cuTensorNet 函数¶
句柄管理 API¶
cutensornetCreate¶
-
cutensornetStatus_t cutensornetCreate(cutensornetHandle_t *handle)¶
初始化 cuTensorNet 库。
与特定 cuTensorNet 句柄关联的设备假定在调用 cutensornetCreate() 后保持不变。为了使 cuTensorNet 库使用不同的设备,应用程序必须通过调用 cudaSetDevice() 设置要使用的新设备,然后通过调用 cutensornetCreate() 创建另一个 cuTensorNet 句柄,该句柄将与新设备关联。
备注
阻塞,不可重入,且线程安全
- 参数
handle – [out] 指向 cutensornetHandle_t 的指针
- 返回值
成功时返回 CUTENSORNET_STATUS_SUCCESS,否则返回错误代码
cutensornetDestroy¶
-
cutensornetStatus_t cutensornetDestroy(cutensornetHandle_t handle)¶
销毁 cuTensorNet 库句柄。
此函数释放 cuTensorNet 库句柄使用的资源。此函数是使用特定句柄对 cuTensorNet 库的最后一次调用。在 cutensornetDestroy() 之后调用任何使用 cutensornetHandle_t 的 cuTensorNet 函数将返回错误。
- 参数
handle – [inout] 保存 cuTensorNet 库上下文的不透明句柄。
网络描述符 API¶
cutensornetCreateNetworkDescriptor¶
-
cutensornetStatus_t cutensornetCreateNetworkDescriptor(const cutensornetHandle_t handle, int32_t numInputs, const int32_t numModesIn[], const int64_t *const extentsIn[], const int64_t *const stridesIn[], const int32_t *const modesIn[], const cutensornetTensorQualifiers_t qualifiersIn[], int32_t numModesOut, const int64_t extentsOut[], const int64_t stridesOut[], const int32_t modesOut[], cudaDataType_t dataType, cutensornetComputeType_t computeType, cutensornetNetworkDescriptor_t *descNet)¶
初始化 cutensornetNetworkDescriptor_t,描述张量之间的连接性(即网络拓扑)。
请注意,此函数在堆上分配数据;因此,一旦不再需要
descNet,调用 cutensornetDestroyNetworkDescriptor() 至关重要。支持的数据类型组合包括
数据类型
计算类型
张量核心
CUDA_R_16F
CUTENSORNET_COMPUTE_32F
Volta+
CUDA_R_16BF
CUTENSORNET_COMPUTE_32F
Ampere+
CUDA_R_32F
CUTENSORNET_COMPUTE_32F
否
CUDA_R_32F
CUTENSORNET_COMPUTE_TF32
Ampere+
CUDA_R_32F
CUTENSORNET_COMPUTE_3XTF32
Ampere+
CUDA_R_32F
CUTENSORNET_COMPUTE_16BF
Ampere+
CUDA_R_32F
CUTENSORNET_COMPUTE_16F
Volta+
CUDA_R_64F
CUTENSORNET_COMPUTE_64F
Ampere+
CUDA_R_64F
CUTENSORNET_COMPUTE_32F
否
CUDA_C_32F
CUTENSORNET_COMPUTE_32F
否
CUDA_C_32F
CUTENSORNET_COMPUTE_TF32
Ampere+
CUDA_C_32F
CUTENSORNET_COMPUTE_3XTF32
Ampere+
CUDA_C_64F
CUTENSORNET_COMPUTE_64F
Ampere+
CUDA_C_64F
CUTENSORNET_COMPUTE_32F
否
注意
如果
stridesIn(stridesOut)设置为 0(NULL),则表示输入张量(输出张量)采用 Fortran(列优先)布局。注意
numModesOut可以设置为-1,以便 cuTensorNet 根据输入模式推断输出模式,或者设置为0以执行完全缩减。注意
如果
qualifiersIn设置为 0(NULL),cuTensorNet 将使用 cutensornetTensorQualifiers_t 中的默认值。- 参数
handle – [in] 保存 cuTensorNet 库上下文的不透明句柄。
numInputs – [in] 输入张量的数量。
numModesIn – [in] 大小为
numInputs的数组;numModesIn[i]表示第 i 个张量中可用的模式数量。extentsIn – [in] 大小为
numInputs的数组;extentsIn[i]具有numModesIn[i]个条目,其中extentsIn[i][j](j<numModesIn[i]) 对应于张量i的第 j 个模式的范围。stridesIn – [in] 大小为
numInputs的数组;stridesIn[i]具有numModesIn[i]个条目,其中stridesIn[i][j](j<numModesIn[i]) 对应于张量i的第 j 个模式的两个逻辑相邻元素之间物理内存中的线性化偏移量。modesIn – [in] 大小为
numInputs的数组;modesIn[i]具有numModesIn[i]个条目,每个条目对应一个模式。输入张量中未出现的每个模式都隐式收缩。qualifiersIn – [in] 大小为
numInputs的数组;qualifiersIn[i]表示第 i 个输入张量的限定符。请参阅 cutensornetTensorQualifiers_tnumModesOut – [in] 输出张量的模式数。在入口处,如果此值为
-1且未提供输出模式,则网络将推断输出模式。如果此值为0,则网络将被强制缩减。extentsOut – [in] 大小为
numModesOut的数组;extentsOut[j](j<numModesOut) 对应于输出张量的第 j 个模式的范围。stridesOut – [in] 大小为
numModesOut的数组;stridesOut[j](j<numModesOut) 对应于输出张量的第 j 个模式的两个逻辑相邻元素之间物理内存中的线性化偏移量。modesOut – [in] 大小为
numModesOut的数组;modesOut[j]表示输出张量的第 j 个模式。输出张量。dataType – [in] 表示所有输入和输出张量的数据类型。
computeType – [in] 表示整个计算中使用的计算类型。
descNet – [out] 指向 cutensornetNetworkDescriptor_t 的指针。
cutensornetDestroyNetworkDescriptor¶
-
cutensornetStatus_t cutensornetDestroyNetworkDescriptor(cutensornetNetworkDescriptor_t desc)¶
释放与网络描述符关联的所有内存。
- 参数
desc – [inout] 指向张量网络描述符的不透明句柄。
cutensornetNetworkGetAttribute¶
-
cutensornetStatus_t cutensornetNetworkGetAttribute(const cutensornetHandle_t handle, const cutensornetNetworkDescriptor_t networkDesc, cutensornetNetworkAttributes_t attr, void *buf, size_t sizeInBytes)¶
获取 networkDescriptor 的属性。
- 参数
handle – [in] 保存 cuTensorNet 库上下文的不透明句柄。
networkDesc – [in] 要访问的不透明结构体。
attr – [in] 指定请求的属性。
buf – [out] 返回时,此缓冲区(大小为
sizeInBytes)保存与networkDesc中的attr对应的值。sizeInBytes – [in]
buf的大小(以字节为单位)。
cutensornetNetworkSetAttribute¶
-
cutensornetStatus_t cutensornetNetworkSetAttribute(const cutensornetHandle_t handle, cutensornetNetworkDescriptor_t networkDesc, cutensornetNetworkAttributes_t attr, const void *buf, size_t sizeInBytes)¶
设置 networkDescriptor 的属性。
- 参数
handle – [in] 保存 cuTensorNet 库上下文的不透明句柄。
networkDesc – [inout] 要访问的不透明结构体。
attr – [in] 指定请求的属性。
buf – [in] 此缓冲区(大小为
sizeInBytes)确定attr将被设置的值。sizeInBytes – [in]
buf的大小(以字节为单位)。
cutensornetGetOutputTensorDetails¶
-
cutensornetStatus_t cutensornetGetOutputTensorDetails(const cutensornetHandle_t handle, const cutensornetNetworkDescriptor_t descNet, int32_t *numModes, size_t *dataSize, int32_t *modeLabels, int64_t *extents, int64_t *strides)¶
已弃用:获取输出张量的模式数量、数据大小、模式标签、范围和步幅。
如果用户需要关于输出张量的所有信息,则应调用此函数两次(第一次检索
numModesOut以分配内存,第二次检索modesOut、extentsOut和stridesOut)。- 参数
handle – [in] 保存 cuTensorNet 库上下文的不透明句柄。
descNet – [in] 指向 cutensornetNetworkDescriptor_t 的指针。
numModes – [out] 返回时,保存输出张量的模式数量。不能为空。
dataSize – [out] 如果返回时非空,则保存输出张量所需的内存大小(以字节为单位)。可选,可以为空。
modeLabels – [out] 如果返回时非空,则保存输出张量的模式标签。可选,可以为空。
extents – [out] 如果返回时非空,则保存输出张量的范围。可选,可以为空。
strides – [out] 如果返回时非空,则保存输出张量的步幅。可选,可以为空。
cutensornetGetOutputTensorDescriptor¶
-
cutensornetStatus_t cutensornetGetOutputTensorDescriptor(const cutensornetHandle_t handle, const cutensornetNetworkDescriptor_t descNet, cutensornetTensorDescriptor_t *outputTensorDesc)¶
创建表示网络输出张量的 cutensornetTensorDescriptor_t。
此函数将创建由
outputTensorDesc指向的描述符。用户负责调用 cutensornetDestroyTensorDescriptor 来销毁描述符。- 参数
handle – [in] 保存 cuTensorNet 库上下文的不透明句柄。
descNet – [in] 指向 cutensornetNetworkDescriptor_t 的指针。
outputTensorDesc – [out] 不透明的 cutensornetTensorDescriptor_t 结构体。不能为空。返回时,新的 cutensornetTensorDescriptor_t 保存
descNet输出张量的元数据。
张量描述符 API¶
cutensornetCreateTensorDescriptor¶
-
cutensornetStatus_t cutensornetCreateTensorDescriptor(const cutensornetHandle_t handle, int32_t numModes, const int64_t extents[], const int64_t strides[], const int32_t modes[], cudaDataType_t dataType, cutensornetTensorDescriptor_t *descTensor)¶
初始化 cutensornetTensorDescriptor_t,描述张量的信息。
请注意,此函数在堆上分配数据;因此,一旦不再需要
descTensor,调用 cutensornetDestroyTensorDescriptor() 至关重要。注意
如果
strides设置为NULL,则表示张量采用 Fortran(列优先)布局。- 参数
handle – [in] 保存 cuTensorNet 库上下文的不透明句柄。
numModes – [in] 张量的模式数量。
extents – [in] 大小为
numModes的数组;extents[j]对应于张量第 j 个模式的范围。strides – [in] 大小为
numModes的数组;strides[j]对应于相对于张量第 j 个模式的两个逻辑相邻元素之间在物理内存中的线性偏移量。modes – [in] 大小为
numModes的数组;modes[j]表示张量的第 j 个模式。dataType – [in] 表示张量的数据类型。
descTensor – [out] 指向 cutensornetTensorDescriptor_t 的指针。
cutensornetGetTensorDetails¶
-
cutensornetStatus_t cutensornetGetTensorDetails(const cutensornetHandle_t handle, const cutensornetTensorDescriptor_t tensorDesc, int32_t *numModes, size_t *dataSize, int32_t *modeLabels, int64_t *extents, int64_t *strides)¶
获取张量的模式数量、数据大小、模式标签、范围和步幅。
如果用户需要关于张量的所有信息,则应调用此函数两次(第一次检索
numModes以分配内存,第二次检索modeLabels、extents和strides)。- 参数
handle – [in] 保存 cuTensorNet 库上下文的不透明句柄。
tensorDesc – [in] 张量描述符的不透明句柄。
numModes – [out] 返回时,保存张量的模式数量。不能为空。
dataSize – [out] 如果返回时非空,则保存张量所需的内存大小(以字节为单位)。可选,可以为空。
modeLabels – [out] 如果返回时非空,则保存张量的模式标签。可选,可以为空。
extents – [out] 如果返回时非空,则保存张量的范围。可选,可以为空。
strides – [out] 如果返回时非空,则保存张量的步幅。可选,可以为空。
cutensornetDestroyTensorDescriptor¶
-
cutensornetStatus_t cutensornetDestroyTensorDescriptor(cutensornetTensorDescriptor_t descTensor)¶
释放与张量描述符关联的所有内存。
- 参数
descTensor – [inout] 张量描述符的不透明句柄。
收缩优化器 API¶
cutensornetCreateContractionOptimizerConfig¶
-
cutensornetStatus_t cutensornetCreateContractionOptimizerConfig(const cutensornetHandle_t handle, cutensornetContractionOptimizerConfig_t *optimizerConfig)¶
为收缩顺序求解器设置所需的超优化参数(参见 cutensornetContractionOptimize())。
请注意,此函数在堆上分配数据;因此,一旦不再需要
optimizerConfig,调用 cutensornetDestroyContractionOptimizerConfig() 至关重要。- 参数
handle – [in] 保存 cuTensorNet 库上下文的不透明句柄。
optimizerConfig – [out] 此数据结构保存有关用户请求的超优化参数的所有信息。
cutensornetDestroyContractionOptimizerConfig¶
-
cutensornetStatus_t cutensornetDestroyContractionOptimizerConfig(cutensornetContractionOptimizerConfig_t optimizerConfig)¶
释放与
optimizerConfig关联的所有内存。- 参数
optimizerConfig – [inout] 不透明结构体。
cutensornetContractionOptimizerConfigGetAttribute¶
-
cutensornetStatus_t cutensornetContractionOptimizerConfigGetAttribute(const cutensornetHandle_t handle, const cutensornetContractionOptimizerConfig_t optimizerConfig, cutensornetContractionOptimizerConfigAttributes_t attr, void *buf, size_t sizeInBytes)¶
获取
optimizerConfig的属性。- 参数
handle – [in] 保存 cuTensorNet 库上下文的不透明句柄。
optimizerConfig – [in] 要访问的不透明结构体。
attr – [in] 指定请求的属性。
buf – [out] 返回时,此缓冲区(大小为
sizeInBytes)保存与optimizerConfig中的attr对应的值。sizeInBytes – [in]
buf的大小(以字节为单位)。
cutensornetContractionOptimizerConfigSetAttribute¶
-
cutensornetStatus_t cutensornetContractionOptimizerConfigSetAttribute(const cutensornetHandle_t handle, cutensornetContractionOptimizerConfig_t optimizerConfig, cutensornetContractionOptimizerConfigAttributes_t attr, const void *buf, size_t sizeInBytes)¶
设置
optimizerConfig的属性。- 参数
handle – [in] 保存 cuTensorNet 库上下文的不透明句柄。
optimizerConfig – [inout] 要访问的不透明结构体。
attr – [in] 指定请求的属性。
buf – [in] 此缓冲区(大小为
sizeInBytes)确定attr将被设置的值。sizeInBytes – [in]
buf的大小(以字节为单位)。
cutensornetCreateContractionOptimizerInfo¶
-
cutensornetStatus_t cutensornetCreateContractionOptimizerInfo(const cutensornetHandle_t handle, const cutensornetNetworkDescriptor_t descNet, cutensornetContractionOptimizerInfo_t *optimizerInfo)¶
为
optimizerInfo分配资源。请注意,此函数在堆上分配数据;因此,一旦不再需要
optimizerInfo,调用 cutensornetDestroyContractionOptimizerInfo() 至关重要。- 参数
handle – [in] 保存 cuTensorNet 库上下文的不透明句柄。
descNet – [in] 描述张量网络(即,其张量及其连通性),为其创建
optimizerInfo。optimizerInfo – [out] 指向 cutensornetContractionOptimizerInfo_t 的指针。
cutensornetDestroyContractionOptimizerInfo¶
-
cutensornetStatus_t cutensornetDestroyContractionOptimizerInfo(cutensornetContractionOptimizerInfo_t optimizerInfo)¶
释放与
optimizerInfo关联的所有内存。- 参数
optimizerInfo – [inout] 不透明结构体。
cutensornetContractionOptimize¶
-
cutensornetStatus_t cutensornetContractionOptimize(const cutensornetHandle_t handle, const cutensornetNetworkDescriptor_t descNet, const cutensornetContractionOptimizerConfig_t optimizerConfig, uint64_t workspaceSizeConstraint, cutensornetContractionOptimizerInfo_t optimizerInfo)¶
为给定的张量网络计算“优化”的收缩顺序以及切片信息(有关更多信息,请参见概述部分),以便在遵守用户提供的内存约束的同时,最大限度地缩短总求解时间。
- 参数
handle – [in] 保存 cuTensorNet 库上下文的不透明句柄。
descNet – [in] 描述张量网络的拓扑结构(即,所有张量、它们的连通性和模式)。
optimizerConfig – [in] 保存所有超优化参数,这些参数控制对“最优”收缩顺序的搜索。
