 插件的输入、输出和通信设施。
输入
Gst 缓冲区
来自可用源流的帧批次
NvDsBatchMeta包括来自主推理模块的检测到的对象信息
有关 NvDsBatchMeta 的更多详细信息,请参见链接。
NvTracker 插件支持的输入视频帧颜色格式为 NV12 和 RGBA。根据底层跟踪器库要求的颜色格式和分辨率,从输入视频帧创建单独的视频帧批次。
输出
Gst 缓冲区
与输入相同。未修改。
NvDsBatchMeta使用来自跟踪器底层库的附加数据进行更新
输出没有单独的数据结构。相反,跟踪器插件只是在现有的 NvDsBatchMeta(及其 NvDsObjectMeta)中添加/更新来自跟踪器底层库的输出数据,包括跟踪的对象坐标、跟踪器置信度和对象 ID。还有一些其他杂项数据可以作为用户元数据附加,这在杂项数据输出部分中介绍。
注意
如果跟踪器算法未生成置信度值,则跟踪对象的跟踪器置信度值将设置为默认值(即,1.0)。对于 IOU、NvSORT 和 NvDeepSORT 跟踪器,tracker_confidence 设置为 1.0,因为这些算法不生成跟踪对象的置信度值。另一方面,NvDCF 跟踪器由于其视觉跟踪能力而生成跟踪对象的置信度,其值设置在 NvDsObjectMeta 结构中的 tracker_confidence 字段中。
请注意,NvDsObjectMeta 中有单独的参数用于检测器的置信度和跟踪器的置信度,分别是 confidence 和 tracker_confidence。更多详细信息请参见 新元数据字段
下表总结了插件的功能。
功能 |
描述 |
发布版本 |
|---|---|---|
可配置的跟踪器宽度/高度 |
帧在 NvTracker 插件中内部缩放到指定分辨率以进行跟踪,并传递到底层库 |
DS 2.0 |
多流 CPU/GPU 跟踪器 |
支持在由来自多个源的帧组成的批处理缓冲区上进行跟踪 |
DS 2.0 |
NV12 输入 |
DS 2.0 |
|
RGBA 输入 |
DS 3.0 |
|
可配置的 GPU 设备 |
用户可以选择 GPU 用于内部缩放/颜色格式转换和跟踪 |
DS 2.0 |
运行时动态添加/删除源 |
支持在运行时添加的新源上进行跟踪,并在删除源时清理资源 |
DS 3.0 |
支持用户选择底层库 |
动态加载用户选择的底层库 |
DS 4.0 |
完全支持批处理 |
支持将来自多个输入流的帧发送到底层库 |
DS 4.0 |
多种缓冲区格式作为底层库的输入 |
将输入缓冲区转换为底层库请求的格式,每个帧最多 4 种格式 |
DS 4.0 |
启用跟踪 ID 显示 |
支持启用或禁用跟踪 ID 的显示 |
DS 5.0 |
基于事件的跟踪 ID 重置 |
基于管道事件(即,GST_NVEVENT_STREAM_EOS 和 GST_NVEVENT_STREAM_RESET),特定流上的跟踪 ID 可以重置为从 0 或新 ID 开始。 |
DS 6.0 |
杂项数据 |
如果底层库支持该功能,则支持输出用户定义的杂项数据(包括过去的帧数据、终止轨迹列表等) |
DS 6.3 |
Re-ID 张量输出 |
如果底层库使用 Re-ID 模型,则支持输出对象的 Re-ID 特征(即,嵌入) |
DS 6.3 |
支持 NVIDIA 的 VPI™ 基于 Crop-scaler 和 DCF-Tracker 算法在 NvDCF 跟踪器中(Alpha 功能) |
NvDCF 跟踪器中提供的配置选项允许用户切换到 NVIDIA 的 VPI™ Crop-scaler 和 DCF-Tracker 实现。用户还可以配置要在 VPI™ 支持的后端之间使用的计算后端 |
DS 6.4 |
通过 VPI™ 的统一 API 实现 NvDCF 的 PVA 后端(Alpha 功能) |
允许在 Jetson 上基于 PVA 执行 NvDCF 的重要部分,从而降低 GPU 利用率 |
DS 6.4 |
子批处理 (Alpha 功能) |
支持将帧批次拆分为子批次,这些子批次在内部并行处理,从而提高资源利用率。此功能还支持为每个子批次指定不同的配置文件。 |
DS 6.4 |
单视图 3D 跟踪 (Alpha 功能) |
当提供相机/模型信息(3x4 投影矩阵和 3D 人体模型信息)时,允许基于 3D 世界坐标系的对象跟踪,以更好地处理部分遮挡 |
DS 6.4 |
Gst 属性#
下表描述了 Gst-nvtracker 插件的 Gst 属性。
属性 |
含义 |
类型和范围 |
示例注释 |
|---|---|---|---|
tracker-width |
跟踪器要运行的帧宽度,以像素为单位。(当 visualTrackerType: 1 或 reidType 为非零且 useVPICropScaler: 0 时,必须是 32 的倍数) |
整数,0 到 4,294,967,295 |
tracker-width=640 |
tracker-height |
跟踪器要运行的帧高度,以像素为单位。(当 visualTrackerType: 1 或 reidType 为非零且 useVPICropScaler: 0 时,必须是 32 的倍数) |
整数,0 到 4,294,967,295 |
tracker-height=384 |
ll-lib-file |
Gst-nvtracker 要加载的底层跟踪器库的路径名。 |
字符串 |
ll-lib-file=/opt/nvidia/deepstream/deepstream/lib/libnvds_nvmultiobjecttracker.so |
ll-config-file |
底层库的配置文件(如果需要)。 (Alpha 功能)当配置 sub-batches 属性时,可以指定配置文件列表。 |
配置文件路径 或 以分号分隔的配置文件路径列表 |
ll-config-file=config_tracker_NvDCF_perf.yml ll-config-file=config_tracker_NvDCF_perf1.yml; config_tracker_NvDCF_perf2.yml |
gpu-id |
要在其上分配设备/统一内存以及要使用其完成缓冲区复制/缩放的 GPU 的 ID。(仅限 dGPU。) |
整数,0 到 4,294,967,295 |
gpu-id=0 |
tracking-surface-type |
设置跟踪的表面流类型。(默认值为 0) |
整数,≥0 |
tracking-surface-type=0 |
display-tracking-id |
在 OSD 上启用跟踪 ID 显示。 |
布尔值 |
display-tracking-id=1 |
compute-hw |
用于缩放的计算引擎。 0 - 默认 1 - GPU 2 - VIC(仅限 Jetson) |
整数,0 到 2 |
compute-hw=1 |
tracking-id-reset-mode |
允许基于管道事件强制重置跟踪 ID。一旦启用跟踪 ID 重置并且发生此类事件,跟踪 ID 的低 32 位将重置为 0 0:当流重置或 EOS 事件发生时,不重置跟踪 ID 1:当流重置发生时(即,GST_NVEVENT_STREAM_RESET),终止所有现有跟踪器并为流分配新 ID 2:在接收到 EOS 事件后(即,GST_NVEVENT_STREAM_EOS),让跟踪 ID 从 0 开始(注意:只有跟踪 ID 的低 32 位从 0 开始) 3:同时启用选项 1 和 2 |
整数,0 到 3 |
tracking-id-reset-mode=0 |
input-tensor-meta |
如果 tensor-meta-gie-id 可用,则使用来自 Gst-nvdspreprocess 的 tensor-meta |
布尔值 |
input-tensor-meta=1 |
tensor-meta-gie-id |
要使用的 Tensor Meta GIE ID,仅当 input-tensor-meta 为 TRUE 时属性才有效 |
无符号整数,≥0 |
tensor-meta-gie-id=5 |
sub-batches (Alpha 功能) |
配置将帧批次拆分为子批次。有两种方法可以配置子批次。 第一个选项允许将每个源 ID 静态映射到单独的子批次。 第二个选项允许用户配置子批次大小。单个流到子批次的映射在运行时动态发生。 |
选项 1:以分号分隔的整数数组,其中每个数字对应于源 ID。 必须包含从 0 到 (batch-size -1) 的所有值,其中 batch-size 在 选项 2:以冒号分隔的整数数组,其中每个数字对应于子批次的大小(即,子批次可以容纳的最大流数) |
选项 1:sub-batches=0,1;2,3 在此示例中,批次大小 4 被拆分为两个子批次,其中第一个子批次由源 ID 0 和 1 组成,第二个子批次由源 ID 2 和 3 组成 选项 2:sub-batches=2:1 以上示例表明有两个子批次,第一个子批次可以容纳 2 个流,第二个子批次可以容纳 1 个流。 |
sub-batch-err-recovery-trial-cnt (Alpha 功能) |
配置当子批次中的底层跟踪器返回致命错误时,插件可以尝试恢复的次数。 为了从错误中恢复,插件重新初始化底层跟踪器库。 |
整数,≥-1,其中, -1 对应于无限次尝试 |
sub-batch-err-recovery-trial-cnt=3 |
user-meta-pool-size |
跟踪器杂项数据缓冲区池的大小 |
无符号整数,>0 |
user-meta-pool-size=32 |
底层跟踪器库的 NvDsTracker API#
可以使用 sources/includes/nvdstracker.h 中定义的 API 实现底层跟踪器库。API 的某些部分引用 sources/includes/nvbufsurface.h。API 函数和数据结构的名称以 NvMOT 为前缀,代表 NVIDIA 多对象跟踪器。以下是从底层库的角度来看 API 的一般流程
第一个必需的函数是
NvMOTStatus NvMOT_Query ( uint16_t customConfigFilePathSize, char* pCustomConfigFilePath, NvMOTQuery *pQuery );
插件在启动与库的任何处理会话(即,上下文)之前,使用此函数查询底层库的功能和要求。查询的属性包括输入帧的颜色格式(例如,RGBA 或 NV12)和内存类型(例如,NVIDIA® CUDA® 设备或 CPU 映射的 NVMM)。
插件在初始化阶段执行此查询一次,其结果应用于与底层库建立的所有上下文。如果指定了底层库配置文件,则在查询中提供该文件以供库参考。查询回复结构
NvMOTQuery包含以下字段NvMOTCompute computeConfig:报告库支持的计算目标。插件当前仅在启动上下文时回显报告的值。uint8_t numTransforms:底层库所需的颜色格式数。此字段的有效范围是0到NVMOT_MAX_TRANSFORMS。如果库不需要任何视觉数据,则将其设置为0。注意
0并不意味着未转换的数据将传递到库。NvBufSurfaceColorFormat colorFormats[NVMOT_MAX_TRANSFORMS]:底层库所需的颜色格式列表。只有前numTransforms项有效。NvBufSurfaceMemType memType:转换缓冲区的内存类型。插件分配此类型的缓冲区来存储颜色和比例转换的帧,并且缓冲区在每帧传递到底层库。当前支持仅限于以下类型dGPU
NVBUF_MEM_CUDA_PINNED NVBUF_MEM_CUDA_UNIFIED
Jetson
NVBUF_MEM_SURFACE_ARRAYbool supportBatchProcessing:如果底层库支持跨多个流的批处理,则为 True;否则为 false。bool supportPastFrame:如果底层库支持输出过去的帧数据,则为 True;否则为 false。
查询后,在任何帧到达之前,插件必须通过调用以下函数使用底层库初始化上下文
NvMOTStatus NvMOT_Init ( NvMOTConfig *pConfigIn, NvMOTContextHandle *pContextHandle, NvMOTConfigResponse *pConfigResponse );
上下文句柄在底层库外部是不透明的。在批处理模式下,插件为所有输入流请求单个上下文。另一方面,在每流处理模式下,插件为每个输入流进行此调用,以便每个流都有自己的上下文。此调用包括上下文的配置请求。底层库有机会
查看配置,并且仅在接受请求时才创建上下文。如果配置请求的任何部分被拒绝,则不创建上下文,并且返回状态必须设置为
NvMOTStatus_Error。pConfigResponse字段可以选择包含特定配置项的状态。基于配置预分配资源。
注意
在
NvMOTMiscConfig结构中,logMsg字段当前不受支持且未初始化。
customConfigFilePath指针仅在调用期间有效。
一旦上下文初始化,插件会在从上游接收到帧数据以及检测到的对象边界框时,将这些数据发送到底层库。它始终将数据表示为帧批次,尽管在每流处理上下文中,批次可能只包含单个帧。请注意,根据帧到达跟踪器插件的时间,帧批次的组成可以是完整批次(包含来自每个流的帧)或部分批次(仅包含来自流子集的帧)。在任何一种情况下,都保证每个批次最多包含一个帧来自每个流。
此处理的函数调用是
NvMOTStatus NvMOT_Process ( NvMOTContextHandle contextHandle, NvMOTProcessParams *pParams, NvMOTTrackedObjBatch *pTrackedObjectsBatch );,其中
pParams是指向要处理的输入帧批次的指针。该结构包含一个或多个帧的列表,每个流最多一个帧。因此,没有两个帧条目具有相同的streamID。每个帧数据条目都包含以底层库要求的颜色格式的一个或多个缓冲区的列表,以及帧的对象属性数据列表。大多数库最多需要一种颜色格式。
pTrackedObjectsBatch是指向对象属性数据输出批次的指针。它预先填充了numFilled的值,该值与输入参数中包含的帧数相同。如果帧没有输出对象属性数据,则它仍然在
numFilled中计数,并用空列表条目 (NvMOTTrackedObjList) 表示。空列表条目具有正确的streamID设置,并且 numFilled 设置为0。注意
输出对象属性数据
NvMOTTrackedObj包含指向与跟踪对象关联的检测器对象(在输入中提供)的指针,该指针存储在associatedObjectIn中。您必须仅为输入对象传入的帧将此设置为关联的输入对象。例如,对于 PGIEinterval=1的管道
帧 0:传入
NvMOTObjToTrackX。跟踪器为其分配 ID 1,并且输出对象的associatedObjectIn指向X。帧 1:跳过推理,因此没有来自检测器的输入对象要关联。跟踪器找到对象 1,并且输出对象的
associatedObjectIn指向NULL。帧 2:传入
NvMOTObjToTrackY。跟踪器将其识别为对象 1。输出对象 1 的associatedObjectIn指向Y。
根据底层跟踪器的能力,可能有一些用户定义的杂项数据要报告给跟踪器插件。
NvDsBatchMeta中的batch_user_meta_list作为用户元数据NvMOTStatus NvMOT_RetrieveMiscData ( NvMOTContextHandle contextHandle, NvMOTProcessParams *pParams, NvMOTTrackerMiscData *pTrackerMiscData );
其中
pParams是指向要处理的输入帧批次的指针。此结构用于检查批次中的流 ID 列表。
pTrackerMiscData是指向要由底层跟踪器填充的当前批次的输出杂项数据的指针。数据结构NvMOTTrackerMiscData在nvdstracker.h中定义。
如果动态删除了视频流源,则插件会调用以下函数,以便底层跟踪器库也可以删除它。请注意,此 API 是可选的,仅在启用批处理模式时有效,这意味着它仅在底层跟踪器库具有 API 的实际实现时才会执行。如果调用,底层跟踪器库可以释放它可能已分配的任何每流资源
void NvMOT_RemoveStreams ( NvMOTContextHandle contextHandle, NvMOTStreamId streamIdMask );
当所有处理完成时,插件会调用此函数以清理上下文并释放其资源
void NvMOT_DeInit (NvMOTContextHandle contextHandle);
NvMultiObjectTracker:参考底层跟踪器库#
多目标跟踪 (MOT) 是大量智能视频分析 (IVA) 应用的关键构建模块,这些应用需要对感兴趣的对象进行时空分析,以便深入了解对象在长期内的行为。给定来自单路或多路流的 Primary GIE (PGIE) 模块检测到的一组对象,并使用为跟踪器插件定义的 API,底层跟踪器库应执行实际的多目标跟踪操作,以便为同一对象在一段时间内保持持久 ID。
DeepStream SDK 提供了一个单一的参考底层跟踪器库,名为 NvMultiObjectTracker,它在一个统一的架构中实现了所有四种底层跟踪算法(即 IOU、NvSORT、NvDeepSORT 和 NvDCF)。它支持在批处理模式下进行多流、多目标跟踪,以便在 CPU 和 GPU(以及 Jetson 的 PVA)上进行高效处理。以下章节将介绍统一的跟踪器架构以及每个参考跟踪器实现的详细信息。
用于可组合多目标跟踪器的统一跟踪器架构#
