Aerial cuPHY 组件#
L2 适配器#
L2 适配器是 L1 和 L2 之间的接口,它将 SCF FAPI 命令转换为时隙命令。时隙命令由 cuPHY 驱动程序接收,以启动 cuPHY 任务。它利用 nvipc 库在 L1 和 L2 之间传输消息和数据。它还负责发送时隙指示,以驱动 L1-L2 接口的定时。L2 适配器跟踪时隙定时,如果从 L2 收到的消息延迟,它可以丢弃这些消息。
cuPHY 驱动程序#
cuPHY 驱动程序负责使用 cuPHY 和 FH 库来编排 GPU 和 FH 上的工作。它处理 L2 适配器生成的 L2 时隙命令以启动任务,并将 cuPHY 输出(例如 CRC 指示、UCI 指示、测量报告等)传回 L2。它使用 L2 适配器 FAPI 消息处理程序库与 L2 通信。
cuPHY 驱动程序配置并启动 DL 和 UL cuPHY 任务,这些任务反过来在 GPU 上启动 CUDA 内核。这些过程在时隙级别进行管理。cuPHY 驱动程序还控制 CUDA 内核,这些内核负责用户平面(U-plane)数据包与 NIC 接口之间的传输和接收。驱动程序启动的 CUDA 内核负责 UL 数据包的重新排序和解压缩以及 DL 数据包的压缩。DL 数据包在压缩后通过 GPU 发起的通信进行传输。
cuPHY 驱动程序使用符合 ORAN 标准的 FH 库与 FH 接口交互,以协调 FH 控制平面(C-plane)数据包的传输。C-plane 数据包的传输通过 DPDK 库调用(CPU 发起的通信)完成。U-plane 数据包通过 cuphycontroller 创建的发送和接收队列进行通信。
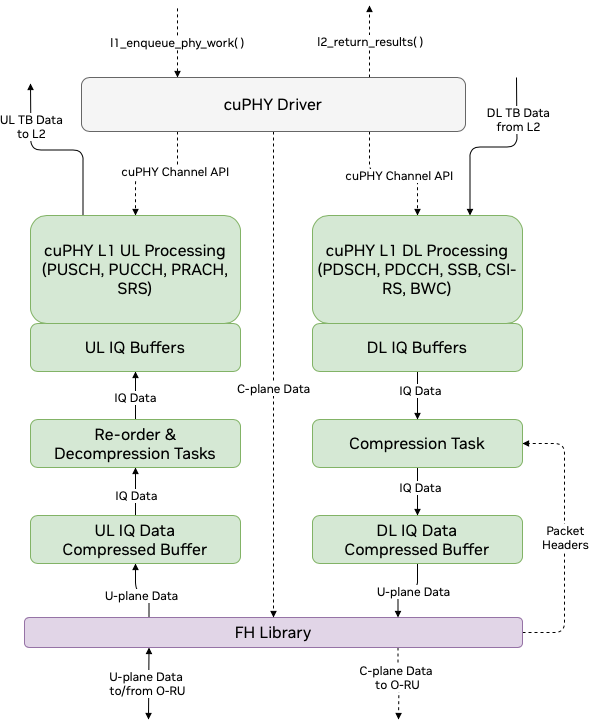
通过 cuPHY 驱动程序和 cuPHY 任务的用户和控制平面数据流#
FH 驱动程序库#
FH 库确保 O-DU 和 O-RU 之间 FH 数据包的及时传输和接收。它使用 NIC 的精确发送调度功能,以符合 O-RAN FH 规范的定时要求。
FH 驱动程序维护每个 eAxCid 的上下文和连接。它负责 U-plane 和 C-plane 消息的 FH 命令的编码和解码。
从 L2 收到的 FAPI 命令触发 DL 或 UL 时隙的处理。C-plane 消息用于在 CPU 上生成并在 DL 和 UL 上都通过带有 DPDK 的 NIC 接口与 O-RU 通信。DL U-plane 数据包的有效负载在 GPU 上准备,并使用 DOCA GPU NetIO 库从 GPU 上的内存池发送到 NIC 接口。下图说明了 DL C-plane 和 U-plane 数据包的流程。
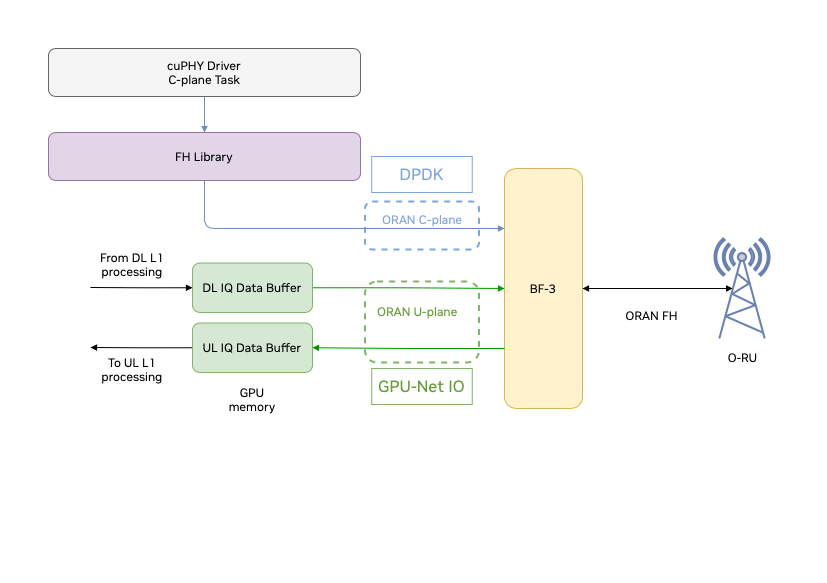
FH 上的数据包流程#
如上图所示,从 O-RU 收到的 UL U-plane 数据包使用 DOCA GPU NetIO 库直接从 NIC 接口复制到 GPU 内存。UL 数据被解压缩并由 GPU 内核处理。在 UL 内核完成后,解码后的 UL 数据传输块被发送到 L2。
cuPHY 控制器#
cuPHY 控制器是主要应用程序,它使用所需的配置初始化系统。在启动过程中,cuPHY 控制器为与 O-RU 的每个新连接(由 MAC 地址、VLAN ID 和 eAxCid 集标识)创建新上下文(内存资源、任务)。它启动 cuphydriver DL/UL 工作线程,并将它们分配给 yaml 文件中配置的 CPU 核心。它还准备 GPU 资源并启动 FH 驱动程序和 NIC 类对象。
cuPHY 控制器根据所需的 gNB 配置准备 L1。它还可以使用小区生命周期管理功能将载波投入和撤出服务。
cuPHY#
cuPHY 是 5G PHY 层信号处理功能的 CUDA 实现。cuPHY 库支持符合 3GPP Release 15 规范的所有 5G NR PHY 信道。如下图所示,根据 O-RAN 7.2x 分割选项 [8],cuPHY 库对应于上层 PHY 堆栈。
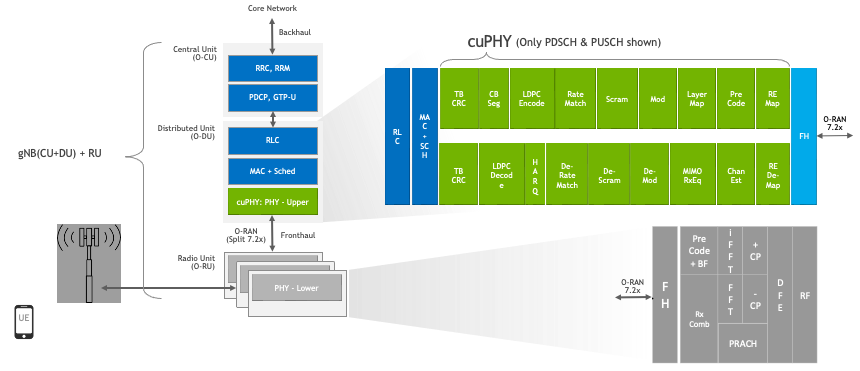
5G NR 软件堆栈中的 cuPHY 库#
cuPHY 经过优化,可以通过在可能的情况下并行运行工作负载来利用 GPU 架构的大规模并行处理能力。cuPHY 驱动程序编排在 GPU 上运行的信号处理任务。这些任务根据 PHY 层信道类型(例如 PDSCH、PUSCH、SSB 等)进行组织。与给定信道相关的任务称为流水线。例如,PDSCH 信道在 PDSCH 流水线中处理,PUSCH 信道在 PUSCH 流水线中处理。每个流水线都包含一系列与特定流水线相关的功能,并由多个 CUDA 内核组成。每个流水线都能够运行多个小区的信号处理工作负载。流水线由 cuPHY 驱动程序使用信道聚合对象为每个时隙动态管理。在给定时隙中执行的 cuPHY 信道流水线组取决于 L2 在该时隙中调度的内容。
cuPHY 库为每个 PHY 信道公开一组 API,用于创建、销毁、设置、配置和运行每个流水线,如下图所示。L2 适配器转换 SCF FAPI 消息和其他系统配置,cuPHY 驱动程序为每个时隙调用相关的 cuPHY API。灰色显示的 API(例如(重新)配置、状态更新)目前不受支持。
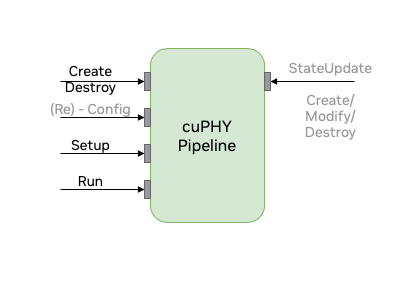
cuPHY API 接口#
以下是上图中 API 的描述
- 创建: 执行流水线构建时间操作,例如 PHY
和 CUDA 对象实例化、内存分配等。
- 销毁: 执行流水线的拆卸程序并释放
已分配的资源。
- 设置: 设置带有时隙信息和批处理的 PHY 描述符
执行流水线所需。
运行: 启动流水线。
以下章节提供有关每个 cuPHY 信道流水线实现的更多详细信息。
PDSCH 流水线#
PDSCH 流水线接收每个小区和 UE 的配置参数以及相应的 DL 传输块 (TB)。在完成 PDSCH 信道的编码后,流水线输出映射到分配给 PDSCH 的资源元素 (RE) 的 IQ 样本。PDSCH 流水线由多个 CUDA 内核组成,这些内核使用 CUDA 图功能启动,以减少内核启动开销。下图显示了 PDSCH 流水线使用的 CUDA 图的图表。绿色框表示 CUDA 内核,橙色框表示输入和输出缓冲区。
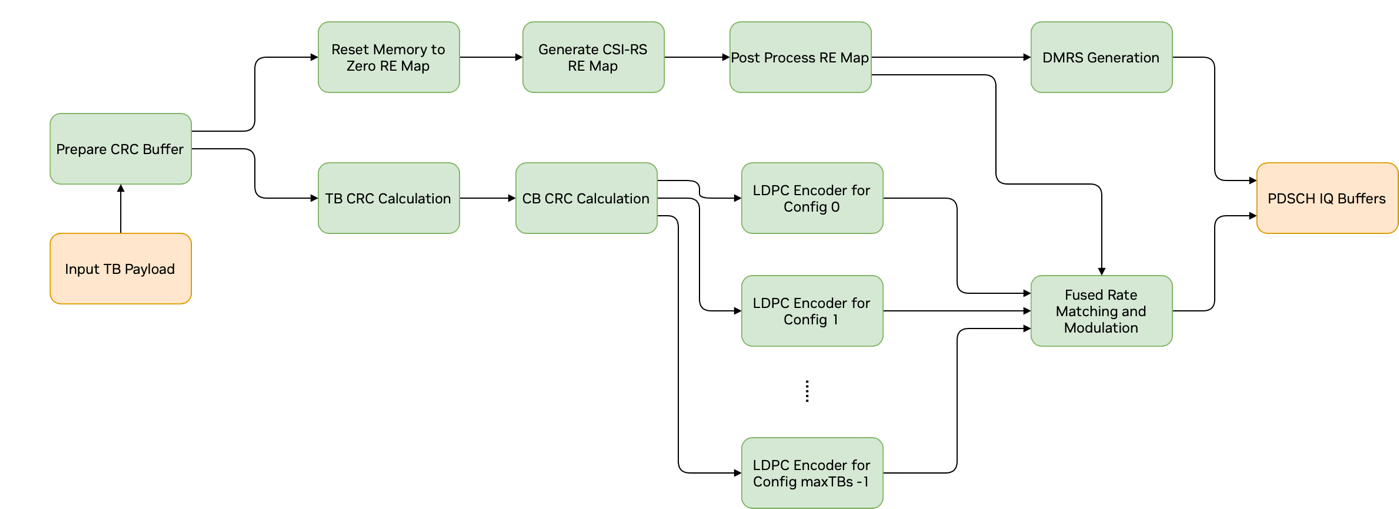
PDSCH 流水线的图表#
PDSCH 流水线包含以下组件
TB 和代码块 (CB) 的 CRC 计算
LDPC 编码
融合速率匹配和调制映射器
DMRS 生成
CRC 计算组件执行代码块分段和 CRC 计算。首先为每个 TB 计算 CRC,然后为每个 CB 计算 CRC。融合速率匹配和调制组件执行速率匹配、加扰、层映射、预编码和调制。此组件还知道如果配置了 CSI-RS,则应跳过哪些资源元素。
PDSCH 流水线涉及以下内核
prepare_crc_buffers
crcDownlinkPdschTransportBlockKernel
crcDownlinkPdschCodeBlocksKernel
ldpc_encode_in_bit_kernel
fused_dl_rm_and_modulation
fused_dmrs
仅当 CSI-RS 参数存在时才执行的内核如下所示
zero_memset_kernel
genCsirsReMap
postProcessCsirsReMap
cuPHY PDSCH 发射流水线填充 GPU 内存中 I/Q 样本的 3D 张量缓冲区的一部分,其中每个样本是使用 fp16 的复数,即每个样本是使用 x 表示实部,y 表示虚部的 __half2。输出 3D 张量缓冲区由 cuPHY 驱动程序在首次启动应用程序时分配,并由 cuPHY 驱动程序为每个时隙(即,在连续的 PDSCH 启动之间)重置。在此,重置缓冲区意味着将其初始化为所有零值。
输出张量在时域(x 轴)上包含 14 个符号,在频域(y 轴)上包含 273 个 PRB(物理资源块),在空域(z 轴)上最多包含 16 层。对于 y 轴,每个 PRB 包含 12 个 RE,每个 RE 都是 __half2 数据。同一 OFDM 符号和空间层的连续 PRB 在内存中彼此相邻分配。资源在内存中按以下顺序映射:频域、时域,然后是空域(或层域)。这是每个小区每个时隙所需的输出缓冲区的最大大小。
PDSCH 仅填充该缓冲区的一部分,即其分配的 PRB,基于其接收到的随时间变化的各种配置参数。时隙的一部分可以由其他下行链路控制信道填充。从 PDSCH 的角度来看,只有上面列出的两个 fused_* 内核,fused_dl_rm_and_modulation 和 fused_dmrs 写入输出缓冲区。融合速率匹配和调制内核写入 I/Q 样本的数据部分,而 DMRS 内核仅写入 DMRS 符号,即 x 维度中仅 1 或 2 个连续符号。请注意,与其他组件不同,DMRS 不依赖于任何先前的流水线阶段。
PDSCH 流水线期望预先填充的结构 cuphyPdschStatPrms_t(cuPHY PDSCH 静态参数)和 cuphyPdschDynPrms_t(cuPHY PDSCH 动态参数),其中包括输入数据和必要的配置参数。
TB 数据输入可以存在于 CPU 或 GPU 内存中,具体取决于 cuphyPdschDataIn_t.pBufferType。如果这是 GPU_BUFFER,则该数据的主机到设备 (H2D) 内存复制可以在为每个小区执行 PDSCH 设置之前发生。这称为预先 H2D 复制,可以通过在 l2_adapter_config_*.yaml 文件中设置 prepone_h2d_copy 标志来配置。如果未启用预先 H2D 复制,则复制操作将在 PDSCH 设置期间发生。强烈建议应启用预先 H2D 复制,以在多小区场景中实现高容量。
