主机状态向量迁移¶
关于本文档¶
cuStateVec 库提供了 custatevecSubSVMigrator API,使用户能够结合使用主机 CPU 内存和设备 GPU 内存,以扩展其模拟的规模。本文档概述了利用此 API 的可能场景。
custatevecSubSVMigrator API¶
custatevecSubSVMigrator API 是一种实用程序,用于迁移在 CPU(主机)上以及 GPU(设备)上分配的状态向量。此 API 允许利用 CPU 内存来容纳状态向量。还可以同时利用 CPU 和 GPU 内存来分配单个状态向量,从而最大限度地增加要模拟的量子比特数量。
custatevecSubSVMigrator API 的内存模型¶
custatevecSubSVMigrator API 假定 图 1 中所示的内存模型。状态向量被假定为平均切片成一系列子状态向量。子状态向量的数量应始终为 2 的幂。每个子状态向量都可以放置在主机或设备槽上。
子状态向量表示部分状态,并具有与量子比特子集对应的本地索引位。其大小为 \(2^{nLocalIndexBits}\),其中 *nLocalIndexBits* 是本地索引位的数量。
有一个要求,即主机槽应可从设备直接访问。这意味着在没有 HMM 的 x86 平台上,将使用 cudaHostAlloc() 来分配 CUDA 页面锁定内存。对于其他系统(如 GH200),使用 malloc() 分配的内存块可以从设备访问,因此,分配 CUDA 页面锁定内存不是强制性的。每个主机槽可以有自己的内存块,也可以分配为单个连续的内存块。这取决于开发者的选择。
