DOCA Core
本文档提供了关于如何使用 DOCA Core 对象作为 DOCA SDK 编程一部分的指南。
DOCA Core 库目前处于 Beta 级别。
DOCA Core 对象为应用程序开发者提供了一个统一和整体的接口,用于与各种 DOCA 库进行交互。DOCA Core API 和对象为应用程序构建提供了一个标准化的流程和构建模块,同时隐藏了处理硬件和其他软件组件的内部细节。DOCA Core 旨在提供适当级别的抽象,同时保持性能。
DOCA Core 对于 NVIDIA® BlueField® 和 CPU 安装具有相同的 API(头文件),但如果 API 未针对该处理器实现,则特定的 API 调用可能会返回 DOCA_ERROR_NOT_SUPPORTED。但是,Windows 和 Linux 的情况并非如此,因为 DOCA Core 在 Windows 和 Linux 安装之间确实存在 API 差异。
DOCA Core 向应用程序编写者公开 C 语言 API,用户必须根据其应用程序所需的 DOCA Core 功能包含正确的头文件才能使用。
DOCA Core 可以分为以下软件模块
DOCA Core 模块 | 描述 |
通用 |
|
设备处理 |
信息
Representor 实体与其对应的“被代表”设备之间存在对称性。API 或对象名称中使用 |
内存管理 |
|
进度引擎和任务执行 |
|
同步事件 |
|
以下章节描述了 DOCA Core 的架构和子系统,以及一些帮助用户开始使用 DOCA Core 的基本流程。
DOCA Core 对象在 NVIDIA® BlueField® 网络平台(DPU 或 SuperNIC)和主机上均受支持。两者都必须满足以下先决条件
DOCA 版本 2.0.2 或更高版本
NVIDIA® BlueField® 软件 4.0.2 或更高版本
NVIDIA® BlueField®-3 固件版本 32.37.1000 及更高版本
NVIDIA® BlueField®-2 固件版本 24.37.1000 及更高版本
请参阅 DOCA 向后兼容性策略
2.10.0 版本变更
新增
doca_error_t doca_devinfo_rep_get_iface_name(struct doca_devinfo_rep *devinfo_rep, char *iface_name, uint32_t size)
已更改
doca_devinfo_rep_create_list(struct doca_dev *dev, int filter, struct doca_devinfo_rep ***dev_list_rep, uint32_t *nb_devs_rep);现在支持主机上的网络 representor 发现。
以下章节描述了各种 DOCA Core 软件模块的架构。有关 DOCA 头文件文档,请参阅 DOCA 库 API。
通用
所有核心对象都遵循相同的流程,这在以后有助于在快速路径中不进行分配。
流程如下:
创建对象实例(例如,
doca_mmap_create)。配置实例(例如,
doca_mmap_set_memory_range)。启动实例(例如,
doca_mmap_start)。
实例启动后,它会遵守零分配原则,并且可以在数据路径中安全使用。实例完成后,必须停止并销毁(doca_mmap_stop, doca_mmap_destroy)。
有些核心对象可以重新配置并再次重启(即,创建 → 配置 → 启动 → 停止 → 配置 → 启动)。请阅读头文件以查看特定对象是否支持此选项。
doca_error_t
所有 DOCA API 都以 doca_error_t 的形式返回状态。
typedef enum doca_error {
DOCA_SUCCESS,
DOCA_ERROR_UNKNOWN,
DOCA_ERROR_NOT_PERMITTED, /**< Operation not permitted */
DOCA_ERROR_IN_USE, /**< Resource already in use */
DOCA_ERROR_NOT_SUPPORTED, /**< Operation not supported */
DOCA_ERROR_AGAIN, /**< Resource temporarily unavailable, try again */
DOCA_ERROR_INVALID_VALUE, /**< Invalid input */
DOCA_ERROR_NO_MEMORY, /**< Memory allocation failure */
DOCA_ERROR_INITIALIZATION, /**< Resource initialization failure */
DOCA_ERROR_TIME_OUT, /**< Timer expired waiting for resource */
DOCA_ERROR_SHUTDOWN, /**< Shut down in process or completed */
DOCA_ERROR_CONNECTION_RESET, /**< Connection reset by peer */
DOCA_ERROR_CONNECTION_ABORTED, /**< Connection aborted */
DOCA_ERROR_CONNECTION_INPROGRESS, /**< Connection in progress */
DOCA_ERROR_NOT_CONNECTED, /**< Not Connected */
DOCA_ERROR_NO_LOCK, /**< Unable to acquire required lock */
DOCA_ERROR_NOT_FOUND, /**< Resource Not Found */
DOCA_ERROR_IO_FAILED, /**< Input/Output Operation Failed */
DOCA_ERROR_BAD_STATE, /**< Bad State */
DOCA_ERROR_UNSUPPORTED_VERSION, /**< Unsupported version */
DOCA_ERROR_OPERATING_SYSTEM, /**< Operating system call failure */
DOCA_ERROR_DRIVER, /**< DOCA Driver call failure */
DOCA_ERROR_UNEXPECTED, /**< An unexpected scenario was detected */
DOCA_ERROR_ALREADY_EXIST, /**< Resource already exist */
DOCA_ERROR_FULL, /**< No more space in resource */
DOCA_ERROR_EMPTY, /**< No entry is available in resource */
DOCA_ERROR_IN_PROGRESS, /**< Operation is in progress */
DOCA_ERROR_TOO_BIG, /**< Requested operation too big to be contained */
} doca_error_t;
有关更多信息,请参阅 doca_error.h。
通用结构/枚举
以下类型在所有 DOCA API 中都很常见。
union doca_data {
void *ptr;
uint64_t u64;
};
enum doca_access_flags {
DOCA_ACCESS_LOCAL_READ_ONLY = 0,
DOCA_ACCESS_LOCAL_READ_WRITE = (1 << 0),
DOCA_ACCESS_RDMA_READ = (1 << 1),
DOCA_ACCESS_RDMA_WRITE = (1 << 2),
DOCA_ACCESS_RDMA_ATOMIC = (1 << 3),
DOCA_ACCESS_DPU_READ_ONLY = (1 << 4),
DOCA_ACCESS_DPU_READ_WRITE = (1 << 5),
};
enum doca_pci_func_type {
DOCA_PCI_FUNC_PF = 0, /* physical function */
DOCA_PCI_FUNC_VF, /* virtual function */
DOCA_PCI_FUNC_SF, /* sub function */
};
有关更多信息,请参阅 doca_types.h。
DOCA 设备
本地设备和 Representor
representor 模型有两种拓扑结构
DPU 模式拓扑 – BlueField 必须在 DPU 模式下运行(请参阅 “DPU 拓扑” 部分中的说明)。
NIC 模式拓扑 – 所有设备和 representor 都驻留在主机上。这可以通过在 NIC 模式下运行的 BlueField 或 NVIDIA® ConnectX® 设备来实现。请参阅 DOCA 交换下的说明。
DPU 拓扑
DOCA 设备代表可用的处理单元,可以是基于硬件的,也可以是基于软件的。它公开其属性以帮助应用程序选择最合适的设备。DOCA Core 支持两种设备类型
本地设备
本地系统上可用的物理设备(例如,BlueField 或主机)
能够执行 DOCA 库处理任务
Representor 设备
本地设备的代理或表示
通常用于主机端设备,representor 位于 BlueField 上
特殊功能 (SF) 完全驻留在 BlueField 上,并且也有自己的 representor 设备
拓扑示例