workspaceSizeConstraint – [in] 用户将提供的最大设备内存(即,cuTensorNet 必须在此用户定义的约束内找到可行的路径/切片解决方案)。
optimizerInfo – [inout] 返回时,此对象将保存有关优化路径和相关切片信息的所有必要信息。
optimizerInfo将保存的信息包括(参见 cutensornetContractionOptimizerInfoAttributes_t)切片的总数。
切片模式的总数。
关于切片模式的信息 (即切片模式的 ID (关于
modesIn,请参阅 cutensornetCreateNetworkDescriptor()) 以及它们的外延 (有关更多文档,请参阅概述部分))。优化的路径。
浮点运算计数。
最大中间张量中的元素总数。
所有中间张量的模式标签。
估计的运行时和“有效”浮点运算。
cutensornetContractionOptimizerInfoGetAttribute¶
-
cutensornetStatus_t cutensornetContractionOptimizerInfoGetAttribute(const cutensornetHandle_t handle, const cutensornetContractionOptimizerInfo_t optimizerInfo, cutensornetContractionOptimizerInfoAttributes_t attr, void *buf, size_t sizeInBytes)¶
获取
optimizerInfo的属性。- 参数
handle – [in] 保存 cuTensorNet 库上下文的不透明句柄。
optimizerInfo – [in] 要访问的不透明结构。
attr – [in] 指定请求的属性。
buf – [out] 返回时,此缓冲区 (大小为
sizeInBytes) 保存与optimizeInfo中的attr对应的值。sizeInBytes – [in]
buf的大小(以字节为单位)。
cutensornetContractionOptimizerInfoSetAttribute¶
-
cutensornetStatus_t cutensornetContractionOptimizerInfoSetAttribute(const cutensornetHandle_t handle, cutensornetContractionOptimizerInfo_t optimizerInfo, cutensornetContractionOptimizerInfoAttributes_t attr, const void *buf, size_t sizeInBytes)¶
设置 optimizerInfo 的属性。
- 参数
handle – [in] 保存 cuTensorNet 库上下文的不透明句柄。
optimizerInfo – [inout] 要访问的不透明结构。
attr – [in] 指定请求的属性。
buf – [in] 此缓冲区(大小为
sizeInBytes)确定attr将被设置的值。sizeInBytes – [in]
buf的大小(以字节为单位)。
cutensornetContractionOptimizerInfoGetPackedSize¶
-
cutensornetStatus_t cutensornetContractionOptimizerInfoGetPackedSize(const cutensornetHandle_t handle, const cutensornetContractionOptimizerInfo_t optimizerInfo, size_t *sizeInBytes)¶
获取
optimizerInfo对象的打包大小。- 参数
handle – [in] 保存 cuTensorNet 库上下文的不透明句柄。
optimizerInfo – [in] 类型为 cutensornetContractionOptimizerInfo_t 的不透明结构。
sizeInBytes – [out] 打包大小 (以字节为单位)。
cutensornetContractionOptimizerInfoPackData¶
-
cutensornetStatus_t cutensornetContractionOptimizerInfoPackData(const cutensornetHandle_t handle, const cutensornetContractionOptimizerInfo_t optimizerInfo, void *buffer, size_t sizeInBytes)¶
将
optimizerInfo对象打包到提供的缓冲区中。- 参数
handle – [in] 保存 cuTensorNet 库上下文的不透明句柄。
optimizerInfo – [in] 类型为 cutensornetContractionOptimizerInfo_t 的不透明结构。
buffer – [out] 返回时,此缓冲区以打包形式保存 optimizerInfo 的内容。
sizeInBytes – [in] 缓冲区的大小 (以字节为单位)。
cutensornetCreateContractionOptimizerInfoFromPackedData¶
-
cutensornetStatus_t cutensornetCreateContractionOptimizerInfoFromPackedData(const cutensornetHandle_t handle, const cutensornetNetworkDescriptor_t descNet, const void *buffer, size_t sizeInBytes, cutensornetContractionOptimizerInfo_t *optimizerInfo)¶
从提供的缓冲区创建 optimizerInfo 对象。
- 参数
handle – [in] 保存 cuTensorNet 库上下文的不透明句柄。
descNet – [in] 描述张量网络(即,其张量及其连通性),为其创建
optimizerInfo。buffer – [in] 包含打包形式的 optimizerInfo 内容的缓冲区。
sizeInBytes – [in] 缓冲区的大小 (以字节为单位)。
optimizerInfo – [out] 指向 cutensornetContractionOptimizerInfo_t 的指针。
cutensornetUpdateContractionOptimizerInfoFromPackedData¶
-
cutensornetStatus_t cutensornetUpdateContractionOptimizerInfoFromPackedData(const cutensornetHandle_t handle, const void *buffer, size_t sizeInBytes, cutensornetContractionOptimizerInfo_t optimizerInfo)¶
从提供的缓冲区更新提供的
optimizerInfo对象。- 参数
handle – [in] 保存 cuTensorNet 库上下文的不透明句柄。
buffer – [in] 包含打包形式的 optimizerInfo 内容的缓冲区。
sizeInBytes – [in] 缓冲区的大小 (以字节为单位)。
optimizerInfo – [inout] 类型为 cutensornetContractionOptimizerInfo_t 的不透明对象,将被更新。
缩并计划 API¶
cutensornetCreateContractionPlan¶
-
cutensornetStatus_t cutensornetCreateContractionPlan(const cutensornetHandle_t handle, const cutensornetNetworkDescriptor_t descNet, const cutensornetContractionOptimizerInfo_t optimizerInfo, const cutensornetWorkspaceDescriptor_t workDesc, cutensornetContractionPlan_t *plan)¶
初始化 cutensornetContractionPlan_t。
请注意,此函数在堆上分配数据;因此,一旦不再需要
plan,调用 cutensornetDestroyContractionPlan() 至关重要。- 参数
handle – [in] 保存 cuTensorNet 库上下文的不透明句柄。
descNet – [in] 描述张量网络 (即,其张量及其连通性)。
optimizerInfo – [in] 不透明结构。
workDesc – [in] 描述工作区的不透明结构。在创建缩并计划时,仅需要工作区大小;工作区内存的指针可以留空。如果设置了设备内存处理程序,则可以将
workDesc设置为 null (在这种情况下,将推断“推荐”工作区大小,请参阅 CUTENSORNET_WORKSIZE_PREF_RECOMMENDED) 或设置为有效的 cutensornetWorkspaceDescriptor_t,其中设置了期望的工作区大小并且工作区指针为空,请参阅“内存管理 API”部分。plan – [out] cuTensorNet 的缩并计划保存执行张量缩并所需的所有信息;准确地说,它为收缩整个张量网络所需的每个张量缩并初始化一个
cutensorContractionPlan_t。
cutensornetDestroyContractionPlan¶
-
cutensornetStatus_t cutensornetDestroyContractionPlan(cutensornetContractionPlan_t plan)¶
释放
plan拥有的所有资源。- 参数
plan – [inout] 不透明结构。
cutensornetContractionAutotune¶
-
cutensornetStatus_t cutensornetContractionAutotune(const cutensornetHandle_t handle, cutensornetContractionPlan_t plan, const void *const rawDataIn[], void *rawDataOut, cutensornetWorkspaceDescriptor_t workDesc, const cutensornetContractionAutotunePreference_t pref, cudaStream_t stream)¶
自动调整缩并计划,以找到每个成对缩并的最佳
cutensorContractionPlan_t。注意
由于自动调整过程的性质,此函数是阻塞的。
注意
建议输入和输出数据指针为 256 字节对齐,以获得最佳性能。
- 参数
handle – [in] 保存 cuTensorNet 库上下文的不透明句柄。
plan – [inout] 计划必须已创建 (请参阅 cutensornetCreateContractionPlan());将对各个缩并计划进行微调。
rawDataIn – [in] N 个指针的数组 (N 是 cutensornetCreateNetworkDescriptor() 指定的输入张量的数量);
rawDataIn[i]指向与第 i 个输入张量关联的数据 (在设备内存中)。rawDataOut – [out] 指向输出张量的原始数据 (在设备内存中)。
workDesc – [in] 描述工作区的不透明结构。提供的工作区必须是有效的 (工作区大小必须等于或大于最小需要大小以及计划创建时提供的值)。请参阅 cutensornetCreateContractionPlan()、cutensornetWorkspaceGetMemorySize() 和 cutensornetWorkspaceSetMemory()。如果设置了设备内存处理程序,则可以将
workDesc设置为 null,或者可以将workDesc中的工作区指针设置为 null,并且可以将工作区大小设置为 0 (在这种情况下,使用“推荐”大小,请参阅 CUTENSORNET_WORKSIZE_PREF_RECOMMENDED) 或设置为有效大小。指定大小的工作区将从用户的内存池中提取,并在完成后释放回内存池。pref – [in] 控制自动调整过程,并使用户可以控制在此例程中花费的时间。
stream – [in] 执行计算的 CUDA 流。
cutensornetCreateContractionAutotunePreference¶
-
cutensornetStatus_t cutensornetCreateContractionAutotunePreference(const cutensornetHandle_t handle, cutensornetContractionAutotunePreference_t *autotunePreference)¶
为缩并计划设置所需的自动调整参数。
请注意,此函数在堆上分配数据;因此,一旦不再需要
autotunePreference,调用 cutensornetDestroyContractionAutotunePreference() 至关重要。- 参数
handle – [in] 保存 cuTensorNet 库上下文的不透明句柄。
autotunePreference – [out] 此数据结构保存有关用户请求的自动调整参数的所有信息。
cutensornetContractionAutotunePreferenceGetAttribute¶
-
cutensornetStatus_t cutensornetContractionAutotunePreferenceGetAttribute(const cutensornetHandle_t handle, const cutensornetContractionAutotunePreference_t autotunePreference, cutensornetContractionAutotunePreferenceAttributes_t attr, void *buf, size_t sizeInBytes)¶
获取
autotunePreference的属性。- 参数
handle – [in] 保存 cuTensorNet 库上下文的不透明句柄。
autotunePreference – [in] 要访问的不透明结构。
attr – [in] 指定请求的属性。
buf – [out] 返回时,此缓冲区 (大小为
sizeInBytes) 保存与autotunePreference中的attr对应的值。sizeInBytes – [in]
buf的大小(以字节为单位)。
cutensornetContractionAutotunePreferenceSetAttribute¶
-
cutensornetStatus_t cutensornetContractionAutotunePreferenceSetAttribute(const cutensornetHandle_t handle, cutensornetContractionAutotunePreference_t autotunePreference, cutensornetContractionAutotunePreferenceAttributes_t attr, const void *buf, size_t sizeInBytes)¶
设置
autotunePreference的属性。- 参数
handle – [in] 保存 cuTensorNet 库上下文的不透明句柄。
autotunePreference – [inout] 要访问的不透明结构。
attr – [in] 指定请求的属性。
buf – [in] 此缓冲区(大小为
sizeInBytes)确定attr将被设置的值。sizeInBytes – [in]
buf的大小(以字节为单位)。
cutensornetDestroyContractionAutotunePreference¶
-
cutensornetStatus_t cutensornetDestroyContractionAutotunePreference(cutensornetContractionAutotunePreference_t autotunePreference)¶
释放与
autotunePreference关联的所有内存。- 参数
autotunePreference – [inout] 不透明结构。
工作区管理 API¶
cutensornetCreateWorkspaceDescriptor¶
-
cutensornetStatus_t cutensornetCreateWorkspaceDescriptor(const cutensornetHandle_t handle, cutensornetWorkspaceDescriptor_t *workDesc)¶
创建工作区描述符,用于保存关于用户提供的内存缓冲区的信息。
- 参数
handle – [in] 保存 cuTensorNet 库上下文的不透明句柄。
workDesc – [out] 指向不透明工作区描述符的指针。
cutensornetWorkspaceComputeSizes¶
-
cutensornetStatus_t cutensornetWorkspaceComputeSizes(const cutensornetHandle_t handle, const cutensornetNetworkDescriptor_t descNet, const cutensornetContractionOptimizerInfo_t optimizerInfo, cutensornetWorkspaceDescriptor_t workDesc)¶
已弃用:计算收缩输入张量网络并使用提供的收缩路径所需的工作区大小。
- 参数
handle – [in] 保存 cuTensorNet 库上下文的不透明句柄。
descNet – [in] 描述张量网络 (即,其张量及其连通性)。
optimizerInfo – [in] 不透明结构。
workDesc – [out] 用于收集信息的工作区描述符。
cutensornetWorkspaceComputeContractionSizes¶
-
cutensornetStatus_t cutensornetWorkspaceComputeContractionSizes(const cutensornetHandle_t handle, const cutensornetNetworkDescriptor_t descNet, const cutensornetContractionOptimizerInfo_t optimizerInfo, cutensornetWorkspaceDescriptor_t workDesc)¶
计算收缩输入张量网络并使用提供的收缩路径所需的工作区大小。
- 参数
handle – [in] 保存 cuTensorNet 库上下文的不透明句柄。
descNet – [in] 描述张量网络 (即,其张量及其连通性)。
optimizerInfo – [in] 不透明结构。
workDesc – [out] 用于收集信息的工作区描述符。
cutensornetWorkspaceComputeQRSizes¶
-
cutensornetStatus_t cutensornetWorkspaceComputeQRSizes(const cutensornetHandle_t handle, const cutensornetTensorDescriptor_t descTensorIn, const cutensornetTensorDescriptor_t descTensorQ, const cutensornetTensorDescriptor_t descTensorR, cutensornetWorkspaceDescriptor_t workDesc)¶
计算执行张量 QR 分解操作所需的工作区大小。
- 参数
handle – [in] 保存 cuTensorNet 库上下文的不透明句柄。
descTensorIn – [in] 描述张量的模式、维度和其他元数据信息。
descTensorQ – [in] 描述输出张量 Q 的模式、维度和其他元数据信息。
descTensorR – [in] 描述输出张量 R 的模式、维度和其他元数据信息。
workDesc – [out] 用于收集信息的工作区描述符。
cutensornetWorkspaceComputeSVDSizes¶
-
cutensornetStatus_t cutensornetWorkspaceComputeSVDSizes(const cutensornetHandle_t handle, const cutensornetTensorDescriptor_t descTensorIn, const cutensornetTensorDescriptor_t descTensorU, const cutensornetTensorDescriptor_t descTensorV, const cutensornetTensorSVDConfig_t svdConfig, cutensornetWorkspaceDescriptor_t workDesc)¶
计算执行张量 SVD 分解操作所需的工作区大小。
- 参数
handle – [in] 保存 cuTensorNet 库上下文的不透明句柄。
descTensorIn – [in] 描述张量的模式、维度和其他元数据信息。
descTensorU – [in] 描述输出张量 U 的模式、维度和其他元数据信息。
descTensorV – [in] 描述输出张量 V 的模式、维度和其他元数据信息。
svdConfig – [in] 此数据结构保存用户请求的 SVD 参数。
workDesc – [out] 用于收集信息的工作区描述符。
cutensornetWorkspaceComputeGateSplitSizes¶
-
cutensornetStatus_t cutensornetWorkspaceComputeGateSplitSizes(const cutensornetHandle_t handle, const cutensornetTensorDescriptor_t descTensorInA, const cutensornetTensorDescriptor_t descTensorInB, const cutensornetTensorDescriptor_t descTensorInG, const cutensornetTensorDescriptor_t descTensorU, const cutensornetTensorDescriptor_t descTensorV, const cutensornetGateSplitAlgo_t gateAlgo, const cutensornetTensorSVDConfig_t svdConfig, cutensornetComputeType_t computeType, cutensornetWorkspaceDescriptor_t workDesc)¶
计算执行门操作所需的工作区大小。
- 参数
