LLRNet:模型训练和测试#
下图描述了使用 Aerial 的无线 ML 设计流程。
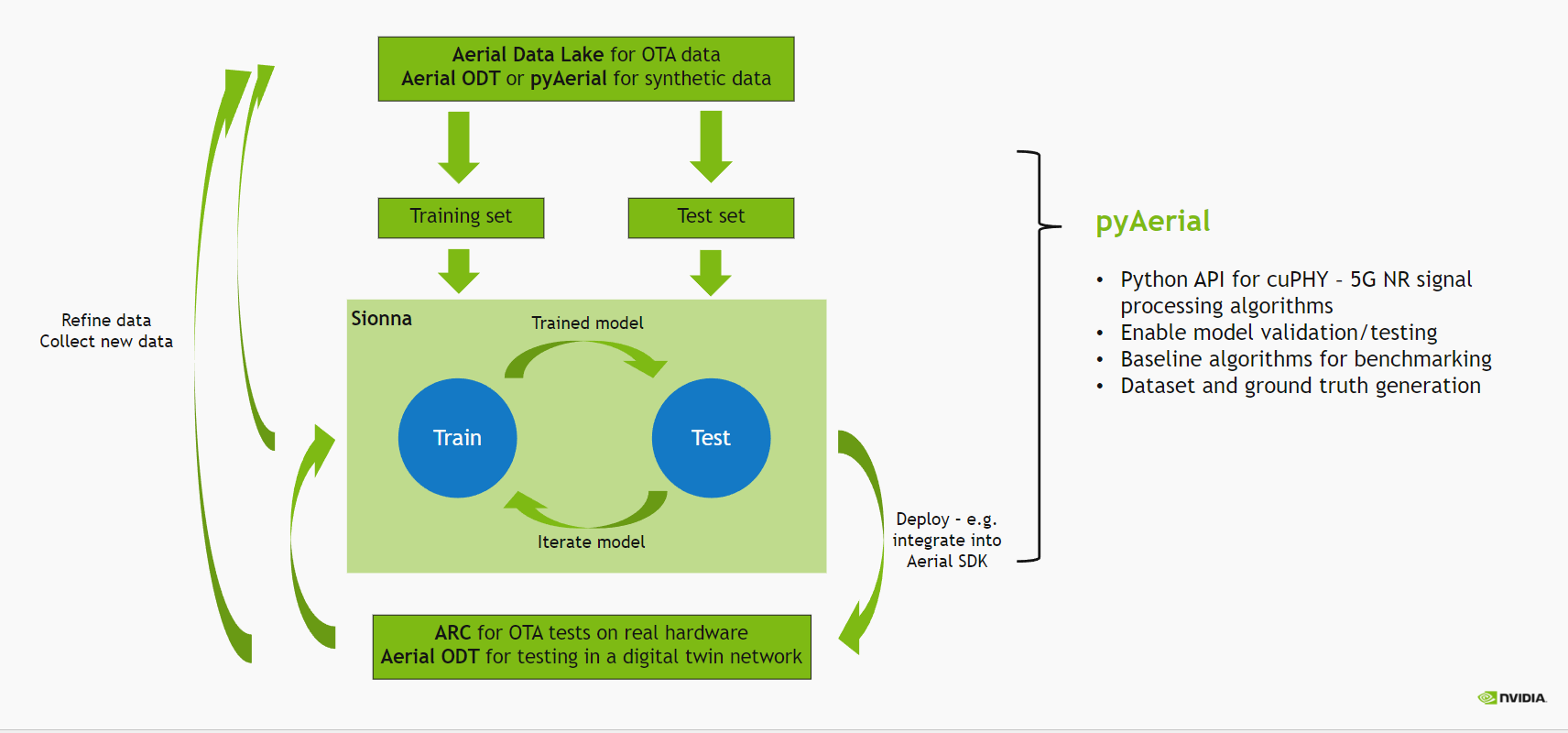
在本笔记本中,我们使用生成的 LLRNet 数据来训练和验证 LLRNet,作为 PUSCH 接收器链的一部分,该接收器链使用 pyAerial 实现,并以 Aerial SDK cuPHY 库作为后端。LLRNet 插入到 PUSCH 接收器链中,取代传统的软解映射器。因此,此笔记本用作使用 pyAerial 进行模型验证的示例。
最后,该模型被导出为 TensorRT 推理引擎所使用的格式,该推理引擎用于将模型集成到 Aerial SDK 中,以便在空中环境中使用真实硬件测试模型。
注 1: 此笔记本需要已生成 Aerial 测试向量。测试向量目录在下面的 AERIAL_TEST_VECTOR_DIR 变量中设置。注 2: 此笔记本还需要首先运行关于 LLRNet 数据集生成的笔记本示例。
[1]:
