入门指南¶
安装 cuQuantum¶
从 conda-forge 安装¶
如果您尚未安装 conda,我们建议您安装。安装 conda 非常简单,可以按照我们关于 conda 最佳实践 的章节进行操作。
cuQuantum¶
使用 conda,您可以使用以下命令安装 cuQuantum
conda install -c conda-forge cuquantum
注意
要为 cuTensorNet 和 cuDensityMat 启用自动 MPI 并行,请使用 conda-forge 中的 Open MPI 安装 cuquantum:conda install -c conda-forge cuquantum openmpi。有关更多信息,请参阅 cuTensorNet MPI 安装说明。
警告
conda-forge 上的 mpich 包不是 CUDA 感知的。有关解决方法,请参阅我们关于 将外部包传递给 conda 的说明。
指定 CUDA 版本¶
如果您需要指定 CUDA 版本,请使用 cuda-version 包。
对于 cuquantum
conda install -c conda-forge cuquantum cuda-version=12
对于 cuquantum-python
conda install -c conda-forge cuquantum-python cuda-version=12
conda 求解器将为您安装所有必需的依赖项。
各个组件¶
MPI 安装说明¶
cuTensorNet 和 cuDensityMat 都原生支持 MPI。为了封装 MPI 相关的功能,我们提供并分发一个与 cuTensorNet 和 cuDensityMat 并行的独立库。这些库分别称为 libcutensornet_distributed_interface_mpi.so 和 libcudensitymat_distributed_interface_mpi.so。当您使用 Open MPI 安装 cuTensorNet 或 cuDensityMat 时,conda 会设置一个环境变量。该变量名为 CUTENSORNET_COMM_LIB/CUDENSITYMAT_COMM_LIB,它告诉 libcutensornet.so 或 libcudensitymat.so 要使用哪个分布式接口库。如果在启用 MPI 支持时未设置此变量,则 C 库将在运行时报错。
注意
conda-forge 上的 mpich 包不是 CUDA 感知的。为了解决这个问题,您可以将系统的 MPI 实现作为外部包提供给 conda。为此,请使用 conda install -c conda-forge cutensornet "mpich=*=external_*"。只要系统提供的 MPI 实现可以被 conda 发现,它就应该像常规 conda 包一样工作。有关更多信息,请参阅 conda-forge 的文档。
警告
如果您已启用 cuTensorNet 或 cuDensityMat 的分布式接口,则必须设置相应的环境变量。如果您不这样做,C 库内部的 MPI 初始化尝试将导致错误。
conda 最佳实践¶
要在 ${conda_install_prefix} 下安装 conda,请使用以下命令
conda_install_prefix="~/" \
operating_system="$(uname)" \
architecture="$(uname -m)" \
miniforge_source="https://github.com/conda-forge/miniforge/releases/latest/download/Miniforge-pypy3-${operating_system}-${architecture}.sh" \
curl -L ${miniforge_source} -o ${conda_install_prefix}/install_miniforge.sh && \
bash ${conda_install_prefix}/install_miniforge.sh -b -p ${conda_install_prefix}/conda && \
rm ${conda_install_prefix}/install_miniforge.sh && \
.${conda_install_prefix}/conda/bin/conda init && \
source ~/.bashrc
有关更多信息,请查看 Miniforge 的 GitHub 仓库。此外,您可能需要更新 conda 的包求解器以使用 mamba
conda config --set solver libmamba
要确认求解器已安装并配置
conda config --show | grep -i "solver" ; conda list | grep -i "mamba"
... solver: libmamba ... conda-libmamba-solver 23.3.0 pyhd8ed1ab_0 conda-forge libmamba 1.4.2 hcea66bb_0 conda-forge libmambapy 1.4.2 py39habbe595_0 conda-forge mamba 1.4.2 py39hcbb6966_0 conda-forge
注意
如果您正在使用 Miniforge,conda-forge 是默认通道,您不必在 conda 子命令中指定 -c conda-forge。
设置 CUQUANTUM_ROOT¶
注意事项¶
使用 conda,软件包安装在当前的 ${CONDA_PREFIX} 中。如果您的 cuQuantum 使用涉及构建使用 cuTensorNet 或 cuStateVec 的库或软件包,您可能需要提供或定义 CUQUANTUM_ROOT。设置此变量的一种方法是使用 ${CONDA_PREFIX},如下所示
export CUQUANTUM_ROOT=${CONDA_PREFIX}
这将有效,并且可以与安装了 cuQuantum 的 conda 环境一起安全使用。如果您在设置此变量时更改 conda 环境,则会导致意外行为。
警告
不建议设置引用特定 conda 环境的环境变量。使用 CUQUANTUM_ROOT=${CONDA_PREFIX} 应谨慎操作。出于类似原因,在使用 conda-build 或类似工具时,不建议在 LD_LIBRARY_PATH 中使用 ${CONDA_PREFIX}。有关更多详细信息,请参阅 conda-build 的 文档的此部分。
我们的建议¶
设置 CUQUANTUM_ROOT 时,应使用 conda env config vars set 创建附加到安装了 cuQuantum 的 conda 环境的环境变量