在 NvMultiObjectTracker 底层跟踪器库中,不同类型的多目标跟踪器在基本功能(例如,数据关联、目标管理、状态估计等)方面共享通用模块,而在其他核心功能(例如,NvDCF 的视觉跟踪和 NvDeepSORT 的深度关联度量)方面有所不同。NvMultiObjectTracker 库采用统一的架构,允许通过配置 组合 多目标跟踪器,仅启用特定对象跟踪器所需的模块。例如,IOU 跟踪器需要最少的一组模块,包括数据关联和目标管理模块。在此基础上,NvSORT 添加了一个状态估计器,以实现更准确的运动估计和预测,而 NvDeepSORT 进一步引入了深度 Re-ID 网络,将外观信息集成到数据关联中。与 NvDeepSORT 中基于深度神经网络的 Re-ID 特征不同,NvDCF 采用基于判别相关滤波器 (DCF) 的视觉跟踪模块,该模块使用传统的特征描述符以实现更高效的跟踪。但是,NvDCF 仍然允许使用 Re-ID 模块进行目标重关联,以提高长期鲁棒性。
下表总结了用于组合每个对象跟踪器的模块,显示了不同对象跟踪器之间共享的模块以及每个对象跟踪器在模块组成方面的差异
跟踪器类型 |
状态 估计器 |
目标 管理 |
视觉 跟踪器 |
目标重关联 |
数据关联度量 |
|||
|---|---|---|---|---|---|---|---|---|
时空 |
Re-ID |
邻近度和大小 |
视觉相似性 |
Re-ID |
||||
IOU |
O |
O |
||||||
NvSORT |
O |
O |
O |
|||||
NvDeepSORT |
O |
O |
O |
O |
||||
NvDCF |
O |
O |
O |
O |
O |
O |
O |
|
在以下章节中,我们将首先讨论 NvMultiObjectTracker 库的一般工作流程及其核心模块,然后更详细地介绍每种类型的对象跟踪器,并解释每个模块中的配置参数。
NvMultiObjectTracker 库的工作流程和核心模块#
底层跟踪器库的输入包括 (1) 来自单路或多路流的一批视频帧和 (2) 每个视频帧的对象检测器列表。如果检测间隔(即 Primary GIE 部分中的 interval)设置大于 0,则底层跟踪器的输入数据将仅在对视频帧批次执行对象检测推理时才包含检测器对象数据(即推理帧批次)。对于跳过推理的帧批次(即非推理帧批次),输入数据将仅包括视频帧。
注意
检测器对象是指由 PGIE 模块中的检测器检测到的对象,并作为输入提供给多目标跟踪器模块。
目标是指正在被对象跟踪器跟踪的对象。
推理帧是指对其执行对象检测推理的视频帧。由于可以在 PGIE 的设置中配置推理间隔,并且可以大于零,因此两个连续推理帧的
frameNum可能不是连续的。
为了使用给定的输入数据执行多目标跟踪操作,需要执行以下基本功能。部署多线程以优化其在 CPU 上的性能。
新视频帧中的检测器对象与同一视频流的现有目标之间的数据关联
基于数据关联结果的目标管理,包括目标状态更新以及目标的创建和终止
根据跟踪器类型的不同,在数据关联之前可能有一些额外的处理。例如,NvDeepSORT 从所有检测器对象中提取 Re-ID 特征并计算相似度,而 NvDCF 执行基于视觉跟踪器的定位,以便可以使用目标在新帧中的预测位置进行数据关联。更多详细信息将在每个跟踪器的章节中介绍。
数据关联#
对于数据关联,使用各种类型的相似性度量来计算检测器对象和现有目标之间的匹配得分,包括
位置相似性(即邻近度)
边界框大小相似性
Re-ID 特征相似性(NvDeepSORT 跟踪器特有)
视觉外观相似性(NvDCF 跟踪器特有)
对于检测器对象和目标之间的邻近度,IOU 是一种广泛使用的典型度量,但它也取决于它们之间的大小相似性。两个对象之间的框大小相似性可以显式使用,计算为较小框的大小与较大框大小的比率。
检测器对象和目标对的总关联得分是所有度量的加权和
\[totalScore=w_1*IOU+w_2*sizeSimilarity+w_3*reidSimilarity+w_4*visualSimilarity\]
其中 \(w_i\) 是配置文件中为每个度量设置的权重。用户还可以为每个相似度和总分设置最小阈值。
在匹配期间,默认情况下,检测器对象与属于同一类别的目标关联,以最大程度地减少错误匹配。但是,可以通过设置 checkClassMatch: 0 来禁用此功能,从而允许对象关联,而无需考虑其对象类别 ID。当使用像 YOLO 这样的检测器时,这可能很有用,YOLO 可以检测多种类别的对象,其中同一对象可能会随着时间的推移发生错误分类。
关于匹配算法,用户可以将 associationMatcherType 设置为 0,以采用高效的贪婪算法,使用上面定义的相似性度量进行最佳二分图匹配,或者设置为 1,以使用一种名为级联数据关联的新引入方法,以获得更高的准确性。级联数据关联包括多阶段匹配,根据检测和目标置信度分配不同的优先级和相似性度量。检测器对象分为两组,已确认(置信度在 [tentativeDetectorConfidence, 1.0] 之间)和暂定(置信度在 [minDetectorConfidence, tentativeDetectorConfidence] 之间)。然后按顺序执行三个阶段的匹配
已确认的检测和已验证(包括活动和非活动)目标
暂定的检测和剩余的活动目标
剩余的已确认检测和暂定目标
第一阶段使用上面定义的联合相似性度量,而后两个阶段仅考虑 IOU 相似性,因为当检测置信度较低时(例如,由于部分遮挡或噪声),邻近度可能比视觉相似性或 Re-ID 更可靠的度量。每个阶段都将不同的 bbox 集合作为候选对象,并使用高效的贪婪算法进行匹配。匹配对从每个阶段生成并组合在一起。
数据关联模块的输出由三组对象/目标组成
未匹配的检测器对象
检测器对象和现有目标的匹配对
未匹配的目标
未匹配的检测器对象是 PGIE 检测器检测到的对象之一,但尚未与任何现有目标关联。未匹配的检测器对象被视为需要跟踪的新观察对象,除非它们被确定为任何现有目标的副本。如果新检测器对象与任何现有目标的最大 IOU 得分低于 minIouDiff4NewTarget,则将创建一个新的目标跟踪器来跟踪该对象,因为它不是现有目标的副本。
目标管理和错误处理#
尽管检测器检测到了新对象(即检测器对象),但仍有可能这是误报。NvMultiObjectTracker 跟踪器库采用一种称为延迟激活的技术来抑制检测中的此类噪声,其中对新检测到的对象进行一段时间的检查,并且 仅当 它在此期间存活下来时才激活以进行长期跟踪。更具体地说,每当检测到新对象时,都会创建一个新的跟踪器来跟踪该对象,但目标最初会置于 暂定 模式,这是一个试用期,其长度由配置文件 TargetManagement 部分下的 probationAge 定义。在此试用期内,跟踪器输出不会报告给下游,因为目标尚未验证;但是,这些未报告的跟踪器输出数据(即 过去帧数据)存储在底层跟踪器中以供稍后报告。
同一目标可能会在下一帧中被检测到;但是,检测器可能会出现假阴性(即漏检),导致与目标的关联失败。NvMultiObjectTracker 库采用另一种称为影子跟踪的技术,即使目标未与检测器对象关联,目标仍然会在后台跟踪一段时间。每当目标在给定的时间帧内未与检测器对象关联时,目标的内部变量 shadowTrackingAge 就会递增。一旦目标与检测器对象关联,则 shadowTrackingAge 将重置为零。
如果目标处于暂定模式,并且 shadowTrackingAge 达到配置文件中指定的 earlyTerminationAge,则目标将提前终止(这称为提前终止)。如果目标在暂定模式期间未终止并成功与检测器对象关联,则目标将被激活并置于 活动 模式,开始将跟踪器输出报告给下游。如果启用了过去帧数据,则暂定模式期间的跟踪数据也将被报告,因为它们尚未报告。一旦目标被激活(即处于活动模式),如果目标在给定的时间帧内未关联(或跟踪器置信度低于阈值),它将被置于 非活动 模式,并且其 shadowTrackingAge 将会递增,但仍会在后台跟踪。但是,如果 shadowTrackingAge 超过 maxShadowTrackingAge,则目标将被终止。
目标跟踪器的状态转换总结在下图中
NvMultiObjectTracker 库可以在一定程度上生成唯一 ID。如果通过设置 useUniqueID: 1 启用,则在初始化阶段将为每个视频流分配一个 32 位长的随机数。从同一视频流创建的所有目标的 uint64_t 类型目标 ID 的高 32 位都将设置为每个流的随机数。同时,目标 ID 的低 32 位从 0 开始。随机生成的高 32 位数字允许特定视频流的目标 ID 从可能的 ID 空间中的随机位置开始递增。如果禁用(即 useUniqueID: 0,这是默认值),则高 32 位和低 32 位都将从 0 开始,导致目标 ID 在每次运行时都从 0 开始递增。
请注意,目标 ID 的低 32 位的递增是在同一 NvMultiObjectTracker 库实例化的所有视频流中完成的。因此,即使禁用唯一 ID 生成,对于同一管道运行,跟踪器 ID 也是唯一的。例如,如果禁用唯一 ID 生成,并且 Stream 1 有三个对象,Stream 2 有两个对象,则目标 ID 将从 0 到 4 分配(而不是 Stream 1 的 0 到 2 和 Stream 2 的 0 到 1),只要两个流都由同一库实例处理。
preserveStreamUpdateOrder 控制是使用单线程还是多线程来更新目标。如果启用此选项,则新 ID 将使用单线程按每个批次中的输入流 ID 顺序依次生成,即 Stream 1 和 2 的对象将分别具有从 0 到 2 和 3 到 4 的 ID。默认情况下,此选项被禁用,因此目标管理使用多线程完成,以实现更好的性能,但 ID 顺序不会保留。如果用户需要同一视频源在多次运行中保持一致的 ID,请在 deepstream-app 配置中设置 preserveStreamUpdateOrder: 1 和 batched-push-timeout=-1。
NvMultiObjectTracker 库在初始化期间基于以下内容预分配所有 GPU 内存
要处理的流的数量
每个流要跟踪的最大对象数(表示为
maxTargetsPerStream)
因此,NvMultiObjectTracker 库的 CPU/GPU 内存使用量几乎与正在跟踪的对象总数成线性比例,即(视频流数量) × (maxTargetsPerStream),除了依赖库(如 cuFFT™、TensorRT™ 等)使用的暂存内存空间。由于预先分配了所有必需的内存,因此即使对象数量随着时间的推移而增加,NvMultiObjectTracker 库在长期运行期间预计也不会出现内存增长。
一旦正在跟踪的对象数量达到配置的最大值(即 maxTargetsPerStream),任何新对象都将被丢弃,直到某些现有目标被终止。请注意,正在跟踪的对象数量包括在影子跟踪模式下跟踪的目标。因此,NVIDIA 建议用户将 maxTargetsPerStream 设置得足够大,以容纳一帧中可能出现的最大数量的感兴趣对象,以及可能从过去的帧中在影子跟踪模式下跟踪的对象。
低级跟踪器配置文件中 BaseConfig 部分下的 minDetectorConfidence 属性设置了置信度级别,低于该级别,检测器对象将被过滤掉。
状态估计#
NvMultiObjectTracker 库采用两种类型的状态估计器,它们都基于卡尔曼滤波器 (KF):Simple-bbox KF、Regular-bbox KF 和 Simple-location KF。Simple-bbox KF 定义了 6 个状态,即 {x, y, w, h, dx, dy},其中 x 和 y 表示目标 bbox 的左上角坐标,而 w 和 h 分别表示 bbox 的宽度和高度。dx 和 dy 表示 x 和 y 状态的速度。Regular-bbox KF 则定义了 8 个状态,即 {x, y, w, h, dx, dy, dw, dh},其中 dw 和 dh 是 w 和 h 状态的速度,其余与 Simple-bbox KF 相同。Simple-location KF 仅有 4 个状态,即 {x, y, dx, dy}。与估计 bbox 属性的两个 KF 不同,请注意 Simple-location KF 旨在估计对象在 2D 相机图像平面或 3D 世界地面平面中的位置。
所有卡尔曼滤波器类型都采用恒速模型以供通用使用。Simple-bbox 和 Regular-bbox KF 的测量向量定义为 {x, y, w, h},表示 bbox 属性,而 Simple-location KF 的测量向量定义为 {x, y}。当启用 useAspectRatio 时,可以选择使用 bbox 纵横比 a 及其速度 da 来代替 w 和 dw,NvDeepSORT 专门使用此选项。如果状态估计器用于通用用例(如 NvDCF 跟踪器中),则 {x, y}、{w, h} 和 {dx, dy, dw, dh} 的过程噪声方差可以分别通过 processNoiseVar4Loc、processNoiseVar4Size 和 processNoiseVar4Vel 进行配置。
当启用视觉跟踪器模块时(如 NvDCF 跟踪器中),从状态估计器的角度来看,可能存在两种不同的测量值:(1) 来自 PGIE 检测器的 bbox(或位置)和 (2) 来自跟踪器定位的 bbox(或位置)。这是因为 NvDCF 跟踪器模块能够使用其自身学习的滤波器来定位目标。这两种不同类型的测量的测量噪声方差可以通过 measurementNoiseVar4Detector 和 measurementNoiseVar4Tracker 进行配置。预计将根据检测器和跟踪器的特性调整或优化这些参数,以实现更好的测量融合。
NvDeepSORT 跟踪器中状态估计器的用法与上述通用用例略有不同,因为它基本上是Regular KF,但在原始论文和实现中存在一些差异(查看 NvDeepSORT 跟踪器 部分中的参考文献)
使用纵横比
a和高度h(而不是w和h)来估计 bbox 大小与边界框高度成比例(而不是常数值)的过程噪声和测量噪声
为了允许这些差异,NvMultiObjectTracker 库中的状态估计器模块具有一组额外的配置参数
useAspectRatio以启用a(而不是w)的使用noiseWeightVar4Loc和noiseWeightVar4Vel分别作为测量噪声和速度噪声的比例系数
请注意,如果设置了这两个参数,则通用用例的固定过程噪声和测量噪声参数将被忽略。
对象重识别#
重识别 (Re-ID) 使用 TensorRT™ 加速的深度神经网络从检测到的对象中提取独特的特征向量,这些特征向量对时空变化和遮挡具有鲁棒性。它在 NvMultiObjectTracker 中有两个用例:(1) 在 NvDeepSORT 中,Re-ID 相似性用于对象在连续帧之间的数据关联;(2) 在目标重关联中(将在以下部分更详细地描述),提取并保留目标的 Re-ID 特征,以便在目标看似丢失时,可以将其用于与同一目标重新关联。reidType 选择上述每个用例的模式。
在 Re-ID 模块中,检测器对象被裁剪并调整大小为 Re-ID 网络的配置输入大小。参数 keepAspc 控制裁剪后是否保留对象的纵横比。然后,NVIDIA TensorRT™ 从网络创建一个引擎,该引擎批量处理输入,并为每个检测器对象输出一个固定维度的向量作为 Re-ID 特征。余弦相似度函数要求每个特征的 L2 范数归一化为 1。请查看 Re-ID 特征输出,了解如何在跟踪器插件和下游模块中检索这些特征。对于每个目标,会在内部保留其最近帧中的 Re-ID 特征库。特征库的大小可以通过 reidHistorySize 设置。
注意
config_tracker_NvDeepSORT.yml和config_tracker_NvDCF_accuracy.yml配置默认使用 ReIdentificationNet,它是 NVIDIA TAO 工具包在 NGC 上的 ResNet-50 Re-ID 网络。用户需要按照 设置示例 Re-ID 模型 中的说明进行设置,或者查看 自定义 Re-ID 模型,以获取有关为具有不同架构和数据集的对象跟踪添加自定义 Re-ID 模型的更多信息。
检测器对象和目标之间的 Re-ID 相似度是检测器对象的 Re-ID 特征与其在目标特征库中最邻近的特征之间的余弦相似度,其值范围为 [0.0, 1.0]。具体来说,目标特征库中的每个 Re-ID 特征都与检测器对象的 Re-ID 特征进行点积运算。所有点积运算的最大值就是相似度得分,即
\[score_{ij}=\max_{k}(feature\_det_{i}\cdot feature\_track_{jk})\]
其中
\(\cdot\) 表示点积。
\(feature\_det_{i}\) 表示第 i 个检测器对象的特征。
\(feature\_track_{jk}\) 表示第 j 个目标的特征库中的第 k 个 Re-ID 特征。\(k\) = [1,
reidHistorySize]。
Re-ID 具有时空约束。如果对象移出帧或被遮挡超过 maxShadowTrackingAge,即使它返回到帧中,也会被分配一个新的 ID。
提取的 Re-ID 特征(即嵌入)可以导出到元数据,这在 Re-ID 特征输出 的单独章节中进行了解释。
目标重关联#
目标重关联算法通过共同使用 Re-ID 和时空(即运动)特征来增强多目标跟踪的长期鲁棒性。它解决了在对象以渐进或突兀的方式经历部分或完全遮挡的情况下发生的主要跟踪失败案例。在此过程中,PGIE 模块的检测器可能仅捕获对象的部分(由于部分可见性),从而导致目标上的框大小不合适、中心位置不正确。之后,由于大小和位置预测错误,目标可能无法与再次出现的对象关联,从而可能导致跟踪失败和 ID 切换。这种重关联问题通常可以作为后处理来处理;但是,对于实时分析应用程序,通常希望将其作为实时多目标跟踪的一部分无缝处理。
目标重关联利用目标管理模块中的延迟激活和影子跟踪。它尝试通过以下步骤,以无缝、实时的方式,基于运动和 Re-ID 相似性,将新出现的目标与先前丢失的目标关联起来