以下描述了一个典型的拓扑结构,如图所示
主机拓扑
主机系统包括两个物理功能 (PF):
PF0和PF1。PF0有两个子虚拟功能 (VF):VF0和VF1。PF1有一个关联的 VF:VF0。使用 DOCA SDK API,用户可以将这五个设备作为主机上的本地设备进行查询。
BlueField 端
BlueField 设备通过 representor 设备与主机功能保持 1 对 1 的关系。例如,
hpf0是主机PF0设备的 representor。BlueField 还包括 SF 设备的 representor。SF 及其 representor 都驻留在 BlueField 上。
在 BlueField 上查询设备
在 BlueField 上查询本地设备(而非 representor)时,结果包括
两个 BlueField DPU PF(本例中为
p0和p1)。这些是所有其他设备的父设备。关联设备
7 个 representor 设备
5 个主机功能 representor(
hpf*,在图中显示为连接主机到 BlueField 的箭头)。2 个 SF 设备 representor(
pf0sf0和pf1sf0)。
2 个本地 SF 设备:这些不是 representor,而是 BlueField 上的物理设备(
p0s0和p1s0)。
拓扑结构分为两个部分(在图中用虚线分隔),每个部分由一个 BlueField 物理设备(p0 和 p1)表示。每个 BlueField 设备都充当以下设备的父设备:
本地设备(例如,PF、VF 和 SF)。
Representor 设备(主机 PF、主机 VF 和 SF)。
父设备可以通过 doca_devinfo_rep_list_create API 访问所有关联功能的 representor 设备。
本地设备和 Representor 匹配
根据拓扑图,mmap 导出 API 可以按如下方式使用:
使用 doca_mmap_export_dpu() 时在主机上选择的设备 | BlueField 匹配 Representor | 使用 doca_mmap_create_from_export() 时在 BlueField 上选择的设备 |
|
|
|
|
| |
|
| |
|
|
|
|
|
预期流程
设备发现
为了使用 DOCA 库或 DOCA Core 对象,应用程序必须打开并使用 BlueField 或主机上可用的设备。
根据系统设置,通常有多个设备可用。有关设备拓扑和层次结构的详细信息,请参阅 “DPU 拓扑” 部分。
应用程序可以根据功能、DOCA Core API 以及每个提供各种设备功能的其他库来决定选择哪个设备。流程如下:
应用程序获取可用设备列表。
根据
doca_devinfo的属性和功能选择要使用的特定doca_devinfo。此示例查找特定的 PCIe 地址。一旦确定了合适的
doca_devinfo,使用 DOCA Core API 打开设备以获取doca_dev句柄。打开所需的设备后,释放
doca_devinfo列表以释放资源。使用
doca_dev句柄与 DOCA 库交互或执行所需的操作。当应用程序完成设备使用后,请确保正确关闭
doca_dev以释放资源。

Representor 设备发现
为了使用 DOCA 库或 DOCA Core 对象,某些应用程序必须打开并使用 representor 设备。在打开 representor 设备并使用它之前,应用程序需要工具来允许它们选择具有必要功能的适当 representor 设备。DOCA Core API 提供了各种设备功能,以帮助应用程序选择正确的设备对(设备及其 representor)。流程如下:
应用程序“知道”它要使用哪个设备(例如,通过其 PCIe BDF 地址)。这可以使用 DOCA Core API 或 OS 服务来完成。
应用程序获取特定设备的设备 representor 列表。
根据
doca_devinfo_rep的属性选择要使用的特定doca_devinfo_rep。此示例查找特定的 PCIe 地址。一旦确定了合适的
doca_devinfo_rep,打开doca_dev_rep。用户打开正确的设备 representor 后,他们可以关闭
doca_devinfo_rep列表并继续使用doca_dev_rep。应用程序最终也必须关闭doca_dev_rep。

如前所述,DOCA Core API 可以识别具有唯一属性的设备及其 representor(例如,BDF 地址,设备及其 representor 的相同 BDF)。
关于 representor 设备属性缓存,函数 doca_devinfo_rep_create_list 在调用时提供 DOCA representor 设备属性的快照。如果任何 representor 的属性被动态更改(例如,总线重置后 BDF 地址更改),则该函数返回的设备属性将不会反映此更改。应再次创建列表以获取 representor 的更新属性。
DOCA 应用程序重启
DOCA 应用程序的重启可以优雅地完成,也可以非优雅地完成。每种方法都有自己的步骤和注意事项,以确保正确的资源管理并最大限度地减少停机时间。
在优雅重启中,应用程序遵循结构化流程,以确保在重启之前正确管理和释放所有资源,包括与 DOCA 设备相关的资源(例如,DOCA 流交换机端口及其组件)。释放资源后,应用程序调用 doca_dev_close 关闭 DOCA 设备实例,然后终止。在非优雅重启中,应用程序意外崩溃,而没有释放相关资源。然后应用程序再次启动。
doca_dev_accelerate_resource_reclaim API 在这两种场景中都很有用,可以优化与设备关联的资源的回收过程。通过在缓存中保留关键资源,此 API 确保可以在需要时快速回收它们,从而最大限度地减少停机时间并加快恢复过程,尤其是在非优雅重启场景中。
对于优雅重启,用户应在启动设备资源清理之前调用 doca_dev_accelerate_resource_reclaim API。调用 API 后,用户可以继续释放所有关联资源,使用 doca_dev_close 关闭 DOCA 设备实例,并终止应用程序。这确保了在应用程序重启之前正确管理和释放资源。
对于非优雅重启,即应用程序意外崩溃的情况,可以定期(例如,每 5 秒)调用 doca_dev_accelerate_resource_reclaim API 以确保就绪。这种定期调用使关键资源能够持续保留在缓存中,以便在应用程序重启时可以快速回收这些资源,从而最大限度地减少停机时间并加快恢复过程。
在重启应用程序后,无论是优雅重启还是非优雅重启,应用程序都应调用 doca_dev_open 以创建新的 DOCA 设备实例。
建议在 doca_dev_open 返回后立即调用 doca_dev_accelerate_resource_reclaim API,以延长与设备关联的资源在缓存中的保留时间。
之后,应用程序应分配与 DOCA 设备相关的必要资源。这确保了应用程序可以使用所需的资源恢复其操作,从而利用缓存中保留的资源来实现更快、更高效的重启过程。
使用此 API 并非没有代价,因为它可能会导致系统资源不足或短缺,从而可能导致整体系统性能下降。仅将 API 用于上述指定的用例。如果您不确定特定的应用程序用例,请联系 NVIDIA 企业支持部门进行咨询。
DOCA 内存子系统
DOCA 内存子系统旨在优化性能,同时保持最小的内存占用空间(以方便扩展),这是主要的设计目标。
DOCA 内存具有以下主要组件
doca_buf– 这是数据缓冲区描述符。 这不是实际的数据缓冲区,而是一个描述符,它保存有关“指向”数据缓冲区的元数据。doca_mmap– 这是doca_buf指向的数据缓冲区池。应用程序将内存作为单个内存区域提供,并为某些设备提供访问权限。
由于 doca_mmap 充当数据缓冲区的内存池,因此还有一个名为 doca_buf_inventory 的实体,它充当具有相同特征的 doca_buf 池(更多信息请参见 “DOCA Core 缓冲区” 和 “DOCA Core 清单” 部分)。与所有 DOCA 实体一样,内存子系统对象是不透明的,只能由 DOCA SDK 实例化。
下图显示了 DOCA 内存子系统中的各个模块。