conda env config vars set CUQUANTUM_ROOT=${CONDA_PREFIX}
通过重新激活 conda 环境来确认环境变量已正确设置
conda activate my_conda_env && \
echo ${CUQUANTUM_ROOT}
从 PyPI 安装¶
cuQuantum 和 cuQuantum Python 以元包的形式在 PyPI 上提供。安装后,将检测 CUDA 版本并获取相应的二进制文件。cuQuantum 的 PyPI 包托管在 cuquantum 项目下。cuQuantum Python 的 PyPI 包托管在 cuquantum-python 项目下。
注意
pip 23.1+ 需要 --no-cache-dir 参数。它强制 pip 执行 CUDA 版本检测逻辑。
cuQuantum¶
pip install -v --no-cache-dir cuquantum
cuQuantum Python¶
pip install -v --no-cache-dir cuquantum-python
从 NVIDIA DevZone 安装¶
使用归档文件¶
cuQuantum 归档文件可以从 NVIDIA 的开发者网站 https://developer.nvidia.com/cuQuantum-downloads 下载。请注意,cuTensorNet 和 cuDensityMat 都依赖于 cuTENSOR。文档和下载说明可在 NVIDIA cuTENSOR 开发者网站下找到。
cuQuantum 归档文件名称采用以下形式
cuquantum-linux-${ARCH}-${CUQUANTUM_VERSION}.${BUILD_NUMBER}_cuda${CUDA_VERSION}-archive.tar.xz
例如,要下载 CUDA 版本为 12 的 x86_64 归档文件,请使用
wget https://developer.download.nvidia.com/compute/cuquantum/redist/cuquantum/linux-x86_64/cuquantum-linux-x86_64-24.08.0.5_cuda12-archive.tar.xz
要展开归档文件,请使用
tar -xvf cuquantum-linux-x86_64-24.08.0.5_cuda12-archive.tar.xz
最后,更新您的 .bashrc(或类似文件),以便定义 CUQUANTUM_ROOT
export CUQUANTUM_ROOT=/path/to/cuquantum-linux-x86_64-24.08.0.5_cuda12-archive
注意
要为 cuTensorNet 或 cuDensityMat 启用原生 MPI 支持,请参阅相关的 MPI 安装说明。
MPI 安装说明¶
要在使用 NVIDIA DevZone 的归档文件时为 cuTensorNet 或 cuDensityMat 启用原生 MPI 支持,请按照以下步骤操作
导航到
cutensornet_distributed_interface_mpi.c或cudensitymat_distributed_interface_mpi.c的根目录。运行激活脚本并编译提供 MPI 支持的库。
设置名为
CUTENSORNET_COMM_LIB或CUDENSITYMAT_COMM_LIB的环境变量。
运行激活脚本¶
以 cuTensorNet 为例,脚本 activate_mpi.sh(或从 cuTensorNet v2.6.0 开始的 activate_mpi_cutn.sh)将通过调用 gcc 来编译 cuTensorNet 的分布式接口
cat activate_mpi.sh
...
gcc -shared -std=c99 -fPIC \
-I${CUDA_PATH}/include -I../include -I${MPI_PATH}/include \
cutensornet_distributed_interface_mpi.c \
-L${MPI_PATH}/lib64 -L${MPI_PATH}/lib -lmpi \
-o libcutensornet_distributed_interface_mpi.so
export CUTENSORNET_COMM_LIB=${PWD}/libcutensornet_distributed_interface_mpi.so
编译命令需要定义以下变量
CUDA_PATH… CUDA 安装路径(例如)/usr/local/cudaMPI_PATH… MPI 安装路径
我们预计在 ${MPI_PATH}/include 目录下找到 mpi.h。此激活脚本还将为 CUTENSORNET_COMM_LIB=${CUQUANTUM_ROOT}/distributed_interfaces/libcutensornet_distributed_mpi.so 导出定义。您应该将其添加到您的 .bashrc 或类似文件中。
注意
谨慎地将环境变量添加到您的 .bashrc 文件中。如果您计划将此存档与 conda 环境一起使用,请查看我们的 最佳实践部分。
使用系统包管理器¶
要使用您系统的包管理器安装 cuQuantum,请使用 NVIDIA 的 cuQuantum 选择工具。
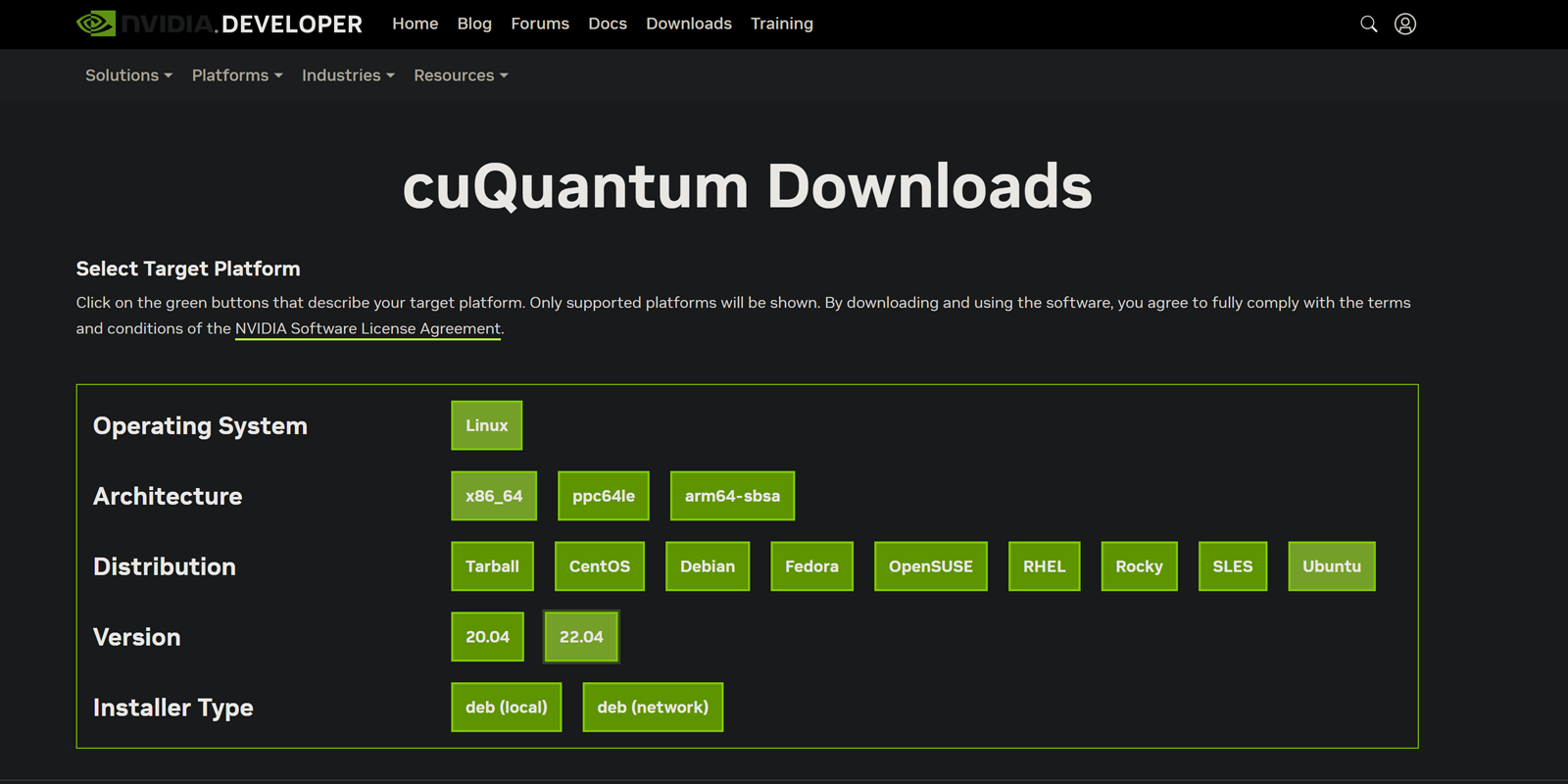
作为示例,以下部分概述了在 Ubuntu 22.04 x86_64 下进行 deb (网络) 安装的命令。我们还描述了如何使用 update-alternatives 来管理您的安装。请参阅此列表以快速导航
密钥环安装¶
下载密钥环、安装密钥环和更新打包工具的命令如下
wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-keyring_1.1-1_all.deb
sudo dpkg --install cuda-keyring_1.1-1_all.deb
sudo apt-get update
通用安装¶
要安装 cuquantum,请使用此命令
sudo apt-get --yes install cuquantum
注意
通用安装 cuQuantum 将会下载并配置 cuQuantum 以支持所有当前支持的 CUDA 主要版本。有关管理您的 cuQuantum 安装的详细信息,请查看我们的 关于使用 update-alternatives 的章节。
指定 CUDA 版本¶
使用特定 CUDA 版本安装 cuquantum 的命令如下所示
sudo apt-get --yes install cuquantum-cuda-XY