handle – [in] 保存 cuTensorNet 库上下文的不透明句柄。
descTensorInA – [in] 描述输入张量 A 的模式、维度和其他元数据信息。
descTensorInB – [in] 描述输入张量 B 的模式、维度和其他元数据信息。
descTensorInG – [in] 描述输入门张量的模式、维度和其他元数据信息。
descTensorU – [in] 描述输出张量 U 的模式、维度和其他元数据信息。未收缩模式的维度应与
descTensorInA和descTensorInG一致。descTensorV – [in] 描述输出张量 V 的模式、维度和其他元数据信息。未收缩模式的维度应与
descTensorInB和descTensorInG一致。gateAlgo – [in] 用于将门张量拆分到张量 A 和 B 上的算法。
svdConfig – [in] 保存用户请求的 SVD 参数的不透明结构。
computeType – [in] 表示整个计算中使用的计算类型。
workDesc – [out] 描述工作区的不透明结构。
cutensornetWorkspaceGetSize¶
-
cutensornetStatus_t cutensornetWorkspaceGetSize(const cutensornetHandle_t handle, const cutensornetWorkspaceDescriptor_t workDesc, cutensornetWorksizePref_t workPref, cutensornetMemspace_t memSpace, uint64_t *workspaceSize)¶
已弃用:检索给定工作区偏好和内存空间所需的工作区大小。
不同任务所需的大小必须通过调用相应的 API 预先计算,例如 cutensornetWorkspaceComputeContractionSizes()、cutensornetWorkspaceComputeQRSizes()、cutensornetWorkspaceComputeSVDSizes() 和 cutensornetWorkspaceComputeGateSplitSizes()。
- 参数
handle – [in] 保存 cuTensorNet 库上下文的不透明句柄。
workDesc – [in] 描述工作区的不透明结构。
workPref – [in] 规划工作区的偏好。
memSpace – [in] 分配工作区的内存空间。
workspaceSize – [out] 所需的工作区大小。
cutensornetWorkspaceGetMemorySize¶
-
cutensornetStatus_t cutensornetWorkspaceGetMemorySize(const cutensornetHandle_t handle, const cutensornetWorkspaceDescriptor_t workDesc, cutensornetWorksizePref_t workPref, cutensornetMemspace_t memSpace, cutensornetWorkspaceKind_t workKind, int64_t *memorySize)¶
检索给定工作区偏好、内存空间、工作区类型所需的工作区大小。
不同任务所需的大小必须通过调用相应的 API 预先计算,例如 cutensornetWorkspaceComputeContractionSizes()、cutensornetWorkspaceComputeQRSizes()、cutensornetWorkspaceComputeSVDSizes() 和 cutensornetWorkspaceComputeGateSplitSizes()。
- 参数
handle – [in] 保存 cuTensorNet 库上下文的不透明句柄。
workDesc – [in] 描述工作区的不透明结构。
workPref – [in] 规划工作区的偏好。
memSpace – [in] 分配工作区的内存空间。
workKind – [in] 工作区的类型。
memorySize – [out] 所需的工作区大小。
cutensornetWorkspaceSet¶
-
cutensornetStatus_t cutensornetWorkspaceSet(const cutensornetHandle_t handle, cutensornetWorkspaceDescriptor_t workDesc, cutensornetMemspace_t memSpace, void *const workspacePtr, uint64_t workspaceSize)¶
已弃用:设置用户提供的工作区的内存地址和工作区大小。
在以下情况下,工作区有效
workspacePtr有效且workspaceSize> 0workspacePtr为空且workspaceSize> 0(在 cutensornetCreateContractionPlan() 期间使用,以提供可用的工作区)。workspacePtr为空且workspaceSize= 0(工作区内存将从用户的内存池中提取)
工作区将在使用时(cutensornetCreateContractionPlan()、cutensornetContractionAutotune()、cutensornetContraction())根据最小需求进行验证
- 参数
handle – [in] 保存 cuTensorNet 库上下文的不透明句柄。
workDesc – [inout] 描述工作区的不透明结构。
memSpace – [in] 分配工作区的内存空间。
workspacePtr – [in] 工作区内存指针,可以为空。
workspaceSize – [in] 工作区大小,必须 >= 0。
cutensornetWorkspaceSetMemory¶
-
cutensornetStatus_t cutensornetWorkspaceSetMemory(const cutensornetHandle_t handle, cutensornetWorkspaceDescriptor_t workDesc, cutensornetMemspace_t memSpace, cutensornetWorkspaceKind_t workKind, void *const memoryPtr, int64_t memorySize)¶
设置用户提供的工作区内存地址和工作区大小。
在以下情况下,工作区有效
memoryPtr有效且memorySize> 0memoryPtr为空且memorySize> 0:用于指示应从内存池中提取具有指示的memorySize的内存,或用于 cutensornetCreateContractionPlan() 以指示可用的工作区大小。memoryPtr为空且memorySize= 0:指示已禁用指定类型的工作区(当前仅适用于 CACHE 类型)。memoryPtr为空且memorySize< 0:指示应从用户的内存池中提取工作区内存,大小为 CUTENSORNET_WORKSIZE_PREF_RECOMMENDED 大小(请参阅 cutensornetWorksizePref_t)。
SCRATCH 类型的
memorySize将在使用时(cutensornetCreateContractionPlan()、cutensornetContractionAutotune()、cutensornetContraction()、cutensornetContractSlices())根据最小需求进行验证。CACHE 内存大小可以是任意值,越大越好。- 参数
handle – [in] 保存 cuTensorNet 库上下文的不透明句柄。
workDesc – [inout] 描述工作区的不透明结构。
memSpace – [in] 分配工作区的内存空间。
workKind – [in] 工作区的类型。
memoryPtr – [in] 工作区内存指针,可以为空。
memorySize – [in] 工作区大小。
cutensornetWorkspaceGet¶
-
cutensornetStatus_t cutensornetWorkspaceGet(const cutensornetHandle_t handle, const cutensornetWorkspaceDescriptor_t workDesc, cutensornetMemspace_t memSpace, void **workspacePtr, uint64_t *workspaceSize)¶
已弃用:检索工作区描述符中托管的工作区的内存地址和工作区大小。
- 参数
handle – [in] 保存 cuTensorNet 库上下文的不透明句柄。
workDesc – [in] 描述工作区的不透明结构。
memSpace – [in] 分配工作区的内存空间。
workspacePtr – [out] 工作区内存指针。
workspaceSize – [out] 工作区大小。
cutensornetWorkspaceGetMemory¶
-
cutensornetStatus_t cutensornetWorkspaceGetMemory(const cutensornetHandle_t handle, const cutensornetWorkspaceDescriptor_t workDesc, cutensornetMemspace_t memSpace, cutensornetWorkspaceKind_t workKind, void **memoryPtr, int64_t *memorySize)¶
检索工作区描述符中托管的工作区的内存地址和工作区大小。
- 参数
handle – [in] 保存 cuTensorNet 库上下文的不透明句柄。
workDesc – [in] 描述工作区的不透明结构。
memSpace – [in] 分配工作区的内存空间。
workKind – [in] 工作区的类型。
memoryPtr – [out] 工作区内存指针。
memorySize – [out] 工作区大小。
cutensornetWorkspacePurgeCache¶
-
cutensornetStatus_t cutensornetWorkspacePurgeCache(const cutensornetHandle_t handle, cutensornetWorkspaceDescriptor_t workDesc, cutensornetMemspace_t memSpace)¶
清除指定内存空间中的缓存数据。
清除/使 CUTENSORNET_WORKSPACE_CACHE 工作区类型在
memSpace内存空间中的缓存数据失效,但不释放内存,也不将其返回到内存池。- 参数
handle – [in] 保存 cuTensorNet 库上下文的不透明句柄。
workDesc – [inout] 描述工作区的不透明结构。
memSpace – [in] 分配工作区的内存空间。
cutensornetDestroyWorkspaceDescriptor¶
-
cutensornetStatus_t cutensornetDestroyWorkspaceDescriptor(cutensornetWorkspaceDescriptor_t desc)¶
释放工作区描述符。
请注意,此 API 不会释放由 cutensornetWorkspaceSetMemory() 提供的内存。
- 参数
desc – [inout] 不透明结构。
网络张量缩并 API¶
cutensornetContraction¶
-
cutensornetStatus_t cutensornetContraction(const cutensornetHandle_t handle, cutensornetContractionPlan_t plan, const void *const rawDataIn[], void *rawDataOut, cutensornetWorkspaceDescriptor_t workDesc, int64_t sliceId, cudaStream_t stream)¶
已弃用:执行张量网络的实际缩并。
注意
如果创建了多个切片,则使用 cutensornetContraction() 缩并切片的顺序应为升序,从切片 0 开始。如果手动并行化切片(以任何方式:流、设备、进程等),请确保输出张量(需要全局归约)已初始化为零。
注意
建议输入和输出数据指针为 256 字节对齐,以获得最佳性能。
注意
此函数相对于调用 CPU 线程是异步的。用户应保证在与流或设备同步执行之前,
workDesc中提供的内存缓冲区有效。- 参数
handle – [in] 保存 cuTensorNet 库上下文的不透明句柄。
plan – [inout] 编码张量网络缩并的执行(参见 cutensornetCreateContractionPlan() 和 cutensornetContractionAutotune())。一些内部元数据可能会在缩并时更新。
rawDataIn – [in] N 个指针的数组 (N 是 cutensornetCreateNetworkDescriptor() 指定的输入张量的数量);
rawDataIn[i]指向与第 i 个输入张量关联的数据 (在设备内存中)。rawDataOut – [out] 指向输出张量的原始数据 (在设备内存中)。
workDesc – [in] 描述工作区的不透明结构。提供的工作区必须有效(工作区大小必须等于或大于最小需要大小以及计划创建时提供的值)。参见 cutensornetCreateContractionPlan(), CUTENSORNET_WORKSIZE_PREF_RECOMMENDED) 或有效大小。指定大小的工作区将从用户的内存池中提取,并在完成后释放回内存池。
sliceId – [in] 当前缩并的切片的 ID(此值范围在
0和optimizerInfo.numSlices之间);如果不使用切片,请使用0。stream – [in] 执行计算的 CUDA 流。
cutensornetContractSlices¶
-
cutensornetStatus_t cutensornetContractSlices(const cutensornetHandle_t handle, cutensornetContractionPlan_t plan, const void *const rawDataIn[], void *rawDataOut, int32_t accumulateOutput, cutensornetWorkspaceDescriptor_t workDesc, const cutensornetSliceGroup_t sliceGroup, cudaStream_t stream)¶
执行张量网络的实际缩并。
注意
建议输入和输出数据指针至少为 256 字节对齐,以获得最佳性能。
警告
在当前版本中,如果激活了分布式执行(通过 cutensornetDistributedResetConfiguration),此函数将同步流。
- 参数
handle – [in] 保存 cuTensorNet 库上下文的不透明句柄。
plan – [inout] 编码张量网络缩并的执行(参见 cutensornetCreateContractionPlan() 和 cutensornetContractionAutotune())。一些内部元数据可能会在缩并时更新。
rawDataIn – [in] N 个指针的数组(N 是 cutensornetCreateNetworkDescriptor() 中指定的输入张量数量):
rawDataIn[i]指向与第 i 个输入张量关联的数据(在设备内存中)。rawDataOut – [out] 指向输出张量的原始数据 (在设备内存中)。
accumulateOutput – [in] 如果为 0,则将缩并结果写入 rawDataOut;否则,将结果累加到 rawDataOut 中。
workDesc – [in] 描述工作区的不透明结构。提供的 CUTENSORNET_WORKSPACE_SCRATCH 工作区必须有效(工作区指针必须是设备可访问的,参见 cutensornetMemspace_t,并且工作区大小必须等于或大于最小需要大小以及计划创建时提供的值)。参见 cutensornetCreateContractionPlan(), cutensornetWorkspaceGetMemorySize() 和 cutensornetWorkspaceSetMemory()。提供的 CUTENSORNET_WORKSPACE_CACHE 工作区必须是设备可访问的,参见 cutensornetMemspace_t;它可以是任何大小,越大越好,直到可以使用 cutensornetWorkspaceGetMemorySize() 查询的大小。如果设置了设备内存处理程序,则可以将
workDesc设置为 null,或者可以将workDesc中的工作区指针设置为 null,并且可以将工作区大小设置为 0(在这种情况下,使用“推荐”大小,参见 CUTENSORNET_WORKSIZE_PREF_RECOMMENDED)或有效大小。对于 CUTENSORNET_WORKSPACE_SCRATCH 类型的工作区,具有指定大小的内存缓冲区将从用户的内存池中提取,并在完成后释放回内存池。对于 CUTENSORNET_WORKSPACE_CACHE 类型的工作区,具有指定大小的内存缓冲区将从用户的内存池中提取,并在workDesc被销毁后释放回内存池,如果workDesc!= NULL,否则,一旦plan被销毁,或者在后续的 cutensornetContractSlices() 调用中提供了具有不同内存地址/大小的替代workDesc。sliceGroup – [in] 指定要缩并的切片的不透明对象(参见 cutensornetCreateSliceGroupFromIDRange() 和 cutensornetCreateSliceGroupFromIDs())。如果设置为 null,则将缩并所有切片。
stream – [in] 执行计算的 CUDA 流。
梯度计算 API¶
cutensornetComputeGradientsBackward¶
-
cutensornetStatus_t cutensornetComputeGradientsBackward(const cutensornetHandle_t handle, cutensornetContractionPlan_t plan, const void *const rawDataIn[], const void *outputGradient, void *const gradients[], int32_t accumulateOutput, cutensornetWorkspaceDescriptor_t workDesc, cudaStream_t stream)¶
计算网络关于需要梯度的输入张量的梯度。网络必须已缩并并加载到
workDescCACHE 中。仅适用于具有单切片且没有单例模式的网络。注意
此功能是实验性的,将来版本可能会更改。
注意
此函数之前应调用 cutensornetContractSlices();cutensornetContractSlices() 和 cutensornetComputeGradientsBackward() 的调用应使用相同的
workDesc实例(为了共享 CACHE 内存),或者都将 null 传递给workDesc以使用相同的内存池分配用于 CACHE。workDesc和plan在这些调用之间不应更改。注意
调用 cutensornetWorkspacePurgeCache() 对于计算不同数据集的梯度是必要的(cutensornetContractSlices() 和 cutensornetComputeGradientsBackward() 组合调用会生成缓存数据,该数据仅对相应的数据集有效,并且在输入张量的数据更改时应清除)。
注意
建议输入数据、输出数据和工作区缓冲区的指针至少为 256 字节对齐,以获得最佳性能。
注意
当提供的 CUTENSORNET_WORKSPACE_CACHE 工作区在主机内存上分配时,此函数将优化通过提供的 SCRATCH 缓冲区与 CPU 内存之间的数据传输。因此,提供比最小要求更大的 SCRATCH 内存可以实现更好的性能。
- 参数
handle – [in] 保存 cuTensorNet 库上下文的不透明句柄。
plan – [inout] 编码张量网络缩并的执行(参见 cutensornetCreateContractionPlan() 和 cutensornetContractionAutotune())。一些内部元数据可能会在缩并时更新。
rawDataIn – [in] N 个指针的数组(N 是 cutensornetCreateNetworkDescriptor() 中指定的输入张量数量):
rawDataIn[i]指向与第 i 个输入张量关联的数据(在设备内存中)。outputGradient – [in] 输出张量的梯度(在设备内存中)。必须具有与张量网络的输出张量相同的内存布局(步幅)。
gradients – [inout] N 个指针的数组:
gradients[i]指向与设备内存中第 i 个输入张量关联的梯度数据。将gradients[i]设置为 null 将跳过计算第 i 个输入张量的梯度。生成的梯度数据具有与其对应的输入张量相同的内存布局(步幅)。accumulateOutput – [in] 如果为 0,则将梯度结果写入
gradients;否则,将结果累加到gradients中。workDesc – [in] 描述工作区的不透明结构。提供的 CUTENSORNET_WORKSPACE_SCRATCH 工作区必须有效(工作区指针必须是设备可访问的,参见 cutensornetMemspace_t,并且工作区大小必须等于或大于最小需要大小)。参见 cutensornetWorkspaceComputeContractionSizes(), cutensornetWorkspaceGetMemorySize() 和 cutensornetWorkspaceSetMemory()。提供的 CUTENSORNET_WORKSPACE_CACHE 工作区必须有效(工作区指针必须是设备可访问的,参见 cutensornetMemspace_t),并且包含来自相应 cutensornetContractSlices() 调用的缓存中间张量。如果设置了设备内存处理程序,并且
workDesc设置为 null,或者workDesc中任一工作区类型的内存指针设置为 null,则对于 cutensornetContractSlices() 和 cutensornetComputeGradientsBackward() 的两个调用,将从内存池中提取内存。有关详细信息,请参见 cutensornetContractSlices()。stream – [in] 执行计算的 CUDA 流。
切片组 API¶
cutensornetCreateSliceGroupFromIDRange¶
-
cutensornetStatus_t cutensornetCreateSliceGroupFromIDRange(const cutensornetHandle_t handle, int64_t sliceIdStart, int64_t sliceIdStop, int64_t sliceIdStep, cutensornetSliceGroup_t *sliceGroup)¶