在图中,您可能会看到两个 doca_buf_inventory。每个 doca_buf 都指向内存缓冲区的一部分,该缓冲区是 doca_mmap 的一部分。mmap 填充了一个连续的内存缓冲区 memrange,并映射到两个设备 dev1 和 dev2。
要求和注意事项
DOCA 内存子系统强制使用池而不是动态分配
doca_buf的池 →doca_buf_inventory数据内存的池 →
doca_mmap
mmap 中的内存缓冲区可以映射到一个或多个设备
mmap 中的设备受到访问权限的限制,这些权限定义了它们如何访问内存缓冲区
doca_buf指向特定的内存缓冲区(或其一部分),并保存该缓冲区的元数据映射和使用设备(例如,内存注册)的内部机制对应用程序是隐藏的
作为最佳实践,应用程序应在初始化阶段启动
doca_mmap,因为启动操作非常耗时。doca_mmap不应作为数据路径的一部分启动,除非必要。主机映射的内存缓冲区可以被 BlueField 访问
doca_mmap
doca_mmap 不仅仅是一个数据缓冲区,因为它从应用程序开发者那里隐藏了很多细节(例如,RDMA 技术细节、设备处理等),同时为使用它的软件提供了适当级别的抽象。doca_mmap 是在主机和 BlueField 之间共享内存的最佳方式,以便 BlueField 可以直接访问主机端内存,反之亦然。
DOCA SDK 支持多种类型的 mmap,以帮助处理不同的用例:本地 mmap 和来自导出的 mmap。
本地 mmap
这是 mmap 的基本类型,它将本地缓冲区映射到本地设备。
应用程序创建
doca_mmap。应用程序使用
doca_mmap_set_memrange设置 mmap 的内存范围。内存范围是应用程序分配和管理的内存(通常保存发送到设备处理单元的数据池)。应用程序添加设备,授予设备对内存区域的访问权限。
应用程序可以使用
doca_mmap_set_permissions指定设备对该内存范围的访问权限。如果 mmap 仅在本地使用,则必须指定
DOCA_ACCESS_LOCAL_*如果在主机上创建 mmap 但与 BlueField 共享(参见步骤 6),则必须指定
DOCA_ACCESS_PCI_*如果在 BlueField 上创建 mmap 但与主机共享(参见步骤 6),则必须指定
DOCA_ACCESS_PCI_*如果 mmap 与远程 RDMA 目标共享,则必须指定
DOCA_ACCESS_RDMA_*
应用程序启动 mmap。
注意从此时起,不能再对 mmap 进行任何更改。
要与 BlueField/主机或 RDMA 远程目标共享 mmap,请分别调用
doca_mmap_export_pci或doca_mmap_export_rdma。如果未提供适当的访问权限,导出将失败。警告导出的数据包含敏感信息。请确保通过安全通道传递此数据!
上一步生成的 blob 可以使用套接字进行带外共享。如果与 BlueField 共享,建议使用 DOCA Comm Channel。有关确切流程,请参阅 DMA Copy 应用程序。
来自导出的 mmap
此 mmap 用于访问主机内存(来自 BlueField)或远程 RDMA 目标的内存。
应用程序从另一端接收 blob。blob 包含前一个要点中步骤 6 返回的数据。
应用程序调用
doca_mmap_create_from_export并接收一个新的 mmap,该 mmap 表示由另一端定义的内存。

现在,应用程序可以创建 doca_buf 以指向此导入的 mmap,并直接访问另一台机器的内存。
如果导出器是同一台机器上的主机,则 BlueField 可以访问导出到 BlueField 的内存。或者它可以访问通过 RDMA 导出的内存,该内存可以在同一台机器、远程主机或远程 BlueField 上。
主机只能访问通过 RDMA 导出的内存。这可以是远程主机、远程 BlueField 或同一台机器上的 BlueField 上的内存。
缓冲区
DOCA 缓冲区对象用于引用 BlueField 硬件可访问的内存。该缓冲区可以在不同的 BlueField 加速器之间使用。缓冲区可以引用 CPU、GPU、主机甚至 RDMA 内存。但是,这是抽象的,因此一旦创建了缓冲区,无论它是如何创建的,都可以以类似的方式处理它。本节介绍 DOCA 缓冲区分配后如何使用。
DOCA 缓冲区具有描述内存区域的地址和长度。每个缓冲区还可以使用数据地址和数据长度指向区域内的数据。这区分了缓冲区的三个部分:头部空间、数据空间和尾部空间。

