运行 Aerial cuPHY#
Aerial cuPHY 提供 cuPHY 库和几个链接到该库的示例。这里我们包括关于使用 MATLAB 生成 TV 的说明。请参阅 生成 TV 和启动模式文件 以了解如何使用 Aerial Python mcore 模块生成 TV。
构建 Aerial cuPHY#
先决条件#
以下说明假定系统配置和 Aerial cuBB 安装已完成。如果未完成,请参阅 cuBB 安装指南 以完成安装或升级过程。
打开系统电源后,使用以下命令验证 GPU 和 NIC 是否处于正确状态
# Verify GPU is detected and CUDA driver version matches the release manifest.
$ nvidia-smi
验证主机上的 NIC 是否处于正确状态(仅在运行 cuBB 端到端时需要)
# Verify NIC is detected: Example CX6-DX
$ sudo lshw -c network -businfo
Bus info Device Class Description
=======================================================
pci@0000:05:00.0 eno1 network I210 Gigabit Network Connection
pci@0000:06:00.0 enp6s0 network I210 Gigabit Network Connection
pci@0000:b5:00.0 ens6f0 network MT2892 Family [ConnectX-6 Dx]
pci@0000:b5:00.1 ens6f1 network MT2892 Family [ConnectX-6 Dx]
# Verify the link state is right. Assuming NIC port 0 is connected.
$ sudo mlxlink -d b5:00.0
Operational Info
----------------
State : Active
Physical state : LinkUp
Speed : 100G
Width : 4x
FEC : Standard RS-FEC - RS(528,514)
Loopback Mode : No Loopback
Auto Negotiation : ON
Supported Info
--------------
Enabled Link Speed (Ext.) : 0x000007f2 (100G_2X,100G_4X,50G_1X,50G_2X,40G,25G,10G,1G)
Supported Cable Speed (Ext.) : 0x000002f2 (100G_4X,50G_2X,40G,25G,10G,1G)
Troubleshooting Info
--------------------
Status Opcode : 0
Group Opcode : N/A
Recommendation : No issue was observed.
设置主机环境#
按照您使用的服务器类型的 cuBB 安装指南设置环境。
启动 cuBB 容器#
使用以下命令启动 cuBB 容器
$ sudo docker exec -it cuBB /bin/bash
在容器中构建 Aerial cuPHY#
在 cuBB 容器中使用以下命令构建 cuPHY
$ cd /opt/nvidia/cuBB/cuPHY
$ cmake -Bbuild -GNinja -DCMAKE_TOOLCHAIN_FILE=cmake/toolchains/native -DCMAKE_INSTALL_PREFIX=./install
$ cmake --build build
默认情况下,cuPHY 在 Release 模式下构建。选项 BUILD_DOCS=ON 也默认启用,以允许 make 为 cuPHY 库 API 生成 Doxygen 文档。要禁用此选项,请将 -DBUILD_DOCS=OFF 传递给 CMake 命令行。输出目录为 cuPHY/install/docs。
要将构建的 cuPHY 头文件和库放入安装目录中,以便其他使用 cuPHY 库的应用程序可以编译和链接 cuPHY,请使用当前构建目录中的命令
$ cmake --install build
这将在 cuPHY/install 目录下创建 include 和 lib 目录。
在单独的服务器上构建和运行#
当在一台服务器上构建源代码,并在另一台服务器上运行二进制文件时,使用针对目标的正确工具链可能很重要。
源代码目录 cuPHY/cmake/toolchains 包含以下目标的工具链
x86-64:devkit、r750、x86-64
arm:grace-cross、bf3
如果使用不同的目标,可能需要创建一个新的工具链文件。
工具链文件定义了要使用的编译器以及 AERIAL_ARCH_TUNE_FLAGS 的值
确保标志正确的一种方法是执行以下操作
在目标上运行 aerial_sdk 容器,在容器内运行以下命令
$ gcc -march=native -Q --help=target
在构建服务器上运行 aerial_sdk 容器,在容器内运行以下命令
$ gcc -march=<march for target> -Q --help=target