# Check platform.
import platform
if platform.machine() != 'x86_64':
raise SystemExit("Unsupported platform!")
导入#
[2]:
%matplotlib widget
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
os.environ['TF_CPP_MIN_LOG_LEVEL'] = "3" # Silence TensorFlow.
os.environ["CUDA_MODULE_LOADING"] = "LAZY"
import cuda
import h5py as h5
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import tf2onnx
import onnx
from IPython.display import Markdown
from IPython.display import display
# PyAerial components
from aerial.phy5g.algorithms import ChannelEstimator
from aerial.phy5g.algorithms import ChannelEqualizer
from aerial.phy5g.algorithms import NoiseIntfEstimator
from aerial.phy5g.algorithms import Demapper
from aerial.phy5g.algorithms import TrtEngine
from aerial.phy5g.algorithms import TrtTensorPrms
from aerial.phy5g.ldpc import LdpcDeRateMatch
from aerial.phy5g.ldpc import LdpcDecoder
from aerial.phy5g.ldpc import CrcChecker
from aerial.phy5g.params import PuschConfig
from aerial.phy5g.params import PuschUeConfig
from aerial.util.cuda import get_cuda_stream
from aerial.util.data import load_pickle
from aerial.util.fapi import dmrs_fapi_to_bit_array
# Configure the notebook to use only a single GPU and allocate only as much memory as needed.
# For more details, see https://tensorflowcn.cn/guide/gpu.
gpus = tf.config.list_physical_devices('GPU')
tf.config.experimental.set_memory_growth(gpus[0], True)
[3]:
tb_errors = dict(aerial=dict(), llrnet=dict(), logmap=dict())
tb_count = dict(aerial=dict(), llrnet=dict(), logmap=dict())
[4]:
# Dataset root directory.
DATA_DIR = "data/"
# Aerial test vector directory.
AERIAL_TEST_VECTOR_DIR = "/mnt/cicd_tvs/develop/GPU_test_input/"
# LLRNet dataset directory.
dataset_dir = DATA_DIR + "example_llrnet_dataset/QPSK/"
# LLRNet model target path
llrnet_onnx_file = f"../models/llrnet.onnx"
llrnet_trt_file = f"../models/llrnet.trt"
# Training vs. testing SNR. Assume these exist in the dataset.
train_snr = [-7.75, -7.5, -7.25, -7.0, -6.75, -6.5]
test_snr = [-7.75, -7.5, -7.25, -7.0, -6.75, -6.5]
# Training, validation and test split in percentages if the same SNR is used for
# training and testing.
train_split = 45
val_split = 5
test_split = 50
# Training hyperparameters.
batch_size = 32
epochs = 5
step = tf.Variable(0, trainable=False)
boundaries = [350000, 450000]
values = [5e-4, 1e-4, 1e-5]
# values = [0.05, 0.01, 0.001]
learning_rate_fn = tf.keras.optimizers.schedules.PiecewiseConstantDecay(boundaries, values)
optimizer = tf.keras.optimizers.Adam(learning_rate=learning_rate_fn, weight_decay=1e-4)