当在 PDSCH 上配置多个 TB 时,LDPC 内核的启动方式可能会发生变化。如果 LDPC 配置参数在 TB 之间相同,则 PDSCH 为所有 TB 启动单个 LDPC 内核(与其他 PDSCH 组件的情况一样)。如果 LDPC 配置参数在 TB 之间不同,则会启动多个 LDPC 内核,每个唯一的配置参数集一个。每个 LDPC 内核都在单独的 CUDA 流上启动。
PDSCH CUDA 图仅包含内核节点,其布局如上面 PDSCH 图表所示。由于无法在运行时动态更改图几何形状,因此创建了 PDSCH_MAX_HET_LDPC_CONFIGS_SUPPORTED 潜在的 LDPC 内核节点。根据 LDPC 配置参数和 TB 的数量,只有这些内核的子集执行 LDPC 编码。如果需要,其余节点在运行时针对每个 PDSCH 禁用。DMRS 内核节点不依赖于任何其他 PDSCH 内核。因此,它可以放置在图中的任何位置。图中 DMRS 之前的三个内核仅在 CSI-RS 参数存在(或配置了 CSI-RS)时才执行。这些内核计算融合速率匹配和调制内核所需的关于需要跳过的 RE 的信息。
PDCCH 流水线#
cuPHY PDCCH 信道处理涉及以下内核
encodeRateMatchMultipleDCIsKernel
genScramblingSeqKernel
genPdcchTfSignalKernel
当在图形模式下运行时,每个时隙启动的 CUDA 图仅包含内核节点,其当前布局如下图所示。

cuPHY PDCCH 图布局#
PDCCH 内核采用与 PDSCH 中相同的静态和动态参数。
关于 PDCCH 配置和数据集约定的说明
PdcchParams 数据集包含给定小区的 coreset 参数。数据集 DciParams_coreset_0_dci_0 包含 coreset 0 的第一个 DCI 的 DCI 参数。小区中的每个 DCI 都有一个单独的数据集,命名约定为:DciParams_coreset_<i>_dci_<j>,其中 i 的值从 0 到(coreset 数量 – 1),而 j 对于每个 coreset i 从 0 开始,并递增到(PdcchParams[i].numDlDci – 1)。
数据集 DciPayload_coreset_0_dci_0 包含 coreset 0 的第一个 DCI 的 DCI 有效负载(以字节为单位)。它遵循上面提到的命名约定 DciParams_coreset_0_dci_0。
数据集 DciPmW_coreset_i_dci_j 保存给定 DCI、coreset 对的预编码矩阵(如果启用了预编码)。
X_tf_fp16 是该小区的 3D 输出张量,用于各种 PDCCH 示例中的参考检查。
包含压缩数据的 X_tf_cSamples_bfp* 数据集在 cuPHY 中未使用,因为压缩发生在 cuphydriver 中,在完成一个时隙中调度的所有下行链路信道的 cuPHY 处理之后。
SSB 流水线#
cuPHY SS 块信道处理涉及以下内核
encodeRateMatchMultipleSSBsKernel
ssbModTfSigKernel
当在图形模式下运行时,每个时隙启动的 CUDA 图仅包含按顺序连接的这两个内核节点。
关于 SSB 配置和数据集约定的说明
SSTxParams 数据集包含给定小区的所有 nSsb、SSB 参数。
SSB 突发不能在频域中复用,它们只能在时域中复用。
nSsb 数据集包含小区中 SSB 的数量,这也是 SSTxParams 数据集的大小。
x_mib 包含小区中每个 SSB 的主信息块 (MIB),作为 uint32_t 元素;只有每个元素的最低有效 24 位有效。
数据集 Ssb_PM_W* 包含预编码矩阵(如果为给定 SSB 启用了预编码)。
- X_tf_fp16 是该小区的 3D 输出张量,用于各种 SSB 示例中的参考检查。那里的每个 I/Q 样本都存储为 __half2c。X_tf 类似于 X_tf_fp16,但那里的每个 I/Q 样本都存储为 float2 而不是 __half2;目前在 cuPHY 中未使用。
X_tf_cSamples_bfp* 数据集保存压缩后的输出,并且在 cuPHY 中未使用,因为压缩作为 cuphydriver 的一部分应用。
CSI-RS 流水线#
cuPHY CSI-RS 信道处理涉及以下内核
genScramblingKernel
genCsirsTfSignalKernel
当在图形模式下运行时,每个时隙启动的 CUDA 图仅包含按顺序连接的这两个内核节点。
关于 CSI-RS 配置和数据集约定的说明
CsirsParamsList 包含用于非零功率信号生成(例如,NZP、TRS)的配置参数。
请注意,CsirsParamsList 数据集可以有多个元素。数据集中的所有元素都可以通过单个设置/运行调用进行处理。
X_tf_fp16 是该小区的 3D 参考输出张量,用于各种 CSI-RS 示例中的参考检查。那里的每个 I/Q 样本都存储为 __half2c。
X_tf 类似于 X_tf_fp16,但那里的每个 I/Q 样本都存储为 float2 而不是 __half2;目前在 cuPHY 中未使用。
X_tf_cSamples_bfp* 数据集保存压缩后的输出,并且在 cuPHY 中未使用,因为压缩作为 cuphydriver 的一部分应用。
X_tf_remap 是 RE Map 的参考输出,目前未使用,因为当前实现仅生成 NZP 信号。
数据集 Csirs_PM_W* 包含预编码矩阵,如果启用了预编码,则使用这些矩阵。
PUSCH 流水线#
PUSCH 流水线包括以下组件(这些组件在PUSCH 流水线前端和PUSCH 和 CSI 第 1 部分解码图中进行了说明)
最小二乘 (LS) 信道估计
最小均方误差 (MMSE) 信道估计
噪声和干扰协方差估计
收缩和白化
信道均衡
载波频率偏移 (CFO) 估计和 CFO 平均
定时偏移 (TO) 估计和平均。
接收信号强度指示器 (RSSI) 估计和平均
噪声方差估计
接收信号接收功率 (RSRP) 估计和平均
SNR 估计
解速率匹配
LDPC 后端
如果配置了 CSI 第 2 部分,则还使用以下组件(这些组件在PUSCH 和 CSI 第 1 部分解码和PUSCH 和 CSI 第 2 部分解码图中进行了说明)
单工解码器或 RM 解码器或极化码解码器(用于 CSI 第 1 部分的 CSI 解码,具体取决于 UCI 有效负载大小)
CSI 第 2 部分解扰和解速率匹配
单工解码器或 RM 解码器或极化码解码器(用于 CSI 第 2 部分的 CSI 解码,具体取决于 UCI 有效负载大小)
PUSCH 流水线接收 IQ 样本,这些样本由排序和解压缩内核提供。接收到的 IQ 数据以 cuphyTensorPrm_t 类型存储在地址 cuphyPuschDataIn_t PhyPuschAggr::DataIn.pTDataRx 中。IQ 样本由半精度(16 位)实值和虚值表示。输入缓冲区的大小是最大 PRB 数 (273)、每个 PRB 的子载波数 (12)、每个时隙的 OFDM 符号数 (14) 和每个小区的最大天线端口数 (16) 的乘积。此缓冲区是为每个小区创建的。
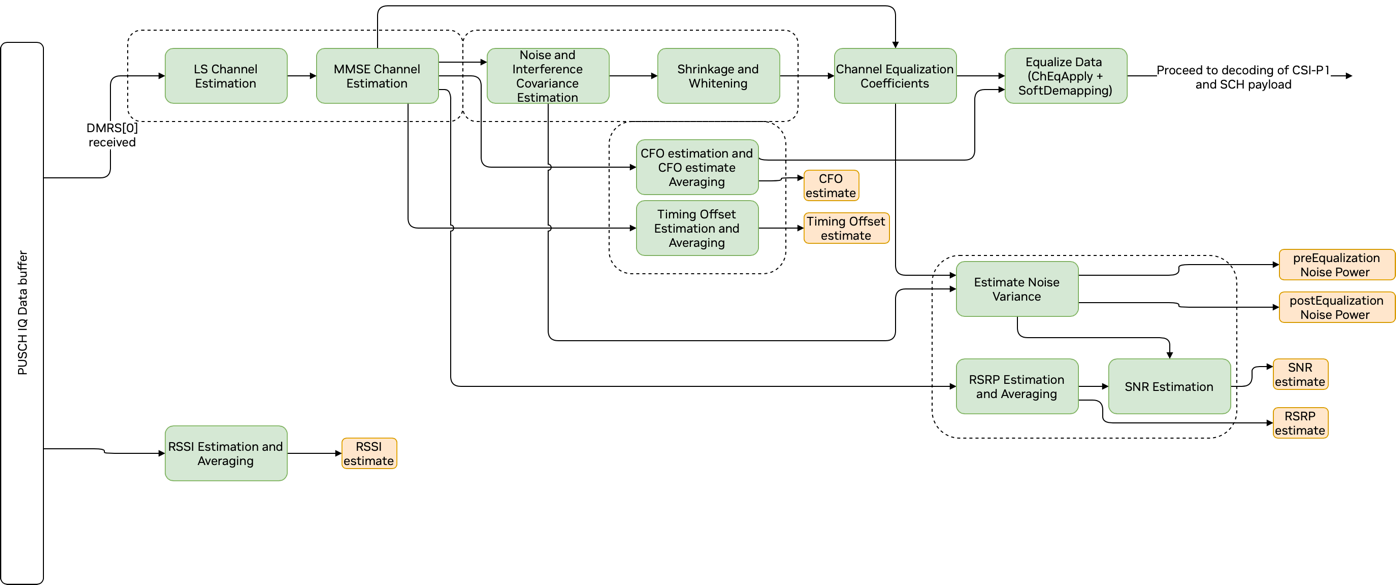
PUSCH 流水线前端的图表#
信道估计#
|
|
|---|---|
输入缓冲区 |
|
数据类型 |
|
维度 |
[(ORAN_MAX_PRB*CUPHY_N_TONES_PER_PRB), OFDM_SYMBOLS_PER_SLOT, MAX_AP_PER_SLOT] [(273*12),14,16] |
描述 |
从 FH 收到的 UL 时隙的输入数据的 IQ 样本。I/Q 数据以半精度浮点数表示。 |
输出缓冲区 |
注意:索引 |
数据类型 |
|
维度 |
[(CUPHY_N_TONES_PER_PRB*(PRB 数量)/2), NUM_LAYERS, NUM_ANTENNAS, NH] [(12*(PRB 数量)/2), (层数), (接收天线数), (DMRS 符号数)] |
描述 |
DMRS 符号上初始信道估计的 IQ 样本。I/Q 数据以半精度浮点数表示。 |
输出缓冲区 |
PuschRx::m_tRefDmrsAccumVec[i] 注意:索引 |
数据类型 |
|
维度 |
|
描述 |
在给定的 PRB 范围内保持 |
信道估计 (CE) 由两个阶段组成:最小二乘 (LS) CE 和最小均方 (MMSE) CE。
第一个 LS CE 阶段调用内核 windowedChEstPreNoDftSOfdmKernel()。DMRS 符号用于获取 DMRS RE 上的初始信道估计,并计算信道脉冲响应 (CIR) 的平均延迟。然后,平均延迟和初始估计用于在第二阶段使用 MMSE 滤波操作获得数据 RE 中的信道估计。
第二阶段调用调度内核 chEstFilterNoDftSOfdmDispatchKernel() 以支持不同的配置。调度内核首先使用来自第一阶段的存储值 m_tRefDmrsAccumVec 计算平均信道延迟。然后,它根据给定 PUSCH 分配中的 PRB 数量和连续 DMRS 符号的数量 (drvdUeGrpPrms.dmrsMaxLen) 选择合适的内核。MMSE 滤波操作由内核 windowedChEstFilterNoDftSOfdmKernel() 完成。