从范围创建一个
cutensornetSliceGroup_t对象,它生成一个切片 ID 序列,从指定的起始值(包括)到指定的停止值(不包括),并具有指定的步长。序列可以是递增或递减,具体取决于起始值和停止值。- 参数
handle – [in] 保存 cuTensorNet 库上下文的不透明句柄。
sliceIdStart – [in] 起始切片 ID。
sliceIdStop – [in] 最终切片 ID 是最大(最小)整数,对于递增(递减)序列,它排除此值以及所有高于(低于)它的值。
sliceIdStep – [in] 两个连续切片 ID 之间的步长。对于递减序列,应指定负步长。
sliceGroup – [out] 指定切片 ID 的不透明对象。
cutensornetCreateSliceGroupFromIDs¶
-
cutensornetStatus_t cutensornetCreateSliceGroupFromIDs(const cutensornetHandle_t handle, const int64_t *beginIDSequence, const int64_t *endIDSequence, cutensornetSliceGroup_t *sliceGroup)¶
从切片 ID 序列创建一个
cutensornetSliceGroup_t对象。将删除输入切片 ID 序列中的重复项。- 参数
handle – [in] 保存 cuTensorNet 库上下文的不透明句柄。
beginIDSequence – [in] 指向切片 ID 序列开始位置的指针。
endIDSequence – [in] 指向切片 ID 序列结束位置的指针。
sliceGroup – [out] 指定切片 ID 的不透明对象。
cutensornetDestroySliceGroup¶
-
cutensornetStatus_t cutensornetDestroySliceGroup(cutensornetSliceGroup_t sliceGroup)¶
释放与
cutensornetSliceGroup_t对象关联的资源,并将其值设置为 null。- 参数
sliceGroup – [inout] 指定要缩并的切片的不透明对象(参见 cutensornetCreateSliceGroupFromIDRange() 和 cutensornetCreateSliceGroupFromIDs())。
近似张量网络执行 API¶
cutensornetTensorQR¶
-
cutensornetStatus_t cutensornetTensorQR(const cutensornetHandle_t handle, const cutensornetTensorDescriptor_t descTensorIn, const void *const rawDataIn, const cutensornetTensorDescriptor_t descTensorQ, void *q, const cutensornetTensorDescriptor_t descTensorR, void *r, const cutensornetWorkspaceDescriptor_t workDesc, cudaStream_t stream)¶
执行张量的 QR 分解。
所有输入模式在
descTensorIn中的划分在descTensorQ和descTensorR中指定。descTensorQ和descTensorR预计共享恰好一个模式,并且该模式的维度不应超过等效组合矩阵 QR 的 m(行维度)和 n(列维度)的最小值。- 参数
handle – [in] 保存 cuTensorNet 库上下文的不透明句柄。
descTensorIn – [in] 描述张量的模式、维度和其他元数据信息。
rawDataIn – [in] 指向输入张量的原始数据的指针(在设备内存中)。
descTensorQ – [in] 描述输出张量 Q 的模式、维度和其他元数据信息。
q – [out] 指向输出张量数据 Q 的指针(在设备内存中)。
descTensorR – [in] 描述输出张量 R 的模式、维度和其他元数据信息。
r – [out] 指向输出张量数据 R 的指针(在设备内存中)。
workDesc – [in] 描述工作空间的不透明结构。提供的工作空间必须是有效的(工作空间大小必须等于或大于最小需求)。请参阅 cutensornetWorkspaceGetMemorySize() 和 cutensornetWorkspaceSetMemory()。
stream – [in] 执行计算的 CUDA 流。
cutensornetTensorSVD¶
-
cutensornetStatus_t cutensornetTensorSVD(const cutensornetHandle_t handle, const cutensornetTensorDescriptor_t descTensorIn, const void *const rawDataIn, cutensornetTensorDescriptor_t descTensorU, void *u, void *s, cutensornetTensorDescriptor_t descTensorV, void *v, const cutensornetTensorSVDConfig_t svdConfig, cutensornetTensorSVDInfo_t svdInfo, const cutensornetWorkspaceDescriptor_t workDesc, cudaStream_t stream)¶
执行张量的 SVD 分解。
所有输入模式在
descTensorIn中的划分在descTensorU和descTensorV中指定。descTensorU和descTensorV预计共享恰好一个模式。共享模式的维度不应超过等效组合矩阵 SVD 的 m(行维度)和 n(列维度)的最小值。支持以下张量 SVD 变体1. 精确 SVD:可以通过将
descTensorU和descTensorV中共享模式的维度设置为 m 和 n 的最小值,并将svdConfig设置为NULL来指定。2. 具有固定维度截断的 SVD:可以通过将
descTensorU和descTensorV中共享模式的维度设置为低于 m 和 n 的最小值来指定。3. 具有基于值的截断的 SVD:可以通过设置
svdConfig的 CUTENSORNET_TENSOR_SVD_CONFIG_ABS_CUTOFF 或 CUTENSORNET_TENSOR_SVD_CONFIG_REL_CUTOFF 属性来指定。4. 具有上述固定维度和基于值的截断组合的 SVD。
注意
在精确 SVD 或具有固定维度截断的 SVD 的情况下,
descTensorU和descTensorV在执行后将保持不变。u和v中的数据将遵循这些张量描述符中的extent和stride。注意
当在
svdConfig中请求基于值的截断时,cutensornetTensorSVD搜索满足基于值的截断和固定维度要求的最小维度。如果发现结果维度与 U/V 张量描述符中指定的维度相同,则将遵循张量描述符中的extent和stride。如果发现结果维度低于 U/V 张量描述符中指定的维度,则u和v中的数据将采用与找到的缩小维度匹配的新 Fortran 布局。descTensorU和descTensorV中的extent和stride也将被覆盖以反映此更改。用户可以使用 cutensornetTensorSVDInfoGetAttribute() 或 cutensornetGetTensorDetails()(它也返回新的步长)查询缩小的维度。注意
由于基于值的截断的缩小尺寸在运行时之前是未知的,因此用户应始终基于初始
descTensorU和descTensorV指定的完整数据大小为u和v分配内存。- 参数
handle – [in] 保存 cuTensorNet 库上下文的不透明句柄。
descTensorIn – [in] 描述张量的模式、维度和其他元数据信息。
rawDataIn – [in] 指向输入张量的原始数据的指针(在设备内存中)。
descTensorU – [inout] 描述输出张量 U 的模式、维度和其他元数据信息。未收缩模式的维度应与
descTensorIn一致。u – [out] 指向输出张量数据 U 的指针(在设备内存中)。
s – [out] 指向输出张量数据 S 的指针(在设备内存中)。当
svdConfig的 CUTENSORNET_TENSOR_SVD_CONFIG_S_PARTITION 属性未设置为默认值(CUTENSORNET_TENSOR_SVD_PARTITION_NONE)时,可以为NULL。descTensorV – [inout] 描述输出张量 V 的模式、维度和其他元数据信息。
v – [out] 指向输出张量数据 V 的指针(在设备内存中)。
svdConfig – [in] 此数据结构保存用户请求的 SVD 参数。如果用户不需要执行基于值的截断或奇异值划分,则可以为
NULL。svdInfo – [out] 不透明结构,保存有关运行时截断的所有信息。如果不需要关于奇异值截断的运行时信息,则可以为
NULL。workDesc – [in] 描述工作空间的不透明结构。提供的工作空间必须是有效的(工作空间大小必须等于或大于最小需求)。请参阅 cutensornetWorkspaceGetMemorySize() 和 cutensornetWorkspaceSetMemory()。
stream – [in] 执行计算的 CUDA 流。
cutensornetGateSplit¶
-
cutensornetStatus_t cutensornetGateSplit(const cutensornetHandle_t handle, const cutensornetTensorDescriptor_t descTensorInA, const void *rawDataInA, const cutensornetTensorDescriptor_t descTensorInB, const void *rawDataInB, const cutensornetTensorDescriptor_t descTensorInG, const void *rawDataInG, cutensornetTensorDescriptor_t descTensorU, void *u, void *s, cutensornetTensorDescriptor_t descTensorV, void ">*v, const cutensornetGateSplitAlgo_t gateAlgo, const cutensornetTensorSVDConfig_t svdConfig, cutensornetComputeType_t computeType, cutensornetTensorSVDInfo_t svdInfo, const cutensornetWorkspaceDescriptor_t workDesc, cudaStream_t stream)¶
执行门分裂操作。
descTensorInA、descTensorInB和descTensorInG预计形成一个完全连接的图,其中未收缩的模式通过张量 SVD 划分到descTensorU和descTensorV上。descTensorU和descTensorV预计共享恰好一个模式。该模式的维度不应超过最小等效矩阵 SVD 问题的 m(行维度)和 n(列维度)的最小值。注意
截断选项以及
extent和stride的处理遵循与张量 SVD 相同的逻辑,请参阅 cutensornetTensorSVD()。- 参数
handle – [in] 保存 cuTensorNet 库上下文的不透明句柄。
descTensorInA – [in] 描述输入张量 A 的模式、维度和其他元数据信息。
rawDataInA – [in] 指向输入张量 A 的原始数据的指针(在设备内存中)。
descTensorInB – [in] 描述输入张量 B 的模式、维度和其他元数据信息。
rawDataInB – [in] 指向输入张量 B 的原始数据的指针(在设备内存中)。
descTensorInG – [in] 描述输入门张量的模式、维度和其他元数据信息。
rawDataInG – [in] 指向输入门张量 G 的原始数据的指针(在设备内存中)。
descTensorU – [in] 描述输出张量 U 的模式、维度和其他元数据信息。未收缩模式的维度应与
descTensorInA和descTensorInG一致。u – [out] 指向输出张量数据 U 的指针(在设备内存中)。
s – [out] 指向输出张量数据 S 的指针(在设备内存中)。当
svdConfig的 CUTENSORNET_TENSOR_SVD_CONFIG_S_PARTITION 属性未设置为默认值(CUTENSORNET_TENSOR_SVD_PARTITION_NONE)时,可以为NULL。descTensorV – [in] 描述输出张量 V 的模式、维度和其他元数据信息。未收缩模式的维度应与
descTensorInB和descTensorInG一致。v – [out] 指向输出张量数据 V 的指针(在设备内存中)。
gateAlgo – [in] 用于将门张量拆分为张量 A 和 B 的算法。
svdConfig – [in] 保存用户请求的 SVD 参数的不透明结构。
computeType – [in] 表示整个计算中使用的计算类型。
svdInfo – [out] 不透明结构,保存有关运行时截断的所有信息。
workDesc – [in] 描述工作区的不透明结构。
stream – [in] 执行计算的 CUDA 流。
张量 SVD 配置 API¶
cutensornetCreateTensorSVDConfig¶
-
cutensornetStatus_t cutensornetCreateTensorSVDConfig(const cutensornetHandle_t handle, cutensornetTensorSVDConfig_t *svdConfig)¶
设置奇异值分解和截断的选项。
请注意,此函数在堆上分配数据;因此,一旦不再需要
svdConfig,调用 cutensornetDestroyTensorSVDConfig() 至关重要。- 参数
handle – [in] 保存 cuTensorNet 库上下文的不透明句柄。
svdConfig – [out] 此数据结构保存用户请求的 svd 参数。
cutensornetDestroyTensorSVDConfig¶
-
cutensornetStatus_t cutensornetDestroyTensorSVDConfig(cutensornetTensorSVDConfig_t svdConfig)¶
释放与张量 svd 配置关联的所有内存。
- 参数
svdConfig – [inout] 指向张量 svd 配置的不透明句柄。
cutensornetTensorSVDConfigGetAttribute¶
-
cutensornetStatus_t cutensornetTensorSVDConfigGetAttribute(const cutensornetHandle_t handle, const cutensornetTensorSVDConfig_t svdConfig, cutensornetTensorSVDConfigAttributes_t attr, void *buf, size_t sizeInBytes)¶
获取
svdConfig的属性。- 参数
handle – [in] 保存 cuTensorNet 库上下文的不透明句柄。
svdConfig – [in] 要访问的不透明结构。
attr – [in] 指定请求的属性。
buf – [out] 返回时,此缓冲区(大小为
sizeInBytes)保存与svdConfig中的attr对应的值。sizeInBytes – [in]
buf的大小(以字节为单位)。
cutensornetTensorSVDConfigSetAttribute¶
-
cutensornetStatus_t cutensornetTensorSVDConfigSetAttribute(const cutensornetHandle_t handle, cutensornetTensorSVDConfig_t svdConfig, cutensornetTensorSVDConfigAttributes_t attr, const void *buf, size_t sizeInBytes)¶
设置
svdConfig的属性。- 参数
handle – [in] 保存 cuTensorNet 库上下文的不透明句柄。
svdConfig – [in] 要访问的不透明结构。
attr – [in] 指定请求的属性。
buf – [in] 此缓冲区(大小为
sizeInBytes)确定attr将被设置的值。sizeInBytes – [in]
buf的大小(以字节为单位)。
张量 SVD 信息 API¶
cutensornetCreateTensorSVDInfo¶
-
cutensornetStatus_t cutensornetCreateTensorSVDInfo(const cutensornetHandle_t handle, cutensornetTensorSVDInfo_t *svdInfo)¶
设置奇异值分解的信息。
请注意,此函数在堆上分配数据;因此,一旦不再需要
svdInfo,调用 cutensornetDestroyTensorSVDInfo() 至关重要。- 参数
handle – [in] 保存 cuTensorNet 库上下文的不透明句柄。
svdInfo – [out] 此数据结构保存有关运行时截断的所有信息。
cutensornetDestroyTensorSVDInfo¶
-
cutensornetStatus_t cutensornetDestroyTensorSVDInfo(cutensornetTensorSVDInfo_t svdInfo)¶
释放与 TensorSVDInfo 对象关联的所有内存。
- 参数
svdInfo – [inout] 指向 TensorSVDInfo 对象的不透明句柄。
cutensornetTensorSVDInfoGetAttribute¶
-
cutensornetStatus_t cutensornetTensorSVDInfoGetAttribute(const cutensornetHandle_t handle, const cutensornetTensorSVDInfo_t svdInfo, cutensornetTensorSVDInfoAttributes_t attr, void *buf, size_t sizeInBytes)¶
获取
svdInfo的属性。- 参数
handle – [in] 保存 cuTensorNet 库上下文的不透明句柄。
svdInfo – [in] 要访问的不透明结构体。
attr – [in] 指定请求的属性。
buf – [out] 返回时,此缓冲区(大小为
sizeInBytes)保存与svdConfig中的attr对应的值。sizeInBytes – [in]
buf的大小(以字节为单位)。
分布式并行化 API¶
cutensornetDistributedResetConfiguration¶
-
cutensornetStatus_t cutensornetDistributedResetConfiguration(cutensornetHandle_t handle, const void *commPtr, size_t commSize)¶
重置分布式 MPI 并行化配置。
此函数接受用户提供的 MPI 通信器(类型擦除形式),并在 cuTensorNet 库句柄内部存储其副本。提供的 MPI 通信器必须通过调用 MPI_Comm_dup 显式创建(请参阅 MPI 规范)。后续对收缩路径查找器、收缩计划自动调优和收缩执行的调用将在提供的 MPI 通信器中的所有 MPI 进程中并行化。提供的 MPI 通信器归用户所有,它应保持有效,直到下次使用不同的 MPI 通信器进行重置调用。如果将 NULL 作为 MPI 通信器的指针提供,则不会对上述过程应用并行化,以便这些过程将在所有 MPI 进程中冗余执行。有关示例,请参阅 tensornet_example_mpi_auto.cu 示例。
要启用分布式并行性,cuTensorNet 要求用户设置一个环境变量
$CUTENSORNET_COMM_LIB,其中包含包装通信原语的共享库的路径。对于 MPI 用户,我们提供了一个包装器源文件cutensornet_distributed_interface_mpi.c,可以使用 tar 存档分发包中同一文件夹内提供的构建脚本,针对目标 MPI 库进行编译。cuTensorNet 将使用包含的函数指针,以使用选定的 MPI 库执行进程间通信。警告
这是一个集体调用,必须由所有 MPI 进程执行。请注意,仍然可以为不同的 MPI 进程子组提供不同的(非 NULL)MPI 通信器(以创建并发的 cuTensorNet 分布式子组)。
警告
提供的 MPI 通信器不得被多个 cuTensorNet 库句柄使用。通过使用 MPI_Comm_dup 可以自动确保这一点。
警告
当前库实现假定每个 MPI 秩一个 GPU 实例,因为 cutensornet 库句柄与单个 GPU 实例关联。如果每个节点有多个 GPU,则如果未设置 CUDA_VISIBLE_DEVICES 以提供对每个 GPU 的独占访问,则在同一节点上运行的每个 MPI 进程仍可能看到所有 GPU 设备。在这种情况下,cutensornet 库运行时将分配 GPU #(processRank % numVisibleDevices),其中 processRank 是当前进程在其 MPI 通信器中的秩,numVisibleDevices 是当前 MPI 进程可见的 GPU 设备数量。分配的 GPU 必须与与 cutensornet 库句柄关联的 GPU 一致,否则会导致错误。为确保一致性,用户必须在每个 MPI 进程中调用 cudaSetDevice 以在创建 cutensornet 库句柄之前选择正确的 GPU 设备。
警告
用户有责任确保每个提供的 MPI 通信器中的每个 MPI 进程都执行完全相同的 cutensornet API 调用序列,否则将导致未定义的行为。
- 参数
handle – [in] cuTensorNet 库句柄。
commPtr – [in] 指向由 MPI_Comm_dup 创建的提供的 MPI 通信器的指针。
commSize – [in] 提供的 MPI 通信器的大小:sizeof(MPI_Comm)。
cutensornetDistributedGetNumRanks¶
-
cutensornetStatus_t cutensornetDistributedGetNumRanks(const cutensornetHandle_t handle, int32_t *numRanks)¶
查询当前分布式 MPI 配置中的 MPI 秩数。
警告
秩数对应于当前 MPI 进程使用的 MPI 通信器。如果不同的 MPI 进程子组使用不同的 MPI 通信器,则报告的数字将指它们特定的 MPI 通信器。