# optimizer = tf.keras.optimizers.experimental.SGD(learning_rate=0.05, weight_decay=1e-4, momentum=0.9)
# Modulation order. LLRNet needs to be trained separately for each modulation order.
mod_order = 2
定义 LLRNet 模型#
LLRNet 模型遵循原始论文
Shental, J. Hoydis, “’Machine LLRning’: Learning to Softly Demodulate”, https://arxiv.org/abs/1907.01512
并且是一个非常简单的 MLP 模型,带有一个隐藏层。它以分离的实部和虚部作为输入,并输出可以进一步馈送到 LDPC (解)速率匹配和解码的软比特(对数似然比)。
[5]:
model = keras.Sequential(
[
layers.Dense(16, input_dim=2, activation="relu"),
layers.Dense(8, activation="linear")
]
)
def loss(llr, predictions):
mae = tf.abs(predictions[:, :mod_order] - llr)
mse = tf.reduce_mean(tf.square(mae))
return mse
训练、验证和测试数据集#
在此,数据集被加载并分割成训练、验证和测试数据集,并以正确的格式放入模型中。
[6]:
# Load the main data file
try:
df = pd.read_parquet(dataset_dir + "l2_metadata.parquet", engine="pyarrow")
except FileNotFoundError:
display(Markdown("**Data not found - has llrnet_dataset_generation.ipynb been run?**"))
# Query the entries for the selected modulation order.
df = df[df["qamModOrder"] == mod_order]
# Collect the dataset by SNR.
llrs = dict()
eq_syms = dict()
indices = dict()
for pusch_record in df.itertuples():
user_data_filename = dataset_dir + pusch_record.user_data_filename
user_data = load_pickle(user_data_filename)
if user_data["snr"] not in llrs.keys():
llrs[user_data["snr"]] = []
eq_syms[user_data["snr"]] = []
indices[user_data["snr"]] = []
llrs[user_data["snr"]].append(user_data["map_llrs"])
eq_syms[user_data["snr"]].append(user_data["eq_syms"])
indices[user_data["snr"]].append(pusch_record.Index)
llr_train, llr_val = [], []
sym_train, sym_val = [], []
test_indices = []
for key in llrs.keys():
llrs[key] = np.stack(llrs[key])
eq_syms[key] = np.stack(eq_syms[key])
# Randomize the order.
permutation = np.arange(llrs[key].shape[0])
np.random.shuffle(permutation)
llrs[key] = llrs[key][permutation, ...]
eq_syms[key] = eq_syms[key][permutation, ...]
indices[key] = list(np.array(indices[key])[permutation])
# Separate real and imaginary parts of the symbols.
eq_syms[key] = np.stack((np.real(eq_syms[key]), np.imag(eq_syms[key])))
num_slots = llrs[key].shape[0]
if key in train_snr and key in test_snr:
num_train_slots = int(np.round(train_split / 100 * num_slots))
num_val_slots = int(np.round(val_split / 100 * num_slots))
num_test_slots = int(np.round(test_split / 100 * num_slots))
elif key in train_snr:
num_train_slots = int(np.round(train_split / (train_split + val_split) * num_slots))
num_val_slots = int(np.round(val_split / (train_split + val_split) * num_slots))
num_test_slots = 0
elif key in test_snr:
num_train_slots = 0
num_val_slots = 0
num_test_slots = num_slots
else:
num_train_slots = 0
num_val_slots = 0
num_test_slots = 0
# Collect training/validation/testing sets.
llr_train.append(llrs[key][:num_train_slots, ...])
llr_val.append(llrs[key][num_train_slots:num_train_slots+num_val_slots, ...])
sym_train.append(eq_syms[key][:, :num_train_slots, ...])
sym_val.append(eq_syms[key][:, num_train_slots:num_train_slots+num_val_slots, ...])