头部空间 – 从缓冲区地址到缓冲区数据地址的内存区域
数据空间 – 从缓冲区数据地址开始,长度由缓冲区数据长度指示的内存区域
尾部空间 – 从数据空间末尾到缓冲区末尾的内存区域
缓冲区长度 – 头部空间、数据空间和尾部空间的总长度
缓冲区注意事项
创建缓冲区有多种方法,但一旦创建,其行为方式相同(请参阅 “清单” 部分)。
缓冲区可能引用 CPU 无法访问的内存(例如,RDMA 内存)
缓冲区是线程不安全的对象
缓冲区可用于表示非连续内存区域(scatter/gather 列表)
缓冲区不拥有也不管理它引用的数据。释放缓冲区不会影响底层内存。
头部空间
头部空间被视为用户空间。例如,用户可以使用它来保存有关缓冲区或数据的信息,这些信息与缓冲区数据空间中的数据耦合。
DOCA 库在所有操作中都忽略此部分并保持不变。
数据空间
数据空间是缓冲区的内容,保存用户可能希望使用 DOCA 库执行不同操作的数据,或此类操作的结果。
尾部空间
尾部空间被 DOCA 库视为缓冲区中的自由写入空间(即,在不同操作中可能被覆盖的内存区域,其中缓冲区用作输出)。
缓冲区作为源
当使用 doca_buf 作为源缓冲区时,源数据仅被视为数据部分(数据空间)。
缓冲区作为目标
当使用 doca_buf 作为目标缓冲区时,数据将写入尾部空间(即,附加在现有数据之后,如果有)。
当 DOCA 库将数据附加到缓冲区时,数据长度会相应增加。
Scatter/Gather 列表
为了对非连续内存区域执行操作,可以创建缓冲区列表。该列表将由单个 doca_buf 表示,该 doca_buf 表示列表的头部。
要创建缓冲区列表,用户必须首先单独分配每个缓冲区,然后将它们链接起来。一旦链接起来,它们也可以取消链接
链接操作
doca_buf_chain_list()接收两个列表(头部),并将第二个列表附加到第一个列表的末尾取消链接操作
doca_buf_unchain_list()接收列表(头部)和列表中的一个元素,并将它们分开创建列表后,可以使用
doca_buf_get_next_in_list()遍历列表。到达最后一个元素后,将返回NULL。链接操作
doca_buf_chain_list_tail()将列表头部附加到列表尾部。应用程序负责维护列表尾部。
将列表传递到另一个库与传递单个缓冲区相同;应用程序发送列表的头部。支持此功能的 DOCA 库可以将构成列表的内存区域视为一个连续区域。
当使用缓冲区列表作为源时,每个缓冲区的数据(在数据空间中)被收集并用作给定操作的连续数据。
当使用缓冲区列表作为目标时,数据分散在列表中的缓冲区的尾部空间中,直到全部写入完成(某些缓冲区可能未被写入)。
缓冲区用例
DOCA 缓冲区被 DOCA 加速库(例如,DMA、压缩、SHA)广泛使用。在这些情况下,缓冲区可以作为源或目标提供。
缓冲区用例注意事项
如果应用程序希望使用链表缓冲区并将多个
doca_buf连接到 scatter/gather 列表,则应用程序应确保库确实支持链表缓冲区。例如,要检查 DMA memcpy 任务的链表支持,应用程序可以调用doca_dma_cap_task_memcpy_get_max_buf_list_len()。除非另有说明,否则对缓冲区数据执行的操作不是原子的
一旦缓冲区作为任务的一部分传递给库,缓冲区的所有权将转移到库,直到该任务完成
注意当使用
doca_buf作为某些处理库(例如,doca_dma)的输入时,doca_buf必须保持有效且未修改,直到处理完成。写入正在进行的缓冲区可能会导致异常行为。同样,从正在进行的缓冲区读取数据时,数据有效性没有保证。
清单
清单是负责分配 DOCA 对象的对象。最基本的清单允许在无需分配任何系统内存的情况下进行分配。其他清单涉及强制缓冲区地址不重叠。
清单注意事项
所有清单在启动后都遵守零分配原则。
DOCA 缓冲区的分配需要数据源和清单。
数据源定义了数据驻留的位置、谁可以访问数据以及访问权限。
数据源必须由应用程序创建。有关创建 mmaps,请参阅
doca_mmap。
清单描述了缓冲区的分配模式,例如,随机访问或池、可变大小或固定大小的缓冲区以及连续或非连续内存。
某些清单在分配缓冲区时需要提供数据源
doca_mmap,而其他清单则在创建清单时需要提供。所有清单类型都是线程不安全的。
清单类型
清单类型 | 特性 | 何时使用 | 注释 |
| 多个 mmap、灵活的地址、灵活的缓冲区大小。 | 当使用多种大小或 mmap 时。 | 最常见的用例。 |
| 单个 mmap,固定缓冲区大小。用户接收指向 DOCA 缓冲区的指针数组。 在 DPA 的情况下,mmap 和缓冲区大小可以未配置,稍后可以从 DPA 设置。 | 用于在 GPU 或 DPA 上创建 DOCA 缓冲区。 |
|
| 单个 mmap,固定缓冲区大小,地址不受用户控制。 | 当缓冲区地址不重要时,用作具有相同特性的缓冲区池。 | 比 |
示例流程
以下是将主机 mmap 导出到 BlueField 以供 DOCA 直接访问主机内存(例如,用于 DMA)的预期步骤的简化示例
在主机上创建 mmap(有关如何选择要添加到 mmap 的
doca_dev(如果导出到 BlueField),请参阅“预期流程”部分)。此示例将单个doca_dev添加到 mmap 并导出,以便 BlueField/RDMA 端点可以使用它。
导入到 BlueField/RDMA 端点(例如,使用 mmap 描述符输出参数作为
doca_mmap_create_from_export的输入)。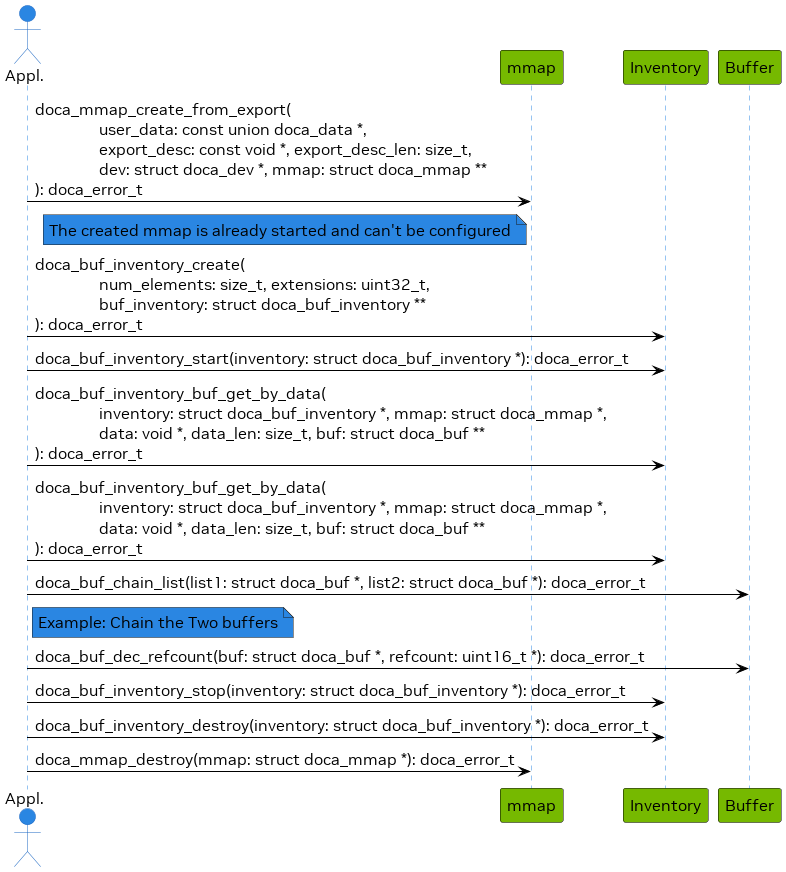


DOCA 执行模型
执行模型基于硬件数据处理和应用程序线程。DOCA 不会创建内部线程来处理数据。
工作负载由任务和事件组成。某些任务将源数据转换为目标数据。基本转换是数据上的 DMA 操作,它只是将数据从一个内存位置复制到另一个内存位置。其他操作允许用户从网络接收数据包或涉及计算源数据的 SHA 值并将其写入目标位置。
例如,转换工作负载可以分解为三个步骤
读取源数据(
doca_buf,请参阅内存子系统)。对读取的数据应用操作(由专用硬件加速器处理)。
将操作结果写入目标位置(
doca_buf,请参阅内存子系统)。
每个这样的操作都称为任务 (doca_task)。
任务描述了应用程序想要提交给 DOCA(硬件或 BlueField)的操作。为此,应用程序需要一种与硬件/BlueField 通信的方式。这就是 doca_pe 的用武之地。进度引擎 (PE) 是每个线程的对象,用于将任务排队以卸载到 DOCA,并最终接收其完成状态。
doca_pe 引入了三个主要操作
提交任务。
检查已提交任务的进度/状态。
接收任务完成的通知(以回调的形式)。
工作负载可以拆分为许多不同的任务,这些任务可以在不同的线程上执行;每个线程由不同的 PE 表示。每个任务都必须与某些上下文相关联,其中上下文定义要完成的任务类型。
可以从 DOCA SDK 中的某些库中获取上下文。例如,要提交 DMA 任务,可以从 doca_dma.h 获取 DMA 上下文,而 SHA 上下文可以使用 doca_sha.h 获取。每个这样的上下文可能允许提交多种任务类型。
任务被认为是异步的,因为一旦应用程序提交任务,DOCA 执行引擎(硬件或 BlueField)将开始处理它,并且应用程序可以继续执行其他处理,直到硬件完成。为了跟踪哪些任务已完成,有两种操作模式:轮询模式 和 事件驱动模式。
要求和注意事项
任务提交/执行流程/API 针对性能(延迟)进行了优化
DOCA 不管理内部(操作系统)线程。相反,进度由应用程序资源管理(在轮询模式下调用 DOCA API 或在事件驱动模式下等待 DOCA 通知)。
执行任务的基本对象是
doca_task。每个任务都从特定的 DOCA 库上下文分配。doca_pe表示应用程序的逻辑执行线程以及提交到进度引擎 (PE) 的任务注意PE 不是线程安全的,并且预期每个 PE 由单个应用程序线程管理(以提交任务和管理 PE)。
与执行相关的元素(例如,
doca_pe、doca_ctx、doca_task)是不透明的,应用程序在使用这些元素之前执行最少的初始化/配置提交给 PE 的任务可能会失败(即使在提交成功之后)。在某些情况下,可以从错误中恢复。在其他情况下,唯一的选择是重新初始化相关对象。
PE 不保证顺序(即,以特定顺序提交的任务可能会乱序完成)。如果应用程序需要顺序,则必须强制执行(例如,在前一个任务完成后提交依赖任务)。
PE 可以以轮询模式或事件驱动模式工作,但不能同时以两种模式工作
所有 DOCA 上下文都支持轮询模式(即,可以添加到支持轮询模式的 PE)
DOCA 上下文
DOCA 上下文 (struct doca_ctx) 定义并提供(实现)任务/事件处理。上下文是特定 DOCA 库的实例(即,当库提供 DOCA 上下文时,其功能由它可以处理的任务/事件列表定义)。当上下文支持多种任务类型时,这意味着支持的任务类型具有一定的相似性,可以实现和利用通用功能。
以下列表定义了任务上下文之间的关系
每个上下文至少利用一个 DOCA 设备功能/加速处理能力
对于每种任务类型,都只有一个且仅有一个上下文类型支持它
上下文实际上为每种支持的任务类型包含一个清单
上下文实际上定义了每种任务类型的处理/执行的所有参数(例如,清单大小、加速处理的设备)
每个上下文都需要进度引擎 (PE) 的实例作为其任务的运行时(即,上下文必须与 PE 关联才能执行任务)。
下图显示了各种 DOCA Core 实体之间的高级(域模型)关系。