基于 cuPHY PUSCH 流水线的测试平台的 cuphy_ex_ch_est 组件级单元测试可用于验证在 CUDA 中实现的现有或新 PUSCH DMRS 信道估计的功能正确性,以对抗 5GModel 生成的参考。利用 cuphy_ex_ch_est 有几个主要步骤
生成
staticApiDataset以包含 PUSCH 流水线的静态参数,dynApiDataset以包含 PUSCH 流水线的动态参数,以及evalDataset以包含来自 cuPHY PUSCH TV 的用于评估目的的 5GModel 生成的参考。创建 C++ 类
PuschRx的对象puschRx,它封装了与来自 staticApiDataset 的 cuPHY PUSCH 流水线相对应的主功能、结构和内部参数,并初始化其内部静态参数。调用 puschRx 的
expandFrontEndParameters()以初始化 CPU 中使用dynApiDataset的结构cuphyPuschRxUeGrpPrms_t数组;为每个 UE 组分配 GPU 设备内存缓冲区,以保存输入 I/Q 样本(即tInfoDataRx)和信道估计结果(例如,tInfoHEst、tInfoDmrsLSEst)。调用
cuphyPuschRxChEstGetDescrInfo()以计算puschRxChEstStatDescr_t和puschRxChEstDynDescr_t的大小;创建相应的 CPU/GPU 缓冲区以保存静态和动态参数(描述符)(即,puschRxChEstStatDescr_t和puschRxChEstDynDescr_t),这些参数直接用作信道估计内核的输入。调用
cuphyCreatePuschRxChEst()以创建 C++ 类puschRxChEst的信道估计对象和相应的句柄puschRxChEstHndl,初始化puschRxChEstStatDescr_t,并返回指示操作是否成功的状态代码;将puschRxChEstStatDescr_t的内容从 CPU 缓冲区复制到 GPU 缓冲区。调用
cuphySetupPuschRxChEst()以从cuphyPuschRxUeGrpPrms_t和其他参数填充puschRxChEstDynDescr_t,选择/配置要使用的内核,并创建内核启动配置cuphyPuschRxChEstLaunchCfgs_t以包括内核节点参数和内核输入参数;将cuphyPuschRxUeGrpPrms_t和puschRxChEstDynDescr_t的内容从 CPU 缓冲区复制到 GPU 缓冲区。基于
cuphyPuschRxChEstLaunchCfgs_t启动信道估计内核以读取输入 I/Q 样本,执行信道估计,并生成信道估计结果。通过调用
cuphyDestroyPuschRxChEst()销毁信道估计对象并释放相应的资源;通过将 GPU 输出与 5GModel 生成的参考进行比较并报告结果的准确性来评估信道估计结果。
|
|
|---|---|
输入缓冲区 |
|
输入缓冲区 |
|
描述 |
请参阅第一阶段(LS CE)表 |
输入 CE 滤波器 |
|
描述 |
插值滤波器系数,具体取决于 PRB 的数量 |
数据类型 |
|
维度 |
[(N_TOTAL_DMRS_INTERP_GRID_TONES_PER_CLUSTER + N_INTER_DMRS_GRID_FREQ_SHIFT), N_TOTAL_DMRS_GRID_TONES_PER_CLUSTER, 3],3 个滤波器:1 个用于中间,1 个用于下边缘,1 个用于上边缘
|
描述 |
这些 CE 滤波器用于执行频域插值并消除 FOCC 效应。滤波器系数根据 PRB 计数和 PRB 位置而有所不同(即,边缘 PRB 的滤波器系数与中心 PRB 的滤波器系数不同)。这些系数可以通过 5GModel 计算,也可以直接从任何 cuPHY PUSCH 测试向量或 |
输入 CE 序列 |
|
数据类型 |
|
维度 |
[(N_DATA_PRB*N_DMRS_GRID_TONES_PER_PRB), 1]
[(N_DATA_P RB*N_DMRS_INTERP_TONES_PER_GRID*N_DMRS_GRIDS_PER_PRB + N_INTER_DMRS_GRID_FREQ_SHIFT), 1]
|
描述 |
这些 CE 序列用于移动(和取消移动)估计的信道脉冲响应,以用于滤波目的。这些序列可以通过 5GModel 计算,也可以直接从任何 cuPHY PUSCH 测试向量或 |
输出缓冲区 |
注意:索引 |
数据类型 |
|
维度 |
[(接收天线数量), (层数), (12*(PRB 数量)), (DMRS 符号数量)] |
描述 |
DMRS 符号上接收信道的估计。 |
噪声和干扰协方差估计#
输入缓冲区 |
接收信道估计内核的输出作为输入。 |
输出缓冲区 |
PuschRx:: m_tRefNoiseVarPreEq |
数据类型 |
CUPHY_R_32_F:浮点实数值 |
维度 |
[1, NUM_UE_GROUPS] |
描述 |
每个 UE 组(或 PRB 范围)的均衡前噪声方差估计。 |
输出缓冲区 |
PuschRx:: m_tRefLwInvVec[i] 注意:索引 i 指的是 PRB 范围(或 UE 组) |
数据类型 |
CUPHY_C_32_F:浮点复数 IQ 采样 |
维度 |
[NUM_ANTENNAS, NUM_ANTENNAS, numPRB] [(接收天线数量), (接收天线数量), (PRB 数量)] |
描述 |
噪声-干扰张量信息的逆 Cholesky 因子。 |
载波频率和定时偏移估计#
载波频率偏移 (CFO) 是由 UE/RU 的本地振荡器偏离标称载波频率引起的。在 UE 的情况下,偏移对于每个 UE 都是独立的(但对于所有 RF 流都相同)。在 RU 处,预计偏移对于所有 RF 流都是相等的。
CFO 可能对接收信号产生以下影响
载波间干扰 (ICI),其中子载波不正交
在不同符号上观察到的线性相位旋转(即在时域中)
CFO 估计通常基于时域内的重复,从而可以估计相位旋转。相位旋转需要在均衡器阶段进行复数乘法,而 ICI 缓解需要时域运算或矩阵乘法。Aerial 中未实现 ICI 缓解。
Aerial 中的 CFO 估计器使用 DMRS 符号的信道估计来计算 CFO 的校正因子。该算法目前支持来自 FDM 模式中复用的多个 UE 的多个 CFO 校正。它具有以下限制
无法估计和补偿来自 CDM 模式(例如 MU-MIMO)中复用的多个 UE 的不同 CFO。
CFO 补偿仅应用于 PUSCH。它至少需要 2 个 DMRS 符号。如果超过两个 DMRS 符号可用,则仅使用 2 个。
最大 CFO 校正限制为 \(\frac{1}{2L}\Delta f\),其中 L 是 DMRS 符号之间的最大间隔,\(\Delta f\) 是子载波间隔。
仅应用相位校正。CFO 导致的 ICI 不会被补偿。
下面,我们公式化用于 CFO 补偿的解决方案。为简单起见,我们假设单个 UE。接收到的 OFDM 信号可以表示为
其中 \(n\) 是时间样本索引,\(k\) 是子载波索引。\(X_{k}\) 是发射的 QAM 符号,\(H_{k}\) 是子载波 \(k\) 上的信道系数。\(\epsilon\) 是 CFO。
在 FFT 之后,我们获得以下内容
项 \(I_{k\,}\) 表示 ICI,由下式给出
ICI 降低了接收信号的 EVM,可以表示为如下形式(对于归一化信号/信道)
此外,CFO 会导致接收符号中的线性相位变化,如下所示
其中 \(Y_{1k}\) 和 \(Y_{2k}\) 分别是符号 1 和 2 上子载波 \(k\) 上的接收信号。请注意,符号索引与其在时隙中的实际位置不对应(即,它们在时隙中可能不是连续的)。
CFO 的最大似然估计器可以如下获得 [12]
其中 \(k_{i}\) 是 PUSCH 传输中分配的 RE 集合。
最大可校正偏移为 0.5/L,其中 L 是符号之间的时域间隔。Aerial 算法使用 DMRS 符号进行 CFO 估计,这需要在时隙中配置至少两个 DMRS 符号。
PRACH 的前导码检测算法能够处理最大 CFO,而无需任何额外的 CFO 校正。PUCCH 的检测对 CFO 不太敏感,因为调制阶数较低 (QPSK),并且在某些情况下持续时间较短。PUCCH 接收器算法不包括 CFO 校正。如果需要,将来可以为 PUCCH 接收实现 CFO 校正。
定时偏移 (TO) 是由 UE 和 gNB 之间的定时未对准引起的。它会导致信道脉冲响应 (CIR) 的额外延迟。如果 TO 足够大,也可能导致信号失真,因为它会导致 CIR 超过循环前缀。
假设 CIR + TO 的持续时间小于循环前缀,则 TO 将表现为沿频域的线性相位,表示为
将 DMRS 信道估计表示为第 \(p\) 个天线、第 \(l\) 层、第 \(k_{1}\) 个 PRB 和 PRB \(k\) 内的第 \(k_{2}\) 个 RE,\(k_{2} \in \,\left\{ 0,1,\ldots,10 \right\}\),用 \(\widehat{H}\,_{p,l,k_{1},k_{2},n_{d}}\) 表示,其中 \(n_{d}\) 是一个时隙中 \(D\) 个 DMRS 符号中的符号索引。我们可以获得归一化的定时偏移,如下所示
其中
以秒为单位的绝对定时偏移可以获得为
其中 \(\mu\, = \,\left\{ 0,1,2,3,4 \right\}\) 是对应于 \(\left\{ 15,\, 30,\, 60,\, 120,\, 240 \right\}\) kHz 子载波频率间隔的 numerology 参数。
输入缓冲区 |
