LLRNet:数据集生成#
下图描述了使用 Aerial 的无线 ML 设计流程。
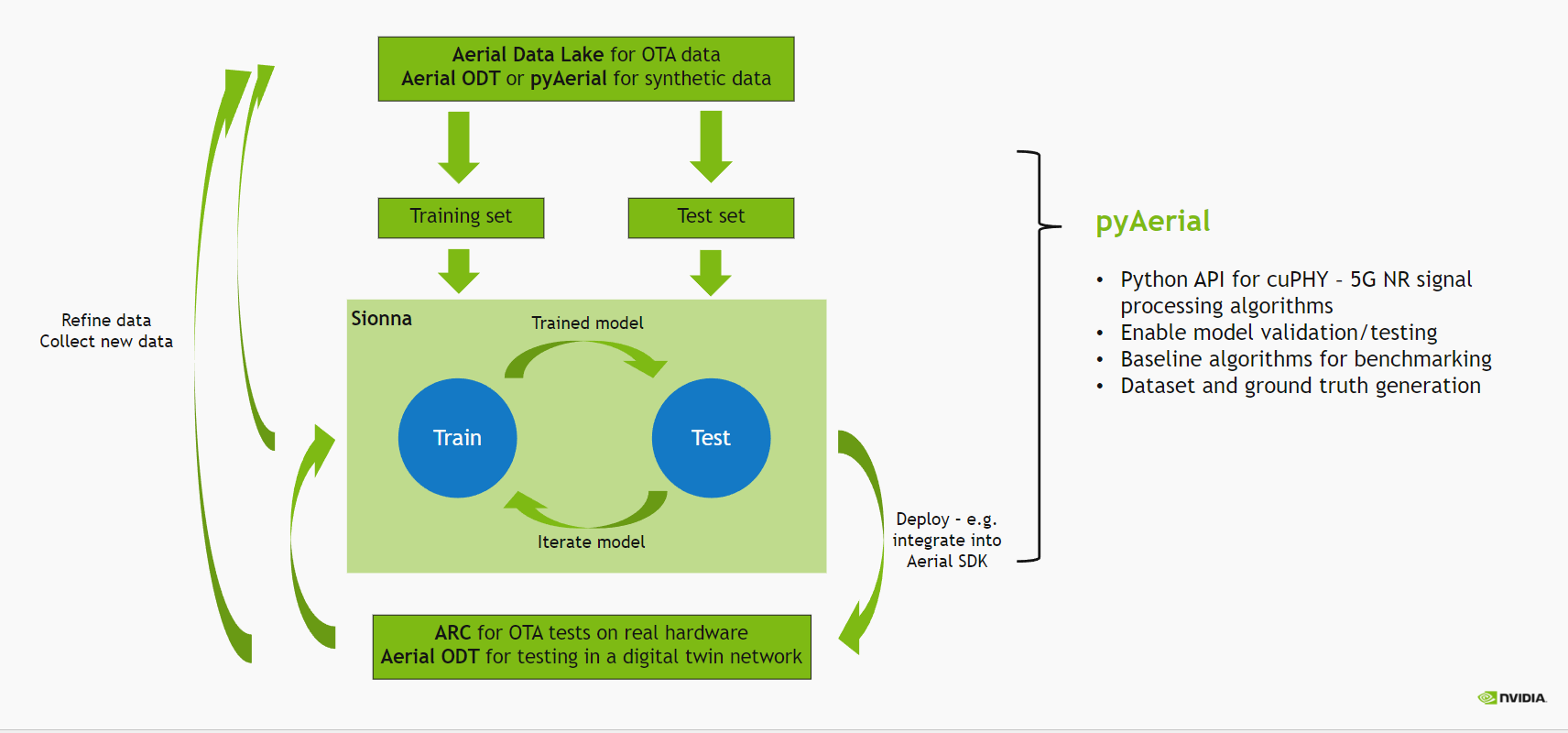
在本笔记本中,我们采用在 使用 pyAerial 通过仿真生成数据 示例中生成的数据,并使用 pyAerial 生成用于训练 LLRNet 的数据集。请注意,假设数据已在本笔记本运行之前生成。
LLRNet,发表于
Shental, J. Hoydis, “’Machine LLRning’: Learning to Softly Demodulate”, https://arxiv.org/abs/1907.01512
是一个简单的神经网络模型,它以均衡器输出(即复数值均衡符号)作为输入,并为每个比特输出相应的对数似然比 (LLR)。该模型用于演示使用 Aerial 的整个 ML 设计流程,从捕获数据到将模型部署到 5G NR PUSCH 接收器,取代 cuPHY 中的传统软解映射器。在本笔记本中,生成了一个数据集。我们使用 pyAerial 调用 cuPHY 功能,以获取预先捕获/模拟的 Rx 数据的均衡符号输出,以及来自传统软解映射器的相应对数似然比。
[1]:
# Check platform.
import platform
if platform.machine() != 'x86_64':
raise SystemExit("Unsupported platform!")
