高级功能#
pyservicemaker 为开发人员提供高级 API/实用程序,以释放 DeepStream SDK 的全部潜力。
处理缓冲区#
Service Maker 中的 Buffer 对象表示一批数据以及相应的元数据。它提供了两个属性,batch_size 和 batch_meta,供开发人员访问批处理的数据和元数据。
Buffer 对象通常通过 BufferOperator 或 BufferRetriever 接口传递,这两个接口都旨在在应用程序中实现,以处理管道中缓冲区的数据。一个区别是 Probe 需要 BufferOperator 接口,而 Receiver 需要 BufferRetriever 接口。虽然在探针中复制和处理缓冲区在技术上是可行的,但这通常不建议这样做。探针主要用于检查目的,应避免在其中执行耗时的任务。这是因为探针通常在管道的关键路径中执行,任何由大量处理引入的延迟都可能增加整体延迟。另一个区别是 BufferOperator 只允许对 Buffer 数据进行就地操作,结果将传递到下游并由同一管道中的其他节点使用,但是,BufferRetriever 应该在管道的末端消耗缓冲区。
以下是用于跳过帧的 BufferOperator 的示例实现。如果 handle_buffer 返回 ‘False’,则当前缓冲区将被丢弃。
from pyservicemaker import BufferOperator, Probe
class FrameSkipper(BufferOperator):
def __init__(self):
super().__init__()
self._frames = 0
def handle_buffer(self, buffer):
self._frames += 1
return (self._frames%2) != 0
一旦我们尝试将帧跳过器应用于上述示例应用程序,我们将注意到下游元素每两个帧只获得一个帧。
pipeline.attach("mux", Probe("probe", FrameSkipper()))
为了对缓冲区执行繁重的操作,首选方法是使用 BufferRetriever。通过将上述示例中的 ‘nveglglessink’ 替换为 ‘appsink’,并附加一个具有 BufferRetriever 实现的 Receiver,我们可以在其 ‘consume’ 方法中访问缓冲区。访问缓冲区数据最方便的方法是将其提取到张量中 - 一种 dlpack 兼容的类,旨在促进与其他 Python 深度学习框架的互操作性。
from pyservicemaker import BufferRetriever, Receiver
class MyBufferRetriever(BufferRetriever):
def consume(self, buffer):
# extract the data from the first buffer in a batch
tensor = buffer.extract(0)
pipeline.attach("sink", Receiver("receiver", MyBufferRetriever(queue)), tips="new-sample")
Service Maker Tensor 对象可以被转换为任何 dlpack 兼容框架中的相应张量,例如 pytorch
from pyservicemaker import BufferRetriever, Receiver
import torch
class MyBufferRetriever(BufferRetriever):
def consume(self, buffer):
tensor = buffer.extract(0)
torch_tensor = torch.utils.dlpack.from_dlpack(tensor.clone())
注意
如果开发人员想要保留张量数据以供以后使用,他们必须使用 clone() 方法复制张量,因为 BufferRetriever 位于管道的末端,并且缓冲区将在 consume() 返回后释放。
也可以通过张量创建缓冲区对象。这种方法通常用于 BufferProvider 的实现中,BufferProvider 与 Feeder 类和 ‘appsrc’ 协同工作,以将数据注入到管道中。以下示例演示了如何加载 pytorch RGB 张量并将其注入到管道中。
from pyservicemaker import BufferProvider, ColorFormat, as_tensor
import torch
class MyBufferProvider(BufferProvider):
def generate(self, size):
torch_tensor = torch.load('tensor_data.pt')
ds_tensor = as_tensor(torch_tensor, "HWC")
return ds_tensor.wrap(ColorFormat.RGB)
通过将原始示例代码中的 ‘urisrcbin’ 替换为 ‘appsrc’,可以将 MyBufferProvider 合并到管道中
pipeline.add("appsrc", "src", {"caps": f"video/x-raw(memory:NVMM), format=RGB, width={width}, height={height}, framerate=30/1", "do-timestamp": True})
此外,也可以通过 python 字节列表创建缓冲区,例如,黑色单色图片是从以下代码生成的
from pyservicemaker import BufferProvider, Buffer
class MyBufferProvider(BufferProvider):