doca_task与执行任务的相关doca_ctx(在相关doca_dev的帮助下)相关联。doca_task在初始化后,被提交到doca_pe以供执行。doca_ctx连接到doca_pe。一旦doca_task排队到doca_pe,它将由与该 PE 中的任务关联的doca_ctx执行。
下图描述了上下文的初始化序列

上下文启动后,可以根据上下文支持的任务类型,使用它来启用向 PE 提交任务。有关更多信息,请参阅“DOCA 进度引擎”部分。
上下文是一个线程不安全的对象,只能连接到单个 PE。
配置阶段
在尝试使用 doca_ctx_start() 启动 DOCA 上下文之前,必须对其进行配置。某些配置是强制性的(例如,提供 doca_dev),而其他配置则不是。
配置可能有助于允许某些任务/事件、启用默认情况下禁用的功能以及根据特定工作负载优化性能。
配置是使用 setter 函数提供的。有关强制性和可选配置及其相应 API 的列表,请参阅上下文文档。
配置在创建上下文之后和启动上下文之前提供。一旦上下文启动,除非再次停止,否则将无法再配置。
常见配置示例
提供设备 – 通常作为创建 API 的一部分完成
启用任务或注册事件 – 所有任务默认情况下都已禁用
执行阶段
上下文配置完成后,即可使用上下文执行任务。上下文通过将工作负载卸载到硬件来执行任务,而软件轮询任务(即等待)直到它们完成。
在此阶段,应用程序使用上下文来分配和提交异步任务,然后轮询任务(等待)直到完成。
应用程序必须构建一个事件循环来轮询任务(等待),利用以下模式之一
在此阶段,上下文和所有核心对象都通过利用内存池来执行零分配。建议应用程序在其自身的逻辑中采用相同的方法。
状态机
状态 | 描述 |
空闲 |
|
启动中 | 对于运行状态的转换受一个或多个异步操作完成/外部事件制约的 CTX,此状态是强制性的。 例如,当客户端连接到通信通道时,它会进入运行状态。等待状态更改可以由自愿(用户) |
运行中 |
|
停止中 |
|
下图描述了 DOCA 上下文状态转换

内部错误
DOCA 上下文状态可能随时遇到内部错误。如果状态为启动中或运行中,则内部错误可能导致非自愿转换到停止状态。
例如,当任务执行失败时,可能会发生从运行到停止的非自愿转换。这会导致失败任务和所有后续任务完成都以错误完成。
停止后,状态可能变为空闲。但是,如果存在配置问题或错误事件阻止了正确转换到启动或运行状态,则 doca_ctx_start() 可能会失败。
DOCA 任务
任务是可以卸载到硬件的功能/处理工作负载的单元。大多数任务利用 NVIDIA® BlueField® 和 NVIDIA® ConnectX® 硬件来提供由任务定义的工作负载的加速处理。任务是异步操作(例如,通过非阻塞 doca_task_submit() API 提交以进行处理的任务)。
任务完成后,预设完成回调将在 doca_pe_progress() 调用的上下文中执行。完成回调是任务的基本/通用属性,类似于用户数据。大多数任务是由 NVIDIA 设备硬件执行/加速的 IO 操作。
任务属性
任务属性共享所有任务类型通用的通用属性和类型特定的属性。由于任务结构是不透明的(即,其内容未向用户公开),因此通过 set/get API 提供对任务属性的访问。
以下是通用任务属性
设置完成回调 – 它具有用于成功完成和失败完成的单独回调。
获取/设置用户数据 – 在完成回调中用作与特定任务对象关联的某些结构。
获取任务状态 – 旨在检索失败完成时的错误代码。
对于每个任务,只有一个所有者:上下文对象。有一个 doca_task_get_ctx() API 用于获取通用上下文对象。
以下是通用任务 API
从 CTX(内部/虚拟)清单分配和释放
通过 setter(或 init API)配置
可提交(即,实现
doca_task_submit(task))
完成后,有一组 getter 用于访问任务执行的结果。
任务生命周期
本节介绍 DOCA 任务的生命周期。每个 DOCA 任务对象的生命周期
在拥有任务的 DOCA 上下文进入 运行中 状态的事件时开始,即,一旦进入 运行中 状态,应用程序可以通过调用
doca_<CTX name>_task_<Task name>_alloc_init(ctx, ... &task)从 CTX 获取任务。在拥有任务的 DOCA 上下文进入 已停止 状态的事件时结束,即,一旦相关的 DOCA 上下文离开 运行中 状态,应用程序将无法再分配任务。
从应用程序的角度来看,DOCA 上下文提供了一个虚拟任务清单。下图显示了 DOCA 任务的所有权如何从 DOCA 上下文虚拟清单传递到应用程序,然后再从应用程序传递回 CTX,请注意应用程序 (APP) 参与者和 DOCA 上下文 (CTX) 参与者以及 DOCA 上下文任务虚拟清单(任务)的激活栏中使用的颜色。

下图显示了 DOCA 任务从分配到提交的生命周期。

上图显示了 DOCA 任务对象生命周期中的以下所有权转换
从分配开始,任务所有权从上下文传递到应用程序
应用程序可以通过 API(模板为
doca_<CTX name>_task_<Task name>_set_<Parameter name>(task, param))修改任务属性;从任务修改调用返回时,任务对象的所有权返回给应用程序。在 PE 中提交任务进行处理,一旦任务对象的所有必需修改/设置完成。在任务提交时,对象的所有权传递给相关的上下文。
以下两张图显示了 DOCA 任务完成时的生命周期。

上图显示了 DOCA 任务 对象生命周期中的以下所有权转换
在 DOCA 任务 完成时,将调用应用程序提供的适当处理程序;在处理程序调用时,DOCA 任务 所有权传递给应用程序。
在 DOCA 任务 完成后,应用程序可以访问任务属性和结果字段,利用适当的 API;应用程序仍然是任务对象的所有者。
当不再需要任务时,应用程序可以调用
doca_task_free();从调用返回时,任务所有权传递给 DOCA 上下文,而任务变为未初始化和预分配状态,直到上下文进入空闲状态。

上图显示了类似于前一张图的 DOCA 任务 对象生命周期中的所有权转换,唯一的区别是调用了 doca_task_submit(task) 而不是 doca_task_free(task)
DOCA 任务 结果(相关属性)可以在进入成功的任务完成回调后立即访问,类似于之前的情况
DOCA 任务 结果的生命周期在退出任务完成回调范围时结束。
在调用
doca_task_free()或doca_<CTX name>_task_<Task name>_set_<Parameter name>(task, param)时,所有任务结果都应被视为无效,无论范围如何。
下图显示了 DOCA 任务 可设置参数的生命周期,而用于设置此类参数的 API 模板为 doca_<CTX name>_task_<Task name>_set_<Parameter name>(task, param)。

