概述¶
本节介绍 cuStateVec 库的基本工作原理。有关量子电路的一般介绍,请参阅 量子计算导论。
API 同步行为¶
cuStateVec API 设计为异步执行。它们的 API 同步行为遵循 API 同步行为 中 CUDA Runtime API 的描述。开发者需要适当调用 CUDA API 来同步 API 调用。
使用 CUDA 流¶
大多数 cuStateVec API 的执行都在附加到由 custatevecCreate() 创建的 cuStateVec 句柄的流上串行化。初始流是默认流。用户可以通过调用 custatevecSetStream() 将用户创建的流设置为 cuStateVec 句柄。所有类型的流(默认、阻塞和非阻塞)都是可接受的。API 调用通过适当的 CUDA API 调用(例如 cudaDeviceSynchronize、cudaStreamSynchronize 或 cudaStreamWaitEvent)同步。
分布式索引位交换 API 中有一个例外。custatevecSVSwapWorkerCreate() API 需要用户创建的流,该流专门用于数据传输。因此,其他 cuStateVec API 调用在附加到句柄的流上并发执行。此外,custatevecSVSwapWorkerExecute() 阻塞在调用 custatevecSVSwapWorkerCreate() API 时指定的流上,以便与数据传输的对等方同步。
状态向量的描述¶
在 cuStateVec 库中,状态向量始终以设备数组的形式给出,其数据类型由 cudaDataType_t 常量指定。用户有责任管理状态向量的内存。
此版本的 cuStateVec 库支持 128 位复数 (complex128) 和 64 位复数 (complex64) 作为状态向量的数据类型。状态向量的大小由 nIndexBits 参数表示,该参数对应于电路中量子比特的数量。因此,状态向量大小表示为 \(2^{\text{nIndexBits}}\)。
类型 custatevecIndex_t 用于表示状态向量索引,它是 64 位有符号整数的 typedef。它也用于表示状态向量元素的数量。
位顺序¶
在 cuStateVec 库中,状态向量索引的位顺序以小端顺序定义。第 0 个索引位是最低有效位 (LSB)。大多数函数接受参数以整数数组的形式指定位位置。这些位位置以小端顺序指定。位位置中的值范围为 \([0, \text{nIndexBits})\)。
