迁移到 Triton 推理服务器#
迁移到新的推理堆栈可能看起来具有挑战性,但通过分解挑战并理解最佳实践,可以理解这项任务。在本指南中,我们将展示使用像 Triton 推理服务器这样的专用推理服务解决方案的一些好处,并介绍哪种路径最适合您采用 Triton。
为什么我们需要专用推理解决方案?#
构建服务推理所需的基础设施可能非常复杂。让我们考虑一个简单的情况,我们没有任何扩展,并且在单个节点上运行,无需负载均衡器。我们需要什么来服务模型?
如果您正在使用 Python,并且是模型推理领域的新手,或者只是想快速构建一些东西,您可能会转向像 Flask 这样的工具:一个通用的微框架,让您可以自由地根据需要构建生态系统。要在 flask 中提供任何服务,您只需要一个可以处理传入的 POST 请求的函数。
@app.route('/run_my_model',methods=['POST'])
def predict():
data = request.get_json(force=True)
# Pre-processing
...
prediction = model(<data>)
# Post-processing
...
return output
只需几行代码,我们的模型就已启动并运行。任何人都可以发送请求并使用该模型!但是,等等,当我们开始接收多个请求时会发生什么?我们需要一种方法来排队这些任务/请求。假设我们使用 Celery 并解决这个排队挑战。同时,我们还可以构建一个响应缓存来处理重复查询。
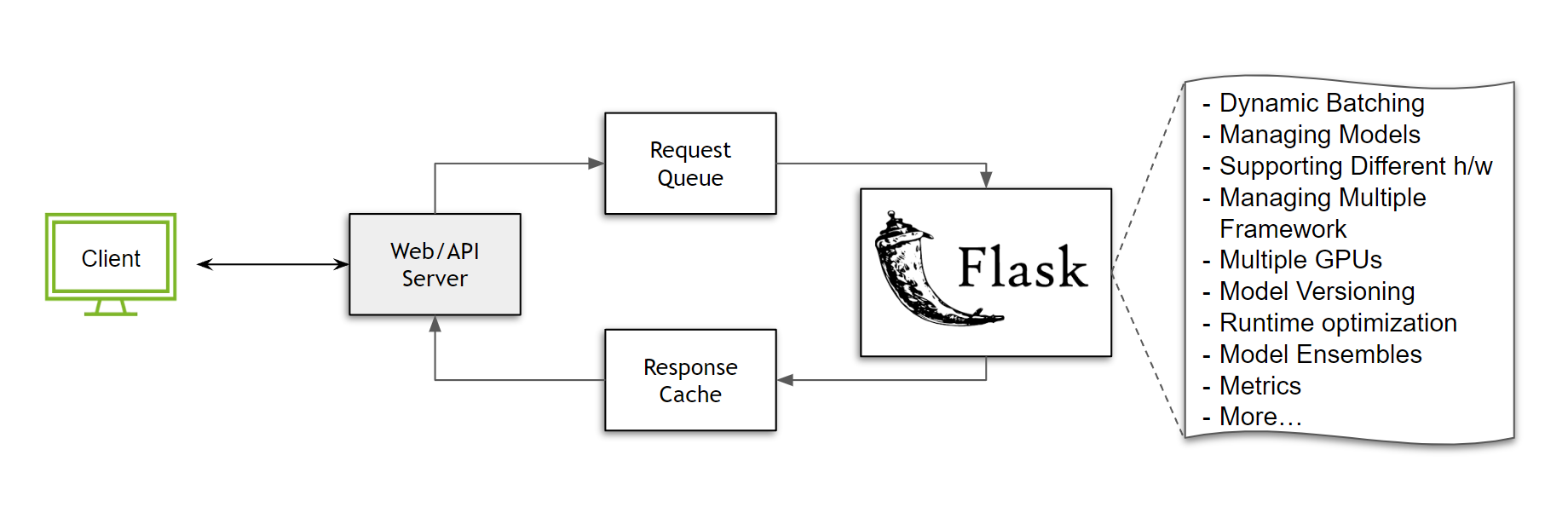
虽然上面的设置确实有效,但它非常受限且资源效率低下。为什么?假设我们正在使用图像分类模型,其最大批处理大小为 64,并且我们的服务器每 100 ms 接收 50 个请求。在不实施任何形式的批处理策略的情况下,所有这些请求都必须按顺序处理,从而浪费 GPU 资源。这只是冰山一角。考虑以下情况
如果我们想支持多个模型怎么办?每次我们必须更新模型时,我们需要重启服务器吗?
我们如何对模型进行版本控制?
我们可以在同一服务器上提供 PyTorch 和 TensorFlow 模型吗?
如果一个模型需要在 CPU 上运行,而另一个模型需要 GPU 怎么办?我们如何优化执行?
我们如何在同一节点上管理多个 GPU?