轨迹预测:每当现有目标在较长时间内(与 probationAge 相同)未与检测器对象关联时,则认为该目标已丢失。当视觉跟踪器模块在影子跟踪模式下跟踪目标时,将使用一些最近匹配的轨迹点(其长度由 prepLength4TrajectoryProjection 设置)生成预测轨迹段(由 trajectoryProjectionLength 配置),并将其存储到内部数据库中,直到它再次与检测器对象匹配或与另一个目标重新关联。
Re-ID 特征提取:在目标丢失之前,Re-ID 网络以 reidExtractionInterval 的帧间隔提取其 Re-ID 特征,并将它们存储在特征库中。这些特征将用于在轨迹段匹配阶段识别目标重新出现。
目标 ID 获取:当实例化新目标时,将检查其有效性几个帧(即 probationAge),并且仅在验证(即延迟激活)后才分配目标 ID,之后目标状态报告开始。在目标 ID 获取期间,将检查新目标是否与内部数据库中现有目标的预测轨迹段之一匹配,其中存储了上述预测轨迹段。如果匹配,则意味着新目标实际上是过去消失的目标的重新出现。然后,新目标将与现有目标重新关联,并且其轨迹段也将融合到其中。否则,将分配一个新的目标 ID。
轨迹片段匹配: 在上一步的轨迹片段匹配过程中,有效的候选轨迹片段会根据 maxTrackletMatchingTimeSearchRange 配置的可行时间窗口从数据库中查询。对于新的目标和每个候选目标,运动相似度和 Re-ID 相似度都会被考虑用于轨迹片段匹配。运动相似度是沿轨迹片段的平均 IOU,其标准包括最小平均 IOU 分数(即 minTrackletMatchingScore)、运动中的最大角度差(即 maxAngle4TrackletMatching)、最小速度相似度(即 minSpeedSimilarity4TrackletMatching)和最小 bbox 尺寸相似度(即 minBboxSizeSimilarity4TrackletMatching),这些都通过类似动态时间规整 (DTW) 的算法计算得出。Re-ID 相似度是新目标的 Re-ID 特征与其在候选特征库中最邻近特征之间的余弦距离。总相似度得分是两种度量的加权和。
\[totalScore=w_1*IOU+w_2*reidSimilarity\]
其中 \(w_i\) 是配置文件中为每个度量设置的权重。用户还可以为每个相似度和总分设置最小阈值。
轨迹片段融合: 一旦两个轨迹片段关联起来,它们将被融合在一起,根据检测器的匹配状态和每个点的置信度生成一个平滑的轨迹片段。
config_tracker_NvDCF_accuracy.yml 提供了一个启用此功能的示例。由于 Re-ID 计算量较大,用户可以选择增加 reidExtractionInterval 以提高性能,或者设置如下参数(即禁用 Re-ID 特征提取)以使用仅基于运动的目标重关联,而无需 Re-ID。
TrajectoryManagement: useUniqueID: 0 # Use 64-bit long Unique ID when assignining tracker ID. Default is [true] enableReAssoc: 1 # Enable Re-Assoc minMatchingScore4Overall: 0 # min matching score for overall minTrackletMatchingScore: 0.5644 # min tracklet similarity score for re-assoc matchingScoreWeight4TrackletSimilarity: 1.0 # weight for tracklet similarity score minTrajectoryLength4Projection: 36 # min trajectory length required to make projected trajectory prepLength4TrajectoryProjection: 50 # the length of the trajectory during which the state estimator is updated to make projections trajectoryProjectionLength: 94 # the length of the projected trajectory maxAngle4TrackletMatching: 106 # max angle difference for tracklet matching [degree] minSpeedSimilarity4TrackletMatching: 0.0967 # min speed similarity for tracklet matching minBboxSizeSimilarity4TrackletMatching: 0.5577 # min bbox size similarity for tracklet matching maxTrackletMatchingTimeSearchRange: 20 # the search space in time for max tracklet similarity trajectoryProjectionProcessNoiseScale: 0.0100 # trajectory projector's process noise scale w.r.t. state estimator trajectoryProjectionMeasurementNoiseScale: 100 # trajectory projector's measurement noise scale w.r.t. state estimator trackletSpacialSearchRegionScale: 0.2598 # the search region scale for peer tracklet ReID: reidType: 0 # The type of reid among { DUMMY=0, NvDEEPSORT=1, Reid based reassoc=2, both NvDEEPSORT and reid based reassoc=3}注意
目标重关联只有在状态估计器启用时才有效,否则轨迹片段预测将无法正确进行。上面提供的参数是为 PeopleNet v2.6.2 调优的,可能不适用于其他类型的检测器。
边界框取消裁剪#
另一个小型实验性功能是边界框取消裁剪。如果目标在摄像机的视场 (FOV) 内完全可见,但开始移出 FOV,则目标将部分可见,并且边界框(即 bbox)可能仅捕获目标的一部分(即被 FOV 裁剪),直到其完全退出场景。如果预期 bbox 的尺寸在视频帧边界附近变化不大,则可以使用目标完全可见时估计的 bbox 尺寸来估计 FOV 限制之外的完整 bbox。可以通过在底层配置文件中的 TargetManagement 模块下设置 enableBboxUnClipping: 1 来启用此功能。
单视图 3D 跟踪 (Alpha)#
如前所述,部分遮挡是对象跟踪器必须处理的最具挑战性的问题之一,并且经常导致跟踪失败。如果对象检测器仅捕获对象的可见部分(通常是这种情况),则部分遮挡将导致检测到的 bbox 在属性方面发生突变或渐变,这些属性包括 bbox 位置、尺寸、纵横比、置信度和最重要的 bbox 内的视觉外观。考虑到对象跟踪器依赖于 bbox 属性作为时空度量,以及 bbox 内提取的视觉外观(例如,ReID 嵌入)作为视觉相似性度量,bbox 属性的这种变化是跟踪失败的主要来源,导致更频繁的 ID 切换。
为了解决这些具有挑战性的问题,DeepStream SDK 引入了一项名为单视图 3D 跟踪 (SV3DT) 的新功能,当 (1) 为视频流提供 3x4 投影矩阵,并且 (2) 在相机信息文件中为视频流提供 3D 模型信息(如下所示)时,允许在 3D 世界坐标系(而不是 2D 相机图像平面)中执行对象跟踪。
# camInfo-01.yml # The 3x4 camera projection matrix (in row-major): # 996.229 -202.405 -9.121 -1.185 # 105.309 478.174 890.944 1.743 # -0.170 -0.859 0.481 -1085.484 projectionMatrix_3x4: - 996.229 - -202.405 - -9.121 - -1.185 - 105.309 - 478.174 - 890.944 - 1.743 - -0.170 - -0.859 - 0.481 - -1085.484 # The cylindrical human model modelInfo: height: 250.0 radius: 30.0
用户可以通过两个选项 (projectionMatrix_3x4 和 projectionMatrix_3x4_w2p) 提供相应的 3x4 相机投影矩阵,以支持不同的用例。请参阅3x4 相机投影矩阵部分了解更多详细信息。
请注意,此算法需要一些假设
人体被建模为 3D 世界坐标系中的圆柱体,具有高度和半径,高度和半径作为 3D 模型信息提供。
为视频流或相机提供 3x4 投影矩阵(将 3D 世界坐标点转换为 2D 相机图像坐标点)。
视频流是从安装高度高于人体高度的摄像机捕获的。
第三个假设确保当人体被部分遮挡时,头部仍然可见,从而允许我们使用顶部 bbox 边缘作为锚点,我们稍后将详细介绍。
对于每个人的检测边界框,SV3DT 算法尝试将 3D 人体模型拟合到检测到的 bbox,使得从世界坐标系到相机图像平面的投影 3D 人体模型的边界框与检测到的 bbox 相匹配。
下图显示了如何将圆柱形 3D 人体模型拟合到输入检测到的 bbox。
在人被部分遮挡的情况下,检测到的 bbox 的顶部边缘用作锚点,以对齐投影的 3D 人体模型的 bbox。一旦对齐,我们可以使用投影的 3D 人体模型恢复全身 bbox,就好像该人未被遮挡一样。因此,如果启用了 SV3DT,则输入检测到的 bbox 始终首先根据提供的 3D 模型信息恢复为全身 bbox,尤其是在输入检测到的 bbox 仅捕获到由于部分遮挡而导致的人的可见部分时。这大大提高了多对象跟踪的准确性和鲁棒性,因为 bbox 属性在部分遮挡过程中不会改变。
下面的动画图像显示了当人被部分遮挡时,如何将圆柱形 3D 人体模型拟合到输入检测到的 bbox 中。人物身上的细灰色 bbox 表示输入检测到的 bbox,它们仅捕获对象的可见部分。该图表明,SV3DT 算法仍然能够估计每个人的准确脚部位置。人物轨迹是根据估计的脚部位置绘制的,从而可以在场景中对人物进行稳健的时空行为分析,尽管遮挡程度不同。此示例中的一些人几乎只看到头部和肩膀,但他们被成功跟踪,就好像完全没有被遮挡一样。
作为派生指标,可见部分的 bbox 与投影的 3D 人体模型的 bbox 之间的比率可以被视为对象的大概可见性,这可能是有用的信息。
用户仍然可以通过查看 NvDsObjectMeta 中的 detector_bbox_info 来访问相应的检测到的 bbox。
为了启用 SV3DT 功能,我们在跟踪器配置文件中引入了一个新部分 ObjectModelProjection,如下所示
ObjectModelProjection: cameraModelFilepath: # In order of the source streams - 'camInfo-01.yml' - 'camInfo_02.yml' ...
每个摄像机视图都不同,因此 3x4 投影矩阵应该对每个摄像机都是唯一的。因此,相机信息文件(例如,camInfo-01.yml)需要为每个流提供,其中包括本节开头显示的 3x4 投影矩阵和模型信息。
一旦估计出与输入检测到的 bbox 相对应的 3D 人体模型并将其定位在世界坐标系中,我们想要持续估计的是人在世界地面上的脚部位置(即圆柱模型的底座中心),因为它是一个物理状态,比 2D 相机图像平面上物体的运动更能遵循运动动力学建模。为了对 3D 世界地面上物体的脚部位置执行状态估计,用户需要将状态估计器类型设置为 stateEstimatorType: 3,如下所示
StateEstimator: stateEstimatorType: 3 # the type of state estimator among { DUMMY_ESTIMATOR=0, SIMPLE_BBOX_KF=1, REGULAR_BBOX_KF=2, SIMPLE_LOCATION_KF=3 } # [Dynamics Modeling] processNoiseVar4Loc: 6810.866 # Process noise variance for location processNoiseVar4Vel: 1348.487 # Process noise variance for velocity measurementNoiseVar4Detector: 100.000 # Measurement noise variance for detector's detection measurementNoiseVar4Tracker: 293.323 # Measurement noise variance for tracker's localization
可用于调试或可视化的附加杂项数据是投影的 3D 人体模型在 2D 相机图像平面上的凸包。通过使用每个对象的凸包数据,用户还可以创建如图所示的可视化效果。
启用 SV3DT 时生成的附加杂项数据包括 (1) 可见性,(2) 世界平面和 2D 图像中的脚部位置,以及 (3) 凸包(投影到 2D 图像上的人体圆柱体)。这些数据可以保存在文本文件中和/或输出到对象元数据以供下游使用。为此,用户需要在 ObjectModelProjection 部分分别设置 outputVisibility: 1、outputFootLocation: 1、outputConvexHull: 1。示例用例包括在低级跟踪器的终止轨迹转储中保存,在 deepstream-app 的 KITTI 轨迹转储中附加,以及通过 Gst-nvmsgconv 将它们转换为架构。
为了方便用户轻松试用和体验 SV3DT,SV3DT 的示例用例已托管在 GitHub 上。因此,用户只需克隆并使用提供的示例数据运行即可。
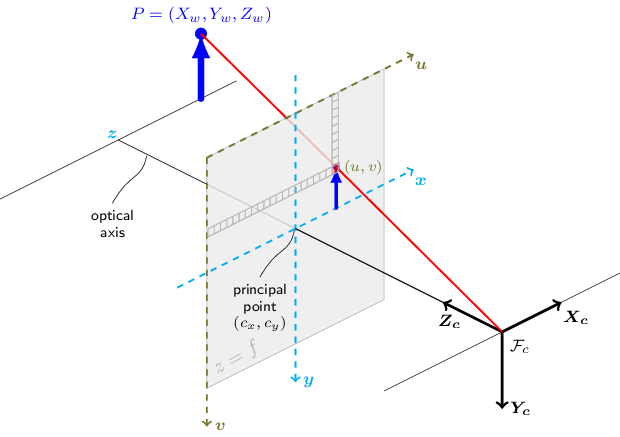
3x4 相机投影矩阵#
3x4 相机投影矩阵也简称为相机矩阵,它是一个 3x4 矩阵,根据针孔相机模型(如下图所示)将 3D 世界点转换为相机图像平面上的 2D 点
{kind=link}
有关相机矩阵的更详细和一般信息,可以在处理计算机视觉几何和相机校准的各种来源中找到,包括 OpenCV 关于相机校准的文档。
对于相机模型文件(例如 camInfo-01.yml)中的 projectionMatrix_3x4,相机矩阵中的主点(即 (Cx, Cy))假定位于 (0, 0) 作为图像坐标。但是,光心(即 (Cx, Cy))位于图像中心(即 (img_width/2, img_height/2))。因此,为了将原点移动到相机图像的左上角(即像素坐标),SV3DT 在使用 projectionMatrix_3x4 中提供的相机矩阵进行变换后,内部添加 (img_width/2, img_height/2)。
如果 3x4 相机投影矩阵已经考虑了主点的这种平移,则用户可以在 projectionMatrix_3x4_w2p 中提供相机矩阵。这假设 3x4 相机投影矩阵将 3D 世界点直接转换为实际像素点,像素点的原点位于图像的左上角,因此不需要对主点进行任何进一步的平移。
配置参数#
下表总结了 NvMultiObjectTracker 低级跟踪器库中常用模块的配置参数。
模块 |
属性 |
含义 |
类型和范围 |
默认值 |
|---|---|---|---|---|
基本配置 |
minDetectorConfidence |
有效对象的最小检测器置信度 |
浮点数,-inf 到 inf |
minDetectorConfidence: 0.0 |
目标管理 |
preserveStreamUpdateOrder |
是否确保目标 ID 更新顺序与输入流 ID 顺序相同 |
布尔值 |
preserveStreamUpdateOrder: 0 |
maxTargetsPerStream |
每个流要跟踪的最大目标数 |
整数,0 到 65535 |
maxTargetsPerStream: 30 |
|
minIouDiff4NewTarget |
丢弃新目标的最小 IOU 与现有目标的差异 |
浮点数,0 到 1 |
minIouDiff4NewTarget: 0.5 |
|
enableBboxUnClipping |
启用边界框取消裁剪 |
布尔值 |
enableBboxUnClipping: 0 |
|
probationAge |
试用期长度,以帧数为单位 |
整数,≥0 |
probationAge: 5 |
|
maxShadowTrackingAge |
阴影跟踪的最大长度 |
整数,≥0 |
maxShadowTrackingAge: 38 |
|
earlyTerminationAge |
提前终止年龄 |
整数,≥0 |
earlyTerminationAge: 2 |
|
outputTerminatedTracks |
将终止轨迹的总帧历史记录输出到跟踪器插件以供下游使用 |
布尔值 |
outputTerminatedTracks: 0 |
|
outputShadowTracks |
将阴影轨迹状态信息输出到跟踪器插件以供下游使用 |
布尔值 |
outputShadowTracks: 0 |
|
terminatedTrackFilename |
保存终止轨迹的文件名前缀 |