设备槽应分配为单个设备内存块,其中所有设备槽都连续放置。这样可以将设备槽用作部分状态向量的单个块。使用此配置,设备槽索引位的操作(例如门应用)将在设备槽中应用。因此,设备槽的数量始终是 2 的幂。
在 cuStateVec 库中,此模型由 custatevecSubSVMigratorDescriptor_t 表示,该描述符由 custatevecSubSVMigratorCreate() 创建,并由 custatevecSubSVMigratorDestroy() 销毁。
索引位交换是在 cuStateVec 中本地化索引位的算法,如分布式索引位交换 API 文档的 量子比特重排序和分布式索引位交换 中所述。迁移子状态向量时,索引位通过使用 custatevecSubSVMigrator API 和 custatevecSwapIndexBits() 进行交换,如本文档后面的章节所述。
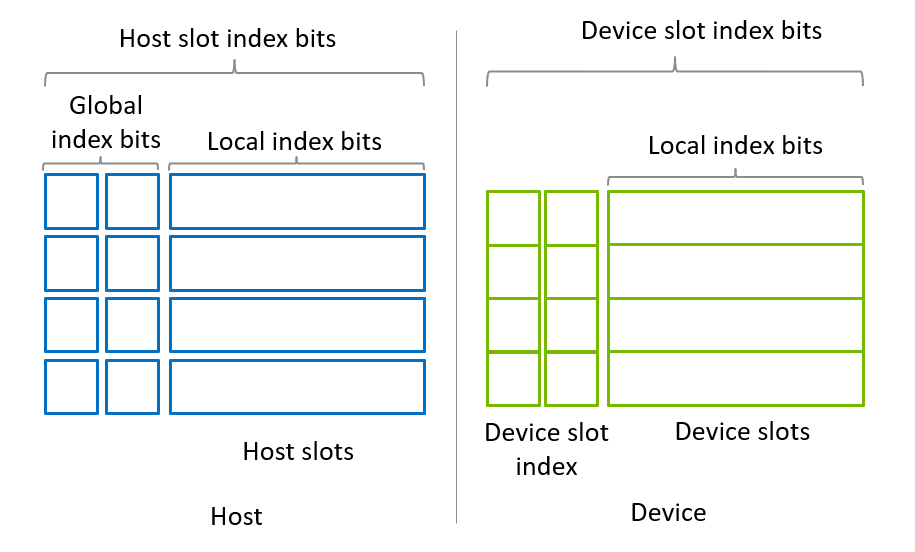
图 1. SubStateVectorMigrator API 的内存模型¶
可能的场景¶
在以下两种场景中,可以考虑使用主机内存分配状态向量。
在主机上分配状态向量
