NVIPC 概述#
本节概述 NVIPC 消息传递功能。
NVIPC 消息传输#
为了实现低延迟和高性能,NVIPC 使用无锁内存池和无锁队列来传递消息。消息传输模块架构如下所示。
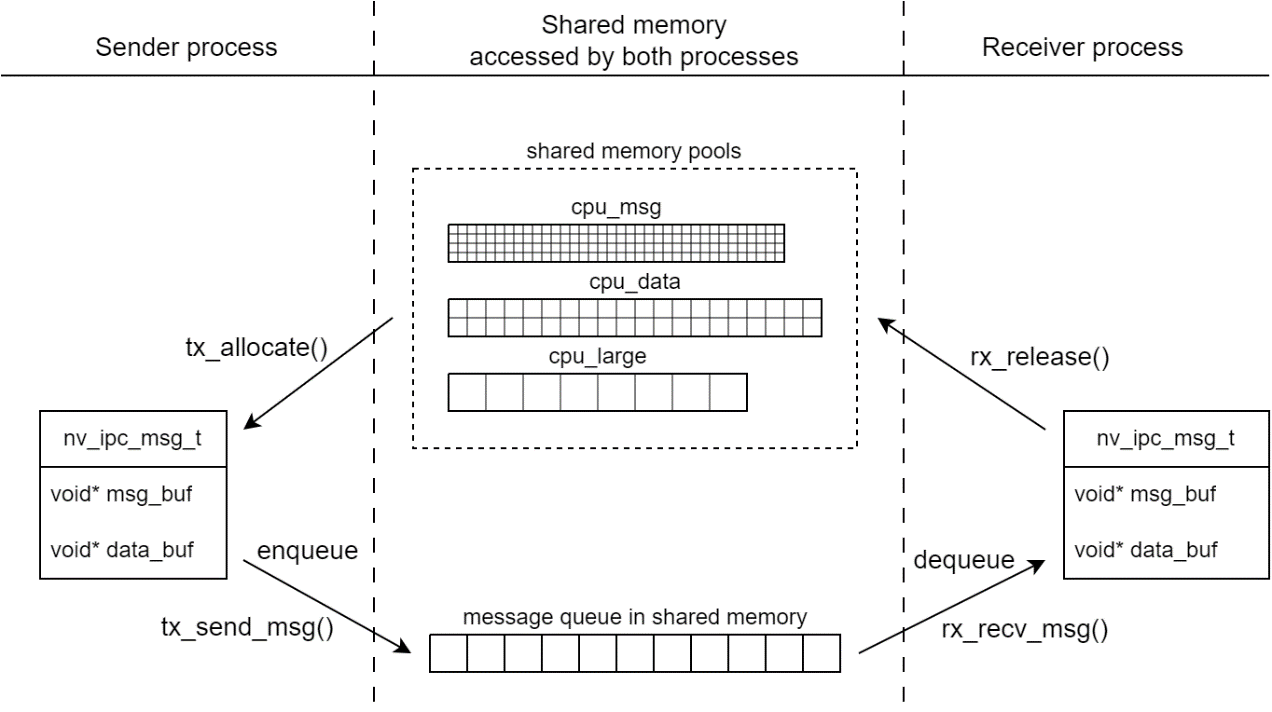
NVIPC API 定义#
NVIPC 消息分为两部分
MSG:在 CPU 线程中运行的控制逻辑中处理。
DATA:使用在 CPU 线程或 GPU 上下文中运行的高性能计算处理。
结构体 nv_ipc_msg_t 被定义为表示通用的 NVIPC 消息,如下所示。
typedef struct
{
int32_t msg_id; // IPC message ID
int32_t cell_id; // Cell ID
int32_t msg_len; // MSG part length
int32_t data_len; // DATA part length
int32_t data_pool; // DATA memory pool ID
void\* msg_buf; // MSG buffer pointer
void\* data_buf; // MSG buffer pointer
} nv_ipc_msg_t;
MSG 部分和 DATA 部分存储在不同的缓冲区中。MSG 部分是强制性的,DATA 部分是可选的。当没有 DATA 部分时,data_buf 为空。
NVIPC 在初始化时创建多个内存池,以管理 MSG 部分和 DATA 部分缓冲区。枚举类型 nv_ipc_mempool_id_t 被定义为内存池指示符。MSG 缓冲区从 CPU 共享内存池分配。DATA 缓冲区可以从 CPU 共享内存池或 CUDA 共享内存池分配。
typedef enum
{
NV_IPC_MEMPOOL_CPU_MSG = 0, // CPU SHM pool for MSG part
NV_IPC_MEMPOOL_CPU_DATA = 1, // CPU SHM pool for DATA part
NV_IPC_MEMPOOL_CPU_LARGE = 2, // CPU SHM pool for large DATA part
NV_IPC_MEMPOOL_CUDA_DATA = 3, // CUDA SHM pool for DATA part
NV_IPC_MEMPOOL_GPU_DATA = 4, // CUDA SHM pool which supports GDR copy
NV_IPC_MEMPOOL_NUM = 5
} nv_ipc_mempool_id_t;
并且在结构体中定义了一系列 API
struct nv_ipc_t
{
