Aerial cuMAC#
Aerial cuMAC 是一个基于 CUDA 的平台,用于加速 NVIDIA GPU 的 5G/6G MAC 层调度器功能。cuMAC 支持的调度器功能包括 UE 选择/分组、PRB 分配、层选择、MCS 选择/链路自适应和动态波束成形,所有这些功能都旨在用于多个协同小区的联合调度。cuMAC 提供了一个基于 C/C++ 的 API,用于将 DU 中 L2 堆栈的调度器功能卸载到 GPU。未来,cuMAC 将发展成为一个平台,将基于 AI/ML 的调度器增强功能与 GPU 加速相结合。
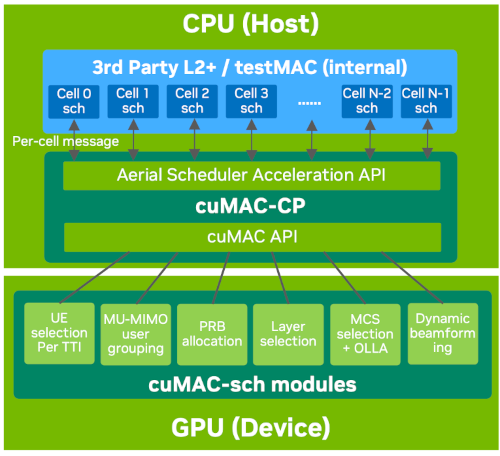
Aerial L2 调度器加速数据流程图#
cuMAC 是 Aerial L2 调度器加速解决方案的主要组件。上图说明了调度器加速的整体数据流程。完整的解决方案包括以下组件:1) Aerial 调度器加速 API,它是 DU/CU 上第三方 L2 堆栈和 cuMAC-CP 之间基于每小区消息传递的接口;2) cuMAC-CP;3) 基于小区组的 cuMAC API;以及 4) cuMAC 多小区调度器 (cuMAC-sch) 模块。
第三方 L2 堆栈位于 CPU 上,并包含一个单小区 L2 调度器,用于控制下的每个小区。为了将 L2 调度卸载到 GPU 以实现加速/性能目的,在每个时隙 (TTI) 中,L2 堆栈主机通过 Aerial 调度器加速 API 向 cuMAC-CP 发送每小区请求消息,其中包含来自每个单小区调度器所需的调度输入和配置信息。接收到每小区请求消息后,cuMAC-CP 将来自这些(协同)小区的所有调度器输入信息集成到 cuMAC API 小区组数据结构中,并填充这些结构中包含的 GPU 数据缓冲区。接下来,cuMAC-CP 通过 cuMAC API 调用 cuMAC 多小区调度器 (cuMAC-sch) 模块,以计算给定时间隙 (TTI) 的调度解决方案。在 cuMAC-sch 模块完成计算并且调度解决方案在 GPU 内存中可用后,cuMAC-CP 将其转换为每小区响应消息,并通过 Aerial 调度器加速 API 将其发送回 CPU 上的 L2 堆栈主机。最后,L2 堆栈主机使用获得的解决方案来调度其控制下的小区。
当有多个协同小区组时,应为每个小区组构建和维护一套独立的 Aerial 调度器加速 API、cuMAC-CP、cuMAC API 和 cuMAC 实例。
实现细节
多小区调度 - 所有 cuMAC 调度算法都实现为 CUDA 内核,这些内核由 GPU 执行,并同时为一组小区联合计算调度解决方案(PRB 分配、MCS 选择、层选择等)。通过在小区组中配置单个小区,可以将算法限制为单小区调度。下图给出了单小区调度器和多小区调度器方法的比较。
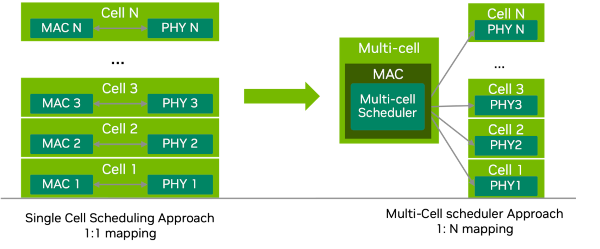
单小区调度器方法 vs. 多小区调度器方法#
调度算法 CUDA 实现
PF UE 下行选择算法 - cuMAC 提供了一种基于 PF 的 UE 选择算法,用于在每个 TTI 中从小区组中每个小区的所有活动 UE 池中下行选择一部分 UE 进行新传输或 HARQ 重传。小区组中 UE 和小区的关联是 UE 选择模块的输入。在每个 TTI 中为每个小区选择 UE 时,UE 选择算法首先为小区中的每个活动 UE 分配一个优先级权重,然后按优先级权重降序对所有活动 UE 进行排序。在每个小区中具有最高优先级权重的一部分 UE 被选择用于在 TTI 中进行调度。每个小区选择的 UE 数量是此模块的输入参数。HARQ 重传始终被分配最高的优先级权重。对于新传输 UE,其优先级权重是 PF 指标,计算为每个 UE 的长期平均吞吐量与其瞬时可实现数据速率的比率。UE 选择算法实现为在 GPU 上运行的 CUDA 内核,并同时为小区组中的所有小区联合选择 UE。