其中 XY 表示 CUDA 的主要版本。例如,以下命令将安装 cuquantum,并支持主要版本为 12 的 CUDA
sudo apt-get --yes install cuquantum-cuda-12
有效的 CUDA 主要版本
显示支持的版本和命令
CUDA 11 → sudo apt-get --yes install cuquantum-cuda-11CUDA 12 → sudo apt-get --yes install cuquantum-cuda-12使用 update-alternatives¶
update-alternatives 可用于查看和更新 /usr/src/libcuquantum/distributed_interfaces 的提供程序。要查看系统安装的 cuQuantum,您可以使用此命令
sudo update-alternatives --display cuquantum
cuquantum - auto mode
link best version is /usr/src/libcuquantum/12/distributed_interfaces
link currently points to /usr/src/libcuquantum/12/distributed_interfaces
link cuquantum is /usr/src/libcuquantum/distributed_interfaces
slave custatevec.h is /usr/include/custatevec.h
slave cutensornet is /usr/include/cutensornet
slave cutensornet.h is /usr/include/cutensornet.h
slave libcustatevec.so is /usr/lib/x86_64-linux-gnu/libcustatevec.so
slave libcustatevec.so.1 is /usr/lib/x86_64-linux-gnu/libcustatevec.so.1
slave libcustatevec_static.a is /usr/lib/x86_64-linux-gnu/libcustatevec_static.a
slave libcutensornet.so is /usr/lib/x86_64-linux-gnu/libcutensornet.so
slave libcutensornet.so.2 is /usr/lib/x86_64-linux-gnu/libcutensornet.so.2
slave libcutensornet_static.a is /usr/lib/x86_64-linux-gnu/libcutensornet_static.a
/usr/src/libcuquantum/11/distributed_interfaces - priority 110
slave custatevec.h: /usr/include/libcuquantum/11/custatevec.h
slave cutensornet: /usr/include/libcuquantum/11/cutensornet
slave cutensornet.h: /usr/include/libcuquantum/11/cutensornet.h
slave libcustatevec.so: /usr/lib/x86_64-linux-gnu/libcuquantum/11/libcustatevec.so
slave libcustatevec.so.1: /usr/lib/x86_64-linux-gnu/libcuquantum/11/libcustatevec.so.1
slave libcustatevec_static.a: /usr/lib/x86_64-linux-gnu/libcuquantum/11/libcustatevec_static.a
slave libcutensornet.so: /usr/lib/x86_64-linux-gnu/libcuquantum/11/libcutensornet.so
slave libcutensornet.so.2: /usr/lib/x86_64-linux-gnu/libcuquantum/11/libcutensornet.so.2
slave libcutensornet_static.a: /usr/lib/x86_64-linux-gnu/libcuquantum/11/libcutensornet_static.a
/usr/src/libcuquantum/12/distributed_interfaces - priority 120
slave custatevec.h: /usr/include/libcuquantum/12/custatevec.h
slave cutensornet: /usr/include/libcuquantum/12/cutensornet
slave cutensornet.h: /usr/include/libcuquantum/12/cutensornet.h
slave libcustatevec.so: /usr/lib/x86_64-linux-gnu/libcuquantum/12/libcustatevec.so
slave libcustatevec.so.1: /usr/lib/x86_64-linux-gnu/libcuquantum/12/libcustatevec.so.1
slave libcustatevec_static.a: /usr/lib/x86_64-linux-gnu/libcuquantum/12/libcustatevec_static.a
slave libcutensornet.so: /usr/lib/x86_64-linux-gnu/libcuquantum/12/libcutensornet.so
slave libcutensornet.so.2: /usr/lib/x86_64-linux-gnu/libcuquantum/12/libcutensornet.so.2
slave libcutensornet_static.a: /usr/lib/x86_64-linux-gnu/libcuquantum/12/libcutensornet_static.a
要使用 update-alternatives 管理您的 cuQuantum 安装,请使用此命令选择 /usr/src/libcuquantum/distributed_interfaces 的提供程序
sudo update-alternatives --config cuquantum
...