// De-initiate and destroy the nv_ipc_t instance
int (\*ipc_destroy)(nv_ipc_t\* ipc);
// Memory allocate/release for TX side
int (\*tx_allocate)(nv_ipc_t\* ipc, nv_ipc_msg_t\* msg, uint32_t options);
int (\*tx_release)(nv_ipc_t\* ipc, nv_ipc_msg_t\* msg);
// Memory allocate/release for RX side
int (\*rx_allocate)(nv_ipc_t\* ipc, nv_ipc_msg_t\* msg, uint32_t options);
int (\*rx_release)(nv_ipc_t\* ipc, nv_ipc_msg_t\* msg);
// Send a ipc_msg_t message. Return -1 if failed
int (\*tx_send_msg)(nv_ipc_t\* ipc, nv_ipc_msg_t\* msg);
// Call tx_tti_sem_post() at the end of a TTI
int (\*tx_tti_sem_post)(nv_ipc_t\* ipc);
// Call rx_tti_sem_wait() and then receive all messages in a TTI
int (\*rx_tti_sem_wait)(nv_ipc_t\* ipc);
// Get a ipc_msg_t message. Return -1 if no available.
int (\*rx_recv_msg)(nv_ipc_t\* ipc, nv_ipc_msg_t\* msg);
// Get SHM event FD or UDP socket FD for epoll
int (\*get_fd)(nv_ipc_t\* ipc);
// Write tx_fd to notify the event, Only need for SHM
int (\*notify)(nv_ipc_t\* ipc, int value);
// Read rx_fd to clear the event. Only need for SHM
int (\*get_value)(nv_ipc_t\* ipc);
// More not used
};
无锁数据结构#
NVIPC 中实现了一个名为“数组队列”的无锁队列。数组队列具有以下特性
FIFO(先进先出)。
无锁:支持无锁的多生产者和多消费者。