PuschRx::m_tRefHEstVec[i] 此缓冲区从信道估计内核接收。 注意:索引 i 指的是 PRB 范围(或 UE 组)。 |
输出缓冲区 |
PuschRx:: m_tRefCfoEstVec[i] 注意:索引 i 指的是 PRB 范围(或 UE 组) |
数据类型 |
CUPHY_R_32_F:浮点实数值 |
维度 |
[MAX_ND_SUPPORTED, (UE 数量)] [14, (UE 数量)] |
描述 |
CFO 估计向量。 |
输出缓冲区 |
PuschRx:: m_tRefCfoHz |
数据类型 |
CUPHY_R_32_F:浮点实数值。 |
维度 |
[1, (UE 数量)] |
描述 |
以 Hz 为单位的 CFO 估计值。 |
输出缓冲区 |
PuschRx:: m_tRefTaEst |
数据类型 |
CUPHY_R_32_F:浮点实数值。 |
维度 |
[1, (UE 数量)] |
描述 |
定时偏移估计。 |
输出缓冲区 |
PuschRx:: m_tRefCfoPhaseRot |
数据类型 |
CUPHY_C_32_F:浮点复数值。 |
维度 |
[CUPHY_PUSCH_RX_MAX_N_TIME_CH_EST, CUPHY_PUSCH_RX_MAX_N_LAYERS_PER_UE_GROUP, MAX_N_USER_GROUPS_SUPPORTED] [(时域中信道估计的最大数量,=4), (每个 UE 组的最大层数,=8), (最大 UE 组数,=128)] |
描述 |
载波偏移相位旋转值 |
输出缓冲区 |
PuschRx:: m_tRefTaPhaseRot |
数据类型 |
CUPHY_C_32_F:浮点复数值。 |
维度 |
[1, CUPHY_PUSCH_RX_MAX_N_LAYERS_PER_UE_GROUP] : [1, (每个 UE 组的最大层数,=8)] |
描述 |
载波偏移相位旋转值 |
软解映射器#
均衡后,根据以下 QAM 符号表计算每个比特的 LLR:\(Z_{r}\, + \, Z_{j}\),其中 \(Z_{r}\) 和 \(Z_{j}\) 是符号的实部和虚部。每个比特的 LLR 将通过每个符号的 postEqMSE 进行缩放,作为软解映射器的输出。
\(A\) |
实部比特的 LLR |
虚部比特的 LLR |
|
|---|---|---|---|
4QAM |
\[\frac{1}{\sqrt{2}}\]
|
\[\lambda_{c_{0}}\, = \, Z_{r}\]
|
\[\lambda_{c_{0}}\, = \, Z_{i}\]
|
16QAM |
\[\frac{1}{\sqrt{10}}\]
|
\[\lambda_{c_{0}}\, = \, Z_{r}\]
\[\lambda_{c_{1}}\, = \, - \left| Z_{r} \right| + 2A\]
|
\[\lambda_{c_{0}}\, = \, Z_{i}\]
\[\lambda_{c_{1}}\, = \, - \left| Z_{i} \right| + 2A\]
|
64QAM |
\[\frac{1}{\sqrt{42}}\]
|
\[\lambda_{c_{0}}\, = \, Z_{r}\]
\[\lambda_{c_{1}}\, = \, - \left| Z_{r} \right| + 4A\]
\[\lambda_{c_{2}}\, = \, - \left| \left| Z_{r} \right| - 4A \right| + 2A\]
|
\[\lambda_{c_{0}}\, = \, Z_{i}\]
\[\lambda_{c_{1}}\, = \, - \left| Z_{i} \right| + 4A\]
\[\lambda_{c_{2}}\, = \, - \left| \left| Z_ {i} \right| - 4A \right| + 2A\]
|
256QAM |
\[\frac{1}{\sqrt{170}}\]
|
\[\lambda_{c_{0}}\, = \, Z_{r}\]
\[\lambda_{c_{1}}\, = \, - \left| Z_{r} \right| + 8A\]
\[\lambda_{c_{2}}\, = \, - \left| \left| Z_{r} \right| - 8A \right| + 4A\]
\[\lambda_{c_{3}}\, = \, - \left| \left| \left| Z_{r} \right| - 8A \right| - 4A \right| + 2A\]
|
\[\lambda_{c_{0}}\, = \, Z_{i}\]
\[\lambda_{c_{1}}\, = \, - \left| Z_{i} \right| + 8A\]
\[\lambda_{c_{2}}\, = \, - \left| \left| Z_{i} \right| - 8A \right| + 4A\]
\[\lambda_{c_{3}}\, = \, - \left| \left| \left| Z_{i} \right| - 8A \right| - 4A \right| + 2A\]
|
信道均衡系数计算内核 |
|
|---|---|
输入缓冲区 |
这些缓冲区从噪声和干扰协方差估计、信道估计和 CFO 估计内核接收。 注意:索引 |
输出缓冲区 |
注意:索引 |
数据类型 |
CUPHY_R_32_F:浮点实数值 |
维度 |
[CUPHY_N_TONES_PER_PRB, NUM_LAYERS, NUM_PRBS, nTimeChEq ]: [12*(PRB 数量), (层数), (PRB 数量), (时域估计数量)] |
描述 |
信道均衡器残余误差向量。 |
输出缓冲区 |
注意:索引 |
数据类型 |
|
维度 |
[NUM_ANTENNAS, CUPHY_N_TONES_PER_PRB, NUM_LAYERS, NUM_PRBS, NH ]: [(接收天线数量), 12*(PRB 数量), (层数), (PRB 数量), (DMRS 位置数量)] |
描述 |
信道均衡器系数。 |
信道均衡 MMSE 软解映射内核 |
|
|---|---|
输入缓冲区 |
这些缓冲区从噪声和干扰协方差估计、信道估计和 CFO 估计内核接收。 注意:索引 i 指的是 PRB 范围(或 UE 组)。 |
输出缓冲区 |
注意:索引 i 指的是 PRB 范围(或 UE 组) |
数据类型 |
|
维度 |
[NUM_LAYERS, NF, NUM_DATA_SYMS ]: [(层数), 12*(PRB 数量), (数据 OFDM 符号数量)] |
描述 |
均衡后的 QAM 数据符号。 |
输出缓冲区 |
注意:索引 |
数据类型 |
CUPHY_R_16_F:半精度浮点实数采样的张量向量。 |
维度 |
[CUPHY_QAM_256, NUM_LAYERS, NF, NUM_DATA_SYMBOLS ]: [(256QAM 的比特数 = 8), (层数), (层数), 12*(PRB 数量), (数据 OFDM 符号数量)] |
描述 |
输出 LLR 或软比特。如果 PUSCH 上启用 UCI,则使用。 |
输出缓冲区 |
注意:指的是 PRB 范围(或 UE 组)索引 i |
数据类型 |
|
维度 |
[CUPHY_QAM_256, NUM_LAYERS, NF, NUM_DATA_SYMBOLS ]: [(256QAM 的比特数 = 8), (层数), (层数), 12*(PRB 数量), (数据 OFDM 符号数量)] |
描述 |
输出 LLR 或软比特。如果没有 PUSCH 上的 UCI,则使用。 |
解速率匹配和解扰#
输入缓冲区 |
|
输出缓冲区 |
|
数据类型 |
uint8_t |
维度 |
TB 大小和 TB 数量的函数。 |
描述 |
速率匹配/解扰输出。它位于主机固定的 GPU 内存上。它映射到 |
RSSI 估计#
RSSI 是根据接收信号计算的,方法是首先计算每个 RE 和每个接收天线上的接收信号功率。然后通过对频率资源和接收天线上的接收功率求和来计算总功率。然后,通过对 DMRS 符号进行平均来获得 RSSI,如 SCF FAPI 规范中所定义。
RSSI 计算如下
其中 \(Y_{p,\, k,\, n_{d}}\) 是第 \(p`\) 个接收天线、第 \(k\) 个子载波和第 \(d\) 个 DMRS 符号的第 \(n_{d}`\) 个 OFDM 符号的接收信号。
输入缓冲区 |
PuschRx:: m_drvdUeGrpPrmsCpu[i].tInfoDataRx |
输出缓冲区 |
PuschRx:: m_tRefRssiFull |
数据类型 |
CUPHY_R_32_F:浮点实数采样的张量向量。 |
维度 |
[MAX_ND_SUPPORTED, MAX_N_ANTENNAS_SUPPORTED , nUEgroups] [(时域估计的最大数量,=14), (天线的最大数量,=64), (UE 组数)] |
描述 |
测量的 RSSI(每个符号、每个天线、每个 UE 组)。 |
输出缓冲区 |
PuschRx:: m_tRefRssi |
数据类型 |
CUPHY_R_32_F:浮点实数采样的张量向量。 |
维度 |
[1, nUEgroups]:[1, (UE 组数)] |
描述 |
每个 UE 组测量的 RSSI。 |
RSRP 和 SINR 估计#
RSRP 计算如下
其中 \(H_{p,l,k,n_{d}}\) 是估计的信道频率响应,针对