def generate(self, size):
data = [0]*(320*240*3)
return Buffer(data)
利用元数据#
元数据提供有关 Deepstream Service Maker 中缓冲区的附加信息。BatchMetadata 对象可以从缓冲区中检索,它充当所有其他元数据对象的根。批处理元数据管理元数据池,并提供初始化各种元数据对象的方法。
BatchMetadata 对象包含缓冲区中一批帧的元数据。它携带批处理信息,例如批处理大小、批处理中的帧数,并且还提供通过其 frame_items 属性访问 FrameMetadata 对象列表的权限。
FrameMetadata 对象封装了缓冲区批处理中各个帧的元数据。这些帧可能来自不同的输入流。通过 FrameMetadata,开发人员可以访问各种信息,包括尺寸、时间戳、帧号等。此外,帧元数据还携带帧级别的其他元数据,包括 ObjectMetadata、DisplayMetadata 和各种用户元数据。
ObjectMetadata 对象携带对象检测的结果。这些元数据对象通常由 ‘nvinfer’ 插件中的对象检测模型创建。然后,ObjectMetadata 可以被 ‘osd (屏幕显示)’ 插件用于图形表示。通过利用 ObjectMetadata,开发人员可以在帧上可视化检测到的对象。当使用自定义模型时,开发人员可以从模型输出创建自己的 ObjectMetadata 以进行可视化。
TensorOutputUserMetadata 是一种自定义用户元数据,它携带推理模型的输出。当 nvinfer 插件中的 output-tensor-meta 属性设置为 True 时,TensorOutputUserMetadata 对象将附加到帧元数据。这允许开发人员直接访问模型的输出张量。通过使用 TensorOutputUserMetadata,开发人员可以直接处理推理结果,从而实现对模型输出的高级处理和分析。
EventMessageUserMetadata 是另一种用户元数据类型,它将对象检测信息转换为消息对象。这些消息元数据被 nvmsgconv 插件用于将消息发布到各种 IoT 服务器。通过使用 EventMessageUserMetadata,开发人员可以促进检测事件与外部系统的通信,从而增强 Deepstream Service Maker 与 IoT 基础设施的集成。
有关 Deepstream 中元数据结构的详细信息,用户应参考文档。
通用工厂#
Service maker python 绑定支持直接从 service maker 插件创建自定义对象。
from pyservicemaker import CommonFactory
# create a smart recording controller instance from "smart_recording_action" and name it "sr_controller"
CommonFactory.create("smart_recording_action", "sr_controller")
该功能用法已在 service-maker/sources/apps/python/pipeline_api/deepstream_test5_app 应用程序中演示。
管道消息#
当管道运行时,会生成各种消息以告知应用程序其状态。Service Maker 在 ‘start’ 方法中支持 ‘on_message’ 参数,为开发人员提供了一个检查和响应他们感兴趣的消息的机会。
on_message 可调用对象接受两个参数:当前管道和接收到的消息。
Service maker 为两个最重要的消息提供绑定
StateTransitionMessage 表示管道内的状态转换
名称 |
描述 |
|---|---|
old_state |
转换的最后状态 |
new_state |
转换的当前状态 |
origin |
触发消息的节点名称 |
DynamicSourceMessage 表示通过 REST API 添加或删除源。如果使用 ‘nvmultiurisrcbin’,则可能会生成该消息。
名称 |
描述 |
|---|---|
source_added |
添加或删除 |
source_id |
源的索引 |
sensor_id |
唯一标识传感器的字符串 |
sensor_name |
传感器的有意义的名称 |
uri |
传感器的 URI |
该功能用法已在 service-maker/sources/apps/python/pipeline_api/deepstream_test5_app 应用程序中演示。
OSD#
Service maker 提供了一个子模块 ‘osd’,用于通过基本图形小工具进行高级显示控制。
文本:格式化字符串
矩形:彩色矩形
线条:直线
箭头:箭头
圆形:圆形
EventHandler:一个预构建的类,用于响应鼠标事件
该功能用法已在 service-maker/sources/apps/python/flow_api/deepstream_test1_app 应用程序中演示。
引擎文件监视器#
EngineFileMonitor 在 ‘utils’ 子模块中定义,可用于监视模型引擎文件,每当引擎文件更新时,推理将重新启动,而不会中断整个管道。
该功能用法已在 service-maker/sources/apps/python/pipeline_api/deepstream_test5_app 应用程序中演示。
性能监视器#
PerfMonitor 在 ‘utils’ 子模块中定义,可用于实时监视帧率。在 PerfMonitor 生效之前,必须将其应用于管道中的特定节点。当与 ‘nvmultiurisrcbin’ 一起使用时,新源需要使用 ‘add_stream’ 向 PerfMonitor 注册,并且在删除源后,必须相应地调用 PerfMonitor 的 ‘remove_stream’。