字符串 |
terminatedTrackFilename: “” |
|
轨迹管理 |
useUniqueID |
启用唯一 ID 生成方案 |
布尔值 |
useUniqueID: 0 |
enableReAssoc |
启用基于运动的目标重关联 |
布尔值 |
enableReAssoc: 0 |
|
minMatchingScore4Overall |
重关联的最小总分 |
浮点数,0.0 到 1.0 |
minMatchingScore4Overall: 0.4 |
|
minTrackletMatchingScore |
轨迹片段之间平均 IOU 方面用于匹配的最小轨迹片段相似度得分 |
浮点数,0.0 到 1.0 |
minTrackletMatchingScore: 0.4 |
|
minMatchingScore4ReidSimilarity |
重关联的最小 ReID 得分 |
浮点数,0.0 到 1.0 |
minMatchingScore4ReidSimilarity: 0.8 |
|
matchingScoreWeight4TrackletSimilarity |
重关联成本函数中轨迹片段相似度项的权重 |
浮点数,0.0 到 1.0 |
matchingScoreWeight4TrackletSimilarity: 1.0 |
|
matchingScoreWeight4ReidSimilarity |
重关联成本函数中 ReID 相似度项的权重 |
浮点数,0.0 到 1.0 |
matchingScoreWeight4ReidSimilarity: 0.0 |
|
minTrajectoryLength4Projection |
执行轨迹投影的目标的最小轨迹片段长度(即年龄)[帧] |
整数,>=0 |
minTrajectoryLength4Projection: 20 |
|
prepLength4TrajectoryProjection |
状态估计器更新以进行投影的轨迹长度 [帧] |
整数,>=0 |
prepLength4TrajectoryProjection: 10 |
|
trajectoryProjectionLength |
投影轨迹的长度 [帧] |
整数,>=0 |
trajectoryProjectionLength: 90 |
|
maxAngle4TrackletMatching |
轨迹片段匹配的最大角度差 [度] |
整数,[0, 180] |
maxAngle4TrackletMatching: 40 |
|
minSpeedSimilarity4TrackletMatching |
轨迹片段匹配的最小速度相似度 |
浮点数,0.0 到 1.0 |
minSpeedSimilarity4TrackletMatching: 0.3 |
|
minBboxSizeSimilarity4TrackletMatching |
轨迹片段匹配的最小 bbox 尺寸相似度 |
浮点数,0.0 到 1.0 |
minBboxSizeSimilarity4TrackletMatching: 0.6 |
|
maxTrackletMatchingTimeSearchRange |
最大轨迹片段相似度的时间搜索空间 |
整数,>=0 |
maxTrackletMatchingTimeSearchRange: 20 |
|
trajectoryProjectionProcessNoiseScale |
轨迹状态估计器的过程噪声比例 |
浮点数,0.0 到 inf |
trajectoryProjectionProcessNoiseScale: 1.0 |
|
trajectoryProjectionMeasurement NoiseScale |
轨迹状态估计器的测量噪声比例 |
浮点数,0.0 到 inf |
trajectoryProjectionMeasurement NoiseScale: 1.0 |
|
trackletSpacialSearchRegionScale |
重关联对等轨迹片段搜索区域比例 |
浮点数,0.0 到 inf |
trackletSpacialSearchRegionScale: 0.0 |
|
reidExtractionInterval |
每目标提取 ReID 特征以进行重关联的帧间隔;-1 表示仅提取每目标的起始帧 |
整数,≥-1 |
reidExtractionInterval: 0 |
|
数据关联器 |
associationMatcherType |
匹配算法的类型 { GREEDY=0, CASCADED=1 } |
整数,[0, 1] |
associationMatcherType: 0 |
checkClassMatch |
仅启用关联相同类别的对象 |
布尔值 |
||
minMatchingScore4Overall |
有效匹配的最小总分 |
浮点数,0.0 到 1.0 |
minMatchingScore4Overall: 0.0 |
|
minMatchingScore4SizeSimilarity |
有效匹配的最小 bbox 尺寸相似度得分 |
浮点数,0.0 到 1.0 |
minMatchingScore4SizeSimilarity: 0.0 |
|
minMatchingScore4Iou |
有效匹配的最小 IOU 得分 |
浮点数,0.0 到 1.0 |
minMatchingScore4Iou: 0.0 |
|
matchingScoreWeight4SizeSimilarity |
匹配成本函数中尺寸相似度项的权重 |
浮点数,0.0 到 1.0 |
matchingScoreWeight4SizeSimilarity: 0.0 |
|
matchingScoreWeight4Iou |
匹配成本函数中 IOU 项的权重 |
浮点数,0.0 到 1.0 |
matchingScoreWeight4Iou: 1.0 |
|
tentativeDetectorConfidence |
如果检测的置信度低于此值但高于 minDetectorConfidence,则将其视为试探性检测 |
浮点数,0.0 到 1.0 |
tentativeDetectorConfidence: 0.5 |
|
minMatchingScore4TentativeIou |
匹配目标和试探性检测的最小 iou 阈值 |
浮点数,0.0 到 1.0 |
minMatchingScore4TentativeIou: 0.0 |
|
状态估计器 |
stateEstimatorType |
状态估计器的类型,包括 { DUMMY=0, SIMPLE=1, REGULAR=2, SIMPLE_LOC=3 } |
整数,[0,3] |
stateEstimatorType: 0 |
processNoiseVar4Loc |
bbox 中心的过程噪声方差 |
浮点数,0.0 到 inf |
processNoiseVar4Loc: 2.0 |
|
processNoiseVar4Size |
bbox 尺寸的过程噪声方差 |
浮点数,0.0 到 inf |
processNoiseVar4Size: 1.0 |
|
processNoiseVar4Vel |
速度的过程噪声方差 |
浮点数,0.0 到 inf |
processNoiseVar4Vel: 0.1 |
|
measurementNoiseVar4Detector |
检测器的检测的测量噪声方差 |
浮点数,0.0 到 inf |
measurementNoiseVar4Detector: 4.0 |
|
measurementNoiseVar4Tracker |
跟踪器定位的测量噪声方差 |
浮点数,0.0 到 inf |
measurementNoiseVar4Tracker: 16.0 |
|
noiseWeightVar4Loc |
bbox 位置的噪声协方差权重;如果设置,位置噪声将与框高度成正比 |
浮点数,>0.0 视为已设置 |
noiseWeightVar4Loc: -0.1 |
|
noiseWeightVar4Vel |
bbox 速度的噪声协方差权重;如果设置,位置噪声将与框高度成正比 |
浮点数,>0.0 视为已设置 |
noiseWeightVar4Vel: -0.1 |
|
useAspectRatio |
在卡尔曼滤波器的状态中使用纵横比 |
布尔值 |
useAspectRatio: 0 |
|
对象 Re-ID |
reidType |
Re-ID 网络的类型,包括 { DUMMY=0, NvDEEPSORT=1, 基于 Reid 的重关联=2, NvDEEPSORT 和基于 reid 的重关联=3 } |
整数,[0, 3] |
reidType: 0 |
batchSize |
Re-ID 网络的批处理大小 |
整数,>0 |
batchSize: 1 |
|
workspaceSize |
Re-ID TensorRT 引擎要使用的工作区大小,以 MB 为单位 |
整数,>0 |
workspaceSize: 20 |
|
reidFeatureSize |
Re-ID 特征的大小 |
整数,>0 |
reidFeatureSize: 128 |
|
reidHistorySize |
特征库的大小,即为一个跟踪器保留的最大 Re-ID 特征数 |
整数,>0 |
reidHistorySize: 100 |
|
inferDims |
Re-ID 网络输入维度 CHW 或 HWC,基于 inputOrder |
整数,>0 |
inferDims: [128, 64, 3] |
|
inputOrder |
Re-ID 网络输入顺序 {NCHW=0, NHWC=1} |
整数,[0, 1] |
inputOrder: 1 |
|
colorFormat |
Re-ID 网络输入颜色格式,包括 {RGB=0, BGR=1 } |
整数,[0, 1] |
colorFormat: 0 |
|
networkMode |
Re-ID 网络推理精度模式,包括 {FP32=0, FP16=1, INT8=2 } |
整数,[0, 1, 2] |
networkMode: 0 |
|
offsets |
要从每个输入通道中减去的值数组,长度等于通道数 |
逗号分隔的浮点数数组 |
offsets: [0.0, 0.0, 0.0] |
|
netScaleFactor |
减去偏移量后 Re-ID 网络输入的比例因子 |
浮点数,>0 |
netScaleFactor: 1.0 |
|
addFeatureNormalization |
如果 Re-ID 网络的输出 Re-ID 特征向量未进行 l2 归一化,则显式执行 l2 归一化 |
布尔值 |
addFeatureNormalization: 0 |
|
tltEncodedModel |
TAO 工具包编码模型的路径名 |
字符串 |
tltEncodedModel: “” |
|
tltModelKey |
TAO 工具包编码模型的密钥 |
字符串 |
tltModelKey: “” |
|
onnxFile |
ONNX 模型文件的路径名 |
字符串 |
onnxFile: “” |
|
modelEngineFile |
Re-ID 引擎文件的绝对路径 |
字符串 |
modelEngineFile:”” |
|
calibrationTableFile |
校准表的绝对路径,仅 INT8 需要 |
字符串 |
calibrationTableFile:”” |
|
keepAspc |
在调整输入对象到 Re-ID 网络的大小时,是否保持纵横比 |
布尔值 |
keepAspc: 1 |
|
outputReidTensor |
将 Re-ID 特征输出到用户元数据以供下游使用 |
布尔值 |
outputReidTensor: 0 |
|
useVPICropScaler (Alpha 功能) |
使用 NVIDIA 的 VPI™ Crop Scaler 算法而不是内置实现 |
布尔值 |
useVPICropScaler: 0 |
|
对象模型投影 |
cameraModelFilepath |
相机信息文件的文件路径列表。应为每个视频流提供有效的相机信息文件 |
字符串 |
cameraModelFilepath: “” |
outputVisibility |
将对象可见性输出到对象元数据和文件转储 |
布尔值 |
outputVisibility: 0 |
|
outputFootLocation |
将对象(特别是人)的脚部位置输出到对象元数据和文件转储 |
布尔值 |
outputFootLocation: 0 |
|
outputConvexHull |
将投影的对象凸包(特别是人的圆柱体)输出到对象元数据和文件转储 |
布尔值 |
outputConvexHull: 1 |
|
maxConvexHullSize |
构成对象凸包的最大点数 |
整数,>0 |
maxConvexHullSize: 15 |
低级跟踪器比较和权衡#
DeepStream SDK 提供了四个参考低级跟踪器库,它们在准确性、鲁棒性和效率方面具有不同的资源需求和性能特征,允许用户根据其用例和要求选择最佳跟踪器。请参阅下表进行比较。
跟踪器类型 |
GPU 计算 |
CPU 计算 |
优点 |
缺点 |
最佳用例 |
|---|---|---|---|---|---|
IOU |
否 |
非常低 |
|
|
|
NvSORT |
否 |
非常低 |
|
|
|
NvDeepSORT |
高 |
低 |
|
|
|
NvDCF |
中等 |
低 |
|
|
|
IOU 跟踪器#
NvMultiObjectTracker 库提供了一个对象跟踪器,该跟踪器仅具有多对象跟踪的基本和最小功能集,称为 IOU 跟踪器。IOU 跟踪器仅执行以下功能
来自新视频帧的检测器对象与先前视频帧中的现有目标之间的贪婪数据关联
基于数据关联结果的目标管理,包括目标状态更新以及目标的创建和终止
诸如延迟激活和阴影跟踪之类的错误处理机制是 NvMultiObjectTracker 库的目标管理模块的组成部分;因此,这些功能在 IOU 跟踪器中固有地启用。
IOU 跟踪器可以用作性能基线,因为它消耗最少的计算资源。DeepStream SDK 包中提供了示例配置文件 config_tracker_IOU.yml。
NvSORT 跟踪器#
NvSORT 跟踪器在 IOU 跟踪器的基础上,通过以下改进提高了跟踪精度,同时保持了高性能
使用卡尔曼滤波器进行状态估计,以更好地估计和预测当前帧中目标的状态。
级联数据关联,根据目标和检测器对象的接近程度和置信度在多个阶段关联它们,这比原始 SORT 跟踪器中的简单匹配更准确。
由于 NvSORT 完全依赖于 bbox 属性进行数据关联,因此 NvSORT 的跟踪精度完全归因于检测精度。借助中等或高精度检测器,NvSORT 可以以最少的计算资源生成高质量的跟踪结果。DeepStream SDK 包中提供了示例配置文件 config_tracker_NvSORT.yml。
NvDeepSORT 跟踪器#
NvDeepSORT 跟踪器利用基于深度学习的对象外观信息,在不同帧和位置中实现准确的对象匹配,从而增强了在遮挡情况下的鲁棒性并减少了 ID 切换。它应用预训练的重识别 (Re-ID) 神经网络来提取每个对象的特征向量,使用余弦距离度量比较不同对象之间的相似度,并将其与状态估计器结合以执行跨帧的数据关联。在运行 NvDeepSORT 之前,需要按照 设置示例 Re-ID 模型 和 自定义 Re-ID 模型 设置 Re-ID 模型。
数据关联#
对于 NvDeepSORT 跟踪器中的数据关联,使用了两个指标
邻近度
基于 Re-ID 的相似度
对于邻近度得分,使用目标的预测位置及其相关的不确定性计算第 i 个检测器对象和第 j 个目标之间的马氏距离
\[dist_{ij}=(D_i-Y_j)^TS_j^{-1}(D_i-Y_j)\]
其中
\(D_i\) 表示
{x, y, a, h}格式的第 i 个检测器对象。\(Y_j\) 表示来自第 j 个跟踪器的状态估计器的预测状态
{x', y', a', h'}。\(S_j\) 表示来自第 j 个跟踪器的状态估计器的预测协方差。
在原始 DeepSORT 实现中,检测器对象和目标的有效对的最大马氏距离阈值设置为 9.4877,表示从逆卡方分布计算出的 95% 置信度。请注意,在 NvDeepSORT 中,该值由跟踪器配置中的 thresholdMahalanobis 配置,以针对特定的检测器模型(例如 PeopleNet v2.6.2)实现更高的精度,因此它可能与原始实现中的值不同。
在滤除无效对后,Re-ID 相似度得分计算为检测器对象和目标之间的最大余弦相似度。然后,级联数据关联算法用于高精度多阶段匹配。
配置参数#
DeepStream SDK 包中提供了示例配置文件 config_tracker_NvDeepSORT.yml。下表总结了 NvDeepSORT 的配置参数。
模块 |
属性 |
含义 |
类型和范围 |
默认值 |
|---|---|---|---|---|
数据关联器 |
thresholdMahalanobis |
基于卡方概率的最大马氏距离 |
Float,>0 时视为已设置 |
thresholdMahalanobis: -1.0 |
minMatchingScore4ReidSimilarity |
匹配目标和临时检测的最小 Re-ID 阈值 |
浮点数,0.0 到 1.0 |
minMatchingScore4ReidSimilarity: 0.0 |
|
matchingScoreWeight4ReIDSimilarity |
匹配代价函数中 Re-ID 相似性项的权重 |
浮点数,0.0 到 1.0 |
matchingScoreWeight4ReIDSimilarity: 0.0 |
实现细节和参考#
NvDeepSORT 与原始实现之间的区别包括:
对于数据关联,原始实现基于跟踪年龄按升序对目标进行排序,并按年龄顺序为每个年龄运行匹配算法,而 NvDeepSORT 应用级联数据关联算法,具有更高的性能和准确性。
NvMultiObjectTracker 库中的 NvDeepSORT 实现采用了与 NvDCF 跟踪器相同的目标管理策略,这比原始 DeepSORT 更先进。
两个特征的余弦距离度量为 \(score_{ij}=1-feature\_det_{i}\cdot feature\_track_{jk}\),值越小表示相似度越高。相比之下,NvDeepSORT 直接使用点积以提高计算效率,因此值越大表示相似度越高。
参考:Wojke, Nicolai, Alex Bewley, 和 Dietrich Paulus。“Simple online and real-time tracking with a deep association metric.” 2017 IEEE international conference on image processing (ICIP). IEEE, 2017。查看 论文 和 Github 上的原始实现。
NvDCF 跟踪器#
NvDCF 跟踪器采用基于判别相关滤波器 (DCF) 的视觉跟踪器,用于学习特定于目标的 correlation filter,并使用学习到的 correlation filter 在后续帧中定位同一目标。这种 correlation filter 学习和定位通常在典型的 MOT 实现中以 per-object 为基础进行,当在 GPU 上处理时,可能会产生大量小的 CUDA kernel 启动。这本身在最大化 GPU 利用率方面带来了挑战,尤其是在预期在单个 GPU 上跟踪来自多个视频流的大量对象时。
为了解决此类性能问题,NvDCF 跟踪器的 GPU 加速操作被设计为在批处理模式下执行,以最大化 GPU 利用率,尽管 per-object 跟踪模型中存在小型 CUDA kernel 的特性。批处理模式应用于整个跟踪操作,包括 bbox 裁剪和缩放、视觉特征提取、correlation filter 学习和定位。这可以被视为类似于 batched cuFFT 或 batched cuBLAS 调用的模型,但不同之处在于,批处理 MOT 执行模型跨越了更高层次的许多操作。批处理能力从多对象批处理扩展到多流批处理,以实现更高的效率和可扩展性。
得益于其视觉跟踪能力,即使 PGIE 中的检测器漏检目标(即假阴性),NvDCF 跟踪器也可以定位和跟踪目标,这可能是由部分或完全遮挡引起的长时间,从而实现更强大的跟踪。增强的鲁棒性特性允许用户使用更高的 maxShadowTrackingAge 值进行更长期的对象跟踪,并且还允许 PGIE 的 interval 值更高,而仅以轻微的精度下降为代价。
与 NvSORT 和 NvDeepSORT 中卡尔曼滤波器仅将检测 bbox 作为输入不同,NvDCF 跟踪器中的卡尔曼滤波器还将视觉跟踪模块的定位结果作为输入。一旦目标被跟踪,视觉跟踪器会不断尝试使用学习到的 correlation filter 在后续帧中定位同一目标,同时可能存在匹配的检测器 bbox。NvDCF 跟踪器中的卡尔曼滤波器融合了基于 DCF 的定位结果和检测器 bbox,以实现更好的目标状态估计和预测。
视觉跟踪#
对于每个跟踪目标,NvDCF 跟踪器在其下一帧的 预测 位置周围定义一个搜索区域,该区域足够大,以便在搜索区域中检测到同一目标。searchRegionPaddingScale 属性确定搜索区域的大小,该大小是目标边界框对角线的倍数。搜索区域的大小将确定为:
\[ \begin{align}\begin{aligned}SearchRegion_{width}=w+searchRegionPaddingScale*\sqrt{w*h}\\SearchRegion_{height}=h+searchRegionPaddingScale*\sqrt{w*h}\end{aligned}\end{align} \]
,其中 \(w\) 和 \(h\) 分别是目标边界框的宽度和高度。
一旦为每个目标在其预测位置定义了搜索区域,则从每个搜索区域裁剪和缩放图像块到预定义的特征图像大小,从中提取视觉特征。featureImgSizeLevel 属性定义了特征图像的大小,其范围为 1 到 5。1 到 5 之间的每个级别分别对应于每个特征通道的 12x12、18x18、24x24、30x30 和 36x36。较低的 featureImgSizeLevel 值会导致 NvDCF 使用较小的特征尺寸,可能会提高 GPU 性能,但会牺牲精度和鲁棒性。配置参数时,请考虑 featureImgSizeLevel 和 searchRegionPaddingScale 之间的关系。如果增加 searchRegionPaddingScale 而 featureImgSizeLevel 固定,则特征图像中对应于目标本身的像素数量将有效减少。
对于每个裁剪的图像块,提取视觉外观特征,例如 ColorNames 和/或 Histogram-of-Oriented-Gradient (HOG)。要使用的视觉特征类型可以通过设置 useColorNames 和/或 useHog 进行配置。HOG 特征由 18 个通道组成,基于不同方向的 bin 数量,而 ColorNames 特征有 10 个通道。如果同时使用这两种特征(通过设置 useColorNames: 1 和 useHog: 1),则通道总数将为 28。因此,如果同时使用 HOG 和 ColorNames 并设置 featureImgSizeLevel: 5,则表示目标的视觉特征的维度将为 28x48x48。使用的视觉特征通道越多,精度越高,但会增加计算复杂性并降低性能。NvDCF 跟踪器使用 NVIDIA 的 VPI™ 库来提取这些视觉特征。
correlation filter 是使用应用于目标 bbox 中心的注意力窗口(使用 Hanning 窗口)生成的。允许用户在垂直方向上移动注意力窗口的中心。例如,featureFocusOffsetFactor_y: -0.2 将导致注意力窗口的中心位于特征图中的 y=-0.2,其中高度的相对范围为 [-0.5, 0.5]。考虑到典型的监控或闭路电视摄像机安装在适度高的位置以监控环境的广阔区域,例如零售商店或交通路口。从这些有利位置来看,其他人员或车辆可能会在人员或车辆的下半身发生更多遮挡。将注意力窗口向上移动一点可能会提高这些用例的准确性和鲁棒性。
一旦为目标生成 correlation filter,典型的基于 DCF 的跟踪器通常会在创建和更新连续帧上的最佳 correlation filter 时采用指数移动平均以实现时间一致性。correlation filter 及其通道权重的此移动平均的学习率可以通过 filterLr 和 filterChannelWeightsLr 分别配置。用于创建最佳 DCF filter 时所需响应的高斯标准差也可以通过 gaussianSigma 进行配置。
计算后端
NvDCF 中的视觉跟踪器模块支持多个计算后端:CUDA/GPU 和 PVA (Programmable Vision Accelerator)。因此,允许用户根据特定用例使用不同的计算后端。
PVA 是 NVIDIA Jetson 设备中 Tegra SOC 中的加速器,专门用于图像处理和计算机视觉算法,具有极低的功耗。当在 Jetson 上使用跟踪器运行基于 DeepStream 的 pipeline 时,建议在 NvDCF 中对 DCF 操作使用 PVA 后端,以获得更好的电源效率。由于 DCF 操作的基于 GPU 的处理被卸载到 PVA 上,因此,更多的 GPU 资源可供用户用于任何需要基于 GPU 的处理的下游或自定义处理。
为了使用 PVA 后端,视觉跟踪器模块利用 NVIDIA 的 VPI™ 提供的 API,可以通过在 Jetson 平台上设置 visualTrackerType: 2 (Alpha 功能)和 vpiBackend4DcfTracker: 2 # {CUDA=1, PVA=2} 来启用。VPI 还具有 CUDA 后端模式,可以通过在任何受支持的 HW 平台(Jetson 或 dGPU 平台)上设置 vpiBackend4DcfTracker: 1 来配置。
由 VPI™ 提供的 DCF 操作的 PVA 后端实现目前具有以下限制:
单个跟踪器库实例可以支持的最大对象数为 512。这转化为 DeepStream 配置中的以下限制:
当未启用子批处理时,跨所有流跟踪的对象总数(即,批处理中的流数 *
maxTargetsPerStream)应小于或等于 512。当启用子批处理时,子批处理中跨所有流跟踪的对象总数(即,子批处理中的流数 *
maxTargetsPerStream)应小于或等于 512。如果有 N 个子批次,则可以在 pipeline 中跟踪的对象总数实际上是
N*512。
仅支持以下三个配置的组合:
useColorNames: 1、useHog: 1和featureImgSizeLevel: 3
VPI™ 提供的 DCF API 的另一个限制是,单个库实例支持的最大流数为 33。因此,要使用 visualTrackerType: 2 运行具有更高批处理大小 (>33) 的 DS 应用程序,建议在跟踪器插件中使用 子批处理 功能,以便每个子批次的大小小于或等于 33 个流。
数据关联#
跨帧关联目标 ID 以实现鲁棒跟踪通常需要基于视觉外观的相似性匹配,为此,在每个候选位置提取视觉外观特征。通常,这是一个计算量大的过程,并且通常充当对象跟踪中的性能瓶颈。与从所有候选位置提取视觉特征并在所有候选对象之间执行特征匹配的现有方法不同,NvDCF 跟踪器利用相关响应(这已经在目标定位阶段获得)作为每个跟踪器在搜索区域上的跟踪置信度图,并且只需查找每个候选位置(即,每个检测器对象的位置)的置信度值,即可获得视觉相似性,而无需任何显式计算。通过比较跟踪器之间的这些置信度,我们可以识别哪个跟踪器对特定检测器对象具有更高的视觉相似性,并将其用作数据关联的匹配分数的一部分。因此,数据关联过程中的视觉相似性匹配可以通过对现有相关响应进行简单的查找表 (LUT) 操作来非常有效地执行。
在下面的动画图中,左侧显示搜索区域内的目标,而右侧显示相关响应图(其中深红色表示更高的置信度,深蓝色表示更低的置信度)。在置信度图中,中心周围的黄色十字(即 +)表示相关响应的峰值位置,而紫色 x 表示附近检测器 bbox 的中心。这些紫色 x 位置的相关响应值指示在视觉相似性方面同一目标在该位置存在的可能性置信度分数。

如果目标周围有多个检测器 bbox(即紫色 x),如下图所示,则数据关联模块将根据视觉相似性分数以及配置的权重和最小值(分别为 matchingScoreWeight4VisualSimilarity 和 minMatchingScore4VisualSimilarity)来处理匹配。

配置参数#
作为 DeepStream SDK 软件包的一部分,提供了一些 NvDCF 跟踪器的示例配置文件,命名为:
config_tracker_NvDCF_max_perf.ymlconfig_tracker_NvDCF_perf.ymlconfig_tracker_NvDCF_accuracy.yml
第一个 max_perf 配置文件将 NvDCF 跟踪器配置为消耗最少的资源,而第二个 perf 配置文件用于需要性能和精度之间良好平衡的用例。最后一个 accuracy 配置文件通过启用大多数功能以发挥其全部能力(尤其是目标重关联)来最大化精度和鲁棒性。
下表总结了 NvDCF 低级跟踪器的配置文件中使用的配置参数(除了前面章节中已提及的通用模块和参数)。
模块 |
属性 |
含义 |
类型和范围 |
默认值 |
|---|---|---|---|---|
视觉跟踪器 |
visualTrackerType |
视觉跟踪器的类型,取值范围为 { DUMMY=0, NvDCF=1, NvDCF_VPI=2 } NvDCF_VPI 是 Alpha 功能。 |
Int, [0, 1, 2] |
visualTrackerType: 0 |
useColorNames |
使用 ColorNames 特征 |
布尔值 |
useColorNames: 1 |
|
useHog |
使用 Histogram-of-Oriented-Gradient (HOG) 特征 |
布尔值 |
useHog: 0 |
|
featureImgSizeLevel |
特征图像的大小 |
Integer, 1 to 5 |
featureImgSizeLevel: 2 |
|
featureFocusOffsetFactor_y |
hanning 窗口中心相对于特征高度的偏移量 |
Float, -0.5 to 0.5 |
featureFocusOffsetFactor_y: 0.0 |
|
useHighPrecisionFeature |
是否使用 16 位高精度特征;否则使用 8 位 |
布尔值 |
useHighPrecisionFeature: 0 |
|
filterLr |
指数移动平均中 DCF 滤波器的学习率 |
浮点数,0.0 到 1.0 |
filterLr: 0.075 |
|
filterChannelWeightsLr |
DCF 中不同特征通道权重的学习率 |
浮点数,0.0 到 1.0 |
filterChannelWeightsLr: 0.1 |
|
gaussianSigma |
所需响应的高斯标准差 |
Float, >0.0 |
gaussianSigma: 0.75 |
|
vpiBackend4DcfTracker |
计算后端,取值范围为 {CUDA=1, PVA=2} 当 visualTrackerType: 2 时有效 |
Int, [1,2] |
vpiBackend4DcfTracker: 1 |
|
目标管理 |
searchRegionPaddingScale |
搜索区域大小 |
Integer, 1 to 3 |
searchRegionPaddingScale: 1 |
minTrackerConfidence |
有效目标的最小检测器置信度 |
浮点数,0.0 到 1.0 |
minTrackerConfidence: 0.6 |
|
数据关联器 |
minMatchingScore4 VisualSimilarity |
有效匹配的最小视觉相似性分数 |
浮点数,0.0 到 1.0 |
minMatchingScore4 VisualSimilarity: 0.0 |
matchingScoreWeight4 VisualSimilarity |
匹配代价函数中视觉相似性项的权重 |
浮点数,0.0 到 1.0 |
matchingScoreWeight4 VisualSimilarity: 0.0 |
另请参阅 跟踪器设置和参数调整中的故障排除 部分,了解跟踪器行为和调整中常见问题的解决方案。
杂项数据输出#
杂项数据提供了一种机制,用于将 Gst Buffer 或 NvDsBatchMeta 之外的其他数据返回给用户。杂项数据缓冲区仅在为特定功能启用选项时才会填充。目前支持的杂项数据类型有:
终止的轨迹列表
阴影跟踪目标数据
过去帧目标数据
每种数据类型在杂项数据中都有唯一的输出变量;但是,它们共享一个通用的数据结构,使用统一的 NvDsTargetMiscDataBatch 数据结构。缓冲区池用于其内存管理,其大小可以使用 user-meta-pool-size 设置。当下游插件释放缓冲区的延迟过长时,缓冲区池可能为空,因此跟踪器将跳过报告下一个批次的杂项数据。将显示警告 gstnvtracker: Unable to acquire a user meta buffer,用户可以将池大小从默认值 32 增加到更大的值,如 64。以下各节定义了每种杂项数据的具体信息。
终止的轨迹列表#
每当目标终止时,完整的目标轨迹数据可以作为杂项数据的一部分导出到元数据,该数据在 NvDsTargetMiscDataBatch 数据结构中填充。此数据不仅通知目标的终止事件,而且对于执行每个对象的基于轨迹的分析的下游模块也很有用。
终止的轨迹列表可以以 deepstream-app 或低级跟踪器库内的文件形式保存:
(选项 1)在
deepstream-app中保存输出在跟踪器配置
TargetManagement部分中添加outputTerminatedTracks: 1在
deepstream-app配置的 application group 属性中添加terminated-track-output-dir=<dir name>创建文件夹
<dir name>运行
deepstream-app以将终止的轨迹历史记录保存到<dir name>中的文本文件中数据格式定义如下。
帧号 |
对象唯一 ID |
类别 ID |
空白 |
空白 |
bbox 左 |
bbox 上 |
bbox 右 |
bbox 下 |
空白 |
空白 |
空白 |
空白 |
空白 |
空白 |
空白 |
置信度 |
跟踪器状态 |
可见性 |
无符号整数 |
长无符号整数 |
无符号整数 |
整数 |
浮点数 |
浮点数 |
浮点数 |
浮点数 |
浮点数 |
浮点数 |
浮点数 |
浮点数 |
浮点数 |
浮点数 |
浮点数 |
浮点数 |
浮点数 |
整数 |
浮点数 |
将为每个流中的每一帧创建一个文件。示例数据如下:
0 7 2 0 0.0 1535.194092 94.266541 1603.132812 301.653625 0.0 0.0 0.0 0.0 0.0 0.0 0.0 1.000000 2 1.000000 1 7 2 0 0.0 1535.938232 94.234810 1603.121338 301.769501 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.982758 2 1.000000 ...