There are 2 choices for the alternative cuquantum (providing /usr/src/libcuquantum/distributed_interfaces).
Selection Path Priority Status
------------------------------------------------------------
* 0 /usr/src/libcuquantum/12/distributed_interfaces 120 auto mode
1 /usr/src/libcuquantum/11/distributed_interfaces 110 manual mode
2 /usr/src/libcuquantum/12/distributed_interfaces 120 manual mode
Press <enter> to keep the current choice[*], or type selection number: ...
您必须指定一个 Selection 编号,并参考您希望使用的 CUDA 主要版本。
使用框架安装 cuQuantum¶
CUDA Quantum¶
cuQuantum 是 NVIDIA GPU 可用系统上的默认模拟器。有关更多信息,请参阅 CUDA Quantum 的文档。要安装 CUDA Quantum,请使用以下命令
pip install cuda-quantum
如果您计划将 CUDA Quantum 与 conda 环境一起使用,请按照 CUDA Quantum 的 PyPI 项目页面上的说明进行操作,此处:https://pypi.ac.cn/project/cuda-quantum。
Qiskit¶
cuQuantum 与 qiskit-aer-gpu 一起分发,作为可用的后端。Qiskit 中不同的 API 将以不同的方式启用或依赖于 cuQuantum 提供的功能。例如,如果您正在使用 AerSimulator,则可以使用关键字参数启用 cuStateVec:cuStateVec_enable=True。对于基于 GPU 加速张量网络的模拟,cuTensorNet 是默认设置。
conda-forge¶
要安装启用 GPU 的 Qiskit 版本,请使用以下命令
conda install -c conda-forge qiskit-aer
注意
要使用特定版本的 CUDA 进行安装,请使用 cuda-version 包
conda install -c conda-forge qiskit-aer cuda-version=XY
其中 XY 是 CUDA 的主要版本。
显示支持的版本和命令。
CUDA 11 → conda install -c conda-forge qiskit-aer cuda-version=11CUDA 12 → conda install -c conda-forge qiskit-aer cuda-version=12Cirq¶
要将 cuQuantum 与 Cirq 一起使用,您可以编译 qsim 或从 conda-forge 安装 qsimcirq 包。我们假设您已经使用 conda 安装了 cuQuantum。完成后,您可以通过在传递给各种 qsimcirq 模拟器组件的 QSimOptions 对象中设置 gpu_mode=1 来使用 cuStateVec 后端。
与 cuQuantum Appliance 一起使用
QSimOptions 在 cuQuantum Appliance 中具有不同的 API 签名
class QSimOptions:
...
gpu_mode: Union[int, Sequence[int]] = (0,)
gpu_network: int = 0
...
这些选项在 Cirq 的 cuQuantum Appliance 部分 中描述。以下是该部分的摘录
|
要使用的 GPU 模拟器后端。如果为 |
|
GPU 间数据传输网络的拓扑结构。当启用多 GPU 支持时,此选项有效。支持的网络拓扑结构包括交换机网络和全互连网络。如果指定为 0,则自动检测网络拓扑结构。如果指定为 1 或 2,则分别选择交换机或全互连网络。交换机网络旨在支持 DGX A100 和 DGX-2 中的 GPU 数据传输网络,其中所有 GPU 都通过 NVLink 连接到 NVSwitch。通过 PCIe 交换机连接的 GPU 也被视为交换机网络。全互连网络旨在支持 DGX Station A100/V100 中看到的 GPU 数据传输网络,其中所有设备都通过 NVLink 直接连接。 |
conda-forge¶
如果您喜欢从 conda 安装 qsim,请使用以下命令
conda install -c conda-forge qsimcirq
注意
要使用特定版本的 CUDA 进行安装,请使用 cuda-version 包
conda install -c conda-forge qsimcirq cuda-version=XY
其中 XY 是 CUDA 的主要版本。
显示支持的版本和命令。
CUDA 11 → conda install -c conda-forge qsimcirq cuda-version=11CUDA 12 → conda install -c conda-forge qsimcirq cuda-version=12导出 CUQUANTUM_ROOT
虽然我们在本节的命令中包含了 export CUQUANTUM_ROOT=${CONDA_PREFIX},但如果您遵循了我们的 最佳实践建议,则这些命令是多余的。具体来说,您不应该 export CUQUANTUM_ROOT=...,因为它会在当前 shell 会话中全局定义环境变量。我们包含 export 命令是为了保证复制和粘贴命令时能够成功执行。
源代码¶
export CUQUANTUM_ROOT=${CONDA_PREFIX}
git clone https://github.com/quantumlib/qsim.git && \
pip install -v --no-cache-dir .