- 参数
handle – [in] cuTensorNet 库句柄。
numRanks – [out] 当前分布式 MPI 配置中的 MPI 秩数。
cutensornetDistributedGetProcRank¶
-
cutensornetStatus_t cutensornetDistributedGetProcRank(const cutensornetHandle_t handle, int32_t *procRank)¶
查询当前 MPI 进程在当前分布式 MPI 配置中的秩。
警告
MPI 进程秩对应于该 MPI 进程使用的 MPI 通信器。如果不同的 MPI 进程子组使用不同的 MPI 通信器,则报告的数字将指它们特定的 MPI 通信器。
- 参数
handle – [in] cuTensorNet 库句柄。
procRank – [out] 当前 MPI 进程在当前分布式 MPI 配置中的秩。
cutensornetDistributedSynchronize¶
-
cutensornetStatus_t cutensornetDistributedSynchronize(const cutensornetHandle_t handle)¶
全局同步当前分布式 MPI 配置中的所有 MPI 进程,确保所有先前的 cutensornet API 调用已在所有 MPI 进程中完成。
警告
这是一个集体调用,必须由所有 MPI 进程执行。
警告
在执行全局同步之前,用户仍然需要本地同步 GPU 操作(通过 CUDA 流同步)。
- 参数
handle – [in] cuTensorNet 库句柄。
高级张量网络 API¶
围绕 cutensornetState_t 的高级张量网络 API 函数允许用户通过逐步将张量算子(例如,量子门)应用于用户定义的直积空间中的初始(真空)状态来定义复杂的张量网络状态,即,构造为给定维度的多个向量空间的直积的张量空间。 特别是,这种定义张量网络状态的方式对于量子电路模拟器非常方便,因为给定量子电路的最终输出状态是通过逐步将量子门应用于所有量子比特(或量子位)的初始(真空)状态来构建的。 一旦指定了所有张量算子的作用,就完全定义了底层的张量网络,以及最终张量网络状态,它与初始(真空)状态位于相同的直积空间中。 用户还可以选择以下选项,以在计算其各种属性之前,请求应用于最终状态的某些近似或操作。
无其他近似或操作。无需其他 API 调用,用户可以直接继续执行下一步以进行属性计算。所有属性都将通过直接收缩与感兴趣的属性相对应的完整张量网络来计算。
显式预先计算完整状态张量。这可以通过调用
cutensornetStateConfigure()、cutensornetStatePrepare()和cutensornetStateCompute()的一系列调用来实现,以配置、准备和最终计算完整状态张量。所有后续属性的计算都可以利用计算出的完整状态张量(不保证会这样做)。以矩阵乘积态 (MPS) 形式提供初始量子态,使其成为非真空态。这可以通过调用
cutensornetStateInitializeMPS()API 在后续调用配置、准备和计算 API 函数之前提供初始状态。请注意,此 API 未指定最终状态将以 MPS 形式计算(见下文),因此可以与基于收缩的计算或基于 MPS 的表示结合使用。将最终状态分解为 MPS 形式。
cutensornetStateFinalizeMPS()API 函数可用于为定义的张量网络状态指定 MPS 分解结构。一旦指定了所需的 MPS 分解,后续对配置、准备和计算 API 函数的调用将配置 MPS 计算、准备 MPS 计算,并最终计算 MPS 分解。所有后续属性都将通过使用原始张量网络状态的 MPS 分解形式来计算。
在选择上述方法之一后,用户可以利用以下 API 来计算与张量网络状态相关的各种属性。
cutensornetStateAccessor_t和相应的 API 可用于计算完整状态张量、其任何笛卡尔切片或单个幅度。
cutensornetStateExpectation_t和相应的 API 可用于计算给定张量网络算子相对于给定张量网络状态的期望值。张量网络算子 (cutensornetNetworkOperator_t) 定义为张量算子的乘积之和,其中构成每个乘积(分量)的张量作用于不相交的自由度(例如,量子位的非相交子集)。
cutensornetStateMarginal_t和相应的 API 可用于计算张量网络状态指定模式上的边际概率分布张量(约化密度矩阵)。特别是,包括所有张量网络状态模式将导致计算张量网络状态的完整密度矩阵。
cutensornetStateSampler_t和相应的 API 可用于从与指定张量网络状态模式关联的概率分布中进行采样。
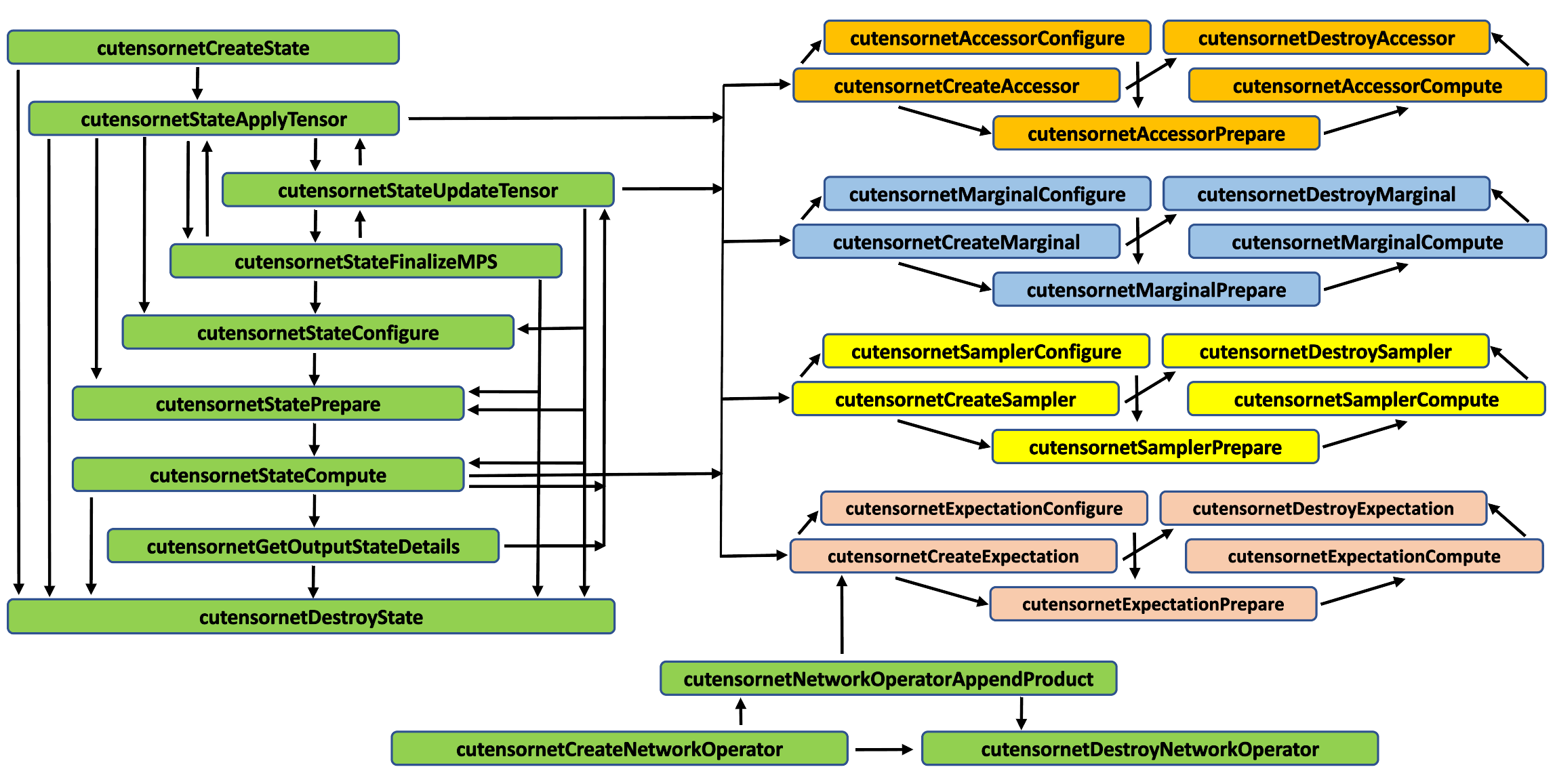
图 1. cuTensorNet 高级 API 工作流程逻辑。箭头指示允许的 API 调用序列。¶
对于可能要计算的张量网络状态的每个此类属性,高级 API 的相应子集包括用于定义(创建)提供功能的对象(Create)的 API 函数(如上面命名的那些),通过设置特定属性(Configure)来配置它,为计算(Prepare)准备它,最后计算它(Compute),当然,最后销毁它(Destroy)。有关 API 工作流程逻辑,请参见 图 1,其中箭头指示允许的 API 调用序列。
注意
当要为张量网络状态的 MPS 分解形式计算属性时,用户负责显式分配 MPS 状态张量的内存,并在 cutensornetState_t 对象的生命周期内维护它。有关基于 MPS 的属性计算的更详细说明,请参阅关于 幅度、期望值、边际分布 和 采样 的这些部分。
cutensornetCreateState¶
-
cutensornetStatus_t cutensornetCreateState(const cutensornetHandle_t handle, cutensornetStatePurity_t purity, int32_t numStateModes, const int64_t *stateModeExtents, cudaDataType_t dataType, cutensornetState_t *tensorNetworkState)¶
创建一个空的张量网络状态,其形状由主张量模式的数量及其范围定义。
张量网络状态是表示某个(尚未指定的)张量网络的完全收缩结果的张量。也就是说,张量网络状态只是一个张量,它存在于给定的主张量空间中,该空间构造为给定数量的向量空间的直积,这些向量空间由其维度指定(每个向量空间代表一个状态模式)。张量网络状态(状态张量)可以是纯态或混合态。纯态张量驻留在定义的主直积空间中,并由该空间中的张量表示。混合张量网络状态(状态张量)驻留在由定义的主直积空间与其对偶(共轭)张量空间张量积形成的直积空间中。混合状态张量是一个具有两倍模式的张量,即来自定义的主直积空间的模式,然后是来自其对偶(共轭)空间的相同数量的模式。随后,可以通过经由 cutensornetStateApplyTensorOperator() 应用用户定义的张量算子(例如,量子门),将初始(空)真空张量状态演化为最终目标张量状态。默认情况下,最终目标张量状态在形式上由单个输出张量表示,即完整张量网络收缩的结果(不必显式计算)。但是,用户可以选择通过 cutensornetStateFinalizeXXX() 调用对最终张量状态施加特定的张量分解,其中支持的张量分解 (XXX) 是:MPS(矩阵乘积态)。在这种情况下,现在必须显式计算的最终张量状态将由根据所选分解方案的输出张量元组表示。有关输出张量的信息可以通过调用 cutensornetGetOutputStateDetails() 查询。
注意
为了给出一个具体的例子,任何具有 4 个量子位的量子电路的纯态张量都具有形状 [2,2,2,2](量子电路是张量网络的一种特定类型)。在这种情况下,混合状态张量将具有形状 [2,2,2,2, 2,2,2,2],对应于 4 量子位寄存器的密度矩阵,尽管在这种情况下,与 4 量子位的主直积空间(4 个维度为 2 的向量空间的直积)关联的定义模式仍然只有 4 个。也就是说,混合状态张量包含两组模式,一组来自主直积空间,另一组来自其对偶空间,但它仍然由主直积空间的模式定义,具体而言,由构成向量空间的维度元组定义(在量子位的情况下为 2 维向量空间)。为了清楚起见,我们将主直积张量空间的模式称为状态模式。现在可以通过调用 cutensornetStateAppyTensor() 方便地指定量子门对张量网络状态的后续操作,通过量子门作用的状态模式的子集来指定。
警告
当前的 cuTensorNet 库版本仅支持纯张量网络状态,并将 MPS 分解作为预览功能提供。
- 参数
handle – [in] cuTensorNet 库句柄。
purity – [in] 张量网络状态的期望纯度(纯态或混合态)。
numStateModes – [in] 定义状态模式的数量,与状态纯度无关。请注意,纯态和混合态张量网络状态都仅由主直积空间的模式定义。
stateModeExtents – [in] 指向定义状态模式的范围(构成主直积空间的向量空间的维度)的指针。
dataType – [in] 状态张量的数据类型。
tensorNetworkState – [out] 张量网络状态(此时为空,也称为真空)。
cutensornetDestroyState¶
-
cutensornetStatus_t cutensornetDestroyState(cutensornetState_t tensorNetworkState)¶
释放张量网络状态拥有的所有资源。
注意
在张量网络状态被销毁后,所有指向用于指定最终目标状态的张量算子数据的指针都可能失效。
- 参数
tensorNetworkState – [in] 张量网络状态。
cutensornetStateApplyTensor¶
-
cutensornetStatus_t cutensornetStateApplyTensor(const cutensornetHandle_t handle, cutensornetState_t tensorNetworkState, int32_t numStateModes, const int32_t *stateModes, void *tensorData, const int64_t *tensorModeStrides, const int32_t immutable, const int32_t adjoint, const int32_t unitary, int64_t *tensorId)¶
已弃用:将张量算子应用于张量网络状态。
张量算子作用于张量状态模式的指定子集,其中作用于的状态模式的数量定义了其秩。张量算子由一个张量表示,该张量的模式数量是其作用于的状态模式数量的两倍,其中张量算子模式的前半部分与输入状态张量的状态模式收缩,而张量算子模式的后半部分形成输出状态张量模式。由于默认张量存储步幅遵循广义列优先布局,因此秩 2 张量算子 G 对秩 2 状态张量 Q0 的作用可以用符号表示为:Q1(i1,i0) = Q0(j1,j0) * G(j1,j0,i1,i0),这只是标准符号的相反形式:Q1(i0,i1) = G(i0,i1,j0,j1) * Q0(j0,j1),因为张量电路的图形表示传统上从左到右应用张量算子(门)。通过这种方式,当使用 C 语言数组初始化语法时,我们方便地确保了张量算子(门)的标准行优先初始化。在上面的示例中,张量算子(门)G 有四个模式,并作用于两个状态模式。
注意
为了定义量子电路,我们当前的约定方便地允许使用 C 数组初始化 2 量子位 CNOT 门(张量算子),其元素精确地遵循 CNOT 门的规范教科书(行优先)定义。
\[\begin{split} \begin{pmatrix} 1 & 0 & 0 & 0 \\ 0 & 1 & 0 & 0 \\ 0 & 0 & 0 & 1 \\ 0 & 0 & 1 & 0 \end{pmatrix} \end{split}\]注意
如果张量算子元素在仍驻留在同一存储位置时更改其值,则仍必须调用
cutensornetStateUpdateTensorOperator以使用相同的指针(存储位置)注册此类更改。警告
指向张量算子元素的指针归用户所有,并且必须在张量网络状态的整个生命周期内保持有效,除非通过
cutensornetStateUpdateTensorOperator显式地替换为另一个指针。- 参数
handle – [in] cuTensorNet 库句柄。
tensorNetworkState – [inout] 张量网络状态。
numStateModes – [in] 张量算子作用于的状态模式的数量。
stateModes – [in] 指向张量算子作用于的状态模式的指针。
tensorData – [in] 张量算子的元素(必须与状态张量的元素具有相同的数据类型)。
tensorModeStrides – [in] 张量算子数据布局的步幅(请注意,张量算子的模式数量是其作用于的状态模式数量的两倍)。传递 NULL 将假定默认的广义列优先布局。
immutable – [in] 张量算子数据在张量网络状态的生命周期内是否可能更改。任何数据更改都必须通过调用
cutensornetStateUpdateTensorOperator注册。adjoint – [in] 张量算子是否作为伴随算子应用(ket 和 bra 模式反转,所有张量元素进行复共轭)。
unitary – [in] 张量算子相对于其模式的前半部分和后半部分是否是酉算子。
tensorId – [out] 唯一的整数 ID(用于以后标识张量算子)。
cutensornetStateApplyTensorOperator¶
-
cutensornetStatus_t cutensornetStateApplyTensorOperator(const cutensornetHandle_t handle, cutensornetState_t tensorNetworkState, int32_t numStateModes, const int32_t *stateModes, void *tensorData, const int64_t *tensorModeStrides, const int32_t immutable, const int32_t adjoint, const int32_t unitary, int64_t *tensorId)¶
将张量算符应用于张量网络状态。
张量算子作用于张量状态模式的指定子集,其中作用于的状态模式的数量定义了其秩。张量算子由一个张量表示,该张量的模式数量是其作用于的状态模式数量的两倍,其中张量算子模式的前半部分与输入状态张量的状态模式收缩,而张量算子模式的后半部分形成输出状态张量模式。由于默认张量存储步幅遵循广义列优先布局,因此秩 2 张量算子 G 对秩 2 状态张量 Q0 的作用可以用符号表示为:Q1(i1,i0) = Q0(j1,j0) * G(j1,j0,i1,i0),这只是标准符号的相反形式:Q1(i0,i1) = G(i0,i1,j0,j1) * Q0(j0,j1),因为张量电路的图形表示传统上从左到右应用张量算子(门)。通过这种方式,当使用 C 语言数组初始化语法时,我们方便地确保了张量算子(门)的标准行优先初始化。在上面的示例中,张量算子(门)G 有四个模式,并作用于两个状态模式。
注意
为了定义量子电路,我们当前的约定方便地允许使用 C 数组初始化 2 量子位 CNOT 门(张量算子),其元素精确地遵循 CNOT 门的规范教科书(行优先)定义。
\[\begin{split} \begin{pmatrix} 1 & 0 & 0 & 0 \\ 0 & 1 & 0 & 0 \\ 0 & 0 & 0 & 1 \\ 0 & 0 & 1 & 0 \end{pmatrix} \end{split}\]注意
如果张量算子元素在仍驻留在同一存储位置时更改其值,则仍必须调用
cutensornetStateUpdateTensorOperator以使用相同的指针(存储位置)注册此类更改。警告
指向张量算子元素的指针归用户所有,并且必须在张量网络状态的整个生命周期内保持有效,除非通过
cutensornetStateUpdateTensorOperator显式地替换为另一个指针。- 参数
handle – [in] cuTensorNet 库句柄。
tensorNetworkState – [inout] 张量网络状态。
numStateModes – [in] 张量算子作用于的状态模式的数量。
stateModes – [in] 指向张量算子作用于的状态模式的指针。
tensorData – [in] 张量算子的元素(必须与状态张量的元素具有相同的数据类型)。
tensorModeStrides – [in] 张量算符数据布局的步长(请注意,张量算符的模式数量是其作用的状态模式数量的两倍)。 传递 NULL 将假定默认的广义列优先存储布局。
immutable – [in] 张量算子数据在张量网络状态的生命周期内是否可能更改。任何数据更改都必须通过调用
cutensornetStateUpdateTensorOperator注册。adjoint – [in] 张量算子是否作为伴随算子应用(ket 和 bra 模式反转,所有张量元素进行复共轭)。
unitary – [in] 张量算子相对于其模式的前半部分和后半部分是否是酉算子。
tensorId – [out] 唯一的整数 ID(用于以后标识张量算子)。
cutensornetStateApplyControlledTensorOperator¶
-
cutensornetStatus_t cutensornetStateApplyControlledTensorOperator(const cutensornetHandle_t handle, cutensornetState_t tensorNetworkState, int32_t numControlModes, const int32_t *stateControlModes, const int64_t *stateControlValues, int32_t numTargetModes, const int32_t *stateTargetModes, void *tensorData, const int64_t *tensorModeStrides, const int32_t immutable, const int32_t adjoint, const int32_t unitary, int64_t *tensorId)¶
将受控张量算符应用于张量网络状态。
此 API 函数执行与
cutensornetStateApplyTensorOperator相同的操作,不同之处在于,张量算符是通过控制-目标表示指定的,这对于多量子比特量子门是典型的。 也就是说,此处只需要提供完整受控张量算符的目标张量(提供的目标张量中的模式数量是其作用的目标状态模式数量的两倍)。 完整的张量算符表示将从目标张量和控制状态模式/值的列表自动生成。警告
目前,仅支持不可变的受控张量算符。 此限制将来可能会解除。
- 参数
handle – [in] cuTensorNet 库句柄。
tensorNetworkState – [inout] 张量网络状态。
numControlModes – 张量算符使用的控制状态模式的数量。
stateControlModes – 张量算符使用的控制状态模式。
stateControlValues – 控制状态模式的控制值。 控制值是 qudit 基分量的顺序整数 ID,它激活目标张量算符的动作。 如果为 NULL,则假定所有控制值都设置为最大 ID(最后一个 qudit 基分量),对于量子比特,这将为 1。
numTargetModes – 张量算符作用的目标状态模式的数量。
stateTargetModes – 张量算符作用的目标状态模式。
tensorData – [in] 受控张量算符的目标张量的元素(必须与状态张量的元素具有相同的数据类型)。
tensorModeStrides – [in] 张量算符数据布局的步长(请注意,张量算符的模式数量是其作用的目标状态模式数量的两倍)。 传递 NULL 将假定默认的广义列优先存储布局。
immutable – [in] 张量算子数据在张量网络状态的生命周期内是否可能更改。任何数据更改都必须通过调用
cutensornetStateUpdateTensorOperator注册。adjoint – [in] 张量算子是否作为伴随算子应用(ket 和 bra 模式反转,所有张量元素进行复共轭)。
unitary – [in] 受控张量算符相对于其模式的前半部分和后半部分是否是酉的。
tensorId – [out] 唯一的整数 ID(用于以后标识张量算子)。
cutensornetStateApplyUnitaryChannel¶
-
cutensornetStatus_t cutensornetStateApplyUnitaryChannel(const cutensornetHandle_t handle, cutensornetState_t tensorNetworkState, int32_t numStateModes, const int32_t *stateModes, int32_t numTensors, void *tensorData[], const int64_t *tensorModeStrides, const double probabilities[], int64_t *channelId)¶
将由一个或多个酉张量算符组成的张量通道应用于张量网络状态。
张量通道是由一个或多个张量算符表示的完全正保迹线性映射。 酉张量通道仅由酉张量算符组成。 所有构成的张量算符的模式数量通常是其作用的状态模式数量的两倍。
注意
所有构成的张量算符的存储布局必须相同,由单个
tensorModeStrides参数表示。- 参数
handle – [in] cuTensorNet 库句柄。
tensorNetworkState – [inout] 张量网络状态。
numStateModes – [in] 张量通道作用的状态模式的数量。
stateModes – [in] 指向张量通道作用的状态模式的指针。
numTensors – [in] 定义张量通道的构成张量算符的数量。
tensorData – [in] 构成张量通道的张量算符的元素(必须与状态张量的元素具有相同的数据类型)。
tensorModeStrides – [in] 张量数据存储布局的步长(请注意,提供的张量具有的模式数量是其作用的状态模式数量的两倍)。 传递 NULL 将假定默认的广义列优先存储布局。
probabilities – [in] 与各个张量算符关联的概率。
channelId – [out] 唯一整数 ID(用于以后标识张量通道)。
- 返回值
cutensornetStatus_t
cutensornetStateApplyNetworkOperator¶
-
cutensornetStatus_t cutensornetStateApplyNetworkOperator(const cutensornetHandle_t handle, cutensornetState_t tensorNetworkState, const cutensornetNetworkOperator_t tensorNetworkOperator, const int32_t immutable, const int32_t adjoint, const int32_t unitary, int64_t *operatorId)¶