# Just indices for the test set.
test_indices += indices[key][num_train_slots+num_val_slots:num_train_slots+num_val_slots+num_test_slots]
llr_train = np.transpose(np.concatenate(llr_train, axis=0), (1, 0, 2))
llr_val = np.transpose(np.concatenate(llr_val, axis=0), (1, 0, 2))
sym_train = np.concatenate(sym_train, axis=1)
sym_val = np.concatenate(sym_val, axis=1)
# Fetch the total number of slots in each set.
num_train_slots = llr_train.shape[1]
num_val_slots = llr_val.shape[1]
num_test_slots = len(test_indices)
normalizer = 1.0 #np.sqrt(np.var(llr_train))
llr_train = llr_train / normalizer
llr_val = llr_val / normalizer
# Reshape into samples x mod_order array.
llr_train = llr_train.reshape(mod_order, -1).T
llr_val = llr_val.reshape(mod_order, -1).T
# Reshape into samples x 2 array.
sym_train = sym_train.reshape(2, -1).T
sym_val = sym_val.reshape(2, -1).T
print(f"Total number of slots in the training set: {num_train_slots}")
print(f"Total number of slots in the validation set: {num_val_slots}")
print(f"Total number of slots in the test set: {num_test_slots}")
Total number of slots in the training set: 5400
Total number of slots in the validation set: 600
Total number of slots in the test set: 6000
模型训练和验证#
模型训练在此处使用 Keras 完成。
[7]:
print("Training...")
model.compile(loss=loss, optimizer=optimizer, metrics=[loss])
model.fit(
x=sym_train,
y=llr_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_data=(sym_val, llr_val),
shuffle=True
)
Training...
Epoch 1/5
WARNING: All log messages before absl::InitializeLog() is called are written to STDERR
I0000 00:00:1728635635.827841 20098 device_compiler.h:186] Compiled cluster using XLA! This line is logged at most once for the lifetime of the process.
552825/552825 [==============================] - 790s 1ms/step - loss: 32.6663 - val_loss: 32.3584
Epoch 2/5
552825/552825 [==============================] - 794s 1ms/step - loss: 32.5126 - val_loss: 32.3580
Epoch 3/5
552825/552825 [==============================] - 791s 1ms/step - loss: 32.5123 - val_loss: 32.3583
Epoch 4/5
552825/552825 [==============================] - 792s 1ms/step - loss: 32.5125 - val_loss: 32.3583
Epoch 5/5
552825/552825 [==============================] - 788s 1ms/step - loss: 32.5124 - val_loss: 32.3582
[7]:
<keras.src.callbacks.History at 0x7f03d83de4d0>
导出到 TensorRT#
最后,模型被导出为 ONNX 格式。ONNX 格式需要转换为 TRT 引擎格式才能被 TensorRT 推理引擎使用,这在此处使用命令行工具 trtexec 完成。
[8]:
input_signature = [tf.TensorSpec([None, 2], tf.float32, name="input")]
onnx_model, _ = tf2onnx.convert.from_keras(model, input_signature)
onnx.save(onnx_model, llrnet_onnx_file)
print("ONNX model created. Converting to TRT engine file...")
command = f"trtexec " + \
f"--onnx={llrnet_onnx_file} " + \
f"--saveEngine={llrnet_trt_file} " + \
f"--skipInference " + \
f"--minShapes=input:1x2 " + \
f"--optShapes=input:42588x2 " + \
f"--maxShapes=input:85176x2 " + \
f"--inputIOFormats=fp32:chw " + \
f"--outputIOFormats=fp32:chw" + \
f"> /dev/null"
return_val = os.system(command)
if return_val == 0:
print("TRT engine model created.")
else:
raise SystemExit("Failed to create the TRT engine file!")
ONNX model created. Converting to TRT engine file...
TRT engine model created.
使用 pyAerial 定义 PUSCH 接收器链#
此类封装了整个 PUSCH 接收器链。组件包括信道估计、噪声和干扰估计、信道均衡和软解映射、LDPC (解)速率匹配和 LDPC 解码。接收器输出以字节为单位的接收传输块。
软解映射部分可以被 LLRNet 替换。
[9]:
class Receiver:
"""PUSCH receiver class.
This class encapsulates the whole PUSCH receiver chain built using
pyAerial components.
