分布式索引位交换 API¶
关于本文档¶
cuStateVec 库包含用于分布式索引位交换的 API,该 API 用于在多个设备和节点上分布状态向量模拟。本文档解释了其设计和用法。
分布式状态向量模拟¶
状态向量分布¶
在分布式状态向量模拟中,状态向量被平均分割并分布到多个 GPU。在 cuStateVec 中,这些分割的状态向量被称为子状态向量。子状态向量分布到 GPU,其数量是 2 的幂。
图 1 (a) 显示了状态向量分布的示例,其中 \(n_{local}\) 表示子状态向量的量子比特数。通过组合分布到 GPU 的多个子状态向量,可以向状态向量添加量子比特。图 1 中,四个子状态向量组合在一起,添加了 2 个 (\(= log_2(4)\)) 量子比特。
状态向量索引的位直接映射到量子线路中的量子比特(或线)。索引位有两种类型。第一种是 GPU 本地的子状态向量的索引位。第二种是对应于子状态向量索引的索引位。这些类型的索引位被称为本地索引位和全局索引位,如图 1 (b) 所示。
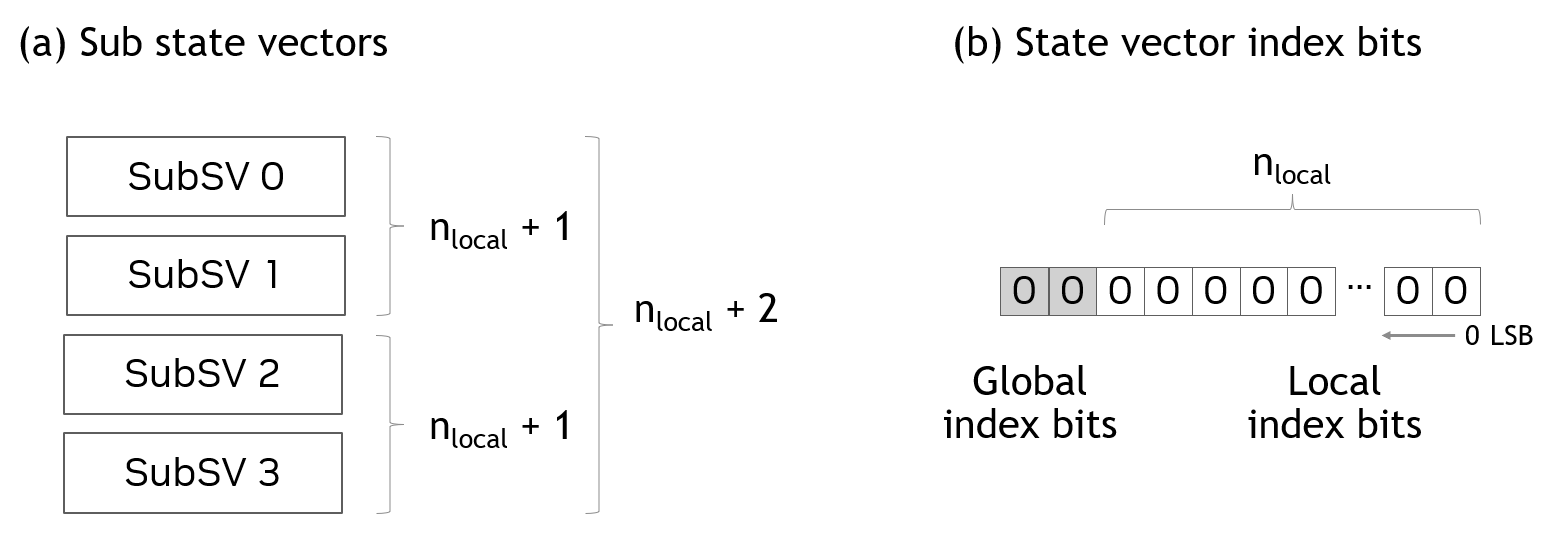
图 1. 子状态向量¶
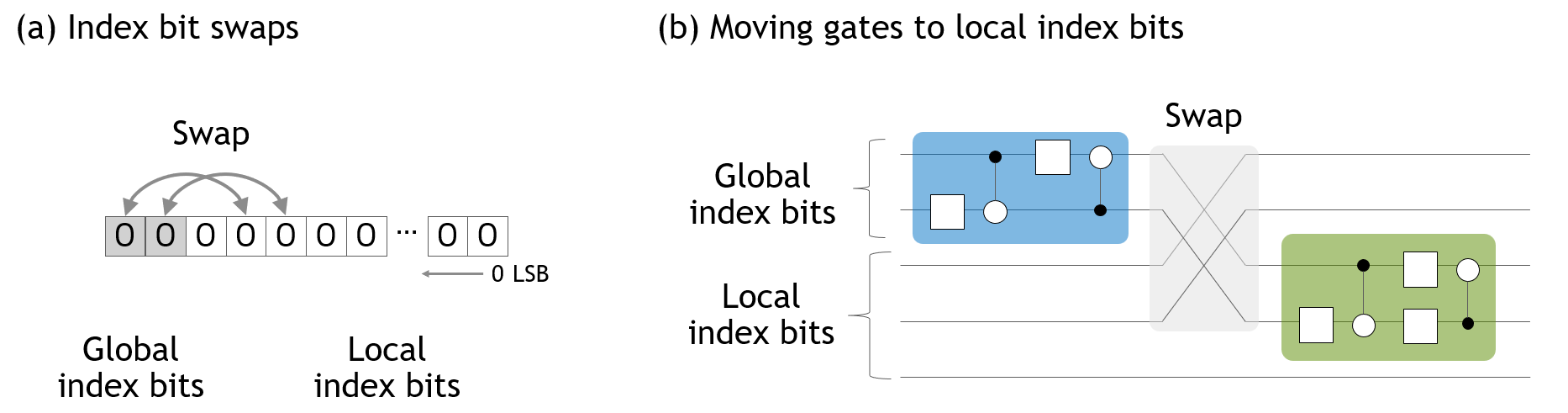
如果门作用于本地索引位,则门在每个子状态向量中并发应用,而无需访问其他 GPU。但是,如果门作用于全局索引位,则门应用需要访问多个子状态向量。由于子状态向量分布到多个 GPU,因此全局索引位上的门应用会导致 GPU 之间的数据传输,这是分布式状态向量模拟的性能限制因素。
要求¶
分布式索引位交换 API 需要以下条件。
单 GPU/单进程
此版本的主要重点是支持单 GPU/单进程配置 *。一个进程拥有一个 GPU 和一个子状态向量。子状态向量索引与分配子状态向量的进程的秩相同。
CUDA-aware MPI
MPI 库应该是 CUDA-aware 的。当前版本要求
MPI_Isend()和MPI_Irecv()接受设备指针。
注意