我们的执行运行时是否优化?我们是否有效地处理 I/O?
我们如何使用模型集成?
监控服务器指标的最佳方法是什么?
这些只是我们必须做出的一些考虑,并投入工程时间来构建。此外,这些功能必须定期维护和优化,以适应每个主要版本的软件和硬件加速器或执行环境。随着部署规模的扩大,这些挑战只会变得更加严峻。显然,解决方案不可能是每个开发人员都从一个多用途框架开始,并花费资源来构建和维护基础设施。而这正是拥有像 Triton 推理服务器这样专门构建的推理服务器能够解决很多问题的地方。
我如何将我的工作流程迁移到 Triton?#
本指南假定您在概念层面上理解 Triton 推理服务器的基础知识。如果您是 Triton 推理服务器的新手,您可能需要先查看这个入门视频和本指南。
每个现有的推理管道都是独一无二的,因此没有“一刀切”的解决方案可以将您当前的堆栈迁移到 Triton 推理服务器。尽管如此,本指南将尝试建立直觉,以简化迁移过程。广义上讲,大多数推理堆栈都属于四个通用类别。
与更大的模块紧密耦合:也许您正在迭代或微调模型,其中将模型从现有堆栈中解耦将需要相当大的努力。您仍然需要更好的性能来尽可能少地使用硬件资源,并与内部团队共享您的开发分支。隔离依赖项、导出模型、设置某种形式的存储等所需的工作是不可行的。您需要的是一个可以注入到现有代码库中的解决方案,该解决方案不会具有侵入性或耗时。
在这种情况下,我们建议使用 PyTriton,它是一个类似于 Flask/FastAPI 的接口,用户可以使用它为他们的用例利用 Triton 推理服务器。
from pytriton.decorators import sample from pytriton.model_config import ModelConfig, Tensor from pytriton.triton import Triton MODEL = ... @sample def <your_function_name>(sequence: np.ndarray, labels: np.ndarray): # Decode input sequence = np.char.decode(sequence.astype("bytes"), "utf-8") labels = np.char.decode(labels.astype("bytes"), "utf-8") result = MODEL(...) return {"scores": results} # PyTriton code with Triton() as triton: triton.bind( model_name="<model name>", infer_func=<your_function_name>, # function you want to serve inputs=[ Tensor(name="sequence", dtype=bytes, shape=(1,)), Tensor(name="labels", dtype=bytes, shape=(-1,)), ], outputs=[ Tensor(name="scores", dtype=np.float32, shape=(-1,)), ], # add the features you want to enable here config=ModelConfig(batching=False), ) triton.serve()
上面的示例是此示例的骨架版本。需要注意的关键点是,您希望提供的任何函数,无论它是否具有模型推理组件或只是一些 python 代码,都可以绑定到 Triton。作为用户,您不必担心启动 Triton 推理服务器或构建模型仓库,所有必需的步骤都由 PyTriton 库处理。有关架构的更多信息可以在这里找到。
松散耦合,但管道混乱:假设您正在服务的管道可以隔离到不同的环境中。用户通常在模型和管道经过内部测试并产生令人满意的结果时处于此阶段。他们可能仍在处理混乱的管道,其中某些模型无法导出,并且预处理/后处理步骤仍然与管道逻辑紧密耦合。
在这种情况下,用户仍然可以使用 pytriton,但如果某些模型是可导出的,则用户可以通过使用 Triton 的 Python 后端以及其他框架后端来获得更高的性能。概念指南的第 6 部分是这种情况的绝佳示例。
目前,并非所有 Triton 推理服务器的功能都可以使用 PyTriton 来利用。用户还可以选择使用 Python 后端来利用 Triton 推理服务器提供的全部功能集。这个HuggingFace 示例可以引导您了解具体细节。
松散耦合、模块化管道:随着管道复杂性的增加,通常会出现深度学习管道中存在相当大的重叠的情况,即多个管道正在使用一组通用的模型或预处理/后处理步骤。在这些情况下,将管道的所有组件部署在 Triton 推理服务器上,然后构建模型集成是非常有益的。即使在没有重叠的情况下,使用 Triton 的模型集成来管理管道也可以提供扩展和性能优势。有关深入解释,请参阅本指南。
部署没有预处理/后处理的单个模型:在许多情况下,管道逻辑以多年开发构建的极其优化的底层脚本的形式存在。在这种情况下,用户可能更喜欢仅部署模型并避免 HTTP/gRPC 网络调用,因为模型正在被更大的应用程序使用。对于这种情况,可以使用 Triton 的共享内存扩展和C API 访问模型,从而无需网络接口。
结论#
虽然部署模型的方法有很多种,但每种情况都提出了自己的挑战和要求。这些要求可以通过使用各种 Triton 推理服务器功能来满足。我们鼓励您浏览 Triton 推理服务器文档,以找到有关这些功能的更多详细信息!