第 \(p\) 个接收天线、第 \(l\) 层、第 \(k\) 个子载波和第 \(D\) 个 DMRS 符号的第 \(n_{d}\) 个 OFDM 符号。在等式中,\(P\) 是接收天线的总数,\(K\) 是子载波的总数,\(D\) 是一个时隙中 DMRS 符号的总数。
为了获得 SINR 估计,我们首先获得噪声信号,如下所示
其中 \(Y_{p,k_{DMRS},n_{d}}\,\) 是第 \(p\) 个接收天线、第 \(k_{DMRS}\) 个 DMRS 子载波和第 \(n_{d}\) 个 DMRS 符号的接收信号。\(H_{p,l,k_{DMRS},n_{d}}\,\) 是第 \(p\) 个接收天线、第 \(l\) 层、第 \(k_{DMRS}\) 个 DMRS 子载波和第 \(d\) 个 DMRS 符号的第 \(n_{d}\,\) 个 OFDM 符号的估计信道响应。\(X_{DMRS,l}\) 是第 \(l\) 层的 DMRS 符号。
然后可以估计噪声方差,如下所示
其中 \(P\) 是接收天线的总数,\(K_{DMRS}\) 是 DMRS 符号中子载波的总数。为了补偿信道估计滤波器导致的噪声功率估计降低,将校正因子(此处未显示)添加到噪声方差中。然后可以通过 \(SINR\, = \,\frac{1}{\sigma_{noise}^{2}}\) 获得 SINR
输入缓冲区 |
PuschRx::m_tRefHEstVec[i], PuschRx:: m_tRefReeDiagInvVec[i], PuschRx:: m_tRefNoiseVarPreEq |
输出缓冲区 |
PuschRx:: m_tRefRsrp |
数据类型 |
CUPHY_R_32_F:浮点实数采样的张量向量。 |
维度 |
[1, nUEgroups]:[1, (UE 组数)] |
描述 |
跨 UE 的 RSRP 值。 |
输出缓冲区 |
PuschRx:: m_tRefNoiseVarPostEq |
数据类型 |
CUPHY_R_32_F:浮点实数采样的张量向量。 |
维度 |
[1, nUEgroups]:[1, (UE 组数)] |
描述 |
跨 UE 的均衡后噪声方差 |
输出缓冲区 |
PuschRx:: m_tRefSinrPreEq |
数据类型 |
CUPHY_R_32_F:浮点实数采样的张量向量。 |
维度 |
[1, nUEgroups]:[1, (UE 组数)] |
描述 |
跨 UE 的均衡前 SINR 值。 |
输出缓冲区 |
PuschRx:: m_tRefSinrPostEq |
数据类型 |
CUPHY_R_32_F:浮点实数采样的张量向量。 |
维度 |
[1, nUEgroups]:[1, (UE 组数)] |
描述 |
跨 UE 的均衡后 SINR 值。 |
PUSCH 上的 UCI 解码器#
如果在 PUSCH 信道上配置了 UCI,则软解映射器的输出首先经过解分割,以分离 HARQ、CSI part 1 和 CSI part 2 以及 SCH 软比特(或 LLR)。此初始步骤由内核 uciOnPuschSegLLRs0Kernel() 完成。
如果存在 CSI-part2,则启动 CSI-part2 控制内核,如下图中的虚线框所示。此内核确定 CSI-part2 比特和速率匹配比特的数量,并选择正确的解码器内核并启动其设置函数。
CSI-part2 负载的解分割由 uciOnPuschSegLLRs2Kernel() 内核完成,该内核分离 CSI-part2 UCI 和 SCH 软比特。
UCI 在 PUSCH 上的第一阶段解分割 |
|
|---|---|
输入缓冲区 |
PuschRx:: m_tPrmLLRVec[i] |
输出缓冲区 |
PuschRx::m_pTbPrmsGpu->pUePrmsGpu[i].d_harqLLrs; |
数据类型 |
__half* |
维度 |
单维数组,大小取决于负载。 |
描述 |
HARQ 软比特。 |
输出缓冲区 |
PuschRx::m_pTbPrmsGpu->pUePrmsGpu[ueIdx].d_csi1LLRs; |
数据类型 |
__half* |
维度 |
单维数组,大小取决于负载。 |
描述 |
CSI part 1 软比特。 |
输出缓冲区 |
PuschRx::m_pTbPrmsGpu->pUePrmsGpu[i]. d_schAndCsi2LLRs |
数据类型 |
__half* |
维度 |
单维数组,大小取决于负载。 |
描述 |
共享信道 (SCH) 和 CSI part 2 软比特。 |
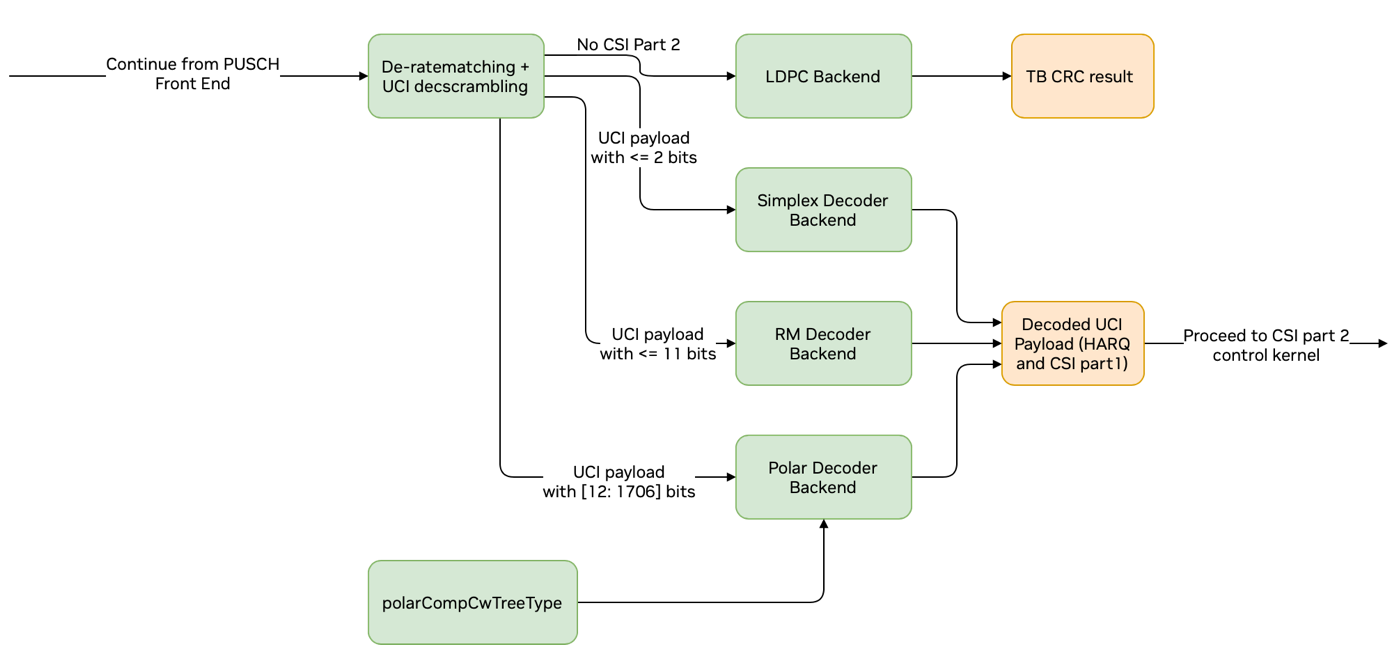
PUSCH 和 CSI Part 1 解码的图表#
UCI 在 PUSCH 上的第二阶段解分割 |
|
|---|---|
输入缓冲区 |
PuschRx:: m_tPrmLLRVec[i] |
输出缓冲区 |
P uschRx::m_pTbPrmsGpu->pUePrmsGpu[i].d_schAndCsi2LLRs; |
数据类型 |
__half* |
维度 |
单维数组,大小取决于负载。 |
描述 |
指向 SCH 软比特的指针 |
输出缓冲区 |
PuschRx::m_pTbPrmsGpu->pUePrmsGpu[i].d_schAndCsi2LLRs + PuschRx::m_pTbPrmsGpu->pUePrmsGpu[i].G; |
数据类型 |
__half* |
维度 |
单维数组,大小取决于负载。 |
描述 |
指向 CSI part2 软比特的指针 |
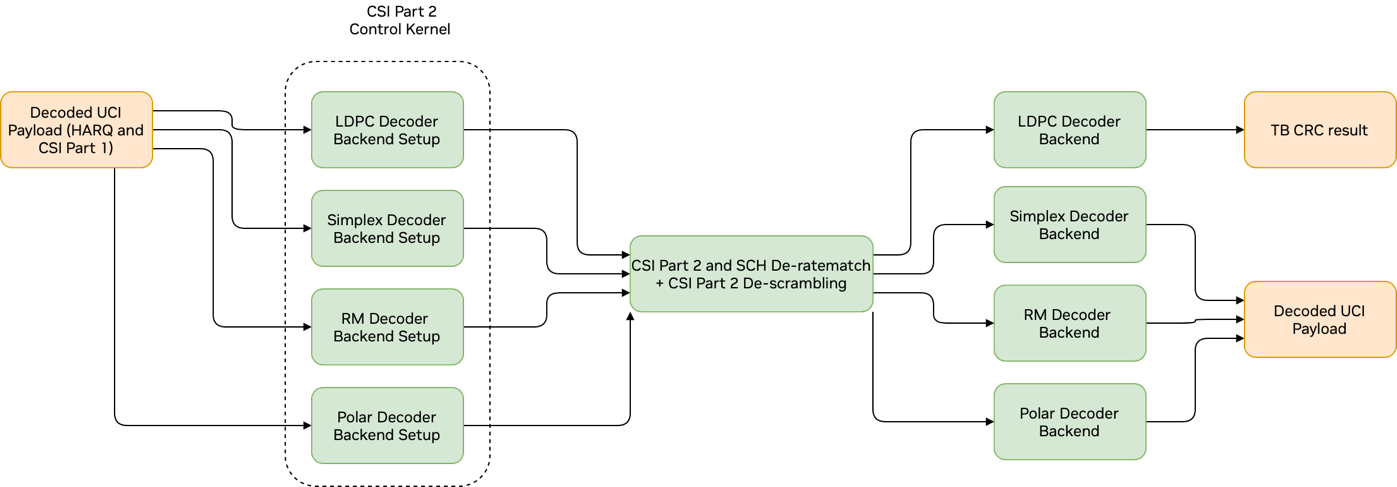
PUSCH 和 CSI Part 2 解码的图表#
Simplex 解码器#
Simplex 解码器实现最大似然 (ML) 解码器。它接收输入 LLR 并输出估计的码字。它还会报告 HARQ DTX 状态。
输入缓冲区 |
PuschRx:: m_pSpxCwPrmsCpu[spxCwIdx].d_LLRs |
数据类型 |
__half* |
维度 |
单维数组,大小取决于负载。 |
描述 |
指向输入 LLR 的指针 |
输出缓冲区 |
PuschRx:: m_pSpxCwPrmsCpu[spxCwIdx].d_cbEst |
数据类型 |
uint32_t* |
维度 |
单维数组,大小取决于负载。 |
描述 |
解码后的 UCI 负载。 |
输出缓冲区 |
PuschRx:: m_pSpxCwPrmsCpu[spxCwIdx].d_DTXStatus |
数据类型 |
Uint8_t* |
维度 |
参数。 |
描述 |
指向 HARQ 检测状态的指针。 |
Reed Muller (RM) 解码器#
RM 解码器实现最大似然 (ML) 解码器。它接收输入 LLR 并输出估计的码字。它还会报告 HARQ DTX 状态。
输入缓冲区 |
PuschRx:: m_pSpxCwPrmsCpu[rmCwIdx].d_LLRs |
数据类型 |
__half* |
维度 |
单维数组,大小取决于负载。 |
描述 |
指向输入 LLR 的指针 |
输出缓冲区 |
PuschRx:: m_pSpxCwPrmsCpu[rmCwIdx].d_cbEst |
数据类型 |
uint32_t* |
维度 |
单维数组,大小取决于负载。 |
描述 |
解码后的 UCI 负载。 |
输出缓冲区 |
PuschRx:: m_pSpxCwPrmsCpu[rmCwIdx].d_DTXStatus |
数据类型 |
Uint8_t* |
维度 |
参数。 |
描述 |
指向 HARQ 检测状态的指针。 |
Polar 解码器#
Polar 解码器使用带有树剪枝的 CRC 辅助列表解码器。在 Polar 码的解码中使用了许多解码算法的变体。有关相关工作,请参阅 [2, 3]。cuPHY 中的确切实现针对 GPU 架构进行了优化。
树剪枝算法将叶节点组合在一起,这是一种更适合并行执行解码的数据结构。因此,它更适合 GPU 架构。在树剪枝算法中,有不同的方法来形成叶节点。在我们的实现中,我们使用 rate-0 和 rate-1 叶码字。在 rate-0 叶节点中,多个比特始终被冻结并且为零,而在 rate-1 叶节点中,没有冻结比特。在 rate-1 码字中,LLR 可以并行解码。
树剪枝由 compCwTreeTypesKernel() 在 Polar 解码器内核接收输入 LLR 之前完成。
如果列表大小等于 1,则运行 polarDecoderKernel();如果列表大小大于 1,则运行 listPolarDecoderKernel()。
输入缓冲区 |
PuschRx:: m_cwTreeLLRsAddrVec |
数据类型 |
__half* |
维度 |
单维数组,大小取决于负载。 |
描述 |
指向 LLR 地址的码字树的指针。 |
输出缓冲区 |
PuschRx:: m_cbEstAddrVec |
数据类型 |
uint32_t* |
维度 |
单维数组,大小取决于负载。 |
描述 |
指向估计的 CB 地址的指针。 |
LDPC 解码器#
LDPC 解码器使用归一化分层最小和算法 [1] 实现,并且它使用半精度浮点 (FP16) 数据类型作为对数似然比 (LLR) 度量。
输入缓冲区 |
PuschRx:: m_LDPCDecodeDescSet.llr_input[m_LDPCDecodeDescSet .num_tbs] 第一个地址也映射到 PuschRx::m_pHarqBuffers[ueIdx] |
数据类型 |
cuphyTransportBlockLLRDesc_t |