当前版本也允许单个进程中的多个子状态向量,但在同步方面存在限制。这是一个初步功能,将在未来的版本中得到支持。
API 设计¶
通过使用批处理索引来调度索引位交换¶
批处理索引定义为两个子状态向量索引的按位异或。通过为批处理索引赋值,定义了子状态向量对。
图 3 显示了四个子状态向量的示例。通过将批处理索引从 1 更改为 3 *,枚举了所有 GPU 对(图 3 (a))。一旦定义了子状态向量对,就从每个子状态向量的指定索引位交换中计算出用于交换状态向量元素的参数集(图 3 (b))。
由批处理索引控制的数据传输序列是分布式索引位交换 API 的关键概念。批处理索引组织了子状态向量之间并发的成对数据传输。
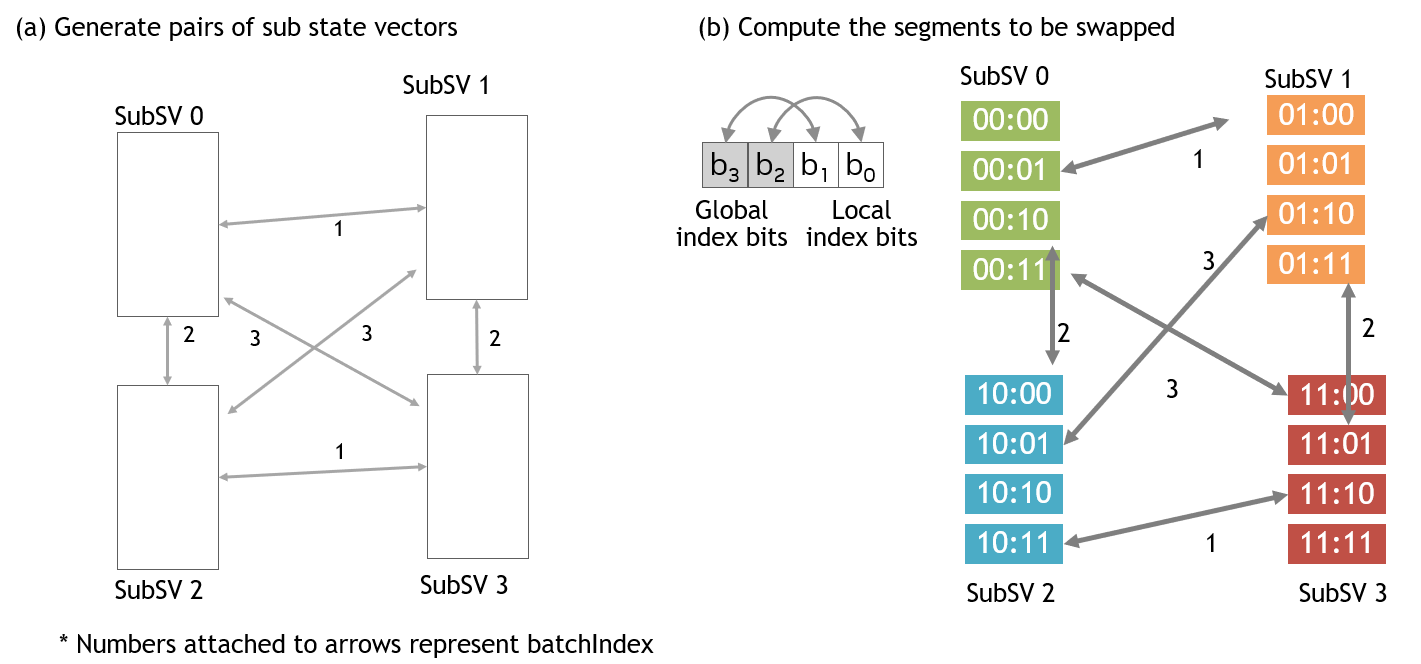
图 3. 索引位交换调度¶
注意
当全局-全局和全局-本地索引位交换混合时,批处理索引可以为 0。
在 cuStateVec API 中,custatevecDistIndexBitSwapScheduler 执行此任务。此组件接受索引位交换,然后根据批处理索引计算要交换的状态向量元素的基。计算出的参数通过使用 custatevecSVSwapParameters 获得。
交换状态向量元素¶
下一步是交换状态向量元素。custatevecSVSwapWorker 接受上一步中生成的参数,选择子状态向量元素,并交换它们。
custatevecSVSwapWorker 可以使用两条通信路径。
第一条路径是默认路径,使用 custatevecCommunicator,它包装了 MPI 库以进行进程间通信。有关详细信息,请参阅下一节。
第二条路径是可选路径,使用 GPUDirect P2P,它允许直接访问在其他进程中分配的设备内存指针。用户需要使用 CUDA IPC 来检索设备指针。通过调用 custatevecSVSwapWorkerSetSubSVsP2P() 将获得的 P2P 设备指针设置为 custatevecSVSwapWorker。有关详细用法,请参阅 custatevecSVSwapWorkerCreate() 和 custatevecSVSwapWorkerSetSubSVsP2P() 部分。