如果主机内存量足够大以容纳整个状态向量,则可以在主机槽上分配状态向量,并使用设备槽来应用操作。在模拟期间,子状态向量将复制到设备槽(检出),并在应用操作后,状态向量将复制回主机槽(检入)。对于要应用于所有子状态向量的操作,将迭代执行此迁移步骤。
在主机和设备上都分配状态向量
为了尽可能多地利用主机和设备内存(以便分配最大的状态向量),可以同时使用主机和设备内存来分配状态向量。操作在设备上应用,并且子状态向量在主机和设备之间交换,以便为所有子状态向量应用操作。
1. 在主机槽上分配状态向量¶
图 2 显示了在主机槽上分配的子状态向量的简化示例。四个子状态向量放置在主机槽上,并且分配了两个设备槽并保持为空。有两个全局索引位,分别表示为 *p* 和 *q*。
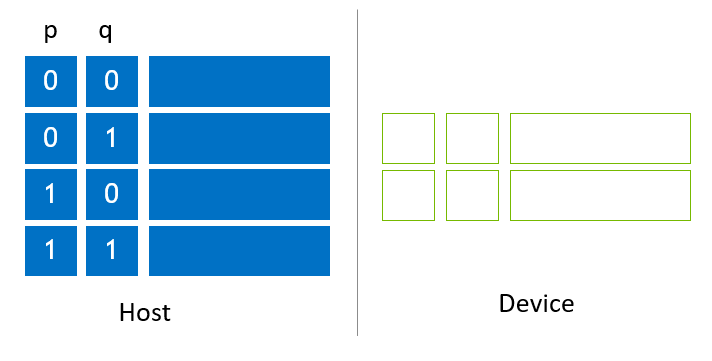
图 2. 在主机槽上分配的状态向量¶
当使用 NVIDIA H100 (80G) 并如图 图 2 所示将内存分配给设备槽时,设备槽的大小为 64 GB,每个槽的大小为 32 GB。主机状态向量大小是其两倍,因此,主机状态向量的大小为 128 GB。使用 NVIDIA H100 (80G) 的最大状态向量大小分别为 33 量子比特 (c64) 和 32 量子比特 (c128)。通过使用 128 GB 的主机内存,最大状态向量大小分别增加 1,达到 34 (complex64) 和 33 (complex128) 量子比特。