请注意,以上命令从源代码编译 qsim + qsimcirq,并将它们安装到您的本地环境中。这需要 cmake 可以检测到有效的 CUDA 编译器工具链。在构建过程中,您应该看到有关 qsim_custatevec 目标的状态消息。鉴于您是从源代码构建,您可以在 pip 中使用可编辑模式
export CUQUANTUM_ROOT=${CONDA_PREFIX}
git clone https://github.com/quantumlib/qsim.git && \
pip install -v --no-cache-dir --editable .
虽然它主要面向开发人员,但它也可以更轻松地从源代码存储库中拉取更新。
注意
请遵循我们关于设置附加到 conda 环境的环境变量的建议。有关更多详细信息,请参阅关于 设置 cuQuantum 根目录 的部分。
PennyLane¶
cuQuantum 是 pennylane-lightning[gpu] 的依赖项。要安装带有 GPU 加速的 PennyLane,请参阅 PennyLane 的安装说明,在其 lightning-gpu 项目下。
conda-forge¶
如果您喜欢从 conda 安装 PennyLane,请使用以下命令
conda install -c conda-forge pennylane-lightning-gpu
注意
要使用特定版本的 CUDA 进行安装,请使用 cuda-version 包
conda install -c conda-forge pennylane-lightning-gpu cuda-version=XY
其中 XY 是 CUDA 的主要版本。
显示支持的版本和命令。
CUDA 11 → conda install -c conda-forge pennylane-lightning-gpu cuda-version=11CUDA 12 → conda install -c conda-forge pennylane-lightning-gpu cuda-version=12运行 cuQuantum Appliance¶
cuQuantum Appliance 在 NGC 上可用:https://catalog.ngc.nvidia.com/orgs/nvidia/containers/cuquantum-appliance
无论您如何使用 cuQuantum Appliance,都必须拉取容器
docker pull nvcr.io/nvidia/cuquantum-appliance:24.03-x86_64
在 24.03 版本中,有必要更改基于 ARM64 机器的标签名称
docker pull nvcr.io/nvidia/cuquantum-appliance:24.03-arm64
注意
运行容器将拉取它(如果当前 Docker 引擎不可用)。
在命令行中¶
以下小节中的命令摘自 NGC 上的 cuQuantum Appliance 概述页面:https://catalog.ngc.nvidia.com/orgs/nvidia/containers/cuquantum-appliance
您可以通过多种方式在命令行中运行 cuQuantum Appliance
使用交互式会话。
使用非交互式会话。
使用特定的 GPU。
使用交互式会话¶
要配置伪终端会话并附加到 STDIN,请使用以下命令
docker run --gpus all -it --rm \
nvcr.io/nvidia/cuquantum-appliance:24.03-x86_64
使用非交互式会话¶
要以非交互方式向容器运行时发出单个命令并退出,请使用以下命令
docker run --gpus all --rm \
nvcr.io/nvidia/cuquantum-appliance:24.03-x86_64 \
python /home/cuquantum/examples/{example_name}.py
使用特定的 GPU¶
要指定在容器中使用的 GPU,请使用以下命令
# with specific GPUs
docker run --gpus '"device=0,3"' -it --rm \
nvcr.io/nvidia/cuquantum-appliance:24.03-x86_64
使用远程主机¶
在许多情况下,使用远程计算资源既更有效又更高效(而且通常是必要的)。通过适当的配置,远程资源扩展了我们本地开发环境的功能,使我们更有效率,并允许更强大的应用程序设计和部署。
在以下部分中,我们做出了一些假设
您已使用有用的、简洁的别名配置了
~/.ssh/config。您的机器上安装了有效的 OpenSSH。
对于您希望使用的所有远程主机,您都配置了基于密钥的身份验证。
澄清我们的假设¶
有用 + 简洁的别名¶
有用且简洁的别名将具有与以下形式一致的形式
cat ~/.ssh/config
...
Host my_concise_alias
User my_username
HostName my_remote_host
Port my_remote_port
IdentityFile /path/to/identity/file
OpenSSH 的有效安装¶
可以使用以下命令确认您的机器上是否安装了有效的 OpenSSH
OpenSSH 版本¶
打开终端,并发出以下命令
ssh -V
Linux 上的典型输出版本
OpenSSH_8.2p1 Ubuntu-4ubuntu0.5, OpenSSL 1.1.1f 31 Mar 2020
Windows 上的典型输出版本
OpenSSH_for_Windows_8.6p1, LibreSSL 3.4.3
基于密钥的身份验证示例¶
要检查是否已设置并正在使用基于密钥的身份验证,请在终端中键入以下命令
ssh -v my_concise_alias
...
debug1: Authentication succeeded (publickey).
...
使用 DOCKER_HOST¶
编排远程主机的一种简单方法是使用 DOCKER_HOST。一旦设置,环境变量赋值将指示本地 Docker CLI 使用 DOCKER_HOST 中定义的远程提供的 Docker 引擎。
在 Linux 上
export DOCKER_HOST=ssh://my_concise_alias
在 Windows 上
$env:DOCKER_HOST='ssh://my_concise_alias'
确认 Docker CLI + 远程 Docker 引擎¶
这些命令指示您的本地 Docker CLI 通过 SSH 连接到 my_concise_alias 上可用的 Docker 引擎,并在当前命令行会话中对所有本地执行的 CLI 命令使用该 Docker 引擎。
例如,在 Linux 终端中运行以下命令将打印 my_concise_alias 上所有正在运行的 Docker 容器。因为我们正在使用 Docker CLI,所以命令与操作系统无关。
docker run --name cuquantum-appliance \
--gpus all \
--network host \
-itd nvcr.io/nvidia/cuquantum-appliance:24.03-x86_64
...
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
... nvcr.io/nvidia/cuquantum-appliance:24.03-x86_64 "/usr/local/bin/entr…" 5 seconds ago Up 4 seconds cuquantum-appliance
... ... ... ... ... ... ...