将张量网络算符应用于张量网络状态。
注意
当前,应用的张量网络算符仅限于包含一个组件(张量积或 MPO)的算符。
注意
返回的唯一整数 ID (operatorId) 定义了与构成张量网络算符唯一组件的张量相关联的唯一整数 ID 的连续范围的开始:[operatorId..(operatorId + N - 1)],其中 N 是构成张量网络算符唯一组件的张量的数量。 然后,此连续范围内的张量 ID 可用于通过
cutensornetStateUpdateTensorOperator注册对相应张量的更新。警告
在当前版本中,仅支持不可变的张量网络算符。 此限制将来可能会解除。
- 参数
handle – [in] cuTensorNet 库句柄。
tensorNetworkState – [inout] 张量网络状态。
tensorNetworkOperator – [in] 仅包含单个组件的张量网络算符。
immutable – [in] 张量网络算符数据在张量网络状态的生命周期内是否可能更改。
adjoint – [in] 张量网络算符是否作为伴随算符应用。
unitary – [in] 张量网络算符相对于其模式的前半部分和后半部分是否是酉的。
operatorId – [out] 唯一整数 ID(用于以后标识张量网络算符)。
cutensornetStateUpdateTensor¶
-
cutensornetStatus_t cutensornetStateUpdateTensor(const cutensornetHandle_t handle, cutensornetState_t tensorNetworkState, int64_t tensorId, void *tensorData, int32_t unitary)¶
注册对先前应用于张量网络状态的指定张量算符的元素进行外部更新。
注意
提供的指向张量元素位置的指针可能与最初使用的指针一致,也可能不一致。 但是,最初提供的张量算符数据布局的步长被假定适用于更新后的张量算符数据位置,也就是说,在张量算符数据更新期间,不能更改存储步长。
警告
指向张量算子元素的指针归用户所有,并且必须在张量网络状态的整个生命周期内保持有效,除非通过
cutensornetStateUpdateTensorOperator显式地替换为另一个指针。警告
在当前版本中,无法更新受控张量算符。
- 参数
handle – [in] cuTensorNet 库句柄。
tensorNetworkState – [in] 张量网络状态。
tensorId – [in] 在
cutensornetStateApplyTensorOperator调用期间分配的张量 ID。tensorData – [in] 指向张量算符的更新元素的指针(张量算符元素必须与状态张量的类型相同)。
unitary – [in] 张量算符相对于其模式的前半部分和后半部分是否是酉的。 此参数不适用于作为矩阵乘积算符 (MPO) 一部分的张量。
cutensornetStateUpdateTensorOperator¶
-
cutensornetStatus_t cutensornetStateUpdateTensorOperator(const cutensornetHandle_t handle, cutensornetState_t tensorNetworkState, int64_t tensorId, void *tensorData, int32_t unitary)¶
注册对先前应用于张量网络状态的指定张量算符的元素进行外部更新。
注意
提供的指向张量元素位置的指针可能与最初使用的指针一致,也可能不一致。 但是,最初提供的张量算符数据布局的步长被假定适用于更新后的张量算符数据位置,也就是说,在张量算符数据更新期间,不能更改存储步长。
警告
指向张量算子元素的指针归用户所有,并且必须在张量网络状态的整个生命周期内保持有效,除非通过
cutensornetStateUpdateTensorOperator显式地替换为另一个指针。警告
在当前版本中,无法更新受控张量算符。
- 参数
handle – [in] cuTensorNet 库句柄。
tensorNetworkState – [in] 张量网络状态。
tensorId – [in] 在
cutensornetStateApplyTensorOperator调用期间分配的张量 ID。tensorData – [in] 指向张量算符的更新元素的指针(张量算符元素必须与状态张量的类型相同)。
unitary – [in] 张量算符相对于其模式的前半部分和后半部分是否是酉的。 此参数不适用于作为矩阵乘积算符 (MPO) 一部分的张量。
cutensornetStateConfigure¶
-
cutensornetStatus_t cutensornetStateConfigure(const cutensornetHandle_t handle, cutensornetState_t tensorNetworkState, cutensornetStateAttributes_t attribute, const void *attributeValue, size_t attributeSize)¶
配置完整张量网络状态的计算,可以是精确形式或分解形式。
- 参数
handle – [in] cuTensorNet 库句柄。
tensorNetworkState – [inout] 张量网络状态。
attribute – [in] 配置属性。
attributeValue – [in] 指向配置属性值的指针(类型擦除)。
attributeSize – [in] 配置属性值的大小。
cutensornetStatePrepare¶
-
cutensornetStatus_t cutensornetStatePrepare(const cutensornetHandle_t handle, cutensornetState_t tensorNetworkState, size_t maxWorkspaceSizeDevice, cutensornetWorkspaceDescriptor_t workDesc, cudaStream_t cudaStream)¶
准备完整张量网络状态的计算,可以是精确形式或分解形式。
警告
cudaStream 参数在当前版本中未使用(可以设置为 0x0)。
- 参数
handle – [in] cuTensorNet 库句柄。
tensorNetworkState – [in] 张量网络状态。
maxWorkspaceSizeDevice – [in] 可用 GPU 暂存内存量的上限(字节)。
workDesc – [out] 工作区描述符(将设置所需的暂存/缓存内存大小)。
cudaStream – [in] CUDA 流。
cutensornetStateGetInfo¶
-
cutensornetStatus_t cutensornetStateGetInfo(const cutensornetHandle_t handle, const cutensornetState_t tensorNetworkState, cutensornetStateAttributes_t attribute, void *attributeValue, size_t attributeSize)¶
检索与完整张量网络状态计算相关的属性,可以是精确形式或分解形式。
注意
Flop 计数 INFO 属性可能并非始终可用,在这种情况下,返回值将为零。
- 参数
handle – [in] cuTensorNet 库句柄。
tensorNetworkState – [in] 张量网络状态。
attribute – [in] 信息属性。
attributeValue – [out] 指向信息属性值的指针(类型擦除)。
attributeSize – [in] 信息属性值的大小。
cutensornetStateCompute¶
-
cutensornetStatus_t cutensornetStateCompute(const cutensornetHandle_t handle, cutensornetState_t tensorNetworkState, cutensornetWorkspaceDescriptor_t workDesc, int64_t *extentsOut[], int64_t *stridesOut[], void *stateTensorsOut[], cudaStream_t cudaStream)¶
执行完整张量网络状态的实际计算,可以是精确形式或分解形式。
注意
extentsOut、stridesOut和stateTensorsOut的长度应与最终目标状态 MPS 表示相对应。例如,如果最终目标状态被分解为具有开放边界条件的 MPS,则stateTensorsOut预计是numStateModes指针的数组,并且所有stateTensorsOut[i]的缓冲区大小预计与在调用 cutensornetStateFinalizeMPS() 之前指定的目标 extent 一致,然后再进行状态计算。如果张量网络状态没有被请求分解,则将返回在此 API 调用中计算的单个完整输出状态张量的形状和步长。警告
提供的 workspace descriptor
workDesc必须显式设置 Device Scratch 缓冲区,因为当前版本不支持用户提供的内存池。此外,在当前版本中,附加的 workspace 缓冲区必须是 256 字节对齐的。- 参数
handle – [in] cuTensorNet 库句柄。
tensorNetworkState – [in] 张量网络状态。
workDesc – [in] Workspace 描述符(所需 scratch/cache 内存缓冲区必须由用户设置)。
extentsOut – [out] 如果不为 NULL,将保存定义输出状态表示的所有张量的 extent。 可选地,如果不需要此数据,则可以为 NULL。
stridesOut – [out] 如果不为 NULL,将保存定义输出状态表示的所有张量的步长。 可选地,如果不需要此数据,则可以为 NULL。
stateTensorsOut – [inout] 指向 GPU 存储的指针数组,用于存储定义输出状态表示的所有张量。
cudaStream – [in] CUDA 流。
cutensornetGetOutputStateDetails¶
-
cutensornetStatus_t cutensornetGetOutputStateDetails(const cutensornetHandle_t handle, const cutensornetState_t tensorNetworkState, int32_t *numTensorsOut, int32_t numModesOut[], int64_t *extentsOut[], int64_t *stridesOut[])¶
查询每个最终输出状态张量的张量数量、模式数量、extent 和步长。
注意
如果用户需要关于输出张量的所有信息,则应调用此函数三次:第一次检索
numTensorsOut以分配numModesOut,第二次检索numModesOut以分配extentsOut和stridesOut,最后一次检索extentsOut和stridesOut。警告
要检索
numTensorsOut和numModesOut,不需要首先通过 cutensornetStateCompute() 调用来计算最终目标状态。但是,要获取extentsOut和stridesOut,可能需要首先调用 cutensornetStateCompute() 以计算输出状态分解,以防输出状态被迫分解(例如,MPS 分解)。- 参数
handle – [in] cuTensorNet 库句柄。
tensorNetworkState – [in] 张量网络状态。
numTensorsOut – [out] 返回时,将保存输出状态张量的数量(参数不能为空)。
numModesOut – [out] 如果不为 NULL,将保存每个输出状态张量的模式数量。 可选地,可以为 NULL。
extentsOut – [out] 如果不为 NULL,将保存每个输出状态张量的模式 extent。 可选地,可以为 NULL。
stridesOut – [out] 如果不为 NULL,将保存每个输出状态张量的步长。 可选地,可以为 NULL。
cutensornetStateInitializeMPS¶
-
cutensornetStatus_t cutensornetStateInitializeMPS(const cutensornetHandle_t handle, cutensornetState_t tensorNetworkState, cutensornetBoundaryCondition_t boundaryCondition, const int64_t *const extentsIn[], const int64_t *const stridesIn[], void *stateTensorsIn[])¶
对具有给定形状和数据的初始张量网络状态施加用户定义的 MPS(矩阵乘积态)分解。
注意
可以在张量网络状态的生命周期内的任何时间调用此 API 函数,以修改其初始状态。 如果未调用,则初始状态将保持在默认真空状态。
- 参数
handle – [in] cuTensorNet 库句柄。
tensorNetworkState – [inout] 张量网络状态。
boundaryCondition – [in] 所选 MPS 表示的边界条件。
extentsIn – [in] 大小为
nStateModes的数组,指定定义初始 MPS 表示的所有张量的 extent。extents[i]预计与模式顺序一致(第 (i-1) 个和第 i 个 MPS 张量之间的共享模式,第 i 个 MPS 张量的状态模式,第 i 个和第 (i+1) 个 MPS 张量之间的共享模式)。对于开放边界条件,第一个张量的模式减少为(状态模式,与第二个站点的共享模式),而最后一个张量的模式变为(与倒数第二个站点的共享模式,状态模式)。stridesIn – [in] 大小为
nStateModes的数组,指定所选 MPS 表示中所有张量的步长。 与extentsIn类似,stridesIn也应与每个 MPS 张量的模式顺序一致。 如果为 NULL,将假定默认的广义列优先步长。stateTensorsIn – [in] 大小为
nStateModes的数组,指定定义所选 MPS 表示的所有张量的数据。 如果为 NULL,则初始 MPS 分解状态将表示真空状态。
cutensornetStateFinalizeMPS¶
-
cutensornetStatus_t cutensornetStateFinalizeMPS(const cutensornetHandle_t handle, cutensornetState_t tensorNetworkState, cutensornetBoundaryCondition_t boundaryCondition, const int64_t *const extentsOut[], const int64_t *const stridesOut[])¶
对具有给定形状的最终张量网络状态施加用户定义的 MPS(矩阵乘积态)分解。
通过调用此 API 函数,仅指定所需的目标张量网络状态表示(MPS 表示),而无需实际计算。 构成原始张量网络状态的张量可能在此 API 函数调用后仍会使用新数据进行更新。 张量网络状态的实际 MPS 分解将在调用
cutensornetStatePrepare和cutensornetStateComputeAPI 函数(在此cutensornetStateFinalizeMPS调用之后)后计算。注意
当前的 MPS 分解功能作为预览版提供,未来版本将推出更多优化和增强功能。 在当前版本中,此功能的主要目标是通过便捷的高级接口,促进张量网络状态的 MPS 压缩的实现,目标是更广泛的、有兴趣将 MPS 算法添加到其模拟器的用户社区。
注意
extentsOut可用于指定相邻 MPS 张量之间共享键的 extent 截断。警告
当前 cuTensorNet 库版本仅支持具有二维状态模式(仅限量子比特,使用量子计算语言)的张量网络状态的 MPS 分解。
警告
在当前版本中,MPS 分解无法从分布式执行中受益。
警告
如果在 CUTENSORNET_STATE_MPS_SVD_CONFIG 中指定了基于值的 SVD 截断,则在执行期间(例如,在 cutensornetStateCompute() 中),
extentsOut和stridesOut可能不会被遵守。 在这种情况下,用户可以通过提供有效的指针在 cutensornetStateCompute() 中查询extentsOut和stridesOut的运行时值。警告
截至当前版本,如果
tensorNetworkState在不同模式上具有不同的 extent,则如果存在作用于两个非相邻模式的算子,则无法计算精确的 MPS 分解。- 参数
handle – [in] cuTensorNet 库句柄。
tensorNetworkState – [inout] 张量网络状态。
boundaryCondition – [in] 目标 MPS 表示的边界条件。
extentsOut – [in] 大小为
nStateModes的数组,指定定义目标 MPS 表示的所有张量的最大 extent。extentsOut[i]预计与模式顺序一致(第 (i-1) 个和第 i 个 MPS 张量之间的共享模式,第 i 个 MPS 张量的状态模式,第 i 个和第 (i+1) 个 MPS 张量之间的共享模式)。对于开放边界条件,第一个张量的模式减少为(状态模式,与第二个站点的共享模式),而最后一个张量的模式变为(与倒数第二个站点的共享模式,状态模式)。stridesOut – [in] 大小为
nStateModes的数组,指定定义目标 MPS 表示的所有张量的步长。 与extentsOut类似,stridesOut也应与每个 MPS 张量的模式顺序一致。 如果为 NULL,将假定默认的广义列优先步长。
cutensornetStateCaptureMPS¶
-
cutensornetStatus_t cutensornetStateCaptureMPS(const cutensornetHandle_t handle, cutensornetState_t tensorNetworkState)¶
将张量网络状态重置为先前通过
cutensornetStateCompute计算的 MPS 状态通过调用此 API 函数,应用于该状态的所有张量算子和张量网络算子都将被删除。 新的初始状态将被重置为先前计算的 MPS 状态,该状态通过
cutensornetStateFinalizeMPS调用指定并通过cutensornetStateCompute调用计算。 通过cutensornetStateConfigure和cutensornetStateFinalizeMPS指定的 MPS 模拟设置将保留。注意
此辅助 API 等效于创建
cutensornetState_t,并将先前的输出 MPS 状态作为初始 MPS 状态,同时保持相同的 MPS 模拟设置和输出 MPS 张量的 extent/步长。警告
删除的张量算子和张量网络算子将不再通过其整数 ID 访问。 后续的张量算子和张量网络算子将具有新的唯一整数 ID,这些 ID 将不与旧的 ID 重叠。
- 参数
handle – [in] cuTensorNet 库句柄。
tensorNetworkState – [inout] 张量网络状态。
cutensornetCreateNetworkOperator¶
-
cutensornetStatus_t cutensornetCreateNetworkOperator(const cutensornetHandle_t handle, int32_t numStateModes, const int64_t stateModeExtents[], cudaDataType_t dataType, cutensornetNetworkOperator_t *tensorNetworkOperator)¶
创建给定形状的未初始化的张量网络算子,该形状由状态模式的数量及其 extent 定义。
张量网络算子是一种将张量网络状态从主直积空间映射回同一张量空间的算子。 张量网络算子的形状由状态模式的数量及其 extent 定义,这应与算子将作用于的张量网络状态的定义相匹配。 请注意,形式上,声明的张量网络算子将具有比定义状态模式数量多两倍的模式,前半部分对应于它作用于的主直积空间,而后半部分对应于结果张量网络状态所在的同一主直积空间。
注意
此 API 定义了一个抽象的未初始化的张量网络算子。 用户稍后可以通过向其附加组件来使用某些具体结构对其进行初始化。
- 参数
handle – [in] cuTensorNet 库句柄。
numStateModes – [in] 算子作用于的状态模式的数量。
stateModeExtents – [in] 大小为
numStateModes的数组,指定每个作用状态模式的 extent。dataType – [in] 算子的数据类型。
tensorNetworkOperator – [out] 张量网络算子(此时为空)。
cutensornetNetworkOperatorAppendProduct¶
-
cutensornetStatus_t cutensornetNetworkOperatorAppendProduct(const cutensornetHandle_t handle, cutensornetNetworkOperator_t tensorNetworkOperator, cuDoubleComplex coefficient, int32_t numTensors, const int32_t numStateModes[], const int32_t *stateModes[], const int64_t *tensorModeStrides[], const void *tensorData[], int64_t *componentId)¶
将张量积算子组件附加到张量网络算子。
张量积算子组件定义为一个或多个张量算子的张量积,这些张量算子作用于状态模式的不相交子集。 请注意,指定张量积中的每个张量算子(张量因子)都具有比其作用的状态模式的数量多两倍的模式。 具体来说,张量算子模式的前半部分将与状态模式收缩。 一个典型的例子是泡利矩阵的张量积,其中每个泡利矩阵作用于张量网络状态的特定模式。 此 API 函数用于将张量网络算子定义为具有复系数的张量算子积之和。
注意
用于定义张量网络算子的所有用户提供的张量必须在张量网络算子的整个生命周期内保持活动状态。
- 参数
handle – [in] cuTensorNet 库句柄。
tensorNetworkOperator – [inout] 张量网络算子。
coefficient – [in] 与附加的算子组件关联的复系数。
numTensors – [in] 张量积中张量因子的数量。
numStateModes – [in] 每个附加的张量因子作用于的状态模式的数量。
stateModes – [in] 每个附加的张量因子作用于的模式(长度 =
numStateModes)。tensorModeStrides – [in] 每个张量因子的张量模式步长(长度 =
numStateModes* 2)。 如果为 NULL,将使用默认的广义列优先步长。tensorData – [in] 存储在 GPU 内存中的每个张量因子的张量数据。