使用 SubStateVectorMigrator API,子状态向量通过使用以下原语进行迁移。通过组合这些原语,全局和本地索引位将被适当地重新排序。
检出主机槽中的子状态向量到设备槽。
将主机槽上的主机子状态向量复制到设备槽。此操作通过将主机槽指针传递给
custatevecSubSVMigratorMigrate()的 *srcSubSV* 参数来执行。
检入设备槽上的子状态向量到主机槽。
将设备槽复制回主机槽。此操作通过将主机槽指针传递给
custatevecSubSVMigratorMigrate()的 *dstSubSV* 参数来执行。
交换设备槽中的索引位
将本地索引位移动到全局索引位位置。此操作通过使用
custatevecSwapIndexBits()API 执行。
全局索引位的移动如图 图 3 所示。图 3 (a-1) 显示了本地化全局索引位 *q* 的第一次迁移。第 0 个和第 1 个子状态向量被复制到设备槽(检出),并且 *q* 移动到设备槽索引位。然后,对设备槽应用门应用和其他操作,以用于包含 *q* 和本地索引位的设备槽索引位。操作完成后,设备槽将复制回以更新主机槽(图 3 (a-2)),这将更新状态向量的前半部分(检入)。对于状态向量的后半部分,执行相同的步骤序列(图 3 (a-3, 4))。