维度 |
单维数组,大小取决于有效 TB 描述符的数量。最大大小为 32。 |
描述 |
输入 LLR 缓冲区。 |
输出缓冲区 |
PuschRx:: m_LDPCDecodeDescSet.tb_output[m_LDPCDecodeDescSet .num_tbs] 第一个地址也映射到 PuschRx::d_LDPCOut + 偏移量 偏移量是 UE 索引和每个 UE 的码字数量的函数。 |
数据类型 |
cuphyTransportBlockDataDesc_t |
维度 |
单维数组,大小取决于有效 TB 描述符的数量。 |
描述 |
指向估计的 TB 地址的指针。 |
CRC 解码器#
代码块 CRC 解码器内核 |
|
|---|---|
输入缓冲区 |
PuschRx::d_pLDPCOut, PuschRx:: m_pTbPrmsGpu |
描述 |
LDPC 解码器输出和解码 CRC 所需的 TB 参数。 |
输出缓冲区 |
PuschRx:: m_outputPrms.pCbCrcsDevice; |
数据类型 |
uint32_t |
维度 |
[1, CB 总数(跨 UE)] |
描述 |
CRC 输出。 |
输出缓冲区 |
PuschRx:: m_outputPrms.pTbPayloadsDevice |
数据类型 |
Uint8_t |
维度 |
[1, TB 负载字节总数] |
描述 |
TB 负载。 |
传输块 CRC 解码器内核 |
|
输入缓冲区 |
PuschRx:: m_outputPrms.pTbPayloadsDevice, PuschRx:: m_pTbPrmsGpu |
输出缓冲区 |
PuschRx:: m_outputPrms.pTbCrcsDevice |
数据类型 |
uint32_t |
维度 |
[1, TB 总数(跨 UE)] |
描述 |
TB CRC 输出。 |
PUCCH 流水线#
PUCCH 流水线可以分为逻辑阶段。第一个阶段,前端处理,对于每种 PUCCH 格式都是唯一的,并且涉及解扰和解调以恢复发射的符号。对于格式 0 和 1,这是唯一执行的阶段,因为不需要解码来恢复数据。对于格式 2 和 3,接下来进行解码。这里,使用的内核与 PUSCH 中用于相同解码类型的内核相同。最后,解码后的数据被分割为 HARQ、SR 和 CSI 负载。
负责前端处理的内核如下
pucchF0RxKernel
pucchF1RxKernel
pucchF2RxKernel
pucchF3RxKernel
每个内核分别对应于格式 0 到 3。对于格式 0 和 1,硬判决作为解调的一部分进行,以恢复 1 或 2 个负载比特,具体取决于特定配置。对于格式 2 和 3,从解调中恢复 LLR,并用于解码。每个前端处理内核还计算 RSSI 和 RSRP,并使用 DMRS 执行 SINR、干扰和定时提前估计。
对于格式 2 和 3,长度小于 12 比特的负载由 Reed Muller 解码器内核处理。12 比特及更大的负载由解速率匹配和解交织内核 (polSegDeRmDeItlKernel) 处理,然后由 polar 解码器内核处理。
最后,格式 2 和 3 解码后的负载由分割内核 (pucchF234UciSegKernel) 分割,以恢复相应的 HARQ、SR 和 CSI 负载。
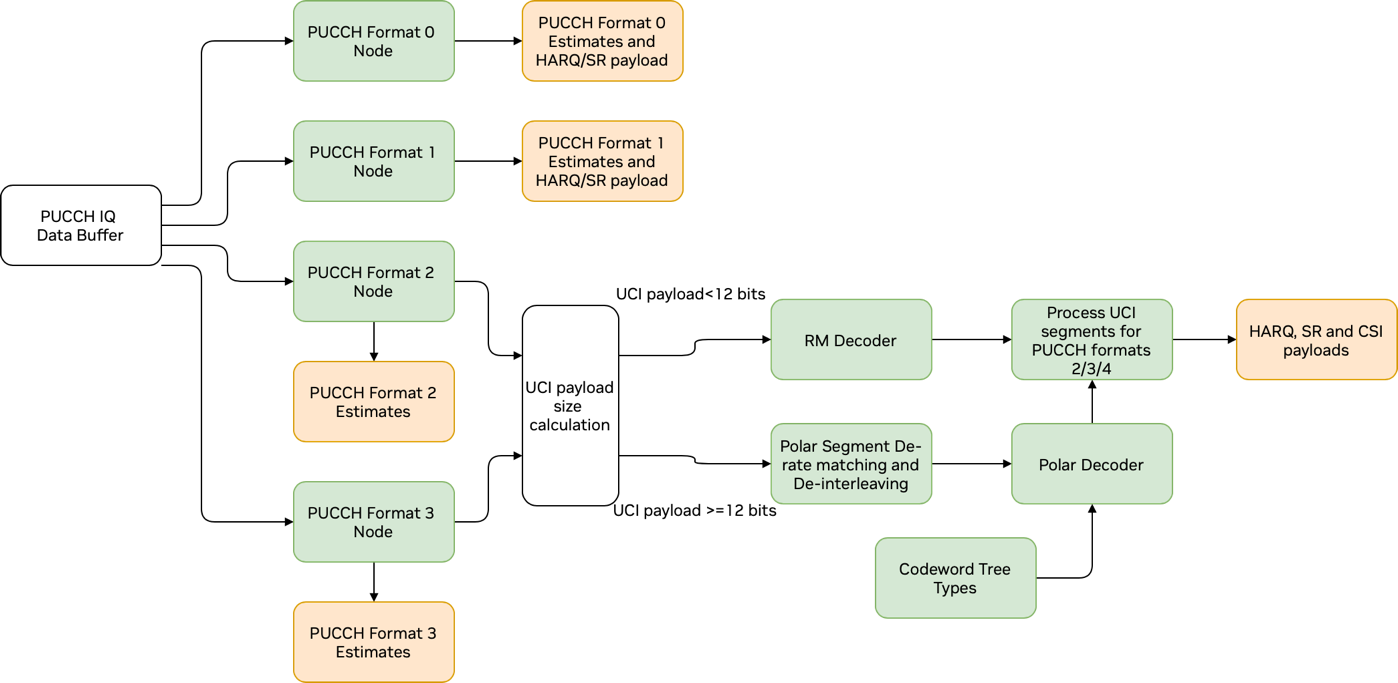
PUCCH 流水线的图表#
输入缓冲区 |
PucchRx::m_tPrmDataRxBufCpu[i].tInfoDataRx |
数据类型 |
CUPHY_C_16_F:IQ 采样的张量向量 |
维度 |
[(ORAN_MAX_PRB*CUPHY_N_TONES_PER_PRB), OFDM_SYMBOLS_PER_SLOT, MAX_AP_PER_SLOT] |
输出缓冲区 |
PucchRx::m_outputPrms.pF0UciOutGpu |
数据类型 |
cuphyPucchF0F1UciOut_t* |
维度 |
长度等于格式 0 UCI 数量的单维数组 |
描述 |
HARQ 值和估计器测量值,包括每个 UCI 的 SINR、干扰、RSSI、RSRP(以 dB 为单位)和定时提前(以 uSec 为单位) |
输出缓冲区 |
PucchRx::m_outputPrms.pF0UciOutGpu |
数据类型 |
cuphyPucchF0F1UciOut_t* |
维度 |
长度等于格式 1 UCI 数量的单维数组 |
描述 |
HARQ 值和估计器测量值,包括每个 UCI 的 SINR、干扰、RSSI、RSRP(以 dB 为单位)和定时提前(以 uSec 为单位) |
输出缓冲区 |
PucchRx:: m_tSinr |
数据类型 |
CUPHY_R_32_F:浮点数值的张量向量。 |
维度 |
[(格式 2 和 3 UCI 的数量)] |
描述 |
每个 UCI 测量的 SINR(以 dB 为单位) |
输出缓冲区 |
PucchRx:: m_tRssi |
数据类型 |
CUPHY_R_32_F:浮点数值的张量向量。 |
维度 |
[(格式 2 和 3 UCI 的数量)] |
描述 |
每个 UCI 测量的 RSSI(以 dB 为单位) |
输出缓冲区 |
PucchRx:: m_tRsrp |
数据类型 |
CUPHY_R_32_F:浮点数值的张量向量。 |
维度 |
[(格式 2 和 3 UCI 的数量)] |
描述 |
每个 UCI 测量的 RSRP(以 dB 为单位) |
输出缓冲区 |
PucchRx:: m_tInterf |
数据类型 |
CUPHY_R_32_F:浮点数值的张量向量。 |
维度 |
[(格式 2 和 3 UCI 的数量)] |
描述 |
每个 UCI 测量的干扰(以 dB 为单位) |
输出缓冲区 |
PucchRx:: m_tNoiseVar |
数据类型 |
CUPHY_R_32_F:浮点数值的张量向量。 |
维度 |
[(格式 2 和 3 UCI 的数量)] |
描述 |
每个 UCI 测量的噪声方差(以 dB 为单位) |
输出缓冲区 |
PucchRx:: m_tTaEst |
数据类型 |
CUPHY_R_32_F:浮点数值的张量向量。 |
维度 |
[(格式 2 和 3 UCI 的数量)] |
描述 |
每个 UCI 测量的定时提前(以 uSec 为单位) |
输出缓冲区 |
PucchRx::m_tUciPayload |
数据类型 |
CUPHY_R_8U:无符号字节的张量向量 |
维度 |
[(格式 2 和 3 UCI 的负载字节总数,向上舍入到每个负载的 4 字节字)] |
描述 |
格式 2 和 3 UCI 负载,舍入为 4 字节字。如果 1 个 UCI 具有 HARQ 和 CSI-P1,每个 1 比特,它们将各自获得一个 4 字节字,总共 8 字节。 |
输出缓冲区 |
PucchRx:: m_tHarqDetectionStatus |
数据类型 |
CUPHY_R_8U:无符号字节的张量向量 |
维度 |
[(格式 2 和 3 UCI 的数量)] |
描述 |
HARQ 检测状态 |
输出缓冲区 |
PucchRx:: m_tCsiP1DetectionStatus |
数据类型 |
CUPHY_R_8U:无符号字节的张量向量 |
维度 |
[(格式 2 和 3 UCI 的数量)] |
描述 |
CSI Part 1 检测状态 |
输出缓冲区 |
PucchRx:: m_tCsiP2DetectionStatus |
数据类型 |
CUPHY_R_8U:无符号字节的张量向量 |
维度 |
[(格式 2 和 3 UCI 的数量)] |
描述 |
CSI Part 2 检测状态 |
PRACH 流水线#
PRACH 流水线使用为每次场合分割的 IQ 采样,并对配置的 PRACH 信号执行检测和估计。此过程跨多个内核运行,如下所示
prach_compute_correlation 内核接收输入 IQ 数据,并执行重复之间的平均,然后对预期 PRACH 信号的参考版本执行时域相关(在频域中完成)。此内核同时在每个 PRACH 场合上运行。
逆 FFT 内核将频域相关结果转换为时域。单独的内核在每次场合上运行。
prach_compute_pdp 内核对每个前导码区域的相关结果执行非相干组合。然后,它计算每个前导码区域的功率以及峰值索引和值。
prach_search_pdp 内核计算前导码和噪声功率估计,并报告具有峰值功率的前导码索引。它还执行基于阈值的检测声明。
还有一组单独的内核作为 PRACH 流水线的一部分,用于执行 RSSI 计算。
memsetRssi 内核清除用于计算 RSSI 的设备缓冲区。
prach_compute_rssi 内核计算每个 PRACH 场合的 RSSI,包括每个天线的 RSSI 和所有天线的平均功率
memcpyRssi 内核将 RSSI 结果存储在主机可访问的内存中
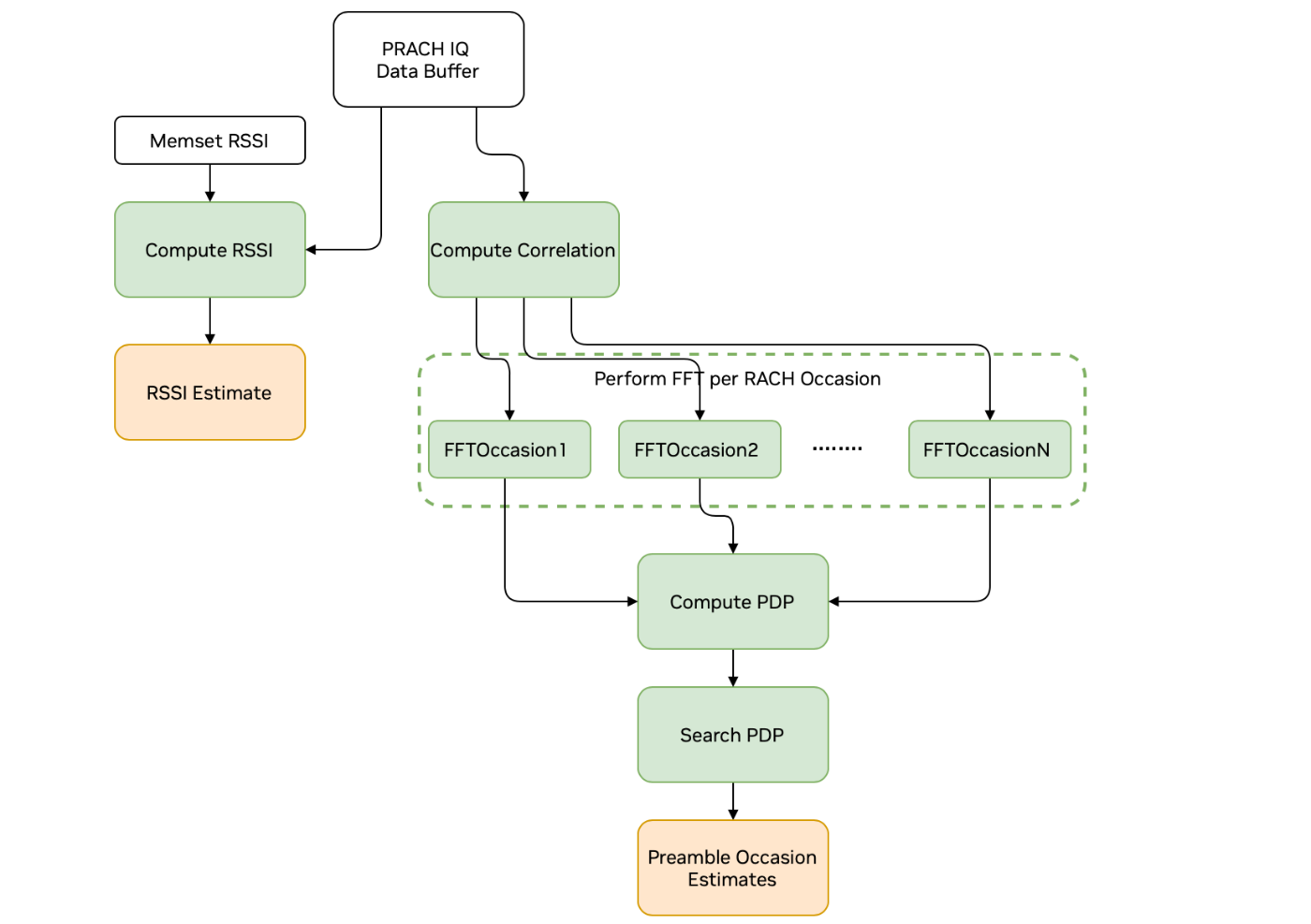
PRACH 流水线的图表#
输入缓冲区 |
PrachRx:: h_dynParam[i].dataRx |
数据类型 |
CUPHY_C_16_F:每个场合缓冲区的张量 |
维度 |
[(前导码长度+5)*重复次数,N_ant] |
输出缓冲区 |
PrachRx:: numDetectedPrmb |
数据类型 |
CUPHY_R_32U:uint32 的张量向量 |
维度 |
[1, PRACH_MAX_OCCASIONS_AGGR] |
描述 |
每次场合检测到的前导码数量 |
输出缓冲区 |