componentId – [out] 附加的张量网络算子组件的唯一顺序整数标识符。
cutensornetNetworkOperatorAppendMPO¶
-
cutensornetStatus_t cutensornetNetworkOperatorAppendMPO(const cutensornetHandle_t handle, cutensornetNetworkOperator_t tensorNetworkOperator, cuDoubleComplex coefficient, int32_t numStateModes, const int32_t stateModes[], const int64_t *tensorModeExtents[], const int64_t *tensorModeStrides[], const void *tensorData[], cutensornetBoundaryCondition_t boundaryCondition, int64_t *componentId)¶
将矩阵乘积算子 (MPO) 组件附加到张量网络算子。
MPO 张量的模式遵循标准的 cuTensorNet 约定(每个内部 MPO 张量有四个模式):模式 0:第 (i-1) 个 - 第 (i) 个连接; 模式 1:作用于 ket 状态模式的第 (i) 个站点开放模式; 模式 2:第 (i) 个 - 第 (i+1) 个连接; 模式 3:作用于 bra 状态模式的第 (i) 个站点开放模式; 当请求开放边界条件时,第一个 MPO 张量将移除模式 0,而最后一个 MPO 张量将移除模式 2,两者都只有三个模式(按顺序)。
注意
用于定义张量网络算子的所有用户提供的 MPO 张量必须在张量网络算子的整个生命周期内保持活动状态。
- 参数
handle – [in] cuTensorNet 库句柄。
tensorNetworkOperator – [inout] 张量网络算子。
coefficient – [in] 与附加的算子组件关联的复系数。
numStateModes – [in] MPO 作用于的状态模式的数量(MPO 中张量的数量)。
stateModes – [in] MPO 作用于的状态模式。
tensorModeExtents – [in] 每个 MPO 张量的张量模式 extent。
tensorModeStrides – [in] 每个 MPO 张量的存储步长,或 NULL(默认的广义列优先步长)。
tensorData – [in] 存储在 GPU 内存中的每个 MPO 张量因子的张量数据。
boundaryCondition – [in] MPO 边界条件。
componentId – [out] 附加的张量网络算子组件的唯一顺序整数标识符。
cutensornetDestroyNetworkOperator¶
-
cutensornetStatus_t cutensornetDestroyNetworkOperator(cutensornetNetworkOperator_t tensorNetworkOperator)¶
释放张量网络算子拥有的所有资源。
- 参数
tensorNetworkOperator – [inout] 张量网络算子。
cutensornetCreateAccessor¶
-
cutensornetStatus_t cutensornetCreateAccessor(const cutensornetHandle_t handle, cutensornetState_t tensorNetworkState, int32_t numProjectedModes, const int32_t *projectedModes, const int64_t *amplitudesTensorStrides, cutensornetStateAccessor_t *tensorNetworkAccessor)¶
创建张量网络状态振幅访问器。
状态振幅访问器允许用户提取单个状态振幅(状态张量的元素)、状态振幅切片(状态张量的切片)以及完整状态张量。特定切片的选择是通过指定张量网络状态的投影模式来完成的,即张量网络状态模式的子集,这些模式将在计算期间投影到特定的基向量。其余的张量状态模式(开放模式)按照它们各自的相对顺序将定义用户请求的结果状态振幅张量的形状。
注意
提供的张量网络状态在状态振幅访问器的生命周期内必须保持有效。此外,在用于创建状态振幅访问器后,对张量网络状态应用张量算子将使状态振幅访问器无效。另一方面,仅通过 cutensornetStateUpdateTensorOperator() 更新张量算子数据是允许的。
- 参数
handle – [in] cuTensorNet 库句柄。
tensorNetworkState – [in] 已定义的张量网络状态。
numProjectedModes – [in] 投影状态模式的数量(投影到特定基向量的张量网络状态模式)。
projectedModes – [in] 投影状态模式(当没有或所有模式都被投影时,可以为 NULL)。
amplitudesTensorStrides – [in] 结果振幅张量的模式步幅。如果为 NULL,将假定为默认的广义列优先步幅。
tensorNetworkAccessor – [out] 张量网络状态振幅访问器。
cutensornetDestroyAccessor¶
-
cutensornetStatus_t cutensornetDestroyAccessor(cutensornetStateAccessor_t tensorNetworkAccessor)¶
销毁张量网络状态振幅访问器。
- 参数
tensorNetworkAccessor – [inout] 张量网络状态振幅访问器。
cutensornetAccessorConfigure¶
-
cutensornetStatus_t cutensornetAccessorConfigure(const cutensornetHandle_t handle, cutensornetStateAccessor_t tensorNetworkAccessor, cutensornetAccessorAttributes_t attribute, const void *attributeValue, size_t attributeSize)¶
配置请求的张量网络状态振幅张量的计算。
- 参数
handle – [in] cuTensorNet 库句柄。
tensorNetworkAccessor – [inout] 张量网络状态振幅访问器。
attribute – [in] 配置属性。
attributeValue – [in] 指向配置属性值的指针(类型擦除)。
attributeSize – [in] 配置属性值的大小。
cutensornetAccessorPrepare¶
-
cutensornetStatus_t cutensornetAccessorPrepare(const cutensornetHandle_t handle, cutensornetStateAccessor_t tensorNetworkAccessor, size_t maxWorkspaceSizeDevice, cutensornetWorkspaceDescriptor_t workDesc, cudaStream_t cudaStream)¶
准备计算请求的张量网络状态振幅张量。
警告
cudaStream 参数在当前版本中未使用(可以设置为 0x0)。
- 参数
handle – [in] cuTensorNet 库句柄。
tensorNetworkAccessor – [in] 张量网络状态振幅访问器。
maxWorkspaceSizeDevice – [in] 可用 GPU 暂存内存量的上限(字节)。
workDesc – [out] 工作区描述符(将设置所需的暂存/缓存内存大小)。
cudaStream – [in] CUDA 流。
cutensornetAccessorGetInfo¶
-
cutensornetStatus_t cutensornetAccessorGetInfo(const cutensornetHandle_t handle, const cutensornetStateAccessor_t tensorNetworkAccessor, cutensornetAccessorAttributes_t attribute, void *attributeValue, size_t attributeSize)¶
检索与请求的张量网络状态振幅张量的计算相关的属性。
- 参数
handle – [in] cuTensorNet 库句柄。
tensorNetworkAccessor – [in] 张量网络状态振幅访问器。
attribute – [in] 信息属性。
attributeValue – [out] 指向信息属性值的指针(类型擦除)。
attributeSize – [in] 信息属性值的大小。
cutensornetAccessorCompute¶
-
cutensornetStatus_t cutensornetAccessorCompute(const cutensornetHandle_t handle, cutensornetStateAccessor_t tensorNetworkAccessor, const int64_t *projectedModeValues, cutensornetWorkspaceDescriptor_t workDesc, void *amplitudesTensor, void *stateNorm, cudaStream_t cudaStream)¶
计算张量网络状态的振幅。
注意
在张量线路状态不能保证具有单位范数的情况下,计算出的振幅不会自动归一化。在这种情况下,平方状态范数将作为单独的参数返回。
警告
提供的 workspace descriptor
workDesc必须显式设置 Device Scratch 缓冲区,因为当前版本不支持用户提供的内存池。此外,在当前版本中,附加的 workspace 缓冲区必须是 256 字节对齐的。警告
在当前版本中,此 API 函数的执行将同步提供的 CUDA 流。此限制可能会在未来解除。
- 参数
handle – [in] cuTensorNet 库句柄。
tensorNetworkAccessor – [in] 张量网络状态振幅访问器。
projectedModeValues – [in] 投影状态模式的值;如果没有投影模式,则为 NULL 指针。
workDesc – [in] Workspace 描述符(所需 scratch/cache 内存缓冲区必须由用户设置)。
amplitudesTensor – [inout] 用于存储计算出的张量网络状态振幅张量的存储空间。
stateNorm – [out] 底层张量线路状态的平方 2-范数(主机指针)。返回的标量将具有与张量线路状态相同的数值数据类型。提供 NULL 指针将忽略范数计算。
cudaStream – [in] CUDA 流。
cutensornetCreateExpectation¶
-
cutensornetStatus_t cutensornetCreateExpectation(const cutensornetHandle_t handle, cutensornetState_t tensorNetworkState, cutensornetNetworkOperator_t tensorNetworkOperator, cutensornetStateExpectation_t *tensorNetworkExpectation)¶
创建张量网络状态期望值的表示。
张量网络状态期望值是给定张量网络算子相对于给定张量网络状态的期望值。请注意,计算出的期望值是未归一化的,张量网络状态的范数将单独返回(可选)。
注意
提供的张量网络状态在张量网络状态期望值的生命周期内必须保持有效。此外,在用于创建张量网络状态期望值后,对张量网络状态应用张量算子将使张量网络状态期望值无效。另一方面,仅通过 cutensornetStateUpdateTensorOperator() 更新张量算子数据是允许的。
注意
提供的张量网络算子在张量网络状态期望值的生命周期内必须保持有效。此外,在用于创建张量网络状态期望值后,向张量网络算子追加新组件将使张量网络状态期望值无效。另一方面,仅更新张量网络算子内部的张量数据是允许的。
- 参数
handle – [in] cuTensorNet 库句柄。
tensorNetworkState – [in] 已定义的张量网络状态。
tensorNetworkOperator – [in] 已定义的张量网络算子。
tensorNetworkExpectation – [out] 张量网络期望值表示。
cutensornetDestroyExpectation¶
-
cutensornetStatus_t cutensornetDestroyExpectation(cutensornetStateExpectation_t tensorNetworkExpectation)¶
销毁张量网络状态期望值表示。
- 参数
tensorNetworkExpectation – [inout] 张量网络状态期望值表示。
cutensornetExpectationConfigure¶
-
cutensornetStatus_t cutensornetExpectationConfigure(const cutensornetHandle_t handle, cutensornetStateExpectation_t tensorNetworkExpectation, cutensornetExpectationAttributes_t attribute, const void *attributeValue, size_t attributeSize)¶
配置请求的张量网络状态期望值的计算。
- 参数
handle – [in] cuTensorNet 库句柄。
tensorNetworkExpectation – [inout] 张量网络状态期望值表示。
attribute – [in] 配置属性。
attributeValue – [in] 指向配置属性值的指针(类型擦除)。
attributeSize – [in] 配置属性值的大小。
cutensornetExpectationPrepare¶
-
cutensornetStatus_t cutensornetExpectationPrepare(const cutensornetHandle_t handle, cutensornetStateExpectation_t tensorNetworkExpectation, size_t maxWorkspaceSizeDevice, cutensornetWorkspaceDescriptor_t workDesc, cudaStream_t cudaStream)¶
准备计算请求的张量网络状态期望值。
警告
cudaStream 参数在当前版本中未使用(可以设置为 0x0)。
- 参数
handle – [in] cuTensorNet 库句柄。
tensorNetworkExpectation – [in] 张量网络状态期望值表示。
maxWorkspaceSizeDevice – [in] 可用 GPU 暂存内存量的上限(字节)。
workDesc – [out] 工作区描述符(将设置所需的暂存/缓存内存大小)。
cudaStream – [in] CUDA 流。
cutensornetExpectationGetInfo¶
-
cutensornetStatus_t cutensornetExpectationGetInfo(const cutensornetHandle_t handle, const cutensornetStateExpectation_t tensorNetworkExpectation, cutensornetExpectationAttributes_t attribute, void *attributeValue, size_t attributeSize)¶
检索与请求的张量网络状态期望值的计算相关的属性。
- 参数
handle – [in] cuTensorNet 库句柄。
tensorNetworkExpectation – [in] 张量网络状态期望值表示。
attribute – [in] 信息属性。
attributeValue – [out] 指向信息属性值的指针(类型擦除)。
attributeSize – [in] 信息属性值的大小。
cutensornetExpectationCompute¶
-
cutensornetStatus_t cutensornetExpectationCompute(const cutensornetHandle_t handle, cutensornetStateExpectation_t tensorNetworkExpectation, cutensornetWorkspaceDescriptor_t workDesc, void *expectationValue, void *stateNorm, cudaStream_t cudaStream)¶
计算给定张量网络算子在给定张量网络状态上的(未归一化的)期望值。
注意
在张量网络状态不能保证具有单位范数的情况下,计算出的期望值不会自动归一化。在这种情况下,平方状态范数将作为单独的参数返回。然后,通过将返回的未归一化期望值除以返回的平方状态范数,可以获得真实的张量网络状态期望值。
警告
提供的 workspace descriptor
workDesc必须显式设置 Device Scratch 缓冲区,因为当前版本不支持用户提供的内存池。此外,在当前版本中,附加的 workspace 缓冲区必须是 256 字节对齐的。警告
在当前版本中,此 API 函数的执行将同步提供的 CUDA 流。此限制可能会在未来解除。
- 参数
handle – [in] cuTensorNet 库句柄。
tensorNetworkExpectation – [in] 张量网络状态期望值表示。
workDesc – [in] Workspace 描述符(所需 scratch/cache 内存缓冲区必须由用户设置)。
expectationValue – [out] 计算出的未归一化张量网络状态期望值(主机指针)。返回的标量将具有与张量线路状态相同的数值数据类型。
stateNorm – [out] 底层张量线路状态的平方 2-范数(主机指针)。返回的标量将具有与张量线路状态相同的数值数据类型。提供 NULL 指针将忽略范数计算。
cudaStream – [in] CUDA 流。
cutensornetCreateMarginal¶
-
cutensornetStatus_t cutensornetCreateMarginal(const cutensornetHandle_t handle, cutensornetState_t tensorNetworkState, int32_t numMarginalModes, const int32_t *marginalModes, int32_t numProjectedModes, const int32_t *projectedModes, const int64_t *marginalTensorStrides, cutensornetStateMarginal_t *tensorNetworkMarginal)¶
为给定的张量网络状态创建指定边缘张量的表示。
张量网络状态边缘张量是通过张量网络状态与其对偶(共轭)状态的直积形成的,然后对除显式指定的所谓开放状态模式之外的所有状态模式进行迹运算。在计算张量网络状态边缘张量时,将遵循指定的开放状态模式的顺序。此外,在迹运算之前,某些状态模式可以选择性地投影到这些模式的特定单个基态,从而形成所谓的投影模式,这些模式将不参与迹运算。请注意,结果边缘张量将比指定的开放模式的数量多两倍的模式,前半部分来自主直积空间,而后半部分对称地来自对偶(共轭)空间。
注意
在量子领域,边缘张量被称为约化密度矩阵。例如,在量子线路模拟中,约化密度矩阵由保持不变的状态模式和被追踪的剩余状态模式指定。此外,在迹运算之前,可以将某些量子位模式投影到这些模式的特定单个基态,从而产生投影的约化密度矩阵。
注意
提供的张量网络状态在张量网络状态边缘张量的生命周期内必须保持有效。此外,在用于创建张量网络状态边缘张量后,对张量网络状态应用张量算子将使张量网络状态边缘张量无效。另一方面,仅通过 cutensornetStateUpdateTensorOperator() 更新张量算子数据是允许的。
- 参数
handle – [in] cuTensorNet 库句柄。
tensorNetworkState – [in] 张量网络状态。
numMarginalModes – [in] 定义边缘张量的开放状态模式的数量。
marginalModes – [in] 指向定义边缘张量的开放状态模式的指针。
numProjectedModes – [in] 投影状态模式的数量。
projectedModes – [in] 指向投影状态模式的指针。
marginalTensorStrides – [in] 边缘张量的存储步幅(张量模式的数量是定义开放模式数量的两倍)。如果为 NULL,将假定为默认的广义列优先步幅。
tensorNetworkMarginal – [out] 张量网络状态边缘张量。
cutensornetDestroyMarginal¶
-
cutensornetStatus_t cutensornetDestroyMarginal(cutensornetStateMarginal_t tensorNetworkMarginal)¶
销毁张量网络状态边缘 (marginal)。
- 参数
tensorNetworkMarginal – [in] 张量网络状态边缘 (marginal) 表示。
cutensornetMarginalConfigure¶
-
cutensornetStatus_t cutensornetMarginalConfigure(const cutensornetHandle_t handle, cutensornetStateMarginal_t tensorNetworkMarginal, cutensornetMarginalAttributes_t attribute, const void *attributeValue, size_t attributeSize)¶
配置请求的张量网络状态边缘 (marginal) 张量的计算。
- 参数
handle – [in] cuTensorNet 库句柄。
tensorNetworkMarginal – [inout] 张量网络状态边缘 (marginal) 表示。
attribute – [in] 配置属性。
attributeValue – [in] 指向配置属性值的指针(类型擦除)。
attributeSize – [in] 配置属性值的大小。
cutensornetMarginalPrepare¶
-
cutensornetStatus_t cutensornetMarginalPrepare(const cutensornetHandle_t handle, cutensornetStateMarginal_t tensorNetworkMarginal, size_t maxWorkspaceSizeDevice, cutensornetWorkspaceDescriptor_t workDesc, cudaStream_t cudaStream)¶