为了将全局索引位 *p* 移动到设备槽,第 0 个和第 2 个子状态向量被复制到设备槽,这会将 *p* 移动到设备槽索引位(图 3 (b-1))。应用与 图 3 (b-2) - (b-4) 中所示类似的步骤来完成操作。
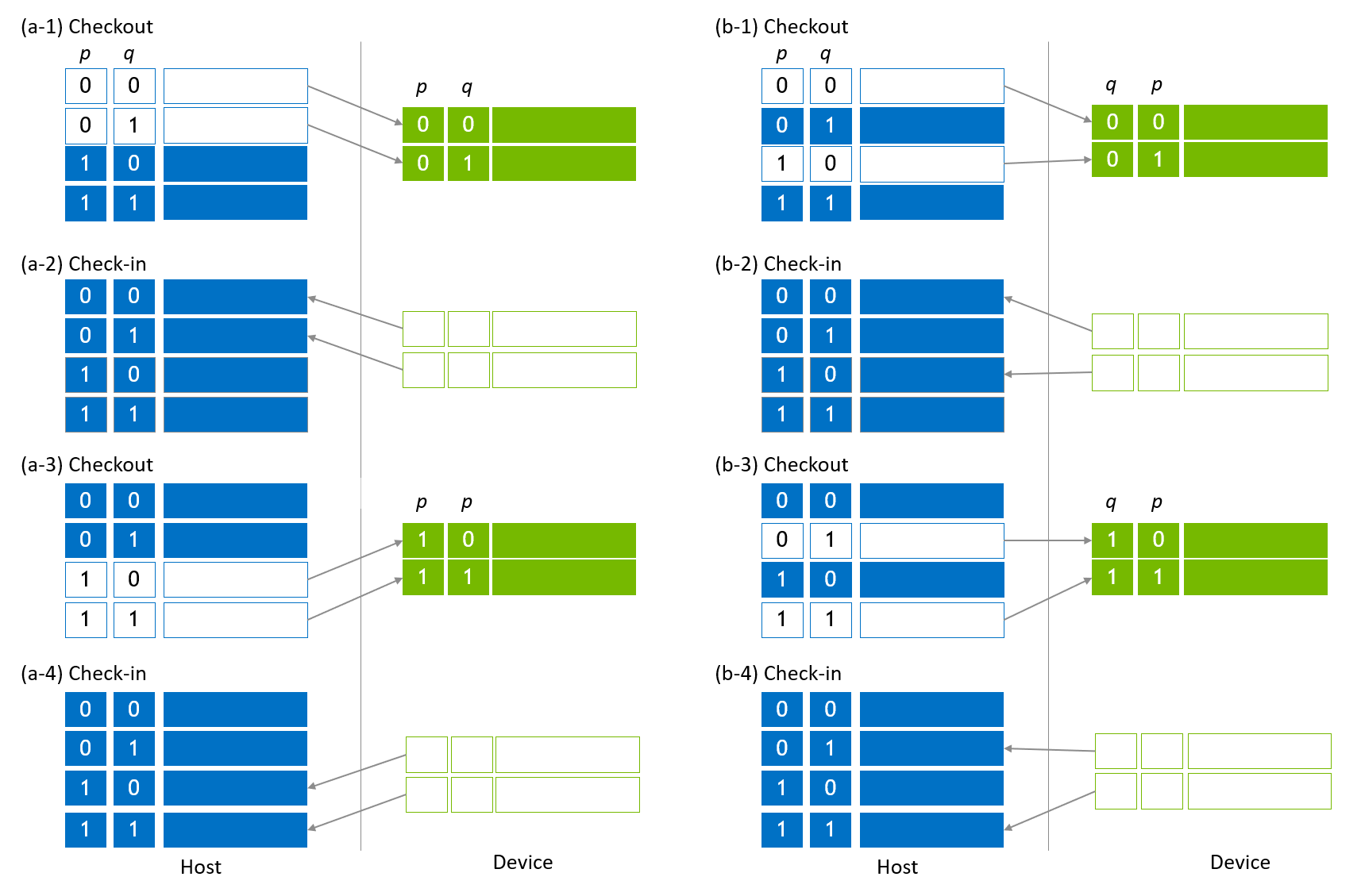
图 3. 主机向量迁移以本地化全局索引位¶
在状态向量迁移期间,存在一种优化,可以重叠检出和检入子状态向量,以利用主机和设备之间的双向传输(在 x86 系统上的 PCIe 和 GH200 上的 NVLink-C2C 上)。图 4 的左侧部分是 图 3 (a-2) 和 (a-3) 的剪切部分。这两个步骤融合为一个步骤,如图 图 4 的右侧部分所示。
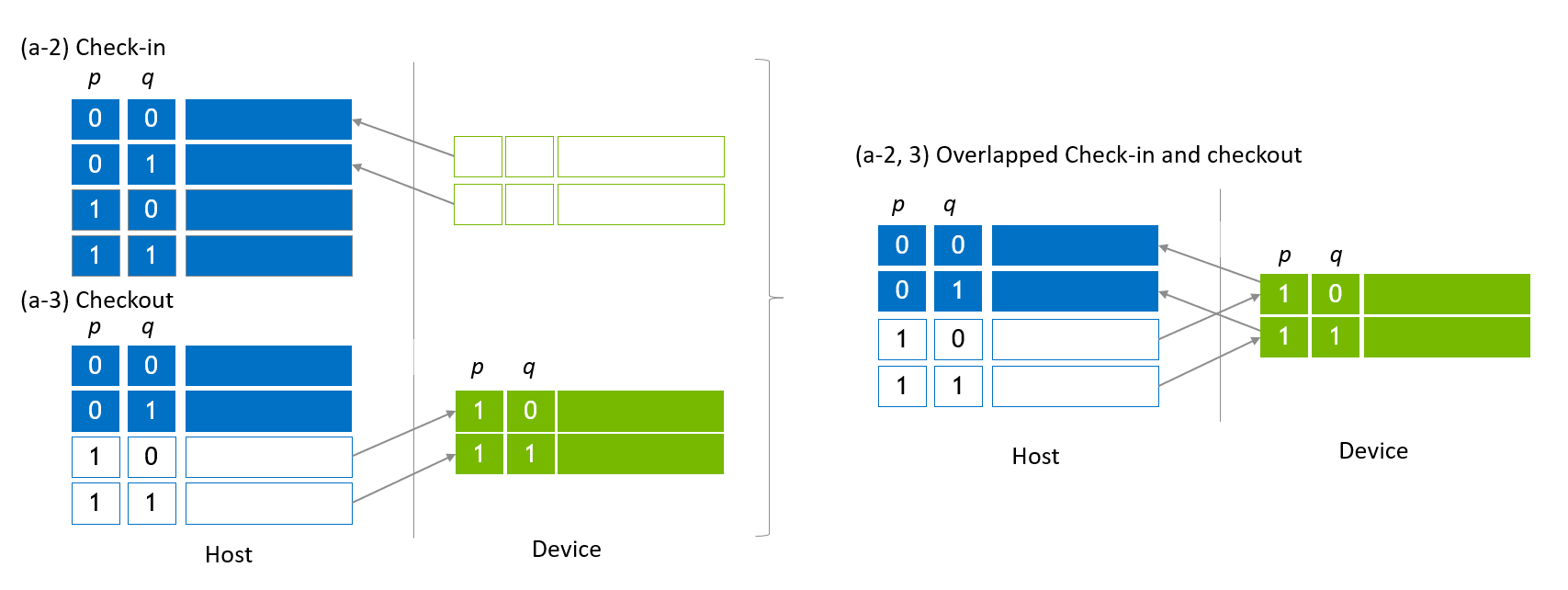
图 4. 重叠的检入和检出¶
为了将本地索引位交换为全局索引位,索引位交换在迁移步骤期间应用,如图 图 5 所示。该图的左侧部分显示了初始状态向量分配,其中 *p* 和 *q* 是全局索引位,而 *r* 表示要与全局索引位 *q* 交换的本地索引位的 LSB。
第一个检出步骤与 图 3 中所示的迁移步骤相同。然后,交换 q 和 r,以将 q 移动为本地索引位,将 r 移动为全局索引位。此交换操作通过 cuStateVec API custatevecSwapIndexBits() 完成。交换 q 和 r 后,设备槽上的子状态向量被检入到主机槽。通过对剩余的主机子状态向量应用相同的操作,全局索引位 q 和本地索引位 r 被交换。