"""
def __init__(self,
llrnet_model_file,
num_rx_ant,
enable_pusch_tdi,
eq_coeff_algo):
"""Initialize the PUSCH receiver."""
self.cuda_stream = get_cuda_stream()
# Build the components of the receiver.
self.channel_estimator = ChannelEstimator(
num_rx_ant=num_rx_ant,
cuda_stream=self.cuda_stream
)
self.channel_equalizer = ChannelEqualizer(
num_rx_ant=num_rx_ant,
enable_pusch_tdi=enable_pusch_tdi,
eq_coeff_algo=eq_coeff_algo,
cuda_stream=self.cuda_stream
)
self.noise_intf_estimator = NoiseIntfEstimator(
num_rx_ant=num_rx_ant,
eq_coeff_algo=eq_coeff_algo,
cuda_stream=self.cuda_stream
)
self.demapper = Demapper(mod_order=mod_order)
self.trt_engine = TrtEngine(
llrnet_model_file,
max_batch_size=85176,
input_tensors=[TrtTensorPrms('input', (2,), np.float32)],
output_tensors=[TrtTensorPrms('dense_1', (8,), np.float32)]
)
self.derate_match = LdpcDeRateMatch(
enable_scrambling=True,
cuda_stream=self.cuda_stream
)
self.decoder = LdpcDecoder(cuda_stream=self.cuda_stream)
self.crc_checker = CrcChecker(cuda_stream=self.cuda_stream)
self.llr_method = "llrnet"
def set_llr_method(self, method):
"""Set the used LLR computation method.
Args:
method (str): Either "aerial" meaning the conventional log-likelihood
ratio computation, or "llrnet" for using LLRNet instead.
"""
if method not in ["aerial", "logmap", "llrnet"]:
raise ValueError("Invalid LLR computation method!")
self.llr_method = method
def run(
self,
rx_slot,
slot,
pusch_configs):
"""Run the receiver."""
# Channel estimation.
ch_est = self.channel_estimator.estimate(
rx_slot=rx_slot,
slot=slot,
pusch_configs=pusch_configs
)
# Noise and interference estimation.
lw_inv, noise_var_pre_eq = self.noise_intf_estimator.estimate(
rx_slot=rx_slot,
channel_est=ch_est,
slot=slot,
pusch_configs=pusch_configs
)
# Channel equalization and soft demapping. Note that the cuPHY kernel actually computes both
# the equalized symbols and the LLRs.
llr, eq_sym = self.channel_equalizer.equalize(
rx_slot=rx_slot,
channel_est=ch_est,
lw_inv=lw_inv,
noise_var_pre_eq=noise_var_pre_eq,
pusch_configs=pusch_configs
)
# Use the LLRNet model here to get the log-likelihood ratios.
dmrs_syms = pusch_configs[0].dmrs_syms
start_sym = pusch_configs[0].start_sym
num_symbols = pusch_configs[0].num_symbols
num_prbs = pusch_configs[0].num_prbs
mod_order = pusch_configs[0].ue_configs[0].mod_order
layers = pusch_configs[0].ue_configs[0].layers
num_data_sym = (np.array(dmrs_syms[start_sym:start_sym + num_symbols]) == 0).sum()
if self.llr_method == "llrnet":
# Put the input in the right format.
eq_sym_input = np.stack((np.real(eq_sym[0]), np.imag(eq_sym[0]))).reshape(2, -1).T
# Run the model.
llr_output = self.trt_engine.run({"input": eq_sym_input})["dense_1"]
# Reshape the output in the right format for the LDPC decoding process.
llr_output = np.array(llr_output)[..., :mod_order].T.reshape(mod_order, layers, num_prbs * 12, num_data_sym)
llr_output *= normalizer
elif self.llr_method == "aerial":
llr_output = llr[0]
elif self.llr_method == "logmap":
inv_noise_var_lin = self.channel_equalizer.ree_diag_inv[0]
inv_noise_var_lin = np.transpose(inv_noise_var_lin[..., 0], (1, 2, 0)).reshape(inv_noise_var_lin.shape[1], -1)
llr_output = self.demapper.demap(eq_sym[0], inv_noise_var_lin[..., None])