绿色激活的 param 参与者描述了 DOCA 库拥有所有 DOCA 任务 参数的时间段。在调用 doca_task_submit() 时,所有任务参数的所有权都从应用程序传递到 DOCA 上下文,相关的任务对象属于该上下文。任务完成时,任务参数的所有权传递回应用程序。如果应用程序不拥有参数,则不应修改和/或销毁/释放任务参数相关对象。
DOCA 进度引擎
进度引擎 (PE) 支持在单线程执行环境中异步处理和处理多种不同类型的任务和事件。它是所有基于上下文的 DOCA 库的事件循环,其中 I/O 完成是最常见的事件类型。
PE 设计为线程不安全(即,它一次只能在一个线程中使用),但单个 OS 线程可以使用多个 PE。用户可以通过将不同的上下文添加到不同的 PE 并相应地调整每个 PE 的轮询频率,为不同的上下文分配不同的优先级。查看 PE 的另一种方式是将其视为计划执行的工作负载单元队列。
没有显式的 API 可以将工作负载添加到 PE 或在 PE 上调度工作负载,但可以通过以下方式添加工作负载
将 DOCA 上下文添加到 PE
注册 DOCA 事件以供(PE)探测,并在探测为肯定时执行关联的处理程序
PE 负责调度工作负载(即,选择要执行的下一个工作负载)。工作负载执行顺序与任务提交顺序、事件注册顺序或上下文与给定 PE 对象的关联顺序无关。多个任务完成回调的执行顺序可能与相关任务提交的顺序不同。
下图描述了 PE 的初始化流程

创建 PE 并连接到上下文后,它可以开始处理提交到上下文的任务。请参阅上下文文档以查找详细信息,例如可以使用上下文提交哪些任务。
请注意,PE 可以连接到多个上下文。这些上下文可以是相同类型或不同类型。这允许将不同类型的任务提交到同一 PE,并在同一位置/线程等待其中任何一个完成。
初始化 PE 后,应用程序可以使用以下模式之一定义事件循环
PE 作为事件循环操作模式
任务和事件的所有完成处理程序都在 doca_pe_progress() 的上下文中执行。doca_pe_progress() 循环遍历计划执行的每个工作负载(即,每个工作负载单元)
运行选定的工作负载单元。对于以下情况
任务完成,执行关联的处理程序并中断循环,并返回状态
made some progress事件的肯定探测,执行关联的处理程序并中断循环,并返回状态
made some progress在为将来任务完成或肯定事件探测做出重大贡献方面取得进展,中断循环并返回状态
made some progress
否则,到达循环末尾并返回状态 no progress。
轮询模式
在此模式下,应用程序提交任务,然后进行忙等待以找出任务何时完成。
下图演示了此序列

应用程序提交所有任务(一个或多个),并跟踪任务完成的数量以了解是否所有任务都已完成。
应用程序通过连续轮询
doca_pe_progress()来等待任务完成。如果
doca_pe_progress()返回 1,则表示正在取得进展(即,某些任务已完成或某些事件已处理)。每次任务完成或事件处理时,都会相应地执行其预设完成或事件处理回调。
如果任务完成时出现错误,则会执行预设的任务错误完成回调(请参阅“错误处理”部分)。
应用程序可以在完成回调或事件处理程序中添加代码,以跟踪已完成和挂起的工作负载量。
在此模式下,即使应用程序什么都不做(忙等待),也始终在使用 CPU。
阻塞模式 - 通知驱动
在此模式下,应用程序提交任务,然后等待接收通知,然后再查询状态。
下图演示了此序列

应用程序从
doca_pe获取通知句柄,该句柄表示一个 Linux 文件描述符,用于向应用程序发出信号,指示某些工作已完成。然后,应用程序使用
doca_pe_request_notification()启动 PE。注意每次应用程序希望从 PE 接收通知时,都必须执行此操作。
注意在
doca_pe_request_notification()之后,不允许调用doca_pe_progress()。换句话说,doca_pe_request_notification()之后应跟随doca_pe_clear_notification,然后再调用doca_pe_progress()。应用程序提交任务。
应用程序等待(例如,Linux epoll/select)在
pe-fd上接收信号。应用程序清除接收到的通知,通知 PE 已接收到信号,并允许其执行通知处理。
应用程序尝试通过(多次)调用
doca_pe_progress()来处理接收到的通知。注意不能保证调用
doca_pe_progress()会执行任何任务完成/事件处理程序,但 PE 可以继续操作。应用程序处理其内部状态更改,这些更改是由上一步中调用的任务完成和事件处理程序引起的。
重复步骤 2-7,直到所有任务都完成并且所有预期事件都已处理。
进度引擎与 Epoll
Linux 中的 epoll 机制和 DOCA PE 处理事件驱动架构中的高并发性。Epoll 就像一个邮局,跟踪“邮箱”(文件描述符),并在“信件”(事件)到达时通知“邮递员”(epoll_wait 函数)。DOCA PE 就像一家餐厅,使用单个“服务员”来处理来自“顾客”(DOCA 上下文)的“订单”(工作负载单元)。当订单准备就绪时,它会被放在“托盘”(任务完成处理程序/事件处理程序执行)上,并按接收顺序交付。这两个系统都在等待事件或任务完成时有效地管理资源。
DOCA 事件
事件是一种可以由 DOCA 软件检测或验证的发生类型,它可以触发处理程序(回调函数)来执行操作。事件与特定的源对象相关联,源对象是其状态或属性更改定义事件发生的实体。例如,上下文状态更改事件是由上下文对象的状态更改引起的。
要注册事件,用户必须调用 doca_<event_type>_reg(pe, ...) 函数,传递指向用户处理程序函数的指针和处理程序的 opaque 参数。用户还必须将事件处理程序与 PE 相关联,PE 负责运行涉及事件检测和处理程序执行的工作负载。
一旦事件注册,doca_pe_progress() 函数会定期检查它,该函数在与事件绑定的 PE 相同的执行上下文中运行。如果满足事件条件,则调用处理程序函数。事件不是线程安全的对象,应仅由与其绑定的 PE 访问。

错误处理
在任务成功提交后,后续调用 doca_pe_progress() 可能会失败(即,调用任务失败完成回调)。
一旦任务失败,上下文可能会转换为停止状态,在此状态下,应用程序必须处理所有正在进行的任务直到完成,然后再销毁或重新启动上下文。
下图显示了应用程序如何处理来自 doca_pe_progress() 的错误