该功能用法已在 service-maker/sources/apps/python/pipeline_api/deepstream_test5_app 应用程序中演示。
MediaInfo#
MediaInfo 对象可用于检索媒体源的信息。
from pyservicemaker import utils
mediainfo = utils.MediaInfo.discover("sample.mp4")
MediaExtractor#
MediaExtractor 是 utils 模块中提供的便捷类,用于从多个媒体源提取视频帧。每个媒体源由一个 MediaChunk 对象定义,该对象具有 ‘source’、‘start_pts’ 和 ‘duration’。MediaExtractor 是可调用的,必须使用 MediaChunk 的输入列表构造,一旦调用,它将返回 Queue 对象列表,从中可以检索每个媒体块的解码帧。从解码的视频帧中,开发人员可以从其 tensor 属性访问数据,并从其 ‘timestamp’ 属性访问时间戳。
以下代码片段显示了如何从媒体源检索帧,并且仅适用于 x86 系统
from pyservicemaker import BufferProvider, Buffer, Flow, Pipeline, ColorFormat
from pyservicemaker.utils import MediaExtractor, MediaChunk
from concurrent.futures import ThreadPoolExecutor
import queue
VIDEO_FILE = "/opt/nvidia/deepstream/deepstream/samples/streams/sample_720p.mp4"
N_CHUNKS = 8
class MyBufferProvider(BufferProvider):
def __init__(self, queue, width, height):
print("MyBufferProvider")
super().__init__()
self._queue = queue
self.format = "RGB"
self.width = width
self.height = height
self.framerate = 30
self.device = 'gpu'
self.frames = 0
def generate(self, size):
try:
frame = self._queue.get(timeout=2)
self.frames += 1
return frame.tensor.wrap(ColorFormat.RGB)
except queue.Empty:
print("Buffer empty")
return Buffer()
chunks = [MediaChunk(f) for f in [VIDEO_FILE]*N_CHUNKS]
qs = MediaExtractor(chunks=chunks, batch_size=N_CHUNKS)()
with ThreadPoolExecutor(max_workers=N_CHUNKS) as exe:
exe.map(lambda q: Flow(Pipeline("renderer")).inject([MyBufferProvider(q, 1280, 720)]).render(sync=False)(), qs)
准备和激活#
对于特定用例,我们引入了替代 API 来管理管道执行
Pipeline.prepare()#
与 pipeline.start() 不同,pipeline.start() 在新线程中将管道的状态转换为播放,pipeline.prepare() 在同一线程中将管道的状态设置为暂停。这在多管道场景中尤其有用,在多管道场景中,每个管道的状态都需要按顺序更改为暂停。
Pipeline.activate()#
在使用 pipeline.prepare() 之后,pipeline.activate() 将管道的状态从暂停转换为在新线程中播放。这有效地启动了管道。在多管道场景中,这允许所有管道同时开始执行。
Pipeline.wait()#
此 API 用于加入 pipeline.activate() 创建的线程,确保所有线程在继续之前完成其执行。
Sample Test 5 应用程序演示了如何有效地利用这些 API 调用。
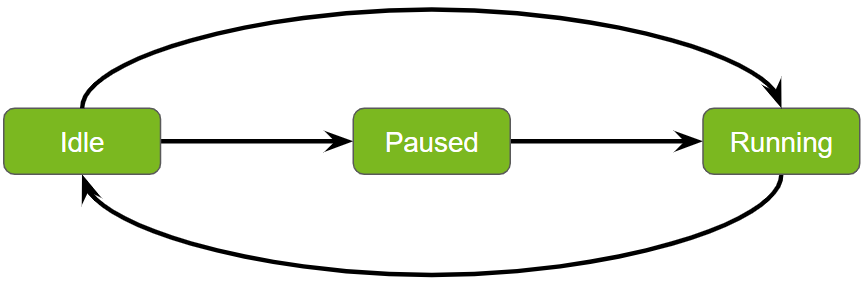
Service Maker 管道中的状态转换#
管理服务管道中的状态转换对于确保高效和有序的操作至关重要。Service maker 促进同步状态转换,从而实现管道状态的平稳和可预测的变化。以下是对这些转换的更清晰和更结构化的解释
启动#
转换:从空闲到运行。
过程:使用 pipeline.start() API 启动管道,使其从空闲状态移动到主动运行任务。
准备和激活#
转换:从空闲到暂停,然后再到运行。
过程:通过执行 pipeline.prepare(),然后执行 pipeline.activate(),管道在完全运行之前会经过暂停状态。此顺序允许在执行之前进行任何必要的设置或配置。
等待#
目的:暂停当前线程,直到管道完成其执行。
过程:在启动和准备/激活序列之后,都需要 pipeline.wait() 函数,以确保当前线程暂停,直到管道完成处理。
停止#
转换:返回到空闲。
过程:pipeline.stop() API 用于将管道返回到其空闲状态,有效地停止操作并将其重置以供将来任务使用。
这些转换旨在有效地管理工作流程,从而允许立即执行和必要的准备阶段。