确保两个命令的输出相同。创建一个工具链文件并在构建 aerial_sdk 时使用它
$ cmake -Bbuild -GNinja -DCMAKE_TOOLCHAIN_FILE=cmake/toolchains/my-target
运行 cuPHY 示例#
本节介绍如何运行 Aerial cuPHY 独立示例程序。它们读取测试向量数据文件作为输入。请参阅 cuPHY 发行说明的 支持的测试向量配置 部分,以确定要用于不同配置的测试向量。请勿将以前 cuBB 版本的旧测试向量与此版本的示例程序一起使用。
使用 Matlab 5GModel 生成测试向量#
运行此 Matlab 命令
cd('nr_matlab'); startup; [nTC, errCnt] = runRegression({'TestVector'}, {'allChannels'}, 'compact', [0, 1] );
所有 cuPHY 测试向量都已生成并存储在 nr_matlab/GPU_test_input 下。
手动测试 cuPHY 通道的说明#
PUSCH#
测试向量
将测试向量名称与 PUSCH_gNB_CUPHY_*.h5 匹配
如何运行
流模式:
cuPHY/build/examples/pusch_rx_multi_pipe/cuphy_ex_pusch_rx_multi_pipe -i ~/<tv_name>.h5图模式:
cuPHY/build/examples/pusch_rx_multi_pipe/cuphy_ex_pusch_rx_multi_pipe -i ~/<tv_name>.h5 -m 1
预期结果
测试 1(CRC 测试 KPI):所有测试用例都必须具有零 CRC 错误(仅当运行通道时才报告 CRC 错误,而不是正确的错误)。
PUCCH#
测试向量
将测试向量名称与 PUCCH_F*_gNB_CUPHY_*.h5 匹配
如何运行
PUCCH 格式 0/1/2/3:cuPHY/build/examples/pucch_rx_pipeline/cuphy_ex_pucch_rx_pipeline -i <tv_name>
预期结果
cuphy_ex_pucch_Fx_receiver检查测试向量是否首先包含 PFx UCI。如果测试向量 UCI 格式不是预期的格式,则会显示“No PFx UCI received”。
如果测试向量 UCI 格式是预期的格式,则会比较 UCI output.xzsd。

PRACH#
测试向量
将测试向量名称与 PRACH_gNB_CUPHY_*.h5 匹配
如何运行
cuPHY/build/examples/prach_receiver_multi_cell/prach_receiver_multi_cell -i <tv_name> -r <num_iteration> -k
预期结果
prach_receiver_multi_cell根据测试向量中的参考测量值进行比较。显示测量值,如果它们在公差范围内,则显示消息
========> Test PASS
PDSCH#
测试向量
将测试向量名称与 PDSCH_gNB_CUPHY_*.h5 匹配
如何运行
非 AAS 模式下的 PDSCH,流模式:
cuPHY/build/examples/pdsch_tx/cuphy_ex_pdsch_tx ~/<tv_name>.h5 2 0 0非 AAS 模式下的 PDSCH,图模式:
cuPHY/build/examples/pdsch_tx/cuphy_ex_pdsch_tx ~/<tv_name>.h5 2 0 1
预期结果
测试 1(针对参考模型的正确性):通道报告与参考模型正确匹配
PDCCH#
测试向量
将测试向量名称与 PDCCH_gNB_CUPHY_*.h5 匹配
如何运行
流模式:
cuPHY/build/examples/pdcch/embed_pdcch_tf_signal -i ~/<tv_name>.h5 -m 0图模式:
cuPHY/build/examples/pdcch/embed_pdcch_tf_signal -i ~/<tv_name>.h5 -m 1
预期结果
测试 1(针对参考模型的正确性):Test PASS
SSB#
测试向量
将测试向量名称与 SSB_gNB_CUPHY_*.h5 匹配
如何运行
流模式:
cuPHY/build/examples/ss/testSS -i ~/<tv_name>.h5 -m 0图模式:
cuPHY/build/examples/ss/testSS -i ~/<tv_name>.h5 -m 1
预期结果
测试 1(针对参考模型的正确性):Test PASS
CSI-RS#
测试向量
将测试向量名称与 CSIRS_gNB_CUPHY_*.h5 匹配
如何运行
流模式:
cuPHY/build/examples/csi_rs/nzp_csi_rs_test -i <tv_name> -m 0图模式:
cuPHY/build/examples/csi_rs/nzp_csi_rs_test -i <tv_name> -m 1
预期结果
测试 1(针对参考模型的正确性):Test PASS
SRS#
测试向量
将测试向量名称与 SRS_gNB_CUPHY_*.h5 匹配
如何运行
流模式:
cuPHY/build/examples/srs_rx_pipeline/cuphy_ex_srs_rx_pipeline -i <tv_name> -r <num_iteration> -m 0图模式:
cuPHY/build/examples/srs_rx_pipeline/cuphy_ex_srs_rx_pipeline -i <tv_name> -r <num_iteration> -m 1
预期结果
测试 1(针对参考模型的正确性):SRS reference check: PASSED!;提供定时结果
BFC#
测试向量
将测试向量名称与 BFW_gNB_CUPHY_*.h5 匹配
如何运行
流模式:
cuPHY/build/examples/bfc/cuphy_ex_bfc -i <tv_name> -r <num_iteration> -m 0图模式:
cuPHY/build/examples/bfc/cuphy_ex_bfc -i <tv_name> -r <num_iteration> -m 1添加
-c以启用参考检查(默认禁用)
预期结果
测试 1(测量没有参考检查的延迟):提供定时结果
测试 2(使用 -c 针对参考模型的正确性):Test PASS;提供定时结果
LDPC 性能测试说明#
cuPHY 存储库中的 ldpc_perf_collect.py Python 脚本可用于对 cuPHY LDPC 解码器执行误码率测试。为 Z = [64, 128, 256, 384]、BG = [1,2] 定义了测试输入文件。当前测试检查误块率(BLER,有时也称为帧错误率或 FER)是否小于 0.1。
从 build 目录中,以下命令运行测试
../util/ldpc/ldpc_perf_collect.py --mode test -i ../util/ldpc/test/ldpc_decode_BG1_Z64_BLER0.1.txt -f -w 800 -P
../util/ldpc/ldpc_perf_collect.py --mode test -i ../util/ldpc/test/ldpc_decode_BG1_Z128_BLER0.1.txt -f -w 800 -P
../util/ldpc/ldpc_perf_collect.py --mode test -i ../util/ldpc/test/ldpc_decode_BG1_Z256_BLER0.1.txt -f -w 800 -P
../util/ldpc/ldpc_perf_collect.py --mode test -i ../util/ldpc/test/ldpc_decode_BG1_Z384_BLER0.1.txt -f -w 800 -P
../util/ldpc/ldpc_perf_collect.py --mode test -i ../util/ldpc/test/ldpc_decode_BG2_Z64_BLER0.1.txt -f -w 800 -P
../util/ldpc/ldpc_perf_collect.py --mode test -i ../util/ldpc/test/ldpc_decode_BG2_Z128_BLER0.1.txt -f -w 800 -P
../util/ldpc/ldpc_perf_collect.py --mode test -i ../util/ldpc/test/ldpc_decode_BG2_Z256_BLER0.1.txt -f -w 800 -P
../util/ldpc/ldpc_perf_collect.py --mode test -i ../util/ldpc/test/ldpc_decode_BG2_Z384_BLER0.1.txt -f -w 800 -P
每个测试输入文件都包含多个针对不同码率的测试,如奇偶校验节点数所指定。
运行 cuPHY 性能测试脚本#
aerial_sdk/testBenches 提供了一个多小区多通道测试平台,用于测试 cuPHY 独立性能。它依赖于 NVIDIA 多进程服务 (MPS) 在多个通道之间共享 GPU。具体来说,有两个文件夹,它们的关系可以概括如下
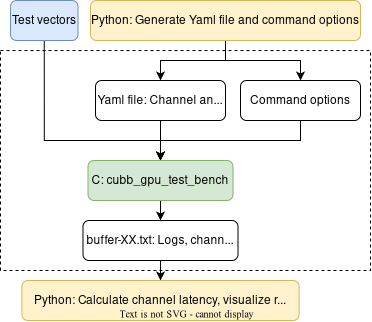
cubb_gpu_test_bench:一个 C 测试平台,用于运行多小区多通道 cuPHY 独立 GPU 工作负载(即,没有与 NIC 或第 2 层的 I/O)。cubb_gpu_test_bench 的输入是测试向量、Yaml 文件和一些用于运行 GPU 工作负载的命令选项。输出是一个 buffer-XX.txt 文件,其中包含日志、通道开始/结束时间、调试信息等。其中 XX 是测试中使用的单元格数。
perf:一组 Python 脚本,用于使用 cubb_gpu_test_bench 自动化性能测试。Python 脚本可以帮助生成 Yaml 文件和命令选项,在运行 cubb_gpu_test_bench 之前配置 GPU 和 MPS;通过从 cubb_gpu_test_bench 读取输出 buffer-XX.txt 来收集测试结果。
使用 Matlab 5GModel 生成测试向量#
运行此 Matlab 命令
cd <5GModel root>/nr_matlab
startup
genCfgTV_perf_ss('performance-avg.xlsm');
genCfgTV_perf_ss_bwc('performance-avg.xlsm');
genCfgTV_perf_pucch();
genCfgTV_perf_pdcch();
genCfgTV_perf_prach();
genCfgTV_perf_csirs();
genCfgTV_perf_ssb();