要确认您的本地 Docker CLI 正在使用远程,您可以尝试几个命令
使用
nvidia-smi。比较
hostname输出。
检查 nvidia-smi¶
在远程执行 nvidia-smi 可以使用以下命令完成
docker exec cuquantum-appliance nvidia-smi
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 530.36 Driver Version: 530.36 CUDA Version: 12.1 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 NVIDIA A100-SXM4-80GB On | 00000000:01:00.0 Off | 0 |
| N/A 38C P0 63W / 275W| 17MiB / 81920MiB | 0% Default |
| | | Disabled |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| No running processes found |
+---------------------------------------------------------------------------------------+
比较主机名¶
同样,您可以从远程 Docker 引擎获取所有(长)主机名,并将它们与在本地终端中执行的相同命令进行比较。
首先,从远程主机 Docker 引擎获取 hostname 输出
docker exec cuquantum-appliance hostname --all-fqdns
接下来,使用此命令在 Linux 上获取本地 hostname 输出
hostname --all-fqdns
或者,如果您使用的是 Windows,请使用此命令来 GetHostByName
[System.Net.Dns]::GetHostByName(($env:computerName)).HostName
使用远程 Docker 引擎运行命令¶
现在,我们可以尝试运行 cuQuantum Appliance 中的示例
docker exec cuquantum-appliance python /home/cuquantum/examples/qiskit_ghz.py --help
...
usage: qiskit_ghz.py [-h] [--nbits NBITS] [--precision {single,double}]
[--disable-cusvaer]
Qiskit ghz.
options:
-h, --help show this help message and exit
--nbits NBITS the number of qubits
--precision {single,double}
numerical precision
--disable-cusvaer disable cusvaer
docker exec cuquantum-appliance python /home/cuquantum/examples/qiskit_ghz.py
...
{'00000000000000000000': 533, '11111111111111111111': 491}
...
使用 Docker 上下文¶
虽然有用,但每次创建新的终端会话时都设置 DOCKER_HOST=ssh://my_concise_alias 很繁琐。同样,我们不建议全局设置 DOCKER_HOST。值得庆幸的是,Docker 提供了用于管理多容器编排方案的基础架构。通过使用 docker context,我们可以创建不同的远程 Docker 引擎组,并使用本地 Docker CLI 管理它们。
DOCKER ENDPOINT 依赖于各种 URI 方案。重要的是,它支持我们与 DOCKER_HOST 一起使用的相同 SSH URI 方案。这意味着我们用于将本地 Docker CLI 连接到单个远程 Docker 引擎的相同 SSH URI (ssh://my_concise_alias) 可以用于创建 Docker 上下文。
以下是 docker context 的命令架构
docker context --help
...
Manage contexts
Usage:
docker context [command]
Available Commands:
create Create new context
export Export a context to a tar or kubeconfig file
import Import a context from a tar or zip file
inspect Display detailed information on one or more contexts
list List available contexts
rm Remove one or more contexts
show Print the current context
update Update a context
use Set the default context
Flags:
-h, --help Help for context
Use "docker context [command] --help" for more information about a command.
列出 Docker 上下文¶
我们可以使用以下命令列出可用的上下文。由于 Docker CLI 的存在,这些命令在 Linux 和 Windows 上是相同的,但预期的输出内容略有不同。
docker context ls
在 Linux 上
...
NAME DESCRIPTION DOCKER ENDPOINT KUBERNETES ENDPOINT ORCHESTRATOR
default * Current DOCKER_HOST based configuration unix:///var/run/docker.sock swarm
在 Windows 上
...
NAME TYPE DESCRIPTION DOCKER ENDPOINT KUBERNETES ENDPOINT ORCHESTRATOR
default * moby Current DOCKER_HOST based configuration npipe:////./pipe/docker_engine
desktop-linux moby Docker Desktop npipe:////./pipe/dockerDesktopLinuxEngine
上下文创建¶
我们可以使用我们的 SSH 别名创建一个新的上下文,如下所示
docker context create my_context --docker "host=ssh://my_concise_alias"
...
my_context
Successfully created context "my_context"
重新运行 docker context ls 会产生
docker context ls
...
NAME TYPE DESCRIPTION DOCKER ENDPOINT KUBERNETES ENDPOINT ORCHESTRATOR
... ... ... ... ... ...