导入#
[2]:
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
from cuda import cudart
import numpy as np
import pandas as pd
from tqdm.notebook import tqdm
from IPython.display import Markdown
from IPython.display import display
from aerial.phy5g.algorithms import ChannelEstimator
from aerial.phy5g.algorithms import NoiseIntfEstimator
from aerial.phy5g.algorithms import ChannelEqualizer
from aerial.phy5g.algorithms import Demapper
from aerial.phy5g.ldpc import LdpcDeRateMatch
from aerial.phy5g.ldpc import LdpcDecoder
from aerial.phy5g.ldpc import CrcChecker
from aerial.phy5g.params import PuschConfig
from aerial.phy5g.params import PuschUeConfig
from aerial.util.data import PuschRecord
from aerial.util.data import load_pickle
from aerial.util.data import save_pickle
from aerial.util.fapi import dmrs_fapi_to_bit_array
import warnings
warnings.filterwarnings("error")
加载源数据#
源数据可以是来自空中设置的真实数据,也可以是通过仿真生成的合成数据。
注意: 本笔记本使用使用此笔记本生成的数据:使用 pyAerial 通过仿真生成数据,需要在本笔记本之前运行。
[3]:
# This is the source data directory which is assumed to contain the source data.
DATA_DIR = "data/"
source_dataset_dir = DATA_DIR + "example_simulated_dataset/QPSK/"
# This is the target dataset directory. It gets created if it does not exist.
target_dataset_dir = DATA_DIR + "example_llrnet_dataset/QPSK/"
os.makedirs(target_dataset_dir, exist_ok=True)
# Load the main data file.
try:
df = pd.read_parquet(source_dataset_dir + "l2_metadata.parquet", engine="pyarrow")
except FileNotFoundError:
display(Markdown("**Data not found - has example_simulated_dataset.ipynb been run?**"))
print(f"Loaded {df.shape[0]} PUSCH records.")
Loaded 12000 PUSCH records.
数据集生成#
在此,pyAerial 用于运行信道估计、噪声/干扰估计和信道均衡,以获得与 LLRNet 输入相对应的均衡符号,以及与 LLRNet 目标输出相对应的对数似然比。
[4]:
cuda_stream = cudart.cudaStreamCreate()[1]
# Take modulation order from the first record. The assumption is that all
# entries have the same modulation order here.
mod_order = df.loc[0].qamModOrder
# These hard-coded too.
num_rx_ant = 2
enable_pusch_tdi = 1
eq_coeff_algo = 1
# Create the PUSCH Rx components for extracting the equalized symbols and log-likelihood ratios.
channel_estimator = ChannelEstimator(
num_rx_ant=num_rx_ant,
cuda_stream=cuda_stream
)
noise_intf_estimator = NoiseIntfEstimator(
num_rx_ant=num_rx_ant,
eq_coeff_algo=eq_coeff_algo,
cuda_stream=cuda_stream
)
channel_equalizer = ChannelEqualizer(
num_rx_ant=num_rx_ant,
eq_coeff_algo=eq_coeff_algo,
enable_pusch_tdi=enable_pusch_tdi,
cuda_stream=cuda_stream)
derate_match = LdpcDeRateMatch(enable_scrambling=True, cuda_stream=cuda_stream)
demapper = Demapper(mod_order=mod_order)
decoder = LdpcDecoder(cuda_stream=cuda_stream)
crc_checker = CrcChecker(cuda_stream=cuda_stream)
# Loop through the PUSCH records and create new ones.
pusch_records = []
tb_errors = []
snrs = []
for pusch_record in (pbar := tqdm(df.itertuples(index=False), total=df.shape[0])):
pbar.set_description("Running cuPHY to get equalized symbols and log-likelihood ratios...")