cuStateVec 库以以下两种方式之一表示位字符串
一个 32 位有符号整数数组,用于一个位字符串
某些 API 使用一对 32 位有符号整数数组
bitString和bitOrdering参数来指定一个位字符串。bitString参数将位字符串值指定为 0 和 1 的数组。bitOrdering参数以小端顺序指定bitString数组元素的位位置。这两个数组都分配在主机内存上。在以下示例中,“10”被指定为一个位字符串。位字符串值映射到第 2 和第 3 个索引位,可用于指定位掩码,\(***\cdots *10*\)。
int32_t bitString[] = {0, 1} int32_t bitOrdering[] = {1, 2}
一个 64 位有符号整数数组,用于多个位字符串
某些 API 引入了一对
bitStrings和bitOrdering参数,以使用 custatevecIndex_t(它是 64 位有符号整数)表示每个位字符串,以处理具有小内存占用量的多个位字符串。bitOrdering参数是一个 32 位有符号整数数组,它以小端顺序指定bitStrings参数中每个位字符串的位位置。以下示例描述了与上一个示例中使用的相同的位字符串
custatevecIndex_t bitStrings[] = {0b10} int32_t bitOrdering[] = {1, 2}
bitStrings分配在主机内存上,但某些 API 允许bitStrings也分配在设备内存上。有关详细要求,请参阅每个 API 描述。
支持的数据类型¶
默认情况下,计算使用状态向量的相应精度执行,complex128 使用双精度浮点 (FP64),complex64 使用单精度浮点 (FP32)。
cuStateVec 库还提供了计算类型,允许以降低的精度进行计算。某些 cuStateVec 函数接受使用 custatevecComputeType_t 指定的计算类型。
下表列出了当前版本的 cuStateVec 库中可用的状态向量和计算类型的组合。
状态向量 / cudaDataType_t |
矩阵 / cudaDataType_t |
计算 / custatevecComputeType_t |
|---|---|---|
复数 128 / CUDA_C_64F |
复数 128 / CUDA_C_64F |
FP64 / CUSTATEVEC_COMPUTE_64F |
复数 64 / CUDA_C_32F |
复数 128 / CUDA_C_64F |