my_context moby ssh://my_concise_alias
使用上下文¶
要使用新创建的上下文,请运行此命令
docker context use my_context
并且使用 Docker CLI 的本地命令将被转发到 my_context 提供的 Docker 端点。运行 cuQuantum Appliance 与之前一样,使用以下命令
docker run --name cuquantum-appliance \
--gpus all --network host \
-itd nvcr.io/nvidia/cuquantum-appliance:24.03-x86_64
运行示例也同样相同
docker exec cuquantum-appliance python /home/cuquantum/examples/qiskit_ghz.py
注意
上下文的使用允许我们管理持久配置,并按某些特征(例如:架构、GPU 数量、GPU 类型等)对多个端点进行分组。
与远程容器交互¶
连接到(并与)远程容器交互可能对以下任务很有用
设计用于异步执行的工作流程。
调试工作负载组件。
电路分析。
有很多方法可以连接到远程容器。一种方法是将正在运行的远程容器附加到本地配置的 IDE。我们将向您展示两种依赖于不同技术的方法
在 Visual Studio Code 中使用 SSH 和 Dev Container 扩展。
在远程容器中使用正在运行的 Jupyter Lab 服务器。
Visual Studio Code¶
要使用 Visual Studio Code 附加到正在运行的远程容器,您需要两个扩展
Remote - SSH¶
要在命令行安装 Remote - SSH 扩展,请使用以下命令
code --install-extension ms-vscode-remote.remote-ssh
否则,您可以从 Marketplace 列表安装它:https://marketplace.visualstudio.com/items?itemName=ms-vscode-remote.remote-ssh
Dev Containers¶
要在命令行安装 Dev Containers 扩展,请使用以下命令
code --install-extension ms-vscode-remote.remote-containers
否则,您可以从 Marketplace 列表安装它:https://marketplace.visualstudio.com/items?itemName=ms-vscode-remote.remote-containers
附加到正在运行的容器¶
步骤如下
在远程主机上运行容器。
使用 Remote - SSH 扩展连接到远程主机。
使用 Dev Containers 扩展附加到正在运行的容器
运行容器¶
使用 连接到远程 docker 引擎 中描述的方法,我们可以使用以下命令启动分离的容器
docker context use my_context && \
docker run --name cuquantum-appliance \
--gpus all \
--network host \
-itd nvcr.io/nvidia/cuquantum-appliance:24.03-x86_64
或者,如果您不想使用 docker context,您可以使用 DOCKER_HOST。首先,按照 相关章节 中的说明设置环境变量。
然后发出 docker run 命令
docker run --name cuquantum-appliance --gpus all --network host -it -d nvcr.io/nvidia/cuquantum-appliance:24.03-x86_64
如果您不想使用远程 Docker 引擎基础设施,请跳至下面关于 使用 Remote - SSH 扩展连接 的部分。
作为演示,我们包含动画,向您展示这一切的样子
使用 Docker 上下文
使用活动的 Docker 上下文执行 docker run
show animation

使用 DOCKER_HOST
使用定义的 DOCKER_HOST 环境变量执行 docker run
… 在 Linux 上
show animation

… 在 Windows 上
show animation

使用 Remote - SSH 连接¶
有两种方法可以使用 Remote - SSH 扩展连接到远程主机
使用 Visual Studio Code 窗口左下角的图形用户界面 (GUI) 按钮。
使用 Visual Studio Code 的命令面板。
Remote - SSH 使用 GUI 按钮
show animation

Remote - SSH 使用命令面板
要使用命令面板通过 Remote - SSH 扩展连接到远程主机,您应该按照以下步骤操作
在 Visual Studio Code 打开的情况下,键入此按键序列:
ctrl+shift+p… 这将打开命令面板。在命令面板处于焦点时,键入
connect to host… 这应该会调出 Remote - SSH 命令Remote-SSH: Connect to Host...。通过使用箭头键或使用光标单击来选择适当的主机。
注意
按 enter(或类似键)以选择突出显示的命令。要导航突出显示的命令,请使用键盘上的箭头键。
show animation

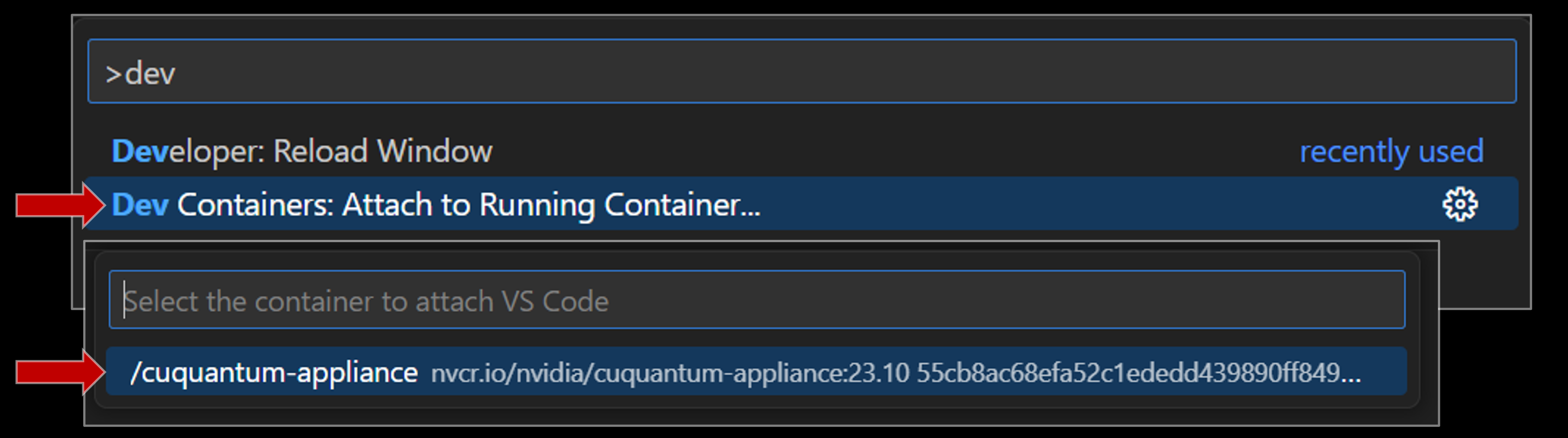
使用 Dev Containers 附加¶
使用 使用 Remote - SSH 扩展连接 中所示的命令面板,我们可以附加到容器。
Dev Containers 与命令面板
要使用命令面板通过 Dev Containers 扩展附加到远程主机上正在运行的容器,您应该按照以下步骤操作
在 Visual Studio Code 打开的情况下,键入此按键序列:
ctrl+shift+p… 这将打开命令面板。在命令面板处于焦点时,键入
Dev Containers… 这应该会调出 Dev Containers 命令Dev Containers: Attach to Running Container ...。通过使用箭头键或使用光标单击来选择适当的容器。
show image
运行 cuQuantum 基准测试¶
在 GitHub 上可用:https://github.com/nvidia/cuquantum,位于 benchmarks 下。
直接链接是 https://github.com/nvidia/cuquantum/tree/main/benchmarks。
cuQuantum Benchmarks 是一个可安装的 Python 包,其目的是简化性能评估和 cuQuantum 产品提供的实用性。它使用户能够在不同的集成场景下测试 cuQuantum。cuQuantum Benchmarks 包可以安装在裸机系统和 cuQuantum Appliance 中。要获取该包,请使用
git clone https://github.com/NVIDIA/cuQuantum.git
有关详细的安装说明,请参阅下面 关于安装基准测试 的相应部分。
用法¶
我们为 cuQuantum Benchmarks CLI 提供了 --help 文档。您可以使用以下命令查询它
cuquantum.benchmarks --help
...
usage: cuquantum-benchmarks [-h] {circuit,api} ...