准备请求的张量网络状态边缘 (marginal) 张量的计算。
警告
cudaStream 参数在当前版本中未使用(可以设置为 0x0)。
- 参数
handle – [in] cuTensorNet 库句柄。
tensorNetworkMarginal – [in] 张量网络状态边缘 (marginal) 表示。
maxWorkspaceSizeDevice – [in] 可用 GPU 暂存内存量的上限(字节)。
workDesc – [out] 工作区描述符(将设置所需的暂存/缓存内存大小)。
cudaStream – [in] CUDA 流。
cutensornetMarginalGetInfo¶
-
cutensornetStatus_t cutensornetMarginalGetInfo(const cutensornetHandle_t handle, const cutensornetStateMarginal_t tensorNetworkMarginal, cutensornetMarginalAttributes_t attribute, void *attributeValue, size_t attributeSize)¶
检索与请求的张量网络状态边缘 (marginal) 张量计算相关的属性。
- 参数
handle – [in] cuTensorNet 库句柄。
tensorNetworkMarginal – [in] 张量网络状态边缘 (marginal) 表示。
attribute – [in] 信息属性。
attributeValue – [out] 指向信息属性值的指针(类型擦除)。
attributeSize – [in] 信息属性值的大小。
cutensornetMarginalCompute¶
-
cutensornetStatus_t cutensornetMarginalCompute(const cutensornetHandle_t handle, cutensornetStateMarginal_t tensorNetworkMarginal, const int64_t *projectedModeValues, cutensornetWorkspaceDescriptor_t workDesc, void *marginalTensor, cudaStream_t cudaStream)¶
计算请求的张量网络状态边缘 (marginal) 张量。
警告
提供的 workspace descriptor
workDesc必须显式设置 Device Scratch 缓冲区,因为当前版本不支持用户提供的内存池。此外,在当前版本中,附加的 workspace 缓冲区必须是 256 字节对齐的。警告
在当前版本中,此 API 函数的执行将同步提供的 CUDA 流。此限制可能会在未来解除。
- 参数
handle – [in] cuTensorNet 库句柄。
tensorNetworkMarginal – [in] 张量网络状态边缘 (marginal) 表示。
projectedModeValues – [in] 指向投影模式值的指针。每个整数值对应于给定(投影)状态模式的基态。
workDesc – [in] Workspace 描述符(所需 scratch/cache 内存缓冲区必须由用户设置)。
marginalTensor – [out] 指向边缘 (marginal) 张量的 GPU 存储的指针,该张量将在此调用中计算。
cudaStream – [in] CUDA 流。
cutensornetCreateSampler¶
-
cutensornetStatus_t cutensornetCreateSampler(const cutensornetHandle_t handle, cutensornetState_t tensorNetworkState, int32_t numModesToSample, const int32_t *modesToSample, cutensornetStateSampler_t *tensorNetworkSampler)¶
创建张量网络状态采样器。
张量网络状态采样器从状态张量生成样本,其概率等于状态张量对应元素的平方绝对值。 也可以选择张量网络状态模式的任何子集,仅从它们所跨越的子空间中进行采样。 指定状态模式的顺序在生成输出样本时将得到遵守。
注意
为了进行量子电路模拟,张量网络状态采样器可以从已定义量子电路的输出状态(即,由门应用定义的张量网络)生成位串(或量子位串)。
注意
提供的张量网络状态必须在张量网络状态采样器的生命周期内保持有效。 此外,在用于创建张量网络状态采样器之后,对张量网络状态应用张量算符将使张量网络状态采样器无效。 另一方面,仅通过 cutensornetStateUpdateTensorOperator() 更新张量算符数据是被允许的。
- 参数
handle – [in] cuTensorNet 库句柄。
tensorNetworkState – [in] 张量网络状态。
numModesToSample – [in] 要从中采样的张量网络状态模式的数量。
modesToSample – [in] 指向要从中采样的状态模式的指针(当请求所有模式时,可以为 NULL)。
tensorNetworkSampler – [out] 张量网络采样器。
cutensornetDestroySampler¶
-
cutensornetStatus_t cutensornetDestroySampler(cutensornetStateSampler_t tensorNetworkSampler)¶
销毁张量网络状态采样器。
- 参数
tensorNetworkSampler – [in] 张量网络状态采样器。
cutensornetSamplerConfigure¶
-
cutensornetStatus_t cutensornetSamplerConfigure(const cutensornetHandle_t handle, cutensornetStateSampler_t tensorNetworkSampler, cutensornetSamplerAttributes_t attribute, const void *attributeValue, size_t attributeSize)¶
配置张量网络状态采样器。
- 参数
handle – [in] cuTensorNet 库句柄。
tensorNetworkSampler – [inout] 张量网络状态采样器。
attribute – [in] 配置属性。
attributeValue – [in] 指向配置属性值的指针(类型擦除)。
attributeSize – [in] 配置属性值的大小。
cutensornetSamplerPrepare¶
-
cutensornetStatus_t cutensornetSamplerPrepare(const cutensornetHandle_t handle, cutensornetStateSampler_t tensorNetworkSampler, size_t maxWorkspaceSizeDevice, cutensornetWorkspaceDescriptor_t workDesc, cudaStream_t cudaStream)¶
准备张量网络状态采样器。
警告
cudaStream 参数在当前版本中未使用(可以设置为 0x0)。
- 参数
handle – [in] cuTensorNet 库句柄。
tensorNetworkSampler – [in] 张量网络状态采样器。
maxWorkspaceSizeDevice – [in] 可用 GPU 暂存内存量的上限(字节)。
workDesc – [out] 工作区描述符(将设置所需的暂存/缓存内存大小)。
cudaStream – [in] CUDA 流。
cutensornetSamplerGetInfo¶
-
cutensornetStatus_t cutensornetSamplerGetInfo(const cutensornetHandle_t handle, const cutensornetStateSampler_t tensorNetworkSampler, cutensornetSamplerAttributes_t attribute, void *attributeValue, size_t attributeSize)¶
检索与张量网络状态采样相关的属性。
- 参数
handle – [in] cuTensorNet 库句柄。
tensorNetworkSampler – [in] 张量网络状态采样器。
attribute – [in] 信息属性。
attributeValue – [out] 指向信息属性值的指针(类型擦除)。
attributeSize – [in] 信息属性值的大小。
cutensornetSamplerSample¶
-
cutensornetStatus_t cutensornetSamplerSample(const cutensornetHandle_t handle, cutensornetStateSampler_t tensorNetworkSampler, int64_t numShots, cutensornetWorkspaceDescriptor_t workDesc, int64_t *samples, cudaStream_t cudaStream)¶
执行张量网络状态的采样,即生成请求数量的样本。
注意
内部使用的伪随机数生成器使用随机默认种子进行初始化,因此通常在每次重复执行时生成不同的样本集。 未来,可能会提供将种子重置为用户定义值的功能,以确保在重复重新运行应用程序时生成完全相同的样本集(这对于调试可能很有用)。
警告
提供的 workspace descriptor
workDesc必须显式设置 Device Scratch 缓冲区,因为当前版本不支持用户提供的内存池。此外,在当前版本中,附加的 workspace 缓冲区必须是 256 字节对齐的。警告
在当前版本中,此 API 函数的执行将同步提供的 CUDA 流。此限制可能会在未来解除。
- 参数
handle – [in] cuTensorNet 库句柄。
tensorNetworkSampler – [in] 张量网络状态采样器。
numShots – [in] 要生成的样本数。
workDesc – [in] Workspace 描述符(所需 scratch/cache 内存缓冲区必须由用户设置)。
samples – [out] 主机内存指针,生成的 state tensor 样本将存储在此处。 样本将以 C 语言符号 samples[SampleId][ModeId] 存储,并且最初指定的要从中采样的张量网络状态模式的顺序将得到遵守。
cudaStream – [in] CUDA 流。
内存管理 API¶
流序 内存分配器(或简称 mempool)以异步方式从/向 mempool 分配/释放内存,这意味着在流上排队的内存操作和计算具有明确定义的流间和流内依赖性。 有几个良好实现的流序 mempool 可用,例如 cudaMemPool_t,它自 CUDA 11.2 起内置于 CUDA 驱动程序级别(因此同一进程中的所有 CUDA 应用程序都可以轻松共享同一池,请参阅 此处)和 RAPIDS 内存管理器 (RMM)。 有关详细介绍,请参阅 NVIDIA 开发者博客。
新的设备内存处理程序 API 允许用户将流序 mempool 绑定到库句柄,这样 cuTensorNet 就可以为用户处理大部分内存管理。 下面是可以完成的操作的说明
MyMemPool pool = MyMemPool(); // kept alive for the entire process in real apps
int my_alloc(void* ctx, void** ptr, size_t size, cudaStream_t stream) {
// assuming this is the memory allocation routine provided by my mempool
return reinterpret_cast<MyMemPool*>(ctx)->alloc(ptr, size, stream);
}
int my_dealloc(void* ctx, void* ptr, size_t size, cudaStream_t stream) {
// assuming this is the memory deallocation routine provided by my mempool
return reinterpret_cast<MyMemPool*>(ctx)->dealloc(ptr, size, stream);
}
// create a mem handler and fill in the required members for the library to use
cutensornetDeviceMemHandler_t handler;
handler.ctx = reinterpret_cast<void*>(&pool);
handler.device_alloc = my_alloc;
handler.device_free = my_dealloc;
memcpy(handler.name, std::string("my pool").c_str(), CUTENSORNET_ALLOCATOR_NAME_LEN);
// bind the handler to the library handle
cutensornetSetDeviceMemHandler(handle, &handler);
/* ... perform the network creation & optimization as usual ... */
// create a workspace descriptor
cutensornetWorkspaceDescriptor_t workDesc;
// (this step is optional and workDesc can be set to NULL if one just wants
// to use the "recommended" workspace size)
cutensornetCreateWorkspaceDescriptor(handle, &workDesc);
// User doesn’t compute the required sizes
// User doesn’t query the workspace size (but one can if desired)
// User doesn’t allocate memory!
// User sets workspacePtr=NULL for the corresponding memory space (device, in this case) to indicate the library should
// draw memory (of the "recommended" size, if the workspace size is set to 0 as shown below) from the user's pool;
// if a nonzero size is set, we would use the given size instead of the recommended one.
// (this step is also optional if workDesc has been set to NULL)
cutensornetWorkspaceSetMemory(handle, workDesc, CUTENSORNET_MEMSPACE_DEVICE, CUTENSORNET_WORKSPACE_SCRATCH, NULL, 0);
// create a contraction plan
cutensornetContractionPlan_t plan;
cutensornetCreateContractionPlan(handle, descNet, optimizerInfo, workDesc, &plan);
// autotune the plan with the workspace
cutensornetContractionAutotune(handle, plan, rawDataIn, rawDataOut, workDesc, pref, stream);
// perform actual contraction with the workspace
for (int sliceId=0; sliceId<num_slices; sliceId++) {
cutensornetContraction(
handle, plan, rawDataIn, rawDataOut, workDesc, sliceId, stream);
}
// clean up
cutensornetDestroyContractionPlan(plan);
cutensornetDestroyWorkspaceDescriptor(workDesc); // optional if workDesc has been set to NULL
// User doesn’t deallocate memory!
如上所示,可以跳过对 workspace 相关 API 的多次调用。 此外,允许库共享您的内存池不仅可以缓解潜在的内存冲突,还可以实现可能的优化。
注意
在当前版本中,只能绑定设备 mempool。
cutensornetSetDeviceMemHandler¶
-
cutensornetStatus_t cutensornetSetDeviceMemHandler(cutensornetHandle_t handle, const cutensornetDeviceMemHandler_t *devMemHandler)¶
设置当前的设备内存处理程序。
设置后,当 cuTensorNet 在各种 API 调用中需要设备内存时,它将从用户提供的内存池中分配,并在完成时释放。 有关更多详细信息,请参阅 cutensornetDeviceMemHandler_t 和需要 cutensornetWorkspaceDescriptor_t 的 API。
内部流顺序是使用传递给 cutensornetContractionAutotune() 和 cutensornetContraction() 的用户提供的流建立的。
警告
在以下情况下,它是未定义的行为
库句柄绑定到一个内存处理程序,然后又绑定到另一个处理程序
库句柄的生命周期长于附加的内存池
内存池不是流序的
- 参数
handle – [in] 保存 cuTensorNet 库上下文的不透明句柄。
devMemHandler – [in] 封装用户 mempool 的设备内存处理程序。 结构内容在内部复制。
cutensornetGetDeviceMemHandler¶
-
cutensornetStatus_t cutensornetGetDeviceMemHandler(const cutensornetHandle_t handle, cutensornetDeviceMemHandler_t *devMemHandler)¶
获取当前的设备内存处理程序。
- 参数
handle – [in] 保存 cuTensorNet 库上下文的不透明句柄。
devMemHandler – [out] 如果之前设置过,则填充
handler指向的结构体,否则返回 CUTENSORNET_STATUS_NO_DEVICE_ALLOCATOR。
错误管理 API¶
cutensornetGetErrorString¶
-
const char *cutensornetGetErrorString(cutensornetStatus_t error)¶
返回错误代码的描述字符串。
备注
非阻塞,不可重入且线程安全
- 参数
error – [in] 要转换为字符串的错误代码。
- 返回值
错误字符串
Logger API¶
cutensornetLoggerSetCallback¶
-
cutensornetStatus_t cutensornetLoggerSetCallback(cutensornetLoggerCallback_t callback)¶
此函数设置日志记录回调例程。
- 参数
callback – [in] 指向回调函数的指针。 请查看 cutensornetLoggerCallback_t。
cutensornetLoggerSetCallbackData¶
-
cutensornetStatus_t cutensornetLoggerSetCallbackData(cutensornetLoggerCallbackData_t callback, void *userData)¶
此函数设置日志记录回调例程以及用户数据。
- 参数
callback – [in] 指向回调函数的指针。 请查看 cutensornetLoggerCallbackData_t。
userData – [in] 指向用户提供的数据的指针,供回调使用。
cutensornetLoggerSetFile¶
-
cutensornetStatus_t cutensornetLoggerSetFile(FILE *file)¶
此函数设置日志记录输出文件。
- 参数
file – [in] 具有写入权限的打开文件。
cutensornetLoggerOpenFile¶
-
cutensornetStatus_t cutensornetLoggerOpenFile(const char *logFile)¶
此函数在给定路径中打开日志记录输出文件。
- 参数
logFile – [in] 日志记录输出文件的路径。
cutensornetLoggerSetLevel¶
-
cutensornetStatus_t cutensornetLoggerSetLevel(int32_t level)¶
此函数设置日志级别的数值。
- 参数
level – [in] 日志级别,应为以下之一
级别
摘要
详细描述
“0”
关闭
日志记录已禁用(默认)
“1”
错误
仅记录错误
“2”
性能追踪
启动 CUDA 内核的 API 调用将记录其参数和重要信息
“3”
性能提示
可能提高应用程序性能的提示
“4”
启发式追踪
提供关于库执行的一般信息,可能包含关于启发式状态的详细信息
“5”
API 追踪
API 追踪 - API 调用将记录其参数和重要信息
cutensornetLoggerSetMask¶
-
cutensornetStatus_t cutensornetLoggerSetMask(int32_t mask)¶
此函数设置日志掩码的数值。
有关详细信息,请参阅 cutensornetLoggerSetLevel()。
- 参数
mask – [in] 日志掩码的值。掩码定义为以下掩码的组合(按位或运算)
级别
描述
“0”
关闭
“1”
错误
“2”
性能追踪
“4”
性能提示
“8”
启发式追踪
“16”
API 追踪
cutensornetLoggerForceDisable¶
-
cutensornetStatus_t cutensornetLoggerForceDisable()¶
此函数禁用整个运行过程的日志记录。