# De-rate matching and descrambling.
coded_blocks = self.derate_match.derate_match(
input_llrs=[llr_output],
pusch_configs=pusch_configs
)
# LDPC decoding of the derate matched blocks.
code_blocks = self.decoder.decode(
input_llrs=coded_blocks,
pusch_configs=pusch_configs
)
# Combine the code blocks into a transport block.
tb, _ = self.crc_checker.check_crc(
input_bits=code_blocks,
pusch_configs=pusch_configs
)
return tb[0]
在 Aerial 测试向量上进行模型测试#
[10]:
if mod_order == 2:
test_vector_filename = "TVnr_7201_PUSCH_gNB_CUPHY_s0p0.h5"
elif mod_order == 4:
test_vector_filename = "TVnr_7916_PUSCH_gNB_CUPHY_s0p0.h5"
elif mod_order == 6:
test_vector_filename = "TVnr_7203_PUSCH_gNB_CUPHY_s0p0.h5"
filename = AERIAL_TEST_VECTOR_DIR + test_vector_filename
input_file = h5.File(filename, "r")
num_rx_ant = input_file["gnb_pars"]["nRx"][0]
enable_pusch_tdi = input_file["gnb_pars"]["TdiMode"][0]
eq_coeff_algo = input_file["gnb_pars"]["eqCoeffAlgoIdx"][0]
receiver = Receiver(
llrnet_trt_file,
num_rx_ant=num_rx_ant,
enable_pusch_tdi=enable_pusch_tdi,
eq_coeff_algo=eq_coeff_algo
)
# Extract the test vector data and parameters.
rx_slot = np.array(input_file["DataRx"])["re"] + 1j * np.array(input_file["DataRx"])["im"]
rx_slot = rx_slot.transpose(2, 1, 0)
slot = np.array(input_file["gnb_pars"]["slotNumber"])[0]
# Wrap the parameters in a PuschConfig structure.
pusch_ue_config = PuschUeConfig(
scid=input_file["tb_pars"]["nSCID"][0],
layers=input_file["tb_pars"]["numLayers"][0],
dmrs_ports=input_file["tb_pars"]["dmrsPortBmsk"][0],
rnti=input_file["tb_pars"]["nRnti"][0],
data_scid=input_file["tb_pars"]["dataScramId"][0],
mcs_table=input_file["tb_pars"]["mcsTableIndex"][0],
mcs_index=input_file["tb_pars"]["mcsIndex"][0],
code_rate=input_file["tb_pars"]["targetCodeRate"][0],
mod_order=input_file["tb_pars"]["qamModOrder"][0],
tb_size=input_file["tb_pars"]["nTbByte"][0],
rv=input_file["tb_pars"]["rv"][0],
ndi=input_file["tb_pars"]["ndi"][0]
)
# Note that this is a list. One UE group only in this case.
pusch_configs = [PuschConfig(
ue_configs=[pusch_ue_config],
num_dmrs_cdm_grps_no_data=input_file["tb_pars"]["numDmrsCdmGrpsNoData"][0],
dmrs_scrm_id=input_file["tb_pars"]["dmrsScramId"][0],
start_prb=input_file["ueGrp_pars"]["startPrb"][0],
num_prbs=input_file["ueGrp_pars"]["nPrb"][0],
dmrs_syms=dmrs_fapi_to_bit_array(input_file["ueGrp_pars"]["dmrsSymLocBmsk"][0]),
dmrs_max_len=input_file["tb_pars"]["dmrsMaxLength"][0],
dmrs_add_ln_pos=input_file["tb_pars"]["dmrsAddlPosition"][0],
start_sym=input_file["ueGrp_pars"]["StartSymbolIndex"][0],
num_symbols=input_file["ueGrp_pars"]["NrOfSymbols"][0]
)]
# Run the receiver with the test vector parameters.
receiver.set_llr_method("llrnet")
tb = receiver.run(
rx_slot=rx_slot,
slot=slot,
pusch_configs=pusch_configs
)
# Check that the received TB matches with the transmitted one.
tb_size = pusch_configs[0].ue_configs[0].tb_size
if np.array_equal(np.array(input_file["tb_data"])[:tb_size, 0], tb[:tb_size]):
print("CRC check passed!")
else:
print("CRC check failed!")