有限大小:最大长度在初始化时定义:N。
有效值是整数:
0、 1、 …、 N-1,可以用作节点索引/指针。不支持重复值。
基于无锁数组队列,实现了通用内存池和环形队列,它们也是无锁的
内存池:数组队列 + 内存缓冲区数组
FIFO 环形队列:数组队列 + 元素节点数组
NVIPC 内存池#
NVIPC 中实现了几个共享内存池。主进程和辅助进程都可以访问它们。每个内存池都是固定大小缓冲区的数组。缓冲区大小和池长度(缓冲区计数)可通过 yaml 文件配置。如果缓冲区大小或池长度配置为 0,则不会创建该内存池。以下是 cuPHY-CP 中使用的默认 NVIPC 内存池配置。
内存池 ID |
在 |
注释 |
|---|---|---|
|
|
用于传输 MSG 部分的 CPU 内存。 |
|
|
用于传输 DATA 部分的 CPU 内存。 |
|
|
用于传输大型 DATA 部分的 CPU 内存。 |
|
|
GPU 内存。未使用。 |
|
|
具有 GDR 复制的 GPU 内存。未使用。 |
在 NVIPC 主应用程序初始化后,SHM 文件将出现在 /dev/shm/ 文件夹中。
双向消息队列#
将创建两个环形队列来传递消息缓冲区索引。发送器应用程序中的 TX 环和接收器应用程序中的 RX 环是系统中共享内存中的同一个环。DL 和 UL 环形队列都存储在同一个共享内存文件中。
在 |
内部代码名称 |
IPC 方向 |
PHY /主 |
MAC /辅助 |
|---|---|---|---|---|
|
|
上行链路 |
TX |
RX |
|
|
下行链路 |
RX |
TX |
NVIPC 消息通知#
NVIPC 使用 Linux event_fd 进行通知。它支持使用 select /poll/epoll 机制的多个 I/O。消息通知模块架构如下所示。
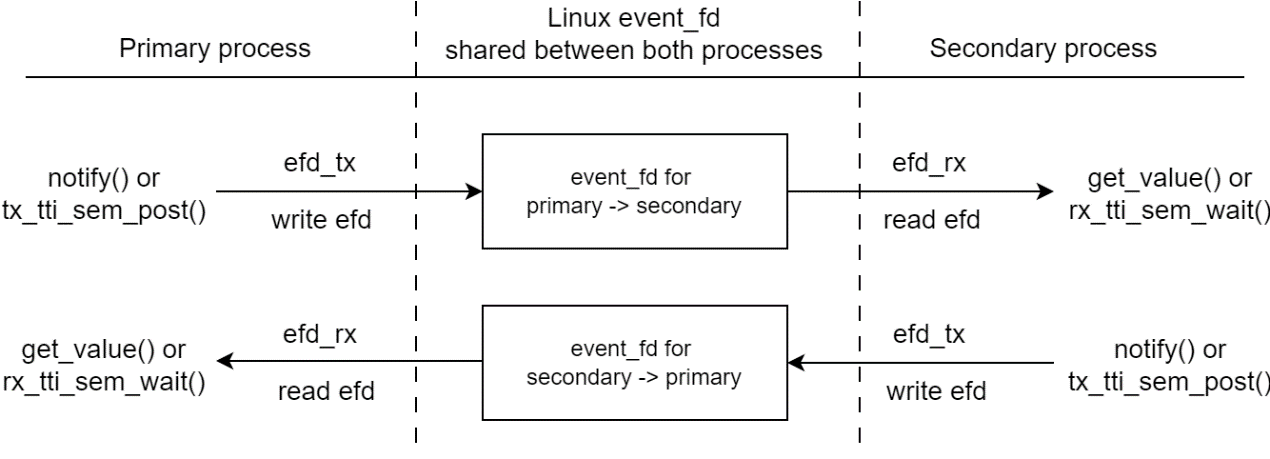
每个进程创建 一个 event_fd 文件描述符 efd_rx 用于传入消息通知,并将其与对等进程共享。本地 efd_rx 用于接收,在对等端共享为 efd_tx ``用于发送 。接收器进程可以调用 ``get_fd() 来获取 I/O 描述符,并使用 poll/epoll 获取通知。此外,event_fd 使用 EFD_SEMAPHORE 标志初始化,因此它可以像信号量一样工作。NVIPC 提供事件/选择样式和信号量样式通知 API。
NVIPC 消息流#
典型的消息传输流程如下所示。

由于内存池和环形队列支持无锁并发,因此通知 API 的使用不是强制性的。如果用户不想使用通知,接收器应通过持续从无锁队列中出队来轮询传入的消息队列。rx_recv_msg() 函数在队列为空时返回 -1。