...
positional arguments:
{circuit,api}
circuit benchmark different classes of quantum circuits
api benchmark different APIs from cuQuantum's libraries
optional arguments:
-h, --help show this help message and exit
例如,您可以使用以下命令在 cuQuantum Appliance 中运行多节点多 GPU 基准测试
mpirun -n ${NUM_GPUS} cuquantum-benchmarks \
circuit --frontend qiskit --backend cusvaer \
--benchmark ${BENCHMARK_NAME} \
--nqubits ${NUM_QUBITS} --ngpus 1 \
--cusvaer-global-index-bits ${LOG2_NUM_NODES_PER_GROUP},${LOG2_NUM_NODE_GROUPS} \
--cusvaer-p2p-device-bits ${LOG2_NUM_PEERED_GPUS}
在这种情况下,--ngpus 1 表示单个 rank/进程必须与单个 GPU 关联。--cusvaer-global-index-bits 和 --cusvaer-p2p-device-bits 的使用指定了多 GPU 多节点集群的网络拓扑结构
参数名称 |
输入形式 |
描述 |
|---|---|---|
|
一个 |
由状态向量负载均衡节点组 log2 大小表示的网络拓扑 |
|
|
状态向量负载均衡的对等可访问组 log2 大小 |
注意
状态向量负载均衡节点组 指的是一组 GPU,其中每个 GPU 都被分配一个大小相等的状态向量分区。为了将仅由量子比特组成的量子态均匀地分布到一组 GPU 中,该组的大小必须是 2 的幂。为了强制执行这一点,我们要求输入的网络拓扑结构以量子比特的数量来表示。
使用 --cusvaer-global-index-bits 选项,您可以定义具有任意数量不同层的网络拓扑结构。有关更多详细信息,请参阅 关于定义网络结构的相关文档。
安装¶
裸机¶
要在您的系统上安装 cuQuantum Benchmarks,您可以使用以下命令
仅基准测试套件
cd cuQuantum/benchmarks && \
pip install .
基准测试和所有可选依赖项
cd cuQuantum/benchmarks && \
pip install .[all]
请注意,这不保证所有依赖项都安装了 GPU 支持。某些框架具有非标准的构建要求才能启用 GPU 支持。
Appliance¶
为了避免意外覆盖 cuQuantum Appliance 中的软件,请使用以下命令安装 cuQuantum Benchmarks
cd cuQuantum/benchmarks && \
pip install .
依赖项¶
cuStateVec¶
GPU 架构 |
Volta, Turing, Ampere, Ada, Hopper |
具有计算能力的 NVIDIA GPU |
7.0+ |
CUDA |
11.x, 12.x |
CPU 架构 |
x86_64, ARM64 |
操作系统 |
Linux |
驱动程序 |
450.80.02+ (Linux),适用于 CUDA 11.x
525.60.13+ (Linux),适用于 CUDA 12.x
|
cuTensorNet¶
GPU 架构 |
Volta, Turing, Ampere, Ada, Hopper |
具有计算能力的 NVIDIA GPU |
7.0+ |
CUDA |
11.x 或 12.x |
CPU 架构 |
x86_64, ARM64 |
操作系统 |
Linux |
驱动程序 |
450.80.02+ (Linux/CUDA 11) 或 525.60.13+ (Linux/CUDA 12) |
cuTENSOR |
v2.0.2+ |
cuDensityMat¶
GPU 架构 |
Volta, Turing, Ampere, Ada, Hopper |
具有计算能力的 NVIDIA GPU |
7.0+ |
CUDA |
11.x 或 12.x |
CPU 架构 |
x86_64, ARM64 |
操作系统 |
Linux |
驱动程序 |
450.80.02+ (Linux/CUDA 11) 或 525.60.13+ (Linux/CUDA 12) |
cuTENSOR |
v2.0.2+ |
cuQuantum Python¶
构建时 |
运行时 |
|
|---|---|---|
Python |
3.10+ |
3.10+ |
pip |
22.3.1+ |
N/A |
setuptools |
>=61.0.0 |
N/A |
wheel |
>=0.34.0 |
N/A |
Cython |
>=0.29.22,<3 |
N/A |
cuStateVec |
1.7.0 |
~=1.7 |
cuTensorNet |
2.6.0 |
~=2.6 |
cuDensityMat |
0.0.5 |
~=0.0.5 |
NumPy |
N/A |
v1.21+ |
CuPy (参见 CuPy 安装指南) |
N/A |
v13.0.0+ |
PyTorch (可选,参见 PyTorch 安装指南) |
N/A |
v1.10+ |
Qiskit (可选,参见 Qiskit 安装指南) |
N/A |
v0.24.0+ |
Cirq (可选,参见 Cirq 安装指南) |
N/A |
v0.6.0+ |
mpi4py (可选,参见 mpi4py 安装指南) |
N/A |
v3.1.0+ |
cuQuantum Appliance¶
CUDA |
11.x |
12.x |
驱动程序 |
470.57.02+ (Linux) |
525.60.13+ (Linux) |