CRC check passed!
在合成/模拟数据上进行模型测试#
[11]:
for pusch_record in df.take(test_indices).itertuples(index=False):
user_data_filename = dataset_dir + pusch_record.user_data_filename
user_data = load_pickle(user_data_filename)
snr = user_data["snr"]
rx_iq_data_filename = dataset_dir + pusch_record.rx_iq_data_filename
rx_slot = load_pickle(rx_iq_data_filename)
ref_tb = pusch_record.macPdu
tb_size = len(pusch_record.macPdu)
slot = pusch_record.Slot
# Wrap the parameters in a PuschConfig structure.
pusch_ue_config = PuschUeConfig(
scid=pusch_record.SCID,
layers=pusch_record.nrOfLayers,
dmrs_ports=pusch_record.dmrsPorts,
rnti=pusch_record.RNTI,
data_scid=pusch_record.dataScramblingId,
mcs_table=pusch_record.mcsTable,
mcs_index=pusch_record.mcsIndex,
code_rate=pusch_record.targetCodeRate,
mod_order=pusch_record.qamModOrder,
tb_size=tb_size
)
# Note that this is a list. One UE group only in this case.
pusch_configs = [PuschConfig(
ue_configs=[pusch_ue_config],
num_dmrs_cdm_grps_no_data=pusch_record.numDmrsCdmGrpsNoData,
dmrs_scrm_id=pusch_record.ulDmrsScramblingId,
start_prb=pusch_record.rbStart,
num_prbs=pusch_record.rbSize,
dmrs_syms=dmrs_fapi_to_bit_array(pusch_record.ulDmrsSymbPos),
dmrs_max_len=1,
dmrs_add_ln_pos=1,
start_sym=pusch_record.StartSymbolIndex,
num_symbols=pusch_record.NrOfSymbols
)]
for llr_method in ["aerial", "llrnet", "logmap"]:
if snr not in tb_errors[llr_method].keys():
tb_errors[llr_method][snr] = 0
tb_count[llr_method][snr] = 0
receiver.set_llr_method(llr_method)
tb = receiver.run(
rx_slot=rx_slot,
slot=slot,
pusch_configs=pusch_configs
)
tb_count[llr_method][snr] += 1
tb_errors[llr_method][snr] += (not np.array_equal(tb[:tb_size], ref_tb[:tb_size]))
[12]:
esno_dbs = tb_count["aerial"].keys()
bler = dict(aerial=[], llrnet=[], logmap=[])
for esno_db in esno_dbs:
bler["aerial"].append(tb_errors["aerial"][esno_db] / tb_count["aerial"][esno_db])
bler["llrnet"].append(tb_errors["llrnet"][esno_db] / tb_count["llrnet"][esno_db])
bler["logmap"].append(tb_errors["logmap"][esno_db] / tb_count["logmap"][esno_db])
[13]:
esno_dbs = np.array(list(esno_dbs))
fig = plt.figure(figsize=(10, 10))
plt.yscale('log')
plt.ylim(0.01, 1)
plt.xlim(np.min(esno_dbs), np.max(esno_dbs))
plt.title("BLER Performance vs. Es/No")
plt.ylabel("BLER")
plt.xlabel("Es/No [dB]")
plt.grid()
plt.plot(esno_dbs, bler["aerial"], marker="d", linestyle="-", color="blue", markersize=8)
plt.plot(esno_dbs, bler["llrnet"], marker="s", linestyle="-", color="black", markersize=8)
plt.plot(esno_dbs, bler["logmap"], marker="o", linestyle="-", color="red", markersize=8)
plt.legend(["Aerial", "LLRNet", "Log-MAP"])
[13]:
<matplotlib.legend.Legend at 0x7f02ac7bc760>