FP32 / CUSTATEVEC_COMPUTE_32F |
复数 64 / CUDA_C_32F |
复数 64 / CUDA_C_32F |
FP32 / CUSTATEVEC_COMPUTE_32F |
注意
CUSTATEVEC_COMPUTE_TF32 在此版本中不可用。
工作区¶
cuStateVec 库在内部管理用于执行函数的临时设备内存,这被称为上下文工作区。
上下文工作区附加到 cuStateVec 上下文,并在通过调用 custatevecCreate() 创建 cuStateVec 上下文时分配。上下文工作区的默认大小被选择为覆盖大多数典型用例,通过调用 custatevecGetDefaultWorkspaceSize() 获得。
当上下文工作区无法提供足够的临时内存量,或者当设备内存块由两个或多个函数共享时,用户有两种选择
用户可以为额外的工作区提供用户管理的设备内存。需要额外工作区的函数具有以
GetWorkspaceSize()为后缀的同级函数。如果这些函数通过extraBufferSizeInBytes参数返回非零值,则请求用户分配设备内存并将指向已分配内存的指针提供给相应的函数。额外的工作区应为 256 字节对齐,这通过使用cudaMalloc()分配设备内存自动满足。如果额外工作区的大小不足,则返回 CUSTATEVEC_STATUS_INSUFFICIENT_WORKSPACE。用户还可以设置设备内存处理程序。当它设置为 cuStateVec 库上下文时,库可以直接代表用户从池中提取内存。在这种情况下,用户不需要显式分配设备内存,并且可以在函数中将空指针(零大小)指定为额外的工作区(大小)。有关详细信息,请参阅 custatevecDeviceMemHandler_t 和 custatevecSetDeviceMemHandler()。
门融合¶
门应用在量子模拟器中的计算成本中占很大比例。我们可以通过将多个门融合为一个更大的门来减少门应用所需的总体内存占用量。
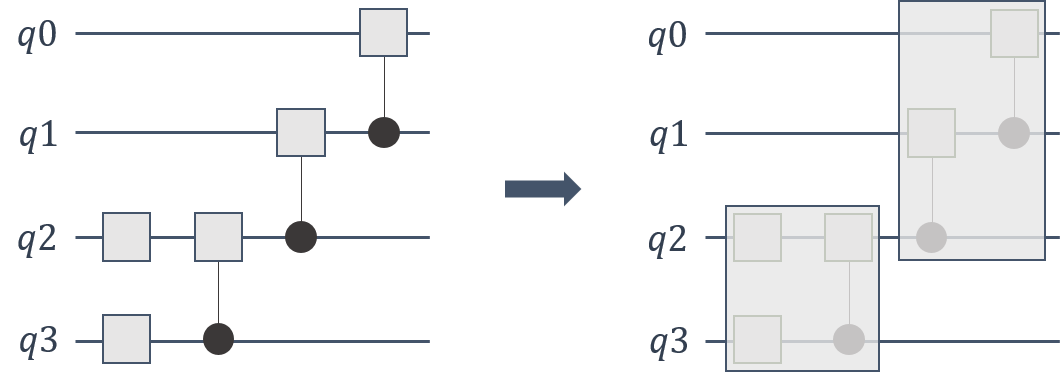
cuStateVec API 支持这些具有多个量子比特的通用门应用。有关详细信息,请参阅 custatevecApplyMatrix()。
多 GPU 计算¶
量子电路模拟中的内存使用量随着量子比特数量的增加呈指数增长。为了模拟更多量子比特,需要多个 GPU。一种典型的方法是将量子比特划分为全局量子比特和本地量子比特。
例如,具有 8 个状态向量元素的 3 量子比特系统可以平均分配到 4 个 GPU,如下图所示。