(选项 2)直接从低级跟踪器保存输出
在跟踪器配置
TargetManagement部分中添加outputTerminatedTracks: 1在跟踪器配置
TargetManagement部分中添加terminatedTrackFilename: <file name prefix>。例如,设置terminatedTrackFilename: track_dump,保存的文件名将为track_dump_0.txt、track_dump_1.txt等。运行
deepstream-app以直接从低级跟踪器库保存终止的轨迹信息数据格式定义如下。足部位置和凸包数据仅在启用 SV3DT 输出时才有用。
帧号(从 1 开始) |
对象唯一 ID |
bbox 左 |
bbox 上 |
bbox 右 |
bbox 下 |
置信度 |
足部世界坐标 X |
足部世界坐标 Y |
空白 |
类别 ID |
跟踪器状态 |
可见性 |
足部图像坐标 X |
足部图像坐标 Y |
凸包点(可选) |
无符号整数 |
长无符号整数 |
整数 |
整数 |
整数 |
整数 |
浮点数 |
浮点数 |
浮点数 |
整数 |
无符号整数 |
整数 |
浮点数 |
浮点数 |
浮点数 |
整数,用竖线分隔 |
将为每个流创建一个文件。示例数据如下:
# SV3DT output disabled 31,48,558,104,31,74,0.949,-1.000,-1.000,-1,0,0.994,-1,-1 32,48,558,104,31,74,0.951,-1.000,-1.000,-1,0,0.995,-1,-1 ... # SV3DT output enabled 31,48,558,104,31,74,0.949,1254.535,2962.867,-1,0,0.994,581,176,-15|-34|-14|-35|-13|-35|-10|-36|-6|-36|-3|-36|0|-36|1|-36|2|-35|16|35|15|35|13|36|9|37|6|37|3|37|0|37|0|36 32,48,558,104,31,74,0.951,1255.602,2968.294,-1,0,0.995,581,176,-14|-34|-14|-35|-13|-35|-10|-35|-6|-36|-3|-36|0|-36|1|-36|2|-35|15|35|15|35|13|36|9|37|6|37|3|37|0|37|0|36 ...
阴影跟踪目标数据#
如前所述,即使目标未与任何检测 bbox 关联,目标仍然以阴影跟踪模式进行跟踪。当以阴影跟踪模式跟踪时,目标数据不会报告给下游,因为目标数据可能不可靠。
但是,当在跟踪器配置文件中的 TargetManagement 部分下设置 outputShadowTracks: 1 时,用户仍然可以将这些阴影跟踪目标数据作为杂项数据的一部分报告。
当在 deepstream-app 中启用时,阴影跟踪数据可以转储到文件中,如下所示:
在
deepstream-app配置的 application group 属性中添加shadow-track-output-dir=<dir name>创建文件夹
<dir name>运行
deepstream-app以将阴影轨迹历史记录保存到<dir name>中的文本文件中数据格式定义如下。
帧号 |
对象唯一 ID |
类别 ID |
空白 |
空白 |
bbox 左 |
bbox 上 |
bbox 右 |
bbox 下 |
空白 |
空白 |
空白 |
空白 |
空白 |
空白 |
空白 |
置信度 |
跟踪器状态 |
可见性 |
无符号整数 |
长无符号整数 |
无符号整数 |
整数 |
浮点数 |
浮点数 |
浮点数 |
浮点数 |
浮点数 |
浮点数 |
浮点数 |
浮点数 |
浮点数 |
浮点数 |
浮点数 |
浮点数 |
浮点数 |
整数 |
浮点数 |
将为每个流中的每一帧创建一个文件。示例数据如下:
1 11 2 0 0.0 296.346130 262.343445 333.428864 376.817291 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.407002 2 1.000000 1 22 2 0 0.0 1663.921875 857.167725 1752.483521 1049.053223 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.912138 2 1.000000 ...
重要提示
当后续帧到达时,终止的轨迹数据和阴影跟踪对象数据都不会保留在低级跟踪器库中。因此,如果用户想要使用这些数据,他们应该在插件中每一帧结束时使用 NvMOT_RetrieveMiscData() API 检索这些杂项数据。否则,数据将在跟踪器库中被丢弃。
过去帧目标数据#
过去帧目标数据始终在杂项数据中报告,并在启用时附加到跟踪器 KITTI 转储中的当前帧对象。
要启用跟踪器 KITTI 转储:
在
deepstream-app配置的 application group 属性中添加kitti-track-output-dir=<dir name>创建文件夹
<dir name>运行
deepstream-app以将跟踪的对象文件保存在<dir name>中。数据格式定义如下,遵循 KITTI 格式。如果启用 SV3DT 输出,足部位置和可见性数据将附加到每行的末尾。
对象标签 |
对象唯一 ID |
空白 |
空白 |
空白 |
bbox 左 |
bbox 上 |
bbox 右 |
bbox 下 |
空白 |
空白 |
空白 |
空白 |
空白 |
空白 |
空白 |
置信度 |
可见性(可选) |
足部图像坐标 X(可选) |
足部图像坐标 Y(可选) |
字符串 |
长无符号整数 |
浮点数 |
整数 |
浮点数 |
浮点数 |
浮点数 |
浮点数 |
浮点数 |
浮点数 |
浮点数 |
浮点数 |
浮点数 |
浮点数 |
浮点数 |
浮点数 |
浮点数 |
浮点数 |
浮点数 |
浮点数 |
将为每个流中的每一帧创建一个文件。示例数据如下:
# SV3DT output disabled person 0 0.0 0 0.0 1302.667236 135.852036 1340.975830 241.724579 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.917301 person 1 0.0 0 0.0 878.249023 195.080475 913.410950 320.695618 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.899029 ... # SV3DT output enabled person 0 0.0 0 0.0 1302.667236 135.852036 1340.975830 241.724579 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.917301 0.966531 1314.492554 239.495193 person 1 0.0 0 0.0 878.249023 195.080475 913.410950 320.695618 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.899029 0.930824 899.187500 316.670013 ...
Re-ID 模型的设置和使用#
本节介绍如何在不同格式中下载和设置 Re-ID 模型,执行 INT8 校准以优化性能,以及将 Re-ID 特征输出到下游模块。
设置示例 Re-ID 模型#
支持的 Re-ID 模型格式为 NVIDIA TAO 和 ONNX。下面列出了多个即用型示例模型。用于用户设置模型的脚本和 README 文件在 sources/tracker_ReID 中提供。
注意
TensorRT 不再支持 UFF,因此请迁移到 TAO 或 ONNX 模型。
NVIDIA TAO ReIdentificationNet#
NVIDIA 预训练的 ReIdentificationNet 是一个高精度的 ResNet-50 模型,特征长度为 256。可以使用以下命令直接下载和使用:
mkdir /opt/nvidia/deepstream/deepstream/samples/models/Tracker/
wget 'https://api.ngc.nvidia.com/v2/models/nvidia/tao/reidentificationnet/versions/deployable_v1.0/files/resnet50_market1501.etlt' -P /opt/nvidia/deepstream/deepstream/samples/models/Tracker/
跟踪器配置文件默认支持此模型。请注意,来自此网络的原始输出未进行 L2 归一化,因此设置了 addFeatureNormalization: 1 以添加 L2 归一化作为后处理。
ONNX 模型#
一个开源的 ONNX 模型示例是 Simple Cues Lead to a Strong Multi-Object Tracker,它提出了一种使用 on-the-fly 域自适应的新 Re-ID 模型。该网络基于 ResNet-50,特征长度为 512。
mkdir /opt/nvidia/deepstream/deepstream/samples/models/Tracker/
wget 'https://vision.in.tum.de/webshare/u/seidensc/GHOST/ghost_reid.onnx' -P /opt/nvidia/deepstream/deepstream/samples/models/Tracker/
然后在跟踪器配置文件 ReID 会话中更新以下参数(保持 reidType 不变)。
ReID:
batchSize: 100
workspaceSize: 1000
reidFeatureSize: 512
reidHistorySize: 100
inferDims: [3,384, 128]
networkMode: 1
# [Input Preprocessing]
inputOrder: 0
colorFormat: 0
offsets: [109.1250, 102.6000, 91.3500]
netScaleFactor: 0.01742919
keepAspc: 1
# [Paths and Names]
onnxFile: "/opt/nvidia/deepstream/deepstream/samples/models/Tracker/ghost_reid.onnx"
自定义 Re-ID 模型#
用户还可以训练 ONNX 格式的自定义 Re-ID 模型,其输出是每个对象的单个向量。然后,Re-ID 相似性分数将基于余弦度量计算,并以与官方模型相同的方式用于执行数据关联。步骤如下:
使用深度学习框架(如 PyTorch 或 TensorFlow)训练 Re-ID 网络。
确保网络层受 TensorRT 支持,并将模型转换为 ONNX。仍然支持混合精度推理,INT8 模式需要校准缓存。
根据自定义模型的属性在跟踪器配置文件中指定以下参数。然后使用新的 Re-ID 模型运行 DeepStream SDK。
reidFeatureSizereidHistorySizeinferDimscolorFormatnetworkModeoffsetsnetScaleFactoraddFeatureNormalization
ONNX 模型必须指定以下参数。
onnxFile
Re-ID 特征输出#
对象的 Re-ID 特征可以在跟踪器插件和下游模块中访问,可用于其他任务,例如多目标多摄像头跟踪。使用 deepstream-app 检索这些特征的步骤如下:
在跟踪器配置
ReID部分中添加outputReidTensor: 1。在deepstream-app配置的 application group 属性中添加reid-track-output-dir=<dir name>,并创建文件夹<dir name>。运行
deepstream-app以将每帧的 Re-ID 特征保存到<dir name>中的文本文件中。在每个文本文件中,每行的第一个整数是对象 ID,其余浮点数是其特征向量。用户可以查看deepstream_app.c中的write_reid_track_output()以了解如何检索这些特征。
只要使用 NvDeepSORT 或基于 Re-ID 的重关联,就支持此功能。要检索每帧的 Re-ID 特征,请确保 PGIE 配置中的 interval=0 和启用重关联时的 reidExtractionInterval: 0。否则,仅当 PGIE 生成边界框并且满足 reidExtractionInterval 时,Re-ID 特征才会在间隔提取。
子批处理的设置和使用 (Alpha)#
本节介绍如何将 sub-batching 功能与多个低级跟踪器配置文件一起使用。解释了两个用例:第一个用例使用不同的跟踪器算法,第二个用例使用不同的计算后端。
在此,我们以 deepstream-app 管道为例。
用例 1#
此用例说明了一个批大小为 4(即 4 个流)的应用程序。该批次被分成 3 个子批次:第一个子批次大小为 2,接下来的两个子批次大小均为 1。第一个子批次使用 NvDCF 跟踪器,第二个子批次使用 NvSORT 跟踪器,第三个子批次分别使用 IOU 跟踪器。为了实现这一点,请修改 DeepStream 软件包随附的 source4_1080p_dec_infer-resnet_tracker_sgie_tiled_display_int8.txt 配置文件中的 [tracker] 部分,如下所示
[tracker]
enable=1
tracker-width=960
tracker-height=544
ll-lib-file=/opt/nvidia/deepstream/deepstream/lib/libnvds_nvmultiobjecttracker.so
ll-config-file=config_tracker_NvDCF_accuracy.yml;config_tracker_NvSORT.yml;config_tracker_IOU.yml
sub-batches=0,1;2;3
在此示例中,sub-batches 也可以使用选项 2 进行配置,即 sub-batches=2:1:1。有关详细信息,请参阅 Gst 属性。
用例 2#
此用例说明了一个批大小为 4 的应用程序,其中批次被分成 2 个子批次,每个子批次大小为 2:第一个子批次使用 NvDCF 跟踪器,设置 visualTrackerType: 1(即,现有的 DCF 模块)。第二个子批次使用 NvDCF 跟踪器,设置 visualTrackerType: 2 和 vpiBackend4DcfTracker: 2(即,带有 PVA 后端的 NvDCF_VPI 跟踪器)。请注意,由于此用例配置了 PVA 后端,因此它将仅在 Jetson 平台上运行。
步骤如下
创建
config_tracker_NvDCF_accuracy.yml的副本,并将其命名为config_tracker_NvDCF_accuracy_PVA.yml在
config_tracker_NvDCF_accuracy_PVA.yml中,按如下方式修改VisualTracker:部分VisualTracker: visualTrackerType: 2 # the type of visual tracker among { DUMMY=0, NvDCF=1, NvDCF_VPI=2 } vpiBackend4DcfTracker: 2 # the type of compute backend among {CUDA=1, PVA=2} ....
然后,按如下方式修改
source4_1080p_dec_infer-resnet_tracker_sgie_tiled_display_int8.txt中的[tracker]部分[tracker] enable=1 tracker-width=960 tracker-height=544 ll-lib-file=/opt/nvidia/deepstream/deepstream/lib/libnvds_nvmultiobjecttracker.so ll-config-file=config_tracker_NvDCF_accuracy.yml;config_tracker_NvDCF_accuracy_PVA.yml sub-batches=0,1;2,3
在此示例中,sub-batches 也可以使用选项 2 进行配置,即 sub-batches=2:2。有关详细信息,请参阅 Gst 属性。
有关子批次功能实现的更多详细信息,请参阅 nvtracker 插件源代码中 nvtracker_proc.cpp 末尾的文档。
管道的最佳 sub-batches 配置取决于多个因素,例如管道中的元素、每个元素的配置、硬件配置等。增加子批次的数量会并行化批次中流的处理。但它也会增加开销。因此,需要通过实验比较各种 sub-batches 配置的 GPU/PVA 利用率和性能来确定要配置的子批次数量。一个经验法则是从单个批次开始,并不断将其拆分为子批次,直到达到最佳性能点。
跟踪器示例管道的设置和可视化#
本节介绍如何使用各种 NVIDIA® 预训练检测器模型和 DeepStream 多对象跟踪器设置多对象跟踪管道,并提供针对高精度跟踪优化的即用型检测器和跟踪器配置文件。DeepStream 发行包中已提供人员跟踪的最佳跟踪器配置(例如,config_tracker_NvSORT.yml、config_tracker_NvDeepSORT.yml、config_tracker_NvDCF_accuracy.yml 等),因此此处我们仅介绍优化的检测器参数。然后,展示了一些示例输出和内部状态的可视化(例如,一些选定目标的关联响应),以帮助用户更好地理解 NvDsTracker 的工作原理,尤其是在视觉跟踪器模块上。此外,我们还介绍了车辆跟踪用例的检测器配置参数和跟踪器配置参数。
人员跟踪#
NVIDIA® 预训练的 PeopleNet 检测人员、包和面部类别。带有 ResNet-34 主干的预训练模型位于 NVIDIA NGC 目录。它可以与各种低级跟踪器结合使用在 PGIE 模块中进行人员跟踪。
设置#
此处以 deepstream-app 管道为例,它可以自然地扩展到其他应用程序。步骤如下
从此处下载检测器模型文件,并将文件放置在
/opt/nvidia/deepstream/deepstream/samples/models/peoplenet下将以下部分中的检测器配置文件
config_infer_primary_PeopleNet.txt复制到特定低级跟踪器(例如 PeopleNet + NvDCF)的工作目录中:cp config_infer_primary_PeopleNet.txt /opt/nvidia/deepstream/deepstream/samples/configs/deepstream-app假设
deepstream-app配置文件是/opt/nvidia/deepstream/deepstream/samples/configs/deepstream-app/deepstream_app_config.txt,请在其中设置 PGIE 和跟踪器配置文件
deepstream_app_config.txt
## Other groups
[primary-gie]
## Use PeopleNet as PGIE
config-file=config_infer_primary_PeopleNet.txt
## Other [primary-gie] configs
[tracker]
## Specify the low level tracker (for example NvSORT)
# ll-config-file=config_tracker_IOU.yml
ll-config-file=config_tracker_NvSORT.yml
# ll-config-file=config_tracker_NvDCF_perf.yml
# ll-config-file=config_tracker_NvDCF_accuracy.yml
# ll-config-file=config_tracker_NvDeepSORT.yml
## Other [tracker] configs
/opt/nvidia/deepstream 是默认的 DeepStream 安装目录。如果用户在不同的目录中设置,则路径将有所不同。
PeopleNet + NvSORT#
此管道执行高性能人员跟踪,具有合理的准确性。这样的 deepstream-app 管道由以下组件构成
检测器:PeopleNet v2.6.2(带有 ResNet-34 作为主干)
对象检测的后处理算法:混合聚类(即,DBSCAN + NMS)
跟踪器:NvSORT,在 DeepStream 发行版中使用
config_tracker_NvSORT.yml配置
一组建议的与 NvSORT 跟踪器一起使用的 PeopleNet v2.6.2 检测器配置参数是
config_infer_primary_PeopleNet.txt
[property]