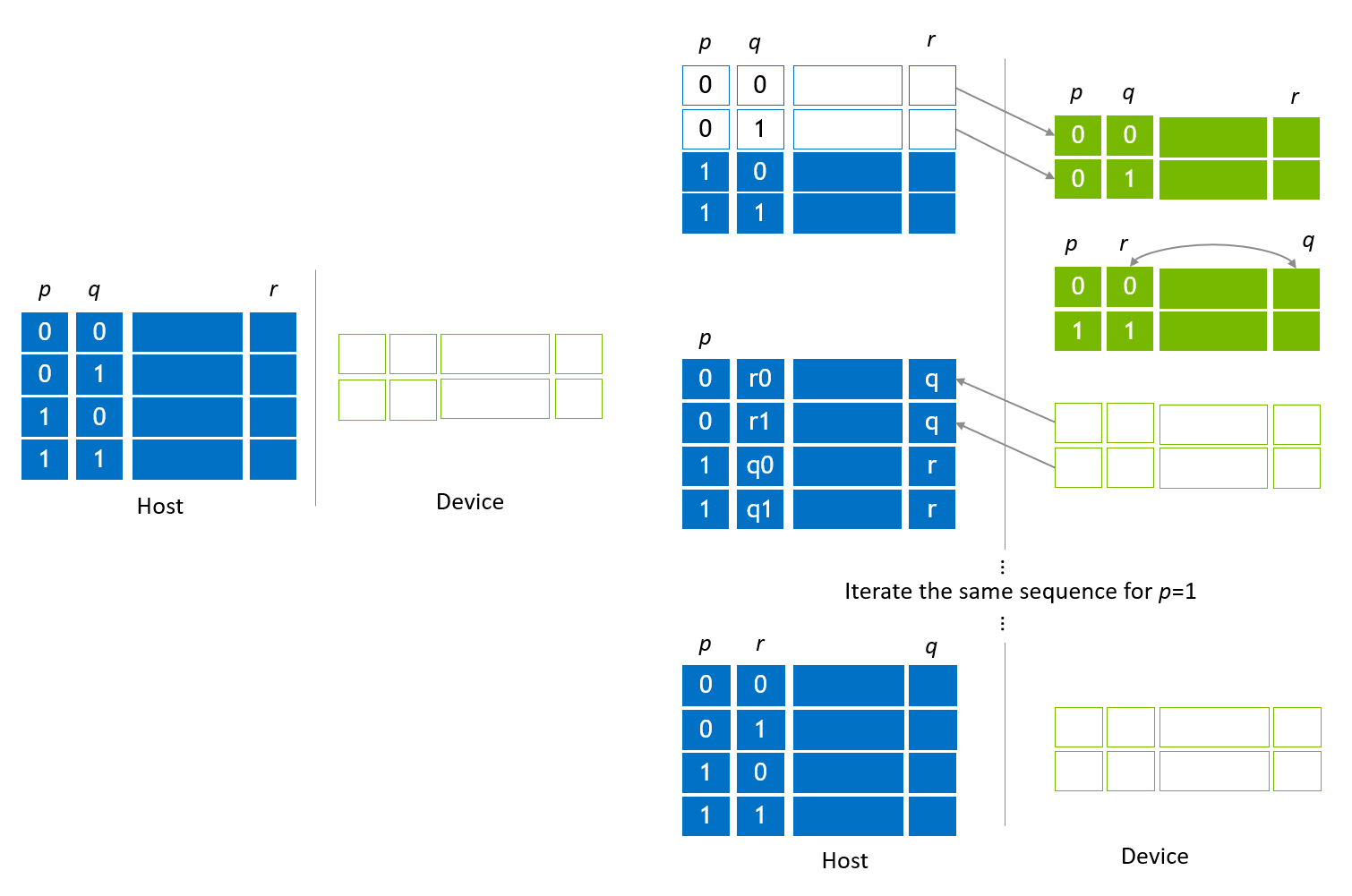
图 5. 全局和本地索引位的索引位交换¶
2. 在主机和设备槽上分配状态向量¶
第二种情况是利用主机和设备内存,并在其上分配状态向量,以最大化状态向量的大小。 图 6 显示了一个分配示例,这是最简单的情况,其中每个主机和设备槽中放置了两个子状态向量。此示例用于简化描述迁移算法。通过增加主机上的子状态向量数量,可以分配更大的状态向量。
例如,当使用 NVIDIA H100 (80G) 根据 图 6 分配设备槽时,设备槽的最大大小为 64 GB。主机状态向量大小相同,因此,主机状态向量的大小为 128 GB(主机上 64 GB + 设备上 64 GB)。通过使用 448 GB 主机内存,状态向量大小增长到 512 GB。
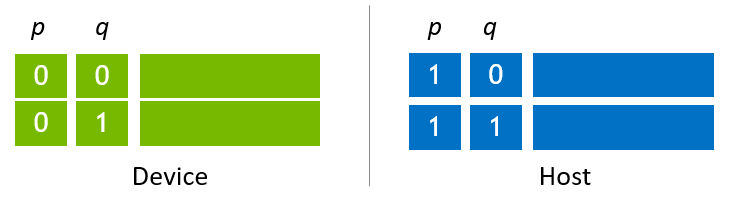
图 6. 在主机和设备上分配的状态向量¶
对于在主机和设备上分配的状态向量,状态向量迁移的原语是交换,这被视为对同一主机状态向量的重叠检入和检出。 custatevecSubSVMigrator 通过将相同的主机子状态向量指针传递给 custatevecSubSVMigratorMigrate() 的 srcSubSV 和 dstSubSV 参数来交换子状态向量。