PrachRx:: prmbIndexEstimates |
数据类型 |
CUPHY_R_32U:uint32 的张量向量 |
维度 |
[PRACH_MAX_NUM_PREAMBLES, PRACH_MAX_OCCASIONS_AGGR] |
描述 |
每次前导码和场合检测到的前导码索引 |
输出缓冲区 |
PrachRx:: prmbDelayEstimates |
数据类型 |
CUPHY_R_32_F:浮点数值的张量向量 |
维度 |
[PRACH_MAX_NUM_PREAMBLES, PRACH_MAX_OCCASIONS_AGGR] |
描述 |
每次前导码和场合的延迟估计 |
输出缓冲区 |
PrachRx:: prmbPowerEstimates |
数据类型 |
CUPHY_R_32_F:浮点数值的张量向量 |
维度 |
[PRACH_MAX_NUM_PREAMBLES, PRACH_MAX_OCCASIONS_AGGR] |
描述 |
每次前导码和场合的功率估计 |
输出缓冲区 |
PrachRx:: antRssi |
数据类型 |
CUPHY_R_32_F:浮点数值的张量向量 |
维度 |
[N_ant, PRACH_MAX_OCCASIONS_AGGR] |
描述 |
每个天线和场合的 RSSI |
输出缓冲区 |
PrachRx:: rssi |
数据类型 |
CUPHY_R_32_F:浮点数值的张量向量 |
维度 |
[1, PRACH_MAX_OCCASIONS_AGGR] |
描述 |
每次场合的 RSSI |
输出缓冲区 |
PrachRx:: interference |
数据类型 |
CUPHY_R_32_F:浮点数值的张量向量 |
维度 |
[1, PRACH_MAX_OCCASIONS_AGGR] |
描述 |
每次场合的干扰 |
输出缓冲区 |
PrachRx:: prmbPowerEstimates |
数据类型 |
CUPHY_R_32_F:浮点数值的张量向量 |
维度 |
[PRACH_MAX_NUM_PREAMBLES, PRACH_MAX_OCCASIONS_AGGR] |
描述 |
每次前导码和场合的功率估计 |
输出缓冲区 |
PrachRx:: antRssi |
数据类型 |
CUPHY_R_32_F:浮点数值的张量向量 |
维度 |
[N_ant, PRACH_MAX_OCCASIONS_AGGR] |
描述 |
每个天线和场合的 RSSI |
输出缓冲区 |
PrachRx:: rssi |
数据类型 |
CUPHY_R_32_F:浮点数值的张量向量 |
维度 |
[1, PRACH_MAX_OCCASIONS_AGGR] |
描述 |
每次场合的 RSSI |
输出缓冲区 |
PrachRx:: interference |
数据类型 |
CUPHY_R_32_F:浮点数值的张量向量 |
维度 |
[1, PRACH_MAX_OCCASIONS_AGGR] |
描述 |
每次场合的干扰 |
SRS 流水线概述#
SRS 流水线实现了蜂窝上行链路传输的信号参考符号 (SRS) 信道估计。该模块以来自 gNB O-RU 天线的接收 IQ 采样作为输入,并输出每个子载波和天线端口的估计信道系数。该模块支持 3GPP 标准指定的不同带宽和传输模式。
SRS 流水线生命周期#
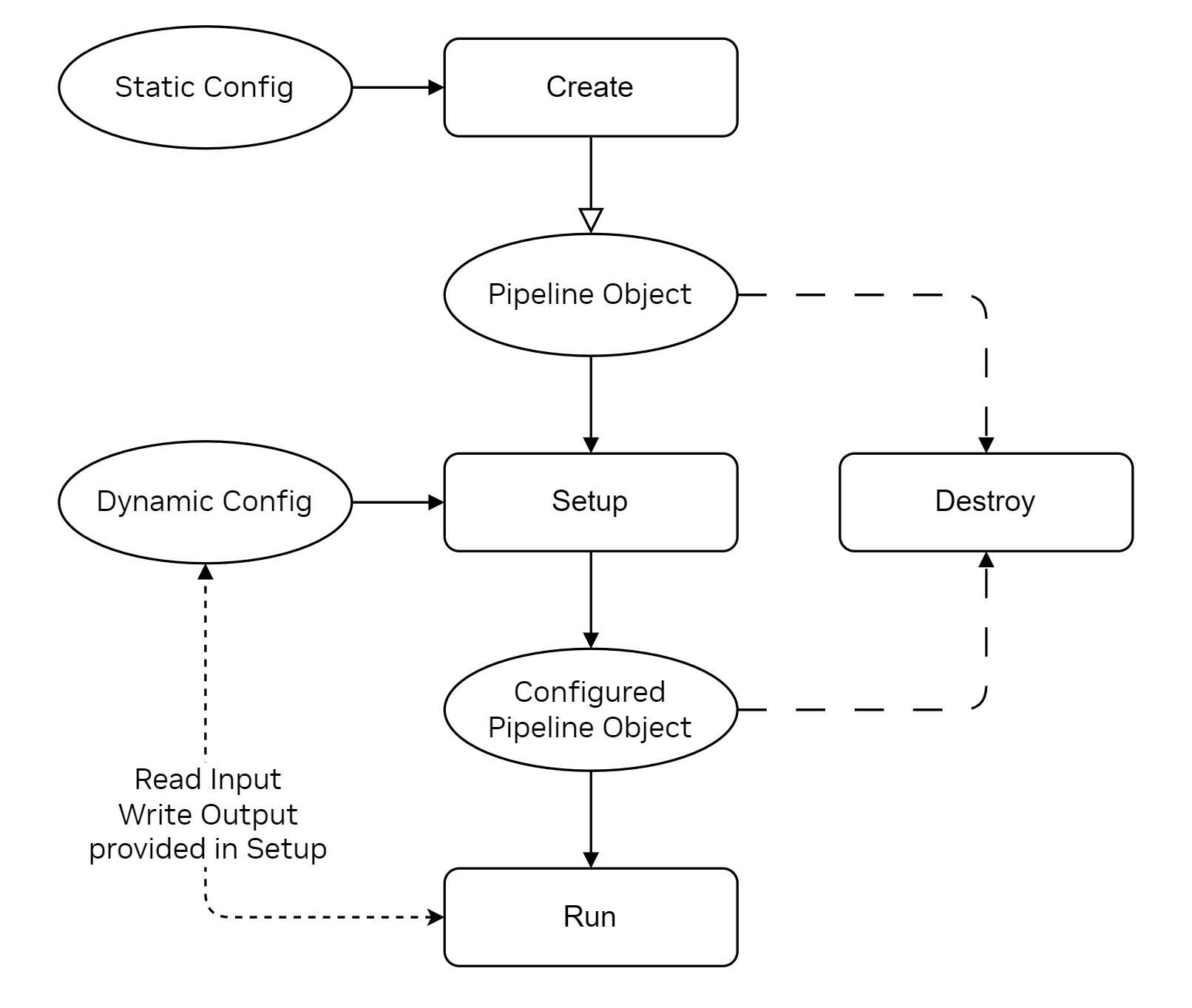
SRS 流水线模块由一个 C++ 类 srsChEst 组成,该类封装了主要功能,以及一个 C API,该 API 提供了外部应用程序的接口。C API 由四个函数组成:cuphyCreateSrsRx()、cuphySetupSrsRx()、cuphyRunSrsRx() 和 cuphyDestroySrsRx()。这些函数中的每一个都对应于流水线生命周期中的一个阶段,分别负责创建、配置、运行和销毁 SRS 流水线实例。
SRS 流水线执行#
SRS 流水线支持图执行,但是该图仅由信道估计内核的单个节点组成。

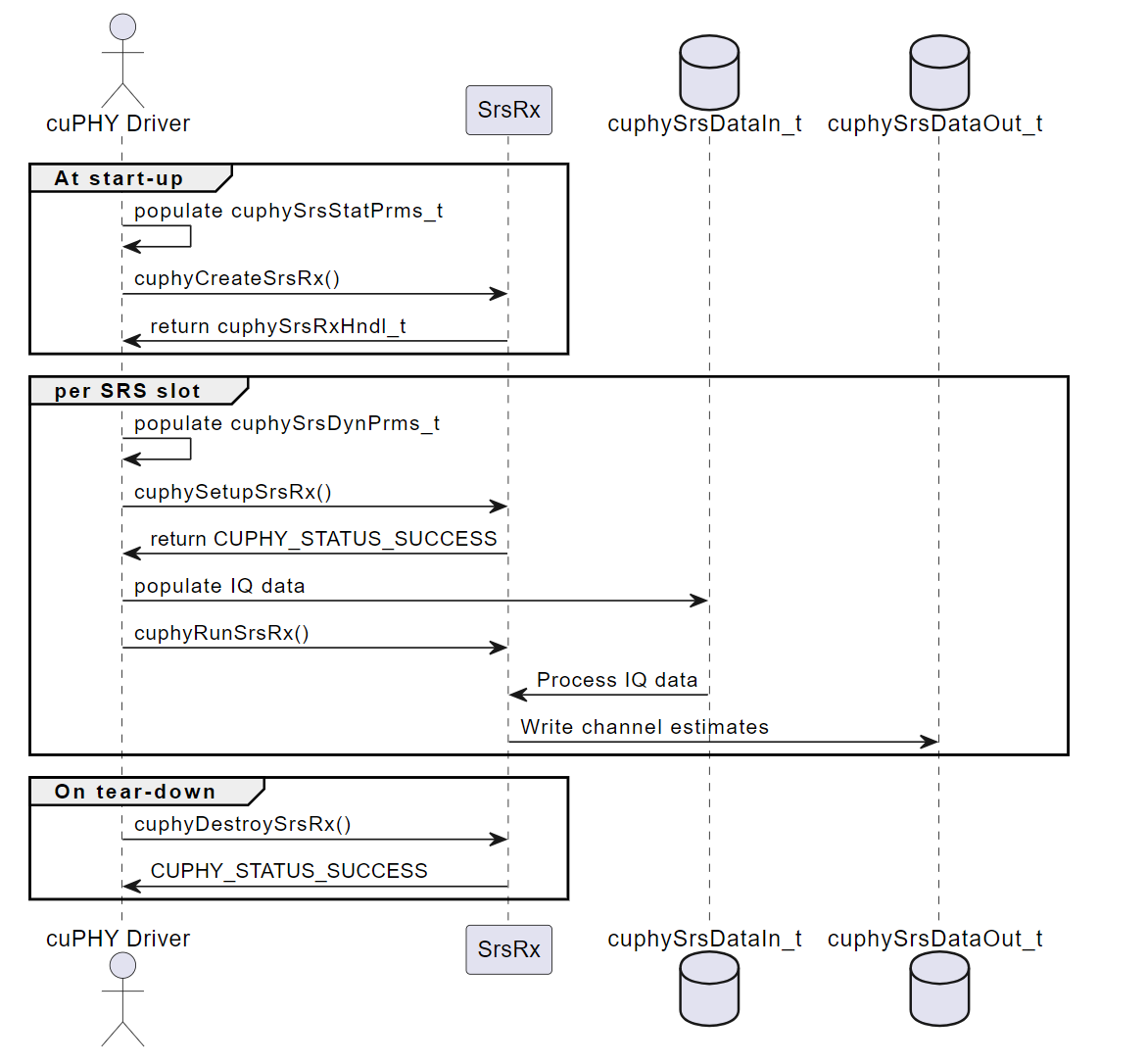
cuphyCreateSrsRx()#
此函数创建 SRS Pipeline 的实例并初始化其内部参数和内存。该函数接受指向 cuphySrsStatPrms_t 类型结构的指针作为输入,该结构包含 SRS Pipeline 的配置参数,这些参数预计在 pipeline 的整个生命周期内保持不变,并确定内存大小调整的上限,例如天线数量和子载波间隔。该函数返回 pipeline 对象的句柄 cuphySrsRxHndl_t,它代表 SRS Pipeline 实例并保存其状态信息。该函数还对输入参数执行一些健全性检查。
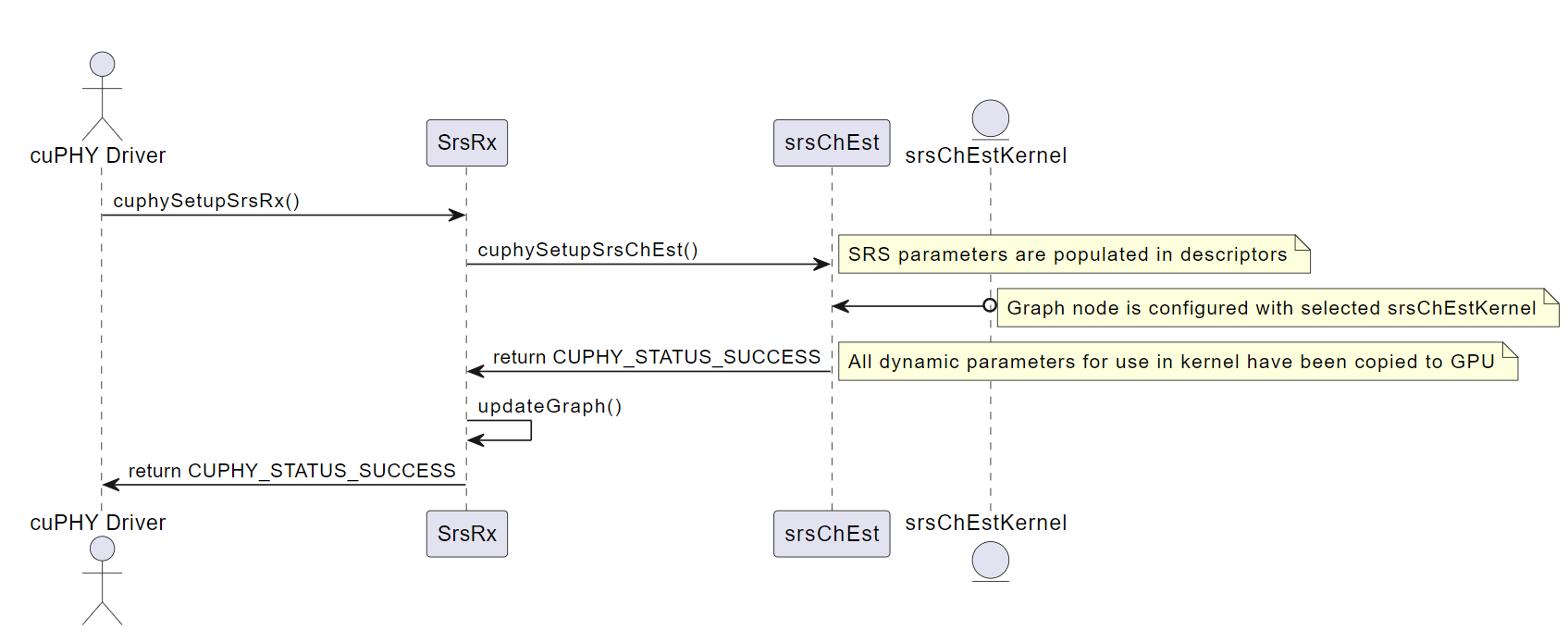
cuphySetupSrsRx()#
此函数使用每次传输的特定参数配置 SRS Pipeline 实例。该函数接受指向 SRS Pipeline 实例的指针和指向 cuphySrsDynPrms_t 类型结构的指针作为输入。该结构包含 SRS Pipeline 的动态参数,例如正在使用的 PRB、SRS 配置索引和 SRS 跳频带宽。该函数从输入数据结构中填充供 SRS 信道估计内核使用的描述符,并设置输入和输出数据的指针,为处理做准备。该函数返回一个状态代码,指示操作是否成功。
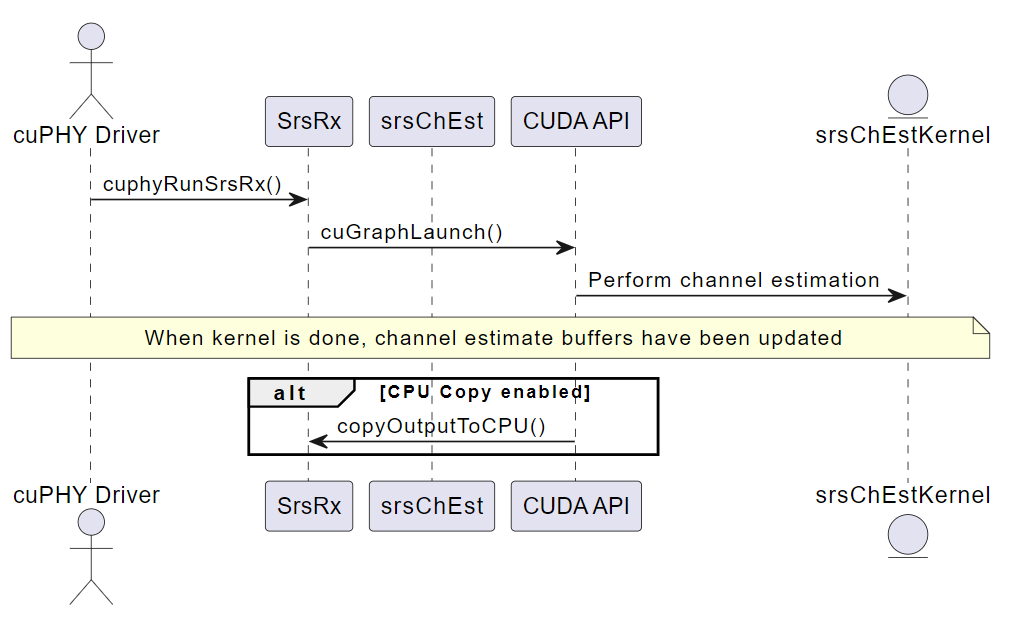
cuphyRunSrsRx()#
此函数在一组给定的 IQ 样本上运行 SRS Pipeline 处理。该函数接受指向 SRS Pipeline 实例的指针。输入数据位置在 cuphySrsDataIn_t 中描述的设置过程中配置,作为 cuphySrsDynPrms_t 结构的一部分。此函数将启动一个内核,该内核配置为从这些位置读取数据以执行信道估计,包括: - 根据 SRS 配置索引和跳频带宽从频域样本中提取 SRS 符号 - 对 SRS 符号应用相位旋转和缩放,以补偿信道效应 - 使用 SRS 符号和已知的 SRS 序列,估计每个子载波和天线端口的信道系数 - 对多个 SRS 符号上的信道估计进行平均,以降低噪声
内核将根据在设置过程中作为 cuphySrsDynPrms_t 一部分提供的 cuphySrsDataOut_t 结构输出信道估计。run 函数还返回一个状态代码,指示处理是否成功。
cuphyDestroySrsRx()#
此函数销毁 SRS Pipeline 实例并释放其资源。该函数接受指向 SRS Pipeline 实例的指针作为输入,并释放其内存。该函数返回一个状态代码,指示操作是否成功。
输入和输出数据#
输入缓冲区 |
SrsRx:: m_hPrmDataRx[i].pTDataRx |
数据类型 |
每个小区的 IQ 样本张量数组,元素类型为 CUPHY_C_16_F |
维度 |
[(ORAN_MAX_PRB*CUPHY_N_TONES_PER_PRB), OFDM_SYMBOLS_PER_SLOT, MAX_AP_PER_SLOT] |
输出缓冲区 |
SrsRx::m_outputPrms.h_chEstBuffInfo |
数据类型 |
cuphySrsChEstBuffInfo_t* |
维度 |
每个用户的结构数组,包含一个 [nPrbGrpEsts, nGnbAnts, nUeAnts] 张量,每个元素为 CUPHY_C_16_F,一个标量指示起始 PRB 组 & PRB 组大小 |
描述 |
描述来自 SRS 的信道估计结果的缓冲区 |
输出缓冲区 |
SrsRx::m_outputPrms.h_srsReports |
数据类型 |
cuphySrsReport_t* |
维度 |
每个用户的结构数组 |
描述 |
结构包含每个用户的估计值,包括定时、信号和噪声估计 |
输出缓冲区 |
SrsRx::m_outputPrms.h_rbSnrBuffer |
数据类型 |
浮点数组 SINR |
维度 |
[m_nPrbs* m_nSrsUes] |
描述 |
包含每个 RB 的 SNR 估计值的数组 |
输出缓冲区 |
SrsRx::m_outputPrms.h_rbSnrBuffOffsets |
数据类型 |
32 位无符号整数数组 |
维度 |
[m_nSrsUes] |
描述 |
包含每个用户到 h_rbSnrBuffer 偏移量的单维数组 |
输出缓冲区 |
SrsRx::m_outputPrms.h_srsChEstToL2 |
数据类型 |
cuphySrsChEstToL2_t* |
维度 |
指向每个用户缓冲区的指针数组。每个缓冲区的维度为 [nPrbGrpEsts, nGnbAnts, nUeAnts],每个元素表示为 float2,一个标量指示起始 PRB 组 & PRB 组大小 |
描述 |
此项和上面的 h_chEstBuffInfo 描述相同的信道估计,但此项位于 CPU 内存中,使用复数 FP32,另一项位于 GPU 内存中,使用 FP16。 |
内存管理#
SRS Pipeline 在其操作中使用不同类型的内存,调用者负责分配和释放其中一些内存。下表总结了 pipeline 使用的内存类型、其所有权、生命周期和位置。
内存类型 |
所有权 |
生命周期 |
位置 |
描述 |
|---|---|---|---|---|
Pipeline 工作内存 |
Pipeline |
在 cuphyCreateSrsRx() 期间分配,在 cuphyDestroySrsRx() 期间释放 |
CPU & GPU |
pipeline 用于其内部处理的内存,例如中间缓冲区、系数等。 |