genCfgTV_perf_srs();
所有 cuPHY 性能测试向量都已生成并存储在 nr_matlab/GPU_test_input 下。
使用 cubb_gpu_test_bench 测量 cuPHY 性能#
要求
性能测量可以使用 Linux 环境运行,该环境可以使用一个或多个 GPU。此处假定此类环境具有
bash 或 zsh 作为默认 shell
Python 3.8+ 和以下软件包:numpy、pyCUDA、pyYAML
正确配置的 CUDA 工具包 11.4 或更高版本,以便 nvidia-cuda-mps-control 和 nvidia-smi 位于 PATH 中
可执行文件
cubb_gpu_test_bench位于 <testBenches>/build 文件夹中。
使用 cubb_gpu_test_bench 测量小区容量时,有三个步骤。perf 文件夹提供了一些预定义的测试用例。以下是使用 TDD 模式 DDDSUUDDDD 的 4T4R (F08) 的示例。
生成定义用例的 JSON 文件(例如,8~16 个峰值或平均小区)
python3 generate_avg_TDD.py --peak 8 9 10 11 12 13 14 15 16 --avg 0 --exact --case F08
根据预定义的模式测量所有通道的延迟
python3 measure.py --cuphy <testBenches>/build --vectors <test_vectors> --config testcases_avg_F08.json --uc uc_avg_F08_TDD.json --delay 100000 --gpu <GPU_ID> --freq <GPU_freq> --start <cell_start> --cap <cell_cap> --iterations 1 --slots <nSlots> --power <budget> --target <sms_prach> <sms_pdcch> <sms_pucch> <sms_pdsch> <sms_pusch> <sms_ssb> --2cb_per_sm --save_buffer --priority --prach --prach_isolate --pdcch --pdcch_isolate --pucch --pucch_isolate --tdd_pattern dddsuudddd --pusch_cascaded --ssb --csirs --groups_dl --pack_pdsch --groups_pusch --ldpc_parallel <--graph>
<GPU_ID>:要在其上运行测量的 GPU 的 ID(例如,对于单 GPU 系统,为0)<GPU_freq>:GPU 时钟频率(以 MHz 为单位)<cell_start>:要测试的最小小区数<cell_cap>:要测试的最大小区数。Python 脚本将针对[<cell_start>, <cell_cap>]小区范围运行cubb_gpu_test_bench,并收集延迟结果。<budget>:功率预算(以瓦特为单位)<sms_channelName>:在运行期间每个通道的每个 MPS 子上下文使用的流式多处理器数量,其中channelName可以是“PRACH”、“PDCCH”、“PUCCH”、“PDSCH”、“PUSCH”或“SSB”<--graph>以图模式运行测量。如果未包含此参数,将使用流模式。
注意
使用
--test查看 Python 脚本生成的 YAML 文件和命令选项,而无需在 GPU 上运行测试。可视化每个通道的延迟(此步骤需要 Python 库
matplotlib)。我们生成一个compare-<date>.png文件,显示所有测试通道的延迟 CDF如果在流模式下运行
python3 compare.py --filename <sms_prach>_<sms_pdcch>_<sms_pucch>_<sms_pdsch>_<sms_pusch>_<sms_ssb>_sweep_streams_avg_F08.json --cells <nCell>+0
如果在图模式下运行
python3 compare.py --filename <sms_prach>_<sms_pdcch>_<sms_pucch>_<sms_pdsch>_<sms_pusch>_<sms_ssb>_sweep_graphs_avg_F08.json --cells <nCell>+0
其中
<nCell>是我们想要可视化延迟结果的小区数
可以在一个图中比较不同小区数的延迟结果。例如,我们可以比较 8 个小区和 9 个小区的延迟
python3 compare.py --filename <sms_prach>_<sms_pdcch>_<sms_pucch>_<sms_pdsch>_<sms_pusch>_<sms_ssb>_sweep_graphs_avg_F08.json <sms_prach>_<sms_pdcch>_<sms_pucch>_<sms_pdsch>_<sms_pusch>_<sms_ssb>_sweep_graphs_avg_F08.json --cells 8+0 9+0
在所有情况下,Aerial CUDA 加速 RAN 都提供了测量所有工作负载延迟的可能性,包括
动态和异构流量(意味着每个小区都受到不同测试向量的刺激,并且每个时隙都看到测试向量到所考虑小区的不同分配)
特定流量模型