状态向量迁移的执行过程如 图 7 所示。 图 7 (a) 中显示的第一步是初始状态,其中全局索引位 q 定位在设备槽中。在 图 7 (b) 中,对包含全局索引位 q 和本地索引位的设备槽索引位应用操作。然后,在主机和设备之间交换子状态向量,并对状态向量的后半部分应用操作 (图 7 (c), (d))。
下一个迁移序列旨在定位全局索引位 p 并应用操作。第一个迁移是交换第 0 个设备子状态向量和第 1 个主机子状态向量 (图 7 (e))。然后,对状态向量的前半部分应用操作 (图 7 (f))。下一个迁移是在主机和设备之间交换子状态向量,并对状态向量的后半部分应用操作。
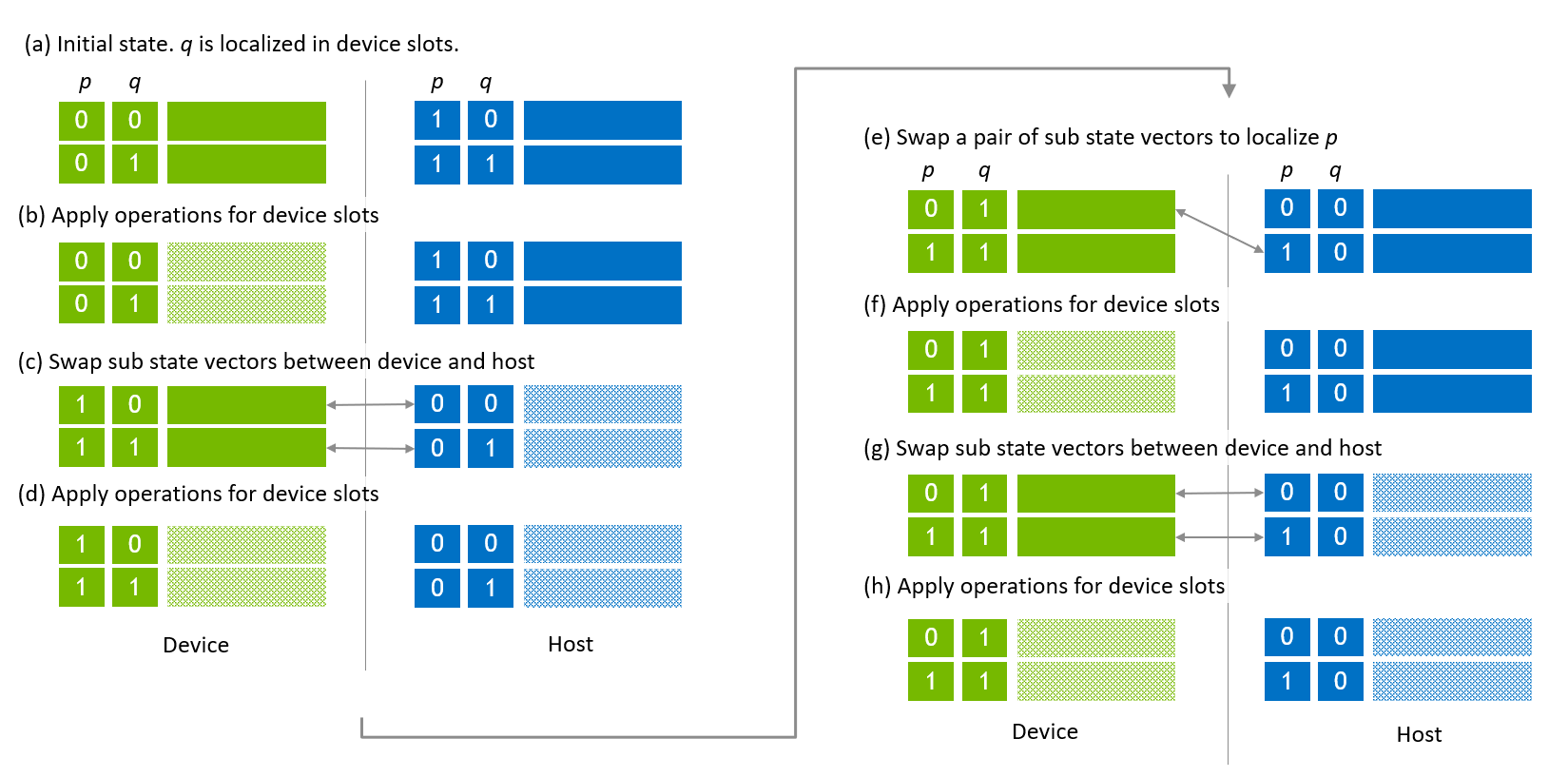
图 7. 主机-设备状态向量的状态向量迁移¶
为了交换全局索引位和本地索引位,cuStateVec API custatevecSwapIndexBits() 的应用方式与用于主机状态向量的方式相同。 图 8 (a) 显示了主机和设备子状态向量的相同放置方式,其中 p 和 q 是全局索引位,r 是本地索引位的 LSB。在应用操作 (图 8 (b)) 后,q 和 r 被交换 (图 8 (c))。然后,在主机和设备之间交换子状态向量 (图 8 (d))。对剩余的子状态向量执行相同的步骤,q 和 r 被交换 (图 8 (e))。
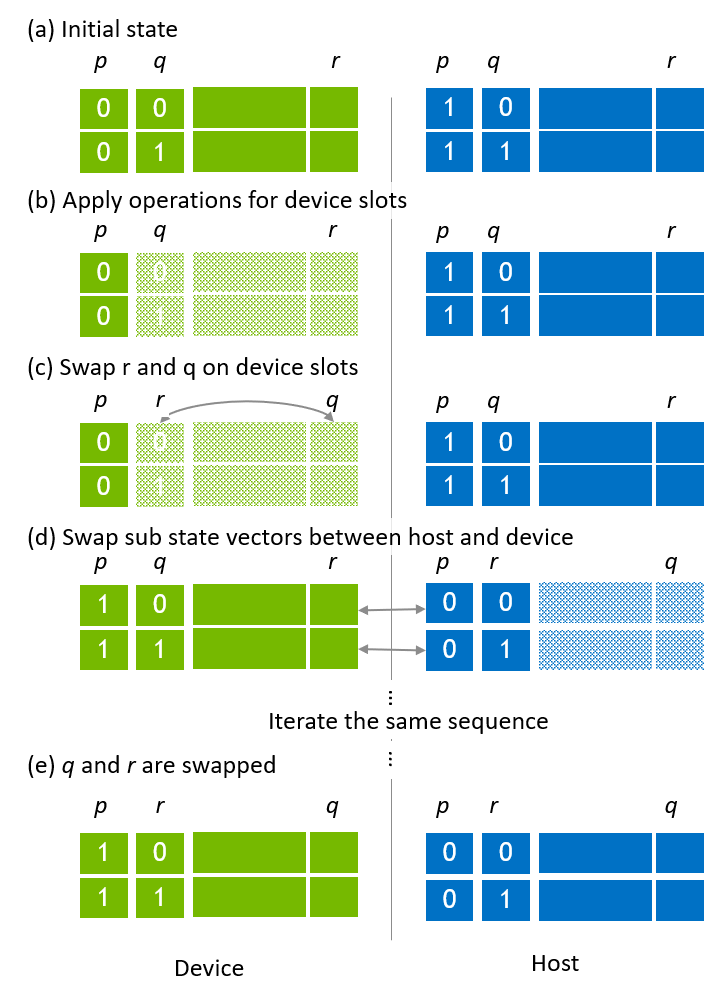
图 8. 在主机-设备状态向量中交换全局和本地索引位¶