cuphySrsStatPrms_t |
调用者 |
仅在 cuphyCreateSrsRx() 期间有效 |
CPU |
用于存储 pipeline 的静态参数的内存,例如天线数量、通道等。 |
cuphySrsDynPrms_t |
调用者 |
仅在 cuphySetupSrsRx() 期间有效 |
CPU |
用于存储 pipeline 的动态参数的内存,例如 SRS 带宽配置、输入数据指针、输出缓冲区指针等。 |
cuphySrsDataIn_t |
调用者 |
在 cuphyRunSrsRx() 期间有效 |
GPU |
用于存储 pipeline 输入数据的内存,例如来自天线的 IQ 样本 |
cuphySrsDataOut_t |
调用者 |
在 cuphyRunSrsRx() 之后有效 |
GPU |
用于存储来自 pipeline 的输出数据的内存,例如信道估计。 |
调用者应确保为输入和输出数据分配的内存对于 pipeline 的操作来说是足够的,并且指针在动态配置参数中正确设置。pipeline 可能不会检查内存的有效性或大小。假定它与静态和动态参数一致。调用者还应确保在 pipeline 使用内存时,内存不会被其他进程修改。
SRS 信道估计算法#
当前的 pipeline 实现执行基于接收到的 SRS 信号的 MMSE 信道估计。信道估计算法包括以下步骤
加载接收到的 SRS 子载波,移除 ZC 覆盖码并平均重复
移除循环移位并应用宽滤波器来估计信道
估计延迟相位斜坡
通过与移位序列相乘,从接收信号中移除延迟相位斜坡
移除循环移位并应用窄滤波器来估计信道
平均估计值。估计能量和噪声
计算相对于正在使用和未使用的循环移位的相关性:对 PRB、天线、循环移位求和
Pipeline 将信道估计、信号能量、噪声方差和相关值保存到输出缓冲区,以便在其他地方使用。
性能优化#
cuPHY 库旨在加速商用级 5G gNB DU 的 PHY 层功能。软件优化确保随着小区数量的增加,降低延迟和可扩展的性能。我们可以将其归类为
使用 CUDA Graphs:cuPHY 库利用 CUDA graph 功能来减少内核启动延迟。实现每个 cuPHY 物理层通道 pipeline 中信号处理组件的 CUDA 内核表示为 CUDA graph 中的节点,组件之间的依赖关系表示为节点之间的边。由于 graph 创建开销很大,因此在通道 pipeline 初始化期间创建具有最坏情况拓扑结构的基础 graph,其中组件内核有多个 specialization。当为给定时隙调度通道时,仅更新和启用必要的 graph 节点子集。
使用 MPS (多进程服务):cuPHY 驱动程序创建多个 MPS 上下文,每个上下文都限制了可在其中启动的内核使用的 SM(流式多处理器)的最大数量。与共享通道的 MPS 上下文相比,控制通道(例如 PUCCH、PDCCH)的 MPS 上下文通常具有显著更低的 SM 限制,这是因为预期的计算负载较低。每个 MPS 上下文还具有一个或多个与之关联的 CUDA 流,这些流可能具有不同的 CUDA 流优先级。
内核融合:cuPHY 实现可能会将来自不同处理步骤的功能融合到单个 CUDA 内核中,以提高性能。例如,下行链路共享通道的速率匹配、加扰和调制处理步骤都在单个内核中执行。这些定制的动机是减少内存访问延迟,从而提高性能。例如,假设有两个内核按顺序运行。第一个内核进行计算,将输出写入全局内存,第二个内核需要从全局内存中读取此输出以继续计算。在这种情况下,融合这两个内核可以减少对具有更高延迟的全局内存的访问次数。
L1-L2 数据流优化:L2 和 L1 之间以及 L1 和 FH 之间的数据流对于延迟优化非常重要。每当 L2 调度 PDSCH 通道时,都需要将 PDSCH 通道的数据 TB 有效负载从 L2 复制到 L1。TB 的大小随着更高的数据吞吐量而增加,TB 的数量也可能随着小区数量和在给定时间时隙上调度的 UE 数量而增加。cuPHY 库对 TB H2D(主机到设备)复制进行流水线处理,以便与 PDSCH 通道设置处理并行运行。这种流水线处理隐藏了 TB H2D 复制延迟,从而减少了整体 PDSCH 完成时间。
运行 cuPHY 示例#
cuPHY 库包含示例程序,可用于测试 cuPHY 通道 pipeline 和组件。如何在 Aerial Release Guide Document 的“Running the cuPHY Examples”部分中解释了如何运行 cuPHY 通道 pipeline。请参阅发布指南,了解如何运行 cuPHY 通道 pipeline。在运行这些示例时,请注意最近的 cuPHY 实现使用 graphs 模式来提高性能。
cuPHY 库还包括其组件的示例。下面提供了一些示例。
上行链路信道估计
cuPHY/build/examples/ch_est/cuphy_ex_ch_est -i ~/<tv_name>.h5
示例测试运行
cuPHY/build/examples/ch_est/cuphy_ex_ch_est -i
TVnr_7550_PUSCH_gNB_CUPHY_s0p0.h5
UE group 0: ChEst SNR: 138.507 dB
ChEst test vector TVnr_7550_PUSCH_gNB_CUPHY_s0p0.h5 PASSED
22:53:17.726075 datasets.cpp:974 WRN[90935 ] [CUPHY.PUSCH_RX] LDPC throughput mode disabled
22:53:17.943272 cuphy.hpp:84 WRN[90935 ] [CUPHY.MEMFOOT]cuphyMemoryFootprint - GPU allocation:
684.864 MiB for cuPHY PUSCH channel object (0x7ffc16f09f90).
22:53:17.943273 pusch_rx.cpp:1188 WRN[90935 ] [CUPHY.PUSCH_RX] PuschRx:
Running with eqCoeffAlgo 3
Simplex 解码器
cuPHY/build/examples/simplex_decoder/cuphy_ex_simplex_decoder -i ~/<tv_name>.h5
示例测试运行
cuPHY/build/examples/simplex_decoder/cuphy_ex_simplex_decoder -i
TVnr_61123_SIMPLEX_gNB_CUPHY_s0p0.h5
AERIAL_LOG_PATH unset
Using default log path
Log file set to /tmp/simplex_decoder.log
22:57:29.115870 WRN 92956 0 [NVLOG.CPP] Using
/opt/nvidia/cuBB/cuPHY/nvlog/config/nvlog_config.yaml for nvlog configuration
22:57:33.455795 WRN 92956 0 [CUPHY.PUSCH_RX] Simplex code: found 0 mismatches out of 1 codeblocks
Exiting bg_fmtlog_collector - log queue ever was full: 0
PUSCH 去速率匹配
cuPHY/build/examples/pusch_rateMatch/cuphy_ex_rateMatch -i ~/<tv_name>.h5
示例测试运行
cuPHY/build/examples/pusch_rateMatch/cuphy_ex_pusch_rateMatch -i
TVnr_7143_PUSCH_gNB_CUPHY_s0p0.h5
AERIAL_LOG_PATH unset
Using default log path
Log file set to /tmp/pusch_rateMatch.log
22:58:20.673934 WRN 93384 0 [NVLOG.CPP] Using cuPHY/nvlog/config/nvlog_config.yaml
for nvlog configuration
22:58:20.896254 WRN 93384 0 [CUPHY.PUSCH_RX] LDPC throughput mode disabled
nUes 1, nUeGrps 1
nMaxCbsPerTb 3 num_CBs 3
uciOnPuschFlag OFF
nMaxTbs 1 nMaxCbsPerTb 3 maxBytesRateMatch 156672
22:58:21.037299 WRN 93384 0 [CUPHY.MEMFOOT] cuphyMemoryFootprint - GPU
allocation: 684.864 MiB for cuPHY PUSCH channel object (0x7ffe23b0f690).
22:58:21.037302 WRN 93384 0 [CUPHY.PUSCH_RX] PuschRx: Running with eqCoeffAlgo 3
22:58:21.037810 WRN 93384 0 [CUPHY.PUSCH_RX] detected 0 mismatches out
of 65280 rateMatchedLLRs
Exiting bg_fmtlog_collector - log queue ever was full: 0