## model-specific params. The paths will be different if the user sets up in different directory.
int8-calib-file=../../models/peoplenet/resnet34_peoplenet_int8.txt
labelfile-path=../../models/peoplenet/labels.txt
onnx-file=../../models/peoplenet/resnet34_peoplenet.onnx
tlt-model-key=tlt_encode
gpu-id=0
net-scale-factor=0.00392156862745098
input-dims=3;544;960
process-mode=1
model-color-format=0
## 0=FP32, 1=INT8, 2=FP16 mode
network-mode=1
num-detected-classes=3
interval=0
gie-unique-id=1
## 1=DBSCAN, 2=NMS, 3= DBSCAN+NMS Hybrid, 4 = None(No clustering)
cluster-mode=3
maintain-aspect-ratio=1
[class-attrs-all]
pre-cluster-threshold=0.1555
nms-iou-threshold=0.3386
minBoxes=2
dbscan-min-score=1.9224
eps=0.3596
detected-min-w=20
detected-min-h=20
PeopleNet + NvDeepSORT#
此管道在跟踪期间启用人员 Re-ID 功能。这样的 deepstream-app 管道由以下组件构成
检测器:PeopleNet v2.6.2(带有 ResNet-34 作为主干)
对象检测的后处理算法:混合聚类(即,DBSCAN + NMS)
跟踪器:NvDeepSORT,在 DeepStream 发行版中使用
config_tracker_NvDeepSORT.yml配置
一组建议的与 NvDeepSORT 跟踪器一起使用的 PeopleNet v2.6.2 检测器配置参数是
config_infer_primary_PeopleNet.txt
[property]
## model-specific params. The paths will be different if the user sets up in different directory.
int8-calib-file=../../models/peoplenet/resnet34_peoplenet_int8.txt
labelfile-path=../../models/peoplenet/labels.txt
onnx-file=../../models/peoplenet/resnet34_peoplenet.onnx
tlt-model-key=tlt_encode
gpu-id=0
net-scale-factor=0.00392156862745098
input-dims=3;544;960
process-mode=1
model-color-format=0
## 0=FP32, 1=INT8, 2=FP16 mode
network-mode=1
num-detected-classes=3
interval=0
gie-unique-id=1
## 1=DBSCAN, 2=NMS, 3= DBSCAN+NMS Hybrid, 4 = None(No clustering)
cluster-mode=3
maintain-aspect-ratio=1
[class-attrs-all]
pre-cluster-threshold=0.1653
nms-iou-threshold=0.5242
minBoxes=2
dbscan-min-score=1.7550
eps=0.1702
detected-min-w=20
detected-min-h=20
PeopleNet + NvDCF#
此管道执行更准确的人员跟踪。对于输出可视化,首先构建一个具有以下组件的 deepstream-app 管道
检测器:PeopleNet v2.6.2(带有 ResNet-34 作为主干)
对象检测的后处理算法:混合聚类(即,DBSCAN + NMS)
跟踪器:NvDCF,在 DeepStream 发行版中使用
config_tracker_NvDCF_accuracy.yml配置
为了更好的可视化,还进行了以下更改
featureImgSizeLevel: 5在config_tracker_NvDCF_accuracy.yml的VisualTracker部分下设置tracker-height=960和tracker-width=544在 deepstream-app 配置文件中的[tracker]部分下设置
一组建议的与 NvDCF_accuracy 跟踪器一起使用的 PeopleNet v2.6.2 检测器配置参数是
config_infer_primary_PeopleNet.txt
[property]
## model-specific params. The paths will be different if the user sets up in different directory.
int8-calib-file=../../models/peoplenet/resnet34_peoplenet_int8.txt
labelfile-path=../../models/peoplenet/labels.txt
onnx-file=../../models/peoplenet/resnet34_peoplenet.onnx
tlt-model-key=tlt_encode
gpu-id=0
net-scale-factor=0.00392156862745098
input-dims=3;544;960
process-mode=1
model-color-format=0
## 0=FP32, 1=INT8, 2=FP16 mode
network-mode=1
num-detected-classes=3
interval=0
gie-unique-id=1
## 1=DBSCAN, 2=NMS, 3= DBSCAN+NMS Hybrid, 4 = None(No clustering)
cluster-mode=3
maintain-aspect-ratio=1
[class-attrs-all]
pre-cluster-threshold=0.1429
nms-iou-threshold=0.4688
minBoxes=3
dbscan-min-score=0.7726
eps=0.2538
detected-min-w=20
detected-min-h=20
上述管道(PeopleNet + 混合聚类 + NvDCF)的结果输出视频如下所示,但请注意,视频中仅检测和显示“Person”类对象
虽然上面的视频显示了每流输出,但下面的每个动画图都显示了 (1) 用于每个目标的裁剪和缩放图像块(左侧)和 (2) 目标对应的相关响应图(右侧)。如前所述,黄色 + 标记显示了使用学习的相关滤波器生成的关联响应图的峰值位置,而紫色 x 标记显示了附近检测器对象的中心。
人员 1(戴蓝色帽子 + 灰色背包) 
|
人员 6(穿红色外套 + 灰色背包) 
|
人员 4(穿绿色外套) 
|
人员 5(穿青色外套) 
|
上面的图显示了在没有遮挡、部分遮挡和完全遮挡发生的情况下,相关响应如何随时间推移。可以看出,即使目标长时间完全遮挡,NvDCF 跟踪器在许多情况下也能够保持对目标的跟踪。
如果使用 featureImgSizeLevel: 3 以获得更好的性能,则用于每个目标的图像块的分辨率将降低,如下图所示。
人员 1(戴蓝色帽子 + 灰色背包) 
|
人员 6(穿红色外套 + 灰色背包) 
|
车辆跟踪#
为了执行车辆和其他类型目标(例如行人、自行车和道路标志)的跟踪,NVIDIA® 预训练检测器模型可在 NGC 中找到
TrafficCamNet:一种基于 ResNet-18 主干的新型模型,在 NVIDIA NGC 上具有更高的检测精度。
以下示例演示了使用 TrafficCamNet 和各种跟踪器,采用不同的检测间隔,以权衡性能和准确性。
设置#
此处以 deepstream-app 管道为例,它可以自然地扩展到其他应用程序。设置管道的步骤如下
对于 TrafficCamNet,从此处下载检测器模型文件,并将文件放置在
/opt/nvidia/deepstream/deepstream/samples/models/trafficcamnet下将以下部分中的检测器和跟踪器配置文件复制到特定跟踪器类型(例如 TrafficCamNet + NvDCF)的工作目录中:
cp config_infer_primary_TrafficCamNet.txt /opt/nvidia/deepstream/deepstream/samples/configs/deepstream-app假设
deepstream-app配置文件是/opt/nvidia/deepstream/deepstream/samples/configs/deepstream-app/deepstream_app_config.txt,请在其中设置检测器和跟踪器配置文件,如下所示
deepstream_app_config.txt
## Other groups
[primary-gie]
## Use TrafficCamNet as PGIE
config-file=config_infer_primary_TrafficCamNet.txt
## Other [primary-gie] configs
[tracker]
## Specify the low level tracker (for example NvDCF_accuracy)
# ll-config-file=config_tracker_IOU.yml
# ll-config-file=config_tracker_NvSORT.yml
# ll-config-file=config_tracker_NvDCF_perf.yml
ll-config-file=config_tracker_NvDCF_accuracy.yml
# ll-config-file=config_tracker_NvDeepSORT.yml
## Other [tracker] configs
/opt/nvidia/deepstream 是默认的 DeepStream 安装目录。如果用户在不同的目录中设置,则路径将有所不同。
TrafficCamNet + NvSORT#
此管道执行高性能车辆跟踪,具有合理的准确性。这样的 deepstream-app 管道由以下组件构成
检测器:TrafficCamNet v1.0.3(带有 ResNet-18 作为主干)
对象检测的后处理算法:混合聚类(即,DBSCAN + NMS)
跟踪器:NvSORT,配置如下
检测器和跟踪器配置文件
config_infer_primary_TrafficCamNet.txt
[property]
## model-specific params. The paths will be different if the user sets up in different directory.
int8-calib-file=../../models/trafficcamnet/resnet18_trafficcamnet_pruned_int8.txt
labelfile-path=../../models/trafficcamnet/labels.txt
onnx-file=../../models/trafficcamnet/resnet18_trafficcamnet_pruned.onnx
tlt-model-key=tlt_encode
gpu-id=0
net-scale-factor=0.00392156862745098
input-dims=3;544;960
process-mode=1
model-color-format=0
## 0=FP32, 1=INT8, 2=FP16 mode
network-mode=1
num-detected-classes=4
interval=0
gie-unique-id=1
## 1=DBSCAN, 2=NMS, 3= DBSCAN+NMS Hybrid, 4 = None(No clustering)
cluster-mode=3
maintain-aspect-ratio=0
[class-attrs-all]
pre-cluster-threshold=0.2327
nms-iou-threshold=0.1760
minBoxes=2
dbscan-min-score=0.7062
eps=0.4807
detected-min-w=20
detected-min-h=20
config_tracker_NvSORT.yml
%YAML:1.0
BaseConfig:
minDetectorConfidence: 0.0415
TargetManagement:
enableBboxUnClipping: 0
maxTargetsPerStream: 300
minIouDiff4NewTarget: 0.6974
minTrackerConfidence: 0.8049
probationAge: 5
maxShadowTrackingAge: 42
earlyTerminationAge: 1
TrajectoryManagement:
useUniqueID: 0
DataAssociator:
dataAssociatorType: 0
associationMatcherType: 1
checkClassMatch: 1
minMatchingScore4Overall: 0.2042
minMatchingScore4SizeSimilarity: 0.2607
minMatchingScore4Iou: 0.3708
matchingScoreWeight4SizeSimilarity: 0.2639
matchingScoreWeight4Iou: 0.4384
tentativeDetectorConfidence: 0.1054
minMatchingScore4TentativeIou: 0.4953
usePrediction4Assoc: 1
StateEstimator:
stateEstimatorType: 2
noiseWeightVar4Loc: 0.0853
noiseWeightVar4Vel: 0.0061
useAspectRatio: 1
TrafficCamNet + NvDeepSORT#
此管道在跟踪期间启用车辆 Re-ID 功能。这样的 deepstream-app 管道由以下组件构成
检测器:TrafficCamNet v1.0.3(带有 ResNet-18 作为主干)
对象检测的后处理算法:混合聚类(即,DBSCAN + NMS)
跟踪器:NvDeepSORT,配置如下。DeepStream 目前未包含车辆 Re-ID 模型,因此用户需要按照 自定义 Re-ID 模型 设置车辆 Re-ID 模型并更改跟踪器配置中的 ReID 部分。
检测器和跟踪器配置文件
config_infer_primary_TrafficCamNet.txt
[property]
## model-specific params. The paths will be different if the user sets up in different directory.
int8-calib-file=../../models/trafficcamnet/resnet18_trafficcamnet_pruned_int8.txt
labelfile-path=../../models/trafficcamnet/labels.txt
onnx-file=../../models/trafficcamnet/resnet18_trafficcamnet_pruned.onnx
tlt-model-key=tlt_encode
gpu-id=0
net-scale-factor=0.00392156862745098
input-dims=3;544;960
process-mode=1
model-color-format=0
## 0=FP32, 1=INT8, 2=FP16 mode
network-mode=1
num-detected-classes=4
interval=0
gie-unique-id=1
## 1=DBSCAN, 2=NMS, 3= DBSCAN+NMS Hybrid, 4 = None(No clustering)
cluster-mode=3
maintain-aspect-ratio=0
[class-attrs-all]
pre-cluster-threshold=0.1654
nms-iou-threshold=0.7614
minBoxes=3
dbscan-min-score=2.4240
eps=0.3615
detected-min-w=20
detected-min-h=20
config_tracker_NvDeepSORT.yml
%YAML:1.0
BaseConfig:
minDetectorConfidence: 0.0451
TargetManagement:
preserveStreamUpdateOrder: 0
maxTargetsPerStream: 150
minIouDiff4NewTarget: 0.0602
minTrackerConfidence: 0.7312
probationAge: 9
maxShadowTrackingAge: 59
earlyTerminationAge: 1
TrajectoryManagement:
useUniqueID: 0
DataAssociator:
dataAssociatorType: 0
associationMatcherType: 1
checkClassMatch: 1
thresholdMahalanobis: 34.3052
minMatchingScore4Overall: 0.0231
minMatchingScore4SizeSimilarity: 0.3104
minMatchingScore4Iou: 0.3280
minMatchingScore4ReidSimilarity: 0.6805
matchingScoreWeight4SizeSimilarity: 0.7103
matchingScoreWeight4Iou: 0.5429
matchingScoreWeight4ReidSimilarity: 0.6408
tentativeDetectorConfidence: 0.0483
minMatchingScore4TentativeIou: 0.5093
StateEstimator:
stateEstimatorType: 2
noiseWeightVar4Loc: 0.0739
noiseWeightVar4Vel: 0.0097
useAspectRatio: 1
ReID: # need customization
reidType: 1
batchSize: 100
workspaceSize: 1000
reidFeatureSize: 128
reidHistorySize: 100
inferDims: [128, 64, 3]
networkMode: 0
inputOrder: 1
colorFormat: 0
offsets: [0.0, 0.0, 0.0]
netScaleFactor: 1.0000
keepAspc: 1
# custom Re-ID model path
TrafficCamNet + NvDCF#
此管道执行更准确的车辆跟踪。对于输出可视化,首先构建一个具有以下组件的 deepstream-app 管道
检测器:TrafficCamNet v1.0.3(带有 ResNet-18 作为主干)
对象检测的后处理算法:混合聚类(即,DBSCAN + NMS)
跟踪器:NvDCF,配置如下。DeepStream 目前未包含车辆 Re-ID 模型,因此用户需要按照 自定义 Re-ID 模型 设置车辆 Re-ID 模型并更改跟踪器配置中的 ReID 部分。
检测器和跟踪器配置文件
config_infer_primary_TrafficCamNet.txt
[property]