PF PRB 分配算法 - cuMAC 提供了算法,用于在每个 TTI 的基础上,在一组小区及其连接的活动 UE 之间执行信道感知和频率选择性 PRB 分配。PRB 分配算法的输入参数包括每小区-UE 链路的窄带 SRS 信道估计(MIMO 信道矩阵)、小区与 UE 之间的关联解决方案以及其他 UE 状态和小区组参数。输出是小区组的 PRB 分配解决方案,其数据格式取决于分配类型:1) 对于 type-0 分配,每个 UE 的二进制位图指示每个 PRB 是否分配给该 UE;2) 对于 type-1 分配,每个 UE 有 2 个元素,指示 UE 分配的起始和结束 PRB 索引。提供了两个版本的 PRB 分配算法,一个用于单小区调度,另一个用于多小区联合调度。两个版本之间的主要区别在于,多小区算法在评估每 PRB SINR 时考虑了小区间干扰的影响,这可以从窄带 SRS 信道估计中导出。单小区版本没有显式考虑小区间干扰,仅利用限制于每个小区的信息。多小区算法可以通过利用来自协同多个小区的所有可用信息,在小区组中实现全局优化的资源分配。下图提供了 PRB 分配算法的原型 CUDA 内核实现。
层选择算法 - cuMAC 提供了层选择算法,这些算法基于 UE 多个层上的奇异值分布,为 UE 选择用于传输的最佳层集。使用预定的奇异值阈值来查找每个子带(PRB 组)上可以支持的层数(具有降序奇异值)。然后,选择分配给 UE 的所有子带中的最小层数作为最佳层选择解决方案。层选择算法的输入参数包括每 UE 的 PRB 分配解决方案、每个 UE 的信道在其分配的子带上的奇异值、小区和 UE 之间的关联解决方案以及其他 UE 状态和小区组参数。输出是每 UE 的层选择解决方案。层选择算法实现为在 GPU 上运行的 CUDA 内核,并同时为小区组中的所有 UE 联合选择层。
MCS 选择算法 - cuMAC 提供了 MCS 选择算法,这些算法基于给定的 PRB 分配解决方案,为每个 UE 选择最佳可行的 MCS(可以满足给定 BLER 目标的最高级别)。外环链路自适应算法在内部集成到 MCS 选择算法中,该算法根据每个 UE 链路的先前传输块解码结果偏移 SINR 估计。MCS 选择算法的输入参数包括每 UE 的 PRB 分配解决方案、每小区-UE 链路的窄带 SRS 信道估计(MIMO 信道矩阵)、小区和 UE 之间的关联解决方案、每个 UE 的最后一个传输块的解码结果以及其他 UE 状态和小区组参数。输出是每 UE 的 MCS 选择解决方案。MCS 选择算法实现为在 GPU 上运行的 CUDA 内核,并同时为小区组中的所有 UE 联合选择 MCS。
HARQ 支持 - 以上所有 cuMAC 调度器算法都可以支持具有非自适应模式的 HARQ 重传,即为重传重用初始传输的相同调度解决方案。
CPU 参考代码 - 还提供了上述算法的 CPU C++ 实现,用于验证和性能评估。
不同的 CSI 类型 - cuMAC 提供了调度器算法 CUDA 内核,用于处理不同的 CSI 类型,包括 SRS 信道系数估计和基于 CSI-RS 的信道质量信息。
FP32 和 FP16 支持 - cuMAC 提供了以 FP32 和 FP16 实现的调度器算法 CUDA 内核。使用 FP16 内核可以帮助减少调度器延迟,同时性能损失较小。
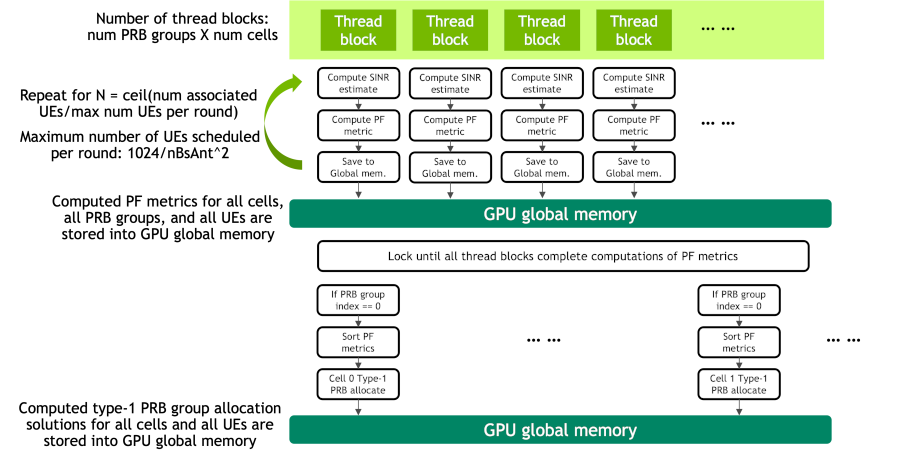
PRB 分配算法的原型 CUDA 内核实现#