应用程序运行事件循环。
可能会发生以下任何一种情况
[可选] 任务失败,并调用任务失败完成处理程序
这可能是由错误的任务参数或其他致命错误引起的
处理程序释放任务和所有关联的资源
[可选] 上下文转换为停止状态,并调用上下文状态更改处理程序
这可能是由任务失败或其他致命错误引起的
在此状态下,保证所有正在进行的任务都会失败
处理程序释放所有非正在进行的任务(如果存在此类任务)
[可选] 上下文转换为空闲状态,并调用上下文状态更改处理程序
这可能是由于遇到错误而发生的,并且上下文没有任何必须由应用程序释放的资源
在这种情况下,应用程序可以决定通过再次调用 start 来恢复上下文,或者可以决定销毁上下文并可能退出应用程序
任务和事件批处理
DOCA 批处理是一种将多个相同类型的任务或事件分组并将其作为一个单元处理的方法。DOCA 提供了两种实现此目的的选项,如下面的小节中所述。
批量任务/事件
在此批处理选项中,库(例如,doca_eth_txq)提供了一个表示批量操作的任务(例如,发送多个数据包),该任务被视为批量任务,并且具有与非批量操作(例如,发送单个数据包)分离的任务类型。
要提交批量任务,用户需要构建批量,然后立即提交它,类似于提交常规任务。
批量的完成基于批量中所有项目的完成,并被视为单个单元的完成来处理。这允许在单个 API 调用中进行多个 DOCA 任务初始化/提交和多个 DOCA 任务/事件完成处理(例如,请参阅 DOCA Ethernet)。
迭代批处理
在此批处理选项中,可以使用现有任务类型来构建批量操作,其中批量中的每个任务都单独提交,并且每个任务都接收其自身的完成。
此外,批量是迭代构建的,用户不需要提前拥有整个批量的所有信息。
要使用此选项,用户可以使用扩展的提交 API doca_task_submit_ex 提交批量中的每个任务,同时提供其他提交标志。
扩展的提交 API 类似于常规提交 API (doca_task_submit),但具有接收提交标志的能力。这些标志用作对执行任务的库的提示。它们可能对当前任务产生影响,但也可能对先前提交的标志产生影响,如下表所述
提交标志 1 | 对当前任务的影响 | 对先前任务的影响 2 | doca_task_submit 的默认行为 | 注释 | ||
提供标志 | 未提供标志 | 提供标志 | 未提供标志 | |||
| 任务立即提交以供硬件执行,并被视为“刷新”。 | 任务可能未提交以供硬件执行,并被视为“未刷新”。 | 所有先前被视为未刷新的任务都变为已刷新。 | 无 | 提供标志 | 只要任务未刷新,它就永远不会完成。 该标志允许批量处理,以便一次刷新多个任务,而不是单独刷新。 |
| 用户在硬件完成任务执行后不会收到任务完成,并且完成被视为“未报告”。 | 用户在硬件完成任务执行后收到任务完成,并且完成被视为“已报告”。 | 无 | 一旦硬件完成此任务的执行,所有先前 3 未报告的完成都变为已报告。 | 未提供标志 | 只要任务未报告,用户就永远不会知道它已完成。 任务的完成通过使用进度引擎的完成回调来报告。 库不保证任何任务执行/完成顺序。 该标志允许批量处理,以便使用单个硬件完成报告多个任务完成,而不是为每个任务接收完成。 |
DOCA 图执行
DOCA 图有助于以特定顺序和依赖关系运行一组操作(任务、用户回调、图)。DOCA 图在 DOCA 进度引擎上运行。
DOCA 图创建图实例,这些实例被提交到进度引擎 (doca_graph_instance_submit)。
节点
DOCA 图由上下文、用户和子图节点组成。这些类型中的每一种都可以在网络中的以下任何位置
根节点 – 根节点没有父节点。图可以有一个或多个根节点。当提交图实例时,所有根节点开始运行。
边缘节点 – 边缘节点是指没有子节点连接到它的节点。当所有边缘节点都完成时,图实例即完成。
中间节点 – 连接到父节点和子节点的节点
上下文节点
上下文节点运行特定的 DOCA 任务并使用特定的 DOCA 上下文 (doca_ctx)。上下文必须在图启动之前连接到进度引擎。
任务的生命周期必须长于或等于图实例的生命周期。
用户节点
用户节点运行用户回调,以便在图实例的运行时执行操作(例如,调整下一个节点任务数据、比较结果)。
子图节点
子图节点运行另一个图的实例。
使用 DOCA 图
使用
doca_graph_create创建图。创建图节点(例如,
doca_graph_node_create_from_ctx)。使用
doca_graph_add_dependency定义依赖关系。注意DOCA 图不支持循环依赖关系(例如,A => B => A)。
使用
doca_graph_start启动图。使用
doca_graph_instance_create创建图实例。设置节点数据(例如,
doca_graph_instance_set_ctx_node_data)。使用
doca_graph_instance_submit将图实例提交到 pe。调用
doca_pe_progress直到图回调被调用。进度引擎可以同时运行图实例和独立任务。
DOCA 图限制
DOCA 图不支持循环依赖关系
DOCA 图必须包含至少一个上下文节点。包含至少一个上下文节点的子图的图是有效的配置。
DOCA 图示例
该图示例基于 DOCA DMA 库。该示例使用 DMA 复制 2 个缓冲区。
该图以用户回调节点结束,该节点比较源和目标。
运行 DOCA 图示例
请参阅以下文档
NVIDIA DOCA Linux 安装指南,了解如何安装 BlueField 相关软件的详细信息。
NVIDIA DOCA 故障排除指南,了解您在安装、编译或执行 DOCA 示例时可能遇到的任何问题。
要构建给定的示例
cd /opt/mellanox/doca/samples/doca_common/graph/ meson build ninja -C build
示例(例如,
doca_graph)用法./build/doca_graph
无需参数。
备用数据路径
DOCA 进度引擎 利用 CPU 将数据路径操作卸载到硬件。但是,某些库支持利用 DPA 和/或 GPU。
注意事项
并非所有上下文都支持备用数据路径
配置阶段始终在 CPU 上完成
数据路径操作始终卸载到硬件。卸载操作的单元本身可以是 CPU/DPA/GPU。
默认的操作模式是 CPU
每种操作模式都引入一组不同的 API,用于执行路径。使用的 API 对于特定的上下文实例是互斥的。
DPA
用户必须首先参考相关上下文(例如,DOCA RDMA)的编程指南,以检查是否支持 DPA 上的数据路径。此外,该指南还提供了可以使用的操作。
要将数据路径模式设置为 DPA,请获取 DOCA DPA 实例,然后使用 doca_ctx_set_datapath_on_dpa() API。
在此模式下启动上下文后,就可以使用相关上下文定义的 API(例如,doca_rdma_get_dpa_handle())获取 DPA 句柄。然后,可以使用此句柄在 DPA 代码中访问 DPA 数据路径 API。
GPU
用户必须首先参考相关上下文(例如,DOCA 以太网)的编程指南,以检查是否支持 GPU 上的数据路径。此外,该指南还提供了可以使用的操作。
要将数据路径模式设置为 GPU,请获取 DOCA GPU 实例,然后使用 doca_ctx_set_datapath_on_gpu() API。
在此模式下启动上下文后,就可以使用相关上下文定义的 API(例如,doca_eth_rxq_get_gpu_handle())获取 GPU 句柄。然后,可以使用此句柄在 GPU 代码中访问 GPU 数据路径 API。
对象生命周期
大多数 DOCA Core 对象共享相同的处理模型,其中
对象由 DOCA 分配,因此对于应用程序是不透明的(例如,
doca_buf_inventory_create,doca_mmap_create)。应用程序初始化对象并设置所需的属性(例如,
doca_mmap_set_memrange)。对象已启动,不允许进行配置或属性更改(例如,
doca_buf_inventory_start,doca_mmap_start)。对象被使用。
对象被停止和删除(例如,
doca_buf_inventory_stop→doca_buf_inventory_destroy,doca_mmap_stop→doca_mmap_destroy)。
以下过程描述了两台机器(远程机器或主机-BlueField)之间的 mmap 导出机制
内存分配在 Machine1 上。
创建 Mmap 并从步骤 1 提供内存。
Mmap 导出到 Machine2,锁定内存。
