示例¶
在本节中,我们将展示如何使用 *cuStateVec* 实现量子计算模拟。首先,我们描述如何安装库以及如何编译它。然后,我们提供一个示例代码来执行 *cuStateVec* 中的常见步骤。
编译¶
假设 cuQuantum 已在 CUQUANTUM_ROOT 中解压,我们相应地更新库路径
export LD_LIBRARY_PATH=${CUQUANTUM_ROOT}/lib:${LD_LIBRARY_PATH}
我们可以通过以下命令编译我们将在下面讨论的示例代码 (statevec_example.cu)
nvcc statevec_example.cu -I${CUQUANTUM_ROOT}/include -L${CUQUANTUM_ROOT}/lib -lcustatevec -o statevec_example
注意
根据 cuQuantum 包的来源,您可能需要将上面的 lib 替换为 lib64。
代码示例¶
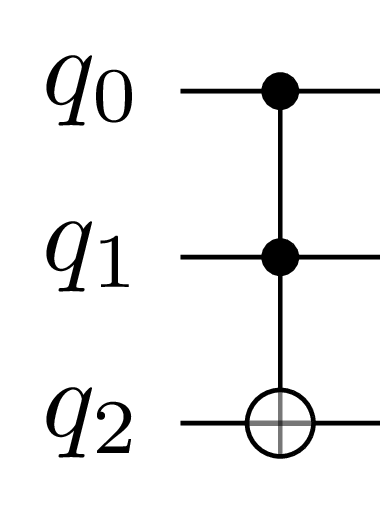
以下代码示例显示了使用 *cuStateVec* 的常用步骤。这里我们应用一个 Toffoli 门,当头两位都为 1 时,它会反转第三位。
#include <cuda_runtime_api.h> // cudaMalloc, cudaMemcpy, etc.
#include <cuComplex.h> // cuDoubleComplex
#include <custatevec.h> // custatevecApplyMatrix
#include <stdio.h> // printf
#include <stdlib.h> // EXIT_FAILURE
int main(void) {
const int nIndexBits = 3;
const int nSvSize = (1 << nIndexBits);
const int nTargets = 1;
const int nControls = 2;
const int adjoint = 0;
int targets[] = {2};
int controls[] = {0, 1};
cuDoubleComplex h_sv[] = {{ 0.0, 0.0}, { 0.0, 0.1}, { 0.1, 0.1},
{ 0.1, 0.2}, { 0.2, 0.2}, { 0.3, 0.3},
{ 0.3, 0.4}, { 0.4, 0.5}};
cuDoubleComplex h_sv_result[] = {{ 0.0, 0.0}, { 0.0, 0.1}, { 0.1, 0.1},
{ 0.4, 0.5}, { 0.2, 0.2}, { 0.3, 0.3},
{ 0.3, 0.4}, { 0.1, 0.2}};
cuDoubleComplex matrix[] = {{0.0, 0.0}, {1.0, 0.0},
{1.0, 0.0}, {0.0, 0.0}};
cuDoubleComplex *d_sv;
cudaMalloc((void**)&d_sv, nSvSize * sizeof(cuDoubleComplex));
cudaMemcpy(d_sv, h_sv, nSvSize * sizeof(cuDoubleComplex),
cudaMemcpyHostToDevice);
//--------------------------------------------------------------------------
// custatevec handle initialization
custatevecHandle_t handle;
custatevecCreate(&handle);
void* extraWorkspace = nullptr;
size_t extraWorkspaceSizeInBytes = 0;
// check the size of external workspace
custatevecApplyMatrixGetWorkspaceSize(
handle, CUDA_C_64F, nIndexBits, matrix, CUDA_C_64F,
CUSTATEVEC_MATRIX_LAYOUT_ROW, adjoint, nTargets, nControls,
CUSTATEVEC_COMPUTE_64F, &extraWorkspaceSizeInBytes);
// allocate external workspace if necessary
if (extraWorkspaceSizeInBytes > 0)
cudaMalloc(&extraWorkspace, extraWorkspaceSizeInBytes);
// apply gate
custatevecApplyMatrix(
handle, d_sv, CUDA_C_64F, nIndexBits, matrix, CUDA_C_64F,
CUSTATEVEC_MATRIX_LAYOUT_ROW, adjoint, targets, nTargets, controls,
nullptr, nControls, CUSTATEVEC_COMPUTE_64F,
extraWorkspace, extraWorkspaceSizeInBytes);
// destroy handle
custatevecDestroy(handle);
//--------------------------------------------------------------------------
cudaMemcpy(h_sv, d_sv, nSvSize * sizeof(cuDoubleComplex),
cudaMemcpyDeviceToHost);
bool correct = true;
for (int i = 0; i < nSvSize; i++) {
if ((h_sv[i].x != h_sv_result[i].x) ||
(h_sv[i].y != h_sv_result[i].y)) {
correct = false;
break;
}
}
if (correct)
printf("example PASSED\n");
else
printf("example FAILED: wrong result\n");
cudaFree(d_sv);
if (extraWorkspaceSizeInBytes)
cudaFree(extraWorkspace);
return EXIT_SUCCESS;
}
更多示例可以在 NVIDIA/cuQuantum 存储库中找到。
实用技巧¶
对于调试,可以设置环境变量
CUSTATEVEC_LOG_LEVEL=n。级别n= 0, 1, …, 5 对应于custatevecLoggerSetLevel()中描述和使用的记录器级别。环境变量CUSTATEVEC_LOG_FILE=<filepath>可用于将日志输出定向到<filepath>而不是 stdout 的自定义文件。