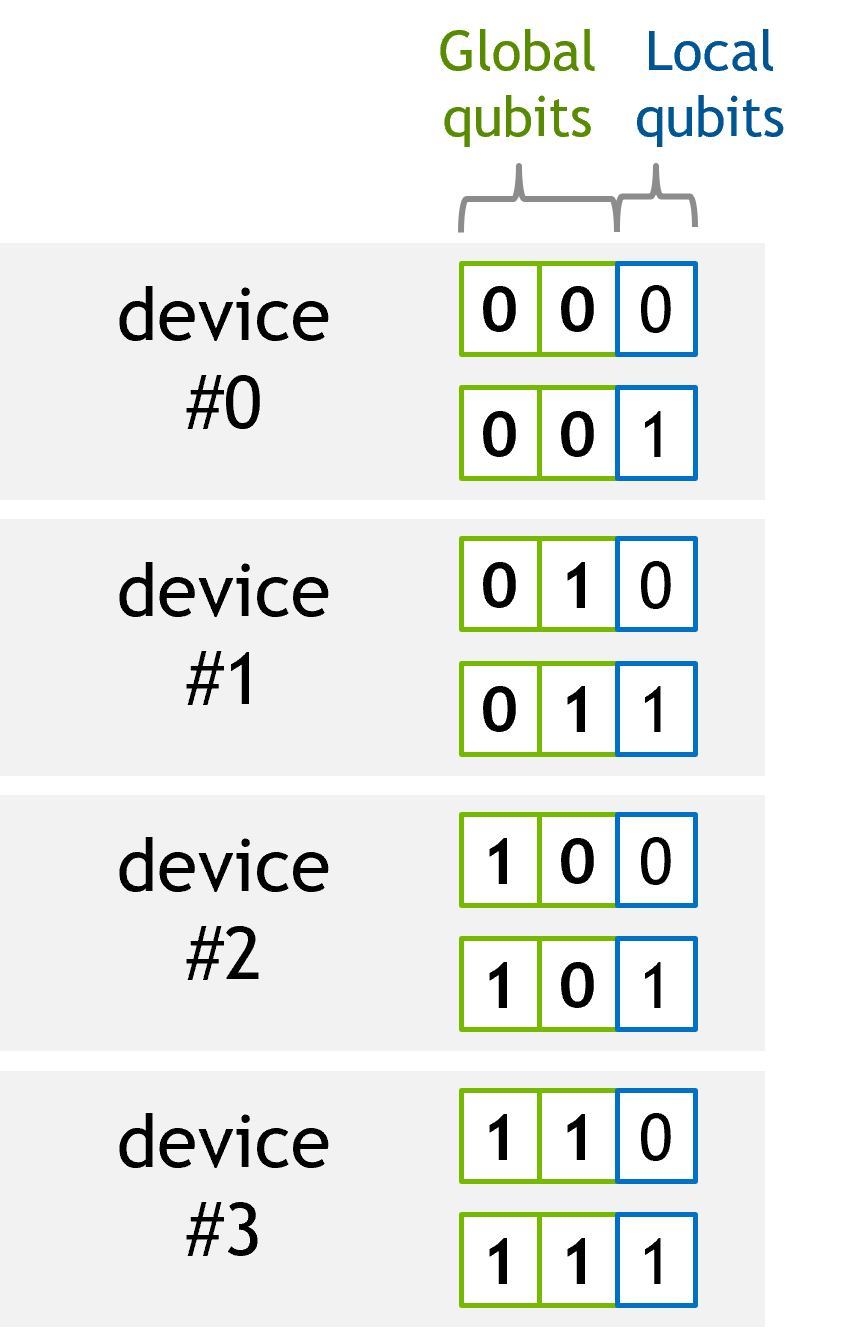
当为每个子状态向量分配索引时,它可以表示高阶量子比特。我们将这些量子比特称为全局量子比特,将其他量子比特称为本地量子比特。在上面的示例中,我们有 2 个全局量子比特和 1 个本地量子比特。
一般来说,对于一个 \(M\) 量子比特系统,假设每个 GPU 可以存储 \(2^N\) 个状态向量元素(对于 \(N\) 个本地量子比特),那么需要 \(2^{M-N}\) 个 GPU(即 \(M-N\) 个全局量子比特)来存储整个状态向量。第 \(k\) 个 GPU (\(k = (i_{M-1} i_{M-2} \cdots i_{N})_2\)) 存储状态向量元素 \(\alpha_{i_{M-1} i_{M-2} \cdots i_{N} i_{N-1} \cdots i_{0}}\),其中 \(i_p \in \{0, 1\}, 0 \leq p \leq N-1\)。
例如,
GPU #0 处理从 \(\alpha_{0_{M-1} \cdots 0_{N+1} 0_{N} 0_{N-1} \cdots 0_{0}}\) 到 \(\alpha_{0_{M-1} \cdots 0_{N+1} 0_{N} 1_{N-1} \cdots 1_{0}}\) 的元素,
GPU #1 处理从 \(\alpha_{0_{M-1} \cdots 0_{N+1} 1_{N} 0_{N-1} \cdots 0_{0}}\) 到 \(\alpha_{0_{M-1} \cdots 0_{N+1} 1_{N} 1_{N-1} \cdots 1_{0}}\) 的元素
GPU #2 处理从 \(\alpha_{0_{M-1} \cdots 1_{N+1} 0_{N} 0_{N-1} \cdots 0_{0}}\) 到 \(\alpha_{0_{M-1} \cdots 1_{N+1} 0_{N} 1_{N-1} \cdots 1_{0}}\) 的元素
GPU #3 处理从 \(\alpha_{0_{M-1} \cdots 1_{N+1} 1_{N} 0_{N-1} \cdots 0_{0}}\) 到 \(\alpha_{0_{M-1} \cdots 1_{N+1} 1_{N} 1_{N-1} \cdots 1_{0}}\) 的元素,依此类推。
这里,索引 \(i_{M-1}, i_{M-2}, \cdots, i_{N}\) 属于全局量子比特,其他索引属于本地量子比特。