## model-specific params. The paths will be different if the user sets up in different directory.
int8-calib-file=../../models/trafficcamnet/trafficcamnet_int8.txt
labelfile-path=../../models/trafficcamnet/labels.txt
tlt-encoded-model=../../models/trafficcamnet/resnet18_trafficcamnet_pruned.etlt
tlt-model-key=tlt_encode
gpu-id=0
net-scale-factor=0.00392156862745098
input-dims=3;544;960
uff-input-blob-name=input_1
process-mode=1
model-color-format=0
## 0=FP32, 1=INT8, 2=FP16 mode
network-mode=1
num-detected-classes=4
interval=0
gie-unique-id=1
output-blob-names=output_cov/Sigmoid;output_bbox/BiasAdd
## 1=DBSCAN, 2=NMS, 3= DBSCAN+NMS Hybrid, 4 = None(No clustering)
cluster-mode=3
maintain-aspect-ratio=0
[class-attrs-all]
pre-cluster-threshold=0.3034
nms-iou-threshold=0.5002
minBoxes=3
dbscan-min-score=1.2998
eps=0.1508
detected-min-w=20
detected-min-h=20
config_tracker_NvDCF_accuracy.yml
%YAML:1.0
BaseConfig:
minDetectorConfidence: 0.0382
TargetManagement:
enableBboxUnClipping: 0
preserveStreamUpdateOrder: 0
maxTargetsPerStream: 150
minIouDiff4NewTarget: 0.1356
minTrackerConfidence: 0.2136
probationAge: 1
maxShadowTrackingAge: 49
earlyTerminationAge: 1
TrajectoryManagement:
useUniqueID: 0
enableReAssoc: 1
minMatchingScore4Overall: 0.0324
minTrackletMatchingScore: 0.2979
minMatchingScore4ReidSimilarity: 0.4329
matchingScoreWeight4TrackletSimilarity: 0.5117
matchingScoreWeight4ReidSimilarity: 0.8356
minTrajectoryLength4Projection: 14
prepLength4TrajectoryProjection: 50
trajectoryProjectionLength: 116
maxAngle4TrackletMatching: 180
minSpeedSimilarity4TrackletMatching: 0
minBboxSizeSimilarity4TrackletMatching: 0.2154
maxTrackletMatchingTimeSearchRange: 16
trajectoryProjectionProcessNoiseScale: 0.0100
trajectoryProjectionMeasurementNoiseScale: 100
trackletSpacialSearchRegionScale: 0.0742
reidExtractionInterval: 2
enableVanishingTrackletReconstruction: 0
minInclusionRatio4DuplicateTrackletRemoval: 0.5705
minIou4DuplicateTrackletRemoval: 0.5260
minMatchRatio4ValidTrackletDetermination: 0.4385
minVisibility4VanishingTrackletReconstruction: 0.3485
visibilityThreshold4VanishingTrackletDetection: 0.5817
DataAssociator:
dataAssociatorType: 0
associationMatcherType: 1
checkClassMatch: 1
minMatchingScore4Overall: 0.1103
minMatchingScore4SizeSimilarity: 0.0392
minMatchingScore4Iou: 0.0980
minMatchingScore4VisualSimilarity: 0.3234
matchingScoreWeight4VisualSimilarity: 0.4223
matchingScoreWeight4SizeSimilarity: 0.8416
matchingScoreWeight4Iou: 0.6517
tentativeDetectorConfidence: 0.0198
minMatchingScore4TentativeIou: 0.1844
StateEstimator:
stateEstimatorType: 1
processNoiseVar4Loc: 374.6508
processNoiseVar4Size: 3364.1350
processNoiseVar4Vel: 3.6082
measurementNoiseVar4Detector: 164.4517
measurementNoiseVar4Tracker: 3439.5683
VisualTracker:
visualTrackerType: 1
useColorNames: 1
useHog: 1
featureImgSizeLevel: 4
featureFocusOffsetFactor_y: 0.0652
filterLr: 0.0993
filterChannelWeightsLr: 0.0549
gaussianSigma: 0.9047
ReID: # need customization
reidType: 2
batchSize: 100
workspaceSize: 1000
reidFeatureSize: 128
reidHistorySize: 148
inferDims: [128, 64, 3]
networkMode: 0
inputOrder: 1
colorFormat: 0
offsets: [0.0, 0.0, 0.0]
netScaleFactor: 1.0000
keepAspc: 1
# onnxFile: customize_onnx_path
下面是 TrafficCamNet 与不同跟踪器在具有大量遮挡的具有挑战性的场景中的并排比较。从左上角顺时针方向依次是仅检测、NvSORT、NvDeepSORT 和 NvDCF 的结果。NvDCF 具有最高的跟踪精度和遮挡鲁棒性。
跟踪器精度调整#
上一节中演示的跟踪器示例管道包含许多针对人员跟踪优化的检测器和跟踪器参数。当用户将此类管道部署到其他场景(例如交通、动物等)时,一个痛点是如何为每个用例找到具有最高精度 KPI 的最佳参数。手动参数调整需要深入了解跟踪器算法以及每个参数如何影响功能。鉴于参数数量众多,此过程的复杂性将呈指数级增长。
从 DeepStream 7.0 开始,发布了一个新工具 PipeTuner,以实现自动精度调整。它可以有效地探索(可能非常高维的)参数空间,并自动找到管道的最佳参数,从而在数据集上产生最高的 KPI。用户可以根据自己的用例,在公共多对象跟踪数据集(例如 MOT Challenge、KITTI)上调整跟踪器,或者使用示例视频和地面实况(边界框和对象 ID)创建自己的数据集。用户可以选择常见的跟踪精度指标,包括 HOTA、MOTA 和 IDF1 作为 KPI。请访问 精度调整工具,了解如何设置 PipeTuner 并开始 DeepStream 跟踪器精度调整。
如何实现自定义低级跟踪器库#
要编写自定义低级跟踪器库,用户需要实现 sources/includes/nvdstracker.h 中定义的 API,这在前面关于 NvDsTracker API 的部分中已介绍,并且部分 API 参考了 sources/includes/nvbufsurface.h。因此,用户需要包含 nvdstracker.h 来实现 API
#include "nvdstracker.h"
下面是每个 API 的示例实现。假设低级跟踪器库定义并实现了一个自定义类(例如,下面示例代码中的 NvMOTContext 类)来执行与每个 API 调用对应的实际操作。下面是初始化和反初始化 API 的示例代码
注意
下面的示例代码仅包含一些框架。用户需要根据需要添加适当的错误处理和其他代码
NvMOTStatus NvMOT_Init(NvMOTConfig *pConfigIn, NvMOTContextHandle *pContextHandle, NvMOTConfigResponse *pConfigResponse) { if(pContextHandle != nullptr) { NvMOT_DeInit(*pContextHandle); } /// User-defined class for the context NvMOTContext *pContext = nullptr; /// Instantiate the user-defined context pContext = new NvMOTContext(*pConfigIn, *pConfigResponse); /// Pass the pointer as the context handle *pContextHandle = pContext; /** * return NvMOTStatus_Error if something is wrong * return NvMOTStatus_OK if everything went well */ } /** * This is a sample code for the constructor of `NvMOTContext` * to show what may need to happen when NvMOTContext is instantiated in the above code for `NvMOT_Init` API */ NvMOTContext::NvMOTContext(const NvMOTConfig &config, NvMOTConfigResponse& configResponse) { // Set CUDA device as needed cudaSetDevice(m_Config.miscConfig.gpuId) // Instantiate an appropriate localizer/tracker implementation // Load and parse the config file for the low-level tracker using the path to a config file m_pLocalizer = LocalizerFactory::getInstance().makeLocalizer(config.customConfigFilePath); // Set max # of streams to be supported // ex) uint32_t maxStreams = config.maxStreams; // Use the video frame info for(uint i=0; i<m_Config.numTransforms; i++) { // Use the expected color format from the input source images NvBufSurfaceColorFormat configColorFormat = (NvBufSurfaceColorFormat)m_Config.perTransformBatchConfig[i].colorFormat; // Use the frame width, height, and pitch as needed uint32_t frameHeight = m_Config.perTransformBatchConfig[i].maxHeight; uint32_t frameWidth = m_Config.perTransformBatchConfig[i].maxWidth; uint32_t framePitch = m_Config.perTransformBatchConfig[i].maxPitch; /* Add here to pass the frame info to the low-level tracker */ } // Set if everything goes well configResponse.summaryStatus = NvMOTConfigStatus_OK; }void NvMOT_DeInit(NvMOTContextHandle contextHandle) { /// Destroy the context handle delete contextHandle; }
在初始化阶段(当调用 NvMOT_Init() 时),预计会实例化低级跟踪器的上下文,并将其指针作为上下文句柄(即 pContextHandle)作为输出以及 pConfigResponse 中的输出状态传递。用户可以根据有关视频帧(例如,宽度、高度、步幅和 colorFormat)和流(例如,最大流数)的信息从输入 NvMOTConfig *pConfigIn 中分配内存,其中结构 NvMOTConfig 的定义可以在 nvdstracker.h 中找到。pConfigIn->customConfigFilePath 中低级跟踪器库的配置文件路径也可以用于解析配置文件以初始化低级跟踪器库。
初始化完成后,跟踪器插件会查询低级跟踪器库所需的参数。查询函数需要像下面这样实现
NvMOTStatus NvMOT_Query(uint16_t customConfigFilePathSize, char* pCustomConfigFilePath, NvMOTQuery *pQuery) { /** * Users can parse the low-level config file in pCustomConfigFilePath to check * the low-level tracker's requirements */ /** An optional function queryParams(NvMOTQuery&) can be implemented in context handle to fill query params. */ /* if (pQuery->contextHandle) { pQuery->contextHandle->queryParams(*pQuery); } */ /** Required configs for all custom trackers. */ pQuery->computeConfig = NVMOTCOMP_GPU; // among {NVMOTCOMP_GPU, NVMOTCOMP_CPU} pQuery->numTransforms = 1; // 0 for IOU and NvSORT tracker, 1 for NvDCF or NvDeepSORT tracker as they require the video frames pQuery->supportPastFrame = true; // Set true only if the low-level tracker supports the past-frame data pQuery->batchMode = NvMOTBatchMode_Batch; // batchMode must be set as NvMOTBatchMode_Batch pQuery->colorFormats[0] = NVBUF_COLOR_FORMAT_NV12; // among {NVBUF_COLOR_FORMAT_NV12, NVBUF_COLOR_FORMAT_RGBA} #ifdef __aarch64__ pQuery->memType = NVBUF_MEM_DEFAULT; #else pQuery->memType = NVBUF_MEM_CUDA_DEVICE; #endif // among {NVBUF_MEM_DEFAULT, NVBUF_MEM_CUDA_DEVICE, NVBUF_MEM_CUDA_UNIFIED, NVBUF_MEM_CUDA_PINNED, ... } pQuery->maxTargetsPerStream = 150; // Max number of targets stored for each stream /** Optional configs to set for additional features. */ pQuery->maxShadowTrackingAge = 30; // Maximum length of shadow tracking, required if supportPastFrame is true pQuery->outputReidTensor = true; // Set true only if the low-level tracker supports outputting reid feature pQuery->reidFeatureSize = 256; // Size of Re-ID feature, required if outputReidTensor is true /** * return NvMOTStatus_Error if something is wrong * return NvMOTStatus_OK if everything went well */ }
一旦低级跟踪器库创建跟踪器上下文并在初始化阶段执行查询,它就需要实现一个函数来处理每个帧批次,即 NvMOT_Process()。确保在输出中正确设置流 ID,以便 pParams->frameList[i].streamID 与 pTrackedObjectsBatch->list[j].streamID 匹配(如果它们用于同一流),而与 i 和 j 无关。下面示例代码中的方法 NvMOTContext::processFrame() 预计使用视频帧的输入数据和检测器对象信息执行所需的多对象跟踪操作,同时在 NvMOTTrackedObjBatch *pTrackedObjectsBatch 中报告跟踪输出。
用户可以参考 在 OpenCV 中访问 NvBufSurface 内存,以了解有关如何访问视频帧中的像素数据的更多信息。
NvMOTStatus NvMOT_Process(NvMOTContextHandle contextHandle, NvMOTProcessParams *pParams, NvMOTTrackedObjBatch *pTrackedObjectsBatch) { /// Process the given video frame using the user-defined method in the context, and generate outputs contextHandle->processFrame(pParams, pTrackedObjectsBatch); /** * return NvMOTStatus_Error if something is wrong * return NvMOTStatus_OK if everything went well */ } /** * This is a sample code for the method of `NvMOTContext::processFrame()` * to show what may need to happen when it is called in the above code for `NvMOT_Process` API */ NvMOTStatus NvMOTContext::processFrame(const NvMOTProcessParams *params, NvMOTTrackedObjBatch *pTrackedObjectsBatch) { // Make sure the input frame is valid according to the MOT Config used to create this context for(uint streamInd=0; streamInd<params->numFrames; streamInd++) { NvMOTFrame *motFrame = ¶ms->frameList[streamInd]; for(uint i=0; i<motFrame->numBuffers; i++) { /* Add something here to check the validity of the input using the following info*/ motFrame->bufferList[i]->width motFrame->bufferList[i]->height motFrame->bufferList[i]->pitch motFrame->bufferList[i]->colorFormat } } // Construct the mot input frames std::map<NvMOTStreamId, NvMOTFrame*> nvFramesInBatch; for(NvMOTStreamId streamInd=0; streamInd<params->numFrames; streamInd++) { NvMOTFrame *motFrame = ¶ms->frameList[streamInd]; nvFramesInBatch[motFrame->streamID] = motFrame; } if(nvFramesInBatch.size() > 0) { // Perform update and construct the output data inside m_pLocalizer->update(nvFramesInBatch, pTrackedObjectsBatch); /** * The call m_pLocalizer->update() is expected to properly populate the ouput (i.e., `pTrackedObjectsBatch`). * * One thing to not forget is to fill `pTrackedObjectsBatch->list[i].list[j].associatedObjectIn`, where * `i` and `j` are indices for stream and targets in the list, respectively. * If the `j`th target was associated/matched with a detector object, * then `associatedObjectIn` is supposed to have the pointer to the associated detector object. * Otherwise, `associatedObjectIn` shall be set NULL. */ } }
低级跟踪器可以通过 NvMOT_RetrieveMiscData() API 将各种数据发送到跟踪器插件。此处使用过去的帧数据作为示例。其他类型的自定义杂项数据可以添加到 NvMOTTrackerMiscData 结构中,也可以在 retrieveMiscData 中输出。
NvMOTStatus NvMOT_RetrieveMiscData(NvMOTContextHandle contextHandle, NvMOTProcessParams *pParams, NvMOTTrackerMiscData *pTrackerMiscData) { /// Retrieve the past-frame data if there are contextHandle->retrieveMiscData(pParams, pTrackerMiscData); /** * return NvMOTStatus_Error if something is wrong * return NvMOTStatus_OK if everything went well */ } /** * This is a sample code for the method of `NvMOTContext::processFramePast()` * to show what may need to happen when it is called in the above code for `NvMOT_ProcessPast` API */ NvMOTStatus NvMOTContext::retrieveMiscData(const NvMOTProcessParams *params, NvMOTTrackerMiscData *pTrackerMiscData) { std::set<NvMOTStreamId> videoStreamIdList; ///\ Indiate what streams we want to fetch past-frame data for(NvMOTStreamId streamInd=0; streamInd<params->numFrames; streamInd++) { videoStreamIdList.insert(params->frameList[streamInd].streamID); } ///\ Retrieve past frame data if (pTrackerMiscData && pTrackerMiscData->pPastFrameObjBatch) { m_pLocalizer->outputPastFrameObjs(videoStreamIdList, pTrackerMiscData->pPastFrameObjBatch); } /** * Add other types of miscellaneous data here */ }
对于动态删除和添加视频流源的情况,可以实现 API 调用 NvMOT_RemoveStreams() 来清理不再需要的资源。
NvMOTStatus NvMOT_RemoveStreams(NvMOTContextHandle contextHandle, NvMOTStreamId streamIdMask) { /// Remove the specified video stream from the low-level tracker context contextHandle->removeStream(streamIdMask); /** * return NvMOTStatus_Error if something is wrong * return NvMOTStatus_OK if everything went well */ } /** * This is a sample code for the method of `NvMOTContext::removeStream()` * to show what may need to happen when it is called in the above code for `NvMOT_RemoveStreams` API */ NvMOTStatus NvMOTContext::removeStream(const NvMOTStreamId streamIdMask) { m_pLocalizer->deleteRemovedStreamTrackers(streamIdMask); }
总而言之,为了使用 NvDsTracker API,用户可能希望定义类似下面的 class NvMOTContext 来实现在上面代码中的方法。每个方法的实际实现可能因用户选择实现的跟踪算法而异。
/** * @brief Context for input video streams * * The stream context holds all necessary state to perform multi-object tracking * within the stream. * */ class NvMOTContext { public: NvMOTContext(const NvMOTConfig &configIn, NvMOTConfigResponse& configResponse); ~NvMOTContext(); /** * @brief Process a batch of frames * * Internal implementation of NvMOT_Process() * * @param [in] pParam Pointer to parameters for the frame to be processed * @param [out] pTrackedObjectsBatch Pointer to object tracks output */ NvMOTStatus processFrame(const NvMOTProcessParams *params, NvMOTTrackedObjBatch *pTrackedObjectsBatch); /** * @brief Output the miscellaneous data if there are * * Internal implementation of retrieveMiscData() * * @param [in] pParam Pointer to parameters for the frame to be processed * @param [out] pTrackerMiscData Pointer to miscellaneous data output */ NvMOTStatus retrieveMiscData(const NvMOTProcessParams *params, NvMOTTrackerMiscData *pTrackerMiscData); /** * @brief Terminate trackers and release resources for a stream when the stream is removed * * Internal implementation of NvMOT_RemoveStreams() * * @param [in] streamIdMask removed stream ID */ NvMOTStatus removeStream(const NvMOTStreamId streamIdMask); protected: /** * Users can include an actual tracker implementation here as a member * `IMultiObjectTracker` can be assumed to an user-defined interface class */ std::shared_ptr<IMultiObjectTracker> m_pLocalizer; };