在 Machine2 上,创建导入的 mmap 并保存对 Machine1 上实际内存的引用。
导入的 mmap 可供 Machine2 用于分配缓冲区。
导入的 mmap 被销毁。
导出的 mmap 被销毁。
原始内存被销毁。
RDMA 网桥
DOCA Core 库为应用程序提供构建块,以便在抽象许多依赖于 RDMA 驱动程序的细节时使用。虽然这消除了复杂性,但它增加了灵活性,特别是对于已经基于 rdma-core 的应用程序。RDMA 桥允许 DOCA SDK 和 rdma-core 之间的互操作性,以便现有应用程序可以将基于 DOCA 的对象转换为基于 rdma-core 的对象。
要求和注意事项
该库使已经使用 rdma-core 的应用程序能够移植其现有应用程序或使用 DOCA SDK 进行扩展。
桥允许将 DOCA 对象转换为等效的 rdma-core 对象。
DOCA Core 对象到 RDMA Core 对象映射
RDMA 桥允许将 DOCA Core 对象转换为匹配的 RDMA Core 对象。下表显示了一个对象如何映射到另一个对象。
RDMA Core 对象 | DOCA 等效项 | RDMA 对象到 DOCA 对象 | DOCA 对象到 RDMA 对象 |
|
|
|
|
|
|
|
|
本节中描述的所有 DOCA 示例均受 BSD-3 软件许可协议管辖。
进度引擎示例
所有进度引擎 (PE) 示例都使用 DOCA DMA,因为它的简单性。PE 示例应用于理解 PE 而不是 DOCA DMA。
pe_common
pe_common.c 和 pe_common.h 包含大多数或所有 PE 示例中使用的代码。
用户可以找到核心代码(例如,创建 MMAP)和使用 PE 的通用代码(例如,poll_for_completion)。
结构 pe_sample_state_base(在 pe_common.h 中定义)是所有 PE 示例的基本状态,包含大多数或所有 PE 示例使用的通用成员。
pe_polling
轮询示例是使用 PE 的最基本示例。从本示例开始学习如何使用 DOCA PE。
您可以比较 pe_polling_sample.c 和任何其他 pe_x_sample.c,以查看其他示例演示的独特功能。
该示例演示了以下功能
如何创建 PE
如何将上下文连接到 PE
如何分配任务
如何提交任务
如何运行 PE
如何清理(例如,销毁上下文,销毁 PE)
注意请注意销毁的顺序(例如,所有上下文必须在 PE 之前销毁)。
该示例执行以下操作
使用一个 DMA 上下文。
分配并提交 16 个 DMA 任务。
信息任务完成回调检查复制的内容是否有效。
轮询直到所有任务完成。
pe_async_stop
上下文可以在仍在处理任务时停止。此停止是异步的,因为上下文必须完成/中止所有任务。
该示例演示了以下功能
如何异步停止上下文
如何实现上下文状态更改回调(关于上下文从停止移动到空闲)
如何实现任务错误回调(检查这是否是实际错误或任务是否已刷新)
该示例执行以下操作
提交 16 个任务,并在完成一半任务后停止上下文。
轮询直到所有任务完成(一半成功完成,一半刷新)。
pe_polling_sample.c 和 pe_async_stop_sample.c 之间的区别在于学习如何使用 PE API 进行事件驱动模式。
pe_event
事件驱动模式降低了 CPU 利用率(等待事件直到任务完成),但可能会增加延迟或降低性能。
该示例演示了以下功能
如何在事件驱动模式下运行 PE
该示例执行以下操作
运行 16 个 DMA 任务。
等待事件。
pe_polling_sample.c 和 pe_event_sample.c 之间的区别在于学习如何使用 PE API 进行事件驱动模式。
pe_multi_context
一个 PE 可以托管同一特定上下文的多个实例。这有助于使用单个 PE 运行多个 BlueField 设备。
该示例演示了以下功能
如何使用单个 PE 运行特定上下文的多个实例
该示例执行以下操作
将 4 个 DOCA DMA 上下文实例连接到 PE。
为每个上下文实例分配并提交 4 个任务。
轮询直到所有任务完成。
pe_polling_sample.c 和 pe_multi_context_sample.c 之间的区别在于学习如何将 PE 与上下文的多个实例一起使用。
pe_reactive
PE 和上下文可以在回调中维护(任务完成和状态更改)。
该示例演示了以下功能
如何在回调而不是程序的主函数中维护上下文和 PE
用户必须确保
查看任务完成回调和状态更改回调
查看
poll_to_completion和 main 中的轮询循环之间的区别
该示例执行以下操作
运行 16 个 DMA 任务。
在所有任务完成后,在完成回调中停止 DMA 上下文。
pe_polling_sample.c 和 pe_reactive_sample.c 之间的区别在于学习如何在反应模型中使用 PE。
pe_single_task_cb
DOCA 任务可以调用成功或错误回调。两个回调共享相同的结构(相同的输入参数)。
DOCA 建议使用 2 个回调
成功回调 – 无需检查任务状态,从而提高性能
错误回调 – 可能需要运行与成功回调不同的流程
该示例演示了以下功能
如何使用单个回调而不是两个回调
该示例执行以下操作
运行 16 个 DMA 任务。
使用单个回调处理完成。
pe_polling_sample.c 和 pe_single_task_comp_cb_sample.c 之间的区别在于学习如何将 PE 与单个完成回调一起使用。
pe_task_error
任务执行可能会失败,导致关联的上下文(例如,DMA)由于此致命错误而移动到停止状态。
该示例演示了以下功能
如何在运行时缓解任务错误
用户必须确保
查看状态更改回调和错误回调,以了解示例如何缓解上下文错误
该示例执行以下操作
提交 255 个任务。
使用导致硬件故障的无效参数分配第二个任务。
缓解故障并轮询直到所有提交的任务都被刷新。
pe_polling_sample.c 和 pe_task_error_sample.c 之间的区别在于学习如何缓解上下文错误。
pe_task_resubmit
任务可以在完成后释放或重用
任务重新提交可以提高性能,因为程序不会释放和分配任务。
任务重新提交可以减少内存使用量(使用更小的任务池)。
可以设置任务成员(例如,源或目标缓冲区),因此如果每次迭代都更改源或目标,则可以使用重新提交。
该示例演示了以下功能
如何在完成回调中重新提交任务
如何在 DMA 任务中替换缓冲区(类似于其他任务类型)
该示例执行以下操作
分配一组 4 个任务和 16 个缓冲区对。
通过重新提交任务,使用任务将所有源复制到目标。
pe_polling_sample.c 和 pe_task_resubmit_sample.c 之间的区别在于学习如何使用任务重新提交。
pe_task_try_submit
doca_task_submit 不验证任务输入(以提高性能)。开发人员可以使用 doca_task_try_submit 在开发期间验证任务。
任务验证会影响性能,不应在生产中使用。
该示例演示了以下功能
如何使用
doca_task_try_submit而不是doca_task_submit
该示例执行以下操作
分配并尝试使用
doca_task_try_submit提交任务。
pe_polling_sample.c 和 pe_task_try_submit_sample.c 之间的区别在于学习如何使用 doca_task_try_submit。
图示例
图示例演示了如何将 DOCA 图与 PE 一起使用。该示例可用于学习如何构建和使用 DOCA 图。
该示例使用 DOCA DMA 的两个节点和一个用户节点。
该图运行两个 DMA 节点(将源缓冲区复制到两个目标)。一旦两个节点都完成,该图将运行用户节点,该节点比较缓冲区。
该示例并行运行该图的 10 个实例。
本节列出了 DOCA SDK 的更改,这些更改会影响向后兼容性。
DOCA Core doca_buf
在 DOCA 2.0.2 之前,当将缓冲区用作输出参数时,缓冲区的数据长度被忽略,并且新数据覆盖了之前存在的数据。从现在开始,新数据将附加在现有数据(如果有)之后,同时相应地更新数据长度。
由于此更改,建议为便于使用,在分配目标缓冲区时不要包含数据段(数据长度为 0)。
在目标缓冲区中的数据长度为 0 的情况下,此更改将不会被注意到(因为附加数据和写入数据段具有相同的结果)。
重用缓冲区需要在希望写入相同数据地址(而不是附加数据)时重置数据长度,从而覆盖现有数据。为此需求专门添加了一个新函数 doca_buf_reset_data_len()。