cuStateVec 提供了用于多 GPU 量子比特测量、采样和量子比特重排序的 API。测量和采样 API 在单个 GPU 上工作,用户需要收集/分散每个 GPU 的结果。有关每个 API 的详细信息,请分别参阅 量子比特测量、采样 和 单进程量子比特重排序。
对于那些对多 GPU 量子模拟感兴趣的人,可以使用 NVIDIA cuQuantum Appliance。
注意
每个 GPU 都需要自己的 cuStateVec 句柄。此外,用户负责切换 CUDA 设备上下文。
批量状态向量模拟¶
cuStateVec 为一组状态向量提供门应用和量子比特测量 API。当使用许多小的状态向量进行计算时,将每个状态向量的 API 调用替换为单个批量 API 调用有望提高性能。
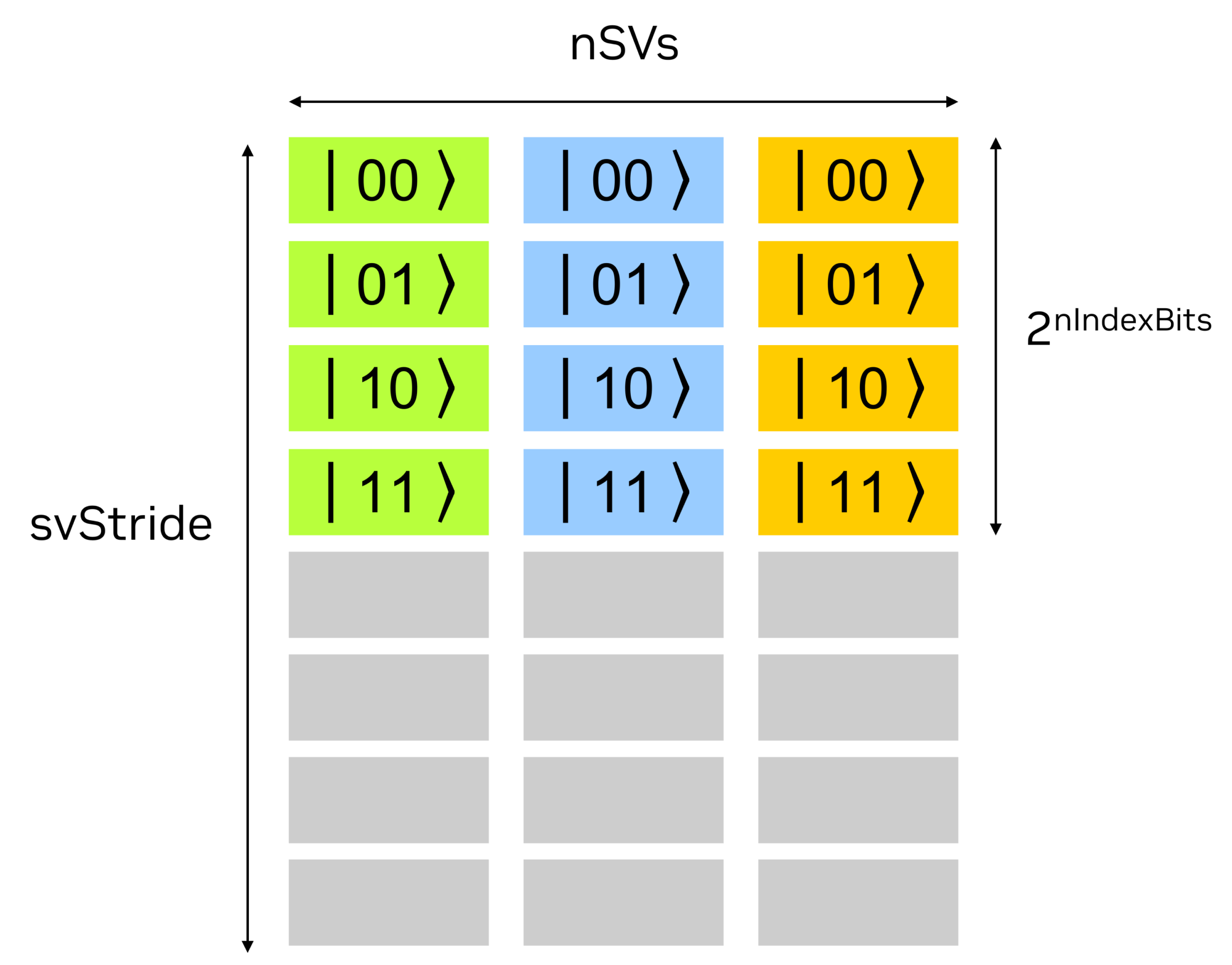
这些批量版本的 API 假定状态向量被分配为设备内存的一个连续块,并且需要三个参数来指定它们的位置
nSVs,批处理中状态向量的数量。
nIndexBits,每个状态向量中量子比特的数量。批处理中的所有状态向量都需要具有相同数量的量子比特。
svStride,两个状态向量之间以元素数量为单位的偏移量。它应等于或大于每个状态向量的大小,1 << nIndexBits。
例如,下图描述了一组状态向量,其中 nSVs = 3,nIndexBits = 2,以及 svStride = 8。这里,图中二维数组的每个元素都以列优先格式排序。
有关每个 API 的详细信息,请参阅 custatevecApplyMatrixBatched(), custatevecComputeExpectationBatched(), custatevecAbs2SumArrayBatched(), custatevecCollapseByBitStringBatched(), 和 custatevecMeasureBatched()。
引用 cuQuantum¶
Bayraktar et al., “cuQuantum SDK: A High-Performance Library for Accelerating Quantum Science,” 2023 IEEE International Conference on Quantum Computing and Engineering (QCE), Bellevue, WA, USA, 2023, pp. 1050-1061, doi: 10.1109/QCE57702.2023.00119.