tbs = len(pusch_record.macPdu)
ref_tb = pusch_record.macPdu
slot = pusch_record.Slot
# Just making sure the hard-coded value is correct.
assert mod_order == pusch_record.qamModOrder
# Wrap the parameters in a PuschConfig structure.
pusch_ue_config = PuschUeConfig(
scid=pusch_record.SCID,
layers=pusch_record.nrOfLayers,
dmrs_ports=pusch_record.dmrsPorts,
rnti=pusch_record.RNTI,
data_scid=pusch_record.dataScramblingId,
mcs_table=pusch_record.mcsTable,
mcs_index=pusch_record.mcsIndex,
code_rate=pusch_record.targetCodeRate,
mod_order=pusch_record.qamModOrder,
tb_size=len(pusch_record.macPdu)
)
# Note that this is a list. One UE group only in this case.
pusch_configs = [PuschConfig(
ue_configs=[pusch_ue_config],
num_dmrs_cdm_grps_no_data=pusch_record.numDmrsCdmGrpsNoData,
dmrs_scrm_id=pusch_record.ulDmrsScramblingId,
start_prb=pusch_record.rbStart,
num_prbs=pusch_record.rbSize,
dmrs_syms=dmrs_fapi_to_bit_array(pusch_record.ulDmrsSymbPos),
dmrs_max_len=1,
dmrs_add_ln_pos=1,
start_sym=pusch_record.StartSymbolIndex,
num_symbols=pusch_record.NrOfSymbols
)]
# Load received IQ samples.
rx_iq_data_filename = source_dataset_dir + pusch_record.rx_iq_data_filename
rx_slot = load_pickle(rx_iq_data_filename)
num_rx_ant = rx_slot.shape[2]
# Load user data.
user_data_filename = source_dataset_dir + pusch_record.user_data_filename
user_data = load_pickle(user_data_filename)
# Run the channel estimation (cuPHY).
ch_est = channel_estimator.estimate(
rx_slot=rx_slot,
slot=slot,
pusch_configs=pusch_configs
)
# Run noise/interference estimation (cuPHY), needed for equalization.
lw_inv, noise_var_pre_eq = noise_intf_estimator.estimate(
rx_slot=rx_slot,
channel_est=ch_est,
slot=slot,
pusch_configs=pusch_configs
)
# Run equalization and mapping to log-likelihood ratios.
llrs, equalized_sym = channel_equalizer.equalize(
rx_slot=rx_slot,
channel_est=ch_est,
lw_inv=lw_inv,
noise_var_pre_eq=noise_var_pre_eq,
pusch_configs=pusch_configs
)
ree_diag_inv = channel_equalizer.ree_diag_inv[0]
ree_diag_inv = np.transpose(ree_diag_inv[..., 0], (1, 2, 0)).reshape(ree_diag_inv.shape[1], -1)
# Just pick one (first) symbol from each PUSCH record for the LLRNet dataset.
# This is simply to reduce the size of the dataset - training LLRNet does not
# require a lot of data.
user_data["llrs"] = llrs[0][:mod_order, 0, :, 0]
user_data["eq_syms"] = equalized_sym[0][0, :, 0]
map_llrs = demapper.demap(equalized_sym[0][0, :, 0], ree_diag_inv[0, ...])
user_data["map_llrs"] = map_llrs
# Save pickle files for the target dataset.
rx_iq_data_fullpath = target_dataset_dir + pusch_record.rx_iq_data_filename
user_data_fullpath = target_dataset_dir + pusch_record.user_data_filename
save_pickle(data=rx_slot, filename=rx_iq_data_fullpath)
save_pickle(data=user_data, filename=user_data_fullpath)
pusch_records.append(pusch_record)
#######################################################################################
# Run through the rest of the receiver pipeline to verify that this was legit LLR data.
# De-rate matching and descrambling.
coded_blocks = derate_match.derate_match(
input_llrs=llrs,
pusch_configs=pusch_configs
)
# LDPC decoding of the derate matched blocks.
code_blocks = decoder.decode(
input_llrs=coded_blocks,
pusch_configs=pusch_configs
)
# Combine the code blocks into a transport block.
tb, _ = crc_checker.check_crc(
input_bits=code_blocks,
pusch_configs=pusch_configs
)
tb_errors.append(not np.array_equal(tb[:tbs], ref_tb[:tbs]))
snrs.append(user_data["snr"])
[5]:
print("Saving...")
df_filename = os.path.join(target_dataset_dir, "l2_metadata.parquet")
df = pd.DataFrame.from_records(pusch_records, columns=PuschRecord._fields)
df.to_parquet(df_filename, engine="pyarrow")
print("All done!")
Saving...
All done!