通过 custatevecCommunicator 进行进程间通信¶
当前版本的先决条件是每个进程拥有一个 GPU,并且每个 GPU 上分配了一个子状态向量。因此,进程间通信发生在子状态向量之间的数据交换期间。在 cuStateVec API 中,custatevecCommunicator 管理进程间通信。在当前版本中,MPI 是用于进程间通信的库,custatevecCommunicator 对其进行了包装。
由于 MPI 库的版本及其 ABI 各不相同,libcustatevec.so 不链接到任何特定的 MPI 库。相反,cuStateVec 提供了两种机制来利用 MPI 库。
MPI 库的动态加载
用户可以通过为
custatevecCommunicatorCreate()指定选项来使用最新版本的 Open MPI 或 MPICH。此函数使用dlopen()动态加载指定的库。ABI 差异在libcustatevec.so中管理。下面显示的版本已验证或预期可以工作。
Open MPI
已验证:v4.1.4 / UCX v1.13.1
预期可以工作:v3.0.x、v3.1.x、v4.0.x、v4.1.x
MPICH
已验证:v4.1
作为扩展的外部共享库
用户可以使用任何首选的 MPI 库。包装 MPI 库的源代码在 samples_mpi 目录下的 NVIDIA/cuQuantum 上提供。此源代码针对所选的 MPI 库进行编译,以生成共享库。如果我们通过
soname参数传递共享库的完整路径,则编译后的共享库将由custatevecCommunicatorCreate()动态加载。
示例¶
如上所述,分布式索引位交换 API 按以下步骤工作,如 图 4 所示。
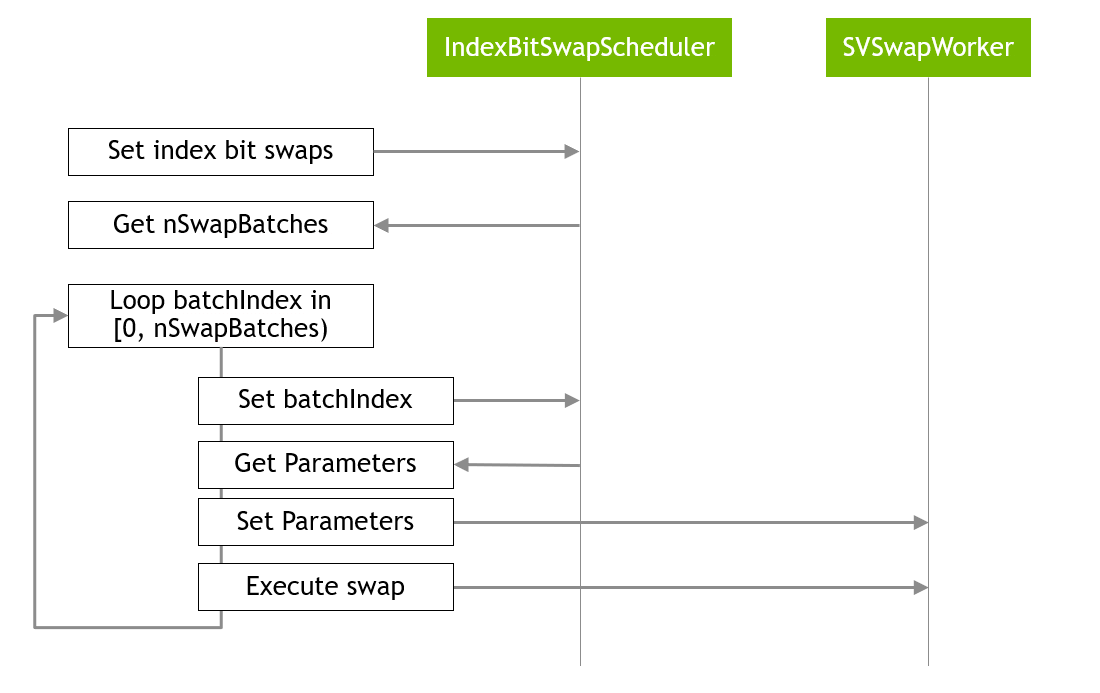
图 4. 分布式索引批处理交换的主循环¶
以下代码是示例的摘录。
// set the pairs of index bits being swapped
// get nSwapBatches as the number of batched swaps
unsigned nSwapBatches = 0;
custatevecDistIndexBitSwapSchedulerSetIndexBitSwaps(
handle, scheduler, indexBitSwaps, nIndexBitSwaps,
nullptr, nullptr, 0, &nSwapBatches);
// main loop, loop batchIndex in [0, nSwapBatches)
for (int batchIndex = 0; batchIndex < nSwapBatches; ++batchIndex)
{
// get parameters
custatevecSVSwapParameters_t parameters;
custatevecDistIndexBitSwapSchedulerGetParameters(
handle, scheduler, batchIndex, orgSubSVIndex, ¶meters);
// set parameters to the worker
custatevecSVSwapWorkerSetParameters(
handle, svSwapWorker, ¶meters, rank);
// execute swap
custatevecSVSwapWorkerExecute(
handle, svSwapWorker, 0, parameters.transferSize);
}
// synchronize all operations on device
cudaStreamSynchronize(localStream);
完整的示例代码可以在 NVIDIA/cuQuantum 存储库中找到。